本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
紹介する論文は、
「FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing」です。
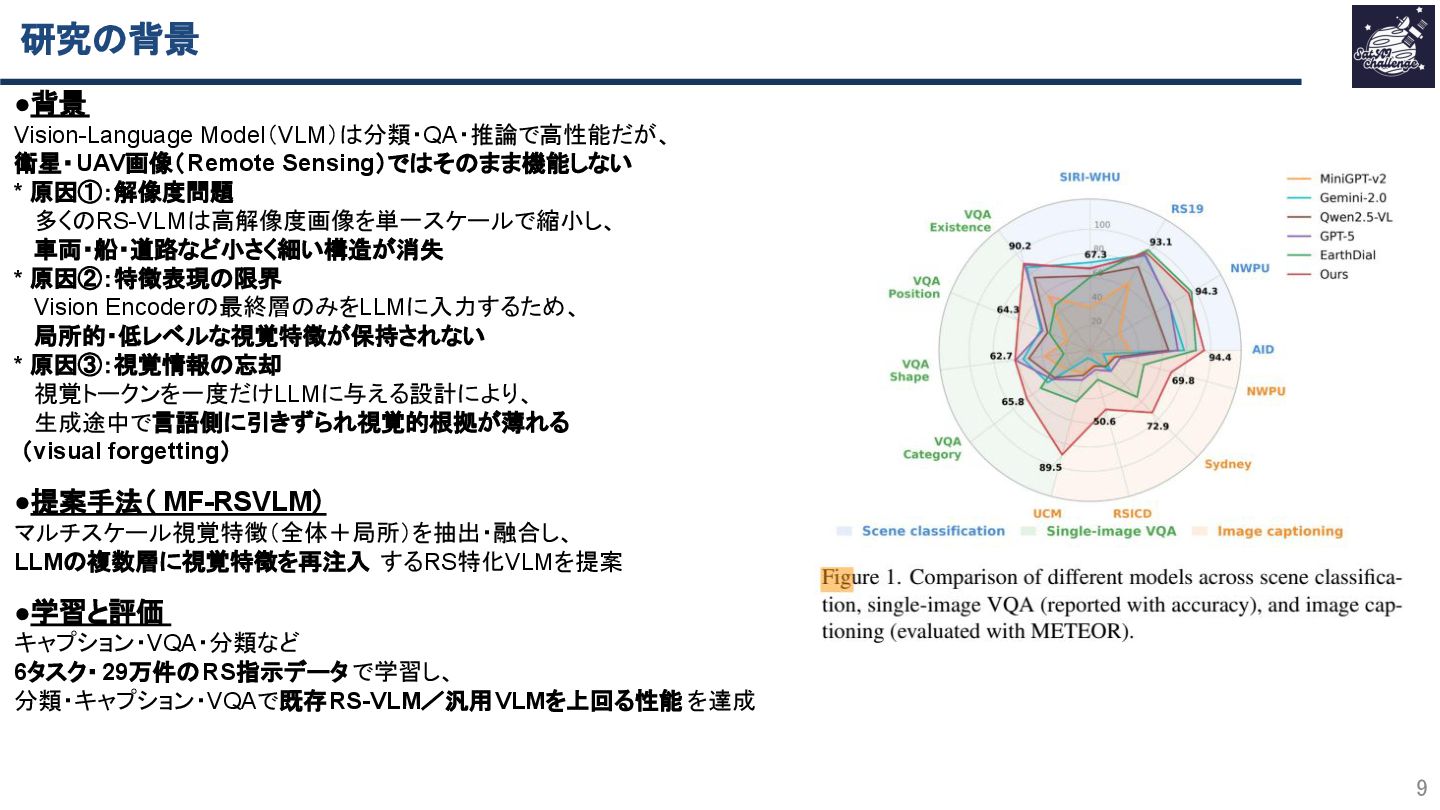
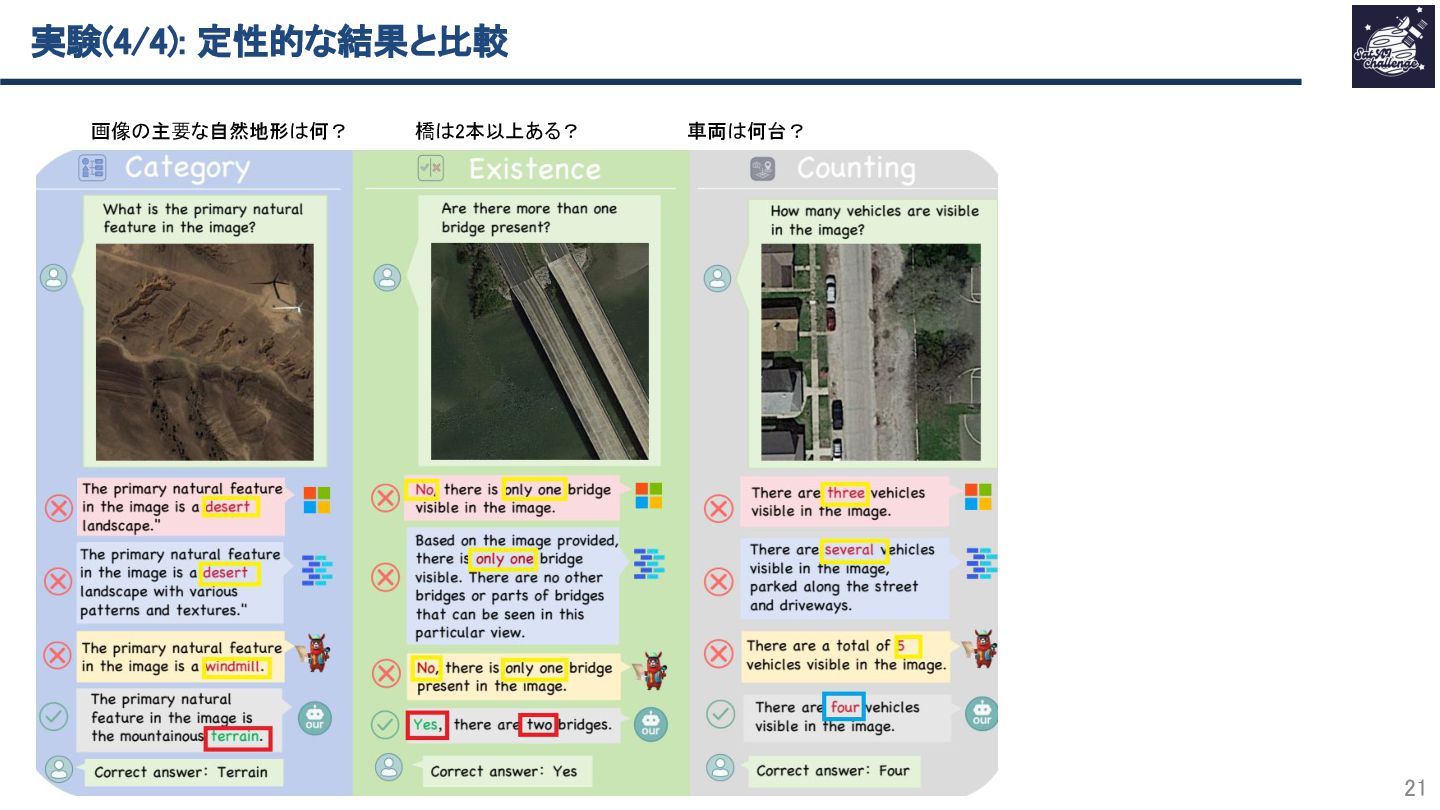
本研究は、衛星・UAV画像を対象に、マルチスケール視覚特徴の融合と再注入によって、
小物体・数・位置関係まで含めた状況説明・VQA・分類・キャプション生成を
高精度に行うリモートセンシング特化VLMを提案します。
293Kの指示データで学習し、視覚情報の“忘却”を抑える設計により、
複数RSベンチマークで既存RS-VLMや汎用VLMを安定して上回る性能を示しています。
Dang et al. (2025), “FUSE-RSVLM: Feature Fusion Vision-Language Model for Remote Sensing” arXiv:2512.24022. より引用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験(1/4): 実験設定 18 •評価タスク( 3系統) [1]. VQA(質問応答)[2]. Scene Classification(シーン分類)[3].](https://files.speakerdeck.com/presentations/902e916850664559bd5aa8db4d659404/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}