本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、
より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。
speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
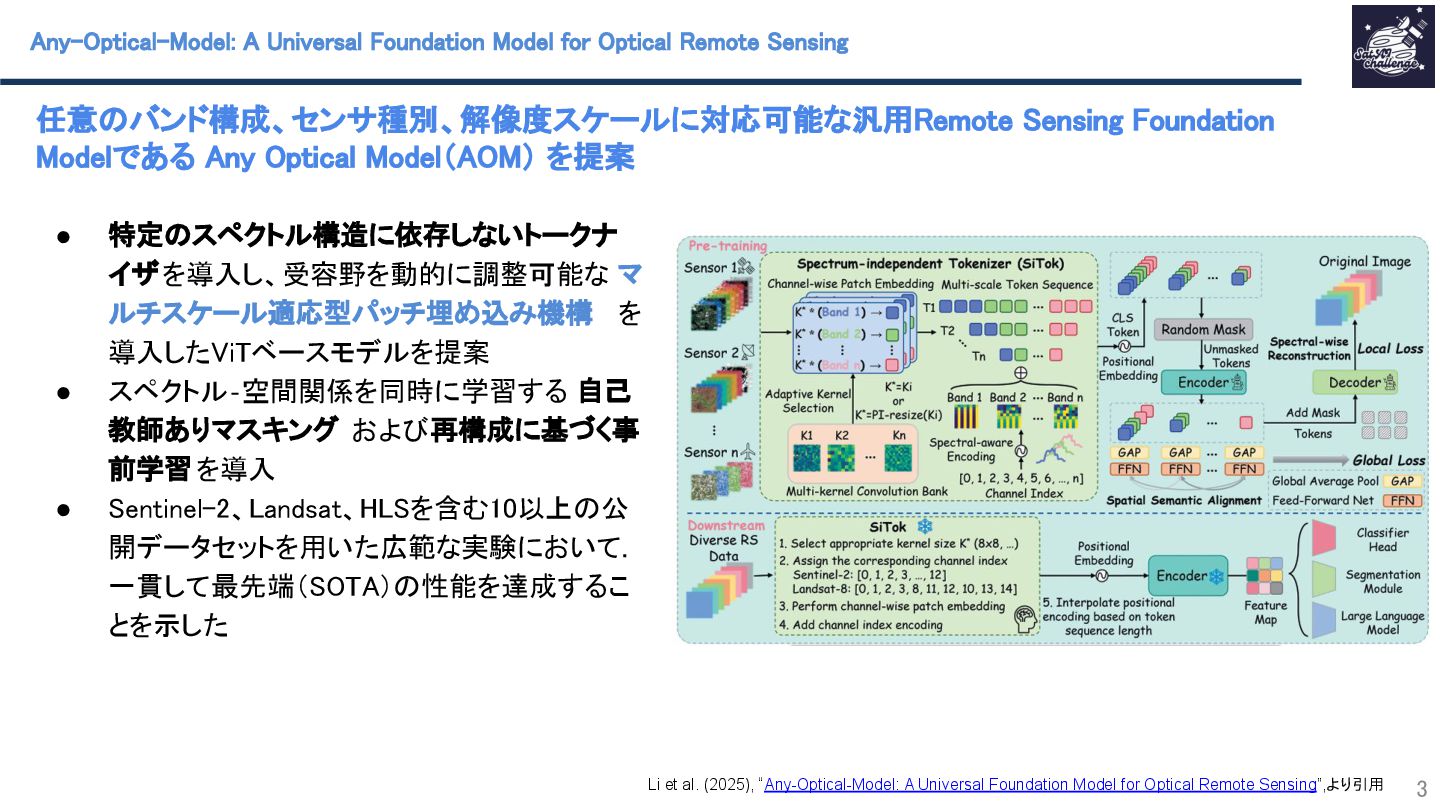
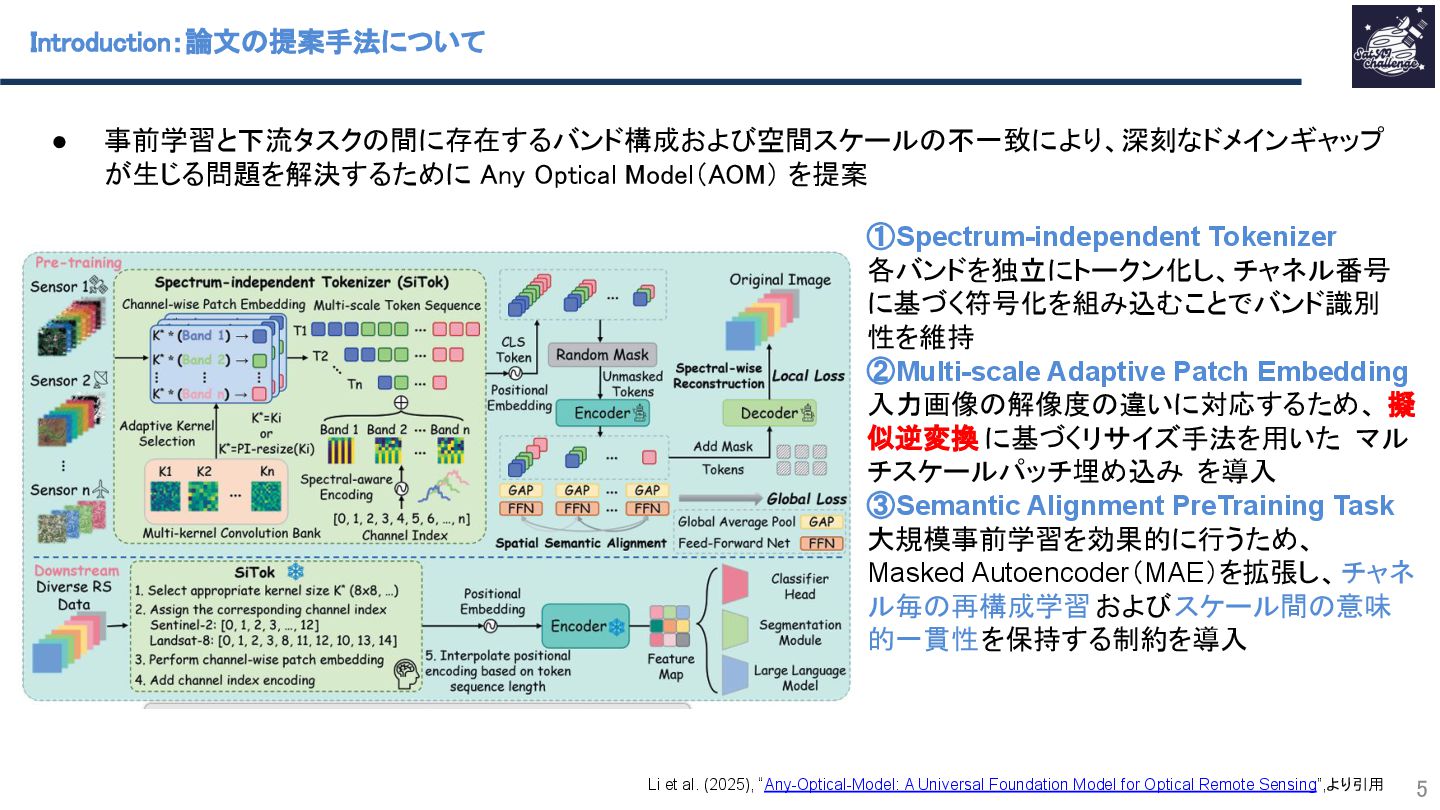
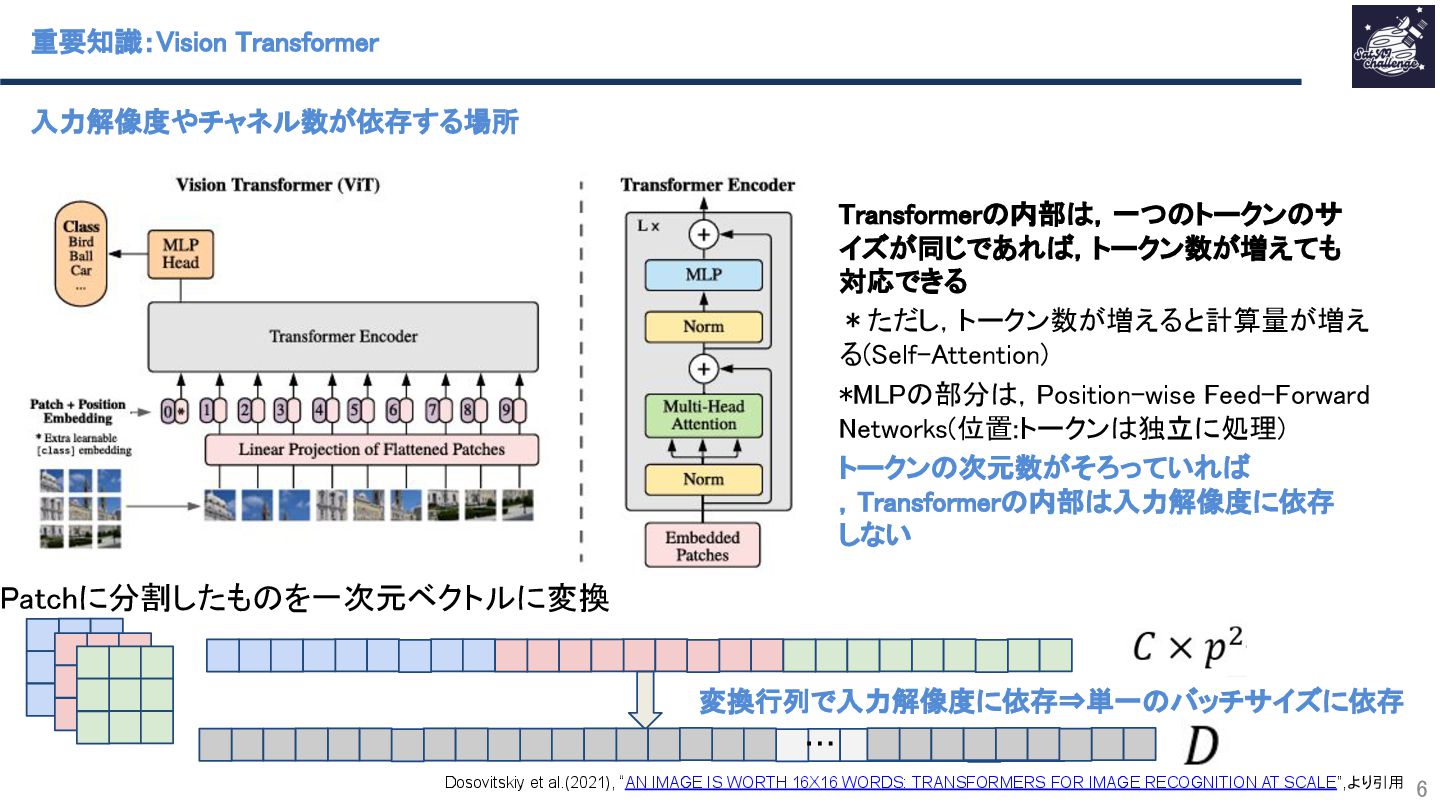
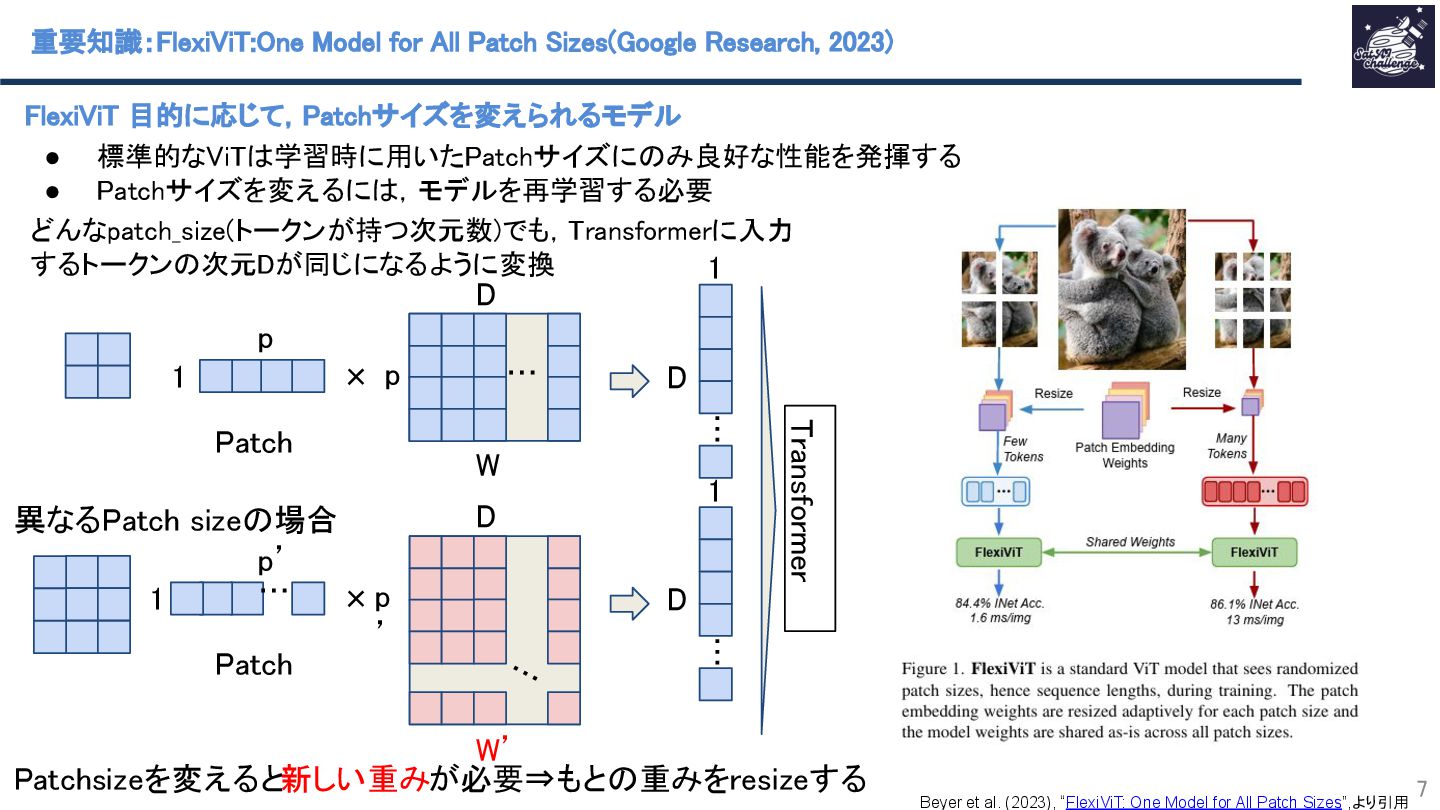
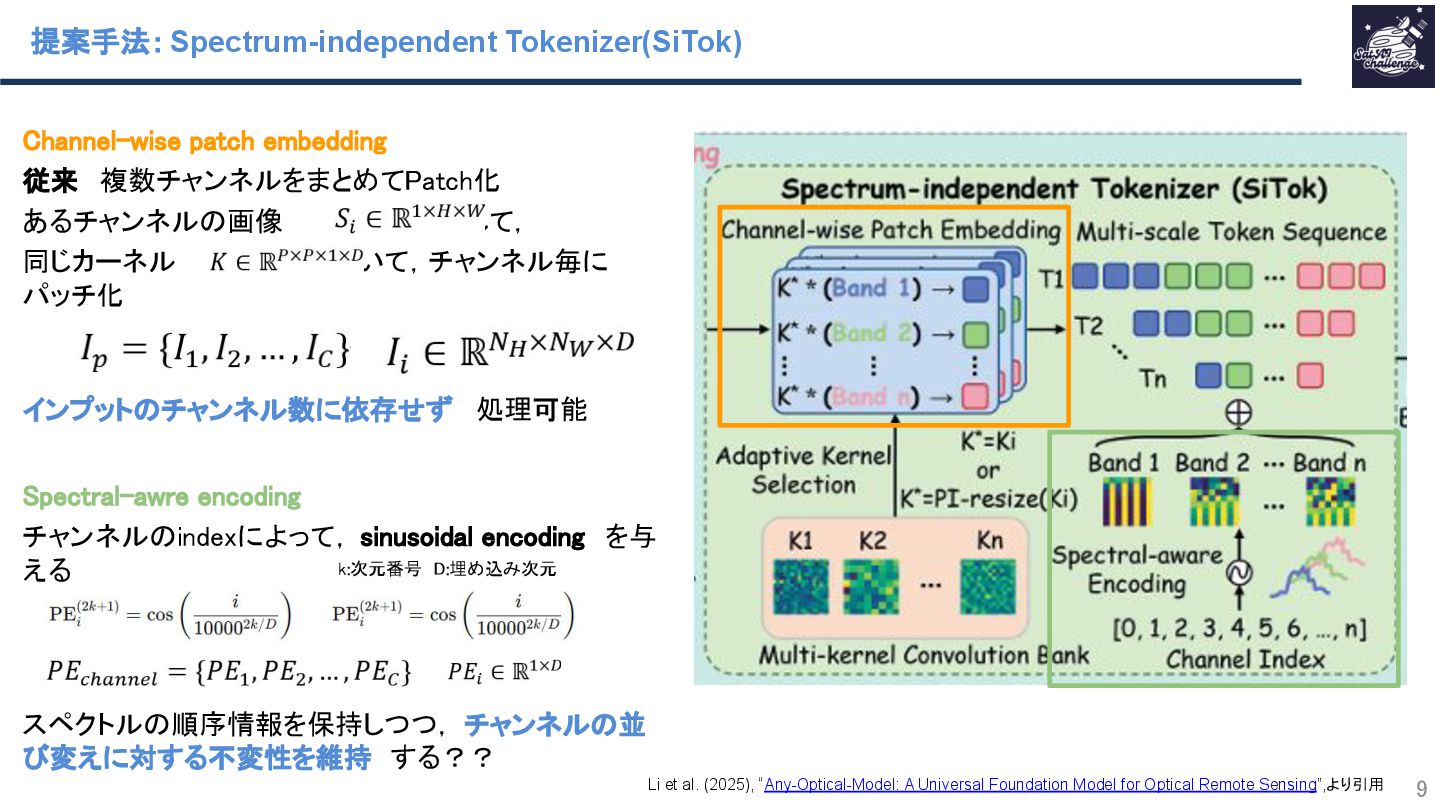
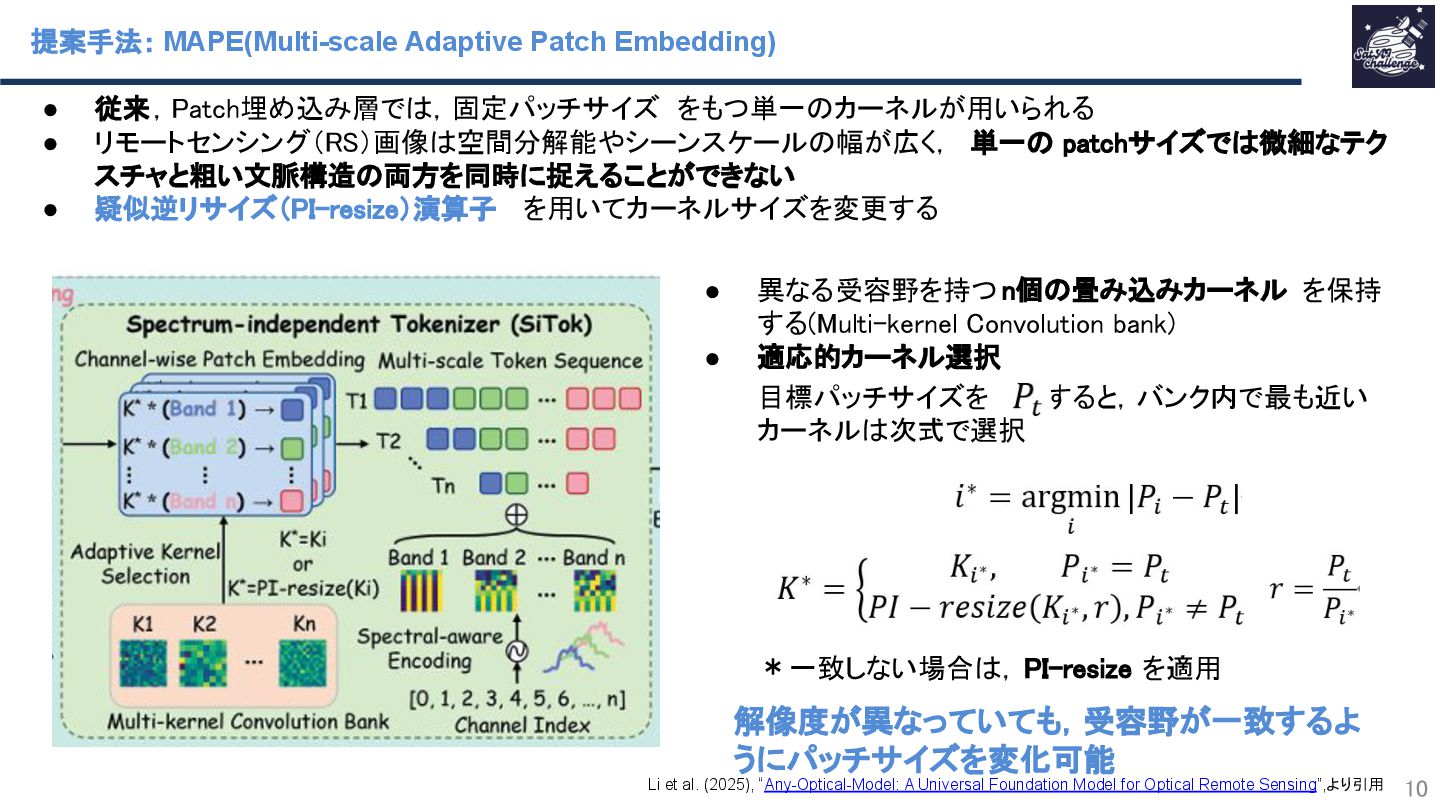
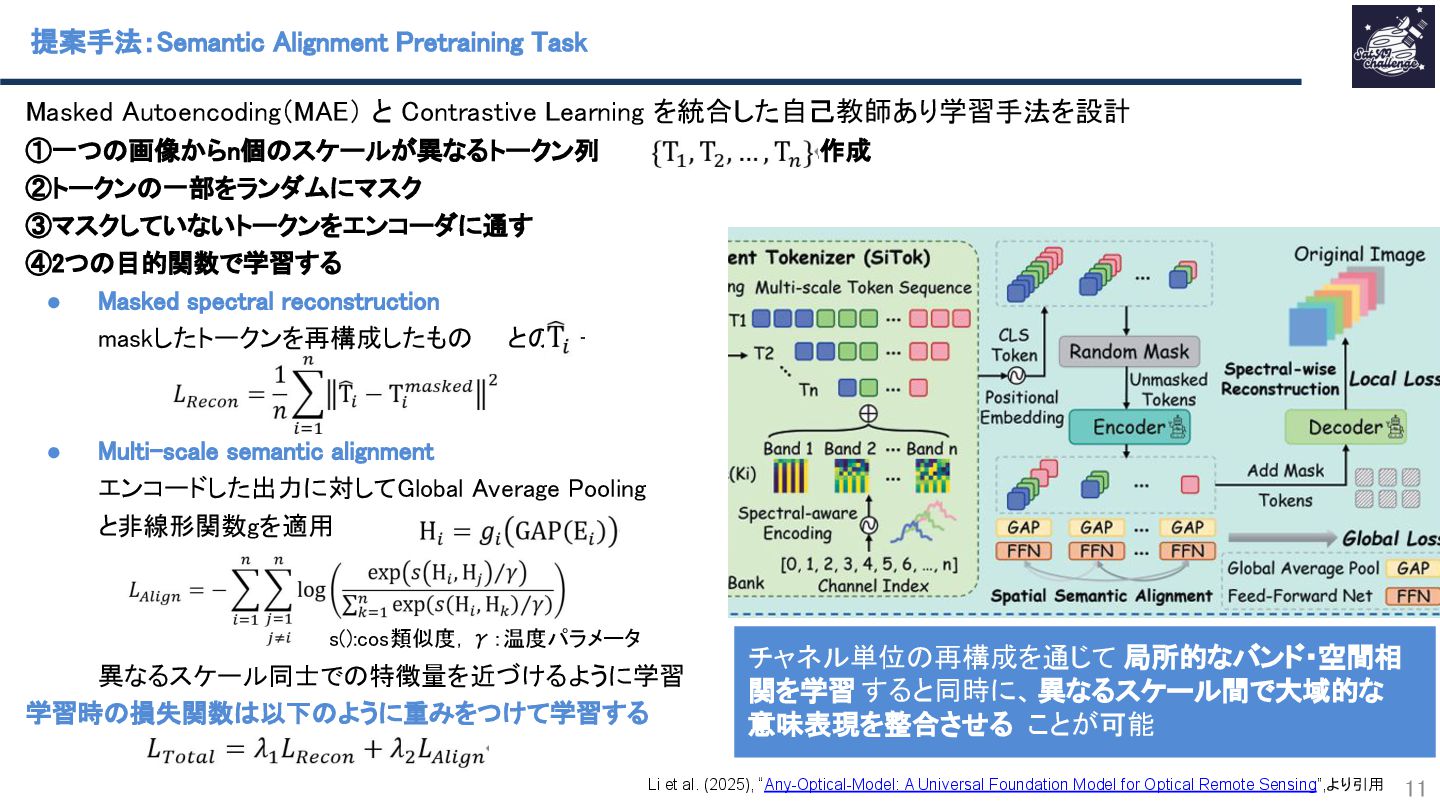
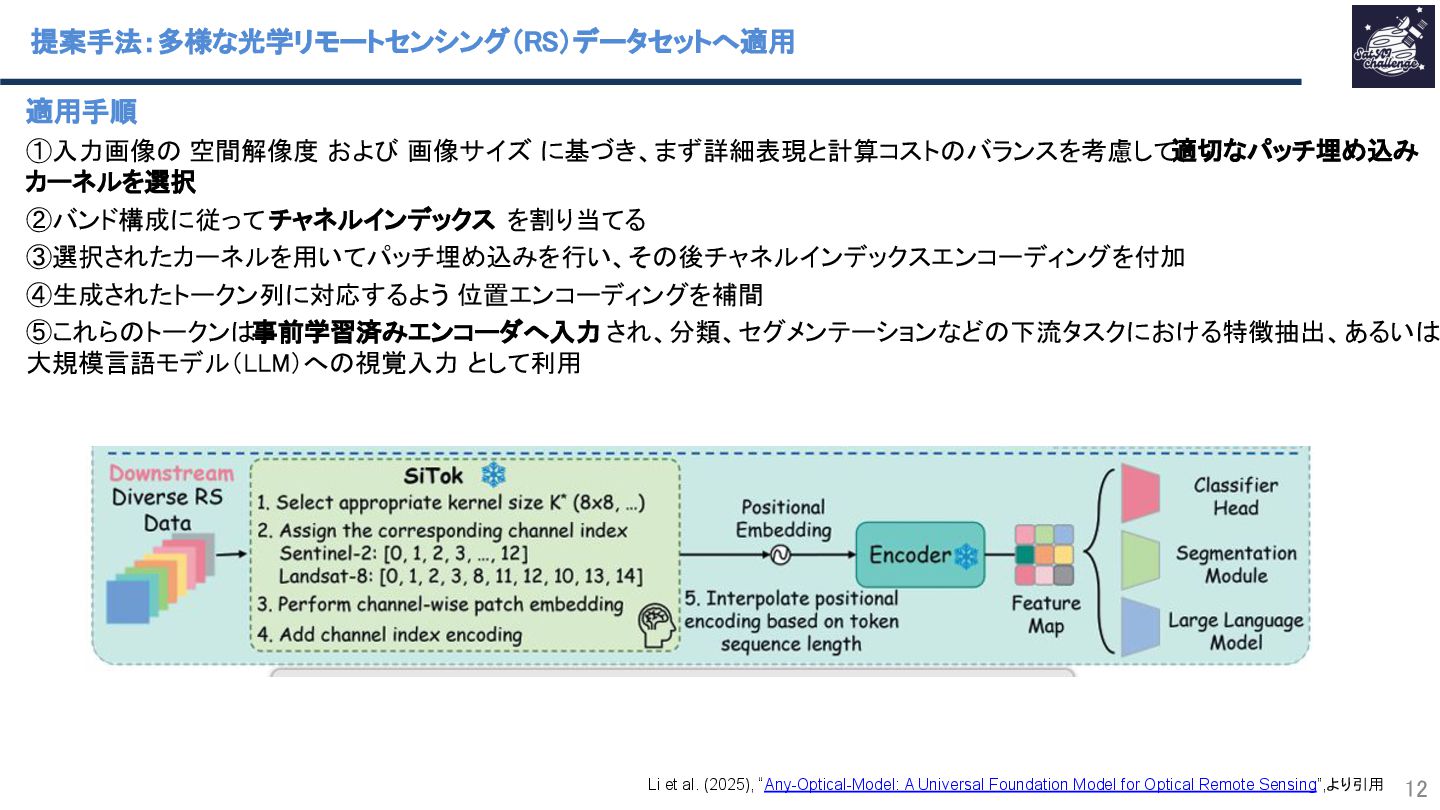
紹介する論文は、「Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing」です.本研究では、任意のバンド構成、センサ種別、解像度スケールに対応可能な汎用Remote Sensing Foundation Modelである Any Optical Model(AOM)を提案.具体的には,特定のスペクトル構造に依存しないトークナイザと,Patchsizeを動的に調整可能なマルチスケール適応型パッチ埋め込み機構を導入したViTベースモデルであり,事前学習法として,スペクトル‐空間関係を同時に学習する自己教師ありマスキングおよび再構成に基づく事前学習を導入.Sentinel-2、Landsat等を含む10以上の公開データセットを用いた実験において.一貫して最先端(SOTA)の性能を達成することを示した.
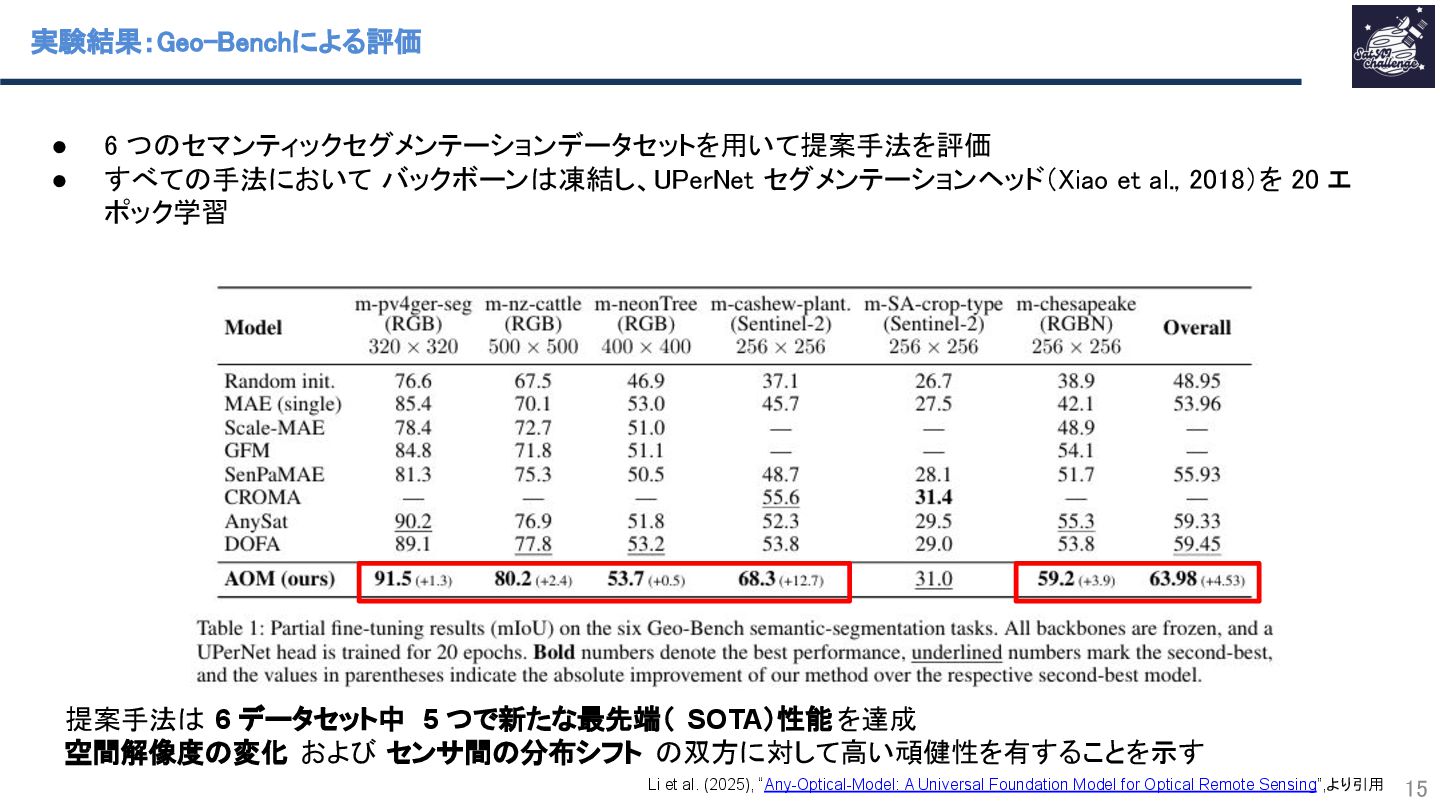
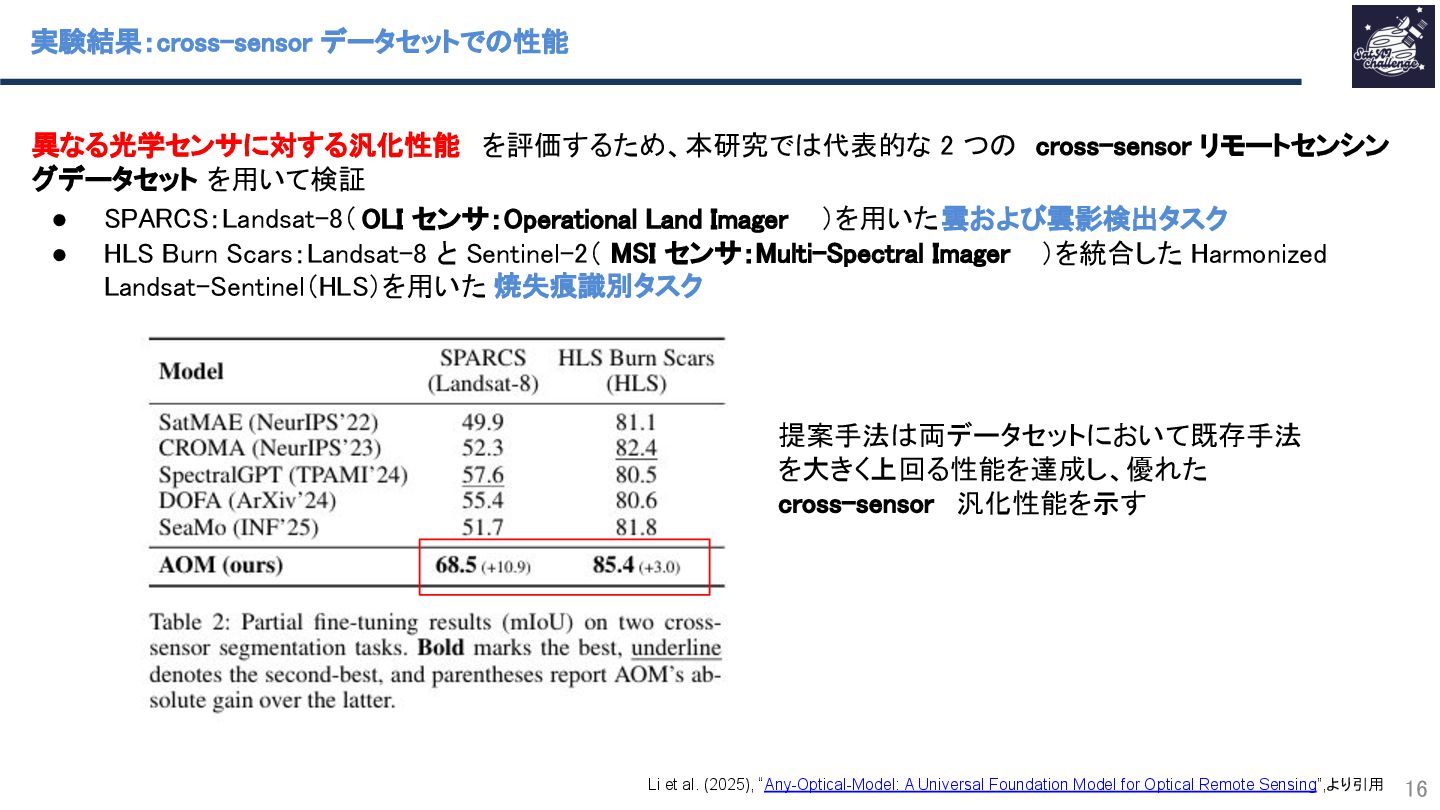
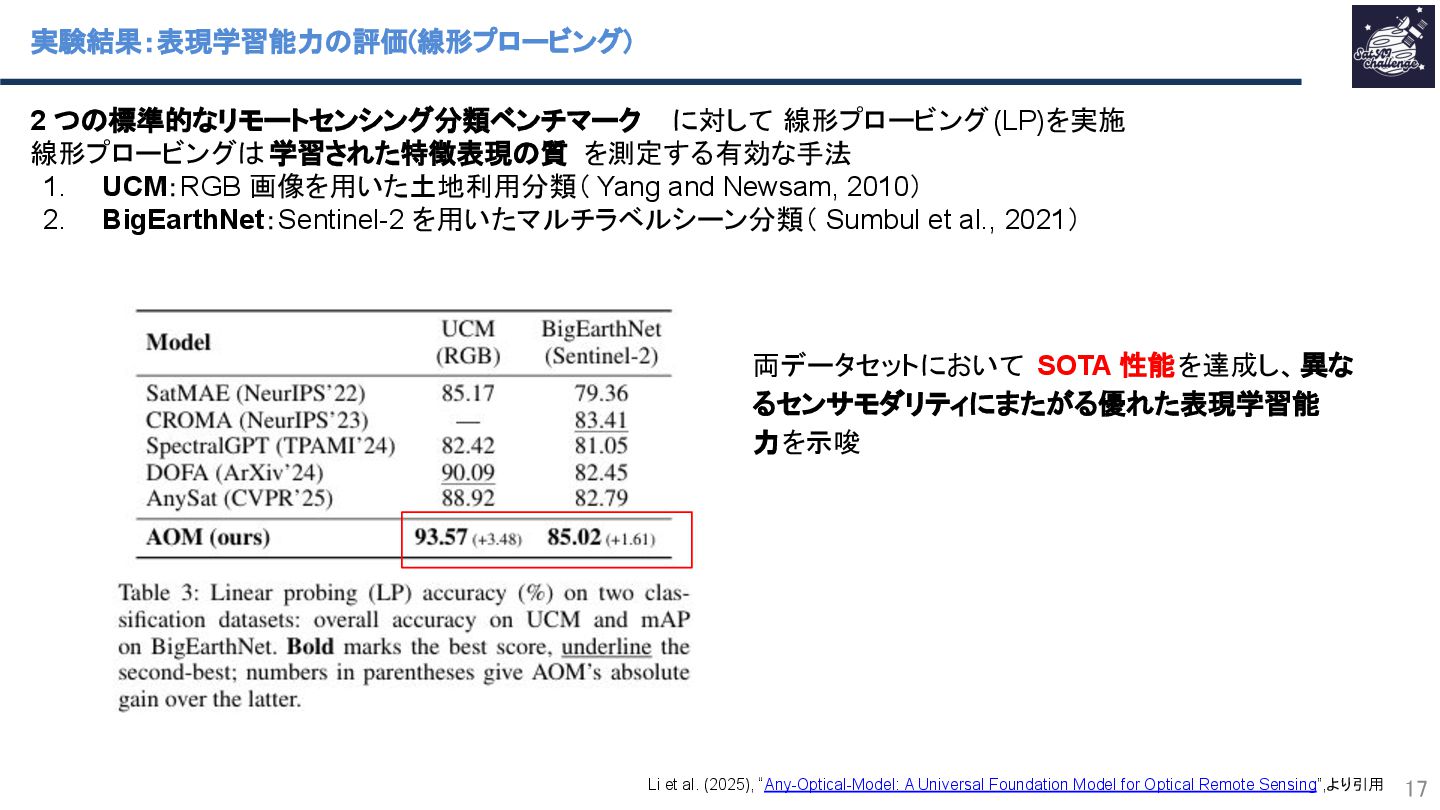
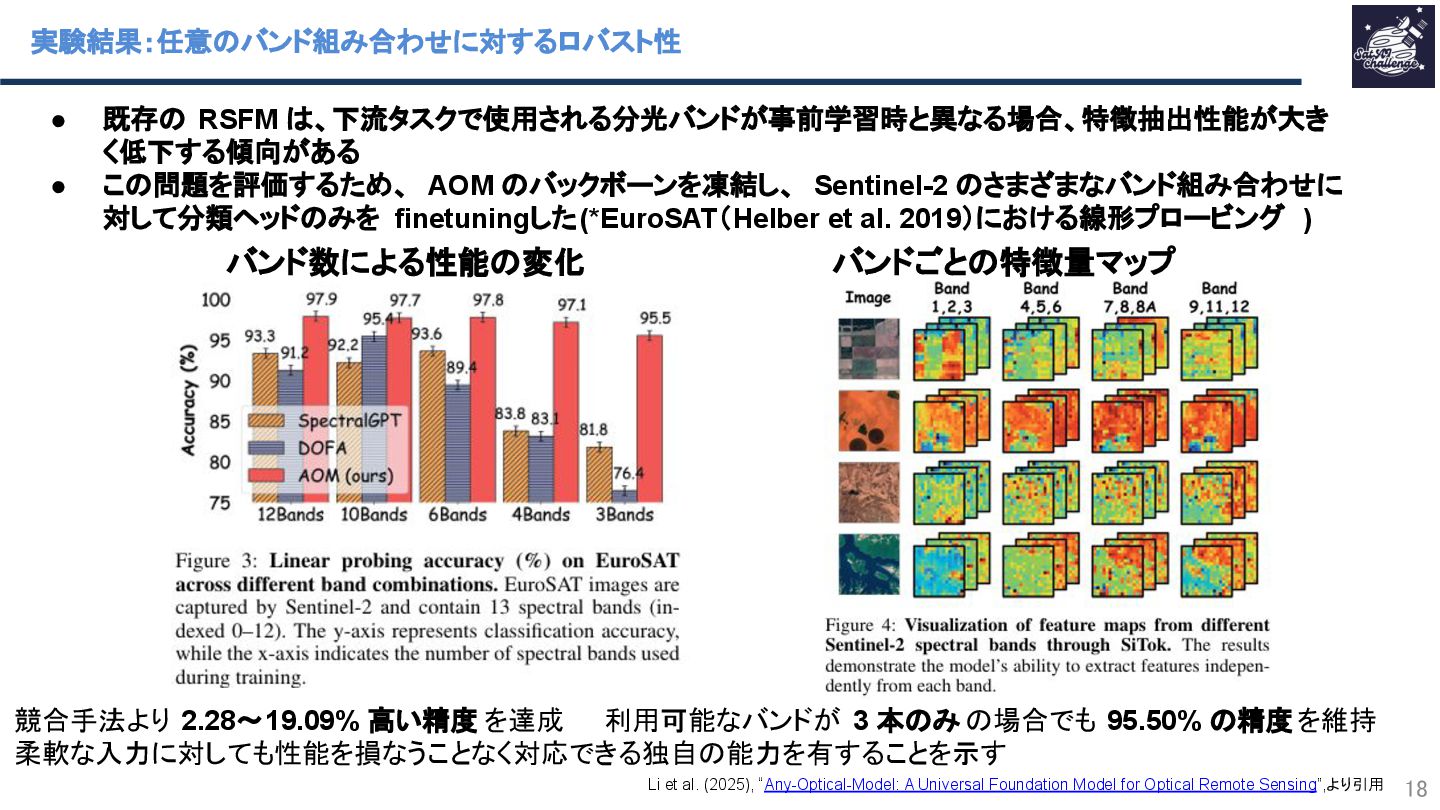
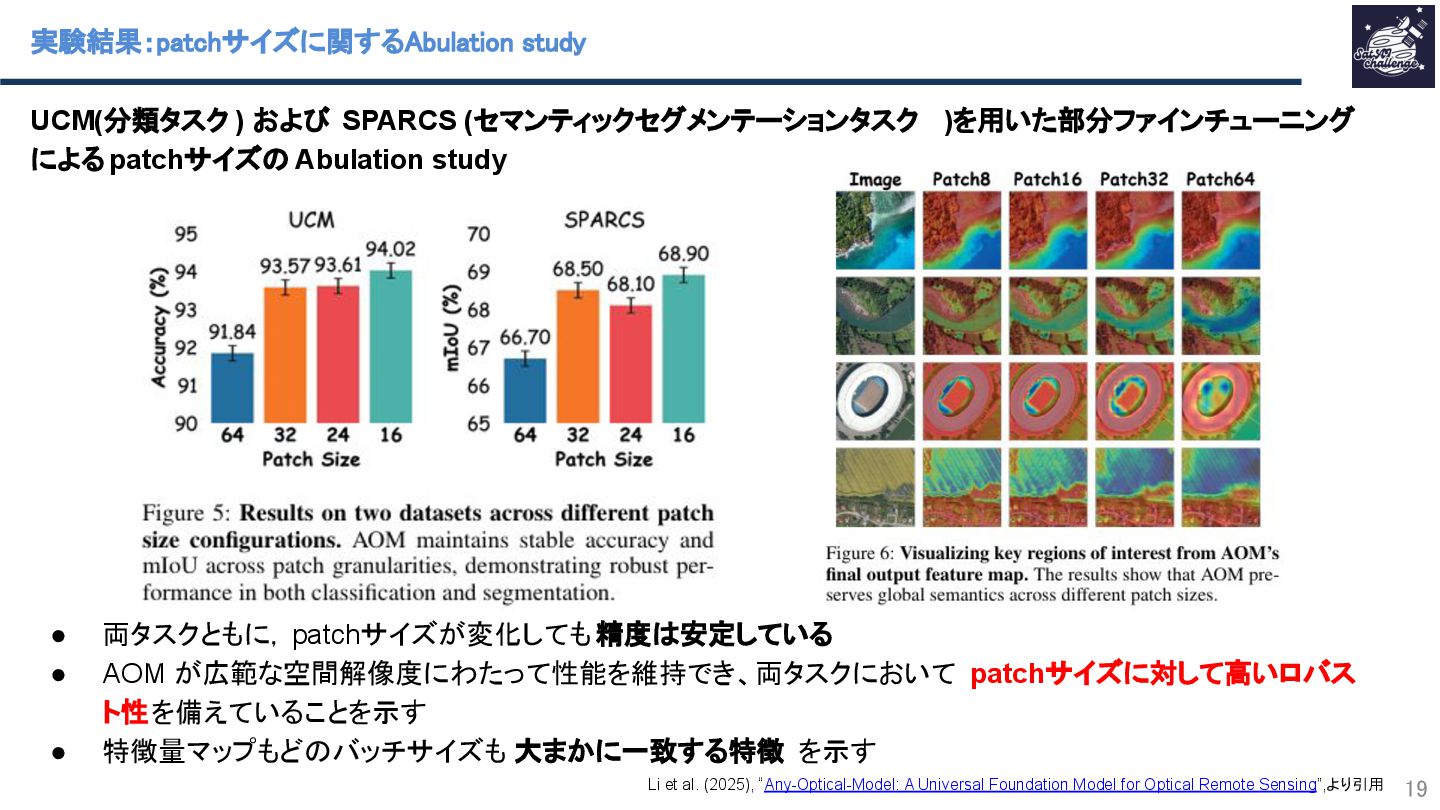
Li et al. (2025), “Any-Optical-Model: A Universal Foundation Model for Optical Remote Sensing”,より引用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}