Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Multi-Scale Self-Attention for Text Classification
Search
Scatter Lab Inc.
January 16, 2020
Research
2.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Multi-Scale Self-Attention for Text Classification
Scatter Lab Inc.
January 16, 2020
More Decks by Scatter Lab Inc.
See All by Scatter Lab Inc.
zeta introduction
scatterlab
0
1.9k
SimCLR: A Simple Framework for Contrastive Learning of Visual Representations
scatterlab
0
4.4k
Adversarial Filters of Dataset Biases
scatterlab
0
2.3k
Sparse, Dense, and Attentional Representations for Text Retrieval
scatterlab
0
2.3k
Weight Poisoning Attacks on Pre-trained Models
scatterlab
0
2.2k
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
scatterlab
0
2.6k
Beyond Accuracy: Behavioral Testing of NLP Models with CheckList
scatterlab
0
2.3k
Open-Retrieval Conversational Question Answering
scatterlab
0
2.3k
What Can Neural Networks Reason About?
scatterlab
0
2.3k
Other Decks in Research
See All in Research
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
880
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
羽田新ルート運用6年の検証
1manken
0
170
AIで最適化を解けるか?
mickey_kubo
0
140
typst の使い方:言語学を研究する学生のために
gitomochang
0
510
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
220
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
440
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
300
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
230
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
190
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
110
Featured
See All Featured
We Have a Design System, Now What?
morganepeng
55
8.2k
HDC tutorial
michielstock
2
750
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Art, The Web, and Tiny UX
lynnandtonic
304
22k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Side Projects
sachag
455
43k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Transcript
Multi-Scale Self-Attention for Text Classification ߔ (ML Research Scientist, Pingpong)
ݾର ݾର! 1. Introduction 1. Self-Attention 2. Problem 2. Proposed
Method 1. Scale-Aware Self-Attention 2. Multi-Scale Multi-Head Self-Attention 3. Multi-Scale Transformer 3. Experiments 1. Effective Scale 2. Text Classification
Introduction Introduction
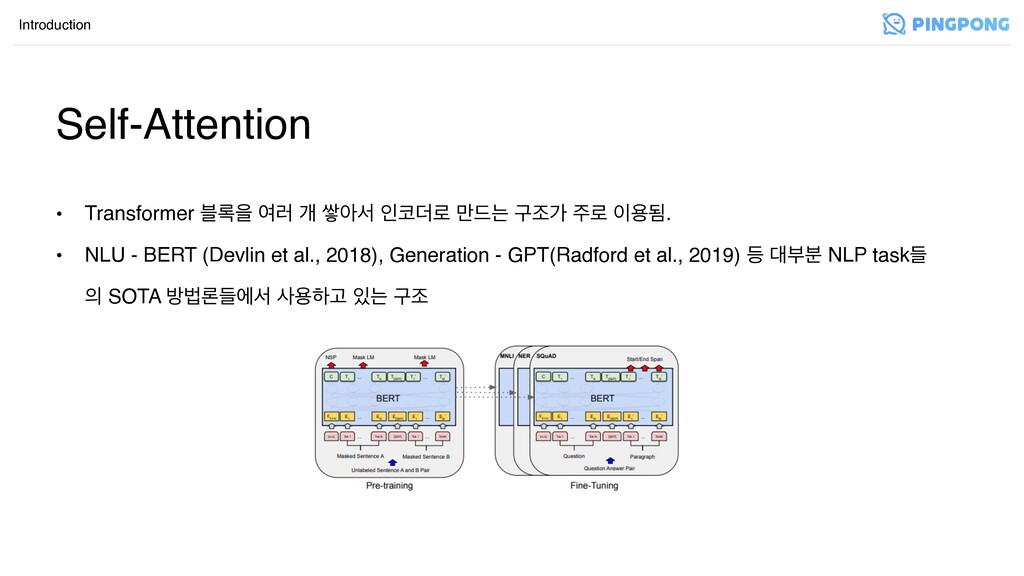
• Attention Is All You Need (Vaswani et al., 2017)
ী ࣗѐػ ӝߨ • ӝઓ Attention Key, Queryо ܰѱ ਊغਵա(Encoder-Decoder), Key, Query, Valueܳ э ѱ ਊ(Self-Attention) • Multi-head: э Key,Query,Value۽ ৈ۞ Headо ة݀ਵ۽ Attention োਸ ೯ೣਵ۽ॄ, নೠ ন࢚ਸ ݽ؛݂ೞӝ ਤೠӝߨ Introduction Self-Attention
• Transformer ࠶۾ਸ ৈ۞ ѐ ऺইࢲ ੋ؊۽ ݅٘ח ҳઑо ۽
ਊؽ. • NLU - BERT (Devlin et al., 2018), Generation - GPT(Radford et al., 2019) ١ ࠗ࠙ NLP taskٜ SOTA ߑߨۿٜীࢲ ࢎਊೞҊ ח ҳઑ Introduction Self-Attention
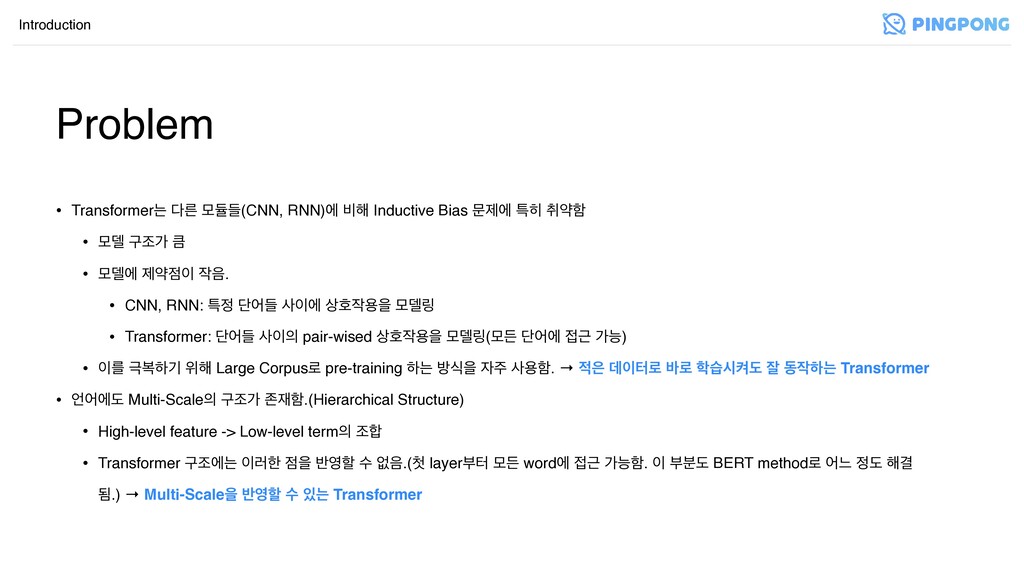
• Transformerח ܲ ݽٕٜ(CNN, RNN)ী ࠺೧ Inductive Bias ޙઁী ౠ
ஂডೣ • ݽ؛ ҳઑо ఀ • ݽ؛ী ઁড . • CNN, RNN: ౠ ױযٜ ࢎী ࢚ഐਊਸ ݽ؛݂ • Transformer: ױযٜ ࢎ pair-wised ࢚ഐਊਸ ݽ؛݂(ݽٚ ױযী Ӕ оמ) • ܳ ӓࠂೞӝ ਤ೧ Large Corpus۽ pre-training ೞח ߑधਸ ࢎਊೣ. → ؘఠ۽ ߄۽ णदெب ੜ زೞח Transformer • যীب Multi-Scale ҳઑо ઓೣ.(Hierarchical Structure) • High-level feature -> Low-level term ઑ • Transformer ҳઑীח ۞ೠ ਸ ߈ೡ ࣻ হ.( layerࠗఠ ݽٚ wordী Ӕ оמೣ. ࠗ࠙ب BERT method۽ যו ب ೧Ѿ ؽ.) → Multi-Scaleਸ ߈ೡ ࣻ ח Transformer Introduction Problem
Proposed Method Proposed Method
Scale-Aware Self-Attention Proposed Method
Scale-Aware Self-Attention Proposed Method ೞա Headীࢲ п token attend ೡ
ࣻ ח ߧਤܳ [-w, w] ࢎ۽ ગ൨.
Multi-Scale Multi-Head Self-Attention Proposed Method п Head݃ attendೡ ࣻ ח
ߧਤܳ ܰѱ оઉх(Multi-Scale Multi-Head).
Multi-Scale Transformer Proposed Method • FFNਸ ࢎਊೞ ঋ. (w=1 +
non-linear activation Ѿҗ৬ زੌೞҊ ࠅ ࣻ ) • Positional Embeddingب ࢎਊೞ ঋ (small-scale۽ )
Multi-Scale Transformer Proposed Method • Classification Node • Bertীࢲח [CLS]
ష representationਸ Classificationী ਊೣ • [CLS]ష representation + աݠ ష representation max pooling feature
Experiments Experiments
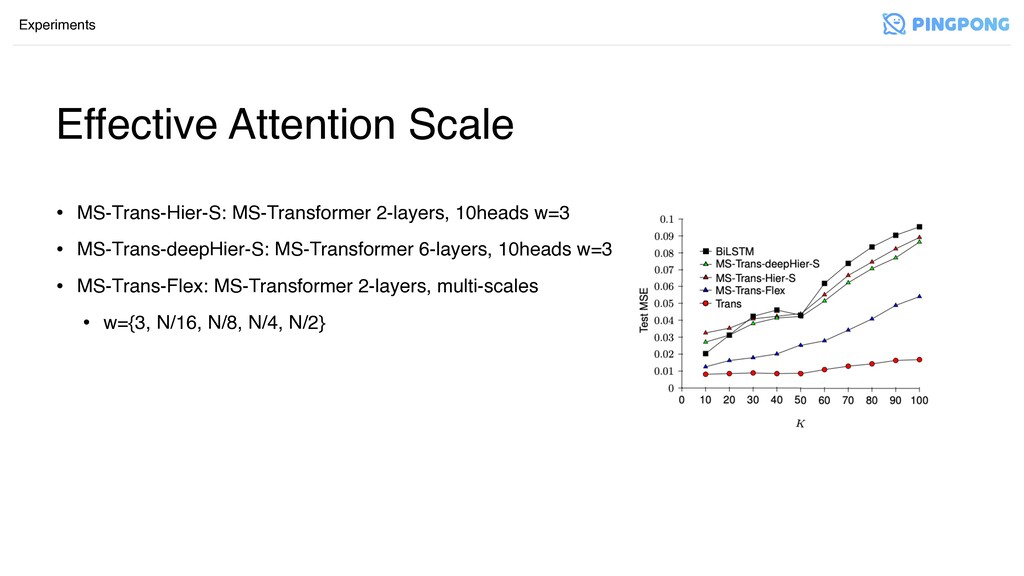
Effective Attention Scale Experiments • Sequence long-range dependancyܳ ੜ ݽ؛݂ೞח
ഛੋೡ ࣻ ח पਸ ӝദ • input: • п aח uniform distribution U(0,1)۽ ࠗఠ random sampling • target: • ড 20݅ѐ ण/పझ ࣇਸ ٜ݅যࢲ णदఇ A = {a 1 , . . . a N }, a ∈ Rd K ∑ i= 1 a i ⊙ a N−i+1
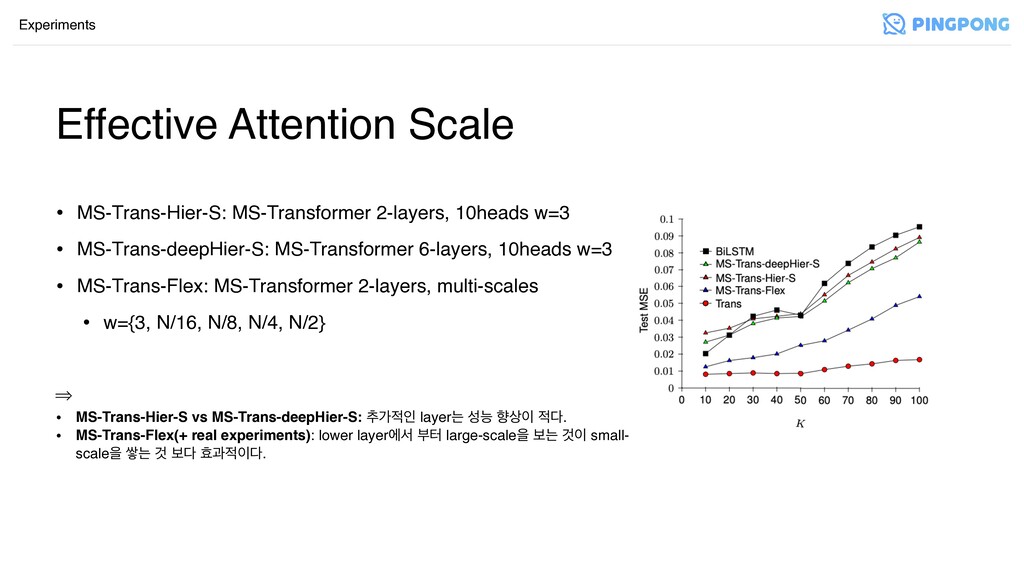
Effective Attention Scale Experiments • MS-Trans-Hier-S: MS-Transformer 2-layers, 10heads w=3
• MS-Trans-deepHier-S: MS-Transformer 6-layers, 10heads w=3 • MS-Trans-Flex: MS-Transformer 2-layers, multi-scales • w={3, N/16, N/8, N/4, N/2}
Effective Attention Scale Experiments • MS-Trans-Hier-S: MS-Transformer 2-layers, 10heads w=3
• MS-Trans-deepHier-S: MS-Transformer 6-layers, 10heads w=3 • MS-Trans-Flex: MS-Transformer 2-layers, multi-scales • w={3, N/16, N/8, N/4, N/2} Ã • MS-Trans-Hier-S vs MS-Trans-deepHier-S: ୶оੋ layerח ࢿמ ೱ࢚ . • MS-Trans-Flex(+ real experiments): lower layerীࢲ ࠗఠ large-scaleਸ ࠁח Ѫ small- scaleਸ ऺח Ѫ ࠁ ബҗ.
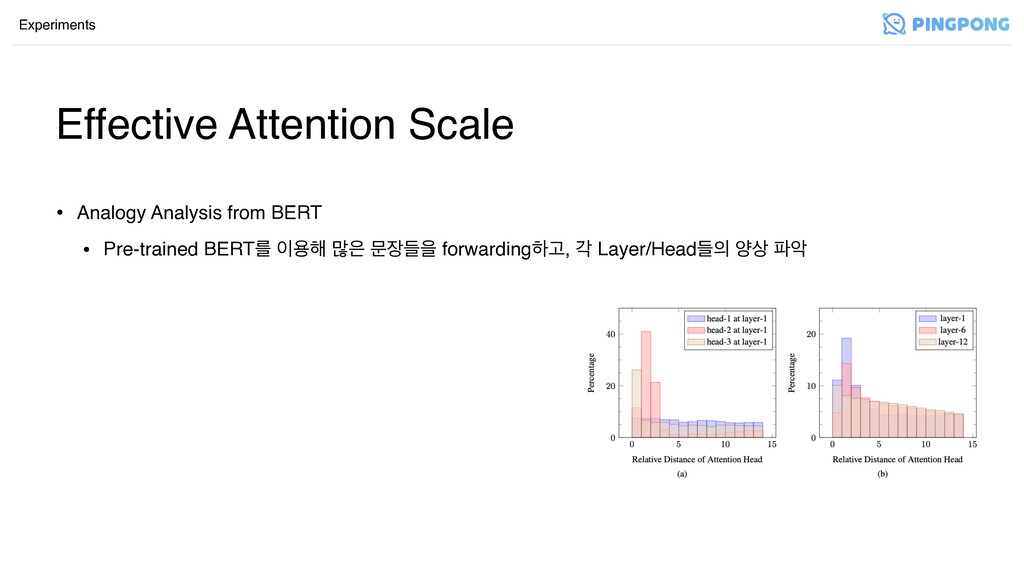
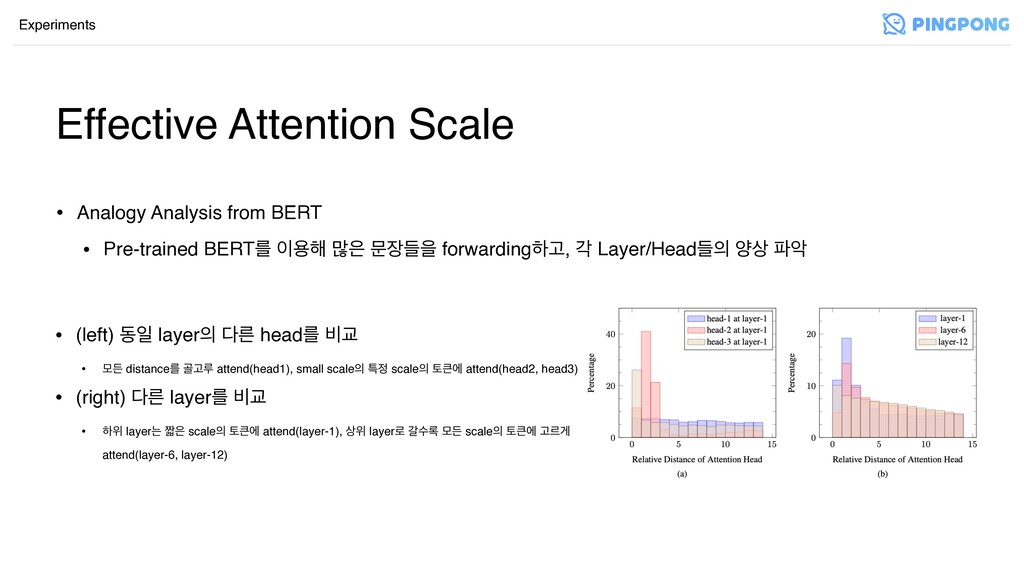
Effective Attention Scale Experiments • Analogy Analysis from BERT •
Pre-trained BERTܳ ਊ೧ ݆ ޙٜਸ forwardingೞҊ, п Layer/Headٜ ন࢚ ঈ
Effective Attention Scale Experiments • Analogy Analysis from BERT •
Pre-trained BERTܳ ਊ೧ ݆ ޙٜਸ forwardingೞҊ, п Layer/Headٜ ন࢚ ঈ • (left) زੌ layer ܲ headܳ ࠺Ү • ݽٚ distanceܳ ҎҊܖ attend(head1), small scale ౠ scale షী attend(head2, head3) • (right) ܲ layerܳ ࠺Ү • ೞਤ layerח ૣ scale షী attend(layer-1), ࢚ਤ layer۽ тࣻ۾ ݽٚ scale షী Ҋܰѱ attend(layer-6, layer-12)
Effective Attention Scale Experiments • Control Factor of Scale Distributions
for Different Layer • , 5ѐ wо ח ҃ • (layer 1) =[0 + 0.5 * 4, 0 + 0.5 * 3, 0 + 0.5 * 2, 0 + 0.5, 0], • … N′ = 10,α = 0.5 [z1 1 , z1 2 , z1 3 , z1 4 , z1 5 ] n l= 1 = {5,2,2,1,0}
Experiment Settings Experiments • Classifier: 2-layer MLP • GloVe Pre-trained
Word-Embeddings • BERT৬ э self-supervised learning method৬ח ࠺Ү ೞ ঋ. • ݽٚ ण word-embeddingਸ ઁ৻ೞҊ from scratch
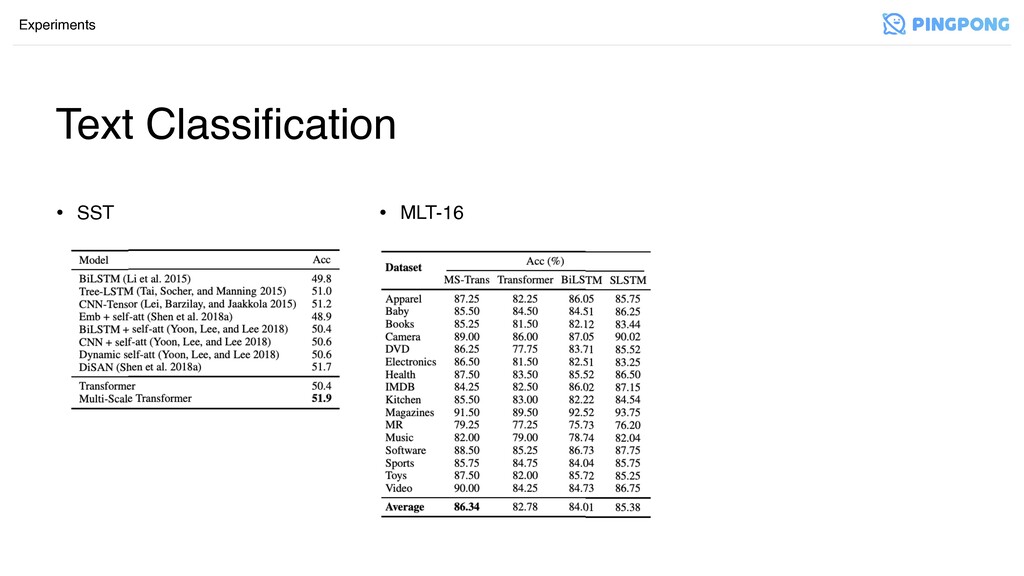
Text Classification Experiments • SST • MLT-16
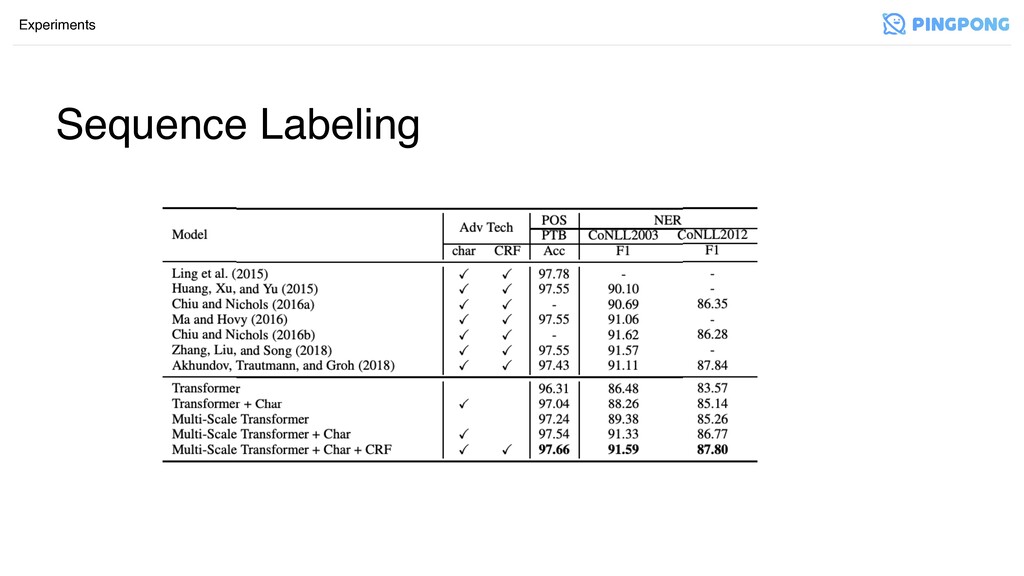
Sequence Labeling Experiments
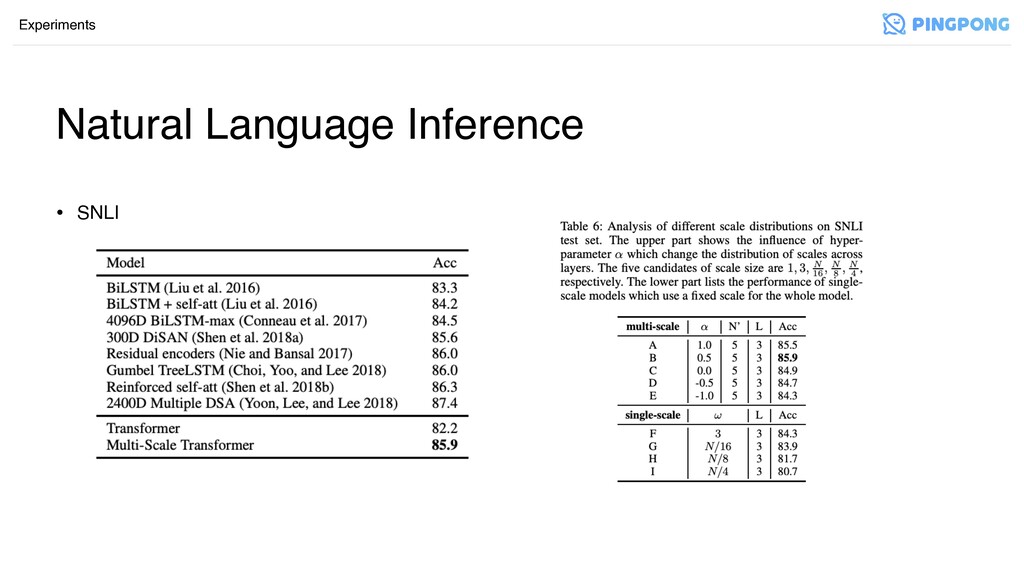
Natural Language Inference Experiments • SNLI
хࢎפ✌ ୶о ޙ ژח ҾӘೠ ݶ ઁٚ ইې োۅ۽
োۅ ࣁਃ! ߔ (ML Software Engineer, Pingpong)
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Multi-Scale Transformer Proposed Method • Classification Node • Bertীࢲח [CLS]](https://files.speakerdeck.com/presentations/ff45dec87681436cb9e76bd7866fb6f1/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}