Production outages can be extremely costly. For a global business, just one minute of downtime can exceed an engineer’s annual compensation. So, how can engineering leaders strengthen incident response across their organizations?
After over a decade of building and operating systems used by millions of people, I’ve distilled an approach that helps engineering leaders strengthen their teams’ incident management practices, based on a simple formula:
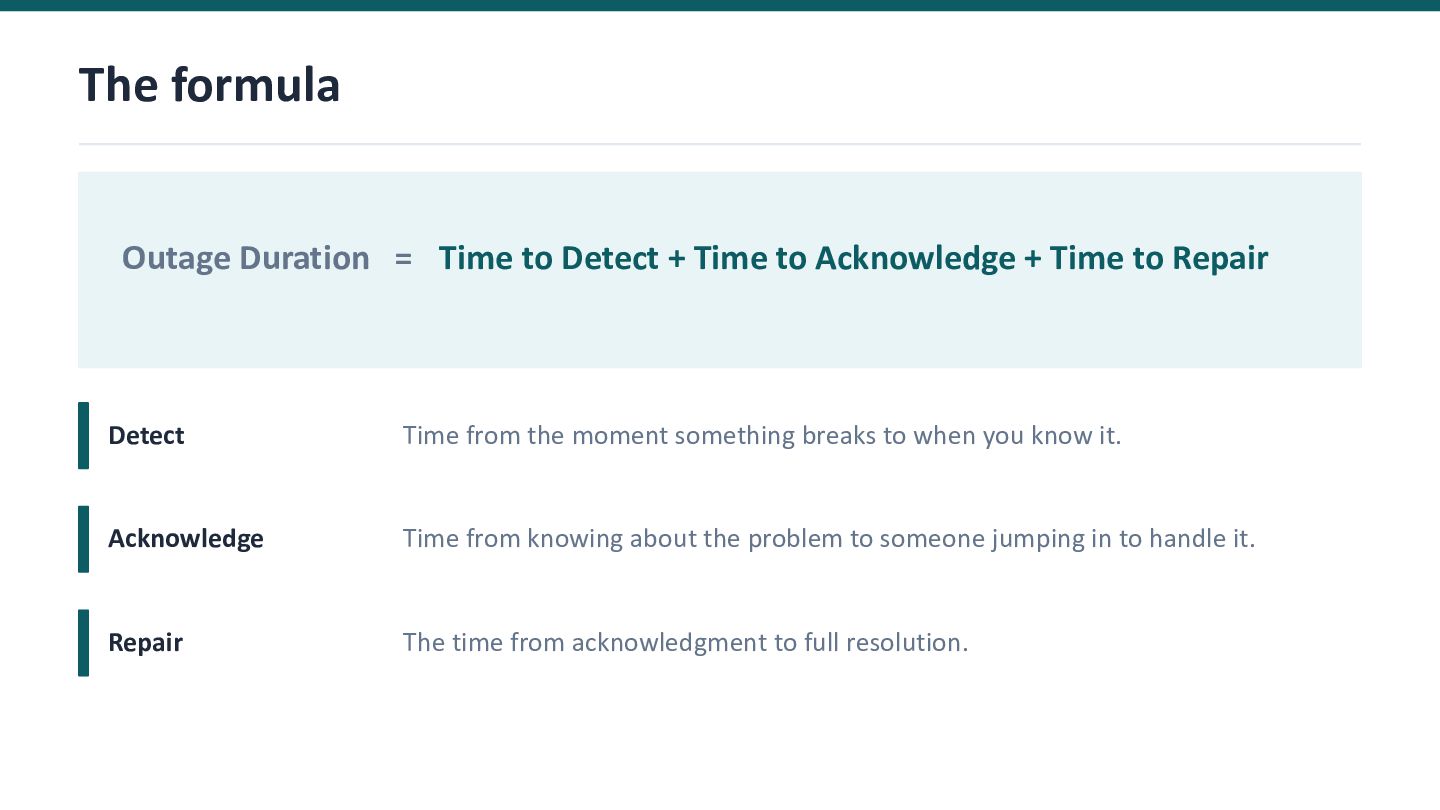
Outage Duration = Time to Detect + Time to Acknowledge + Time to Repair.
To resolve outages quickly, we need to be efficient in all three stages. But shortening the time of each stage requires a coordinated mix of technical, process, and cultural changes. This is where engineering leaders can truly enable and empower their teams.
We’ll unpack each component and examine practical strategies—from tooling investments and observability practices to cultural habits and on-call readiness—that can dramatically shorten outage duration. By the end of the talk, you’ll learn how to set up your teams for success when they face an outage.
More engineering insight in my book: Engineering Manager’s Compass: Insights for building effective engineering organizations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}