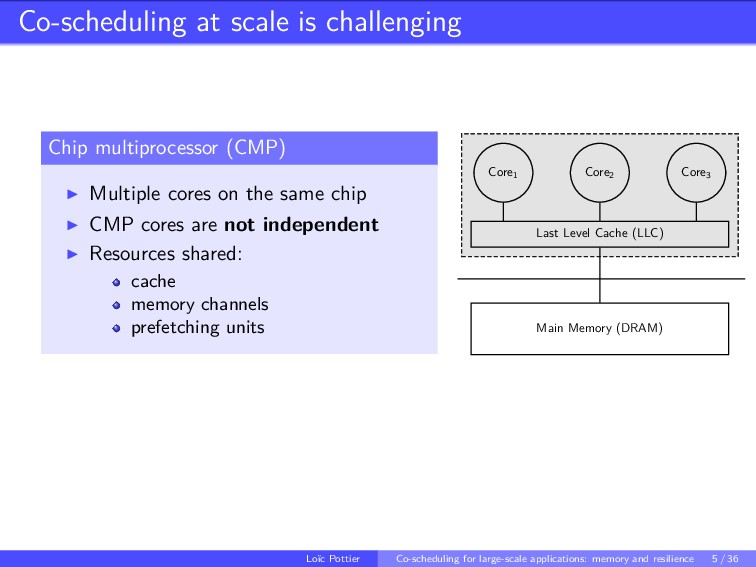
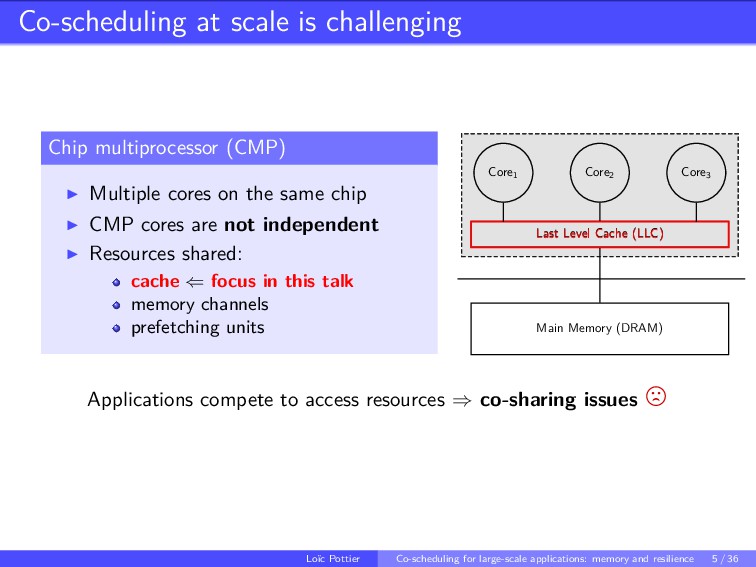
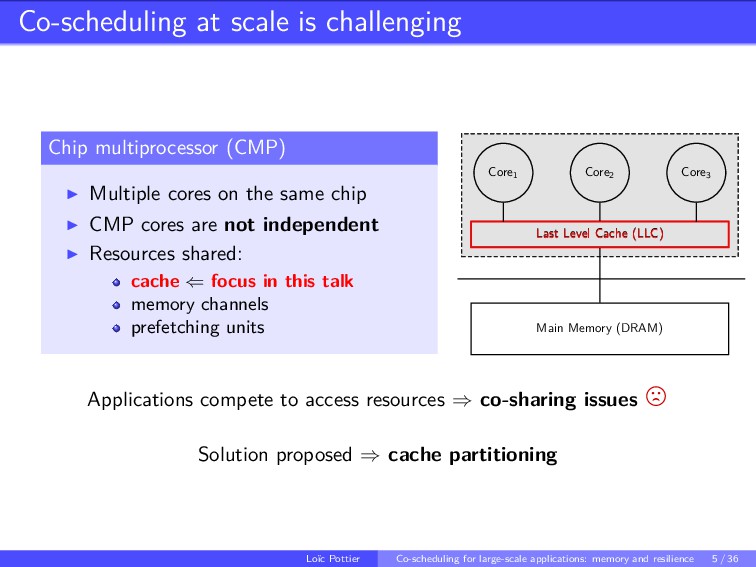
This talk explores co-scheduling problems in the context of large-scale applications with two main focus: the memory side, in particular the cache memory and the resilience side. With the recent advent of many-core architectures such as chip multiprocessors (CMP), the number of processing units is increasing. In this context, the benefits of co-scheduling techniques have been demonstrated. Recall that, the main idea behind co-scheduling is to execute applications concurrently rather than in sequence in order to improve the global throughput of the platform. But sharing resources often generates interferences. With the arising number of processing units accessing to the same last-level cache, those interferences among co-scheduled applications becomes critical. In addition, with that increasing number of processors the probability of a failure increases too. Resiliency aspects must be taking into account, specially for co-scheduling because failure-prone resources might be shared between applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
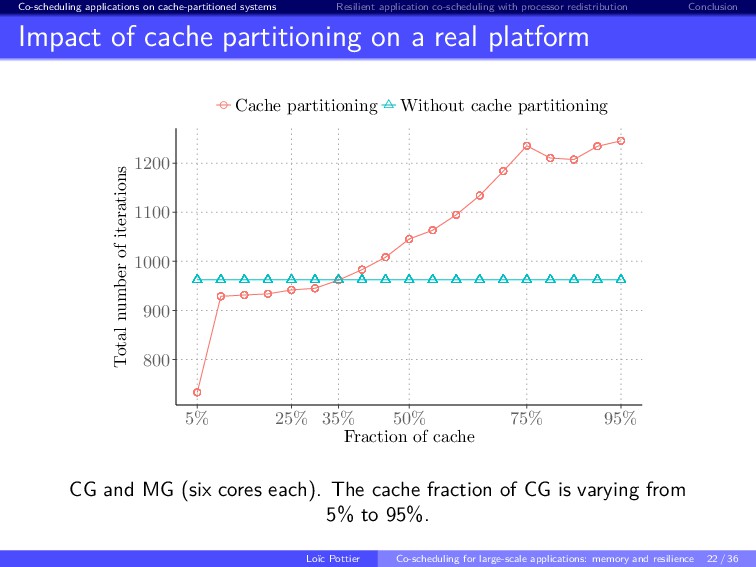{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
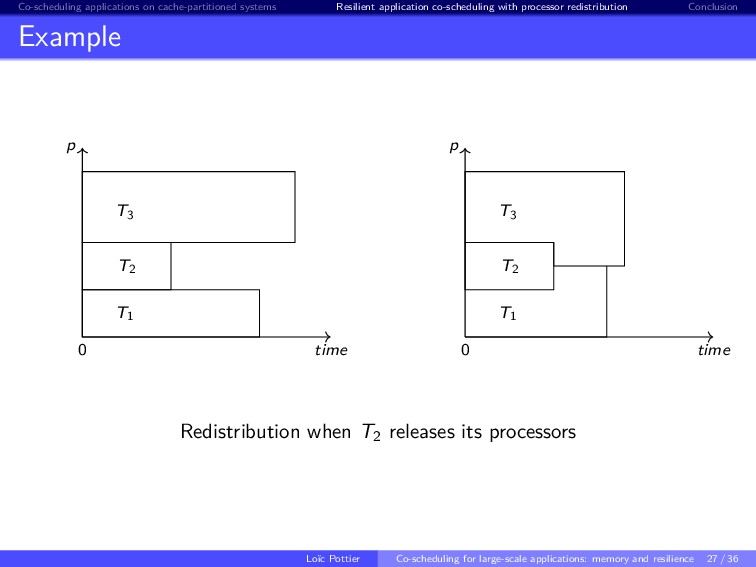{kind=link}
{kind=link}
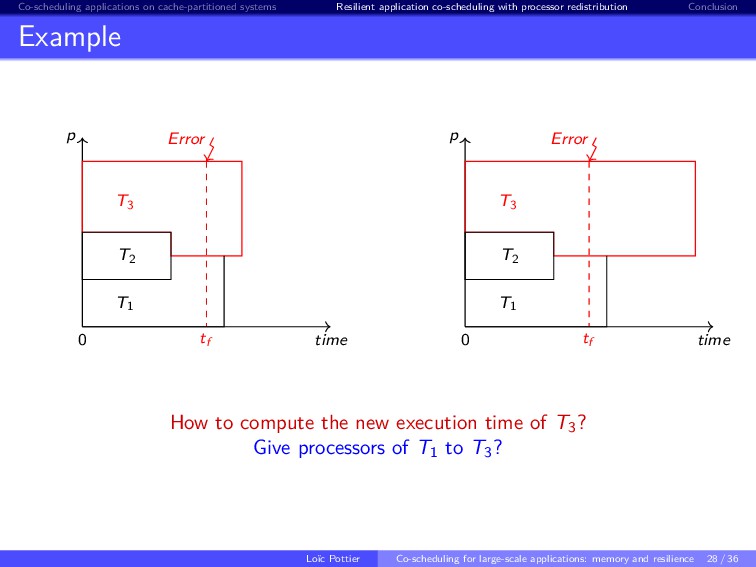{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}