For more than 15 years, the Open Science Grid (OSG) has been offering the science community a fabric of distributed High Throughput Computing (dHTC) services. In close collaboration with science and campus communities as well as resource and software providers, the OSG has been enhancing the computational throughput of a wide spectrum of research effort – from single investigator groups to the largest science endeavors. As the role High Throughput Computing (HTC) plays in scientific discovery is rapidly expending and the research computing landscape is evolving, the OSG distributed services have to adapt and expend. We will review the principals and software technologies that underpin these services and will discuss current development and implementation efforts. These include among others capability based access control and automation of resource provisioning.
{kind=link}
{kind=link}
{kind=link}
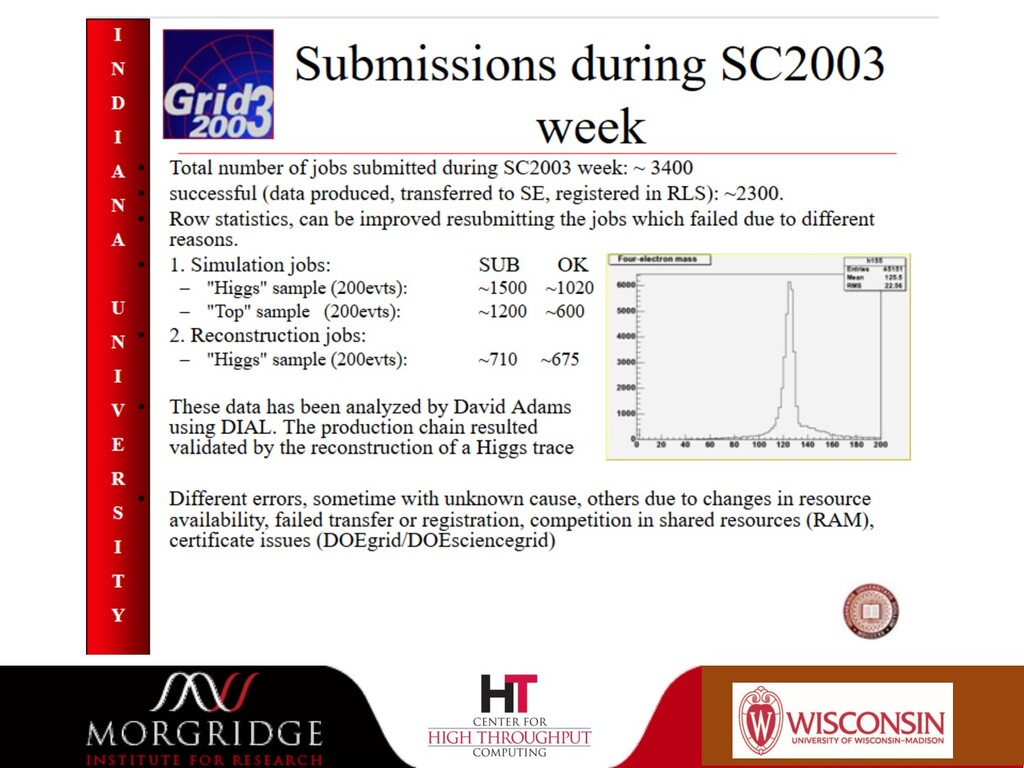{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
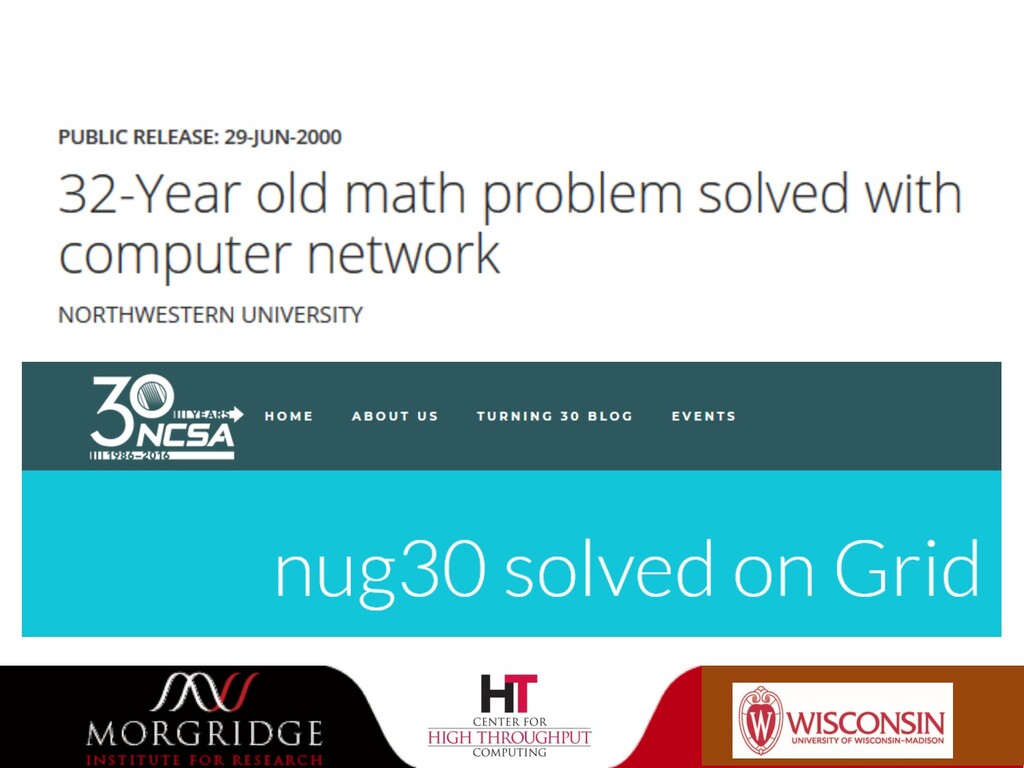{kind=link}
{kind=link}
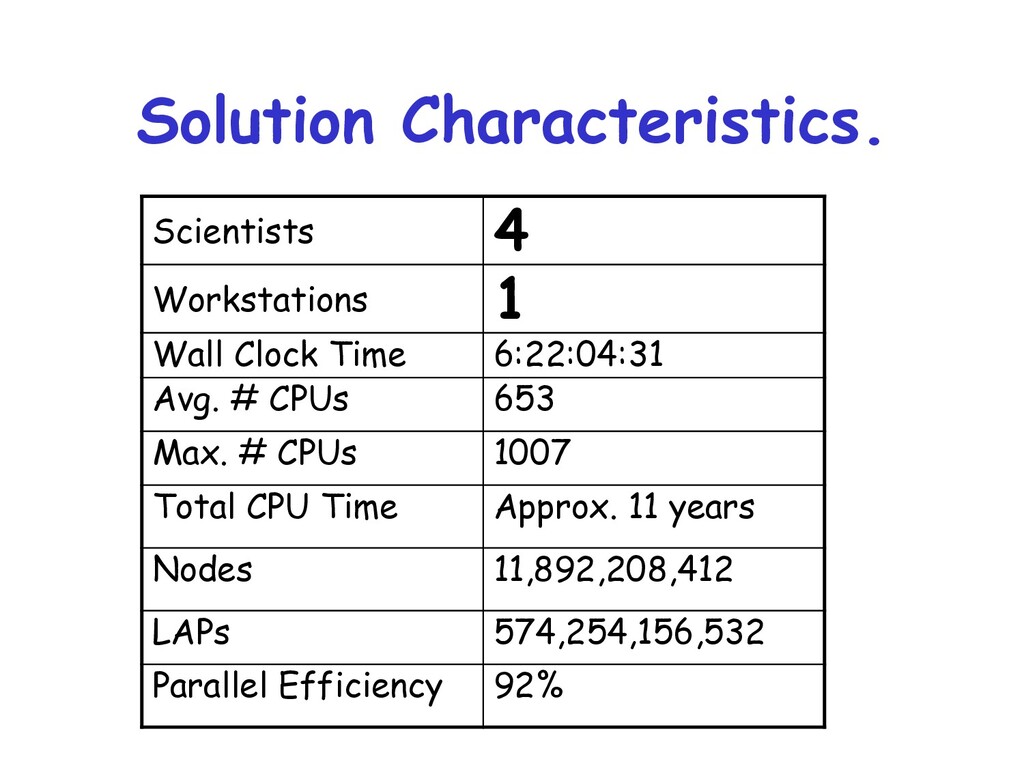{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
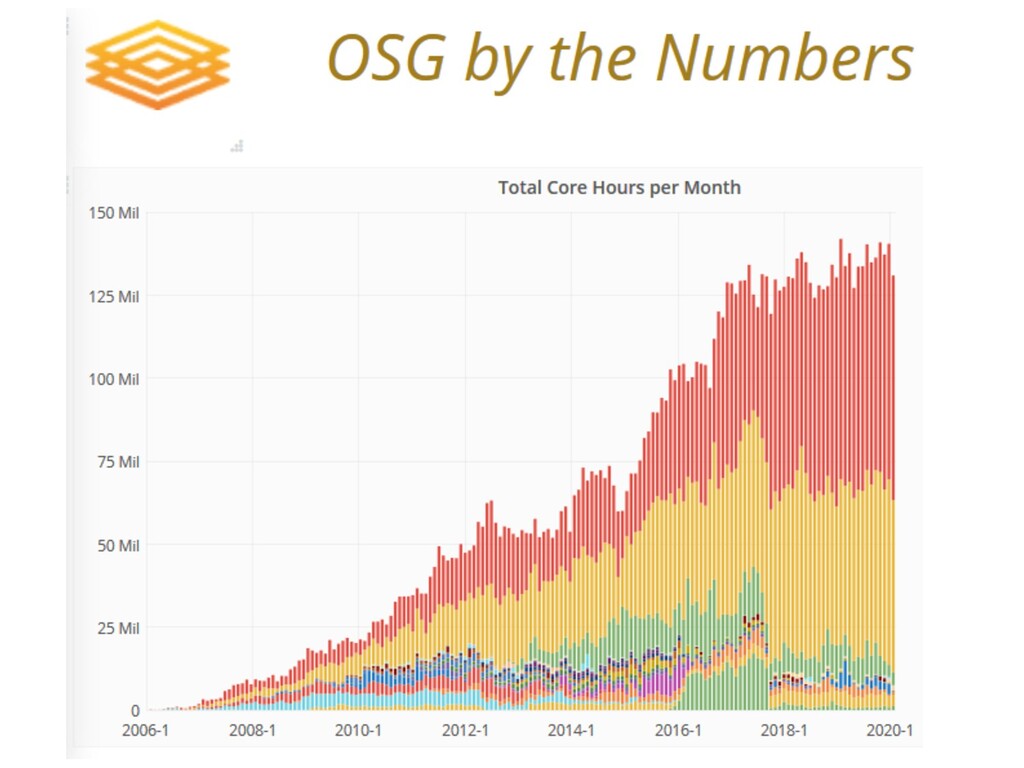{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
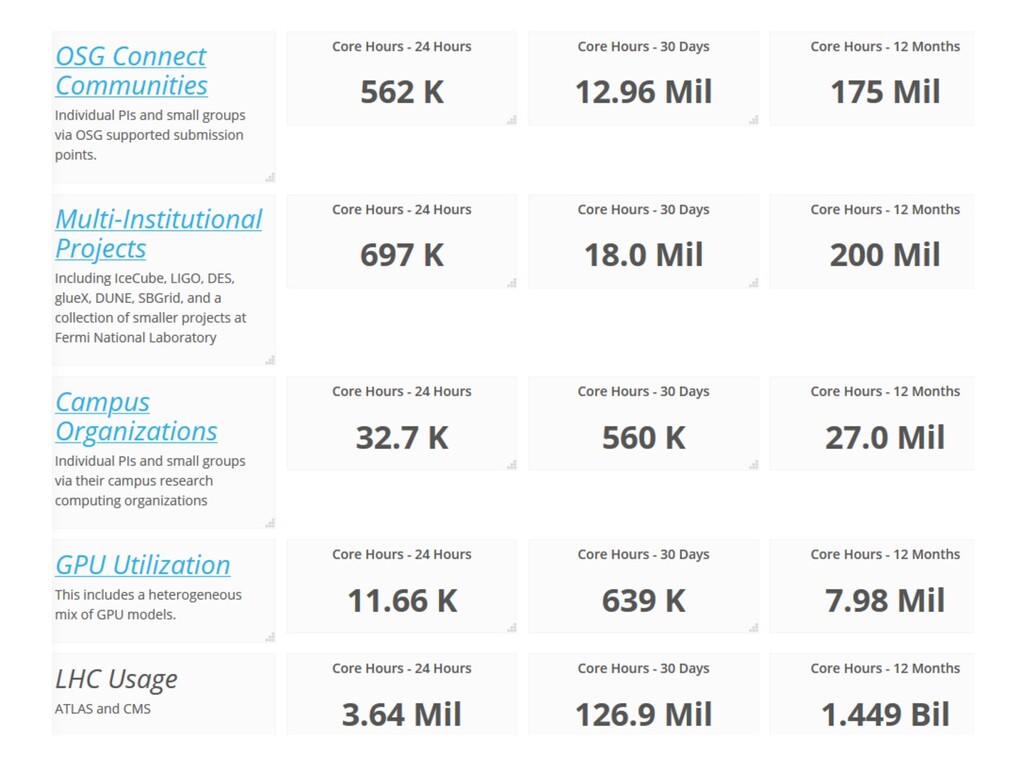{kind=link}
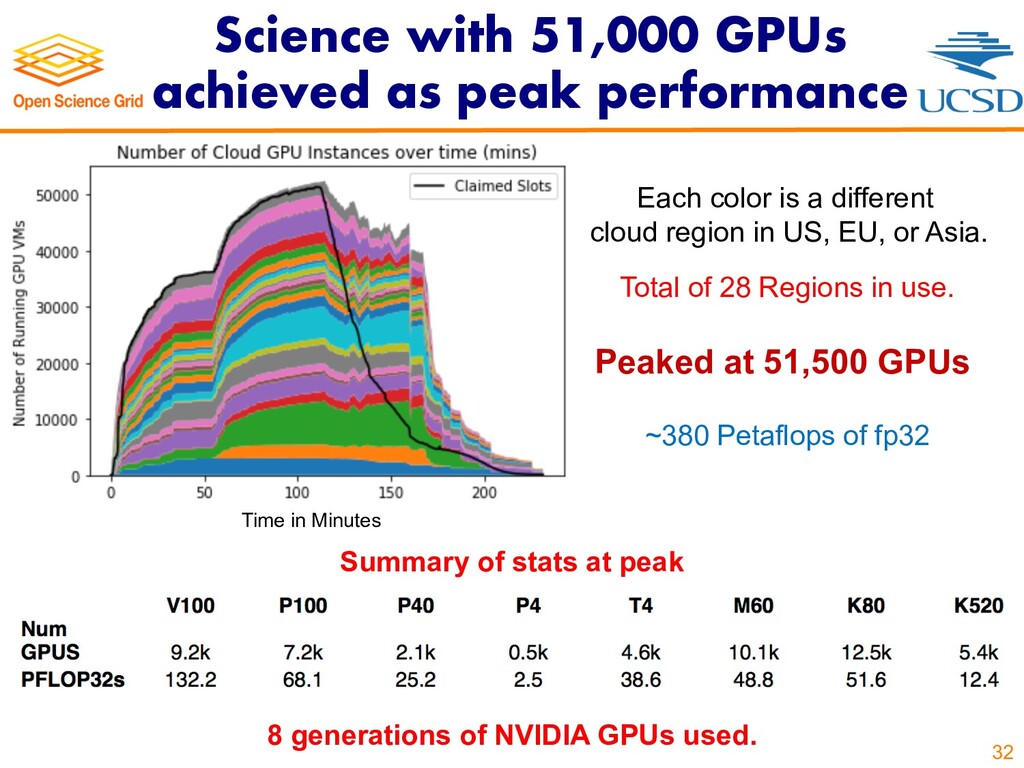{kind=link}
{kind=link}
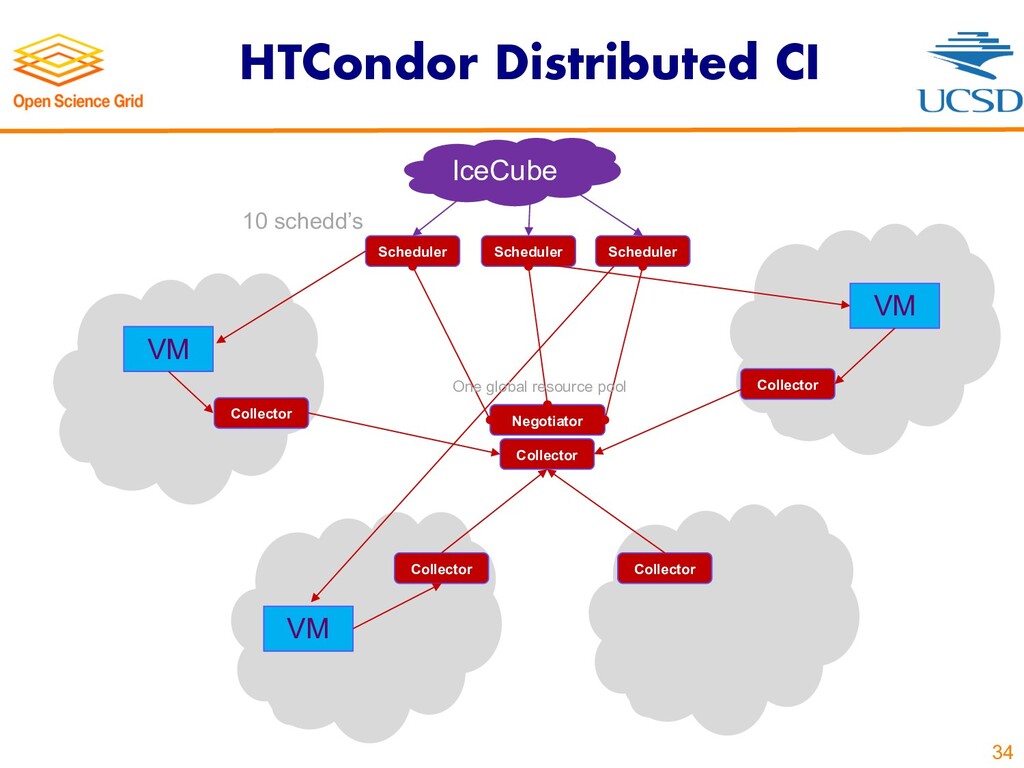{kind=link}
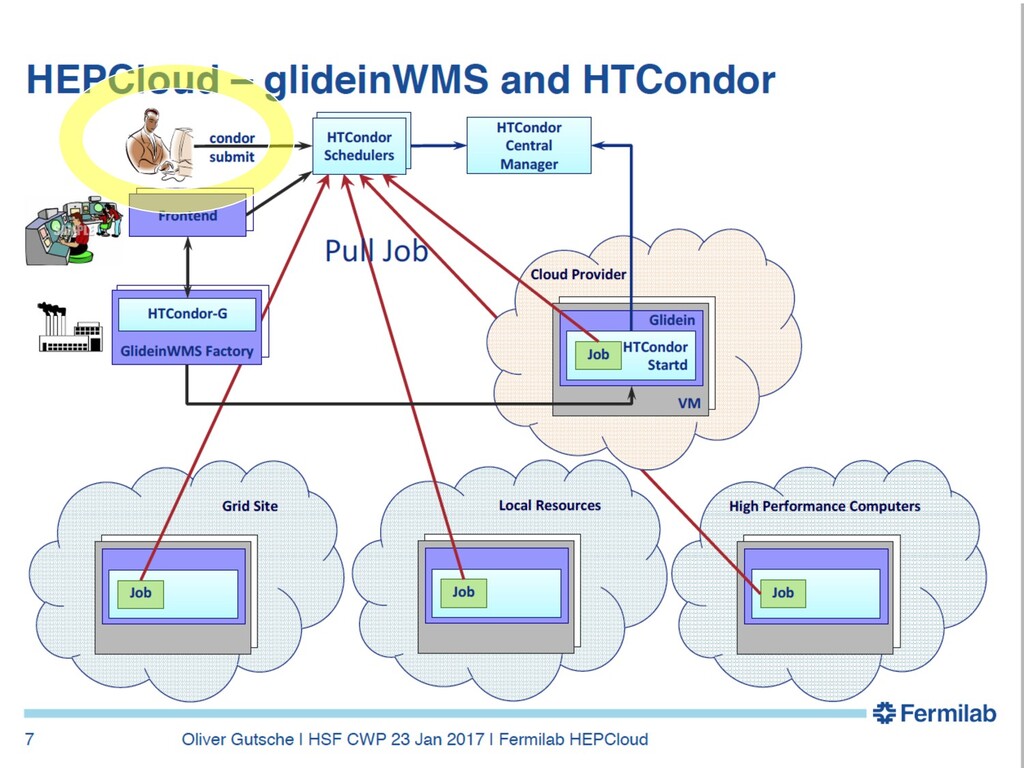{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
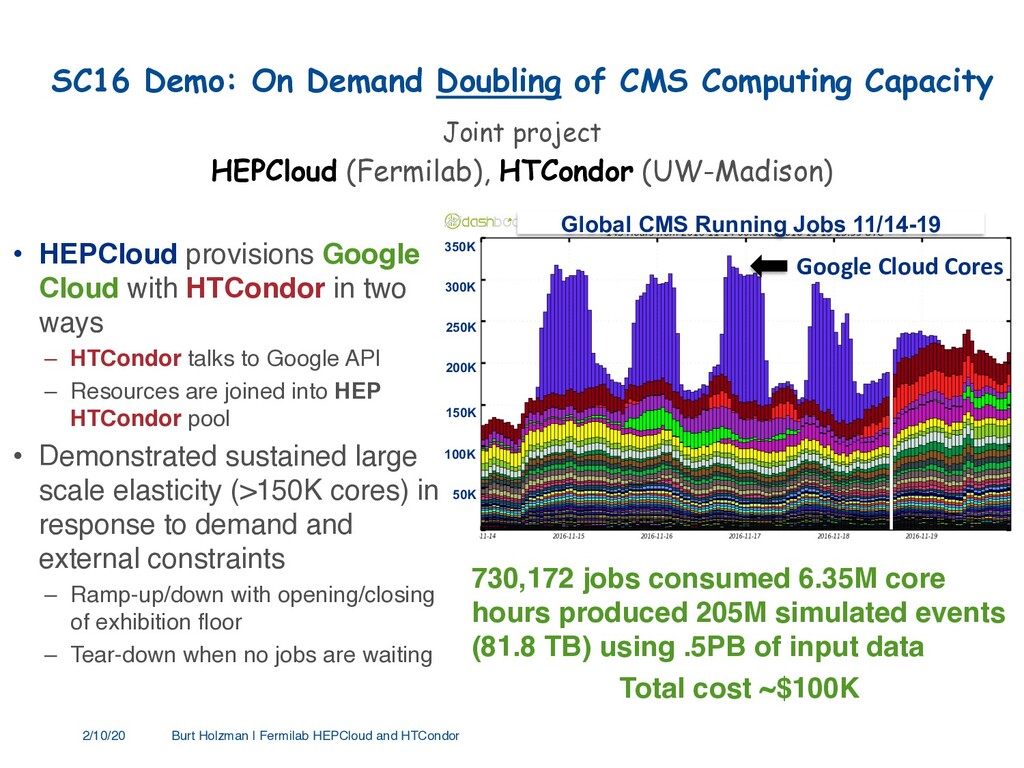{kind=link}
{kind=link}
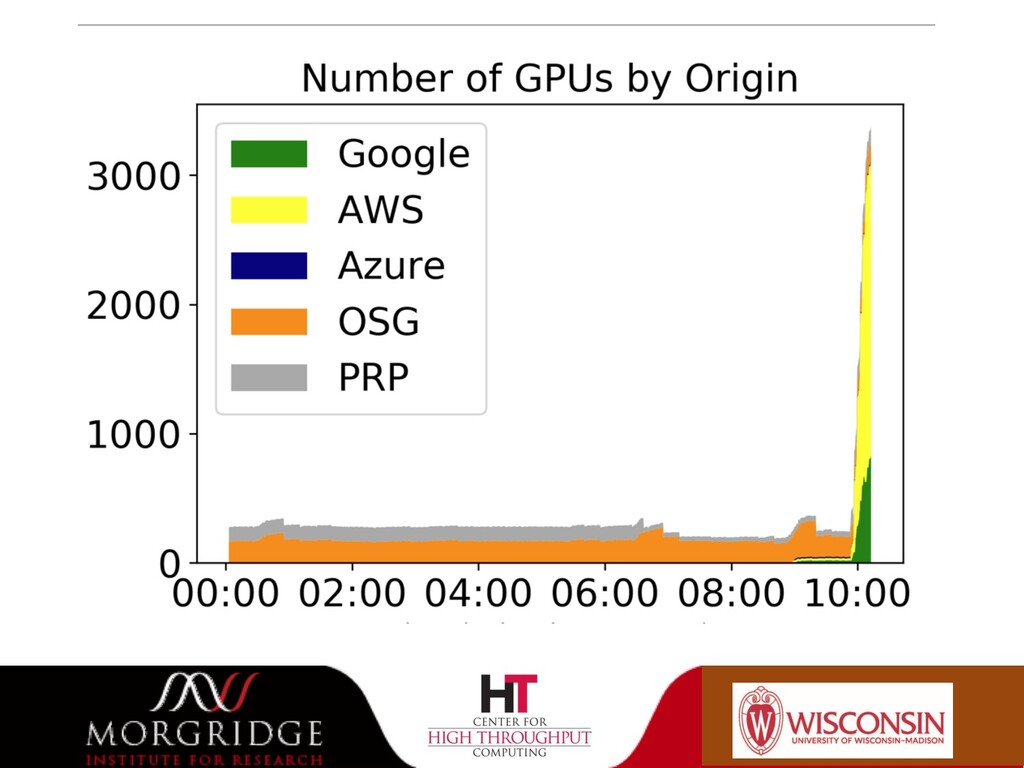{kind=link}
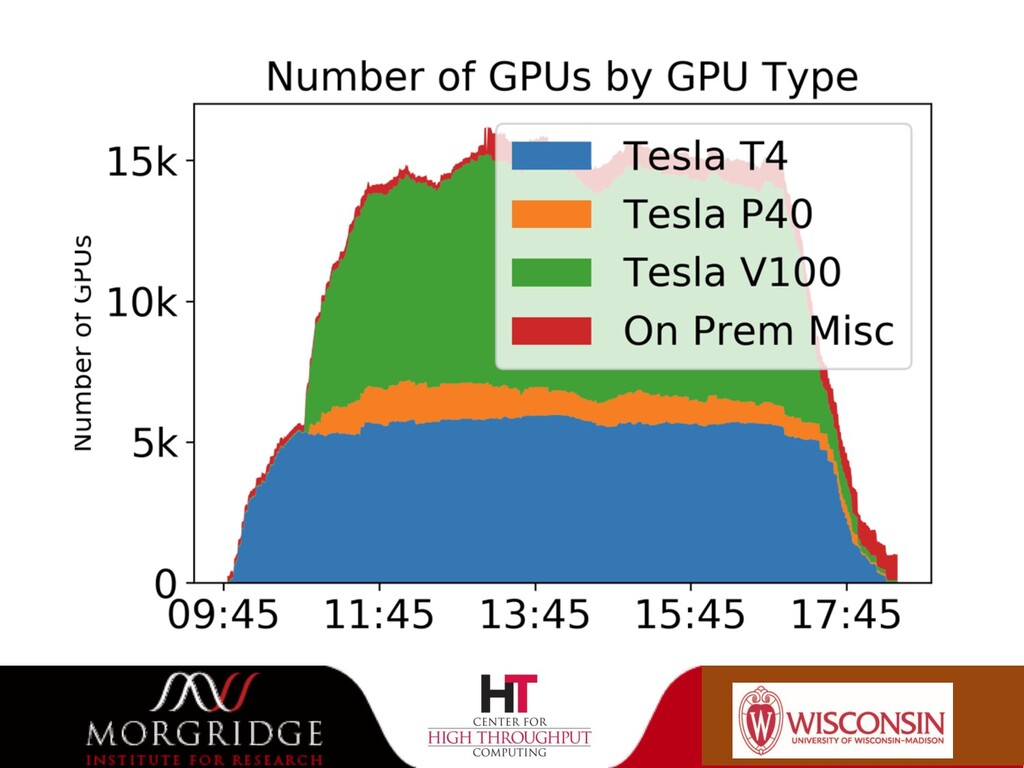{kind=link}
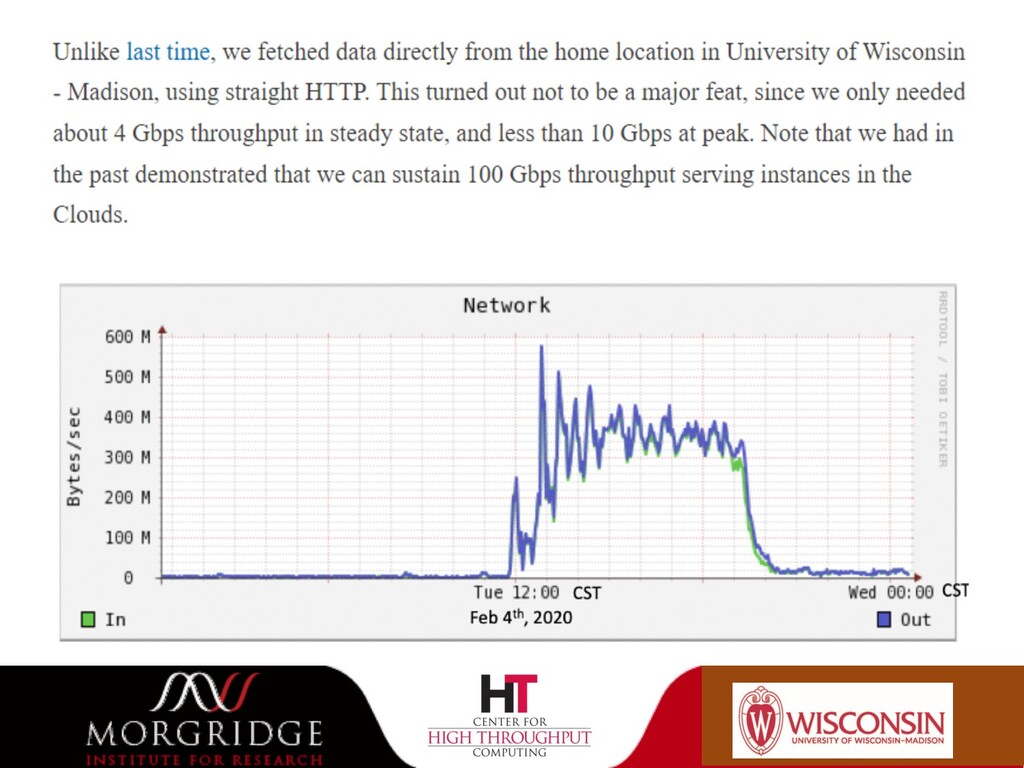{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}