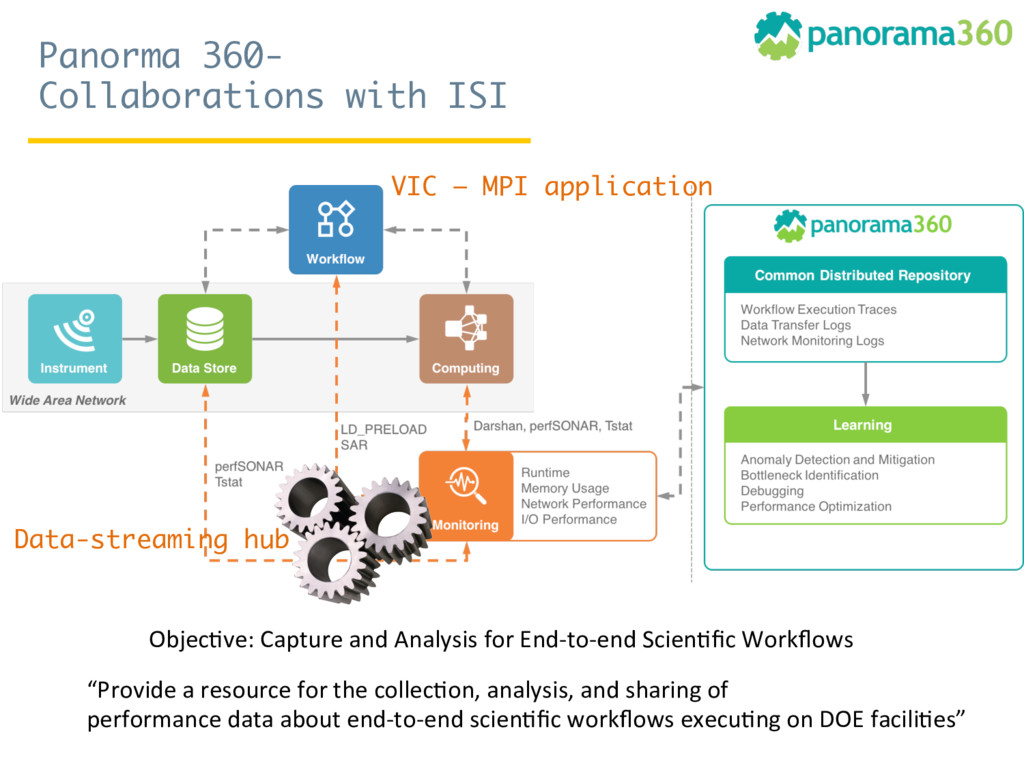
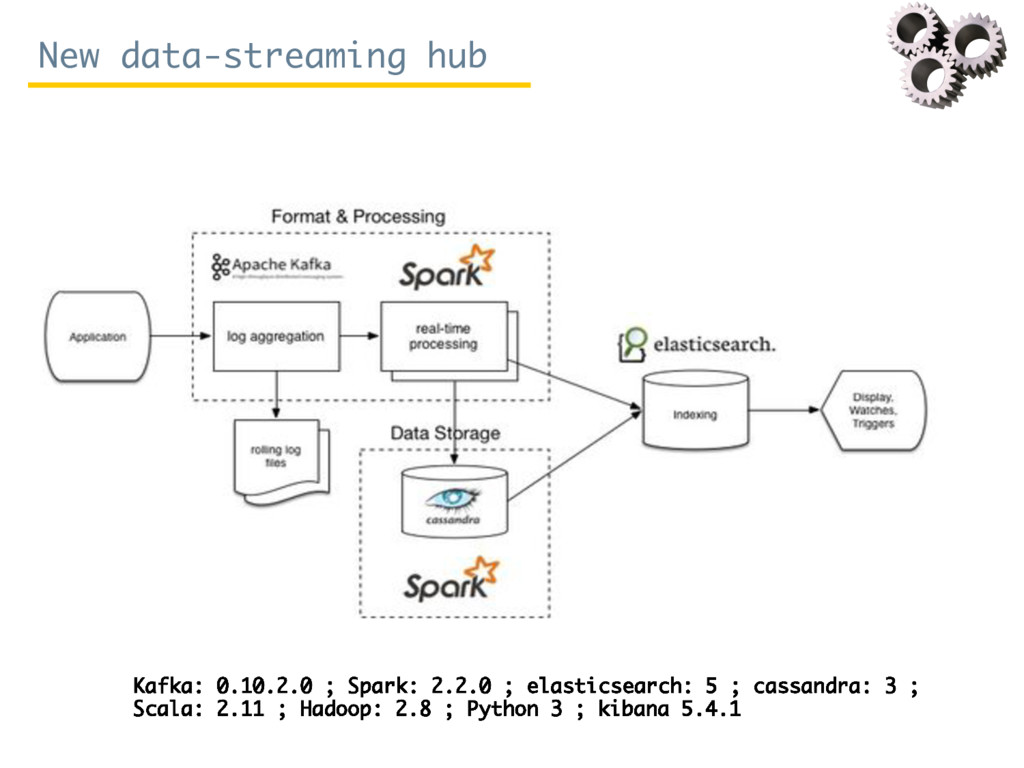
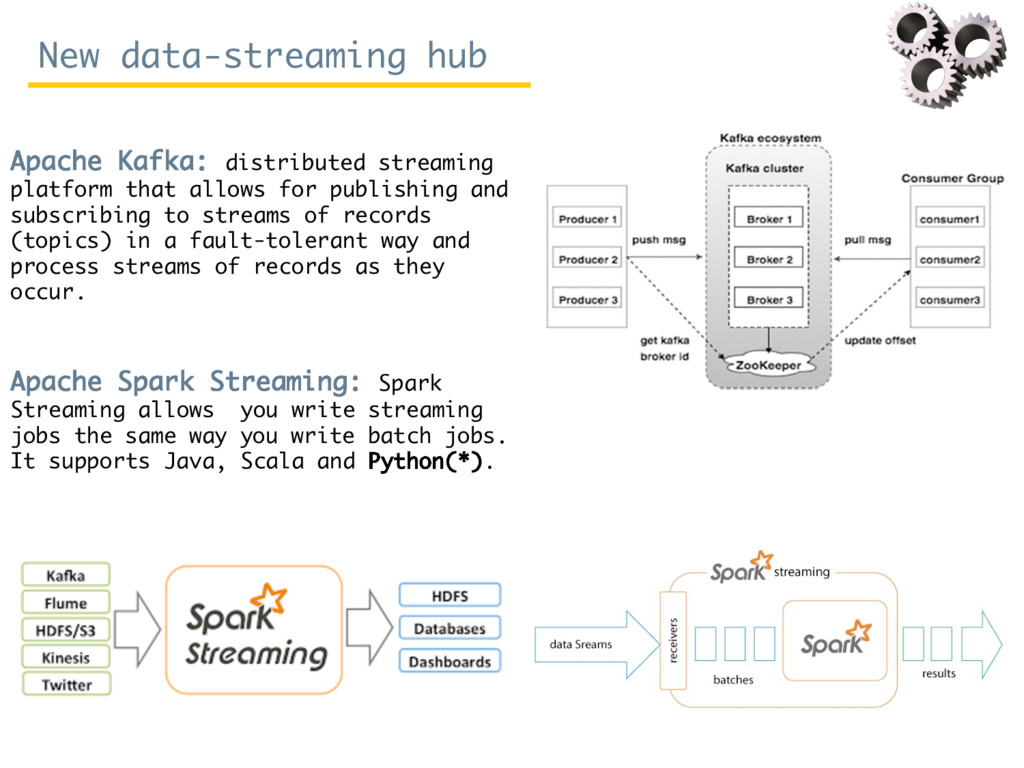
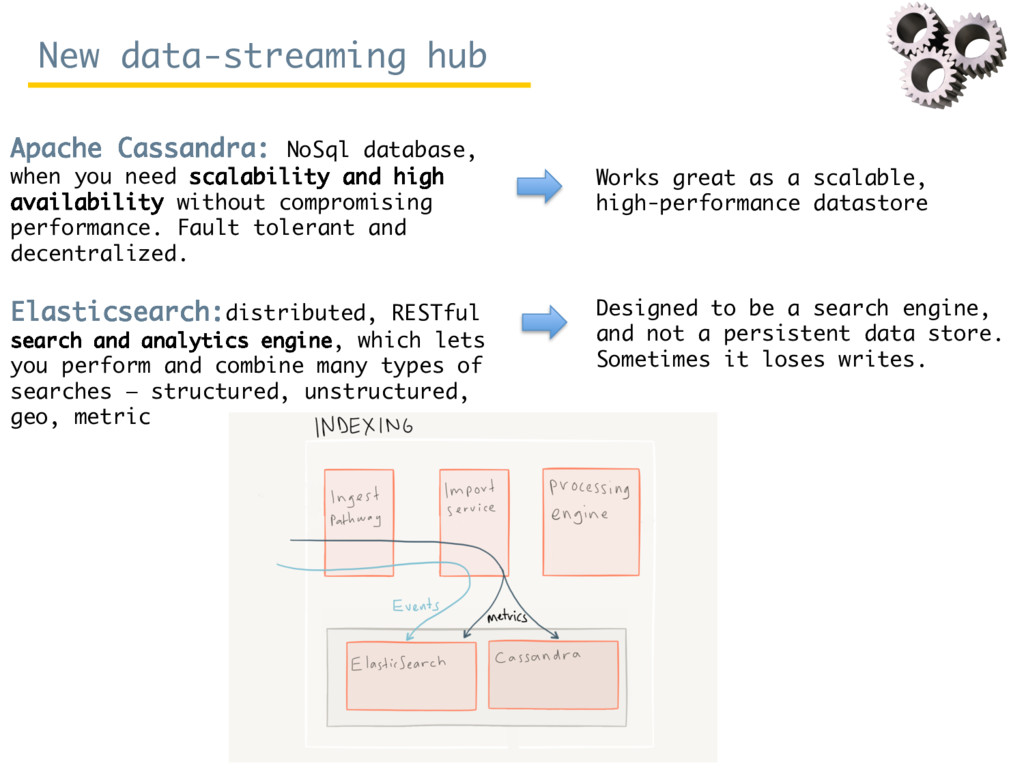
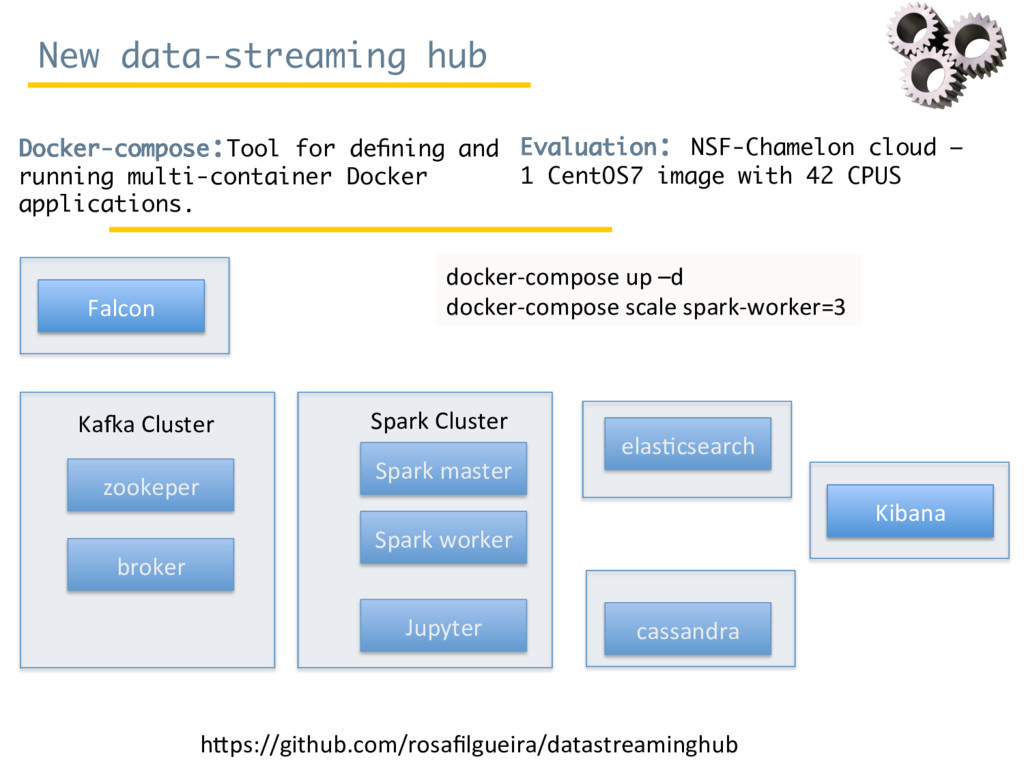
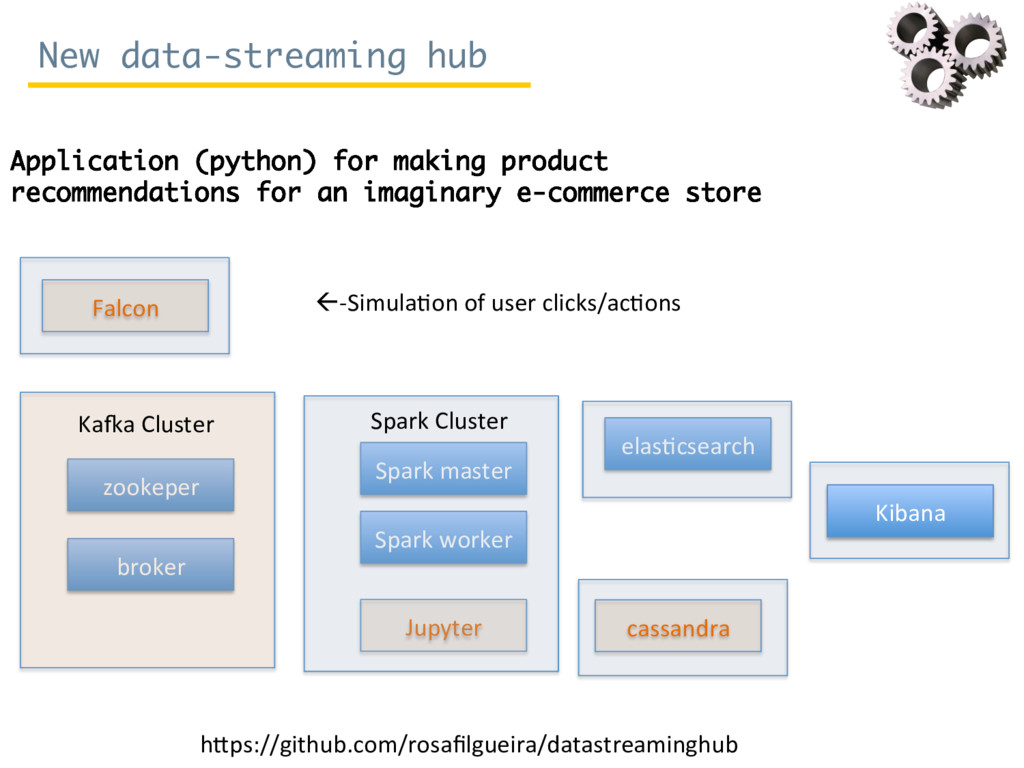
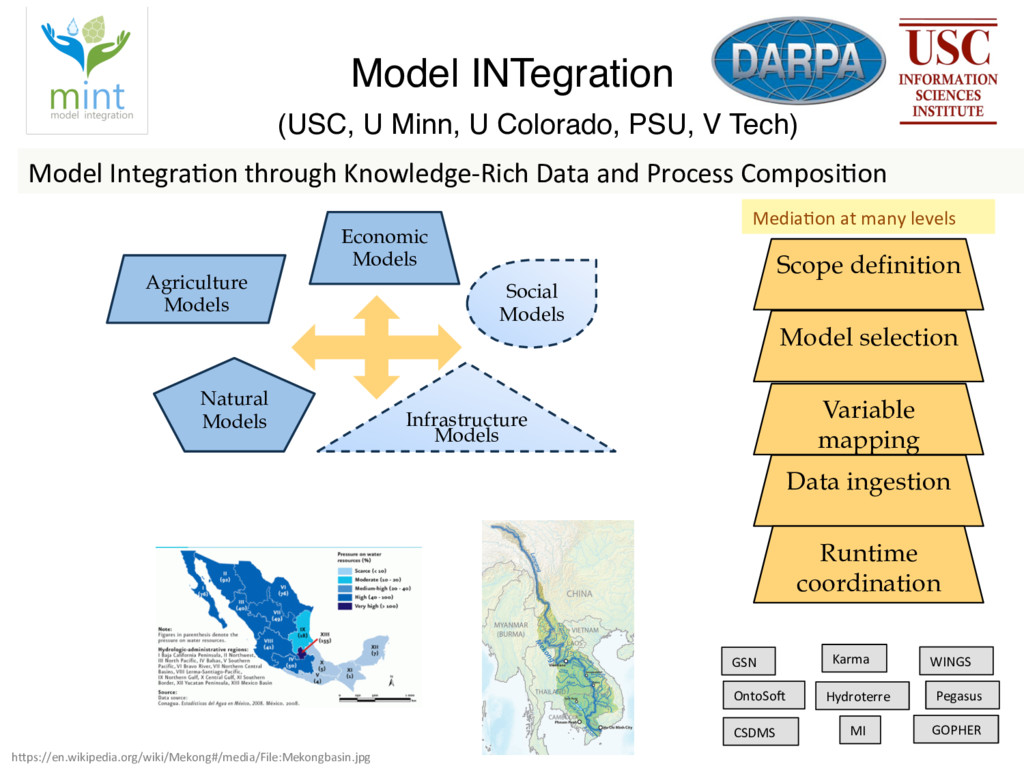
Since October 2016, Rosa Filgueira has been working at the British Geological Survey (BGS) as a Senior Data Scientist. She is involved in a variety of national and international research projects where she applies different technologies from Data Science and High Performance Computing to extract data-driven insights from different domain areas. During her visit at ISI, she has mainly worked in two complementary subjects. The first consists in building a new data-streaming infrastructure to collect and perform data analytics in real-time. The proposed infrastructure can be used for analysing real-time workflows performance and/or for monitoring real-time sensor/instrument data (e.g. geo-energy data). The second topic consists to create a new semantic catalog for describing geosciences resources.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
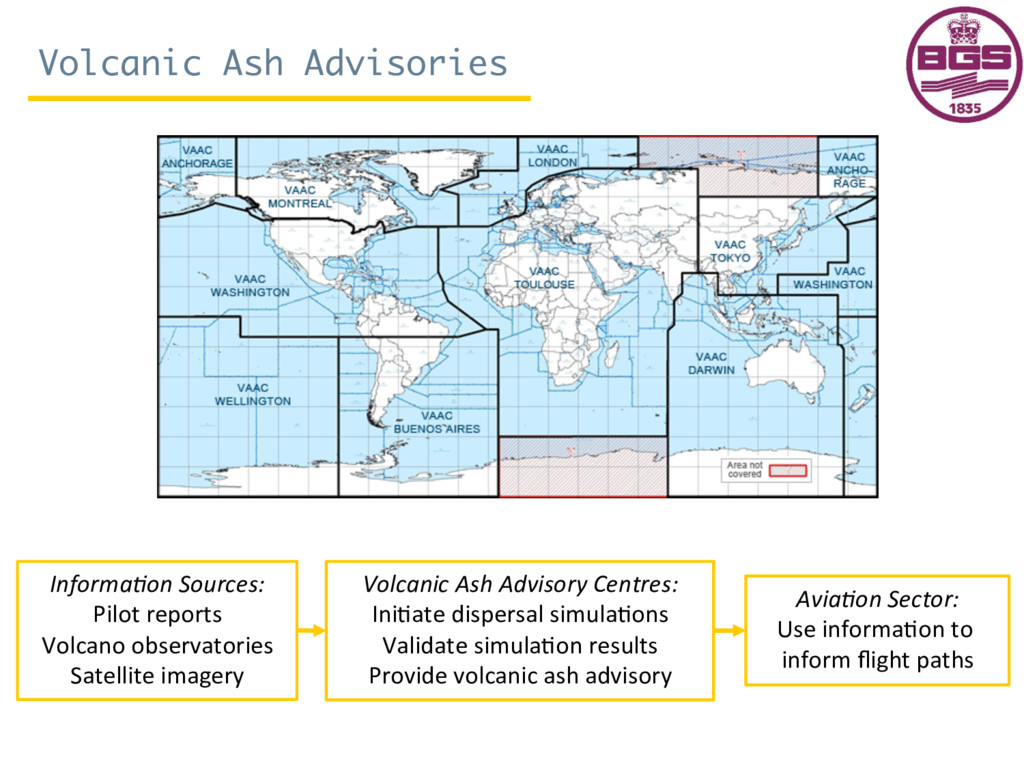{kind=link}
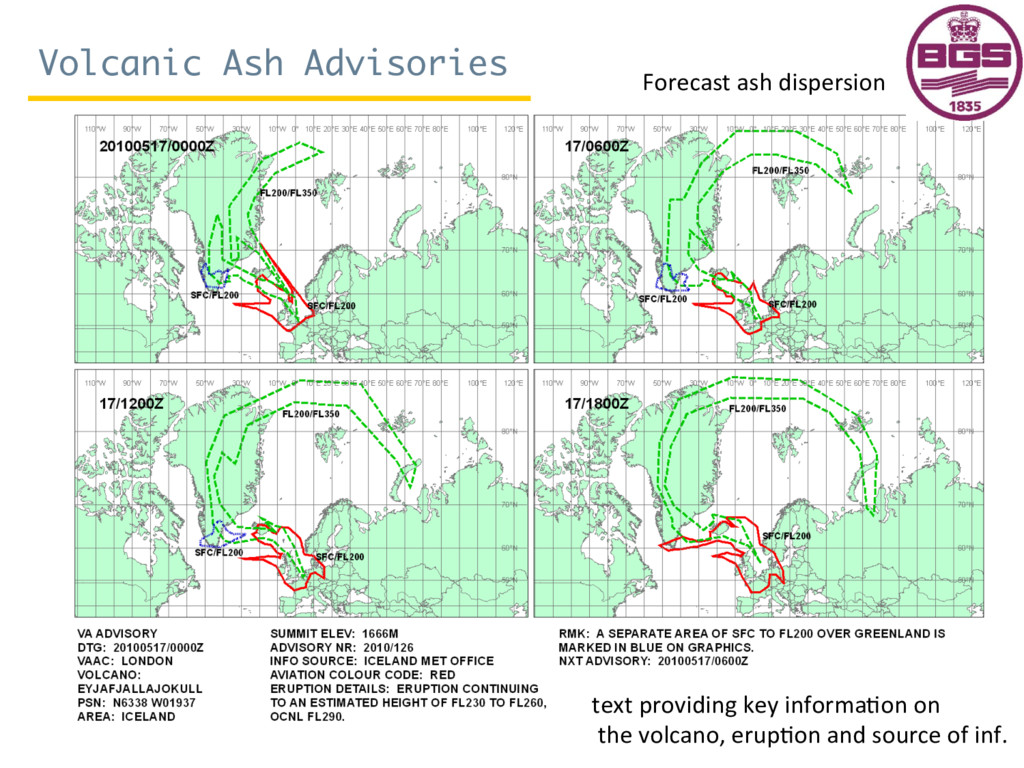{kind=link}
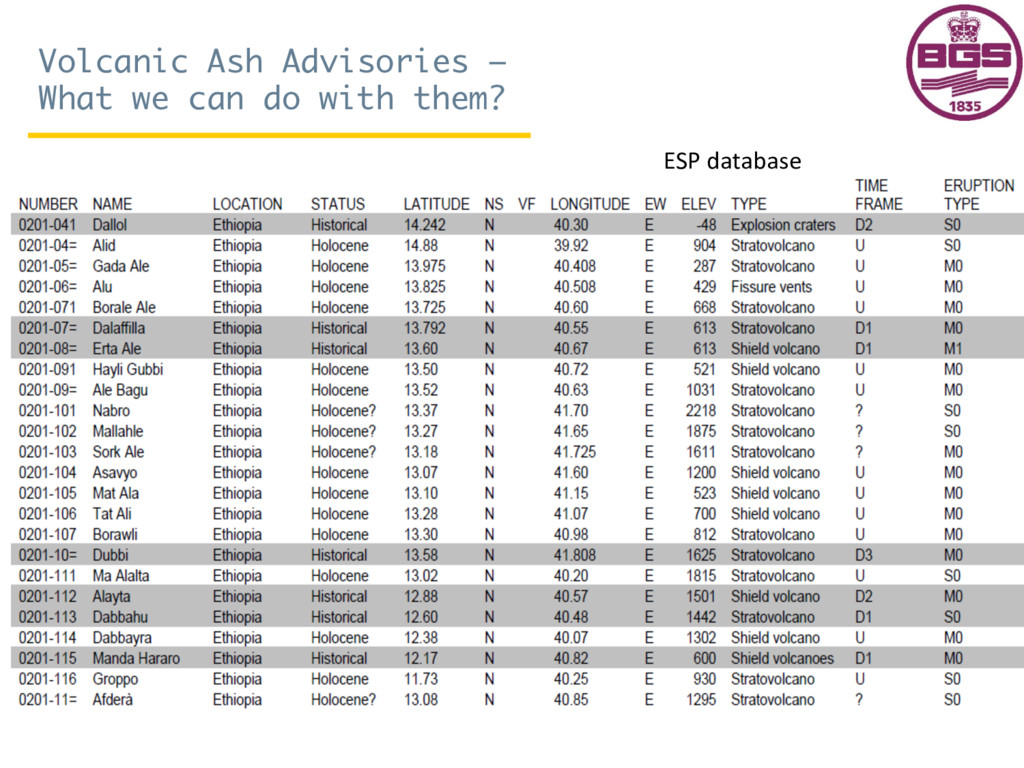{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
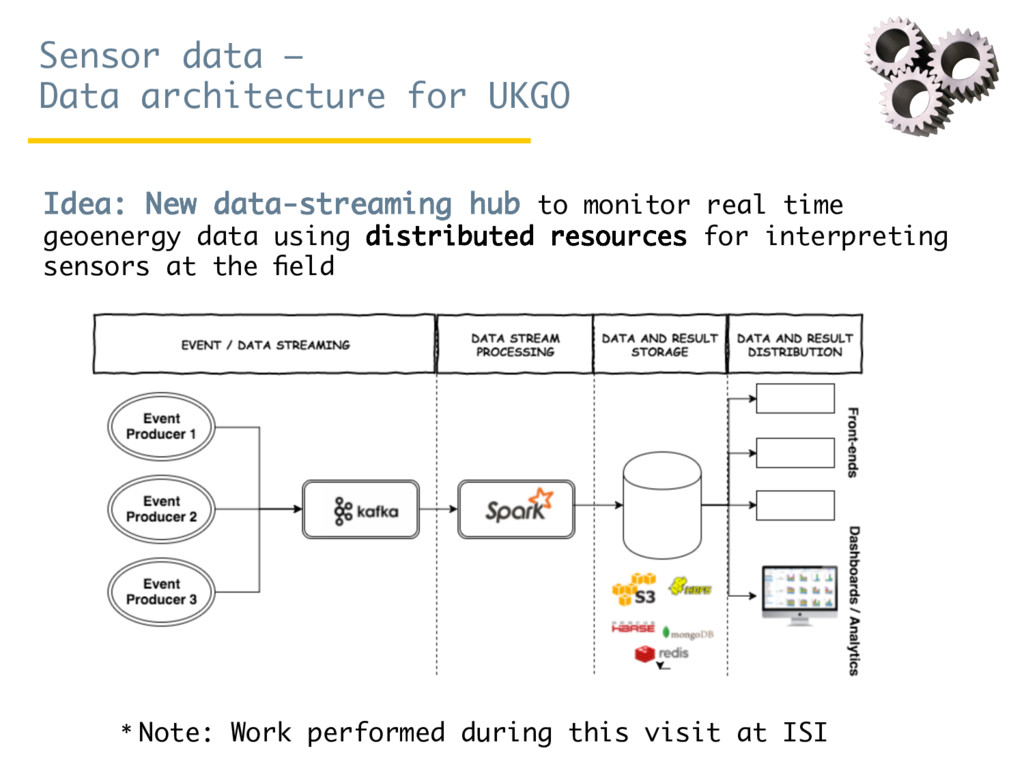{kind=link}
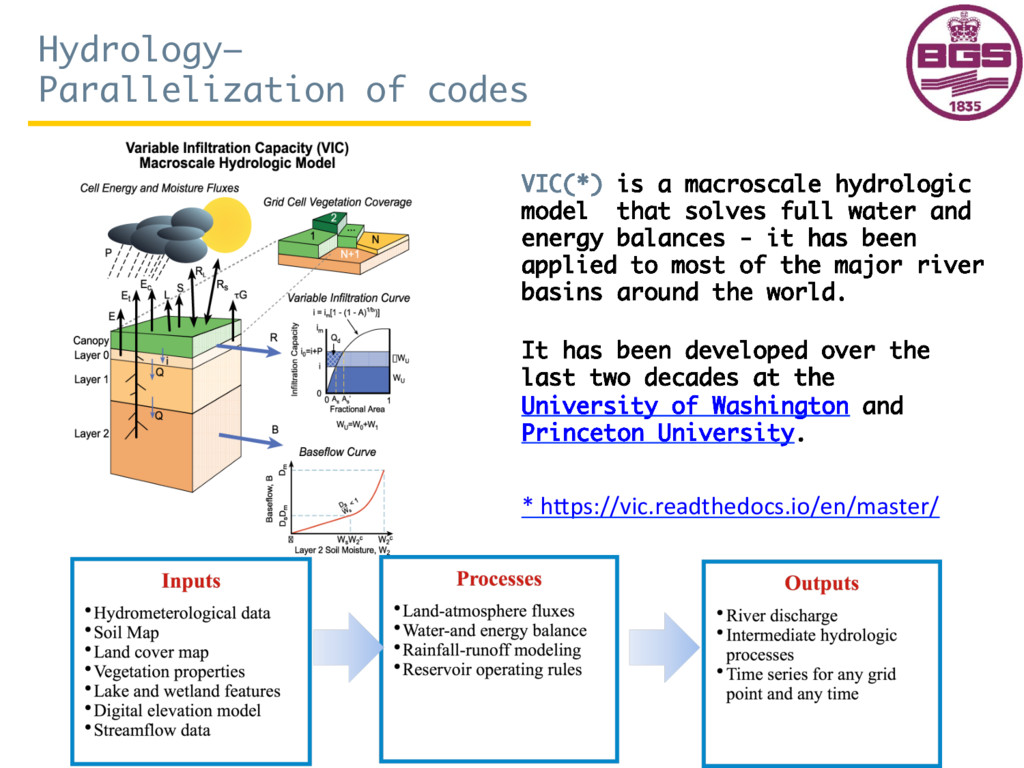{kind=link}
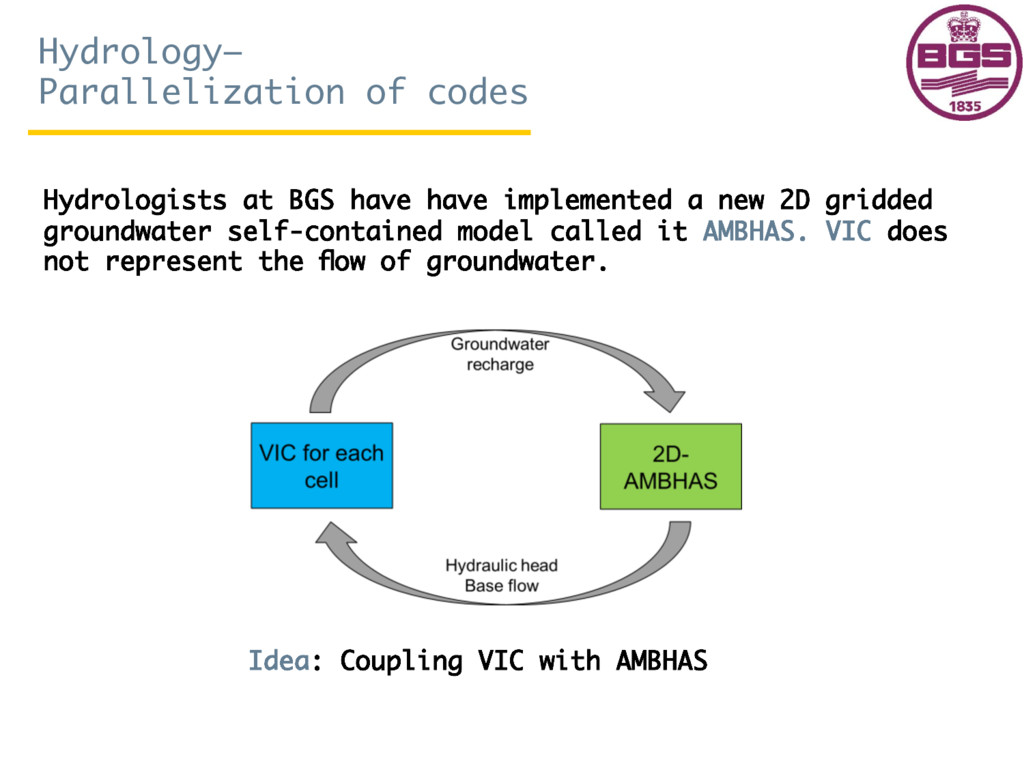{kind=link}
{kind=link}
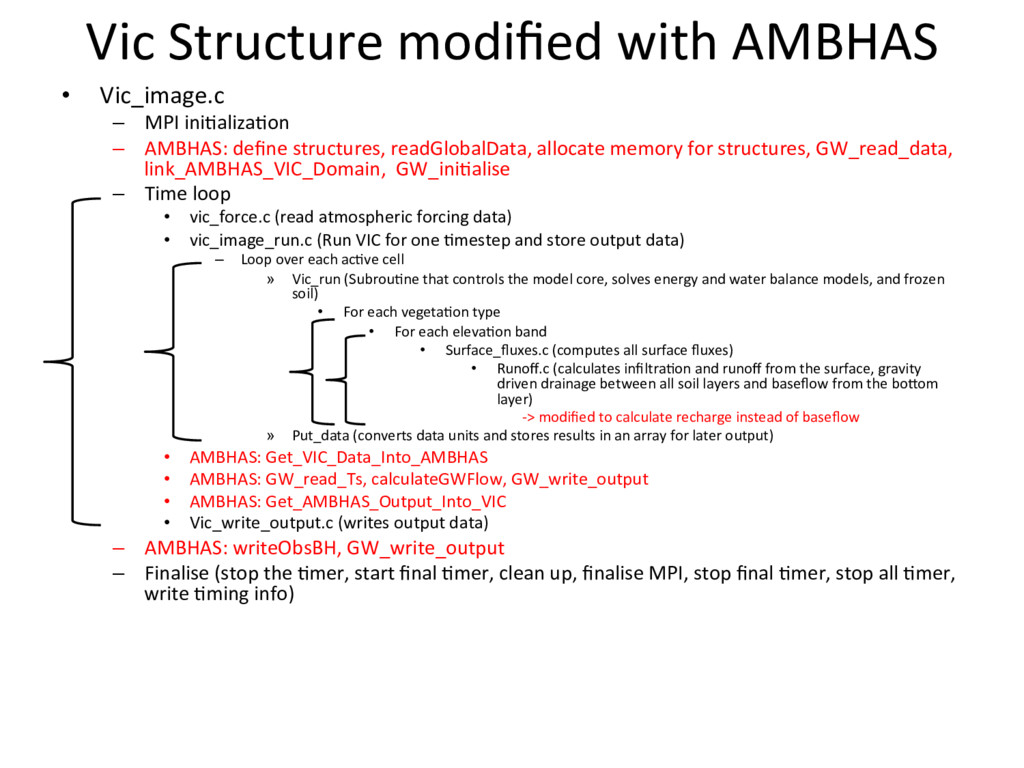{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}