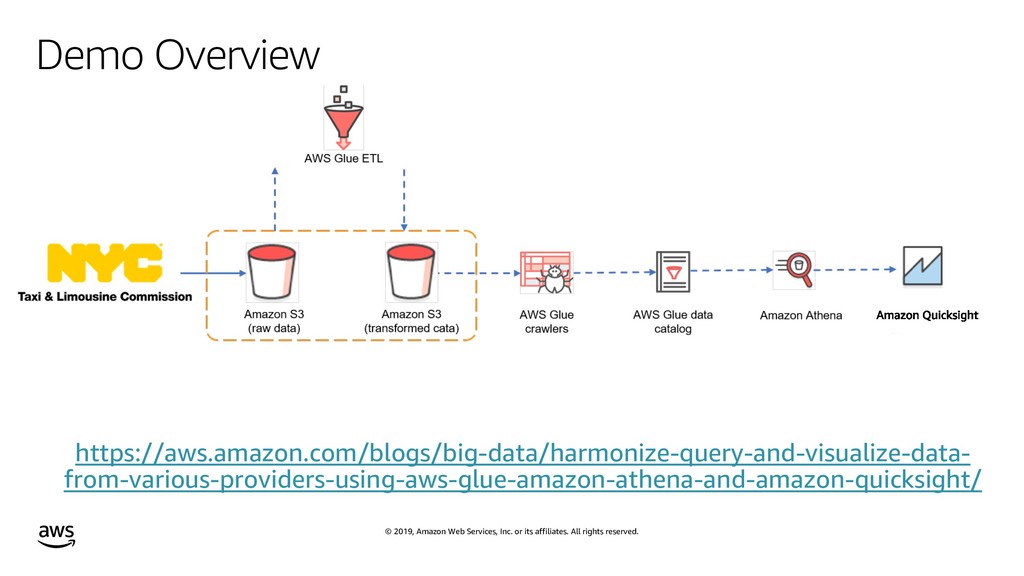
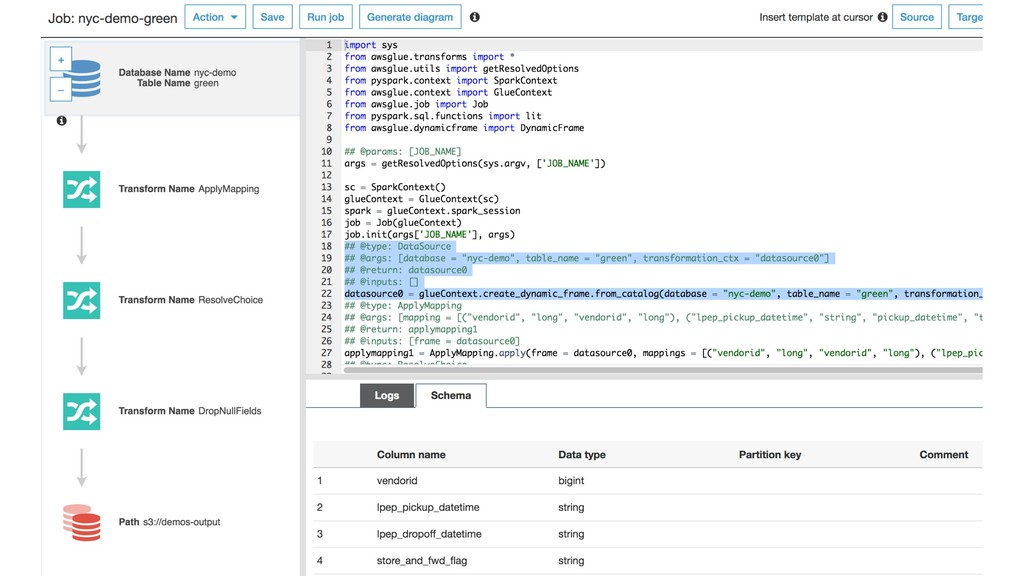
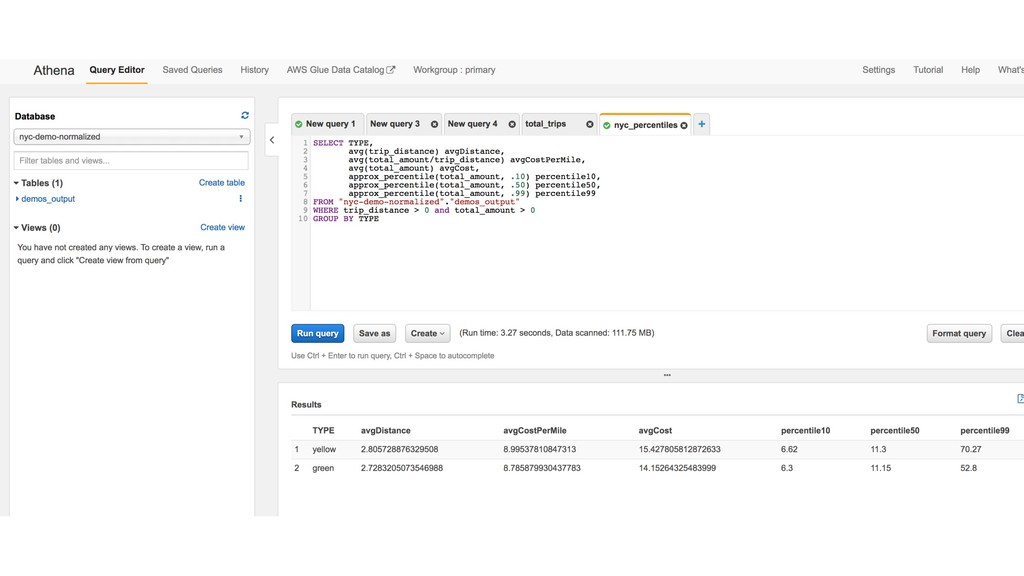
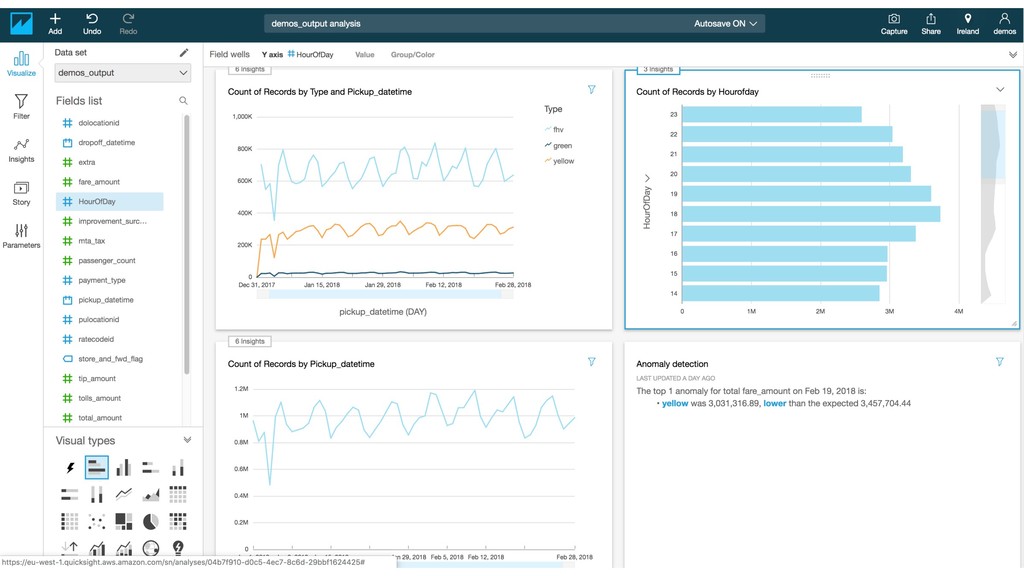
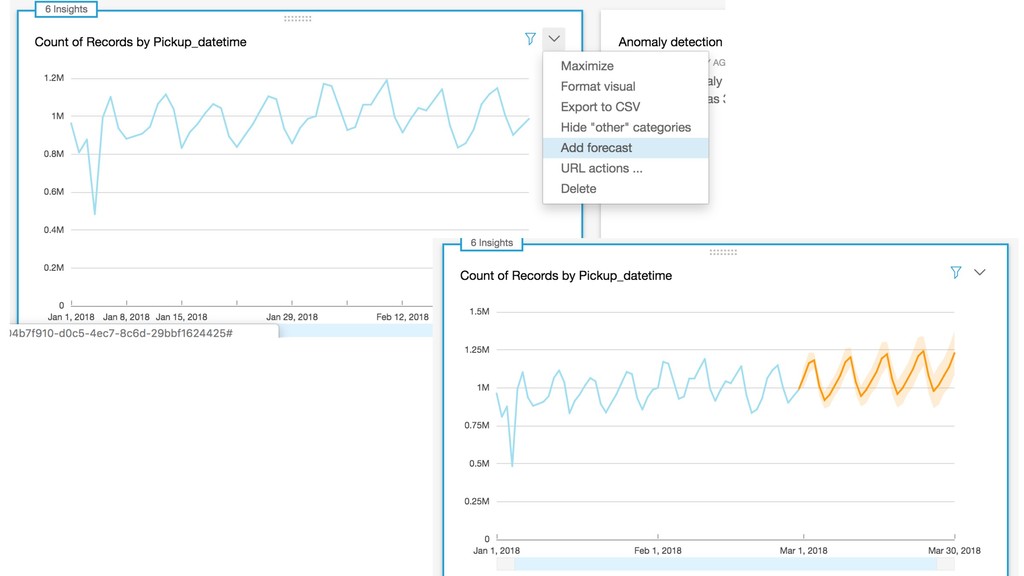
Modern data is massive, quickly evolving, unstructured, and increasingly hard to catalog and understand from multiple consumers and applications. This session will guide you though the best practices for designing a robust data architecture, highlightning the benefits and typical challenges of data lakes and data warehouses. We will build a scalable solution based on managed services such as Amazon Athena, AWS Glue, and AWS Lake Formation.
{kind=link}
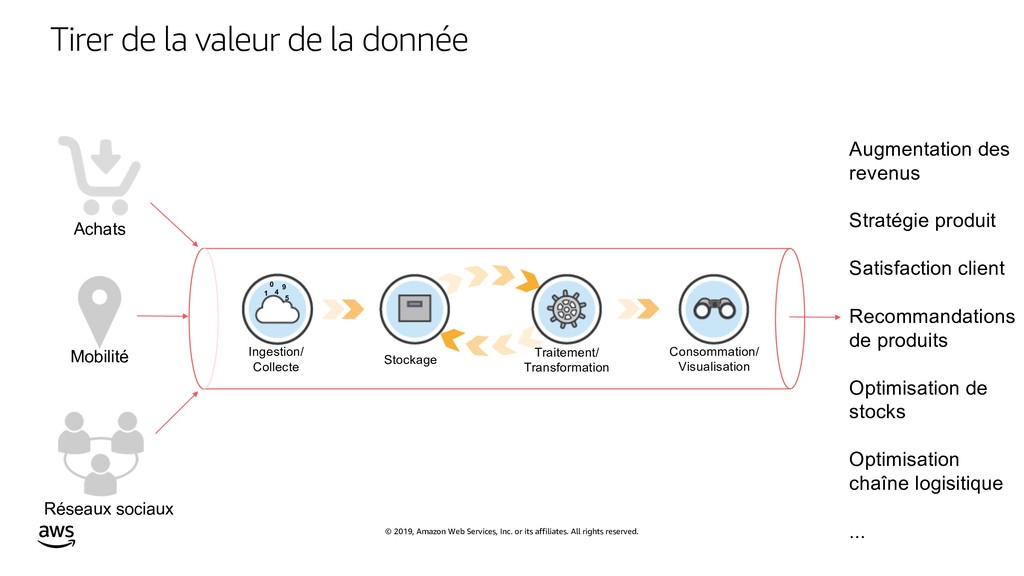{kind=link}
{kind=link}
{kind=link}
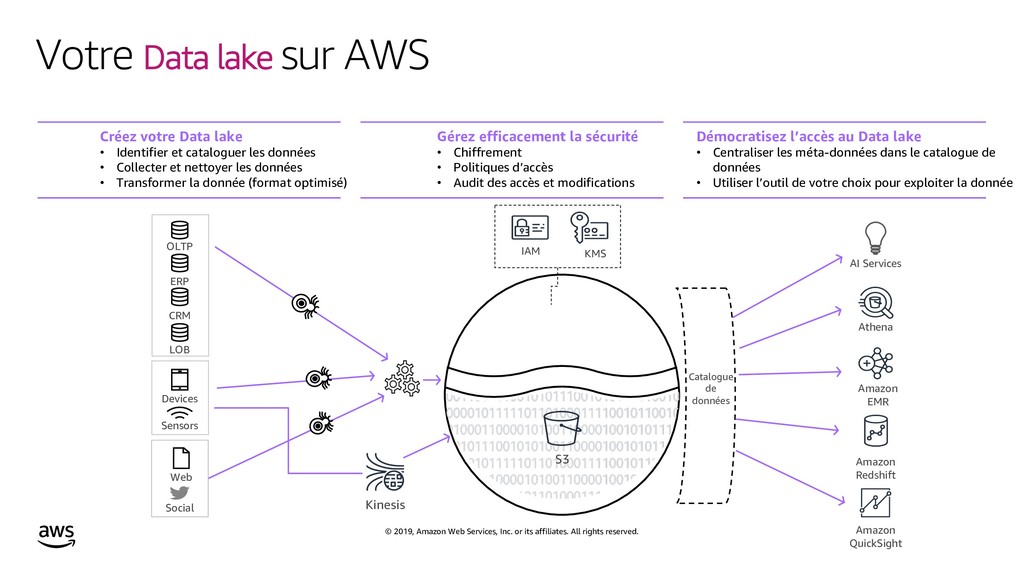{kind=link}
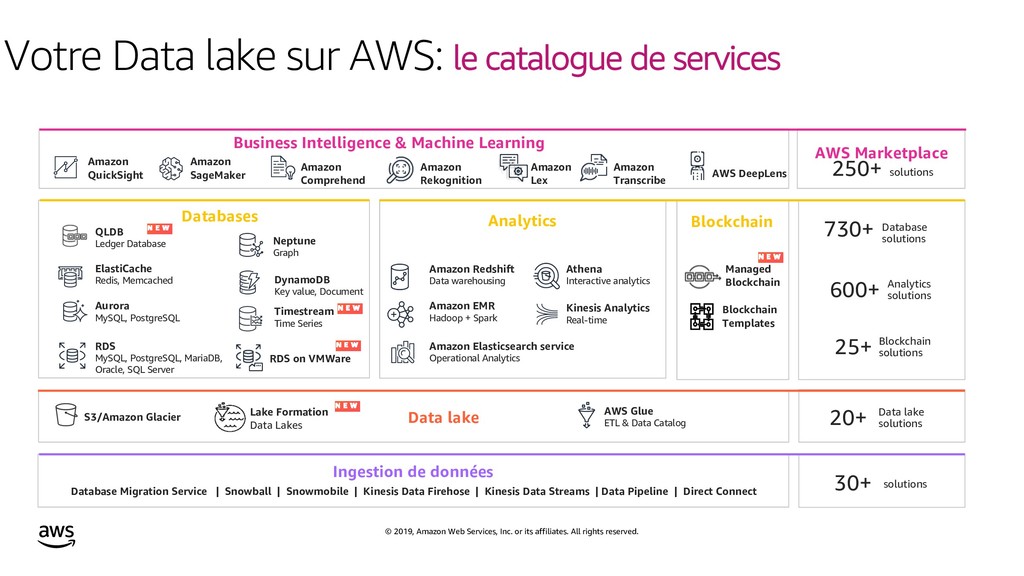{kind=link}
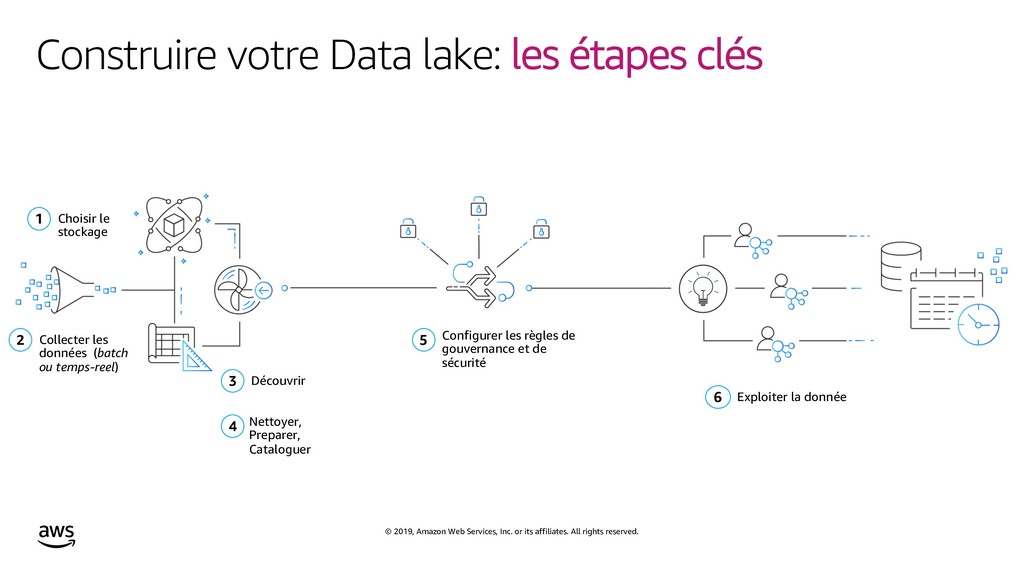{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}