AW S O T H E R S E R V I C E P R O V I D E R S I N F R A S T R U C T U R E A U T O M AT I O N A P I S M O N I T O R I N G , L O G G I N G C L I T O O L S W O N D E R L A N D O T H E R T O O L I N G
the Prometheus pushgateway • For cron jobs, Wonderland automatically notifies cronitor.io about executions • Dead man’s switch: If not notified for a certain time an alert is created W O R K E R H E A LT H C H E C K S
on Wonderland automatically has a dashboard showing key metrics for debugging • Developers can create custom dashboards for more detailed analysis • Grafana pulls data from Prometheus instances
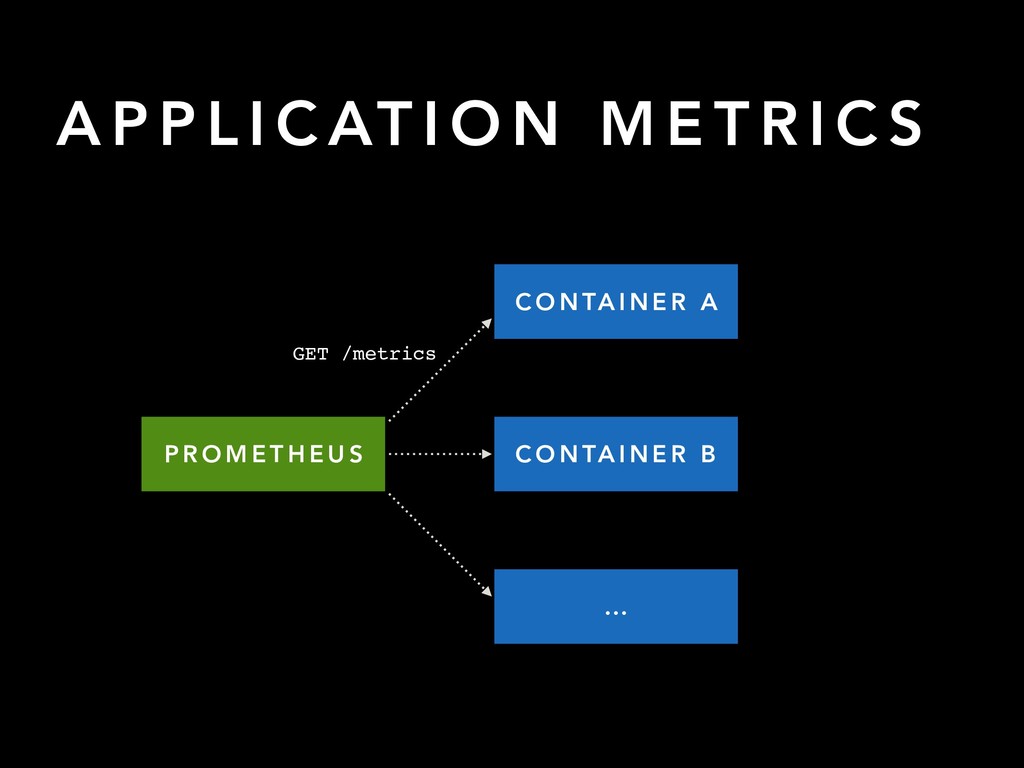
C O N TA I N E R A C O N TA I N E R B … W O N D E R L A N D S E R V I C E D I S C O V E RY W O N D E R L A N D A P I update config locate containers scrape metrics and reload S E R V I C E D I S C O V E RY
P R O M E T H E U S S H O RT- T E R M P R O M E T H E U S scrape filtered metrics 'match[]': - '{job="application_metrics", instance=""}' 3 2 D AY S 3 0 M I N F E D E R AT I O N
P R O M E T H E U S S H O RT- T E R M P R O M E T H E U S scrape filtered metrics http_requests_total{instance=“10.8.3.101:80”} http_requests_total{instance=“10.8.3.102:80”} http_requests_total{instance=“10.8.3.103:80”} ... job:http_requests_total:sum{} job:http_requests_total:sum{}
centrally • Optionally logs are parsed with configurable formats C E N T R A L I S E D L O G G I N G $ cat wonderland.yaml --- components: - name image: my-nginx-image logging: types: - access_log - error_log_nginx
D L O G G I N G D O C K E R L O G B E AT L O G Z . I O fluentd protocol lumberjack protocol Wonderland Logbeat • receives logs via fluent protocol, • parses them, • adds metadata, • and streams them to our logging provider logz.io
this night’s incident, you create the action item to Monitor the number of instances of web-delivery to detect potential breaches of auto-scaling limits before affecting the system’s health
I N G / S O U R C E S • Beyer, Jones, Petoff & Murphy Site Reliability Engineering • Susan Fowler Production-Ready Microservices • Sam Newman Building Microservices • Stripe / Increment On-Call (https://increment.com/on-call/) • Mathias Lafeldt & Paul Seiffert A Journey Through Wonderland (https://speakerdeck.com/mlafeldt/a-journey-through-wonderland)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}