Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
MySQLやSSDとかの話 後編
Search
Takanori Sejima
December 15, 2015
Technology
19
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
MySQLやSSDとかの話 後編
MySQLやSSDとかの話です
Takanori Sejima
December 15, 2015
More Decks by Takanori Sejima
See All by Takanori Sejima
(きっとたぶん)人材育成や教育のような何かの話
sejima
0
990
互換性のある(らしい)DBへの移行など考えるにあたってたいへんざっくり
sejima
1
3.8k
NAND Flash から InnoDB にかけての話(仮)
sejima
0
29
InnoDBのすゝめ(仮)
sejima
0
35
さいきんのMySQLに関する取り組み(仮)
sejima
0
26
sysloadや監視などの話(仮)
sejima
0
25
さいきんの InnoDB Adaptive Flushing (仮)
sejima
0
28
TIME_WAITに関する話
sejima
0
37
MySQLやSSDとかの話 その後
sejima
0
27
Other Decks in Technology
See All in Technology
データ活用研修 問いの発見と仮説構築【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
660
QAと開発の両側から進める AI活用 -QAプロセスAI支援ツールキットと Inner Loop / Outer Loopの取り組み-
legalontechnologies
PRO
2
360
AI驚き屋発見器
yama3133
1
380
新たなDBアーキテクチャ「LTAP」にDeep Dive!!
inoutk
0
150
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
6
1.1k
AIQAのナレッジ構築について
qatonchan
1
120
Escolhendo LLMs na Prática: Lições Reais em Busca Agêntica no Mercado Livre —TDC 2026 Floripa
jpbonson
0
100
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
440
AI工学特論: MLOps・継続的評価
asei
11
3k
信頼できるテスティングAIをどう育てるか?
odan611
0
160
書籍セキュアAPIについて
riiimparm
0
380
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
200
Featured
See All Featured
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Skip the Path - Find Your Career Trail
mkilby
1
170
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Google's AI Overviews - The New Search
badams
0
1.1k
Six Lessons from altMBA
skipperchong
29
4.4k
Unsuck your backbone
ammeep
672
58k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
930
Transcript
Copyright © GREE, Inc. All Rights Reserved. MySQLやSSDとかの話 後編 Takanori
Sejima
Copyright © GREE, Inc. All Rights Reserved. 自己紹介 • わりとMySQLのひと
• 3.23.58 から使ってる • むかしは Resource Monitoring も力入れてやってた • ganglia & rrdcached の(たぶん)ヘビーユーザ • 5年くらい前から使い始めた • gmond は素のまま使ってる • gmetad は欲しい機能がなかったので patch 書いた • webfrontend はほぼ書き直した • あとはひたすら python module 書いた • ganglia じゃなくても良かったんだけど、とにかく rrdcached を使いたかった • というわけで、自分は Monitoring を大事にする • 一時期は Flare という OSS の bugfix などもやってた
Copyright © GREE, Inc. All Rights Reserved. • 古いサーバを、新しくてスペックの良いサーバに置き換えていく際、いろい ろ工夫して集約していっているのですが
• そのあたりの背景や取り組みなどについて、本日はお話しようと思います • オンプレミス環境の話になっちゃうんですが • 一部は、オンプレミス環境じゃなくても応用が効くと思います • あと、いろいろ変なことやってますが、わたしはだいたい考えただけで • 実働部隊は優秀な若者たちがいて、細かいところは彼らががんばってくれ てます 本日のお話
Copyright © GREE, Inc. All Rights Reserved. • 最近の HW
や InnoDB の I/O 周りについて考えつつ、取り組んでおり まして • さいきん、そのあたりを資料にまとめて slideshare で公開しております • 後日、あわせて読んでいただけると、よりわかりやすいかと思います • 参考: • 5.6以前の InnoDB Flushing • CPUに関する話 • EthernetやCPUなどの話 本日のお話の補足資料
Copyright © GREE, Inc. All Rights Reserved. では後編を はじめます
Copyright © GREE, Inc. All Rights Reserved. • ioDrive の実績上がってきたし
• サービス無停止で master 統合の目処も立ったから • 大容量のSSD導入して、ガンガンDB統合していこうと思ってたんだけど
Copyright © GREE, Inc. All Rights Reserved. 次の課題とは?
Copyright © GREE, Inc. All Rights Reserved. それは
Copyright © GREE, Inc. All Rights Reserved. バックアップ どうしよう?
Copyright © GREE, Inc. All Rights Reserved. • DBのバックアップをどうやって取得しよう? •
HDDのころは、masterとslaveは146GBのHDD*4でRAID10だった が、 バックアップファイルを取るためのslaveはHDD*6とかHDD*8とか で、データベース用の領域と、バックアップファイルを書き出すための領域 を確保できるようにしてた • 具体的には、 mysqld 止めて datadir を tar ball で固めてた • つまり、masterのサーバとバックアップファイルを取るためのサーバは、 ストレージの容量が等しくなかった 次の課題
Copyright © GREE, Inc. All Rights Reserved. • バックアップサーバとmasterで同じ容量のSSD使うと、バックアップを取 ることができない
• DBで800GB使いきっちゃうと、 tar ball とれない • 数TBの大容量 PCI-e SSD をバックアップサーバ用に使う? • それはリッチすぎるコストパフォーマンスが悪い • HDDだとI/Oの性能が追いつかない • DBを統合するということは、それだけ更新が増えるということでもある • SSDをRAIDコントローラで束ねる? • そうするとRAIDコントローラがボトルネックになるケースも出てくる • かつては、RAIDコントローラ経由だと SMARTがとれないという課題もあった 一番容量のでかいSATA SSDを使いたい
Copyright © GREE, Inc. All Rights Reserved. • HDDもSSDも、ブロックデバイスは、一つのI/Oコントローラに対して read
と write を同時に発行すると遅い • read only ないし write only のときに最大のスループットがでる • RAIDで束ねたHDD上で tar ball 取得するの、データベースが大きくな るに連れて、無視できない遅さになってきていた • SSDに移行したとしても、このままだといつか遅くなって困るんじゃない? 大容量のSSDを使う前から、課題意識はあった
Copyright © GREE, Inc. All Rights Reserved. 五時間くらい 考えた
Copyright © GREE, Inc. All Rights Reserved. そうだ
Copyright © GREE, Inc. All Rights Reserved. バックアップの取り方 を変えよう
Copyright © GREE, Inc. All Rights Reserved. • master/slave/バックアップサーバをぜんぶ 800GB
のSSDにする • バックアップサーバは ssh 経由で、同じラックにある SATA HDDの RAID6なストレージサーバに tar ball を書き出す • $ tar cvf - ${datadir} | pigz | ssh ${storage_server} “cat - >backup. tar.gz” • SSDなので tar するときの read は速い • pigzでCPUのcoreぜんぶ使いきって圧縮するので、帯域制限にもなるし、 通信量もへる。まぁ、ラックをまたがないので、全力で転送しても困らない • HDDは sequential write only になるので、書き込むのは充分速い • 運用や監視も、既存の方法と比べて大きくは変えなくて良い 方法を変える、許容できる範囲内で
Copyright © GREE, Inc. All Rights Reserved. • データが巨大になると、DB再構築するのに時間がかかるようになる •
今までN+1の構成だったところはN+2にする • slaveは一台多めにしておく。一台故障したら、もう一台故障する前にじっくり再構築 • ストレージサーバは RAID6 にする。 SATA HDD の故障率を考慮して • ストレージサーバはTB単位のデータを持っているため、電源などが故障したときのダメー ジがでかいので、二台構成にする。 • バックアップサーバから書き出す先は現行系のストレージサーバにして、待機系は cron で rsync してコピーする • ストレージサーバはSATA HDDにしたから大容量にできたので、ストレージサーバ一台 に対して、書き込むバックアップサーバは複数台にする。それならば、ストレージサーバを 二台構成にしてもコスト的にペイする • 最終的に、トータルで台数減ればそれでいい 破綻しないよう、考えながら集約する
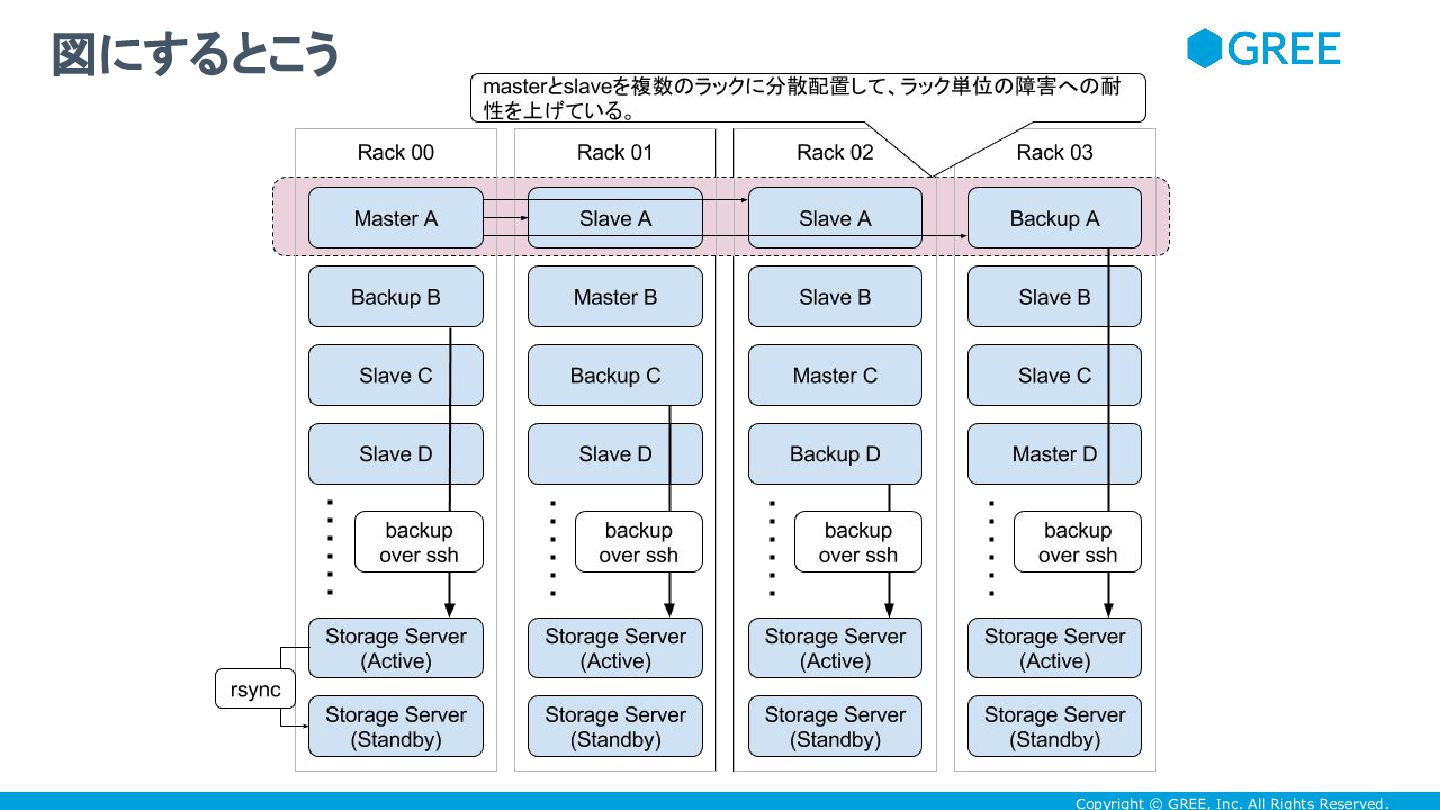
Copyright © GREE, Inc. All Rights Reserved. 図にするとこう
Copyright © GREE, Inc. All Rights Reserved. • Google の
Warehouse-Scale Computer ほど大きい粒度ではなく、4 本以上のラックを一つの単位として考える • replication の traffic は、これらのラックに閉じ込めてしまう。 • RAID5がパリティを複数のディスクに分散させるように、masterやバック アップ用のサーバを複数のラックに分散させる • 万が一、ラックごと落ちたとしても、影響を受ける master の数を限定的にできる • master -> slave 間の replication の traffic が、ラックごとに偏りにくくなる • アプリケーションサーバ <-> slave の traffic が多かったとしても、ラックごとに偏りに くくなる • バックアップサーバを分散配置することで、ストレージサーバのディスク使用量を、ラック ごとに偏らせないようにする 複数のラックをグルーピングし、RAID5の様に扱う
Copyright © GREE, Inc. All Rights Reserved. • 現状のHWの特性や、今後のHWを想定している •
サーバのNICの帯域が増えても、これらのラックの集合の中でその性能が活かせる • 弊社の場合、KVSの replication の traffic が大変多いのだが、 KVSやMySQLの replication の traffic を特定のラックに集約できると、運用上楽になる • pigz でバックアップファイルを圧縮するので、 DBの集約度が上がってDBのサイズが増 えても、CPUのコアが増えれば、バックアップの取得時間を稼ぐことができる • SSDの消費電力の少なさを活かして、一ラックあたりの集積度を上げていける • SSDは消費電力が少なく熱にも強いから、そのぶん CPU で TurboBoost 使って、熱 出しつつ性能を引き出す方向で行ける • TurboBoost 使うことで、NICの帯域が増えても、CPUがパケットさばけるようにする • 現状はSATAのHDDをバックアップ用のストレージに割り当てているけど、 SSDのバイト 単価が十分下がっていけば、別に SSD でもかまわない このラックの使い方には、いろいろな思惑がある
Copyright © GREE, Inc. All Rights Reserved. • 最近は、 ioMemory
や 800GBのエンタープライズグレードの SATA SSD を使い分けてたりする • SATAのSSDはコストパフォーマンスが良い。でも、GREE的には Fusion-IOの方が実績がある • サービスの品質を担保しつつ、使い比べて、適切に使い分けていきたいの で • latencyの要件厳しくないところから、SATAのSSDにしていっている いろいろ考えたので導入してる
Copyright © GREE, Inc. All Rights Reserved. • 書き込み寿命の短いものも、積極的に使うようにしている •
かつて、 ioDrive MLC 320GB は書き込み寿命が 4PBW だったけど • ioMemory SX1300 は、 1250GB の容量で、4PBW • 容量あたりの書き込み寿命短い製品の方が安いので、積極的に書き込み を減らす工夫をしている • こちらの資料 で double write buffer など調査してる理由の一つは、書 き込みを減らして安価な NAND Flash を使ってコストダウンしたいがため • あと、 NAND Flash は微細化が進むに連れて書き込み寿命が短くなる 性質なので、ハードウェアの変化に備えるために ただ、 ioMemory でも
Copyright © GREE, Inc. All Rights Reserved. • ファイルシステムの discard
option 有効にして SATA SSD を使おうと すると、巨大なファイルの削除が遅い傾向にある。(最近の kernel だとな おってるかもしれないが)、Linux は TRIMの最適化がいまいち • 例外的に、Fusion-IO は discard 指定して mount しても、あまり性能 劣化しない傾向なので、 Fusion-IO 使うときだけ discard 指定してる • MySQLでは、 binary log を purge したり、 DROP TABLE などでファ イルを削除する場合があるので、ファイル削除が遅いのはつらい • SATA SSD 使うときは discard 指定しないようにしてる。 TRIM に期待 するより、InnoDB をチューニングして I/O 減らす方がいい LinuxのTRIMサポートにはあまり期待していない
Copyright © GREE, Inc. All Rights Reserved. • MySQL5.6を使って •
5.7の本格導入はこれから • double write buffer は無効化 • innodb_io_capacity=100 • いろいろやってたら、このバグ踏むことは確かにあった • default の 200 ならそんなに困らないんだけど、それでも、 innodb_adaptive_flushing_lwm までredo logがたまらないのはもったいない • 夜中などオフピークの時間帯は、 redo logをためずに書いてしまうことがある • redo logが溜まってきたら、 innodb_adaptive_flushing_lwm や innodb_io_capacity_max に応じて書き込むので、 innodb_adaptive_flushing_lwm まではログをためてもいいという判断 SSDで書き込みを減らすための、最近の取り組み
Copyright © GREE, Inc. All Rights Reserved. • 一つは、安価なNAND Flashを使えるようにして、ランニングコストを下げ
ること • もう一つは、故障率を下げる試みとして • 経験上、たくさん書き込んでる NAND Flash ほど、故障しやすいので • Facebook の論文(A Large-Scale Study of Flash Memory Failures in the Field) でも、たくさん書き込んでると、 uncorrectable な error が発生しやすいとのこ となので • 故障率を下げて、よりサービスを安定稼働させたい • AWS で EBS 酷使するとしても、 iops 減らせるほうが最終的には便利 だし、コストダウンに繋がる 書き込みを減らしたいのは、幾つかの理由から
Copyright © GREE, Inc. All Rights Reserved. • SSD で集約して、一部のサーバのCPU使用率は上げられるようになって
きたけど、もっとCPUを活用していきたい • 今後もCPUはCoreの数増え続けるだろうし • というわけで、性能上問題がないところは InnoDB の圧縮機能を使って、 CPUを活用し、さらに集約度を上げていってる • 秘伝のタレである my.cnf 見なおしたり • DB の設計によっては、 mutex が課題になるケースもある • TurboBoost 使ってCPUの性能を引き出すために、CPUの温度などもさ いきんは取り始めた • バックアップの取り方を、さらに見直すなどもした 他にもやってる取り組み
Copyright © GREE, Inc. All Rights Reserved. • mysqld を止めて
tar ball を取る場合、 mysqld を止めている間に master がクラッシュすると、その間のbinlog取り損なって残念 • そこで、mysqlbinlog で --read-from-remote-server --stop- never --raw を使って、 tar ball とってる間も binlog を取り続けるよう にして、いざというときはその binlog を使えるようにしておく • XtraBackup などでオンラインバックアップを取る運用に変えれば、 mysqld 止めなくてもいいから、binlog欠損しないんだけど、運用を変え ないでいいというのは、導入が容易というメリットがある MySQL5.6以降のmysqlbinlogを活用
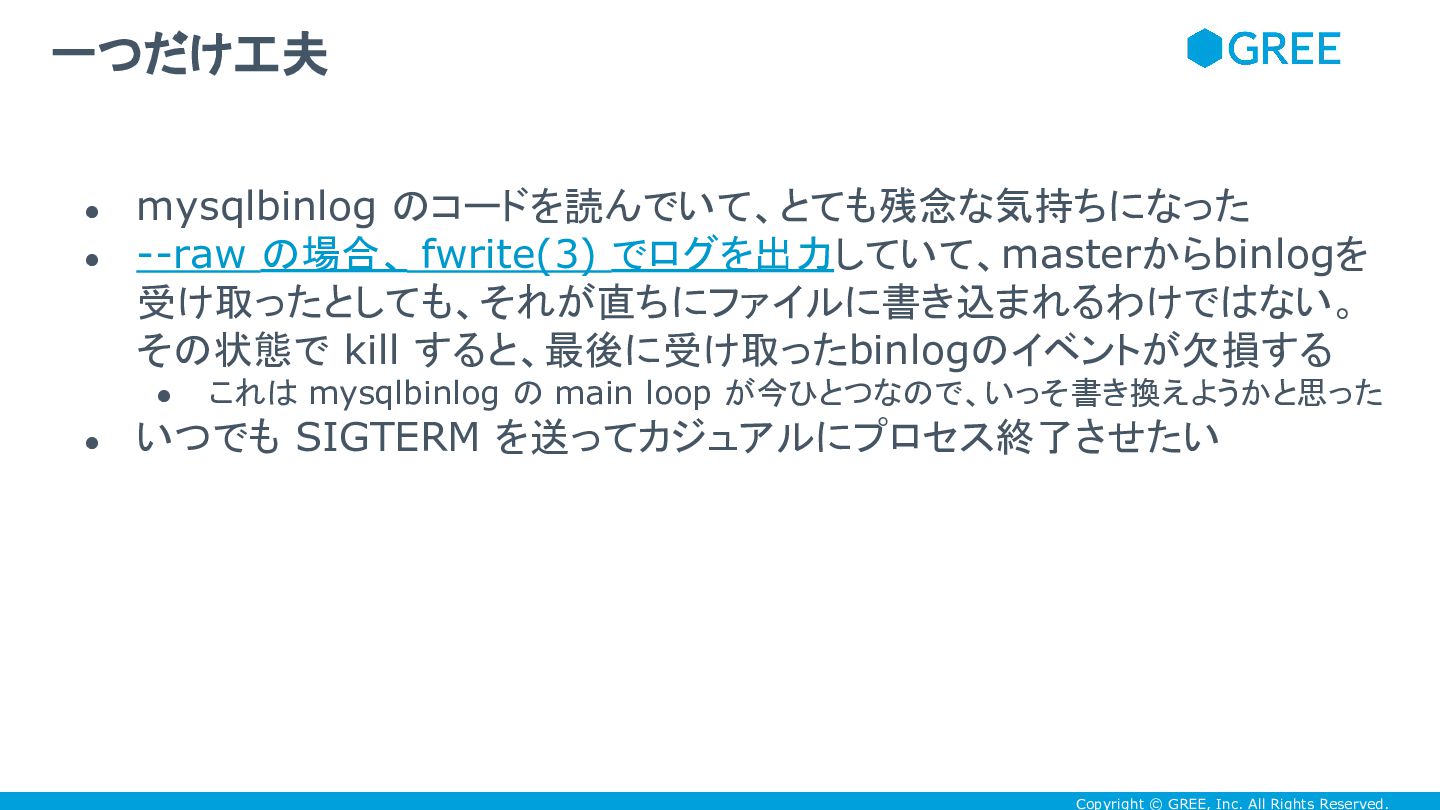
Copyright © GREE, Inc. All Rights Reserved. • mysqlbinlog のコードを読んでいて、とても残念な気持ちになった
• --raw の場合、 fwrite(3) でログを出力していて、masterからbinlogを 受け取ったとしても、それが直ちにファイルに書き込まれるわけではない。 その状態で kill すると、最後に受け取ったbinlogのイベントが欠損する • これは mysqlbinlog の main loop が今ひとつなので、いっそ書き換えようかと思った • いつでも SIGTERM を送ってカジュアルにプロセス終了させたい 一つだけ工夫
Copyright © GREE, Inc. All Rights Reserved. 一時間ほど 考えた
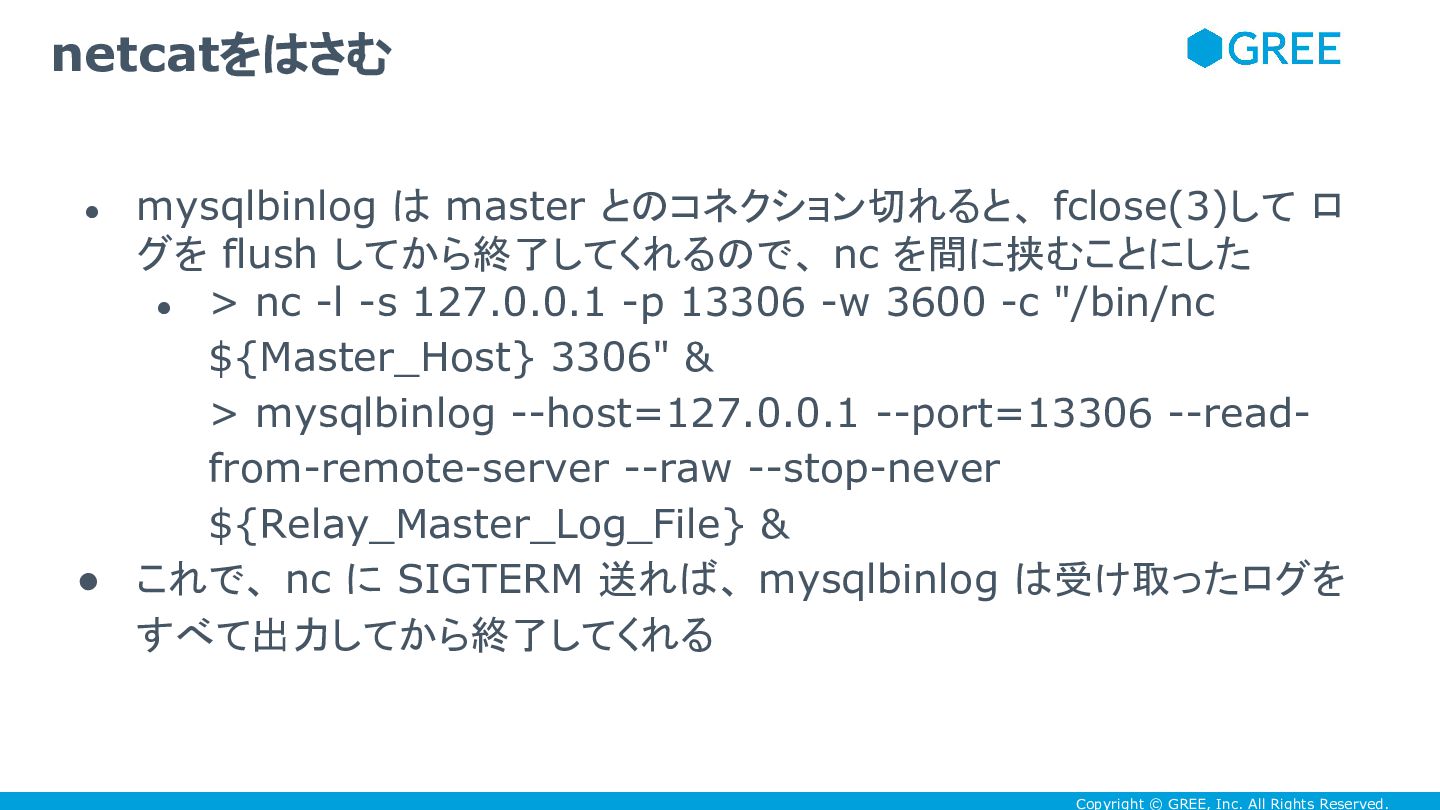
Copyright © GREE, Inc. All Rights Reserved. • mysqlbinlog は
master とのコネクション切れると、 fclose(3)して ロ グを flush してから終了してくれるので、 nc を間に挟むことにした • > nc -l -s 127.0.0.1 -p 13306 -w 3600 -c "/bin/nc ${Master_Host} 3306" & > mysqlbinlog --host=127.0.0.1 --port=13306 --read- from-remote-server --raw --stop-never ${Relay_Master_Log_File} & • これで、 nc に SIGTERM 送れば、 mysqlbinlog は受け取ったログを すべて出力してから終了してくれる netcatをはさむ
Copyright © GREE, Inc. All Rights Reserved. • master統合する前に、統合後の書き込みの負荷がどれくらいになるのか をテストしたかったので
• 次のワンライナーを実行すると、 mysqlbinlog が io_thread、 mysql client が sql_thread 相当の仕事をしてくれるので、レプリケーションし ながらこれで query を流し込めばいい • trickle -s -d ${適当な値} mysqlbinlog --host=${MASTER_HOST} -- verify-binlog-checksum --read-from-remote-server --stop-never ${MASTER_LOG} 2>${LOGFILE}_log.err | tee ${LOGFILE}_log.txt | mysql --binary-mode -vv > ${LOGFILE}_client.txt 2>${LOGFILE} _client.err mysqlbinlog でもう一つ ただし、この方法は各自の責任で試してください!
Copyright © GREE, Inc. All Rights Reserved. • 5.6 で
fix されたけど、それ以前の mysql client は、 mysqlbinlog が生成した query をうまく処理できないケースがあった • なので、前のページで書いた方法は、 5.6 以降の mysqlbinlog と mysql client の組み合わせで試すべき • あと、今後 MySQL の version が上がったときに、 binlog の format が変わらない保証はない • 自分で試すときは、最初に、使う可能性があるすべての version の mysql で binlog 周りのコードを読んでからにした • 当時、わたしは MySQL5.7 を待つ堪え性がなかっただけなので • いまは 5.7で multi source replication 使うほうが無難かも mysqlbinlog と mysql client の相性問題
Copyright © GREE, Inc. All Rights Reserved. • インフラエンジニアが、お客様に対して還元できることは •
サービスの安定性を向上することと • ランニングコストを削減することくらいなので • サービスの安定性を確保しつつ、ランニングコストを削減できれば、そのぶ ん、サービスの改善に活かせるはず なぜこんなことをやるかというと
Copyright © GREE, Inc. All Rights Reserved. • サーバを構成するハードウェア、CPU/メモリ/ストレージ/ネットワークのう ち
• この五年間でもっとも進化したのは、ストレージ • SSDになって、性能向上して、容量増えて、消費電力さがって • 書き込み寿命という概念がもたらされた • ストレージの変化に合わせて、許容できる範囲内でシステムを見なおして • サービスの安定性を向上させつつ、ランニングコストの削減を図って • お客様に還元しようと思った 過去五年間を振り返って考えると
Copyright © GREE, Inc. All Rights Reserved. • 一つのサービスを5年以上続けていると、ハードウェアなど、周囲の環境 が変わってくる
• さいきん立ち上がったサービスは、最初からSSDやAWSが当たり前なの で、それに最適な設計で始められるので、コスト面で優位に立てる可能性 が高い • 古くからあるサービスも、現代の状況に合わせてあるていど変化させない と、コストパフォーマンスが悪いままで、競争で不利になる。古いサービス は先行者利益があるだけではない • 時代の変化に追随して、現代のハードウェアに対して最適な構成に変更 し、競争力を維持するよう努める 時代の変化に追随する
Copyright © GREE, Inc. All Rights Reserved. • 最近は、次にどんなハードウェアが進化するのか、どの構成要素の進化が 著しいのかを考えていて
• それに合わせて、許容できる範囲内でシステムを見なおしてるところです • 個人的には、オンプレミスとかパブリッククラウドとかこだわりはなくって、 何をどう使うのが、最終的に一番メリットあるのか考えてたりします • 現状、オンプレミス環境は、次の2つのメリットがあるので推奨してますが、 これらも時代とともにうつろうのだろうと考えてます • サーバだけでなく、ネットワーク機材のメンテナンスもあるていどスケジューリングできる ので、他社向けのサービスに対し、影響の少ない時間帯にメンテナンス作業ができる • I/Oの性能がよい そういうわけで
Copyright © GREE, Inc. All Rights Reserved. おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}