of using open source code • Web Scrape a single web site - ours • Environment and code – Using Centos V6.2 ( Linux ) – Apache Nutch 1.6 – Solr 4.2.1 – Java 1.6
apache-nutch-1.6-bin.tar ( 64M ) – apache-nutch-1.6-src.tar ( 20M ) • Copy each tar file to your desired location • Install each tar file as – tar xvf <tar file> • Second tar file optional
single web site • Ensure that JAVA_HOME is set • cd apache-nutch-1.6 • Edit agent name in conf/nutch-site.xml <property> <name>http.agent.name</name> <value>Nutch Spider</value> </property> • mkdir -p urls ; cd urls ; touch seed.txt
) to seed.txt – http://www.semtech-solutions.co.nz • Change url filtering in conf/regex-urlfilter.txt, change the line – # accept anything else – +. – To be – +^http://([a-z0-9]*\.)*semtech-solutions.co.nz/ • This means that we will filter the urls found to only be from the local site
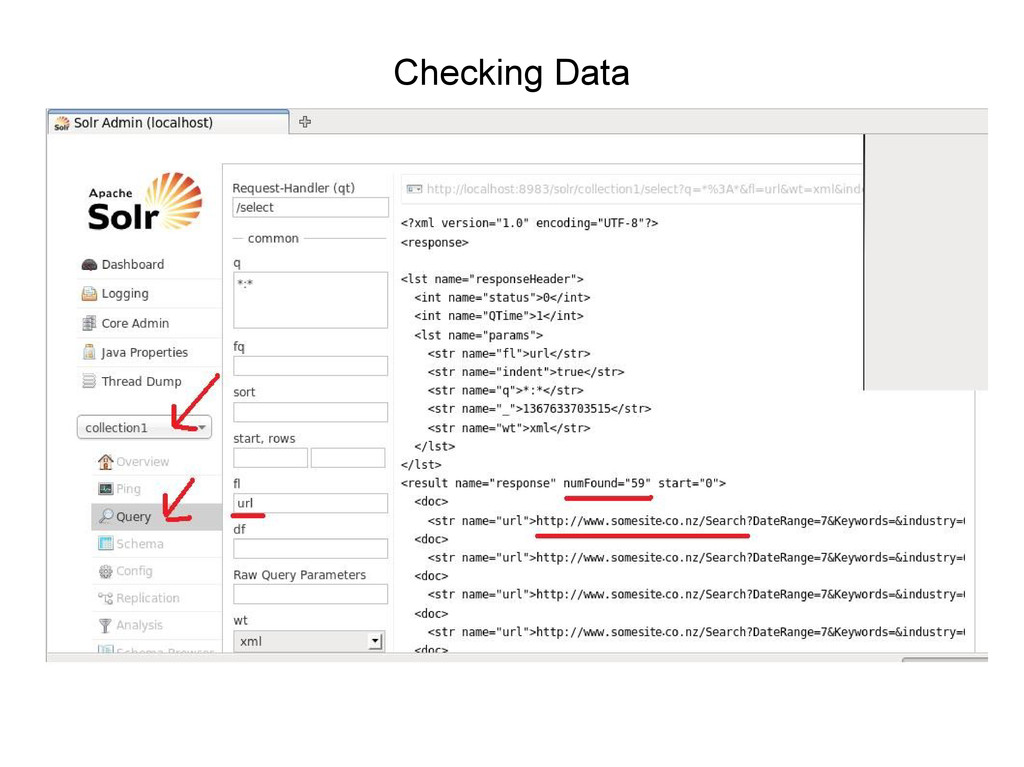
Run the following command • java -jar start.jar • Now try to access admin web page for solr – http://localhost:8983/solr/admin • You should now see the admin web site – ( see next page )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}