system developed using Java • Supports very large data sets • Supports large clusters of servers • Designed to run on pre existing low cost hardware • Allows for fragmentation of work over cluster • Allows for fragmentation of storage over cluster • Provides resiliance via automatic failure handling
utilities for Hadoop module support • Hadoop MapReduce Parallel processing of Hadoop data • Hadoop Yarn Scheduler and resource manager • Hadoop Distributed File System (HDFS) A Master/Slave file system which spreads the Hadoop data over a very large cluster of slave data nodes controlled by a single name node.
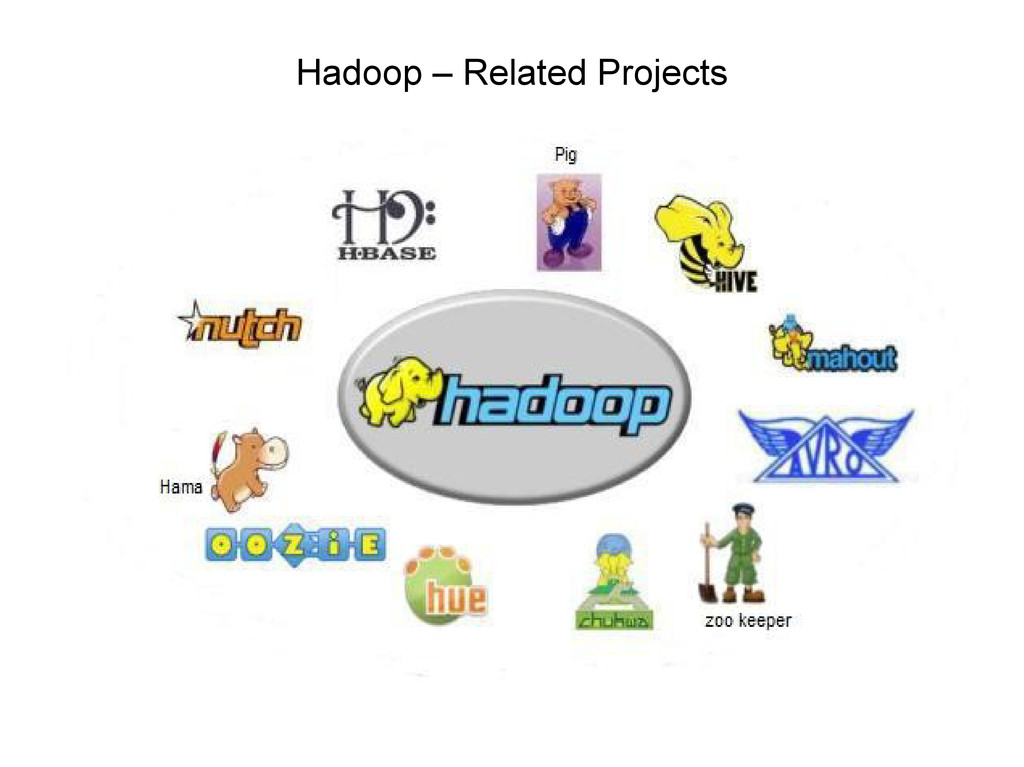
data sets • Hive – data warehouse system for Hadoop • Mahout – machine learning and data mining • Avro – a data serialization system • Zoo Keeper – helps build distributed applications • Chukwa – data collection and analysis
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}