Paging people just creates a series of problems unless you put enough resources to build a healthy "on-call" culture. Nobody wants to be buried into alerts or wake up at 2 am in the morning.
There are several points you have to take into account to make on-call suck less. At the center of each of these items, there are people. If you put your people at the center and design your incident response thinking about them in the first place, on-call becomes a competitive advantage.
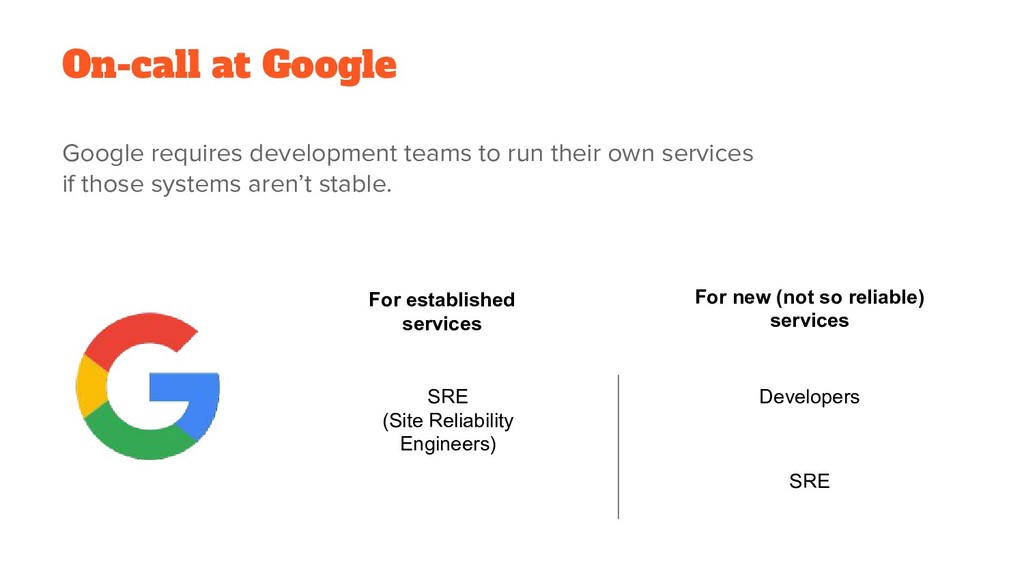
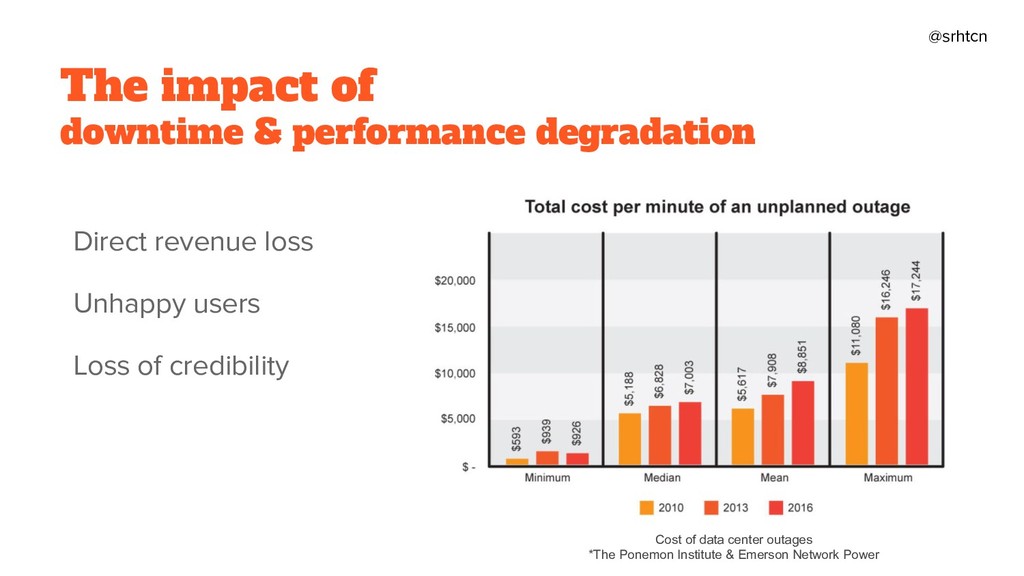
In this presentation, Serhat will start defining on-call and why we need a robust on-call culture. At this point, he'll mention the impact of downtime and performance degradation such as direct revenue, and credibility losses. Then, continue listing 6 must-haves: - Be transparent - Share responsibilities - Get ready for wartime - Build resilient and sustainable systems - Create actionable alerts - Learn from your experiences. In each of these steps, there will be crucial points and pieces of advice to both developers and management systems. In the end, Serhat will show that our efforts in building a better on-call culture, will pay off as our people and user's happiness.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}