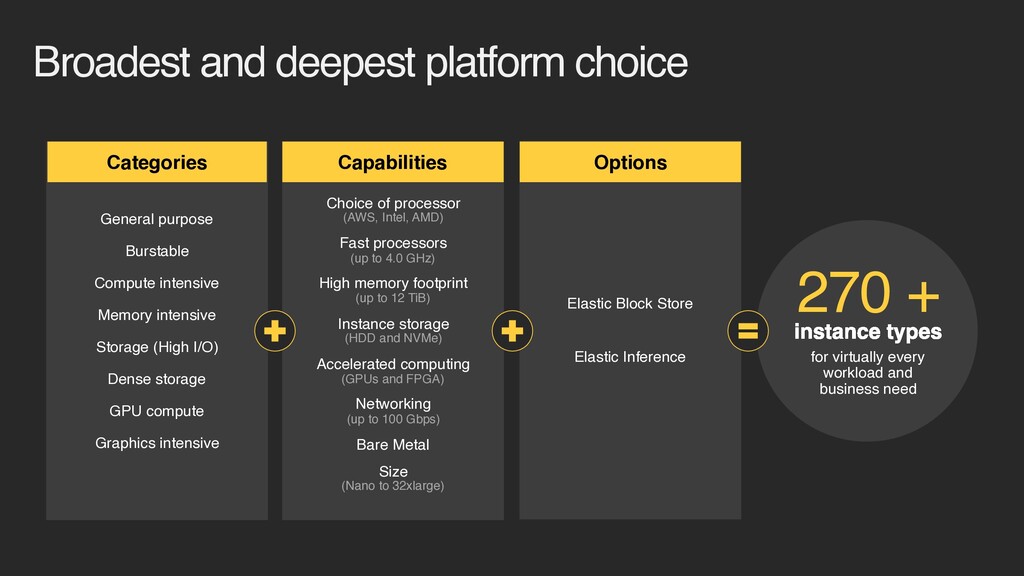
Burstable Compute intensive Memory intensive Storage (High I/O) Dense storage GPU compute Graphics intensive Elastic Block Store Elastic Inference 270 + instance types for virtually every workload and business need Choice of processor (AWS, Intel, AMD) Fast processors (up to 4.0 GHz) High memory footprint (up to 12 TiB) Instance storage (HDD and NVMe) Accelerated computing (GPUs and FPGA) Networking (up to 100 Gbps) Bare Metal Size (Nano to 32xlarge)
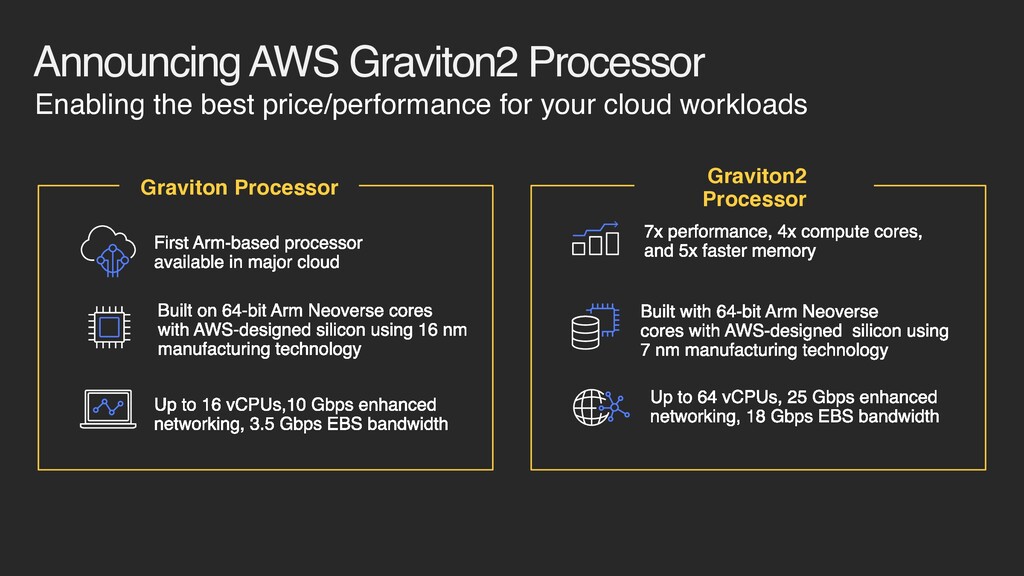
major cloud Built with 64-bit Arm Neoverse cores with AWS-designed silicon using 7 nm manufacturing technology Up to 16 vCPUs,10 Gbps enhanced networking, 3.5 Gbps EBS bandwidth Built on 64-bit Arm Neoverse cores with AWS-designed silicon using 16 nm manufacturing technology Up to 64 vCPUs, 25 Gbps enhanced networking, 18 Gbps EBS bandwidth 7x performance, 4x compute cores, and 5x faster memory Graviton Processor Graviton2 Processor Enabling the best price/performance for your cloud workloads
Preview M6g C6g R6g Up to 40% better price-performance for general purpose, compute intensive, and memory intensive workloads. Built for: General-purpose workloads such as application servers, mid-size data stores, and microservices. Built for: Compute intensive applications such as HPC, video encoding, gaming, and simulation workloads. Built for: Memory intensive workloads such as open-source databases, or in-memory caches. Local NVMe-based SSD storage options will also be available in general purpose (M6gd), compute-optimized (C6gd), and memory-optimized (R6gd) instances
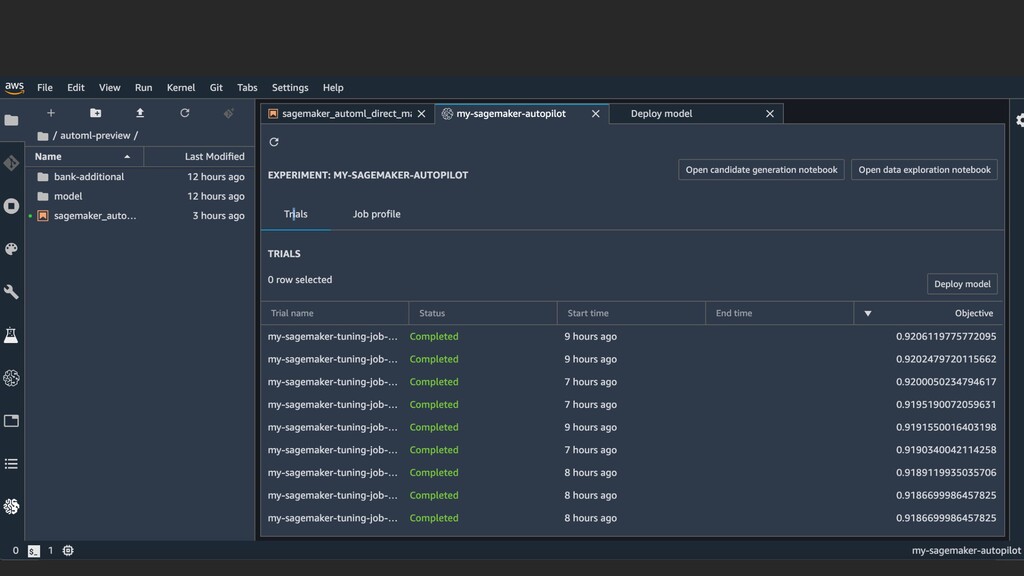
disk variants powered by AWS Graviton2 processors provide up to 40% improved price/performance over comparable x86-based instances. • These Graviton2-powered instances support a broad spectrum of workloads including application servers, open source databases, in-memory caches, microservices, gaming servers, electronic design automation, high-performance computing, and video encoding. • Most applications built on Linux distributions and open source software can run easily on multiple processor architectures and are well suited for the new instance types. • These instances are supported by several Linux distributions and an extensive ecosystem of Independent Software Vendors (ISVs). • M6g instances are available now in preview.
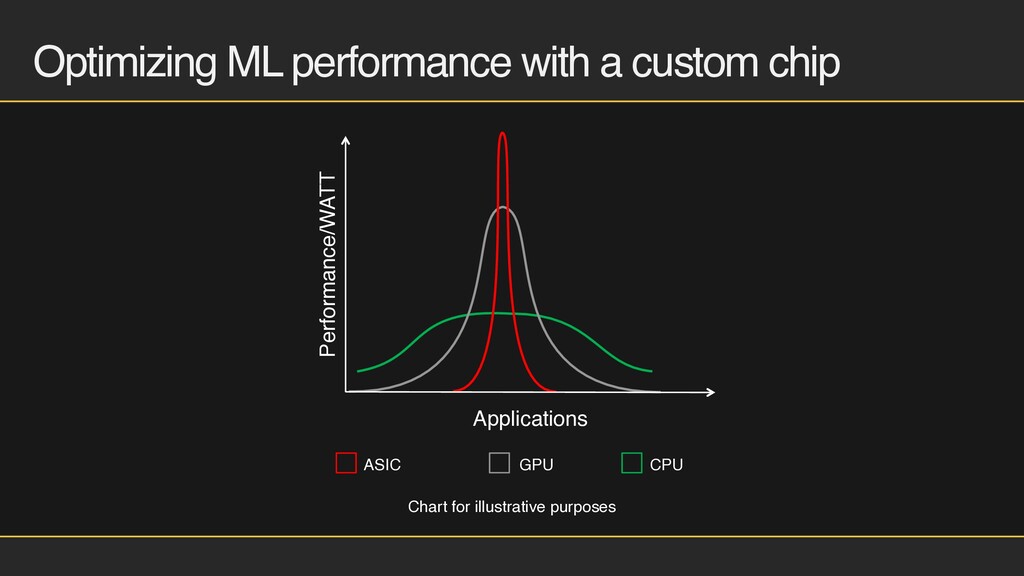
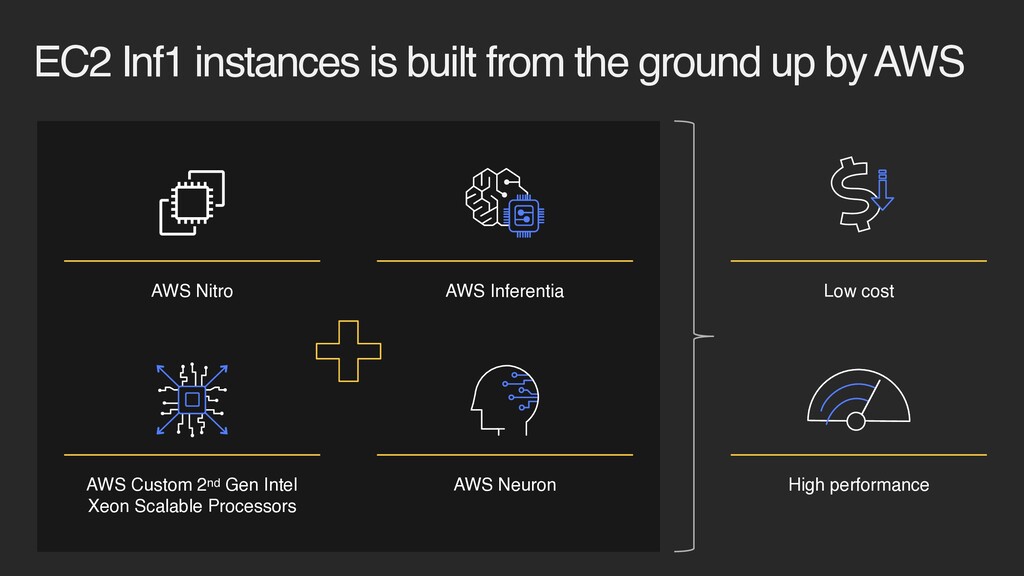
EC2 Custom chip EC2 Inf1 instances GPU based EC2 G4 instances CPU based EC2 C5 instances Applications that leverage common ML frameworks Applications that require access to CUDA, CuDNN or TensorRT libraries Small models and low sensitivity to performance Powered by AWS Inferentia Amazon EC2 G4 instances based on NVIDIA T4 GPUs Intel Skylake CPUs Support for AVX-512/ VNNI instruction set Best price/performance for ML inferencing in the cloud Up to 40% lower cost per inference and up to 3x higher throughput than G4 instances Available today! Launched! Launched!
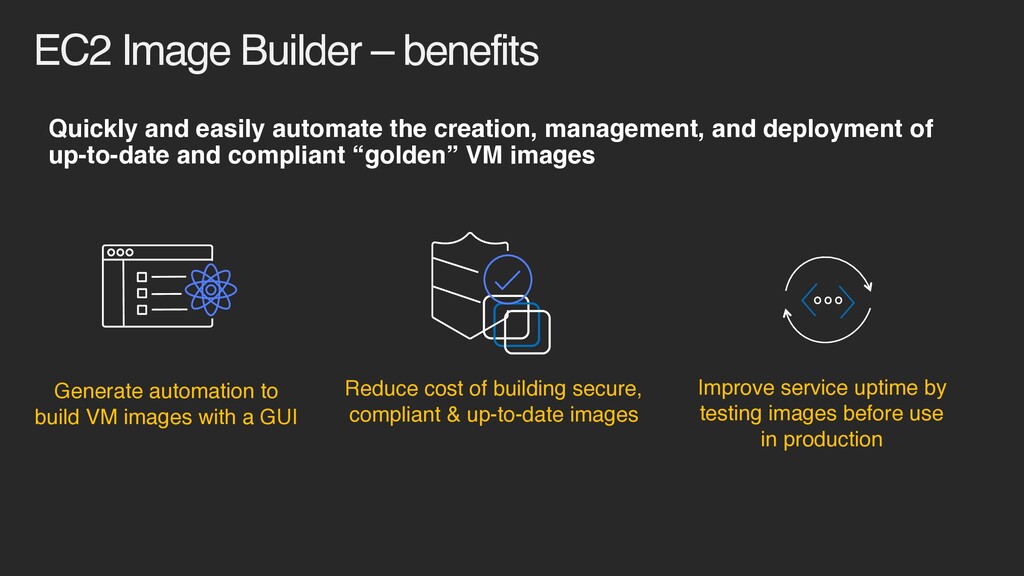
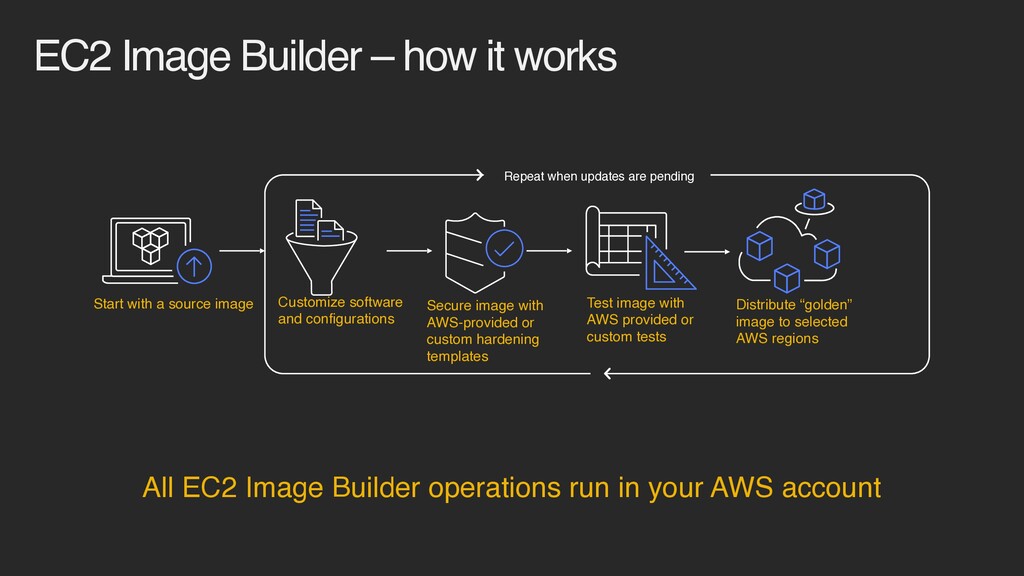
creation, management, and deployment of up-to-date and compliant “golden” VM images Improve service uptime by testing images before use in production Generate automation to build VM images with a GUI Reduce cost of building secure, compliant & up-to-date images
image with AWS-provided or custom hardening templates Test image with AWS provided or custom tests Distribute “golden” image to selected AWS regions All EC2 Image Builder operations run in your AWS account EC2 Image Builder – how it works Repeat when updates are pending
EC2 Auto Scaling groups from 140+ instances from M, C, R, T, and X families Lower costs and improve workload performance Applies insights from millions of workloads to make recommendations Saves time comparing and selecting optimal resources for your workload
on AWS Nitro System) Fully managed, monitored, and operated by AWS as if in AWS Regions Single pane of management in the cloud providing the same APIs and tools as in AWS Regions AWS Outposts: Bringing AWS on-premises
assembled, ready to be rolled into final position • Installed by AWS, simply plugged into power and network • Centralized redundant power conversion unit and DC distribution system for higher reliability, energy efficiency, easier serviceability • Redundant active components including top of rack switches and hot spare hosts Dimensions • 24” Wide • 48” Deep • 80” Tall
leverage existing skills, automation, and governance policies For customers running VMware SDDC on-premises AWS APIs, services, and features as in the AWS cloud EC2 and EBS with support for services including RDS, ECS, EKS, EMR, ALB, others Native AWS VMware Cloud on AWS
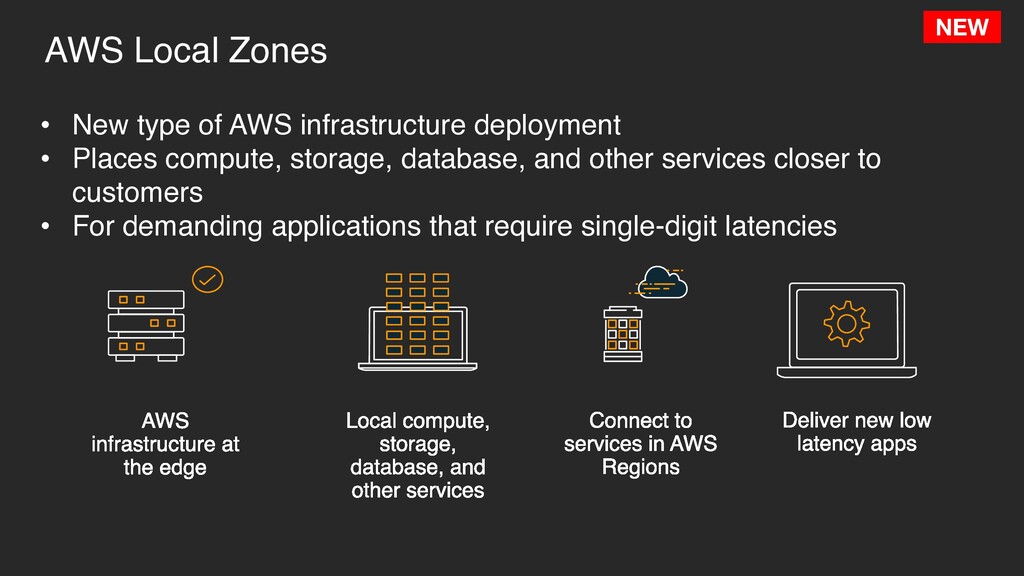
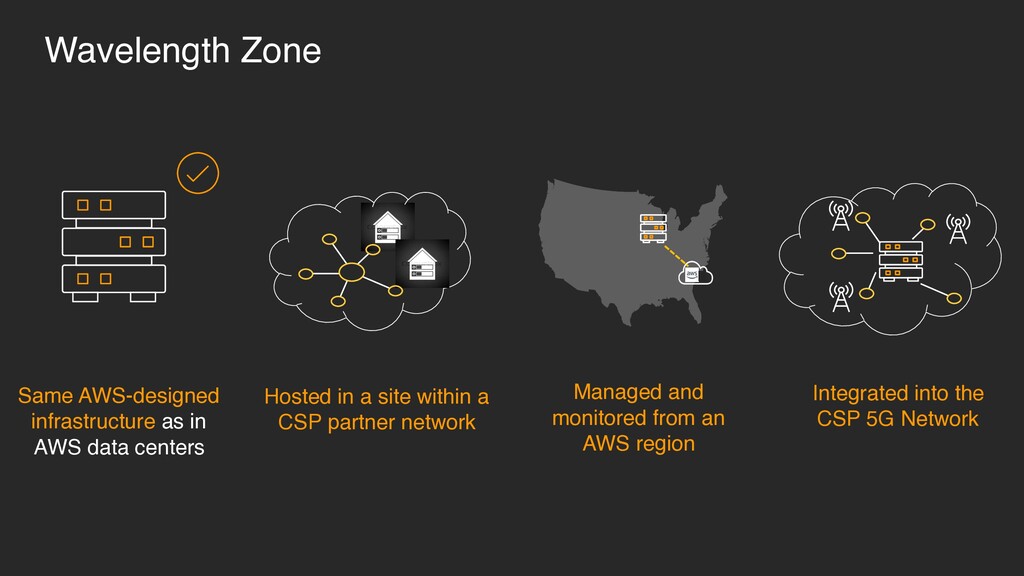
• Places compute, storage, database, and other services closer to customers • For demanding applications that require single-digit latencies AWS infrastructure at the edge Local compute, storage, database, and other services Connect to services in AWS Regions Deliver new low latency apps NEW
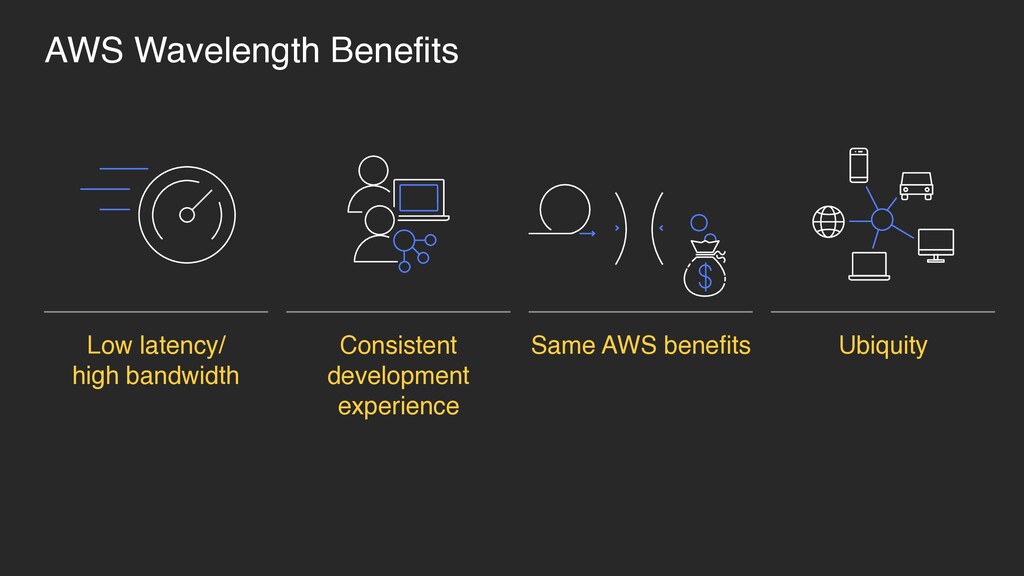
Run latency-sensitive portions of applications in “Wavelength Zones,” and seamlessly connect to the rest of your applications and the full breadth of services in AWS • Same AWS APIs, tools, and functionality • Global partner network NEW
and securely process highly sensitive data such as personally identifiable information (PII), healthcare, financial, and intellectual property data within their Amazon EC2 instances. Nitro Enclaves uses the same Nitro Hypervisor technology that provides CPU and memory isolation for EC2 instances. Enclaves are virtual machines attached to EC2 instances that come with no persistent storage, no administrator or operator access, and only secure local connectivity to customers EC2 instance. NEW
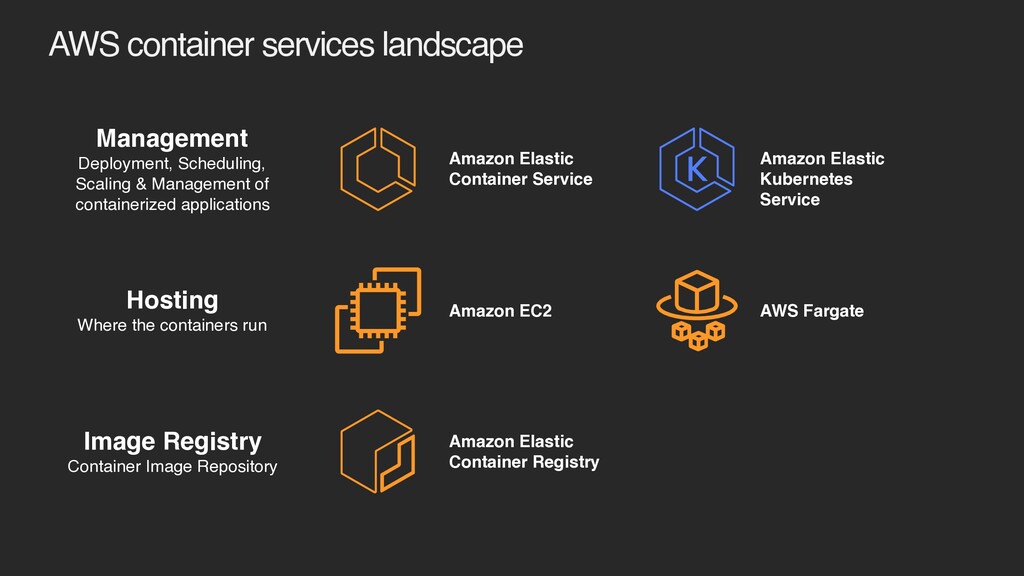
of containerized applications Hosting Where the containers run Amazon Elastic Container Service Amazon Elastic Kubernetes Service Amazon EC2 AWS Fargate Image Registry Container Image Repository Amazon Elastic Container Registry
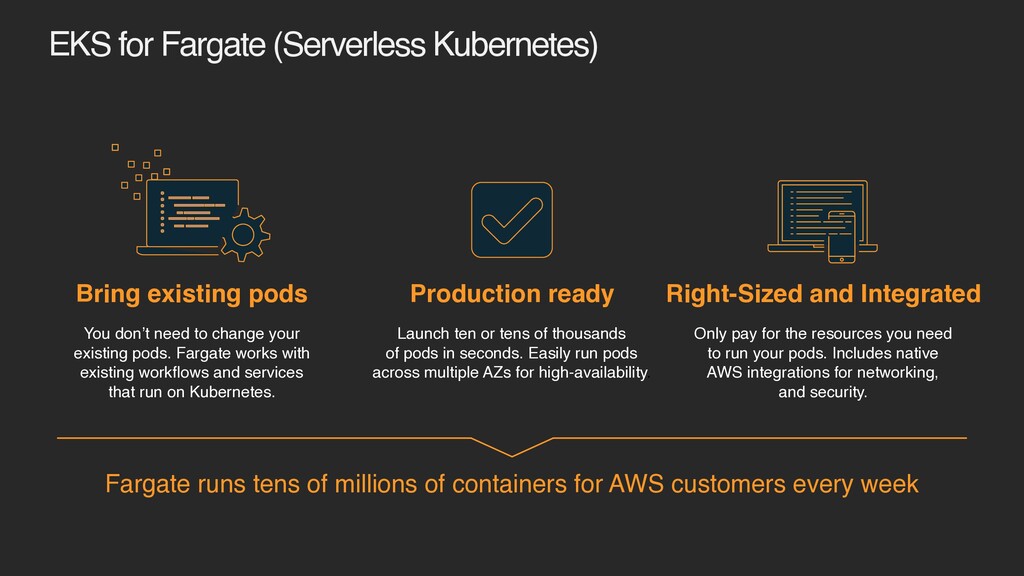
manage Elastic Scale up & down seamlessly. Pay only for what you use Integrated with the AWS ecosystem: VPC Networking, Elastic Load Balancing, IAM Permissions, CloudWatch and more. Run Kubernetes pods or ECS tasks. AWS Fargate
Right-Sized and Integrated You don’t need to change your existing pods. Fargate works with existing workflows and services that run on Kubernetes. Launch ten or tens of thousands of pods in seconds. Easily run pods across multiple AZs for high-availability. Only pay for the resources you need to run your pods. Includes native AWS integrations for networking, and security. Fargate runs tens of millions of containers for AWS customers every week
and hyper-ready to respond in double-digit milliseconds. Customers fully control when or how long to enable Provisioned Concurrency. Taking advantage of Provisioned Concurrency requires no changes to your code.. Serverless LEARN MORE CON213-L: Leadership session: Using containers and serverless to accelerate modern application development. Wednesday, 9:15am Ideal for latency-sensitive applications You fully control when to enable it No changes required to your code Fully serverless PREVIEW NEW
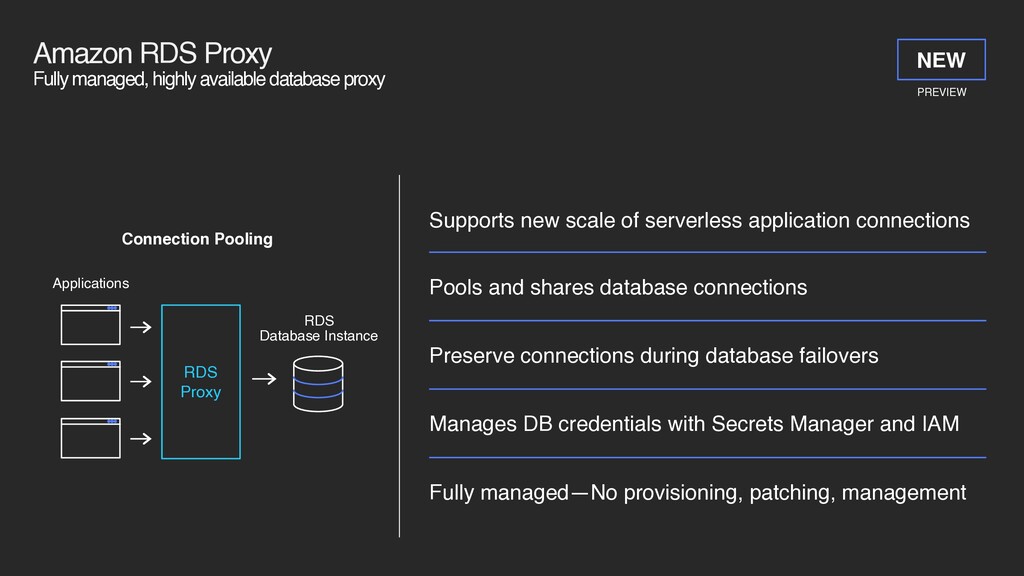
Supports new scale of serverless application connections Pools and shares database connections Preserve connections during database failovers Manages DB credentials with Secrets Manager and IAM Fully managed—No provisioning, patching, management RDS Proxy Applications RDS Database Instance Connection Pooling PREVIEW NEW
to REST APIs HTTP APIs are optimized for building APIs that proxy to AWS Lambda functions or HTTP backends, making them ideal for serverless workloads. • Significantly faster Up to 50% latency reduction. HTTP APIs only support API proxy functionality. For customers who want API proxy functionality and API management features in a single solution, they can use REST APIs from Amazon API Gateway. Serverless PREVIEW NEW https://aws.amazon.com/tr/blogs/compute/announcing-http-apis-for-amazon-api-gateway/
and more teams write custom events, there is more effort required to find events and their structure as well as to write code to react to those events. What? The Amazon EventBridge schema registry stores event structure - or schema - in a shared central location and maps those schema to code for Java, Python, and Typescript so it’s easy to use events as objects in their code. How? Schema from their event bus can be automatically added to the registry through the schema discovery feature. Customers can connect to and interact with schema registry from the AWS console, APIs, or through the SDK Toolkits for Jetbrains (Intellij, PyCharm, Webstorm, Rider) and VS Code. Serverless PREVIEW NEW
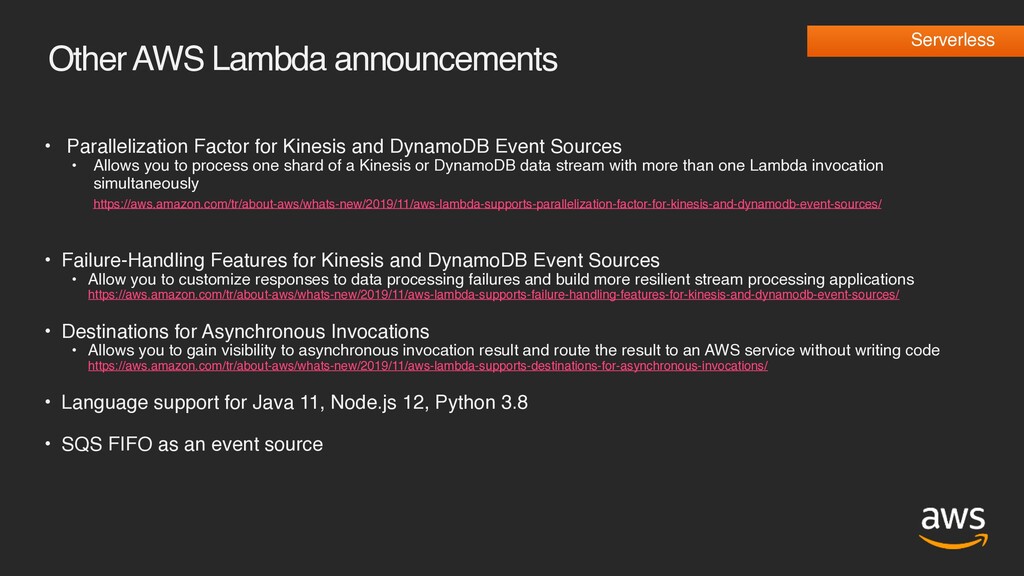
DynamoDB Event Sources • Allows you to process one shard of a Kinesis or DynamoDB data stream with more than one Lambda invocation simultaneously https://aws.amazon.com/tr/about-aws/whats-new/2019/11/aws-lambda-supports-parallelization-factor-for-kinesis-and-dynamodb-event-sources/ • Failure-Handling Features for Kinesis and DynamoDB Event Sources • Allow you to customize responses to data processing failures and build more resilient stream processing applications https://aws.amazon.com/tr/about-aws/whats-new/2019/11/aws-lambda-supports-failure-handling-features-for-kinesis-and-dynamodb-event-sources/ • Destinations for Asynchronous Invocations • Allows you to gain visibility to asynchronous invocation result and route the result to an AWS service without writing code https://aws.amazon.com/tr/about-aws/whats-new/2019/11/aws-lambda-supports-destinations-for-asynchronous-invocations/ • Language support for Java 11, Node.js 12, Python 3.8 • SQS FIFO as an event source Serverless
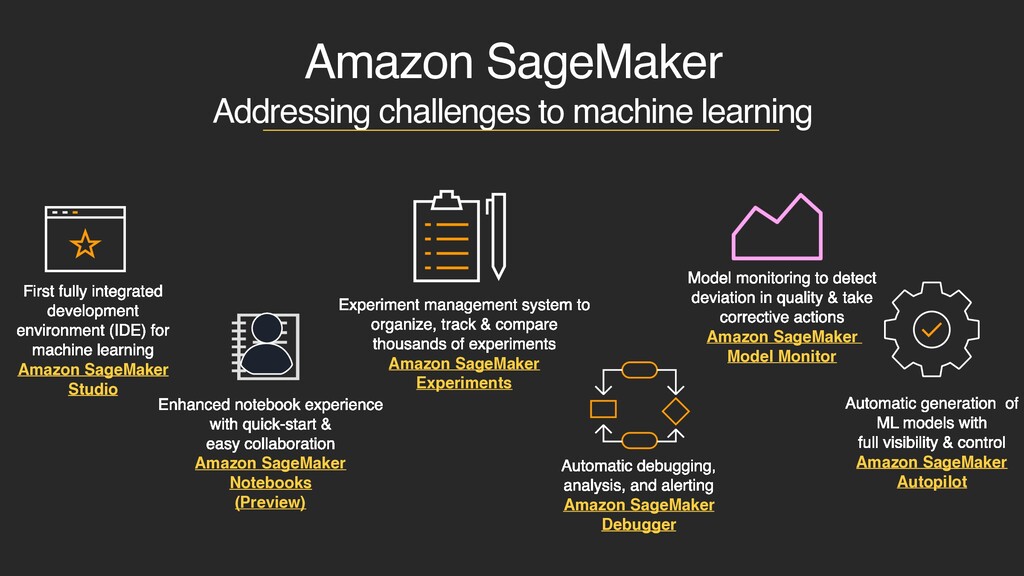
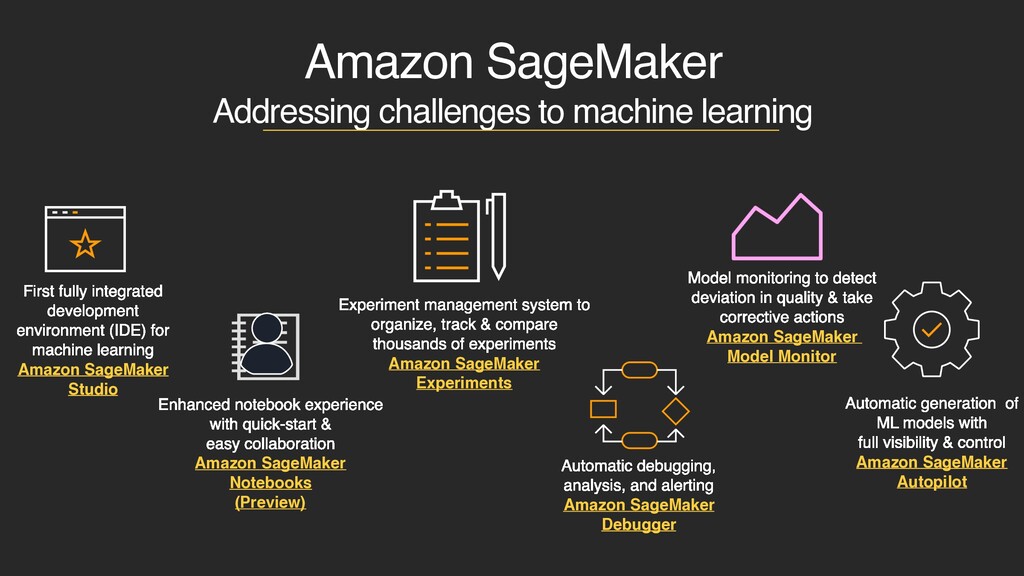
development environment (IDE) for machine learning Amazon SageMaker Studio Enhanced notebook experience with quick-start & easy collaboration Amazon SageMaker Notebooks (Preview) Automatic debugging, analysis, and alerting Amazon SageMaker Debugger Experiment management system to organize, track & compare thousands of experiments Amazon SageMaker Experiments Model monitoring to detect deviation in quality & take corrective actions Amazon SageMaker Model Monitor Automatic generation of ML models with full visibility & control Amazon SageMaker Autopilot
of iterations Multiple tools needed for different phases of the ML workflow Lack of an integrated experience Large number of iterations Cumbersome, lengthy processes, resulting in loss of productivity + + =
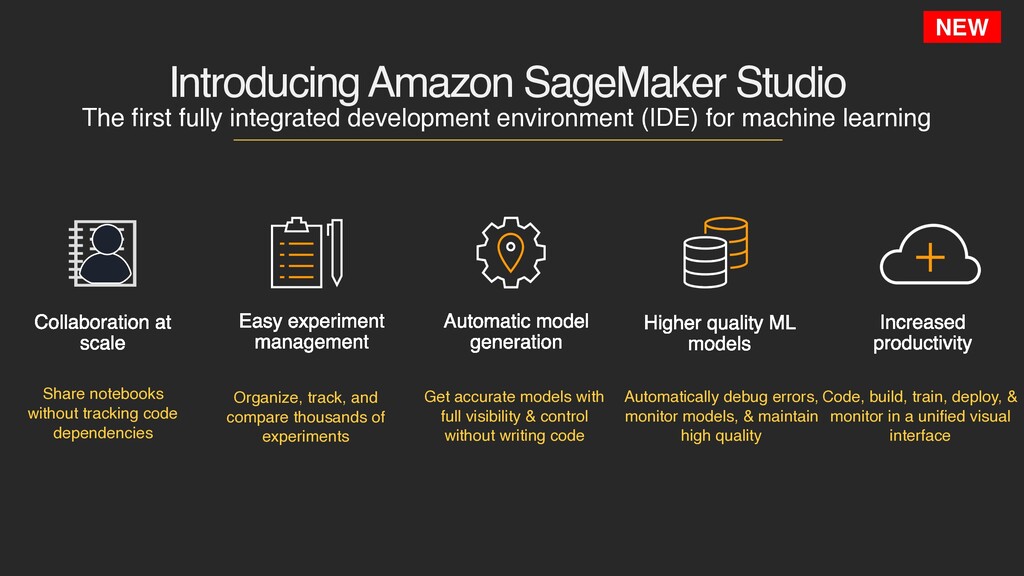
(IDE) for machine learning NEW Organize, track, and compare thousands of experiments Easy experiment management Share notebooks without tracking code dependencies Collaboration at scale Get accurate models with full visibility & control without writing code Automatic model generation Automatically debug errors, monitor models, & maintain high quality Higher quality ML models Code, build, train, deploy, & monitor in a unified visual interface Increased productivity
manage resources Collaboration across multiple data scientists Different data science projects have different resource needs Managing notebooks and collaborating across multiple data scientists is highly complicated + + =
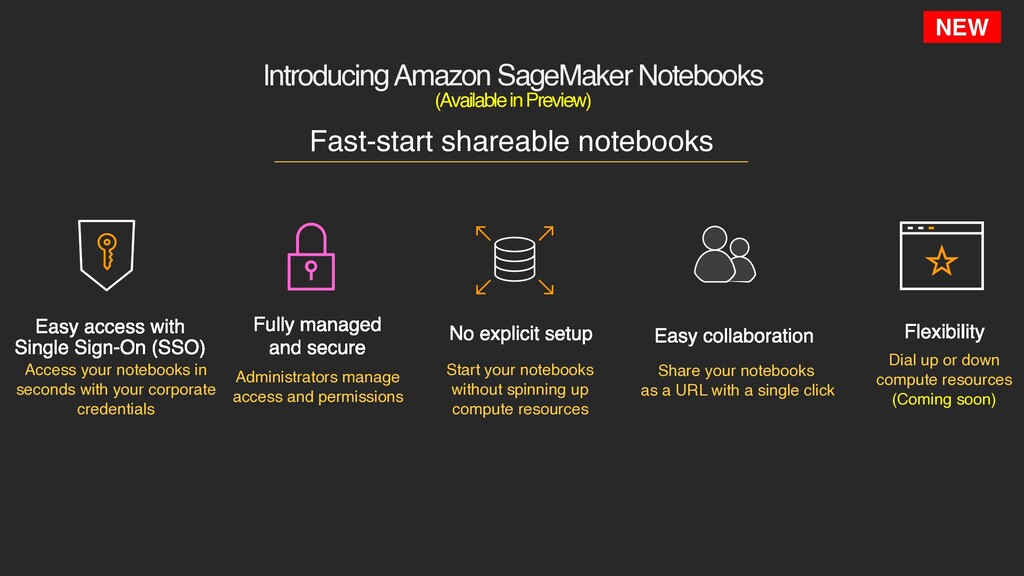
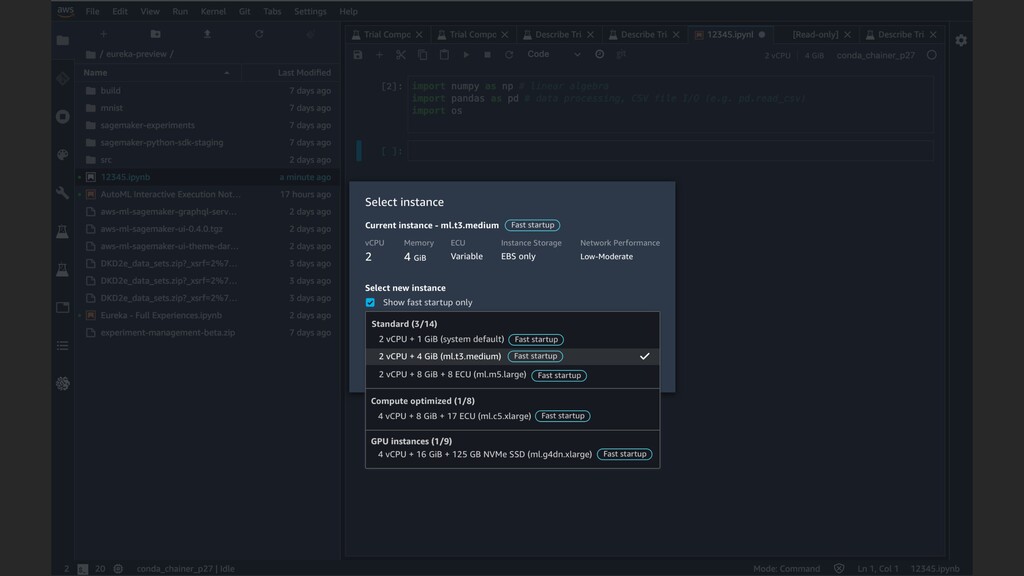
your notebooks in seconds with your corporate credentials Fast-start shareable notebooks Administrators manage access and permissions Fully managed and secure Share your notebooks as a URL with a single click Easy collaboration Dial up or down compute resources (Coming soon) Flexibility Easy access with Single Sign-On (SSO) Start your notebooks without spinning up compute resources No explicit setup
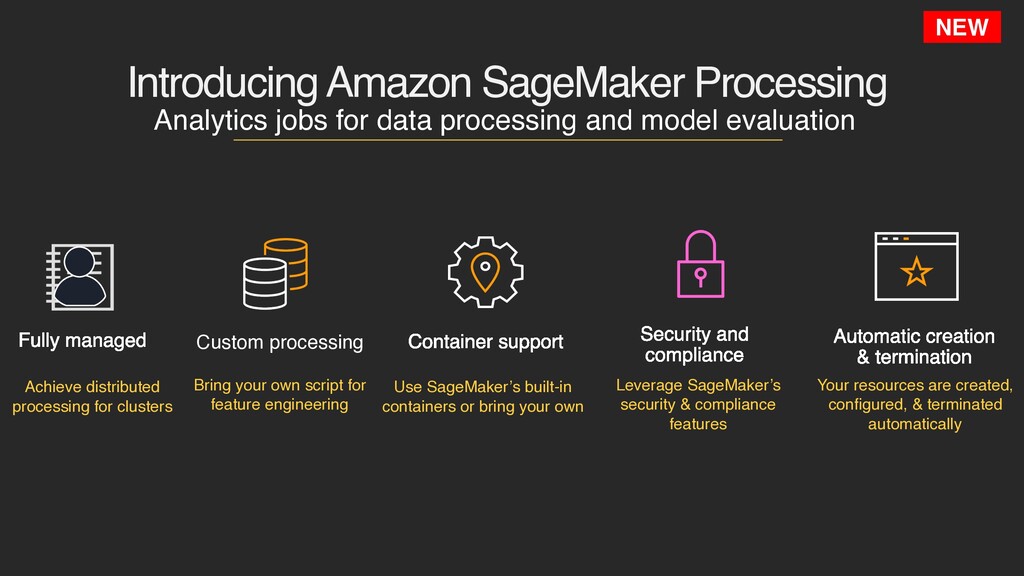
overhead Building and scaling infrastructure for data processing workloads is complex Use of multiple tools or services implies learning and implementing new APIs All steps in the ML workflow need enhanced security, authentication and compliance Need to build and manage tooling to run large data processing and model evaluation workloads + + =
and model evaluation Use SageMaker’s built-in containers or bring your own Bring your own script for feature engineering Custom processing Achieve distributed processing for clusters Fully managed Your resources are created, configured, & terminated automatically Automatic creation & termination Leverage SageMaker’s security & compliance features Security and compliance Container support
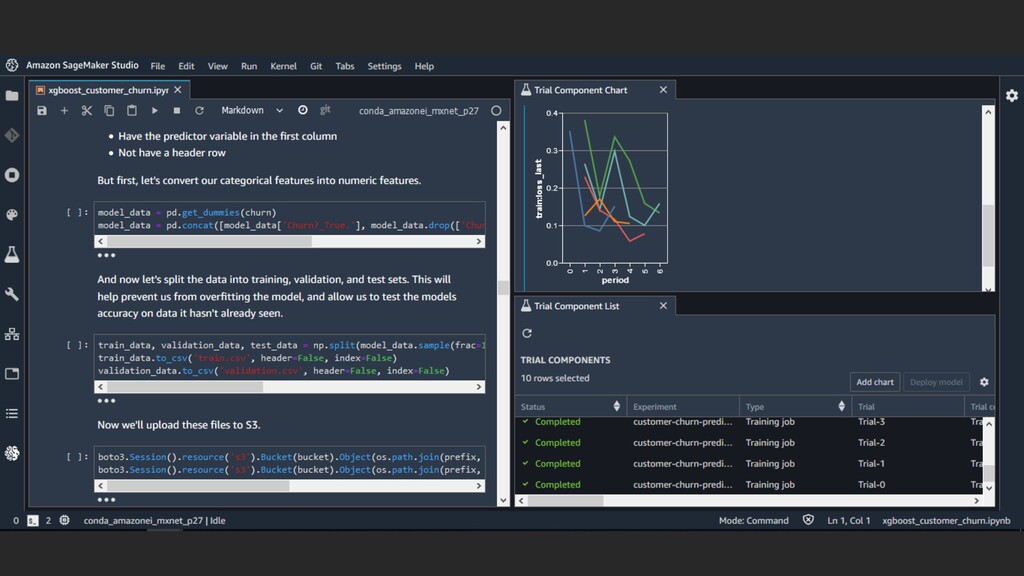
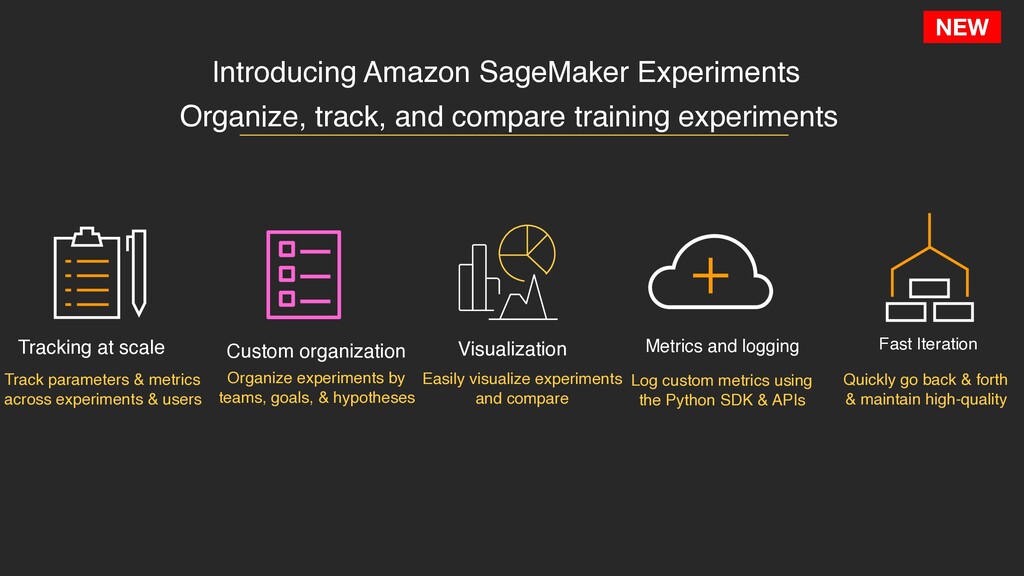
experiments Tracking at scale Visualization Metrics and logging Fast Iteration Track parameters & metrics across experiments & users Custom organization Organize experiments by teams, goals, & hypotheses Easily visualize experiments and compare Log custom metrics using the Python SDK & APIs Quickly go back & forth & maintain high-quality
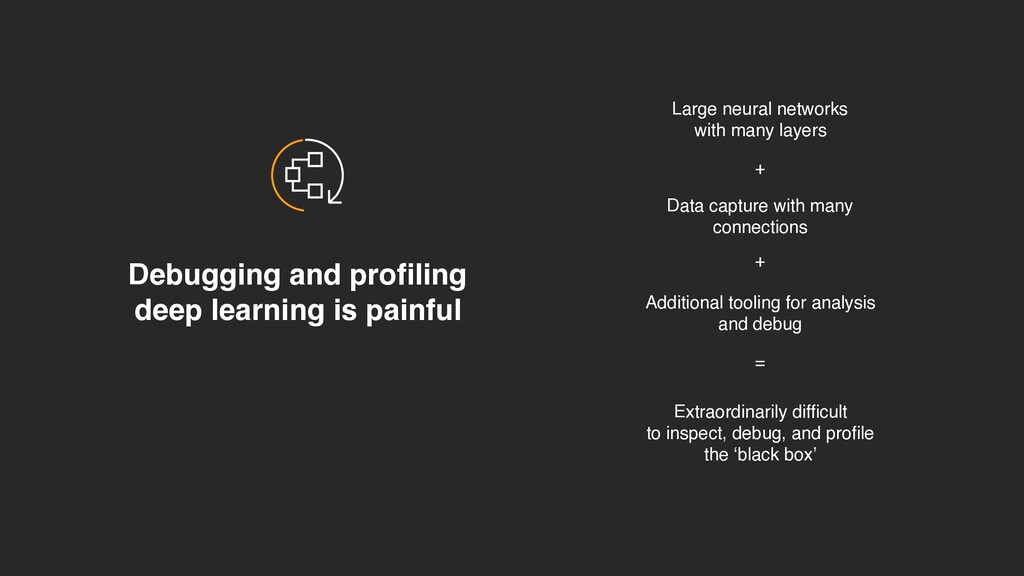
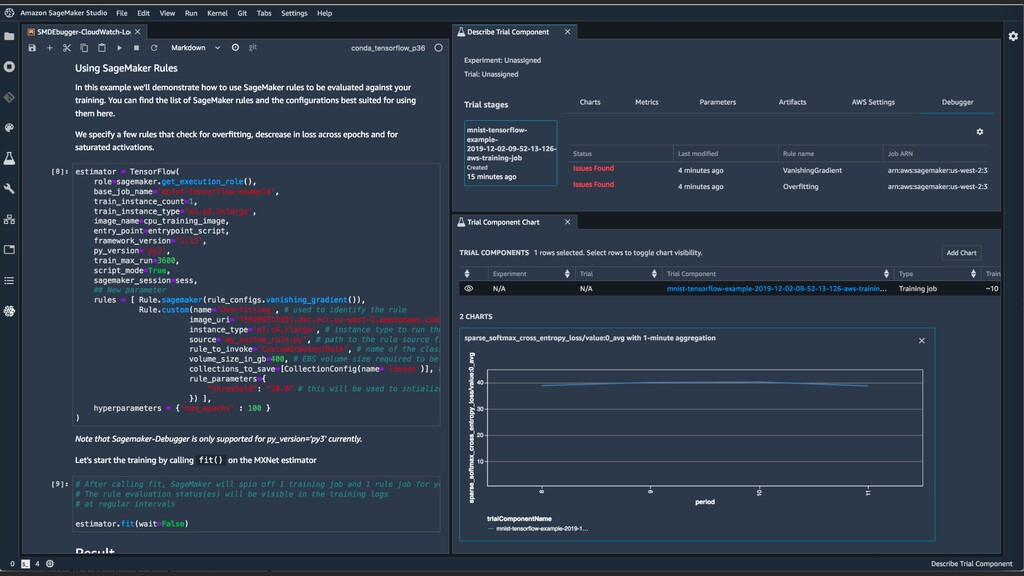
with many layers Data capture with many connections Additional tooling for analysis and debug Extraordinarily difficult to inspect, debug, and profile the ‘black box’ + + =
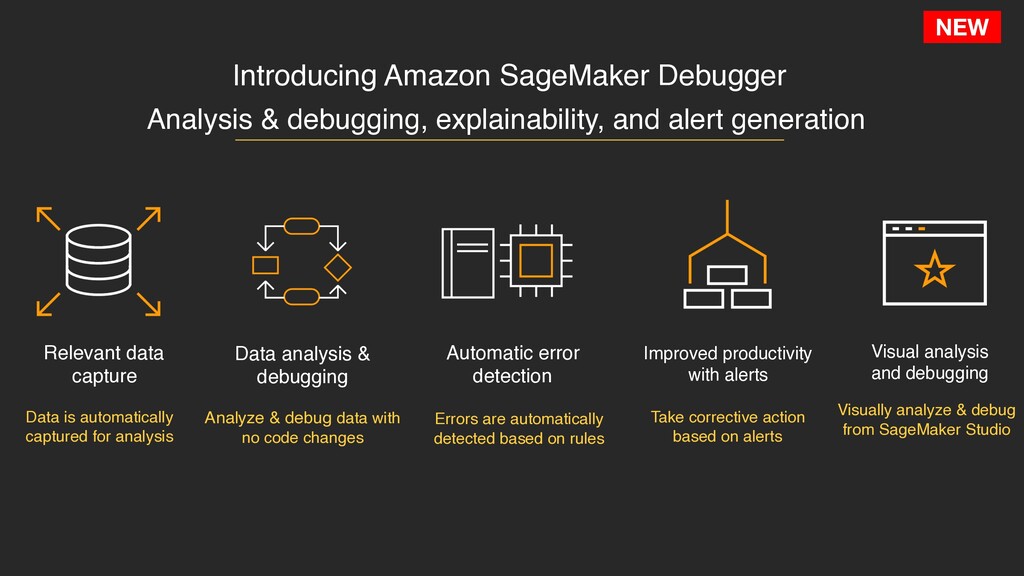
data capture Automatic error detection Improved productivity with alerts Visual analysis and debugging Analyze & debug data with no code changes Data is automatically captured for analysis Errors are automatically detected based on rules Take corrective action based on alerts Visually analyze & debug from SageMaker Studio Analysis & debugging, explainability, and alert generation
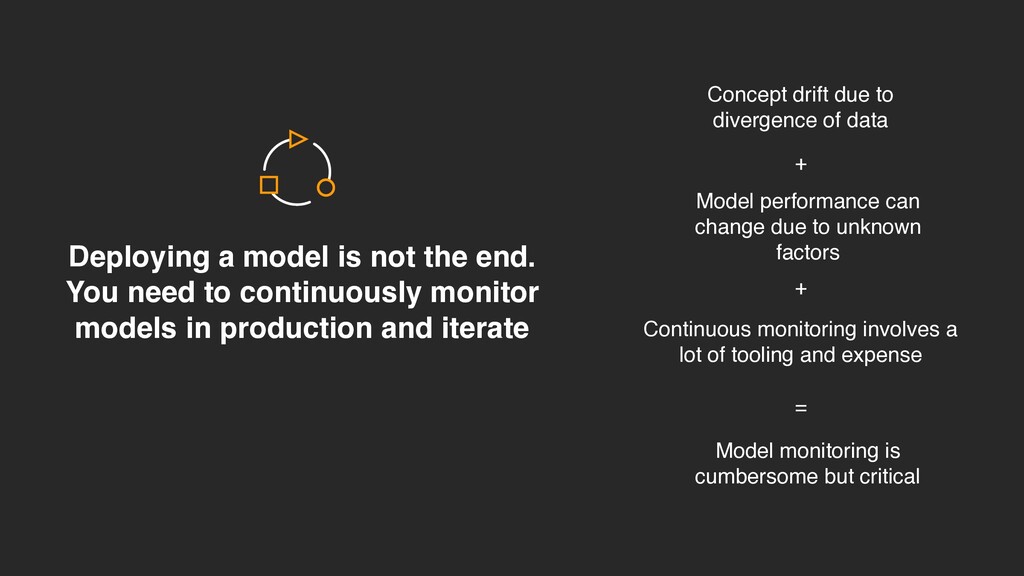
continuously monitor models in production and iterate Concept drift due to divergence of data Model performance can change due to unknown factors Continuous monitoring involves a lot of tooling and expense Model monitoring is cumbersome but critical + + =
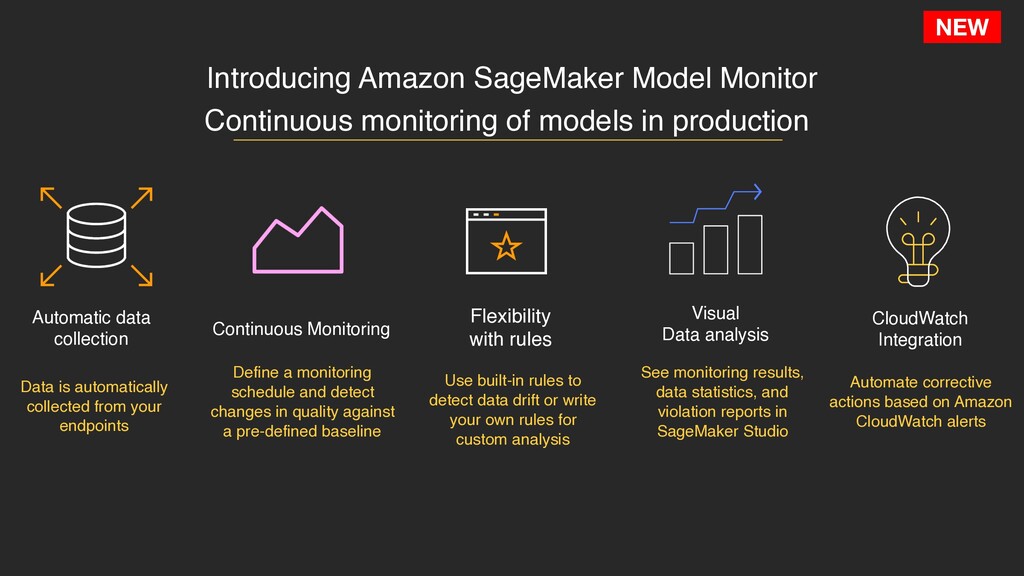
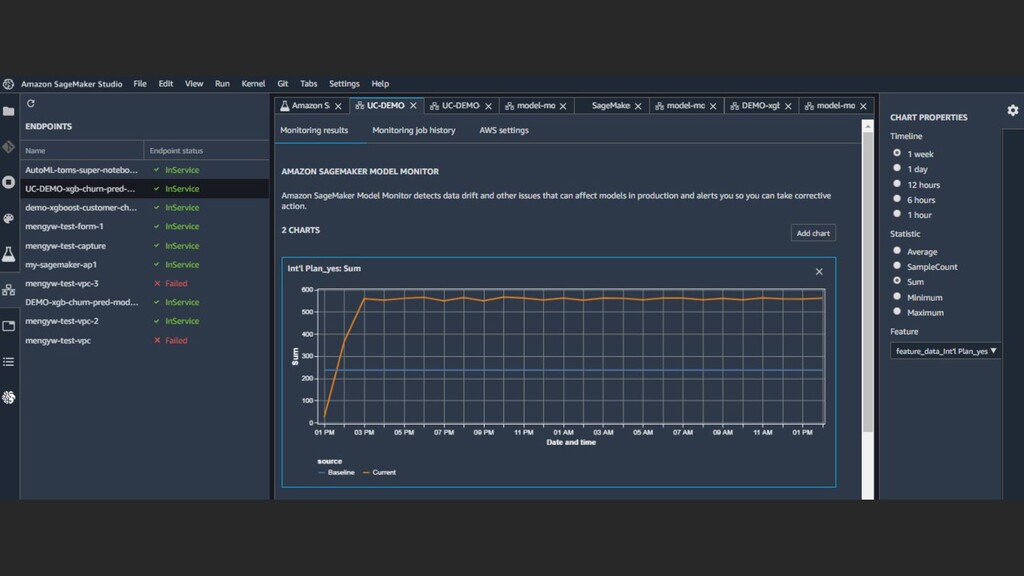
Monitoring CloudWatch Integration Data is automatically collected from your endpoints Automate corrective actions based on Amazon CloudWatch alerts Continuous monitoring of models in production Visual Data analysis Define a monitoring schedule and detect changes in quality against a pre-defined baseline See monitoring results, data statistics, and violation reports in SageMaker Studio Flexibility with rules Use built-in rules to detect data drift or write your own rules for custom analysis
& iterative Requires broad and complete knowledge of ML domain Lack of visibility Time consuming, error prone process, even for ML experts + + = of algorithms, data, parameters
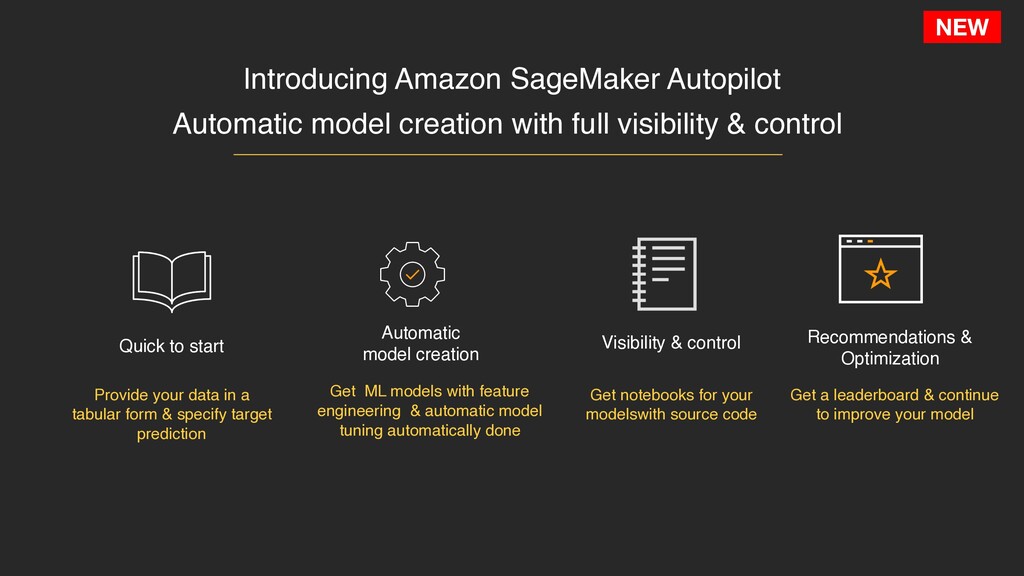
data in a tabular form & specify target prediction Automatic model creation Get ML models with feature engineering & automatic model tuning automatically done Visibility & control Get notebooks for your modelswith source code Automatic model creation with full visibility & control Recommendations & Optimization Get a leaderboard & continue to improve your model
development environment (IDE) for machine learning Amazon SageMaker Studio Enhanced notebook experience with quick-start & easy collaboration Amazon SageMaker Notebooks (Preview) Automatic debugging, analysis, and alerting Amazon SageMaker Debugger Experiment management system to organize, track & compare thousands of experiments Amazon SageMaker Experiments Model monitoring to detect deviation in quality & take corrective actions Amazon SageMaker Model Monitor Automatic generation of ML models with full visibility & control Amazon SageMaker Autopilot
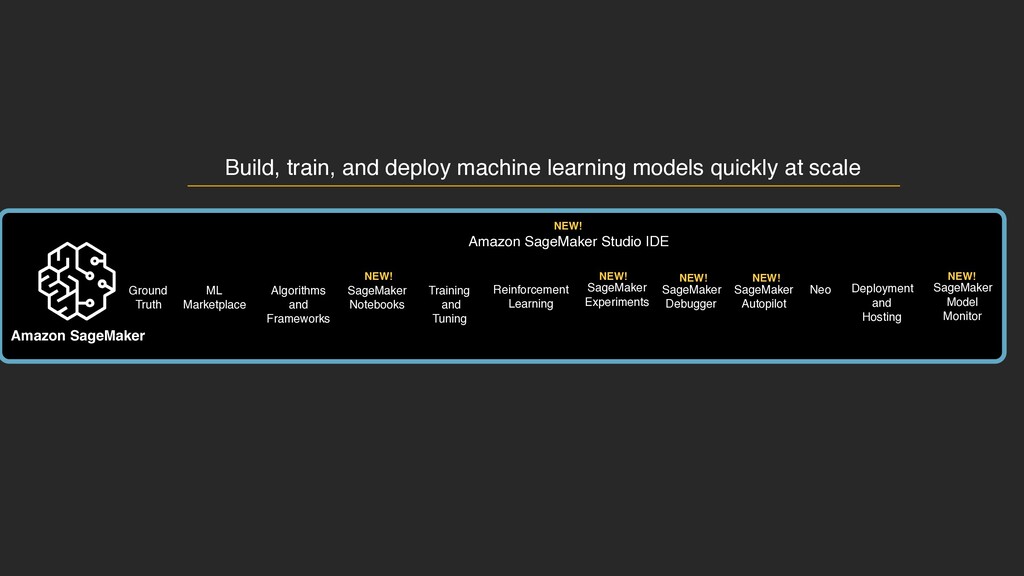
Amazon SageMaker Studio IDE Amazon SageMaker Ground Truth Algorithms and Frameworks SageMaker Notebooks SageMaker Experiments Training and Tuning Deployment and Hosting Reinforcement Learning ML Marketplace SageMaker Debugger SageMaker Autopilot SageMaker Model Monitor NEW! NEW! NEW! NEW! NEW! NEW! Neo
Build and manage services within Kubernetes cluster for ML Make disparate open-source libraries and frameworks work together in a secure and scalable way Requires time and expertise from infrastructure, data science, and development teams Need an easier way to use Kubernetes for ML + + =
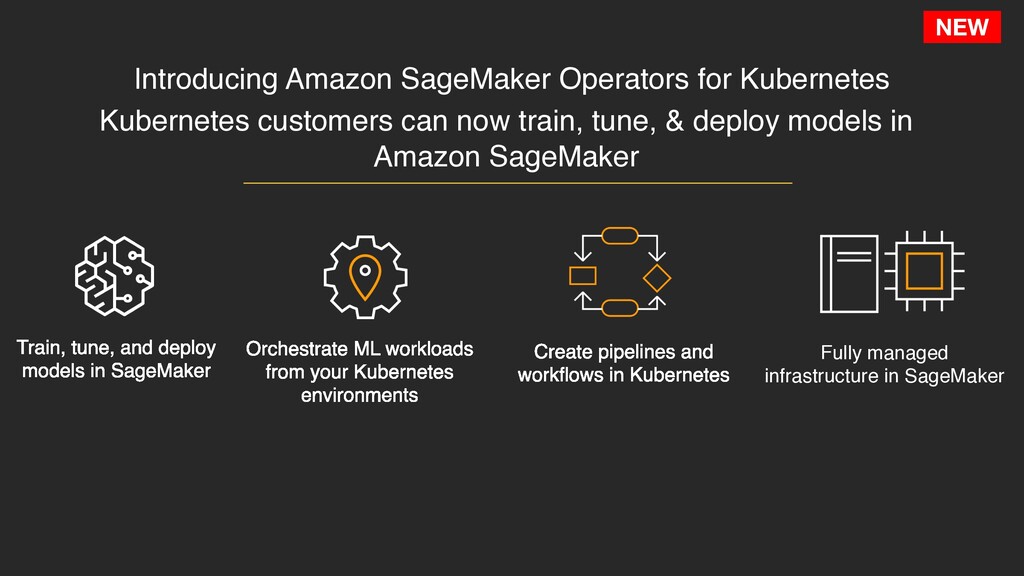
from your Kubernetes environments Create pipelines and workflows in Kubernetes Fully managed infrastructure in SageMaker Introducing Amazon SageMaker Operators for Kubernetes Kubernetes customers can now train, tune, & deploy models in Amazon SageMaker NEW
cost-effective Large number of per-user models or similar models Different access patterns for all models – some highly accessed, others infrequently accessed Need to have all models in production and available to serve inferences at low latency High deployment costs and challenges in managing scale + + =
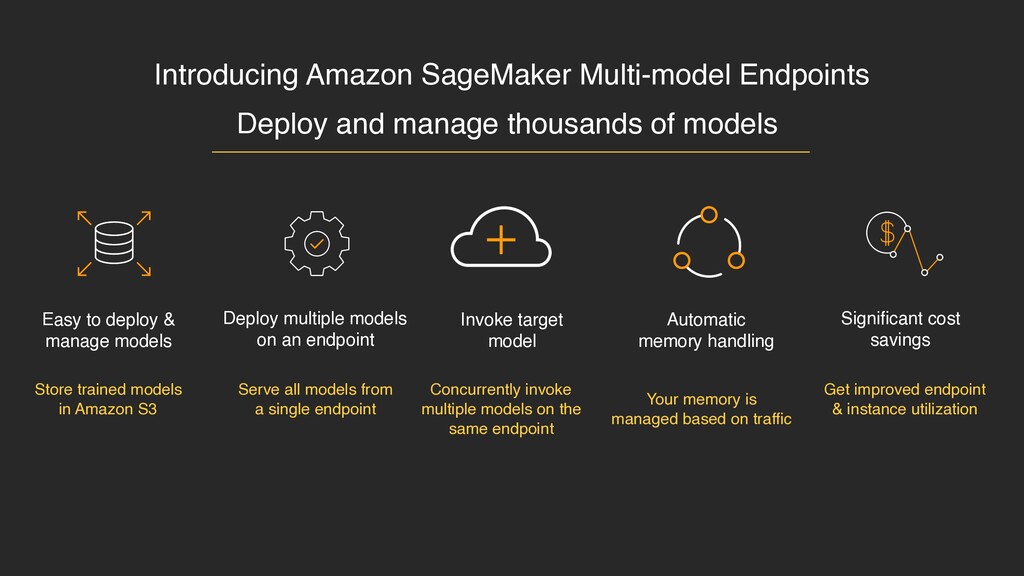
S3 Serve all models from a single endpoint Concurrently invoke multiple models on the same endpoint Your memory is managed based on traffic Get improved endpoint & instance utilization Deploy and manage thousands of models Easy to deploy & manage models Deploy multiple models on an endpoint Invoke target model Automatic memory handling Significant cost savings
last anywhere between few minutes to weeks Want to use EC2 Spot instances, but they can get interrupted ML model training needs to be unaffected by interruptions Need to build complex tooling to use Spot instances for Training ML Models + + =
in training costs Visualize your cost savings for each trainin job Save training costs compared to Amazon EC2 On-Demand instances Spot capacity is managed & interruptions are automatically handled Get support for built-in and your own algorithms & frameworks All SageMaker training capabilities No more interruptionsSupport for algorithms & frameworks Full visibility Take advantage of Automatic Model Tuning & Reinforcement Up to 90% savings
as online payment fraud and the creation of fake accounts PREVIEW NEW Step 1: Upload your historical fraud datasets to Amazon S3 Step 2: Select from pre-built fraud detection model templates Step 3: The model template uses your historical data as input to build a custom model. The model template inspects and enriches data, performs feature engineering, selects algorithms, trains and tunes your model, and hosts the model Step 4: Create rules to either accept, review, or collect more information based on model predictions Step 5: Call the Amazon Fraud Detector API from your online application to receive real-time fraud predictions and take action based on your configured detection rules.
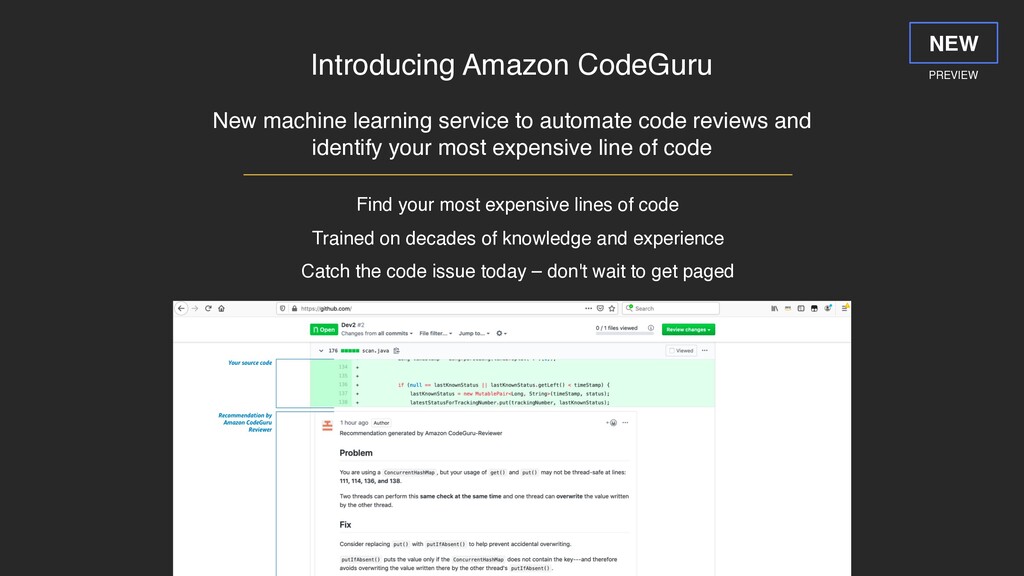
reviews and identify your most expensive line of code PREVIEW NEW Find your most expensive lines of code Trained on decades of knowledge and experience Catch the code issue today – don't wait to get paged
for shared data sets on Amazon S3. With S3 Access Points, you can easily create hundreds of access points per bucket, each with a name and permissions customized for the application. This represents a new way of provisioning access to shared data sets. GA NEW
comprehensive findings if your resource policies grant public or cross-account access Continuously identify resources with overly broad permissions across your entire AWS organization Resolve findings by updating policies to protect your resources from unintended access before it occurs, or archive findings for intended access Access Analyzer for S3
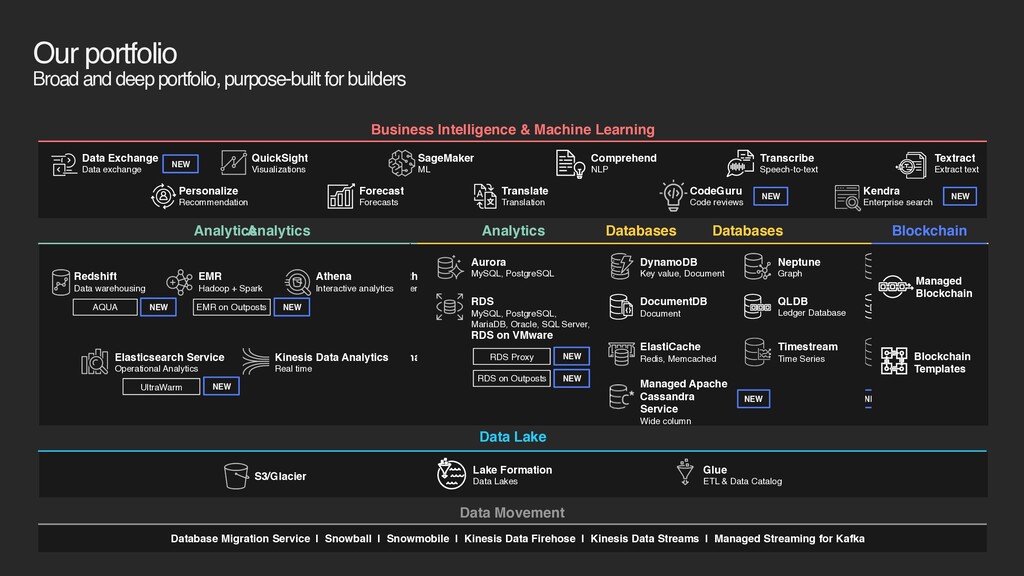
Glue ETL & Data Catalog Lake Formation Data Lakes Database Migration Service | Snowball | Snowmobile | Kinesis Data Firehose | Kinesis Data Streams | Managed Streaming for Kafka Data Movement Data Lake Analytics Redshift Data warehousing EMR Hadoop + Spark Kinesis Data Analytics Real time Elasticsearch Service Operational Analytics Athena Interactive analytics NEW NEW NEW AQUA EMR on Outposts UltraWarm Business Intelligence & Machine Learning Data Exchange Data exchange NEW QuickSight Visualizations SageMaker ML Comprehend NLP Transcribe Speech-to-text Textract Extract text Personalize Recommendation Forecast Forecasts Translate Translation CodeGuru Code reviews Kendra Enterprise search NEW NEW Analytics Redshift Data warehousing EMR Hadoop + Spark Kinesis Data Analytics Real time Elasticsearch Service Operational Analytics Athena Interactive analytics NEW NEW NEW AQUA EMR on Outposts UltraWarm Databases RDS MySQL, PostgreSQL, MariaDB, Oracle, SQL Server, RDS on VMware Aurora MySQL, PostgreSQL DynamoDB Key value, Document ElastiCache Redis, Memcached Neptune Graph Timestream Time Series QLDB Ledger Database Managed Apache Cassandra Service Wide column NEW DocumentDB Document NEW NEW RDS Proxy RDS on Outposts RDS MySQL, PostgreSQL, MariaDB, Oracle, SQL Server, RDS on VMware Aurora MySQL, PostgreSQL DynamoDB Key value, Document ElastiCache Redis, Memcached Neptune Graph Timestream Time Series QLDB Ledger Database Analytics Databases Managed Blockchain Blockchain Templates Blockchain Managed Apache Cassandra Service Wide column NEW DocumentDB Document Redshift Data warehousing EMR Hadoop + Spark Kinesis Data Analytics Real time Elasticsearch Service Operational Analytics Athena Interactive analytics NEW NEW NEW NEW NEW AQUA EMR on Outposts UltraWarm RDS Proxy RDS on Outposts
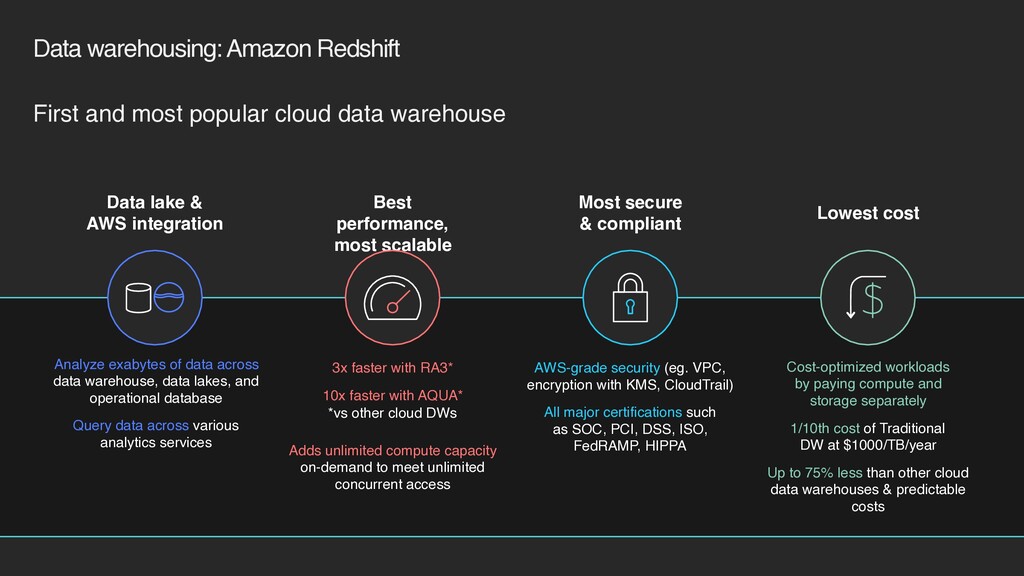
with RA3* 10x faster with AQUA* Adds unlimited compute capacity on-demand to meet unlimited concurrent access Lowest cost Cost-optimized workloads by paying compute and storage separately 1/10th cost of Traditional DW at $1000/TB/year Up to 75% less than other cloud data warehouses & predictable costs Data lake & AWS integration Analyze exabytes of data across data warehouse, data lakes, and operational database Query data across various analytics services Most secure & compliant AWS-grade security (eg. VPC, encryption with KMS, CloudTrail) All major certifications such as SOC, PCI, DSS, ISO, FedRAMP, HIPPA First and most popular cloud data warehouse *vs other cloud DWs
by paying for compute and storage separately Delivers 3x the performance of existing cloud DWs DS2 customers can migrate and get 2x performance and 2x storage for the same cost Automatically scales your DW storage capacity Supports workloads up to 8 PB (compressed) COMPUTE NODE (RA3) SSD Cache S 3 S TO R A G E COMPUTE NODE (RA3) SSD Cache COMPUTE NODE (RA3) SSD Cache COMPUTE NODE (RA3) SSD Cache Managed storage $/node/hour $/TB/month GA NEW
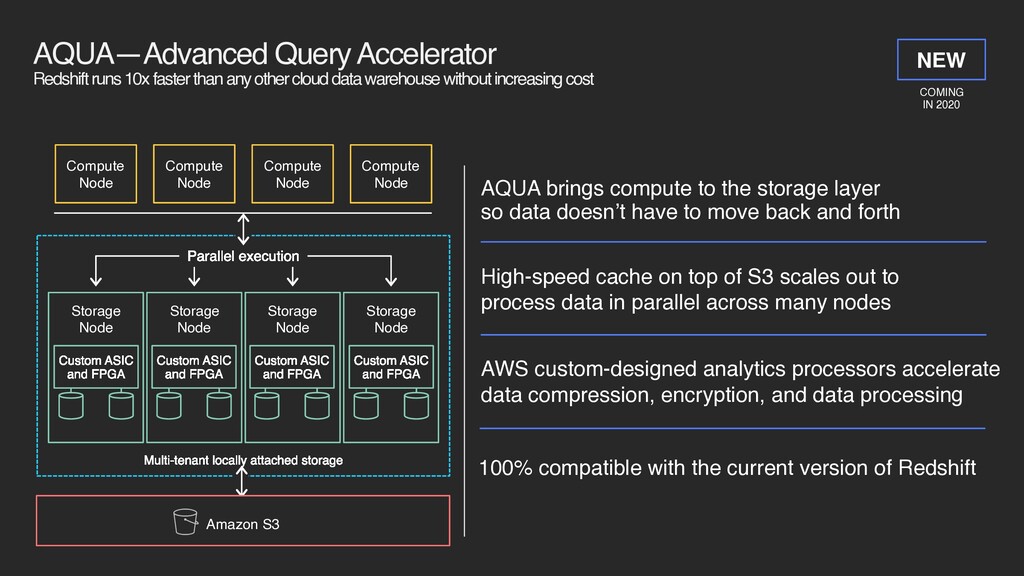
cloud data warehouse without increasing cost Compute Node Compute Node Compute Node Compute Node Parallel execution Storage Node Storage Node Storage Node Storage Node Multi-tenant locally attached storage Custom ASIC and FPGA Custom ASIC and FPGA Custom ASIC and FPGA Custom ASIC and FPGA 100% compatible with the current version of Redshift AQUA brings compute to the storage layer so data doesn’t have to move back and forth High-speed cache on top of S3 scales out to process data in parallel across many nodes AWS custom-designed analytics processors accelerate data compression, encryption, and data processing COMING IN 2020 NEW Amazon S3
more big data apps on AWS Low cost 50–80% reduction in costs with EC2 Spot and Reserved Instances Per-second billing for flexibility Use S3 storage Process data in S3 securely with high performance using the EMRFS connector Latest versions Updated with latest open source frameworks within 30 days Fully managed no cluster setup, node provisioning, cluster tuning Easy
for Apache Spark, 2.6x faster performance at 1/10th the cost *Based on TPC-DS 3 TB Benchmarking running 6 node C4x8 extra large clusters and EMR 5.28, Spark 2.4 Runtime total on 104 queries (seconds— lower is better) t runtime) r runtime) h runtime) 0 7.000 14.000 21.000 28.000 10164 16478 26478 Runtime optimized for Apache Spark performance 100% compliant with Apache Spark APIs Best performance 2.6x faster than Spark with EMR without runtime 1.6x faster than 3rd party Managed Spark (with their runtime) Lowest price 1/10th the cost of 3rd party Managed Spark (with their runtime) NEW
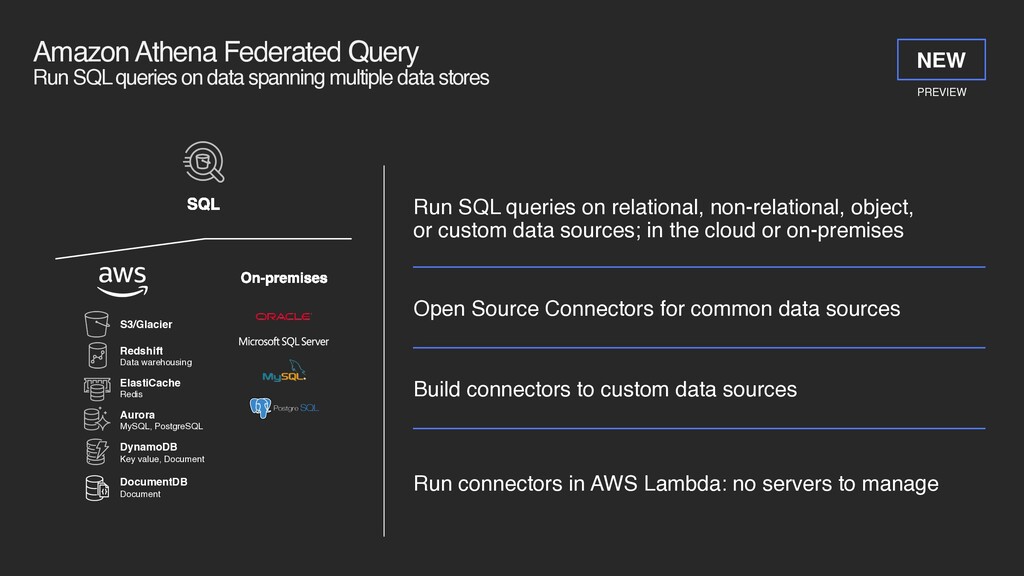
multiple data stores Redshift Data warehousing ElastiCache Redis Aurora MySQL, PostgreSQL DynamoDB Key value, Document DocumentDB Document On-premises SQL S3/Glacier Run connectors in AWS Lambda: no servers to manage Run SQL queries on relational, non-relational, object, or custom data sources; in the cloud or on-premises Open Source Connectors for common data sources Build connectors to custom data sources PREVIEW NEW
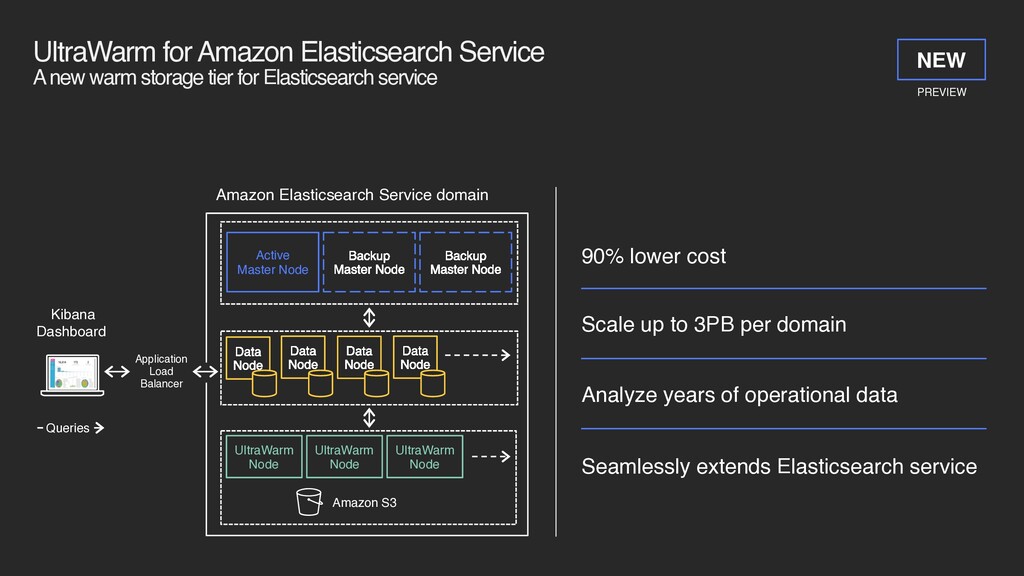
tier for Elasticsearch service Kibana Dashboard Amazon Elasticsearch Service domain Data Node Data Node Data Node Data Node Application Load Balancer Seamlessly extends Elasticsearch service 90% lower cost Scale up to 3PB per domain Analyze years of operational data Amazon S3 UltraWarm Node UltraWarm Node UltraWarm Node Active Master Node Backup Master Node Backup Master Node Queries PREVIEW NEW
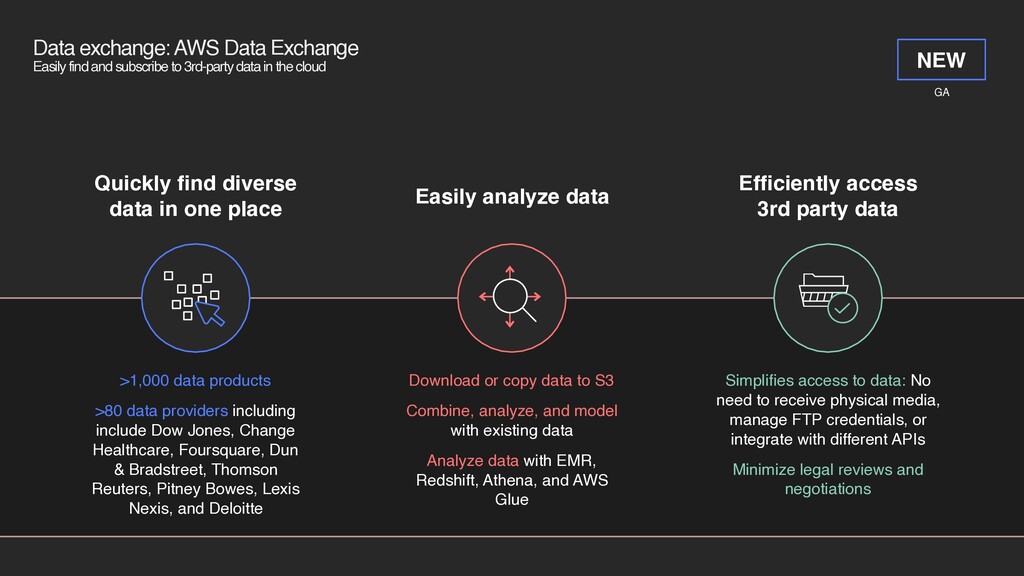
3rd-party data in the cloud Efficiently access 3rd party data Simplifies access to data: No need to receive physical media, manage FTP credentials, or integrate with different APIs Minimize legal reviews and negotiations Quickly find diverse data in one place >1,000 data products >80 data providers including include Dow Jones, Change Healthcare, Foursquare, Dun & Bradstreet, Thomson Reuters, Pitney Bowes, Lexis Nexis, and Deloitte Easily analyze data Download or copy data to S3 Combine, analyze, and model with existing data Analyze data with EMR, Redshift, Athena, and AWS Glue GA NEW
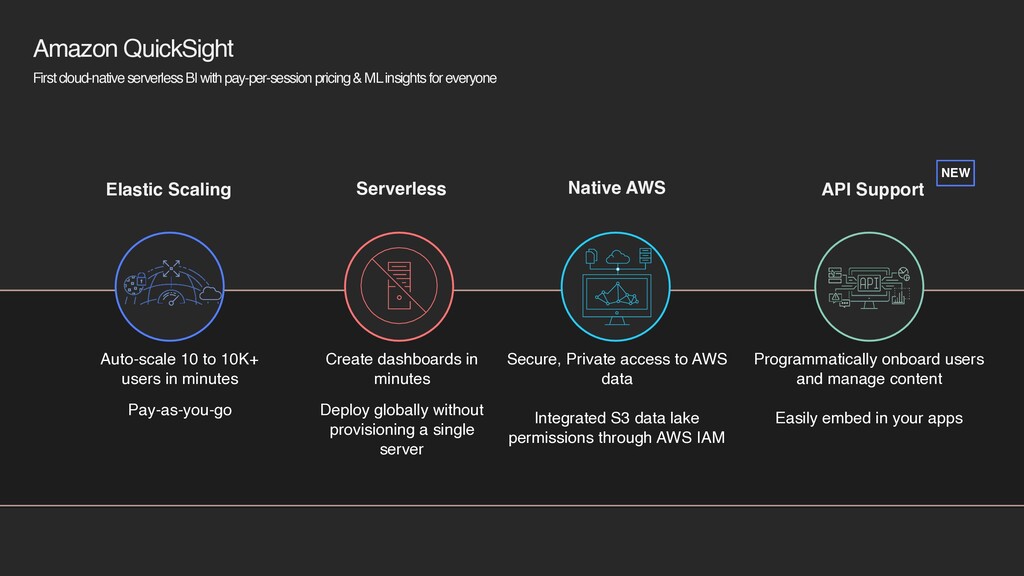
& ML insights for everyone Elastic Scaling Auto-scale 10 to 10K+ users in minutes Pay-as-you-go Serverless Create dashboards in minutes Deploy globally without provisioning a single server Native AWS Secure, Private access to AWS data Integrated S3 data lake permissions through AWS IAM API Support Programmatically onboard users and manage content Easily embed in your apps NEW
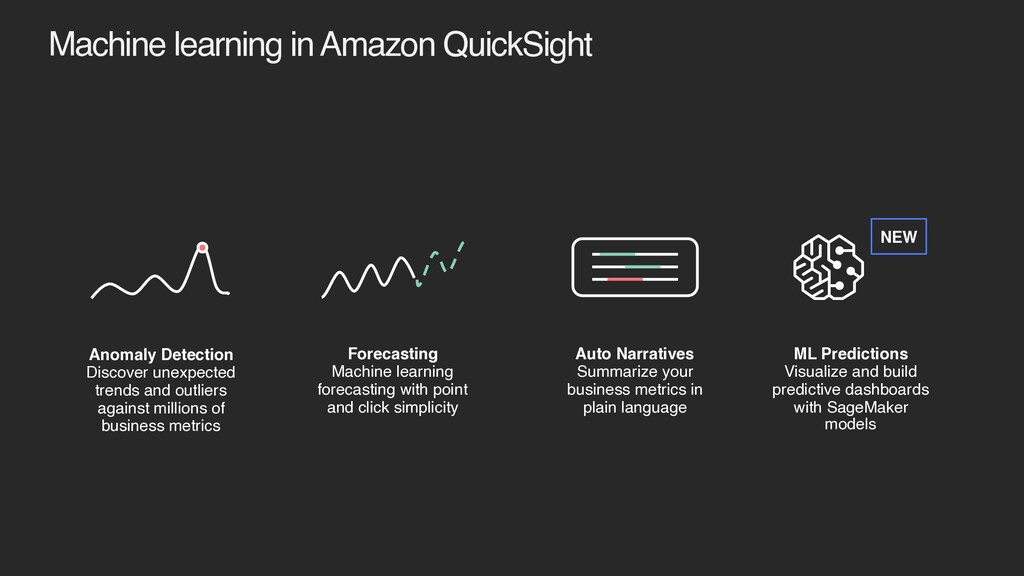
and outliers against millions of business metrics Forecasting Machine learning forecasting with point and click simplicity ML Predictions Visualize and build predictive dashboards with SageMaker models Auto Narratives Summarize your business metrics in plain language NEW
QuickSight APIs and flexible customization. Entirely serverless. Deploy and manage dashboards + data via APIs Match your application UI with QuickSight Themes Embed dashboards in apps without servers • Fast, consistent performance • Pay-per-session Automatically scale to 10s of 1000s of users • No server management • No scripting NEW
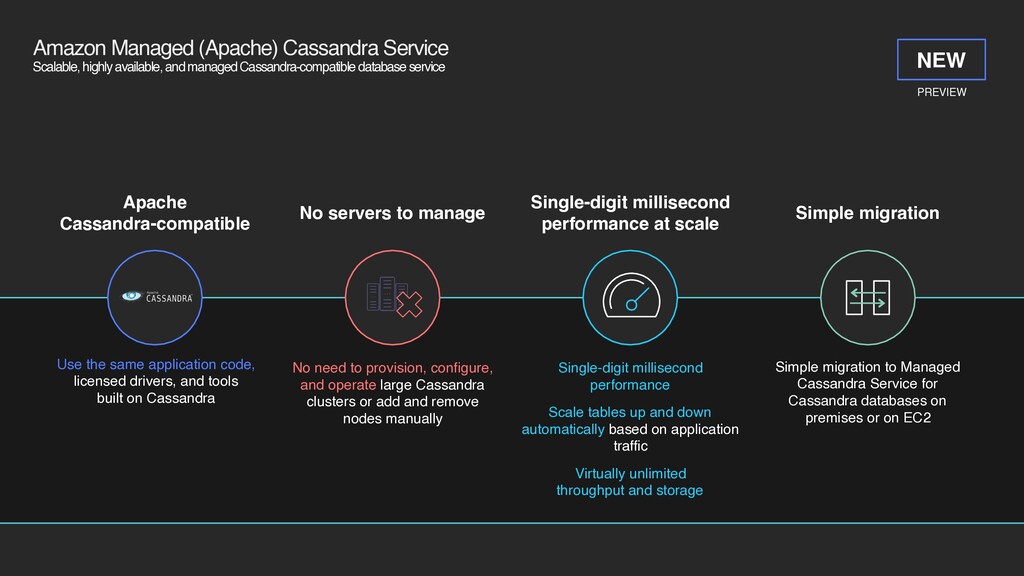
Cassandra-compatible database service No need to provision, configure, and operate large Cassandra clusters or add and remove nodes manually No servers to manage Single-digit millisecond performance Scale tables up and down automatically based on application traffic Virtually unlimited throughput and storage Single-digit millisecond performance at scale Apache Cassandra-compatible Use the same application code, licensed drivers, and tools built on Cassandra Simple migration Simple migration to Managed Cassandra Service for Cassandra databases on premises or on EC2 PREVIEW NEW
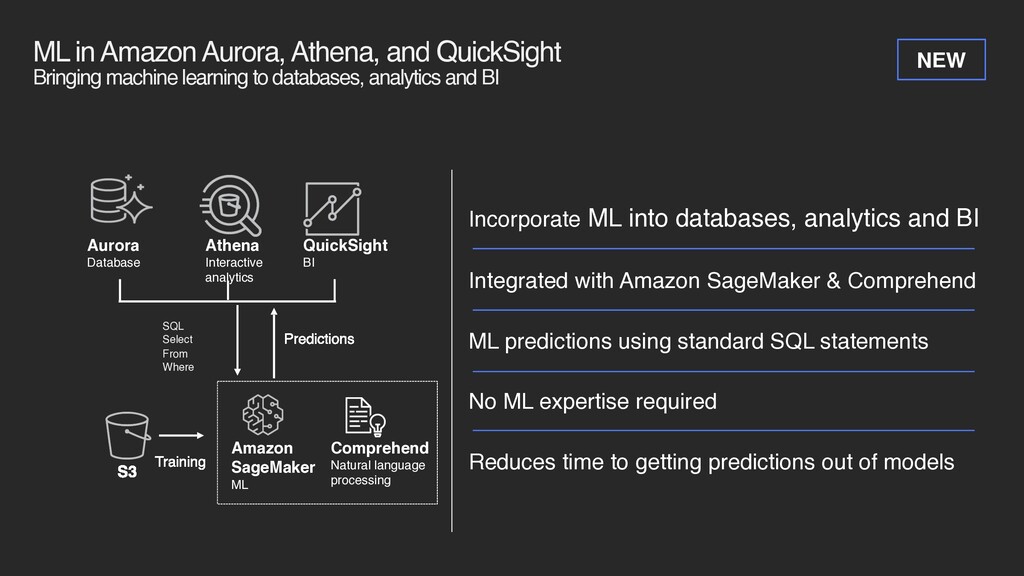
to databases, analytics and BI Incorporate ML into databases, analytics and BI Integrated with Amazon SageMaker & Comprehend ML predictions using standard SQL statements No ML expertise required Reduces time to getting predictions out of models S3 Comprehend Natural language processing Amazon SageMaker ML Aurora Database Athena Interactive analytics QuickSight BI Training SQL Select From Where Predictions NEW
live media with ultra-low latency and enable two-way interactivity for millions of camera devices Standards Compliant Exchange audio, video, and data between devices, mobile, and web apps for real-time two-way interactivity Fully Managed Fully managed WebRTC signaling, TURN, and STUN services with easy to use SDKs Real-time, Two-way Interactivity Compliant with web and mobile platforms for easy plug-in free playback Low Latency Live Media Streaming Peer-to-peer audio and video live streaming with sub-1 second latency for playback N E W !
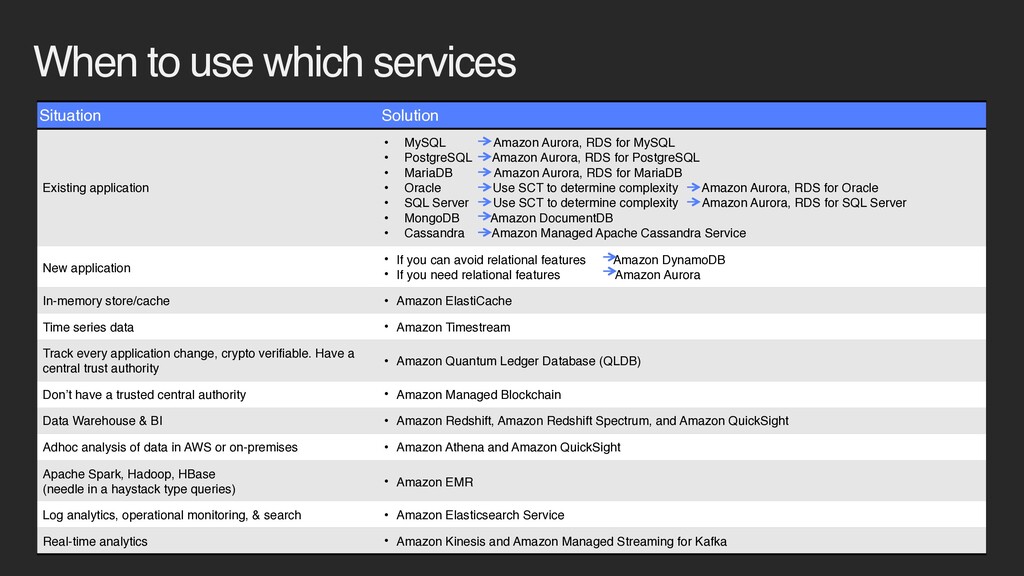
MySQL Amazon Aurora, RDS for MySQL • PostgreSQL Amazon Aurora, RDS for PostgreSQL • MariaDB Amazon Aurora, RDS for MariaDB • Oracle Use SCT to determine complexity Amazon Aurora, RDS for Oracle • SQL Server Use SCT to determine complexity Amazon Aurora, RDS for SQL Server • MongoDB Amazon DocumentDB • Cassandra Amazon Managed Apache Cassandra Service New application • If you can avoid relational features Amazon DynamoDB • If you need relational features Amazon Aurora In-memory store/cache • Amazon ElastiCache Time series data • Amazon Timestream Track every application change, crypto verifiable. Have a central trust authority • Amazon Quantum Ledger Database (QLDB) Don’t have a trusted central authority • Amazon Managed Blockchain Data Warehouse & BI • Amazon Redshift, Amazon Redshift Spectrum, and Amazon QuickSight Adhoc analysis of data in AWS or on-premises • Amazon Athena and Amazon QuickSight Apache Spark, Hadoop, HBase (needle in a haystack type queries) • Amazon EMR Log analytics, operational monitoring, & search • Amazon Elasticsearch Service Real-time analytics • Amazon Kinesis and Amazon Managed Streaming for Kafka
findings if your resource policies grant public or cross-account access Continuously identify resources with overly broad permissions Resolve findings by updating policies to protect your resources from unintended access before it occurs, or archive findings for intended access AWS Identity and Access Management Access Analyzer NEW
adds host management capabilities to simplify your ‘Bring your own license’ (BYOL) experience for software licenses, such as Windows and SQL Server, that require a dedicated physical server. NEW https://aws.amazon.com/tr/about-aws/whats-new/2019/12/aws-license-manager-adds-dedicated-host-management-capabilities/
scientists and developers to explore and experiment with quantum computing. Quantum Technology Single environment to design, test, and run quantum algorithms Experiment with a variety of quantum hardware technologies Run hybrid quantum and classical algorithms Get Expert Help
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}