Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データ収集と整理 〜クラウドデータパイプラインの作成〜
Search
Shasha
August 21, 2024
94
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データ収集と整理 〜クラウドデータパイプラインの作成〜
Shasha
August 21, 2024
More Decks by Shasha
See All by Shasha
20221004_AKIBA.SaaS
shasha48
0
12
MDSを加速する 〜Fivetranとプロフェッショナルサービス〜
shasha48
0
15
データドリブンな小売戦略 〜Snowflakeによるパーソナライズの強化〜
shasha48
0
51
dbtとLookerの 境界線を定めます!
shasha48
0
140
信頼できるデータを届け、使うのは?
shasha48
0
300
DataObserbabilityDevIO2023.pdf
shasha48
0
1.2k
dbtの概要
shasha48
1
1.2k
データ分析について考える - 私が考えるデータ分析の必要性
shasha48
0
1k
Featured
See All Featured
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
The World Runs on Bad Software
bkeepers
PRO
72
12k
New Earth Scene 8
popppiees
3
2.4k
Thoughts on Productivity
jonyablonski
76
5.3k
Claude Code のすすめ
schroneko
67
230k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
160
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
30 Presentation Tips
portentint
PRO
1
360
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Transcript
第3回 データ収集と整理 〜クラウドデータパイプラインの作成〜 クラスメソッド株式会社 2023.11.28 1
10電力会社様向け勉強会「クラウドを活用したデータ分析とモダンデータスタックの可能性」
2 自己紹介 • 名 前 :ほりもと りさ • 所属部署:アライアンス事業部 エンジニアG
• 役 割 :MDS製品のプロフェッショナルサービス • ブ ロ グ:https://dev.classmethod.jp/author/shasha • 著 者 名:紗紗
3 本日お話しする内容(ざっくりと) 分析したいデータを データウェアハウス(DWH)に入れて、 分析しやすい形に整える ためのツールを紹介します。
4 本日お話しすること一覧 • 結論:データエンジニアの採用は大変! • データパイプラインとは? • ETLとELTと...再確認
• Fivetranのご紹介 • dbtのご紹介 • Fivetran x dbt デモ • まとめ
5 いきなり、まとめます
6 まとめ 自社のデータ分析基盤をSaaSで構築すれば、シロウトで もデータ分析基盤を構築することが可能です。
7 どういうことかというと..... データ分析を始めるのに必要なのは...??
8 データ分析を始めるのに必要なのは...?? 全然わからないので、まずは データエンジニアがいないと・・・
9 データ分析を始めるのに必要なのはデータエンジニア...?? そうでしょうか?
10 人を採用するのって時間かかりますよね • データ分析基盤を作ろう ↓ • 分析基盤を作れるエンジニア/外注先が必要だ ↓
• 採用にも会社選定にも時間がかかる・・・・・ ↓ • 人件費/外注コストがかかる
11 SaaSを活用してデータ分析を始めましょう! データ分析基盤の大変な部分を丸っと 管理してくれるSaaSならば、 SQLが書ければ、データの可視化まで ラクラク進めることができます!
12 疑 (疑)
13 だまされたと思って・・・ わたしの話を聞いてください。
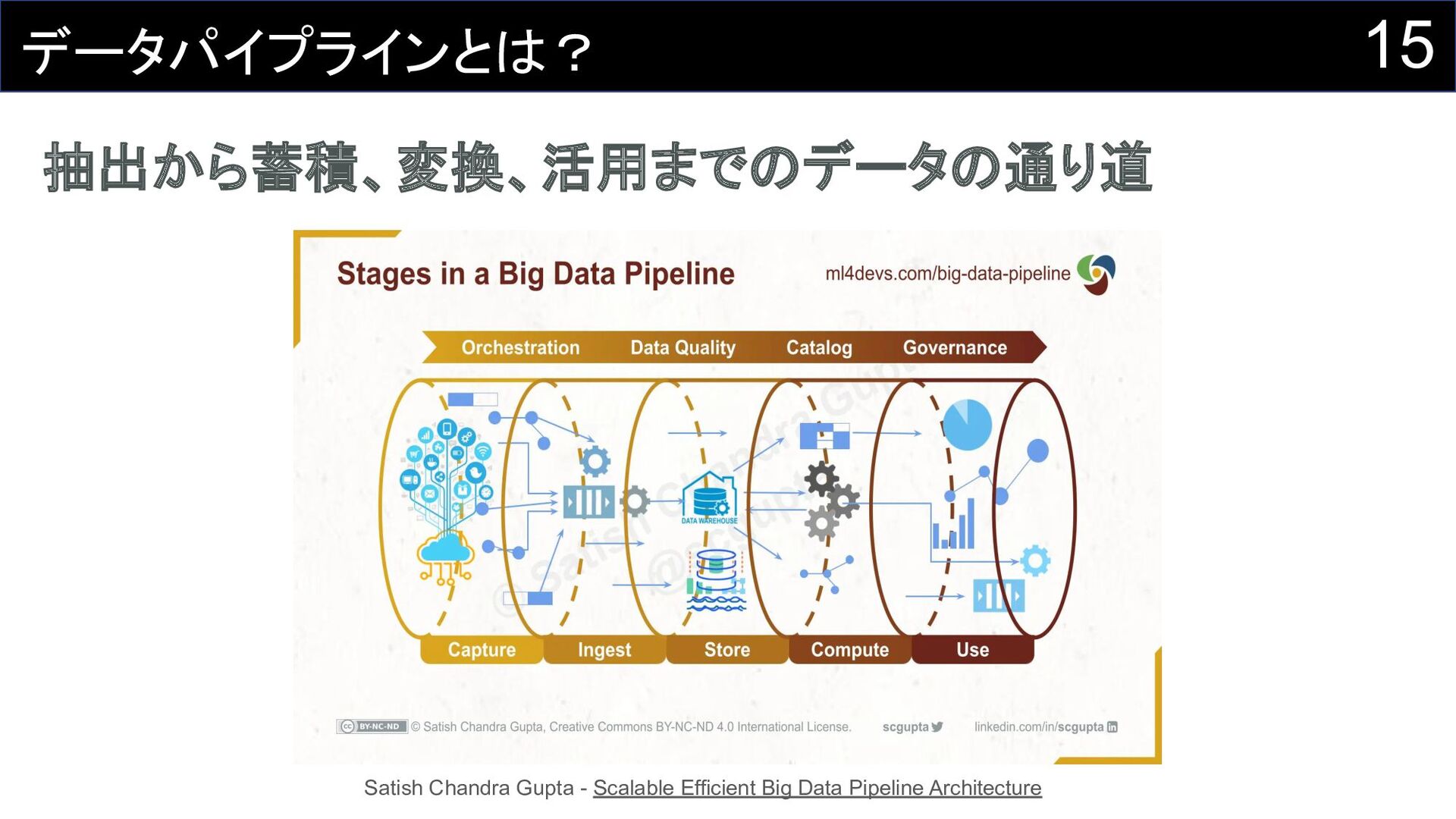
14 データパイプラインとは?
15 データパイプラインとは? 抽出から蓄積、変換、活用までのデータの通り道 Satish Chandra Gupta - Scalable Efficient
Big Data Pipeline Architecture
16 ETLとELTと...再確認
17 ETLとELTと...再確認 • Extract (抽出) • Transform (変換) • Load(読込)
• Extract (抽出) • Load(読込) • Transform (変換) データソースからデータウェアハウスにデータを 入れるまでのやり方2パターン
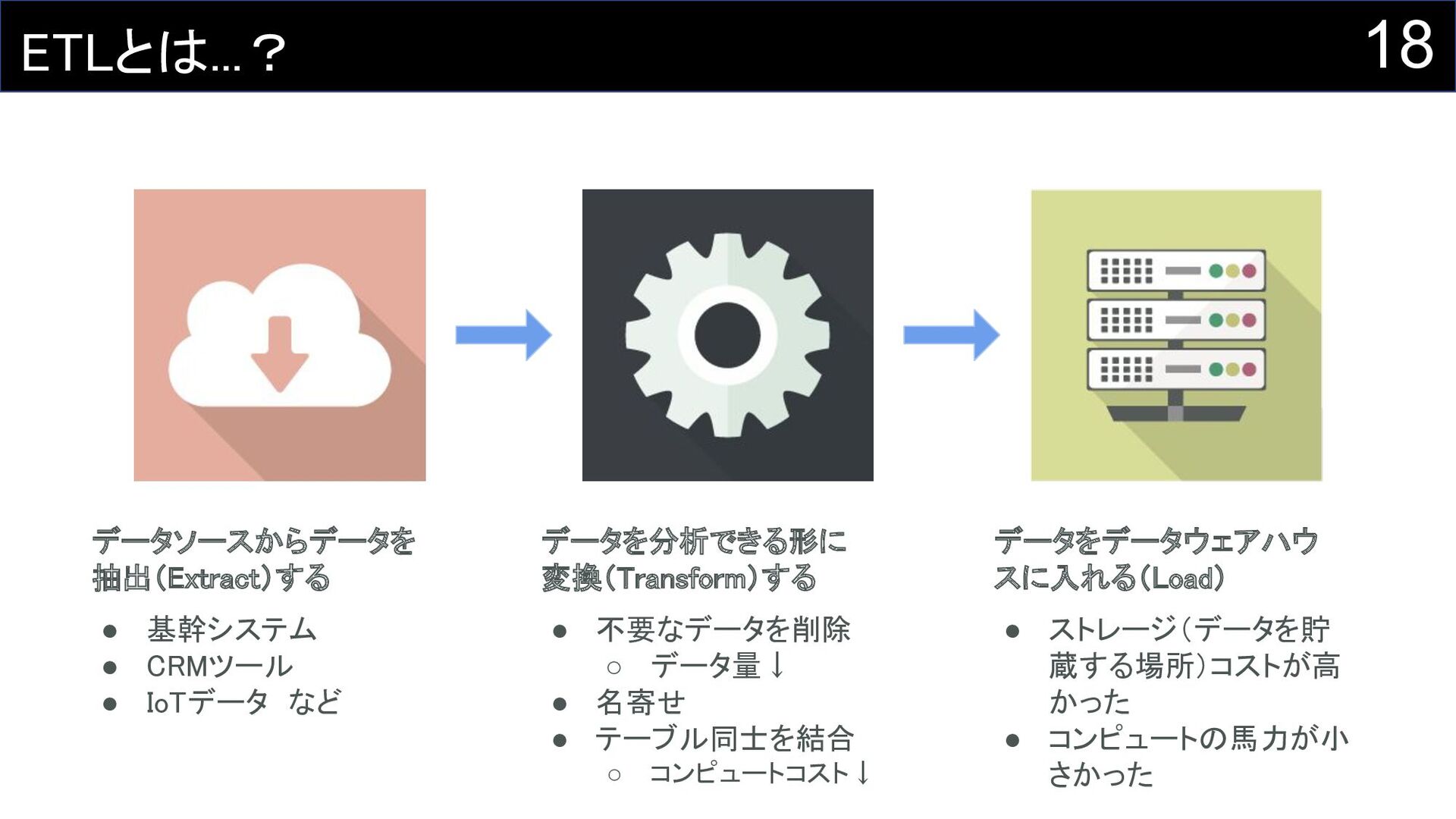
18 ETLとは...? データソースからデータを 抽出(Extract)する • 基幹システム • CRMツール •
IoTデータ など データを分析できる形に 変換(Transform)する • 不要なデータを削除 ◦ データ量↓ • 名寄せ • テーブル同士を結合 ◦ コンピュートコスト↓ データをデータウェアハウ スに入れる(Load) • ストレージ(データを貯 蔵する場所)コストが高 かった • コンピュートの馬力が小 さかった
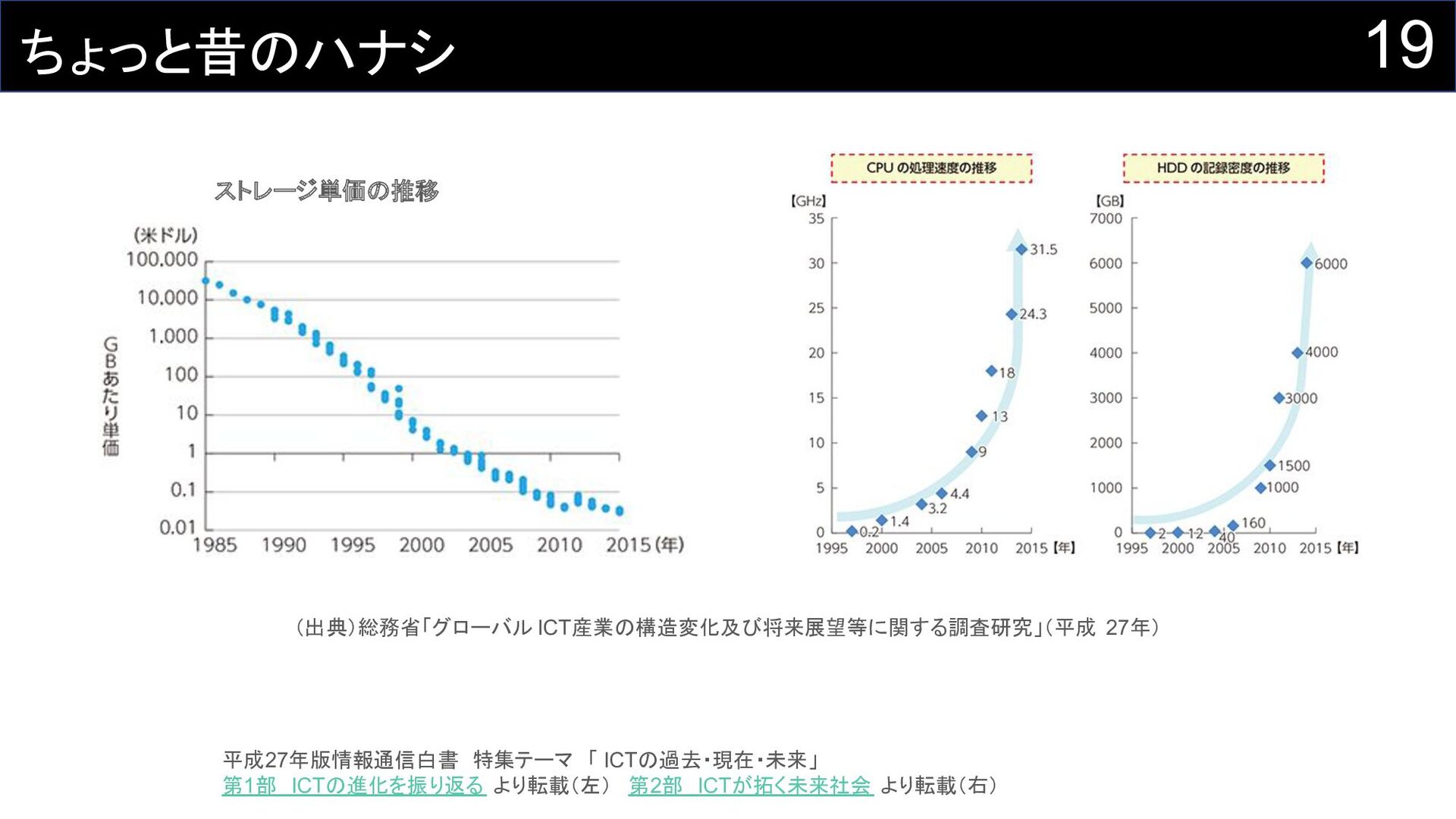
19 ちょっと昔のハナシ ストレージ単価の推移 (出典)総務省「グローバル ICT産業の構造変化及び将来展望等に関する調査研究」(平成 27年) 平成27年版情報通信白書 特集テーマ 「 ICTの過去・現在・未来」 第1部 ICTの進化を振り返る
より転載(左) 第2部 ICTが拓く未来社会 より転載(右)
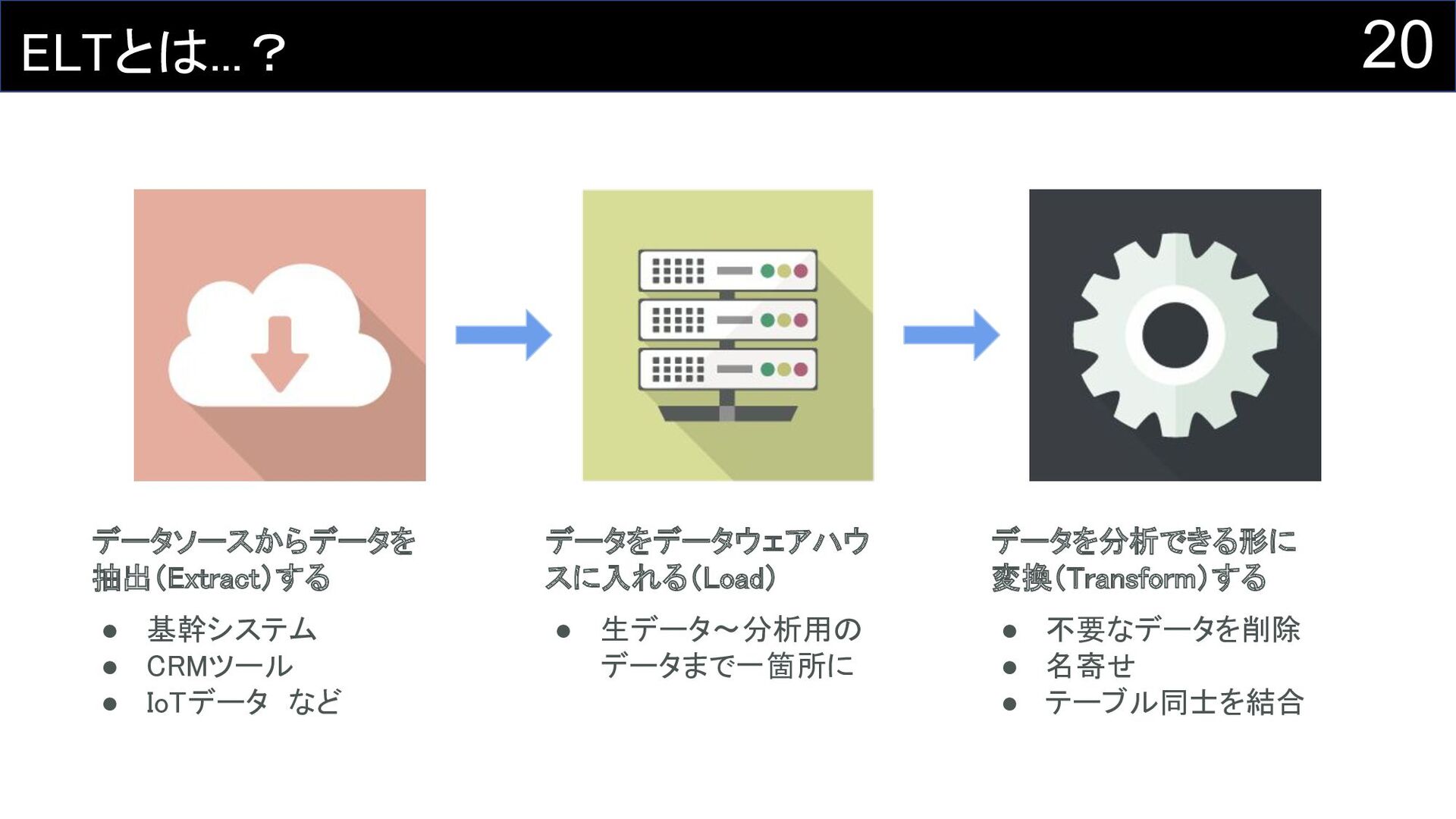
20 ELTとは...? データソースからデータを 抽出(Extract)する • 基幹システム • CRMツール •
IoTデータ など データを分析できる形に 変換(Transform)する • 不要なデータを削除 • 名寄せ • テーブル同士を結合 データをデータウェアハウ スに入れる(Load) • 生データ〜分析用の データまで一箇所に
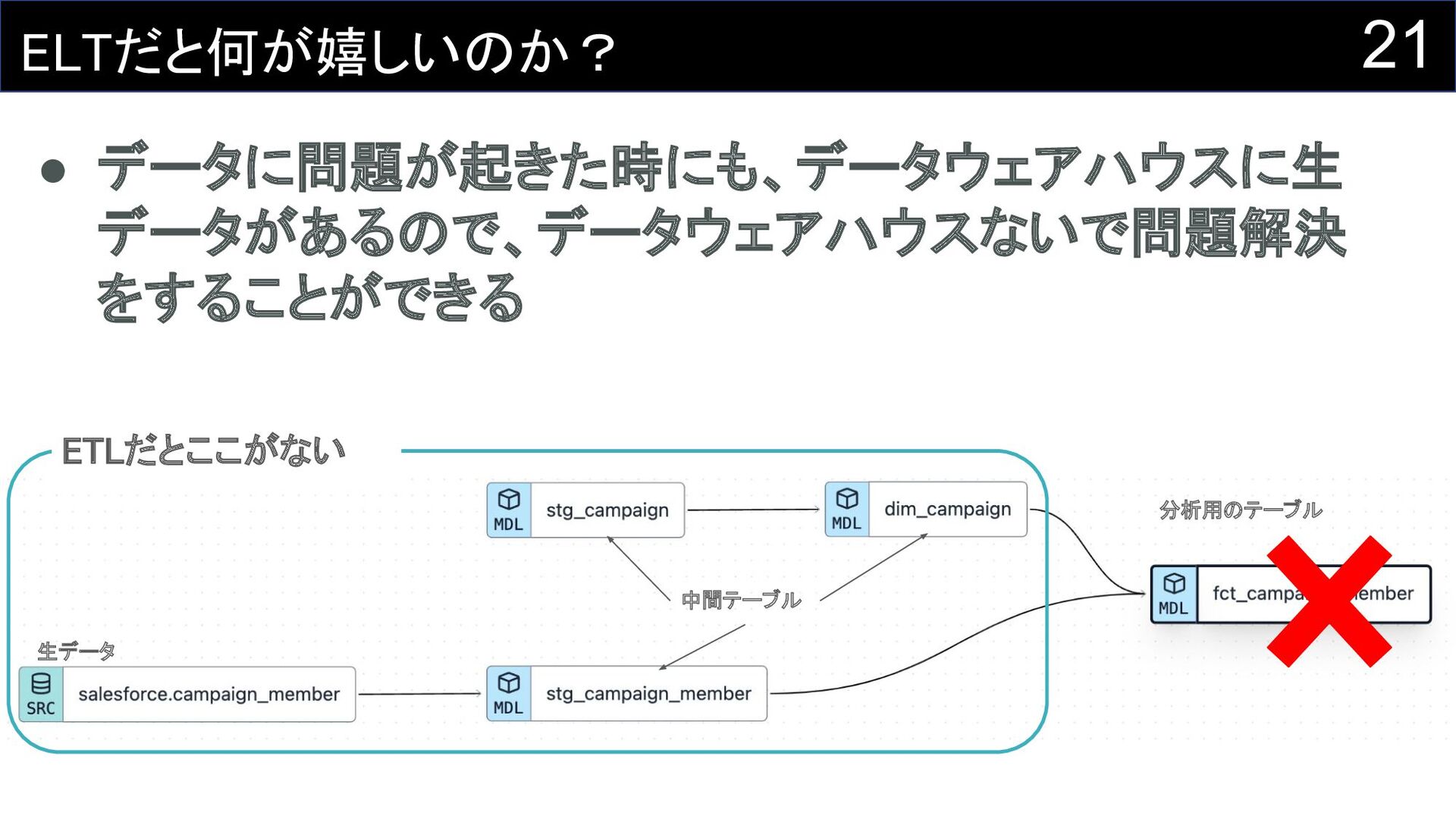
21 ELTだと何が嬉しいのか? • データに問題が起きた時にも、データウェアハウスに生 データがあるので、データウェアハウスないで問題解決 をすることができる ETLだとここがない 生データ
中間テーブル 分析用のテーブル
22 Fivetranのご紹介
23 Fivetranとは? • データパイプライン ◦ ELTのELを担う • SaaS •
ノーコーディング • 300+ のコネクタ
24 Fivetranの特徴 • 自動スキーマ管理 • シームレスなデータ統合 • フルマネージドサービス
DWH BIツール
25 Fivetranの何がうれしいのか
26 @くらにゃん データの抽出とロードを自社で開発しようとするとどんな工程が必要なの? データソース の定義 データ取得方法
の設計 データの変換 データのロード エラーハンドリング ロギング スケジューリング 監視 以上の工程は大まかなもので、細かい部分ではさらに多くの手間と時間が必要になるにゃん。 自社で開発するには複雑で大変なものになるけど、だからといって手を抜かずにやるのが大切にゃん!某もこ う言うけどにゃん、それぞれの手順でたくさんの知識と技術が要求されるから、 専門的なスキルを持つメン バーがいることも重要にゃん !
27 ここがすごいよFivetran! データソース の定義 データ取得方法 の設計
データの変換 データのロード エラーハンドリング ロギング スケジューリング 監視 全部Fivetran がやるにゃん
28 どうですか・・・?? Fivetranめちゃくちゃよくないですか?
29 dbtのご紹介
30 dbtとは? • データパイプライン ◦ ELTのTを担う • 簡単なSQLでデータパイプラインを構築可能
◦ SELECTやJOINが分かれば開発可能 • 主要なDWH/DBに対応 ◦ Snowflake ◦ Redshift ◦ BigQuery など
31 dbt登場した背景
32 2010年代から変化していないデータモデリング • その1:独自開発コード ◦ ビジネスロジックを表現するのにエネルギーが要る ◦ アクセスに難あり(難しい処理はPython) ◦
新しいデータセットの作成に3〜4週間かかってしまう ◦ 社内インフラをホスティングする必要がある • その2:GUIでポチポチ ◦ 高額 ◦ 学習コストが高い ◦ アクセスに難あり(Adminなどに限られる)
33 従来のデータモデリングの問題点 • 都市伝説と化すデータの民主化 ◦ 欲しいデータがすぐに手に入らない ◦ そのデータが信頼できるかわからない •
複雑怪奇で属人的なSQL地獄 ◦ ELTでSQLでデータにアクセス可能に ◦ 野良SQL、テーブル大量発生
34 dbtの特徴 • シンプルかつ容易にデータ変換が可能 ◦ 簡単なSQLさえ知っていればOK • ソフトウェアエンジニアのようにデータパイプラインを開 発できる
◦ バージョン管理、自動テスト、ドキュメンテーション、再利用性
35 dbtが提供するこれからのデータモデリング ・SELECT文を知っていれば、誰でもデータマート開発を行えるサービス ・特別な知識&スキル不要で、アプリ開発の手法を取り入れた開発が可能 (バージョン管理、CI/CD、自動テスト、ドキュメント管理、etc) アプリ開発の手法を取り入れている ・Gitと連携
・継続的インテグレーション ドキュメントの自動生成 ・データの定義や依存関係等がわかる ・データカタログの役割も Jinjaで高度な処理を開発できる ・SQLだけでは実現できない処理の実現 ・マクロとして処理をモジュール化、再利用可 データに対してテストを実行できる ・not nullや参照整合性等を自動でテスト可能 ・Jinjaで、オリジナルのテストも作成可能 主要なDWHに対応 ・Amazon Redshift、Snowflake、Google BigQuery SQLで開発できる ・必要なのはSELECT文だけ ・プログラミング言語の学習は不要 1 6 5 3 4 2
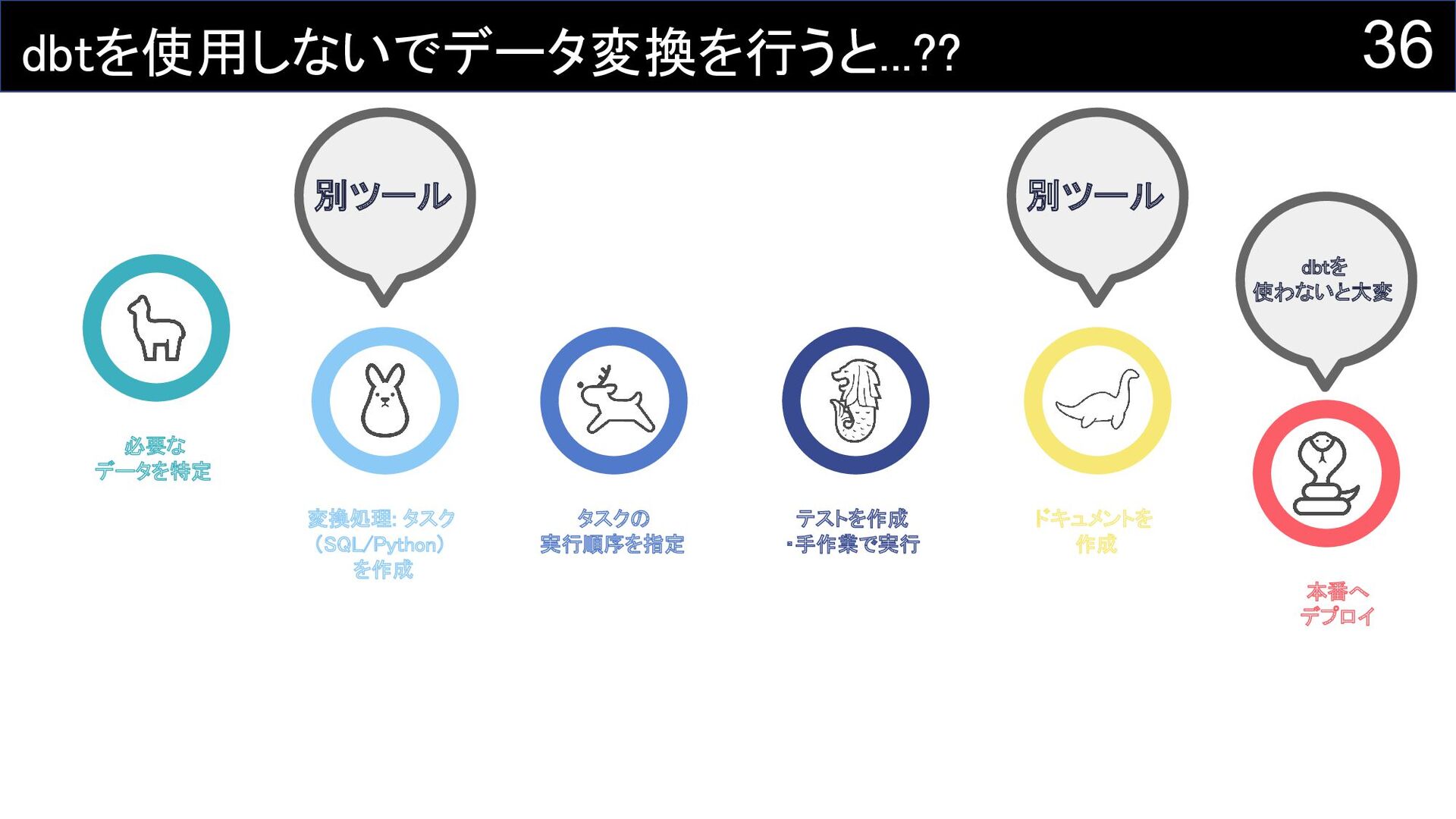
36 dbtを使用しないでデータ変換を行うと...?? 必要な データを特定 変換処理: タスク (SQL/Python)
を作成 タスクの 実行順序を指定 テストを作成 ・手作業で実行 ドキュメントを 作成 本番へ デプロイ 別ツール 別ツール dbtを 使わないと大変
37 dbtを使用しないでデータ変換を行うと...?? • タスクを行う順序を決めて、その通りに実行させる ◦ 数が多くなると管理が煩雑になる • SQLだけで処理ができないものもあるとDWH内で処理 が完結できない
• ドキュメントを別のツールで作成・保存しておく • テストを自動化できない • 開発環境と本番環境を分けるのも手作業
38 dbtを使用してデータ変換を行うと...?? 必要な データを特定 変換処理を作成 (SQLのみ) タスクの
実行順序を指定 テストを作成 ・自動実行 ドキュメントを dbtの機能で作成 本番へ デプロイ
39 dbtデモ
40 Fivetran x dbt デモ
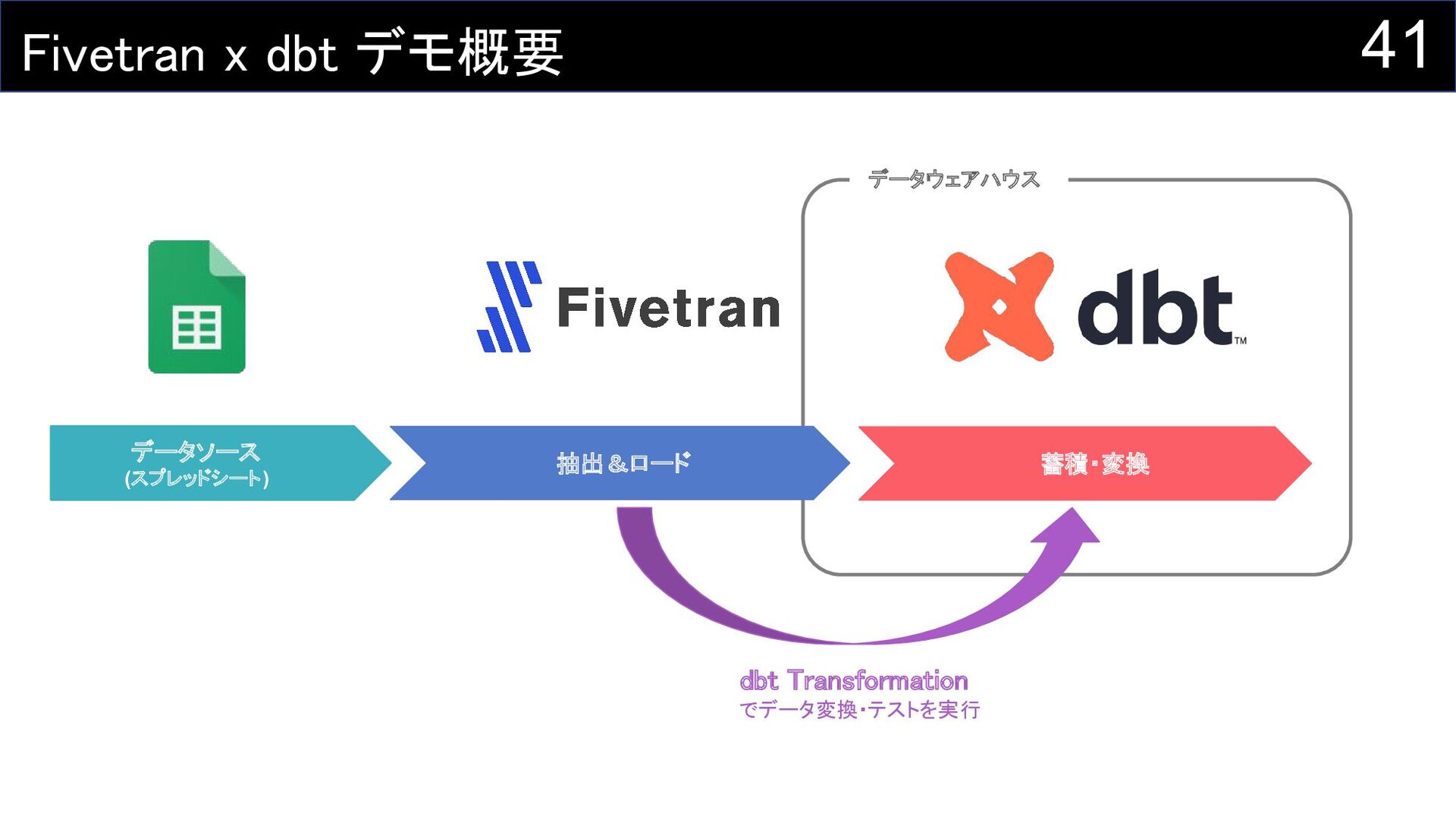
41 Fivetran x dbt デモ概要 データソース (スプレッドシート) 抽出&ロード 蓄積・変換 データウェアハウス
dbt Transformation でデータ変換・テストを実行
42 再掲:まとめ 自社のデータ分析基盤をSaaSで構築すれば、シロウトで もデータ分析基盤を構築することが可能です。
43 まとめ Fivetranとdbtさえあれば、 なんだかラクラクにデータパイプラインの構築が できそうだと思っていただけたでしょうか?
44 Fivetran x dbt デモ 画面を切り替えます
45 よく使うアイコンです。コピーで使用できます
46 人のアイコンです。コピーで使用できます
47 ラインアイコンです。コピーで使用できます
48 dbtのデモ 画面を切り替えます
49 dbtデモ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}