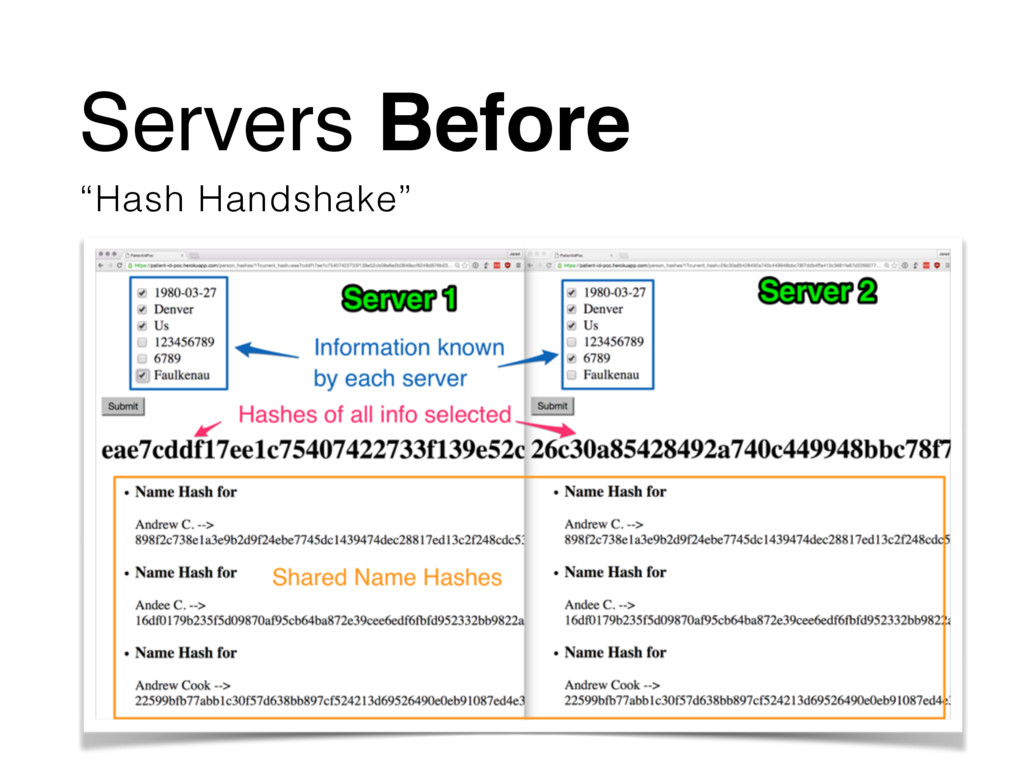
This slide deck describes our entry into the SIIM 2016 Hackathon. It utilizes a novel approach of hashing patient information to ensure patient records are correlated between disparate systems without sharing of private data or the same patient ID number.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}