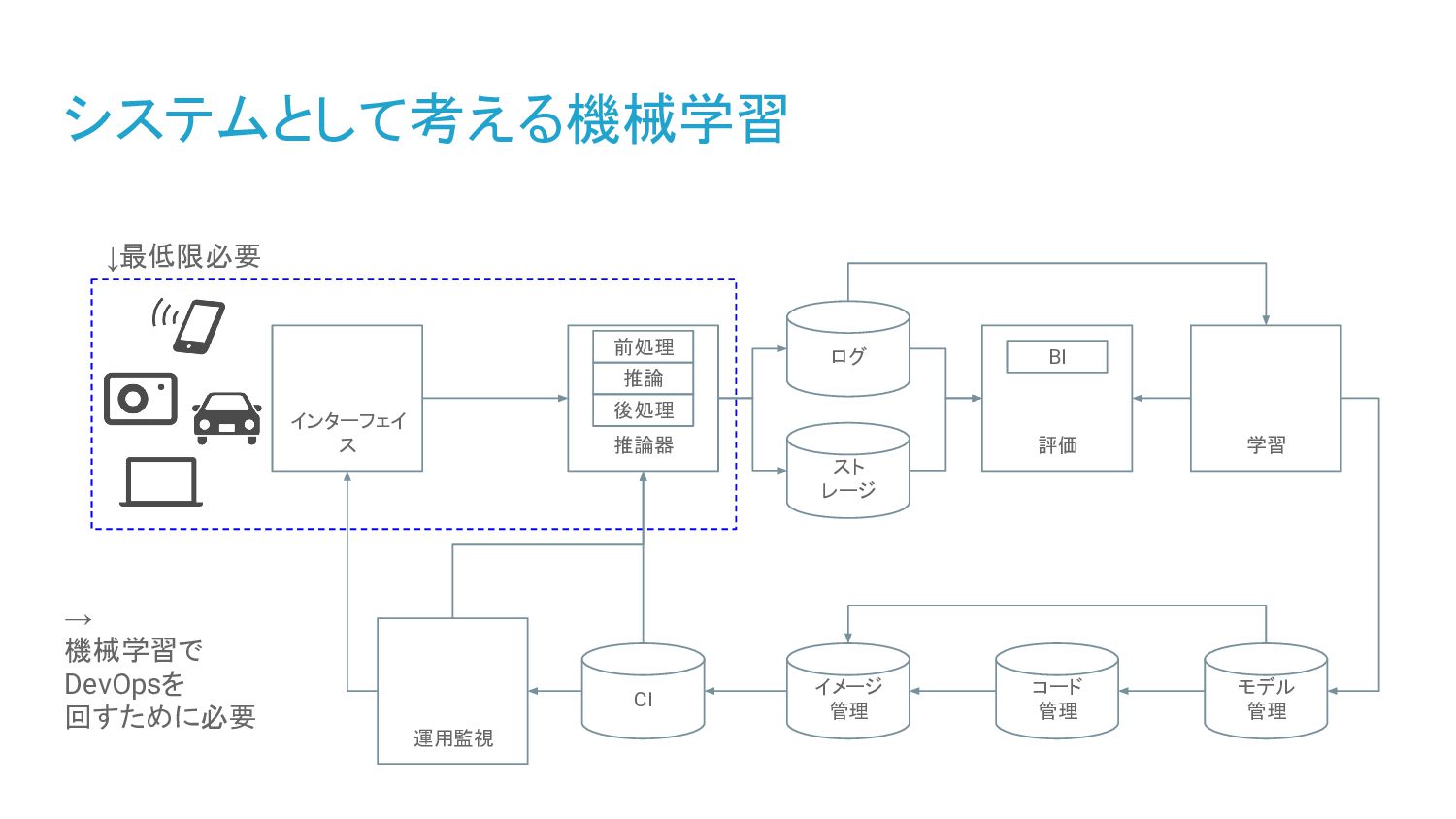
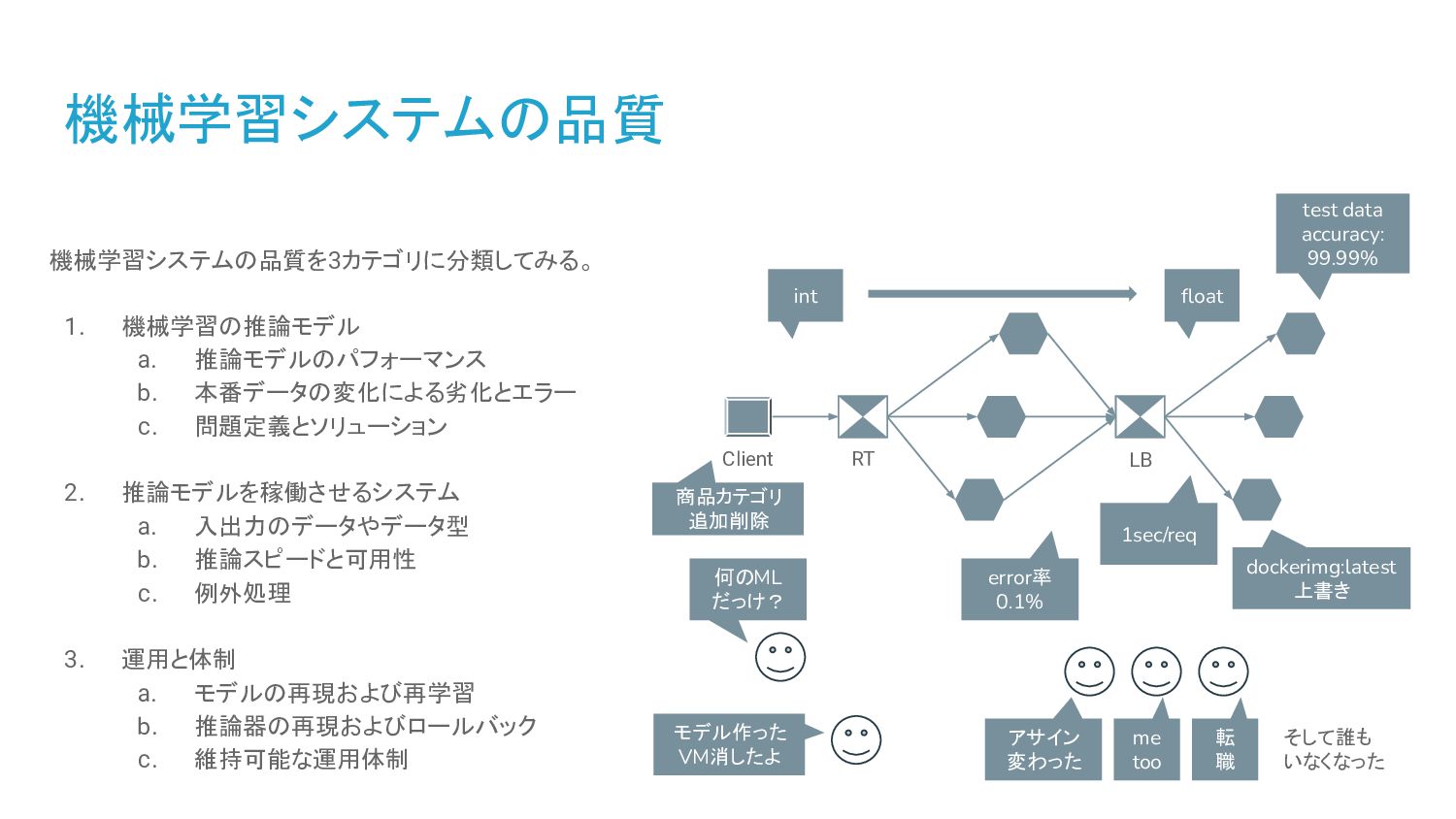
2. 推論モデルを稼働させるシステム a. 入出力のデータやデータ型 b. 推論スピードと可用性 c. 例外処理 3. 運用と体制 a. モデルの再現および再学習 b. 推論器の再現およびロールバック c. 維持可能な運用体制 Client RT LB int float test data accuracy: 99.99% 何のML だっけ? 1sec/req モデル作った VM消したよ dockerimg:latest 上書き error率 0.1% アサイン 変わった me too 転 職 商品カテゴリ 追加削除 そして誰も いなくなった
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}