Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Testing machine learning development
Search
shibuiwilliam
March 17, 2022
Technology
180
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Testing machine learning development
code testing for machine learning development
shibuiwilliam
March 17, 2022
More Decks by shibuiwilliam
See All by shibuiwilliam
LLMやAIエージェントをソフトウェアに組み込むプラクティス
shibuiwilliam
1
210
From Prompt Engineering to Loop Engineering
shibuiwilliam
1
360
OntologyとLLMOps
shibuiwilliam
3
76
Rule repository
shibuiwilliam
3
63
LLM時代の検索アーキテクチャと技術的意思決定
shibuiwilliam
4
2.5k
Why Open Dataspacesのまとめ
shibuiwilliam
2
90
マルチモーダル非構造データとの闘い
shibuiwilliam
2
660
飽くなき自動生成への挑戦
shibuiwilliam
1
92
AIエージェントのメモリについて
shibuiwilliam
1
770
Other Decks in Technology
See All in Technology
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
810
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
250
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
160
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
210
グローバルチームと挑むプロダクト開発
sansantech
PRO
1
170
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
500
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
130
はじめてのWDM
miyukichi_ospf
1
140
SRE本の知られざる名シーン / The Hidden Gems of Google SRE Book
nari_ex
1
310
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
3.8k
Zoom2Youtube.Claude
kawaguti
PRO
3
480
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
340
Featured
See All Featured
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
410
Accessibility Awareness
sabderemane
1
150
30 Presentation Tips
portentint
PRO
1
340
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
400
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
240
Marketing to machines
jonoalderson
1
5.6k
The Curious Case for Waylosing
cassininazir
1
430
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.5k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
GraphQLとの向き合い方2022年版
quramy
50
15k
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Transcript
機械学習の開発を テストする 2021/06/26 shibui yusuke
自己紹介 shibui yusuke • 自動運転スタートアップのティアフォー所属 • MLOpsエンジニア & インフラエンジニア &
データエンジニア • もともとクラウド基盤の開発、運用。 • ここ5年くらいMLOpsで仕事。 • Github: @shibuiwilliam • Qiita: @cvusk • FB: yusuke.shibui • 最近やってること: IstioとGoとデータ分析 cat : 0.55 dog: 0.45 human : 0.70 gorilla : 0.30 物体検知
本を出版しました! • AIエンジニアのための 機械学習システムデザインパターン • 2021年5月17日発売 • https://www.amazon.co.jp/dp/4798169447/ • 機械学習と銘打ってるのに
KubernetesとIstioに 詳しくなれる一冊です! • Amazon.co.jp 情報学・情報科学部門 1位! 人工知能部門 1位! • 増刷決定! • 韓国語版と中国語版(台湾)も出るらしい!
今日話すこと • 機械学習の開発をテストする
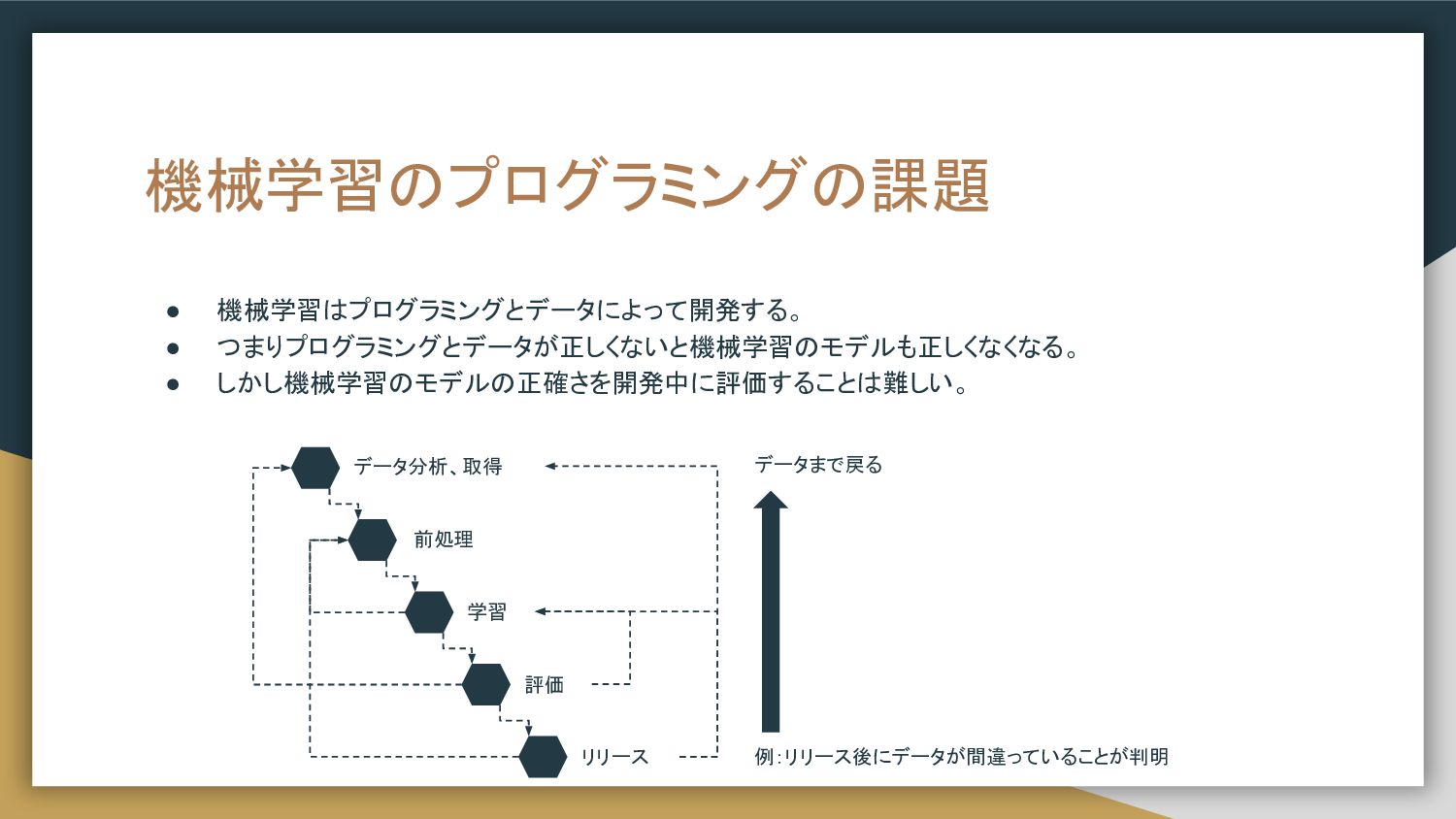
機械学習のプログラミングの課題 • 機械学習はプログラミングとデータによって開発する。 • つまりプログラミングとデータが正しくないと機械学習のモデルも正しくなくなる。 • しかし機械学習のモデルの正確さを開発中に評価することは難しい。 データ分析、取得 前処理 学習
評価 リリース 例:リリース後にデータが間違っていることが判明 データまで戻る
「学習を自動化したい」は簡単ではない • 研究、開発中のコード =毎日読んで書くコード。 =一箇所修正して依存箇所を直すことは容易。 • 自動実行するコード =毎日実行するけど、毎日読まないし書かないコードになる。 =忘れてしまうコードになる。 =開発時に記録されていない情報は失われる。
◦ 失われるものの例:学習時に使ったデータ。特に中間データ
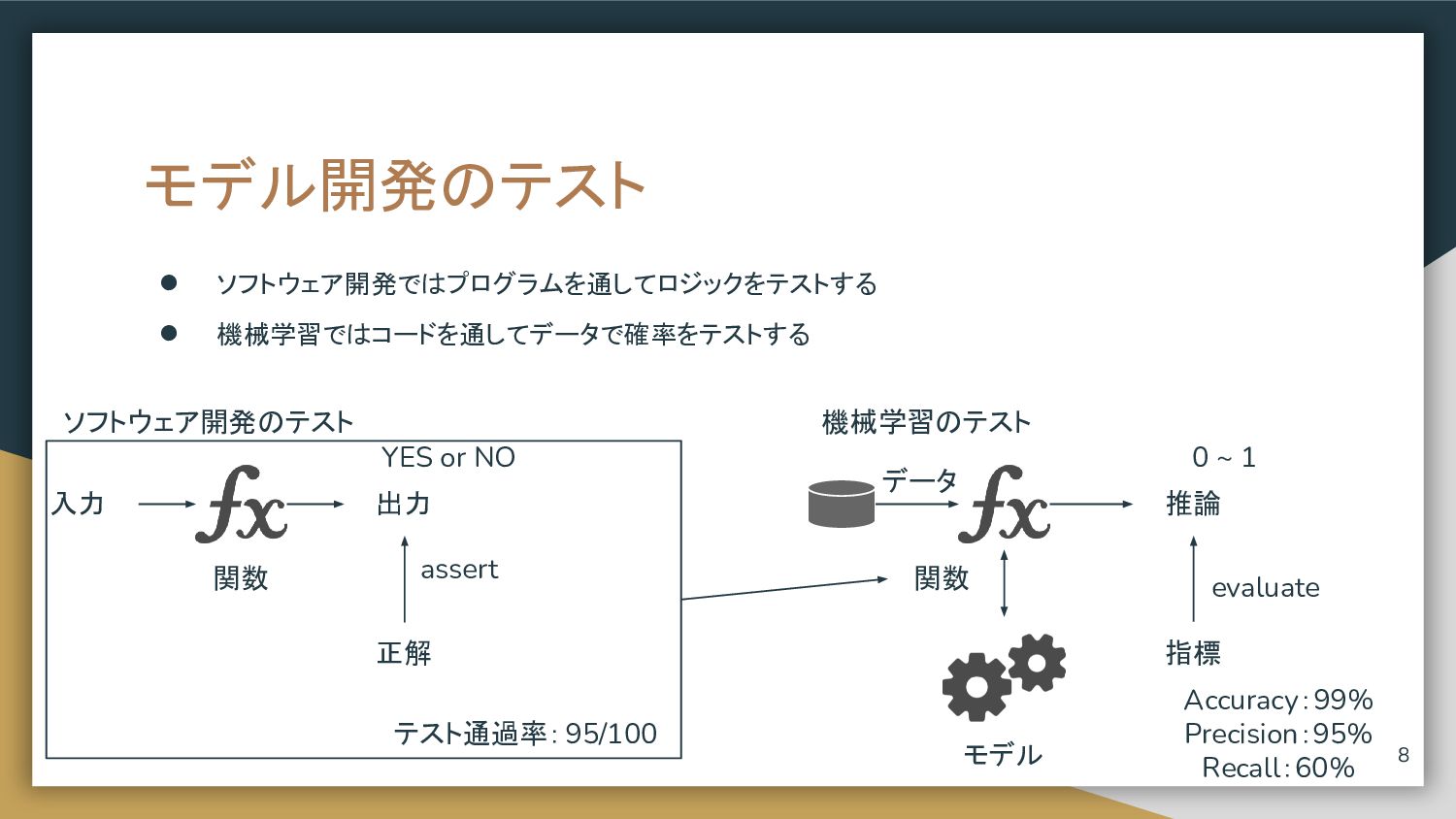
モデル開発のテスト • ソフトウェア開発ではプログラムを通してロジックをテストする • 機械学習ではコードを通してデータで確率をテストする YES or NO 0 ~
1 ソフトウェア開発のテスト 機械学習のテスト 入力 正解 出力 assert 関数 指標 推論 evaluate モデル 関数 テスト通過率:95/100 Accuracy:99% Precision:95% Recall:60% 7 データ
モデル開発のテスト • ソフトウェア開発ではプログラムを通してロジックをテストする • 機械学習ではコードを通してデータで確率をテストする YES or NO 0 ~
1 ソフトウェア開発のテスト 機械学習のテスト 入力 正解 出力 assert 関数 指標 推論 evaluate モデル 関数 テスト通過率:95/100 Accuracy:99% Precision:95% Recall:60% 8 データ
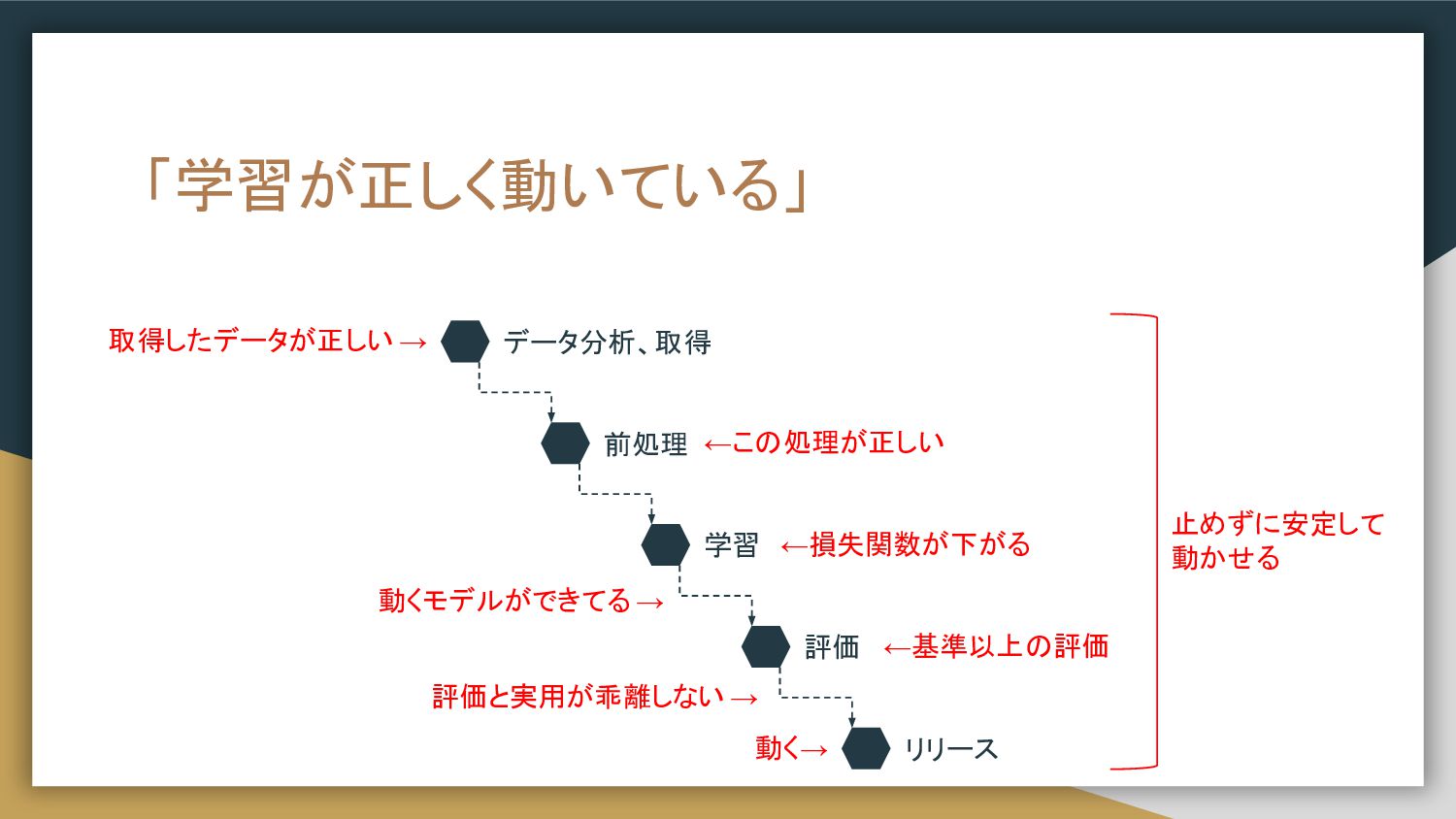
「学習が正しく動いている」 取得したデータが正しい → ←この処理が正しい 動くモデルができてる → ←基準以上の評価 評価と実用が乖離しない → 止めずに安定して
動かせる データ分析、取得 前処理 学習 評価 リリース ←損失関数が下がる 動く→
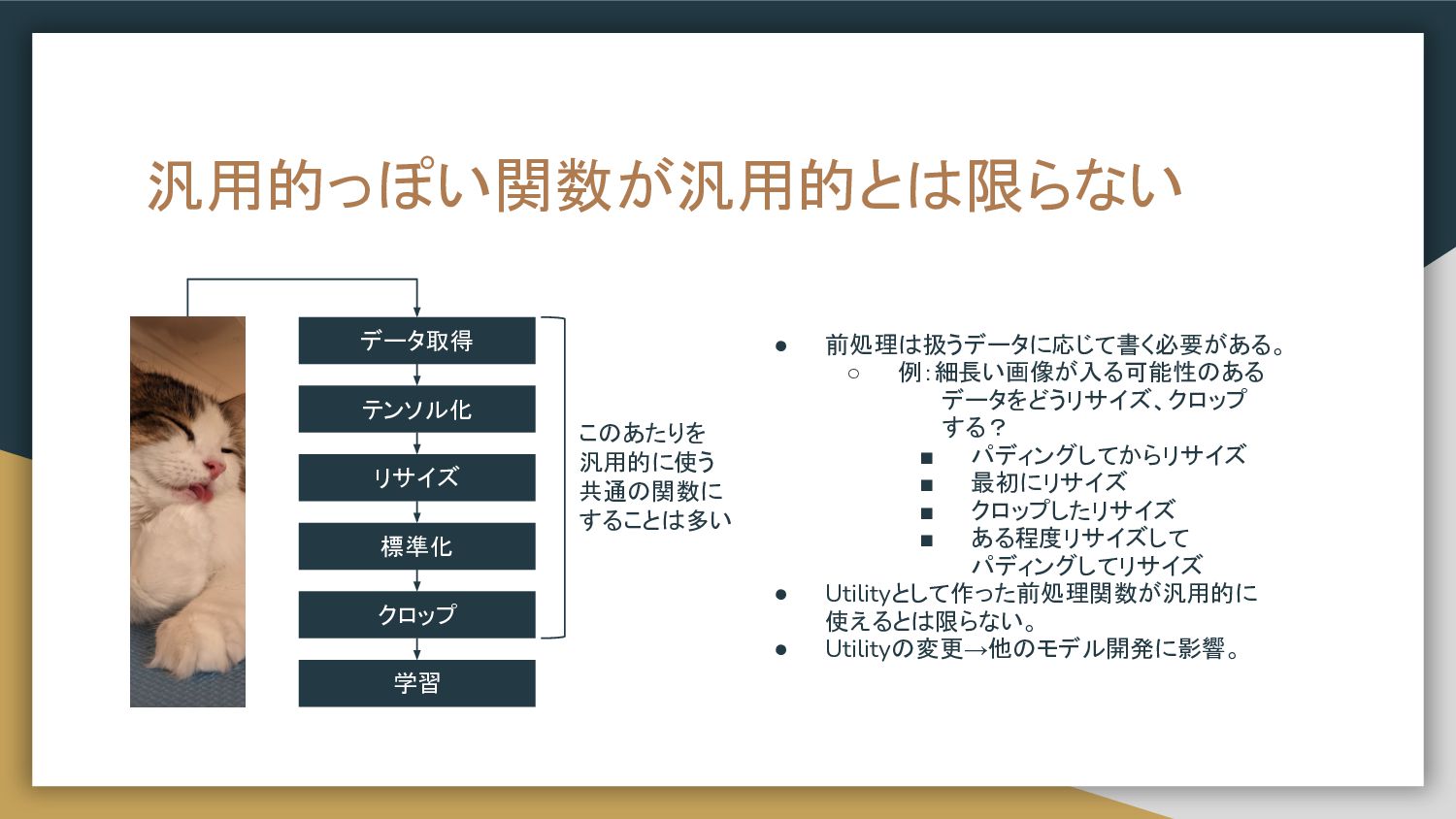
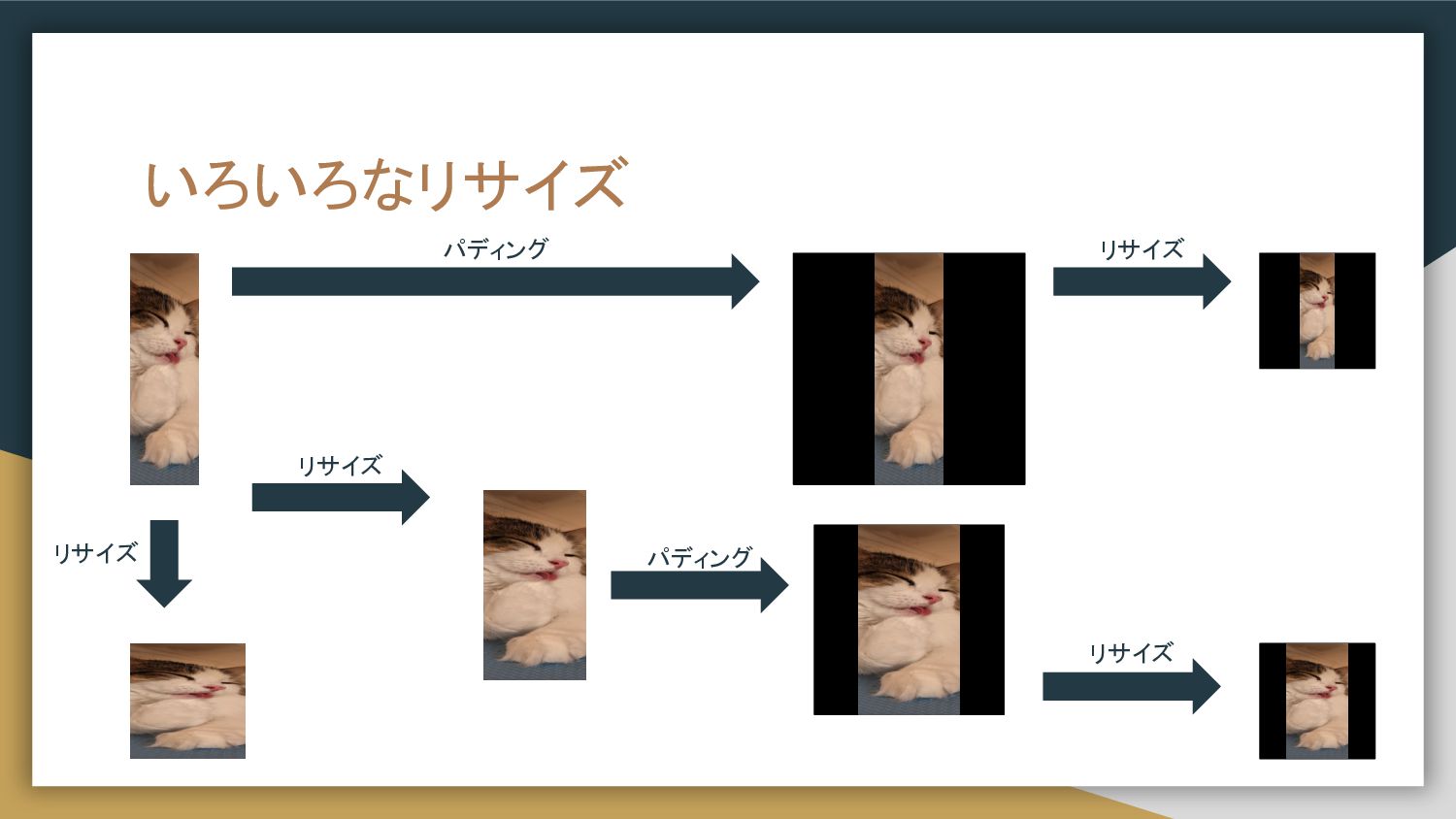
汎用的っぽい関数が汎用的とは限らない • 前処理は扱うデータに応じて書く必要がある。 ◦ 例:細長い画像が入る可能性のある データをどうリサイズ、クロップ する? ▪ パディングしてからリサイズ ▪
最初にリサイズ ▪ クロップしたリサイズ ▪ ある程度リサイズして パディングしてリサイズ • Utilityとして作った前処理関数が汎用的に 使えるとは限らない。 • Utilityの変更→他のモデル開発に影響。 データ取得 テンソル化 リサイズ クロップ 標準化 学習 このあたりを 汎用的に使う 共通の関数に することは多い
いろいろなリサイズ リサイズ リサイズ リサイズ リサイズ パディング パディング
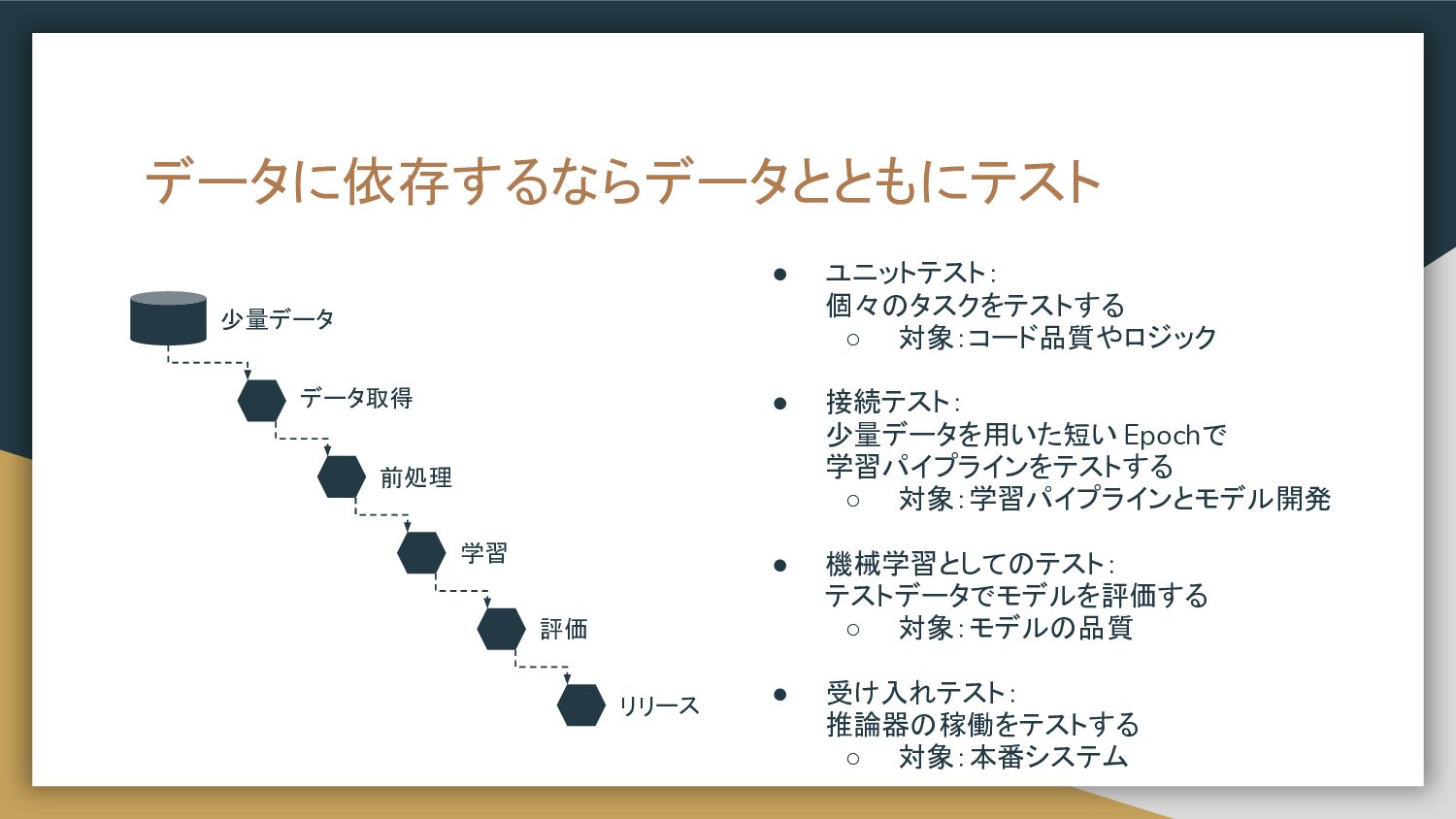
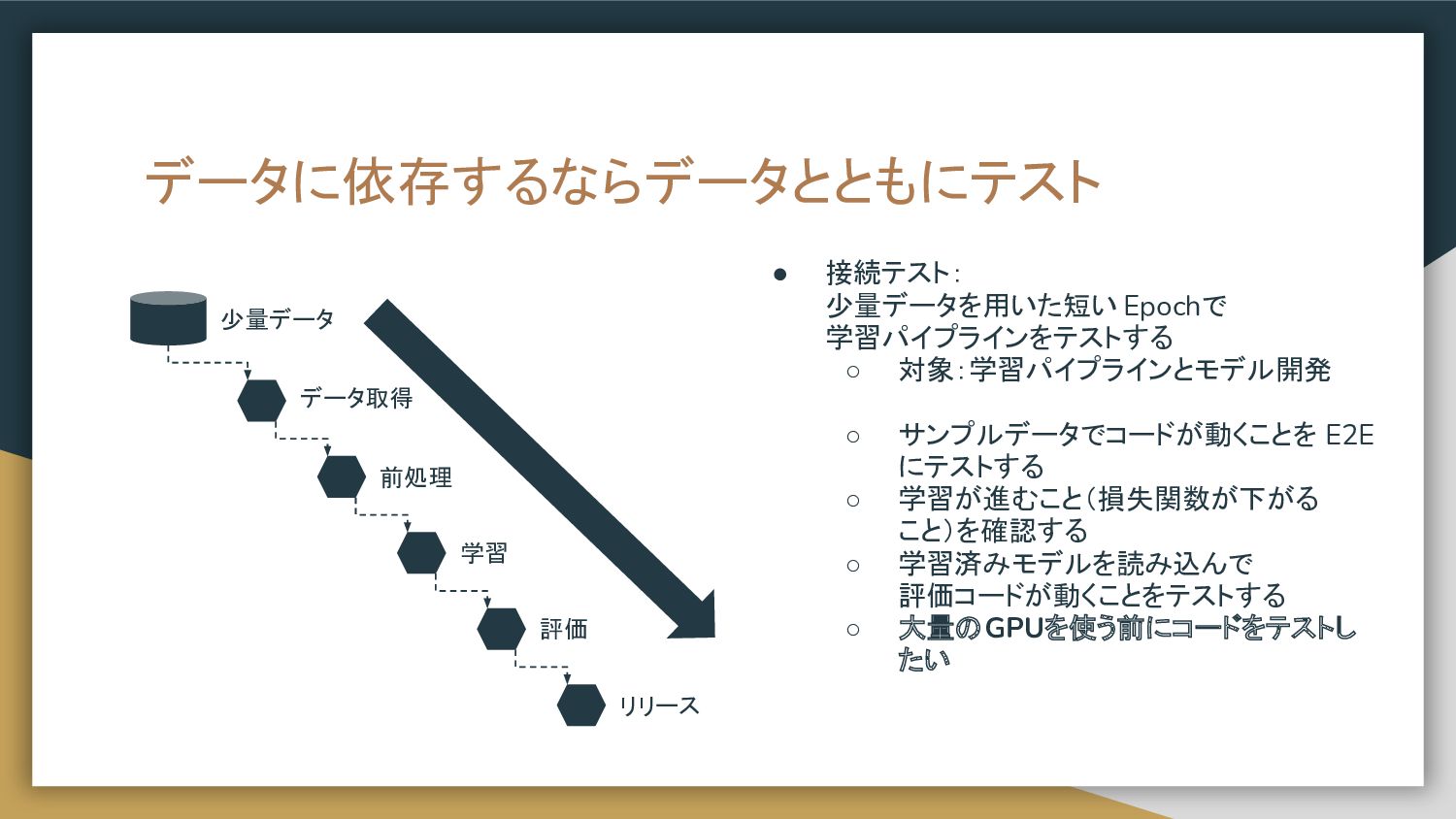
データに依存するならデータとともにテスト • ユニットテスト: 個々のタスクをテストする ◦ 対象:コード品質やロジック • 接続テスト: 少量データを用いた短い Epochで
学習パイプラインをテストする ◦ 対象:学習パイプラインとモデル開発 • 機械学習としてのテスト: テストデータでモデルを評価する ◦ 対象:モデルの品質 • 受け入れテスト: 推論器の稼働をテストする ◦ 対象:本番システム データ取得 前処理 学習 評価 リリース 少量データ
データに依存するならデータとともにテスト • 接続テスト: 少量データを用いた短い Epochで 学習パイプラインをテストする ◦ 対象:学習パイプラインとモデル開発 ◦ サンプルデータでコードが動くことを
E2E にテストする ◦ 学習が進むこと(損失関数が下がる こと)を確認する ◦ 学習済みモデルを読み込んで 評価コードが動くことをテストする ◦ 大量のGPUを使う前にコードをテストし たい データ取得 前処理 学習 評価 リリース 少量データ
ユニットテストの例 def resize_image( img: np.ndarray, width: int, height: int, )
-> np.ndarray: resize_img = cv2.resize(img, (width, height)) return resize_img a = np.random.randint(0, 255, (2, 4, 3)) @pytest.mark.parametrize( ("img", "width", "height"), [(a, 20, 30)], ) def test_resize_image( img: np.ndarray, width: int, height: int, ): resize_img = resize_image(img, width, height) assert resize_img.shape = (width, height, 3) • 普通のユニットテストを書く。
接続テストの例 # 仮のコードです def make_dataloader(data_path: str) -> DataLoader: return dataloader(data_path)
def train(model: nn.Module, epochs: int, trainloader: DataLoader) -> List[float]: losses = [] for epoch in range(epochs): average_loss = train_once(model, trainloader) losses.append(average_loss) model.save() return losses def evaluate(model_path: str, testloader: DataLoader) -> List[float]: predictor = Model(model_path) evaluations = predictor.evaluate(testloader) return evaluations • 少量データで動かす。 @pytest.mark.parametrize( (“model”, "train_path", “test_path” “epochs”), [(model, “/tmp/small_train/”, “/tmp/small_test/”, 10)], ) def test_train( model: nn.Module, train_path: str, test_path: str, epochs: int, ): trainloader = make_dataloader(train_path) testloader = make_dataloader(test_path) init_accuracy = evaluate(model, testloader) losses = train(model, epochs, trainloader) assert losses[0] > losses[-1] trained_accuracy = evaluate(model, testdata) assert init_accuracy < trained_accuracy
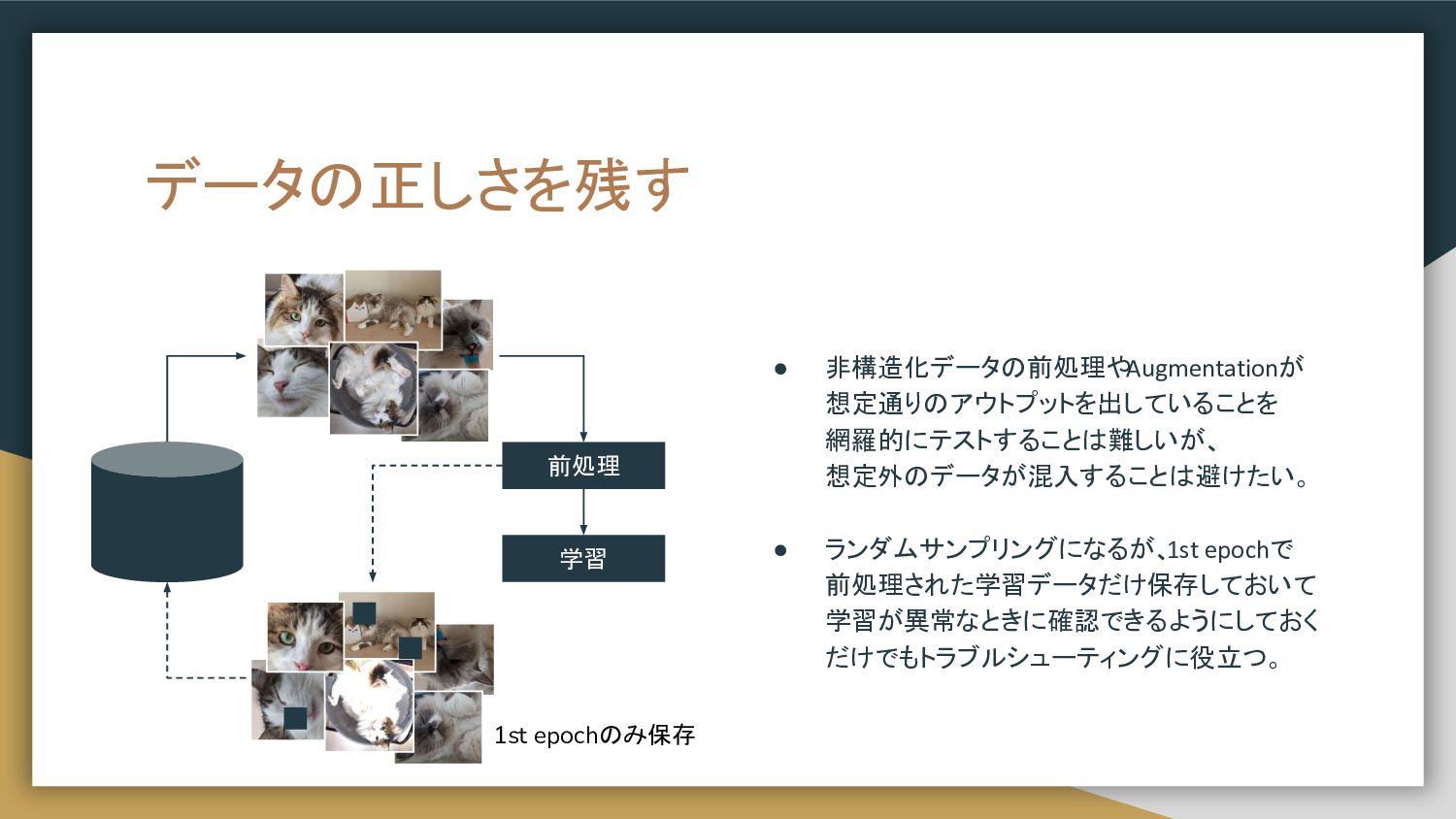
データの正しさを残す • 非構造化データの前処理や Augmentationが 想定通りのアウトプットを出していることを 網羅的にテストすることは難しいが、 想定外のデータが混入することは避けたい。 • ランダムサンプリングになるが、 1st
epochで 前処理された学習データだけ保存しておいて 学習が異常なときに確認できるようにしておく だけでもトラブルシューティングに役立つ。 前処理 学習 1st epochのみ保存
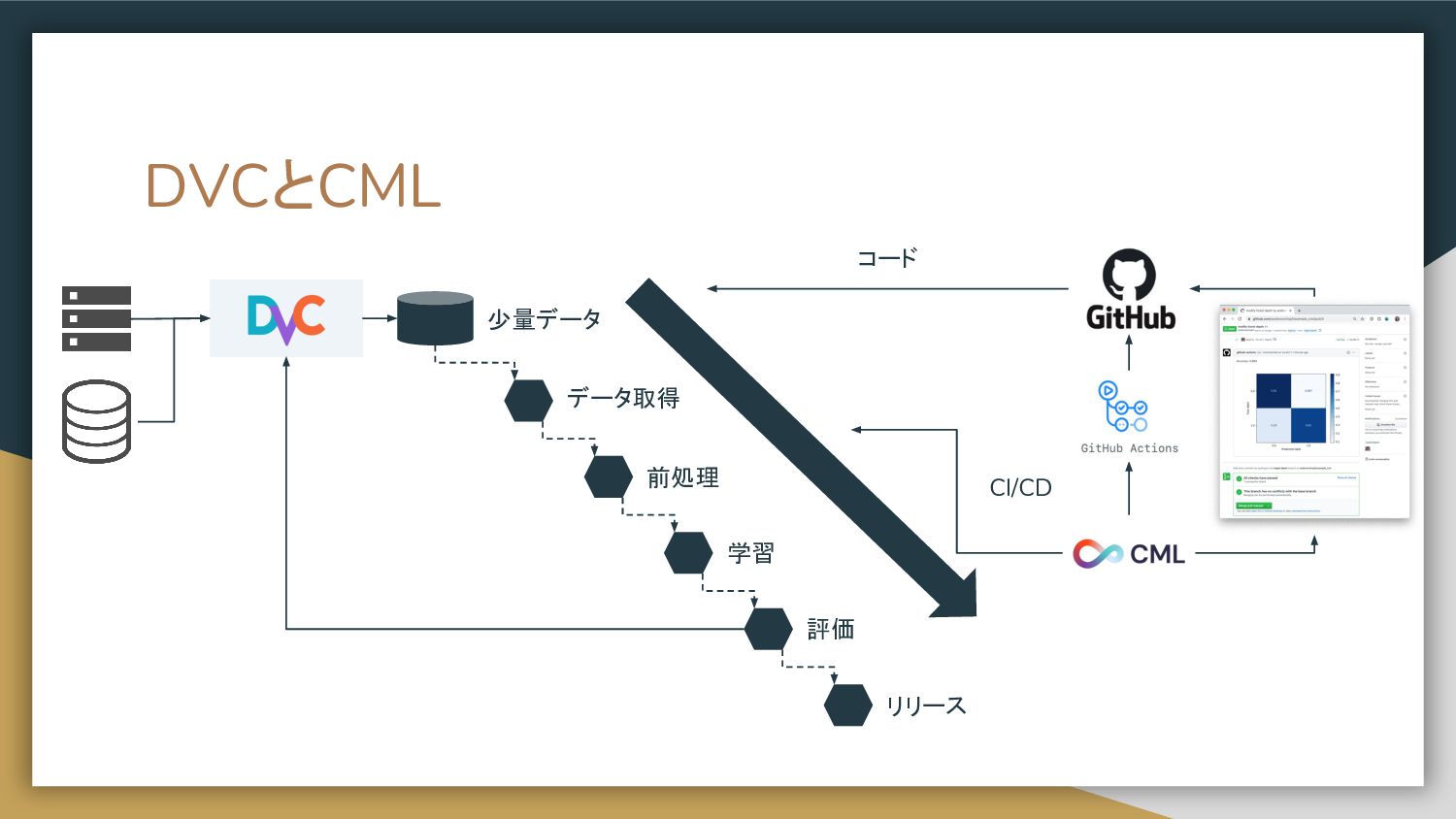
DVCとCML • Data Version Control • データ分析や機械学習で使ったデータを バージョン管理する • Gitみたいに使う
• https://dvc.org/doc • Continuous Machine Learning • 機械学習のためのCI/CD • GitHub ActionとDVCと組み合わせて データを管理したCI/CDが可能 • https://github.com/iterative/cml
DVCとCML データ取得 前処理 学習 評価 リリース 少量データ コード CI/CD
まとめ • 機械学習はデータに依存するため、データとともにテストする • 機械学習とプログラム両方のテストを書く • データの正しさを残す
宣伝 • MLOpsコミュニティを運営してます。 ◦ https://mlops.connpass.com/ • 毎月勉強会開催中! ◦ 7/14はメルカリUSがKubeflow +
Polyaxonによる 機械学習基盤を説明! ◦ https://mlops.connpass.com/event/215133/ • MLOpsコミュニティ公式ツイッター ◦ @MlopsJ ◦ https://twitter.com/MlopsJ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}