Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Perceiver: General Perception with Iterative [輪...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
shibutani
June 22, 2022
Research
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Perceiver: General Perception with Iterative [輪講発表資料]
Perceiver: General Perception with Iterativeに関する輪講発表資料
shibutani
June 22, 2022
More Decks by shibutani
See All by shibutani
越境するAIのために、境界を取り払う - AI 時代の開発体験向上に向けたリポジトリ統合の取り組み -
shibukazu
1
630
メッセージキュー型の非同期処理から Temporal 移行へ
shibukazu
4
5.7k
はじめてのOSS開発からみえたGo言語の強み
shibukazu
4
1.5k
全自動コードレビューの夢 〜実際に活用されるAIコードレビューの実現に向けて〜
shibukazu
11
5.6k
Hybrid Autoregressive Transducer [輪講発表資料]
shibukazu
0
410
Other Decks in Research
See All in Research
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
SLAMはどこまで解決されたのか?
tomonom
0
830
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.4k
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
470
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
340
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
310
NLP colloquium: AI Safety Survey
kanekomasahiro
0
850
コーディングエージェントとABNを再考
hf149
2
770
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
270
人間中心の意思決定支援AI
yukinobaba
PRO
7
3.4k
Featured
See All Featured
The SEO Collaboration Effect
kristinabergwall1
1
510
BBQ
matthewcrist
89
10k
WENDY [Excerpt]
tessaabrams
11
38k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
310
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Google's AI Overviews - The New Search
badams
0
1.1k
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
900
How to Ace a Technical Interview
jacobian
281
24k
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Transcript
Perceiver: General Perception with Iterative Attention [Jaegle, Gimeno+ 2020] 京都大学
音声メディア研究室 M1 渋谷和樹 1
これまではモダリティに依存したアーキテクチャが主流 ⇒アーキテクチャがモダリティにロックインされる Transformerはモダリティに依存しない Transformerの計算量は入力インデックスの二乗に比例 任意の入力長に対応できるTransformerベースのアーキテクチャが必要 ⇒Perceiverの登場 Introduction 2
Perceiver 3
Transformerベースのモダリティ非依存アーキテクチャ CrossAttentionによってTransformerの計算量を削減 画像・音声・点群において優れた性能 Perceiver 4
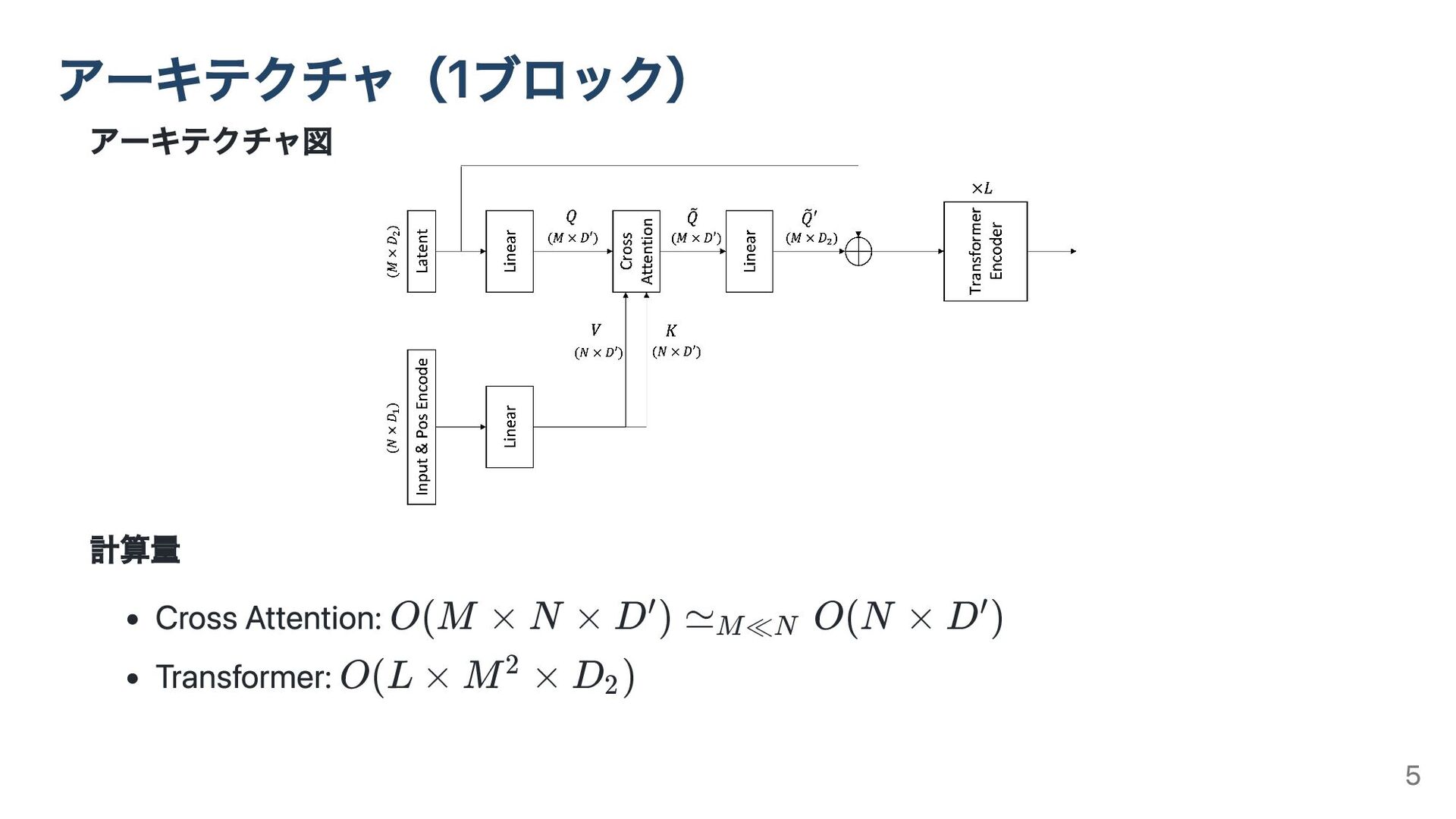
アーキテクチャ図 計算量 Cross Attention: Transformer: アーキテクチャ(1ブロック) O(M × N ×
D ) ≃ ′ M≪N O(N × D ) ′ O(L × M × 2 D ) 2 5
Attentionは入力系列の順序に依存しない Transformerと同様の位置エンコーディングを利用 p = i,2k sin(f πx
) k d p = i,2k+1 cos(f πx ) k d : ハイパーパラメータ : 次元 における位置( ) Transformerと異なり、加算ではなく入力へ連結する 位置エンコーディング f k x d d −1 ∼ 1 6
結果(Image) 7
実験設定 データセット: ImageNet ピクセルレベルの並び替えあり・並び替えなしで実験 評価指標: 予測ラベルの正解率 アーキテクチャ: (CrossAttention + TransformerEncoder
* 6) * 8 入力ベクトル: 50176x3 潜在ベクトル: 512x1024 結果(Image) 8
比較モデル ResNet-50: レイヤー数50のCNNベースモデル ViT-B-16: Transformerベースモデル 入力の処理に16x16の畳み込みを利用 Transformer: 64x64にダウンサンプリングした上で入力 結果(Image -
並び替えなしの場合) 9
結果 モダリティの仮定をせずにベースラインと互角の性能を発揮 ベースラインに位置エンコーディングを入力しても性能は向上しなかった 結果(Image - 並び替えなしの場合) 10
設定 各画像内のピクセルを同一の規則に従って並び替える 帰納バイアスの利用を防ぐ 並び替え前に位置エンコーディングを行う 位置エンコーディングからピクセル同士の関連は学習可能 Learned pos: 位置エンコーディングを学習する inputRF: 入力レイヤーにおける受容野の大きさ
結果(Image - 並び替えありの場合) 11
結果 モダリティを仮定しないTransformerやPerceiverでは性能が悪化しなかった ViTは性能が劣化しづらかった ViTで採用されている畳み込みフィルターはResNet50より大きいから? 最終的にTransformerでパッチ間の関係を見ていることも関係してそう? 結果(Image - 並び替えありの場合) 12
結果(Audio and Video) 13
実験設定 データセット: AudioSet Audio, Video, Audio&Videoで実験 評価指標: meanAveragePrecision アーキテクチャ: (CrossAttention+TransformerEncoder*8)*2
入力ベクトル 生音声: 480x128 メルスペクトログラム: 4800x1 動画: 12544x128 潜在ベクトル: サイズ記載なし 結果(Audio and Video) 14
結果 いずれの入力パターンでもほとんどの比較手法と同等以上の性能 CNN-14に関してはbalancingおよびmixupなどの前処理を除くと性能が下回った Attention AV-fusionとの違いは今後の調査課題 結果(Audio and Video) 15
結果(Point clouds) 16
実験設定 データセット: ModelNet40 評価指標: 予測ラベルの正解率 アーキテクチャ: (CrossAttention+TransformerEncoder*6)*2 入力ベクトル: サイズ記載なし(おそらく単純にflatten?) 潜在ベクトル:
サイズ記載なし 結果(Point cloulds) 17
結果 PointNet++以外の手法より優れていた PointNet++ではドメイン知識に基づいたデータ拡張や特徴量エンジニアリングを行って いるため比較対象としては不適? 結果(Point cloulds) 18
まとめ 19
TransformerベースのPerceiverを提案 Cross-Attentionの利用により、Transformerの計算量を削減 画像・音声・点群いずれにおいても極めて高い性能を発揮 モダリティ特有のデータ拡張や位置エンコーディングへの依存を減らすのが今後の課題 まとめ 20
![Perceiver: General Perception with Iterative Attention [Jaegle, Gimeno+ 2020] 京都大学](https://files.speakerdeck.com/presentations/6999486a794049c3878f67271d8470a6/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}