Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
JAWS-UG クラウド女子会×初心者支部 コラボ会 ~子連れ参加ウェルカム勉強会!
Search
ShigeruOda
February 08, 2026
Technology
100
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
JAWS-UG クラウド女子会×初心者支部 コラボ会 ~子連れ参加ウェルカム勉強会!
JAWS-UG クラウド女子会×初心者支部 コラボ会 ~子連れ参加ウェルカム勉強会!
ShigeruOda
February 08, 2026
More Decks by ShigeruOda
See All by ShigeruOda
AWS re:Invent 2025 Apache Iceberg Recap
shigeruoda
1
110
Amazon Athena で JSON・Parquet・Iceberg のデータを検索し、性能を比較してみた
shigeruoda
1
580
Amazon S3標準/ S3 Tables/S3 Express One Zoneを使ったログ分析
shigeruoda
6
970
CFP選定とタイムテーブル決めについて
shigeruoda
0
200
今年前半のAWSアップデートを振り返り
shigeruoda
0
160
#31 JAWS-UG主催 週刊AWSキャッチアップ (2024/5/6週)
shigeruoda
0
230
#30 JAWS-UG主催 週刊AWSキャッチアップ(2024/4/29週)
shigeruoda
0
190
#28 JAWS-UG主催 週刊AWSキャッチアップ(2024/4/15週)
shigeruoda
0
220
#27 JAWS-UG主催 週刊AWSキャッチアップ(2024/4/8週)
shigeruoda
0
280
Other Decks in Technology
See All in Technology
reFACToring
moznion
0
520
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
1.2k
発表と総括 / Presentations and Summary
ks91
PRO
0
210
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
320
AI時代こそ、スケールしないことをしよう -「作る人」から「なぜ作るか」を考える人へ / Do Things That Don't Scale in the AI Era — From How to Why
kaminashi
1
150
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
880
AI驚き屋発見器
yama3133
1
310
数値で見る Microsoft MVP 〜Spec Kit と GitHub Copilot Agent で作るデータ可視化ダッシュボード〜
yutakaosada
0
150
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
160
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
290
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
210
システム監視入門
grimoh
2
560
Featured
See All Featured
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Believing is Seeing
oripsolob
1
170
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Discover your Explorer Soul
emna__ayadi
2
1.2k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
Technical Leadership for Architectural Decision Making
baasie
3
450
The Invisible Side of Design
smashingmag
301
52k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
280
Transcript
AWS re:Invent 2025 Apache Iceberg Recap JAWS-UG クラウド女子会×初心者支部 コラボ会 ~子連れ参加ウェルカム勉強会!
2025.02.08 1
自己紹介 Name Shigeru Oda Community Japan AWS User Group Beginner's
Branch AWS Community Hero Role Product Infrastructure Technical Lead at Sansan, Inc. 2
お伝えすること Apache Iceberg の基礎 AWS re:Invent 2025 で発表された Apache Iceberg
関連アップデート 3
Apache Iceberg ってなに? Apache Iceberg は「データレイク用のテーブルフォーマット」 S3などのオブジェクトストレージで構成される巨大かつ複雑なテーブルを分散エンジン (Spark、Trino、Flink、Hiveなどから効率良く扱える仕組みを提供します 具体的な機能としては ▪
ACID 保証: トランザクション制御 ▪ スキーマ進化: カラム追加・変更が安全 ▪ タイムトラベル: 過去の状態に遡れる ▪ 高速なメタデータ操作: パーティション管理が効率的 4
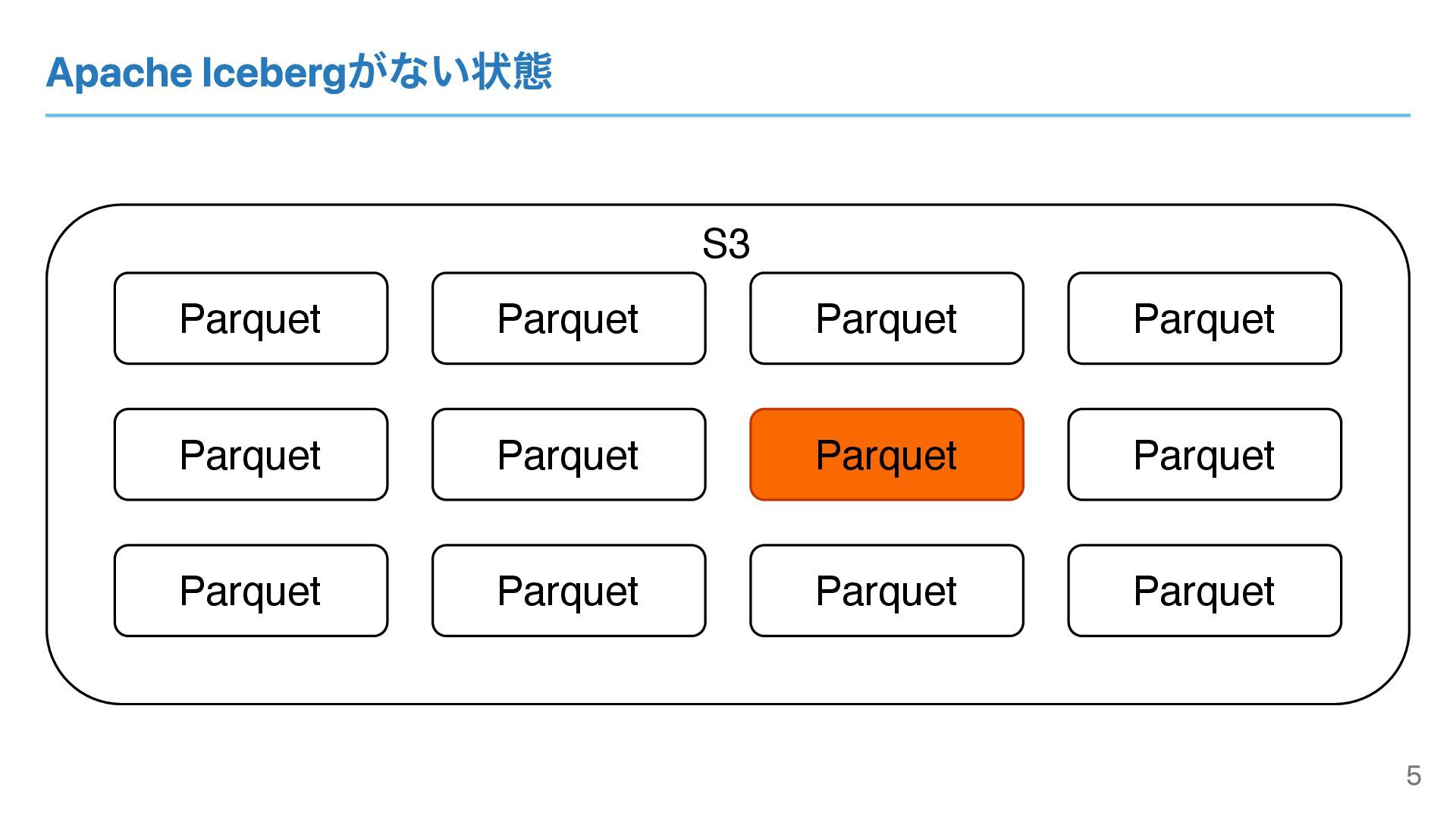
Apache Icebergがない状態 S3 Parquet Parquet Parquet Parquet Parquet Parquet Parquet
Parquet Parquet Parquet Parquet Parquet 5
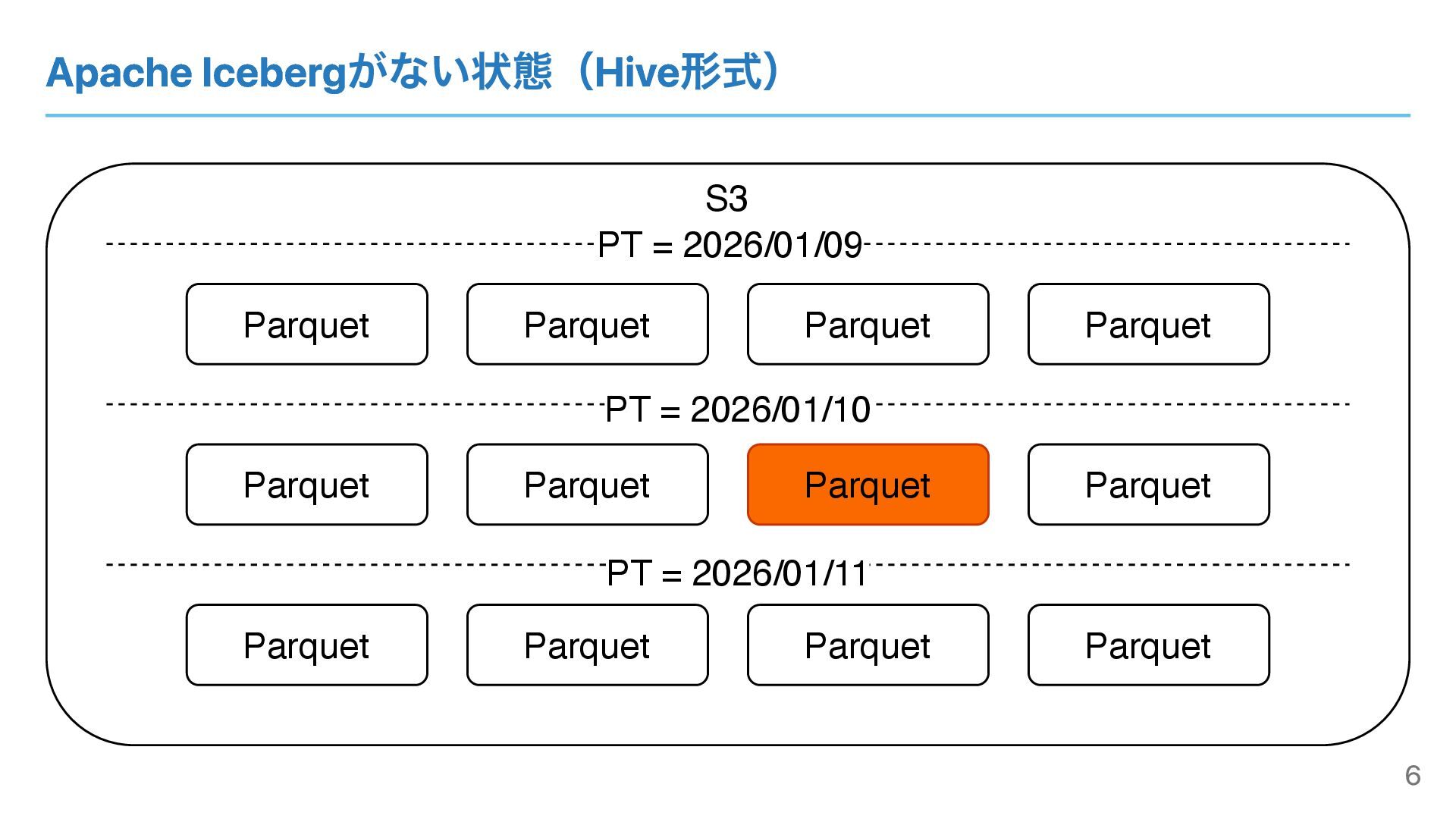
Apache Icebergがない状態(Hive形式) S3 Parquet Parquet Parquet Parquet Parquet Parquet Parquet
Parquet Parquet Parquet Parquet Parquet PT = 2026/01/10 PT = 2026/01/11 PT = 2026/01/09 6
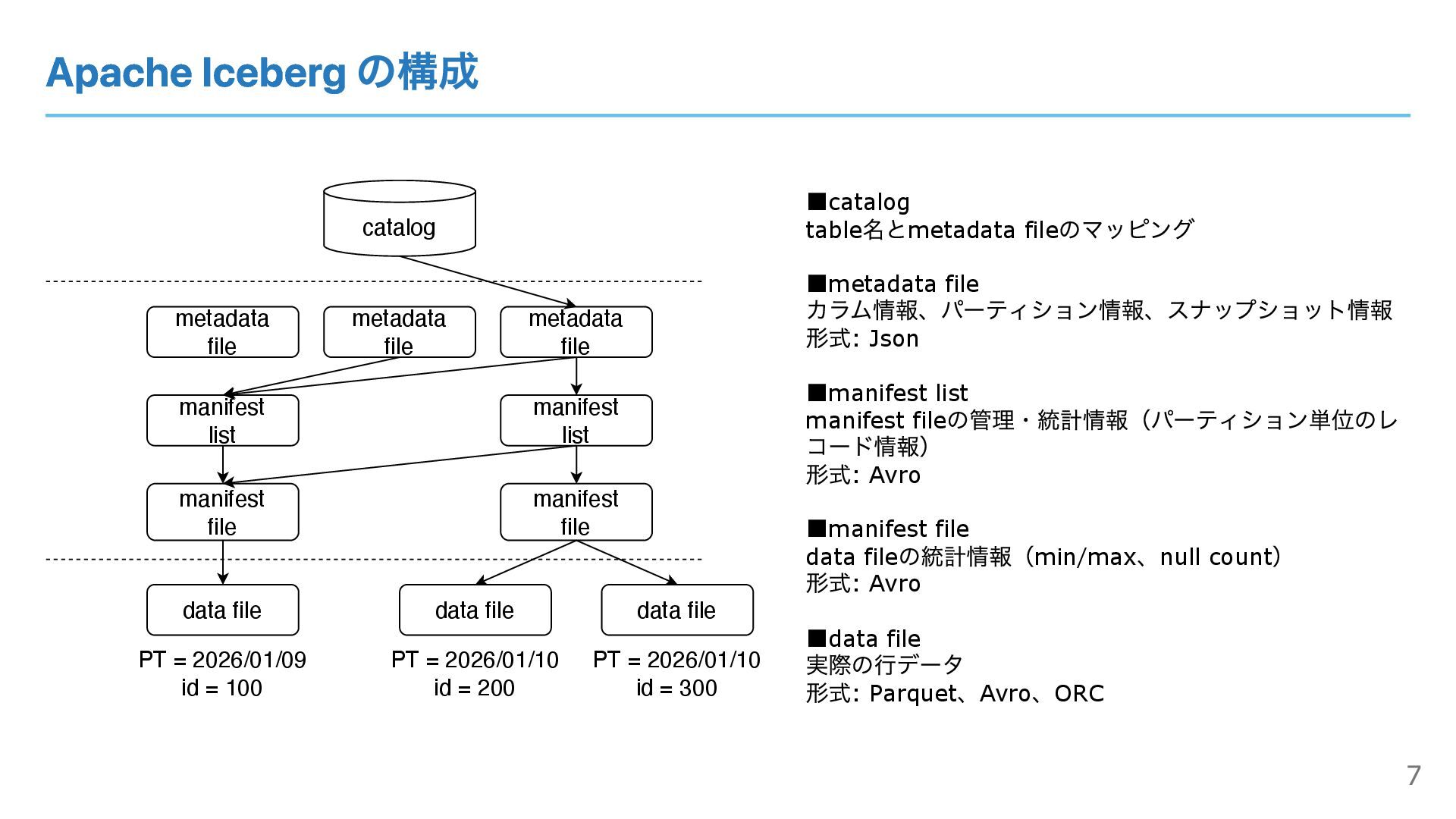
Apache Iceberg の構成 catalog metadata file manifest list manifest file
data file ▪catalog table 名とmetadata file のマッピング ▪metadata file カラム情報、パーティション情報、スナップショット情報 形式: Json ▪manifest list manifest file の管理・統計情報(パーティション単位のレ コード情報) 形式: Avro ▪manifest file data file の統計情報(min/max 、null count ) 形式: Avro ▪data file 実際の⾏データ 形式: Parquet 、Avro 、ORC data file manifest file data file manifest list metadata file PT = 2026/01/09 id = 100 PT = 2026/01/10 id = 200 PT = 2026/01/10 id = 300 metadata file 7
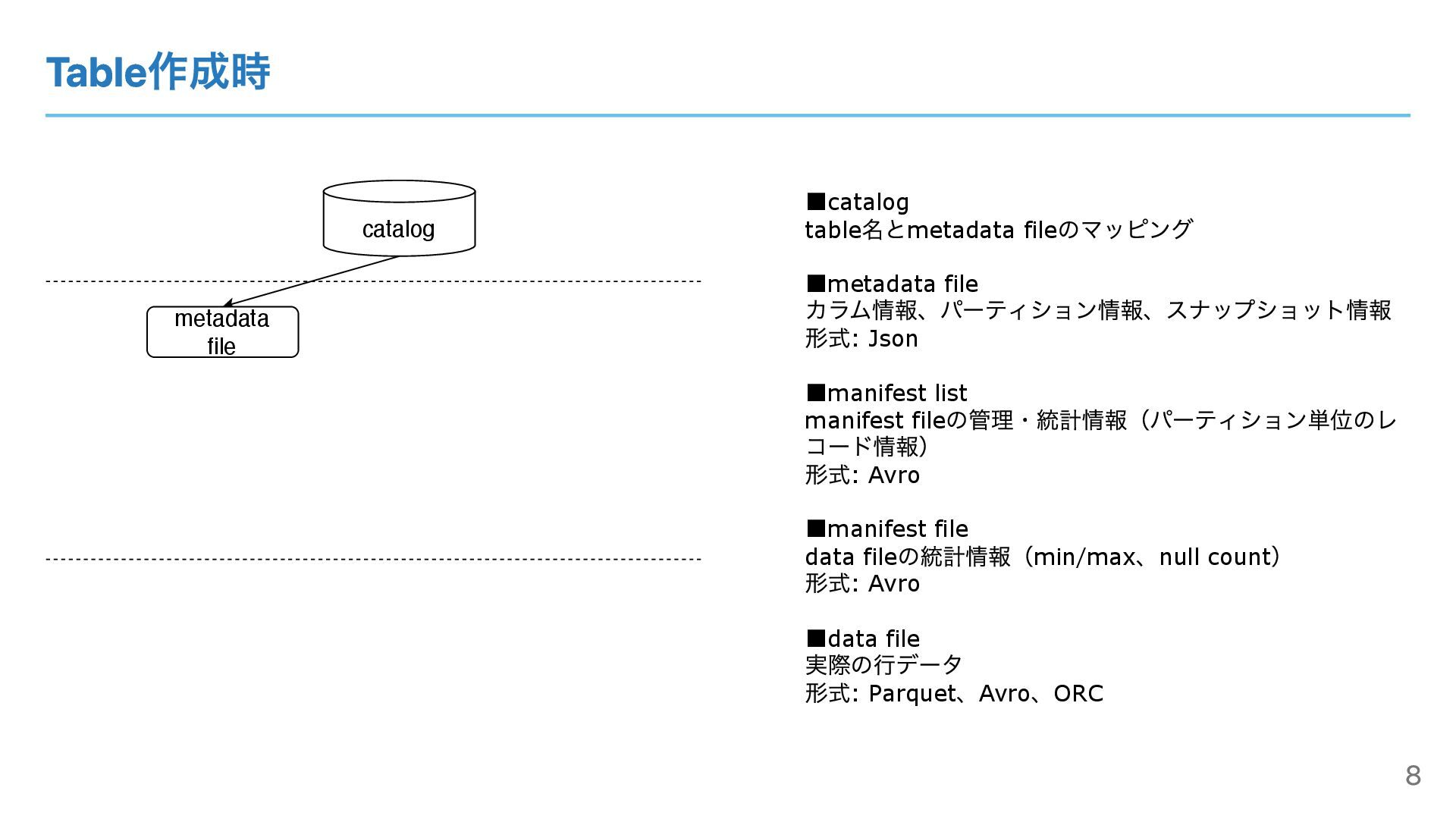
Table作成時 catalog ▪catalog table 名とmetadata file のマッピング ▪metadata file カラム情報、パーティション情報、スナップショット情報
形式: Json ▪manifest list manifest file の管理・統計情報(パーティション単位のレ コード情報) 形式: Avro ▪manifest file data file の統計情報(min/max 、null count ) 形式: Avro ▪data file 実際の⾏データ 形式: Parquet 、Avro 、ORC metadata file 8
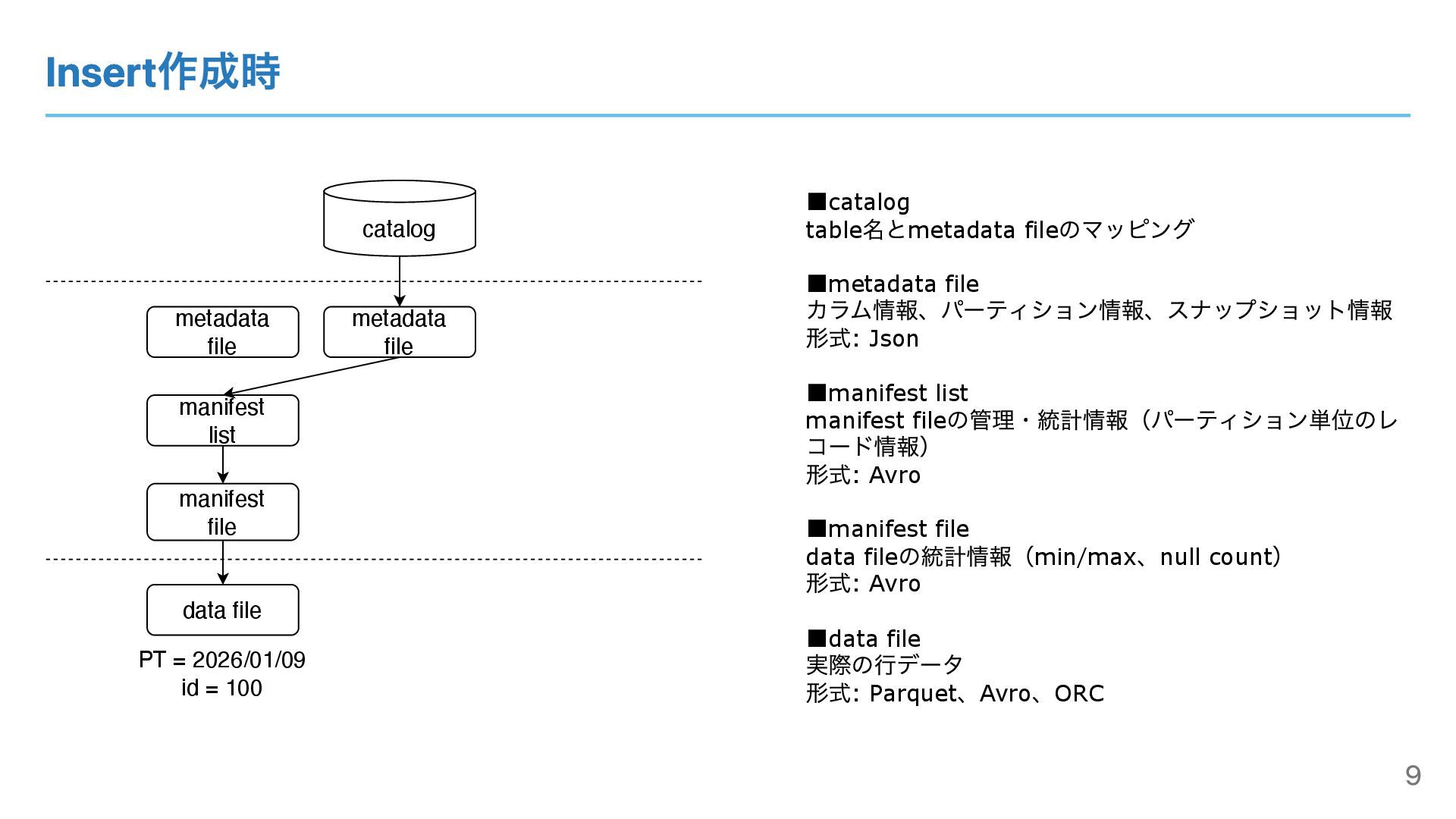
Insert作成時 catalog metadata file ▪catalog table 名とmetadata file のマッピング ▪metadata
file カラム情報、パーティション情報、スナップショット情報 形式: Json ▪manifest list manifest file の管理・統計情報(パーティション単位のレ コード情報) 形式: Avro ▪manifest file data file の統計情報(min/max 、null count ) 形式: Avro ▪data file 実際の⾏データ 形式: Parquet 、Avro 、ORC manifest file data file manifest list metadata file PT = 2026/01/09 id = 100 9
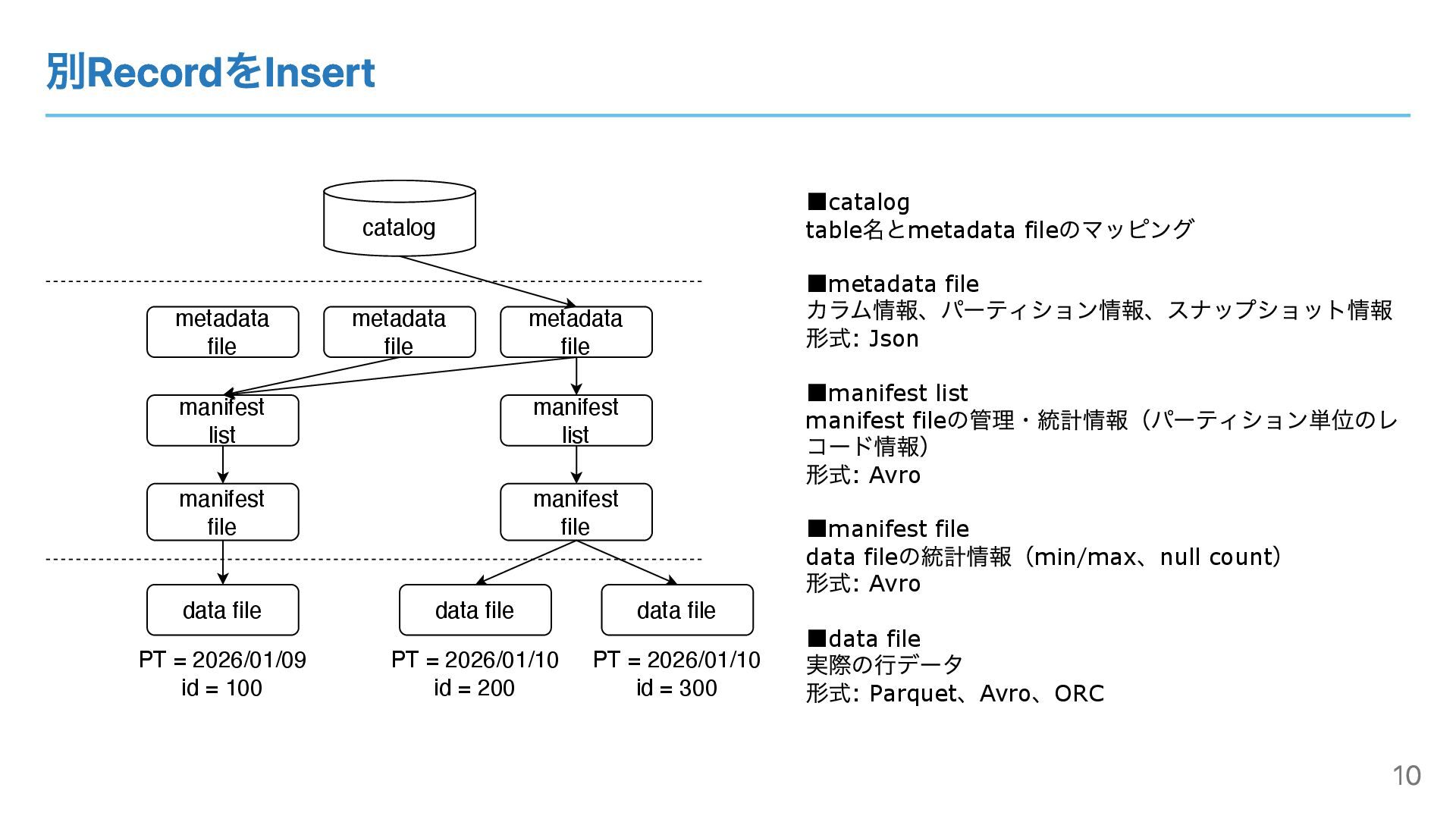
別RecordをInsert catalog metadata file manifest list manifest file data file
▪catalog table 名とmetadata file のマッピング ▪metadata file カラム情報、パーティション情報、スナップショット情報 形式: Json ▪manifest list manifest file の管理・統計情報(パーティション単位のレ コード情報) 形式: Avro ▪manifest file data file の統計情報(min/max 、null count ) 形式: Avro ▪data file 実際の⾏データ 形式: Parquet 、Avro 、ORC data file manifest file data file manifest list metadata file PT = 2026/01/09 id = 100 PT = 2026/01/10 id = 200 metadata file PT = 2026/01/10 id = 300 10
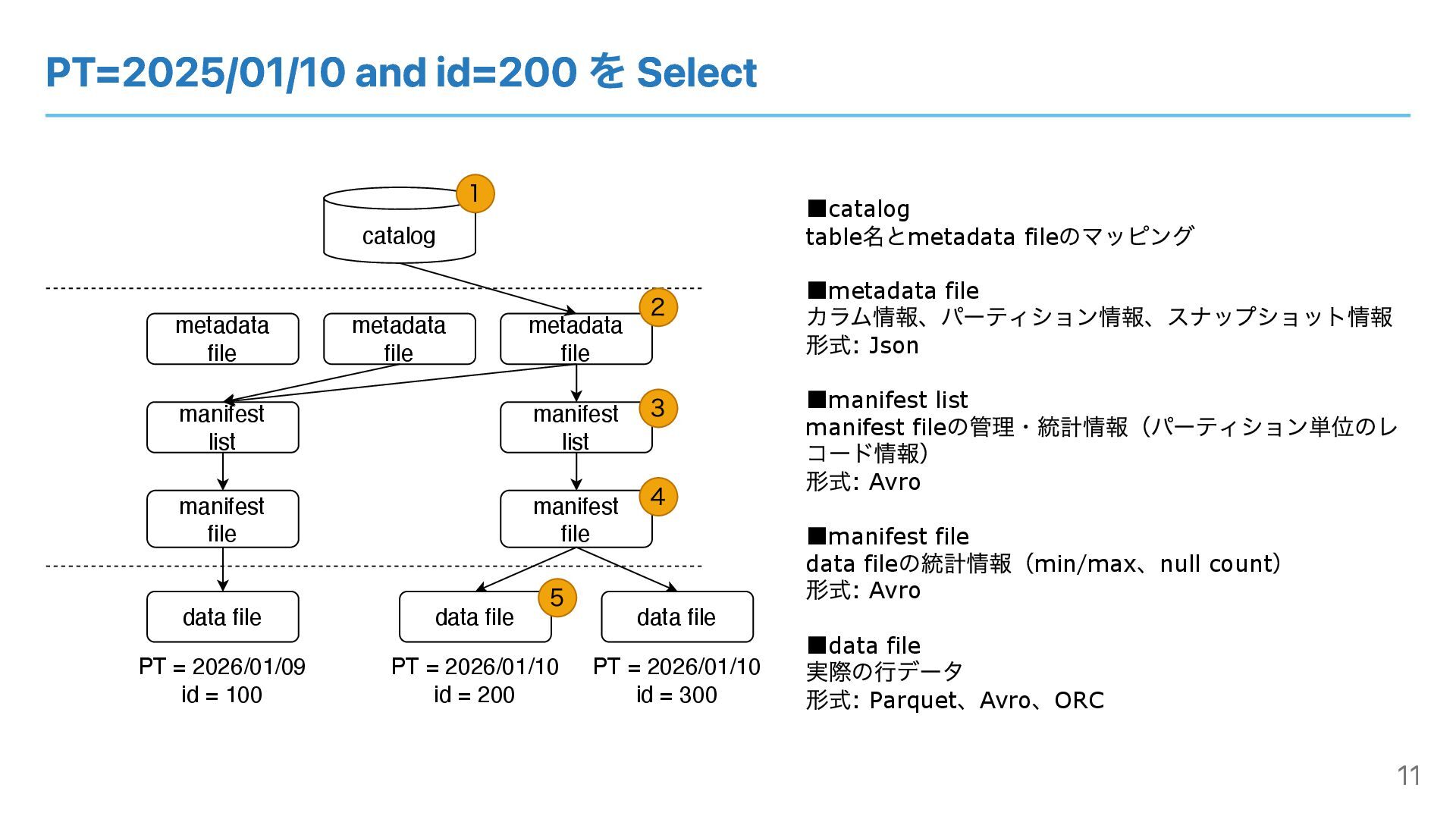
PT=2025/01/10 and id=200 を Select catalog metadata file manifest list
manifest file data file ▪catalog table 名とmetadata file のマッピング ▪metadata file カラム情報、パーティション情報、スナップショット情報 形式: Json ▪manifest list manifest file の管理・統計情報(パーティション単位のレ コード情報) 形式: Avro ▪manifest file data file の統計情報(min/max 、null count ) 形式: Avro ▪data file 実際の⾏データ 形式: Parquet 、Avro 、ORC data file manifest file data file manifest list metadata file PT = 2026/01/09 id = 100 PT = 2026/01/10 id = 200 PT = 2026/01/10 id = 300 metadata file 1 2 3 4 5 11
Apache Iceberg 関連のアップデート その1 Intelligent Tiering for Amazon S3 Tables
アクセス頻度が低いデータを低コストで保存できるようになりました。 Automatic replication of Amazon S3 Tables S3 Tables のデータを別リージョン or 別アカウントにレプリケーション出来るよう になりました。 Amazon S3 Storage Lens enhancements Storage Lens 結果を S3 Table に Export 出来るようになりました。 Iceberg catalog federation for AWS Glue リモートカタログ(Snowflake、Databricks、etc)で管理されているデータを参照で きるようになりました。 (実データは S3 が前提) 12
Apache Iceberg 関連のアップデート その2 Amazon Redshift writes to Apache Iceberg
Redshift から Apache Iceberg に書き込みが出来るようになりました。 (Insert のみ) Unified management in CloudWatch 3rd Party log や CloudTrail などのログを CloudWatch Logs に流せるようになりまし た。 CloudWatch Logs から S3 Table に流せるようになりました。 Deletion vectors and row lineage in Iceberg for EMR データ削除時のコストを削減できるようになりました。 データ更新の履歴を辿れるようになりました。 13
deletion vectors 削除ベクトル 14
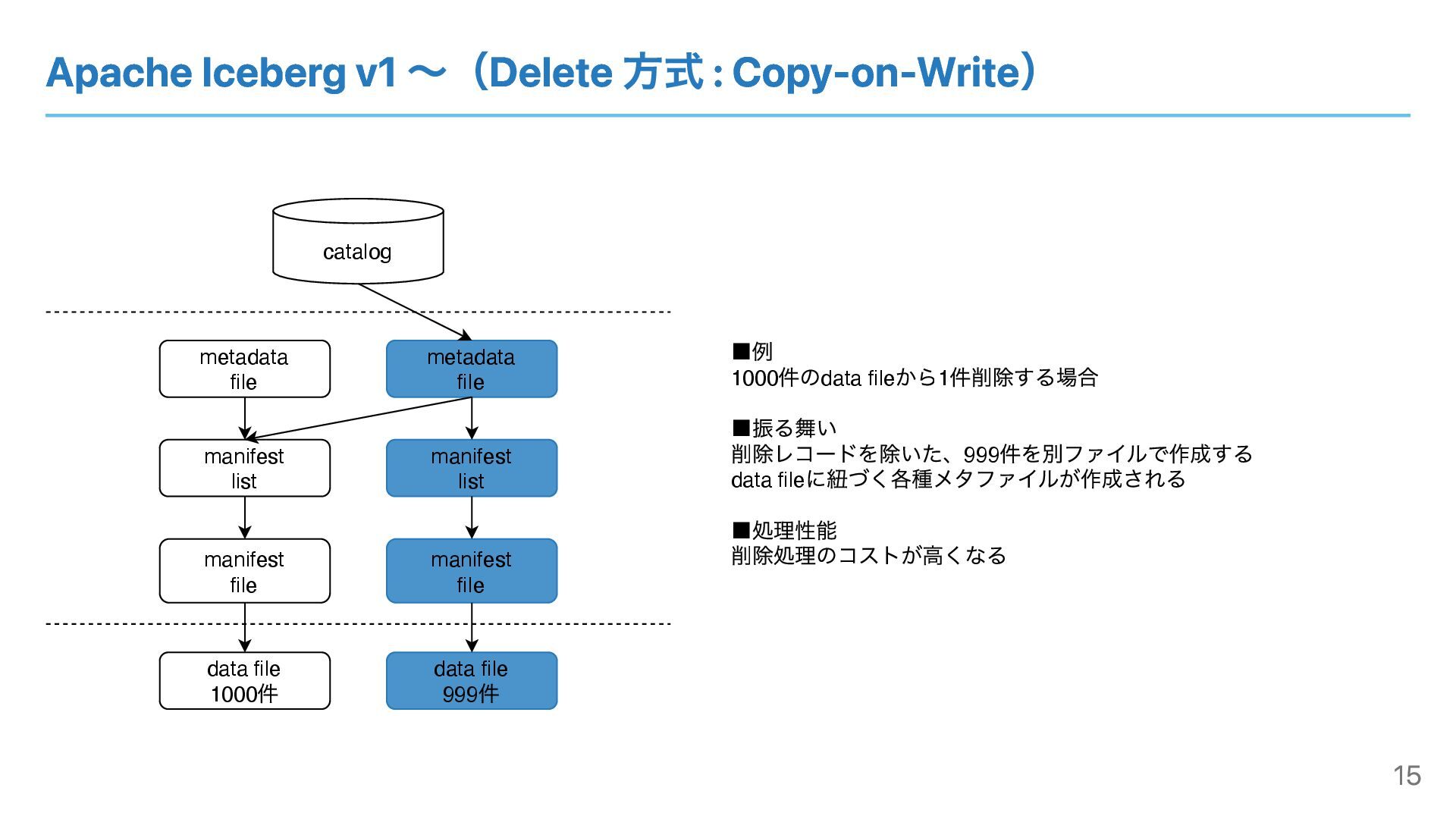
Apache Iceberg v1 〜(Delete 方式 : Copy-on-Write) catalog metadata file
manifest list manifest file data file 1000 件 ▪例 1000 件のdata file から1 件削除する場合 ▪振る舞い 削除レコードを除いた、999 件を別ファイルで作成する data file に紐づく各種メタファイルが作成される ▪処理性能 削除処理のコストが⾼くなる data file 999 件 metadata file manifest list manifest file 15
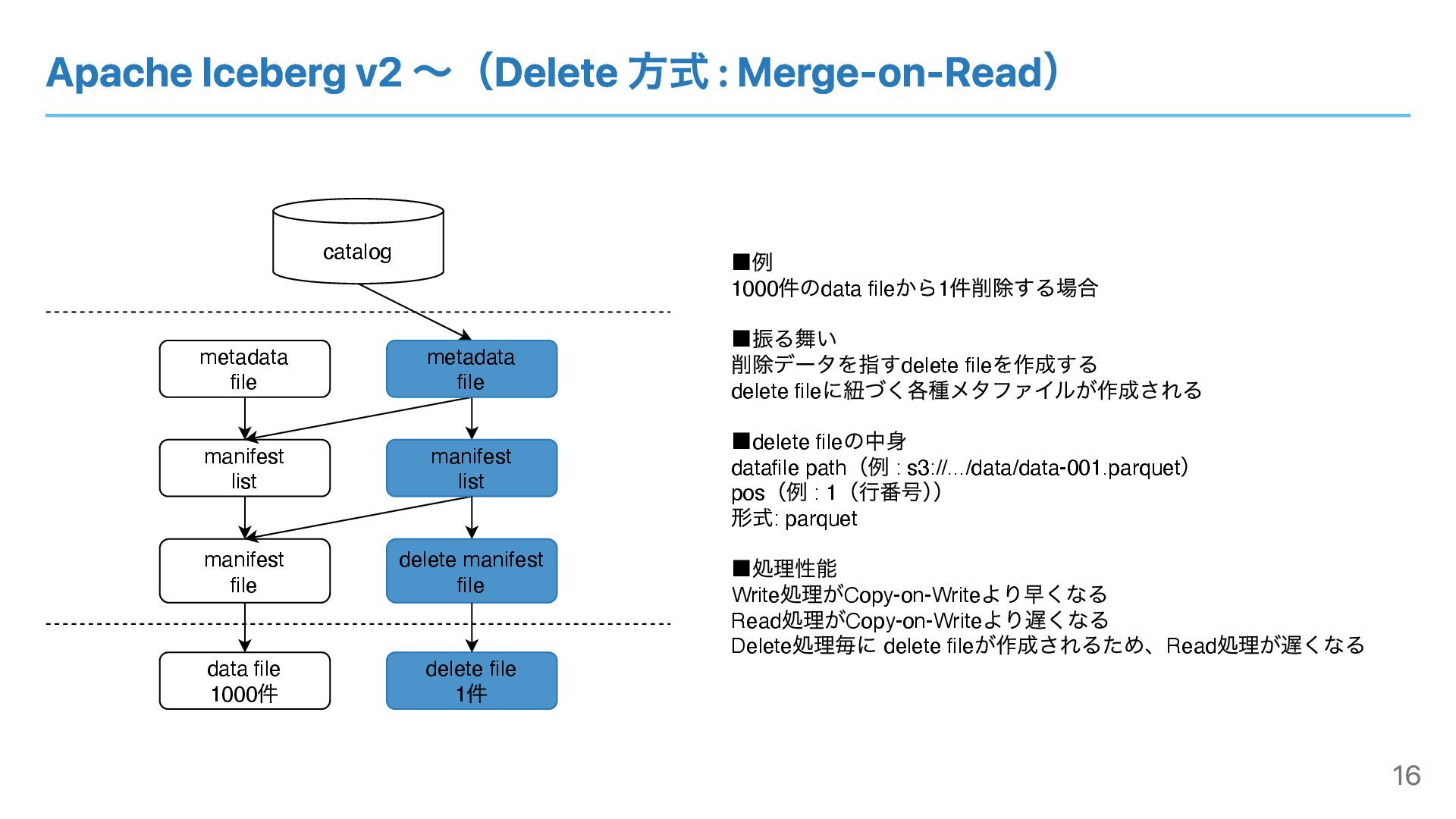
Apache Iceberg v2 〜(Delete 方式 : Merge-on-Read) catalog metadata file
manifest list manifest file data file 1000 件 ▪例 1000 件のdata file から1 件削除する場合 ▪振る舞い 削除データを指すdelete file を作成する delete file に紐づく各種メタファイルが作成される ▪delete file の中⾝ datafile path (例 : s3://.../data/data-001.parquet ) pos (例 : 1 (⾏番号) ) 形式: parquet ▪処理性能 Write 処理がCopy-on-Write より早くなる Read 処理がCopy-on-Write より遅くなる Delete 処理毎に delete file が作成されるため、Read 処理が遅くなる delete file 1 件 metadata file manifest list delete manifest file 16
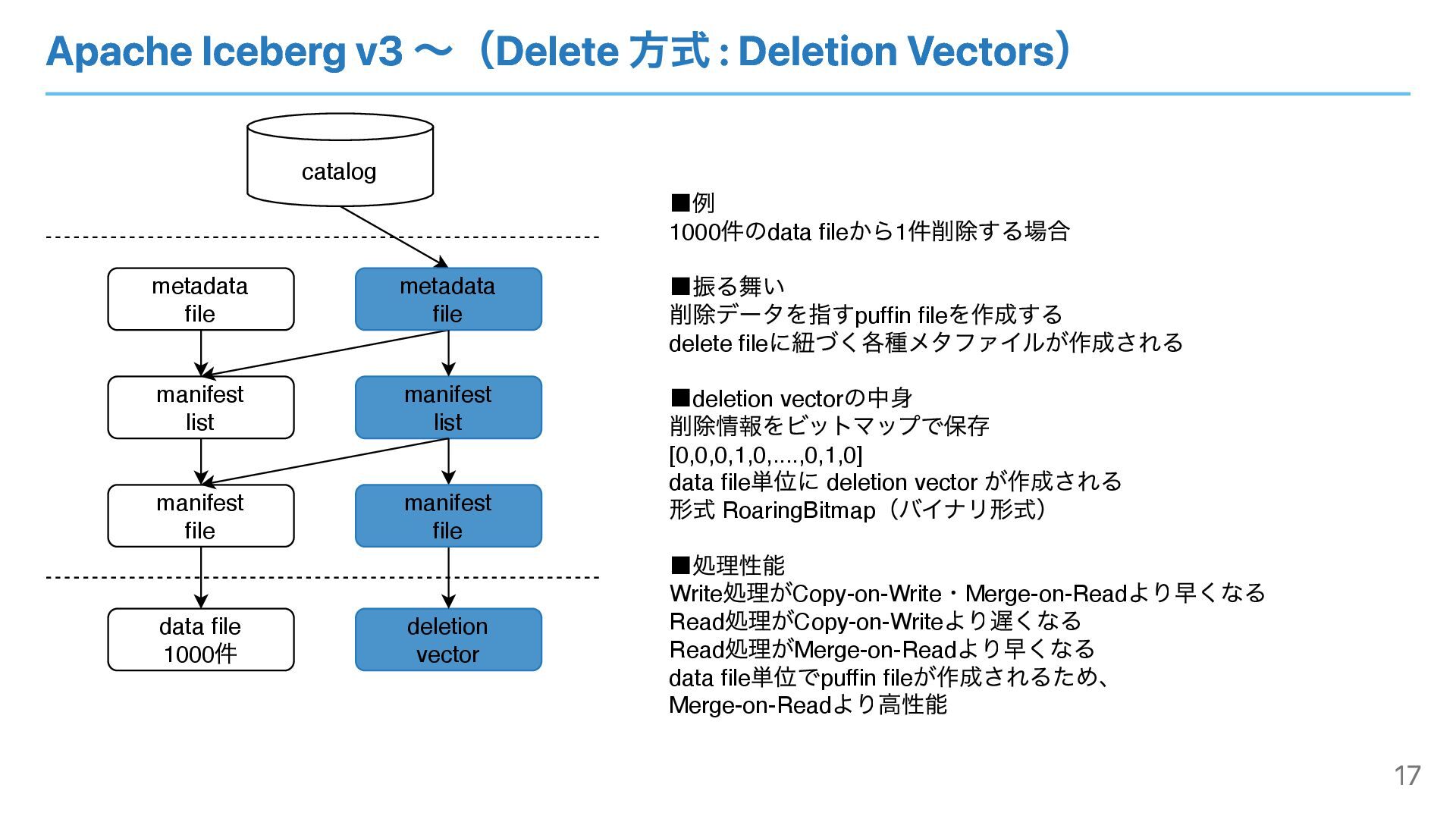
Apache Iceberg v3 〜(Delete 方式 : Deletion Vectors) catalog metadata
file manifest list manifest file data file 1000 件 deletion vector metadata file manifest list ▪例 1000 件のdata file から1 件削除する場合 ▪振る舞い 削除データを指すpuffin file を作成する delete file に紐づく各種メタファイルが作成される ▪deletion vector の中⾝ 削除情報をビットマップで保存 [0,0,0,1,0,....,0,1,0] data file 単位に deletion vector が作成される 形式 RoaringBitmap (バイナリ形式) ▪処理性能 Write 処理がCopy-on-Write ・Merge-on-Read より早くなる Read 処理がCopy-on-Write より遅くなる Read 処理がMerge-on-Read より早くなる data file 単位でpuffin file が作成されるため、 Merge-on-Read より⾼性能 manifest file 17
性能検証 目的 1000 万件のデータから、10 万件を 10 セット削除する 削除処理、および、参照処理の性能検証を行う 環境 プラットフォーム:
Amazon EMR Serverless 7.12 Spark バージョン: 3.5.6-amzn-1 アーキテクチャ: x86_64 キャパシティ: 400 vCPUs, 3000 GB memory, 20000 GB disk(デフォルト) ストレージ: S3 バケット 18
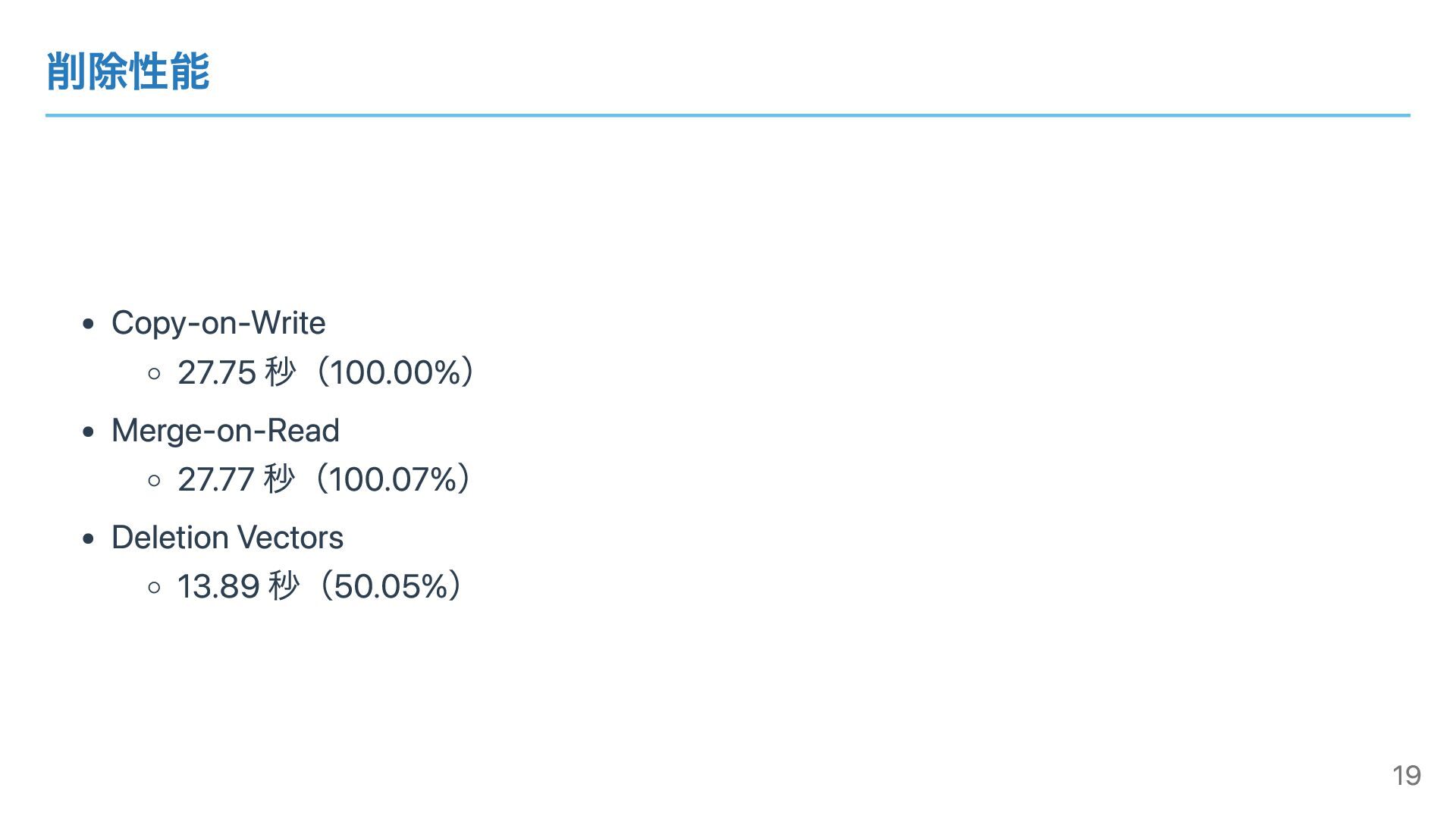
削除性能 Copy-on-Write 27.75 秒(100.00%) Merge-on-Read 27.77 秒(100.07%) Deletion Vectors 13.89
秒(50.05%) 19
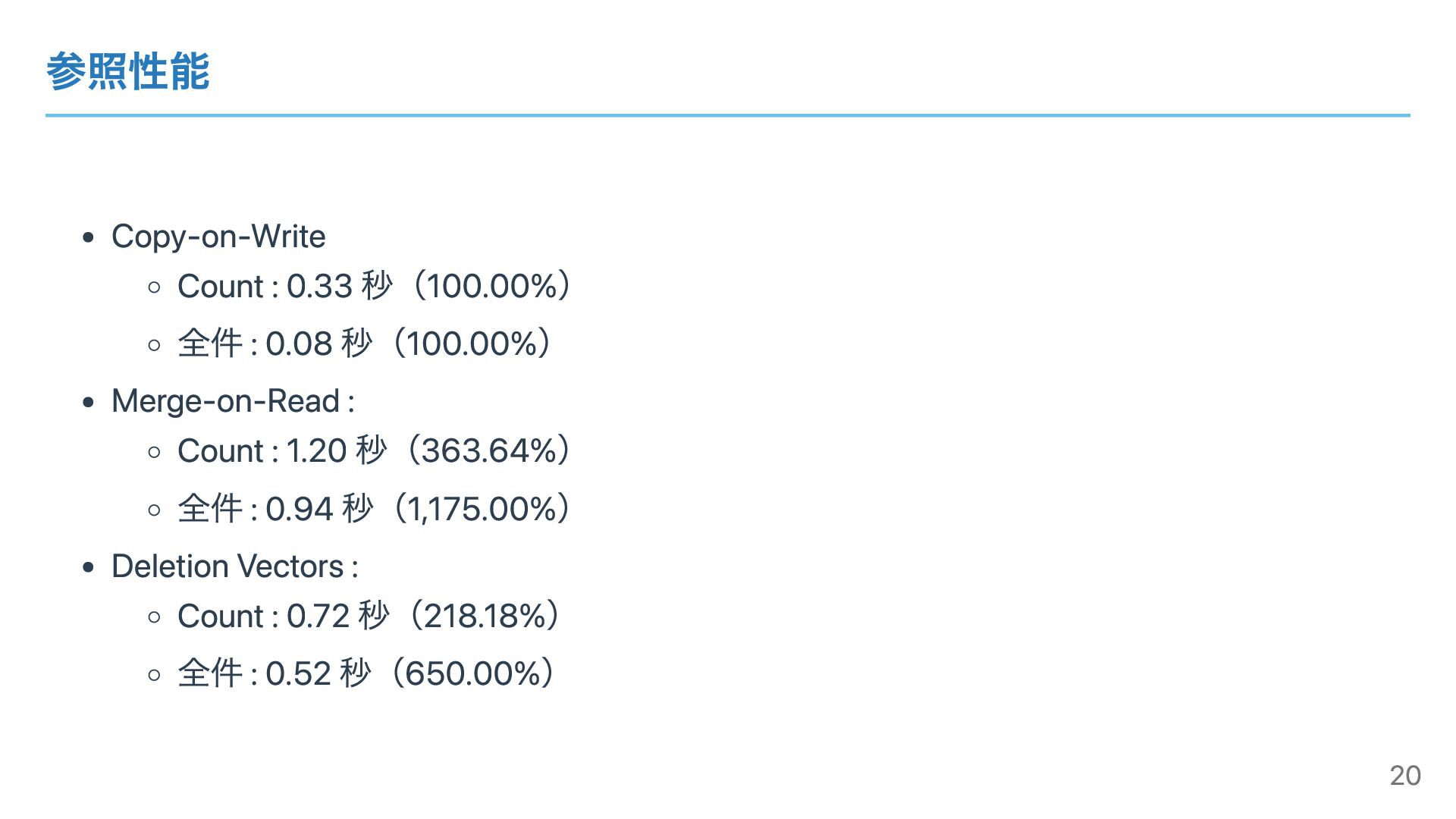
参照性能 Copy-on-Write Count : 0.33 秒(100.00%) 全件 : 0.08 秒(100.00%)
Merge-on-Read : Count : 1.20 秒(363.64%) 全件 : 0.94 秒(1,175.00%) Deletion Vectors : Count : 0.72 秒(218.18%) 全件 : 0.52 秒(650.00%) 20
性能評価 削除・更新中心のワークロードでは Deletion Vectors 削除性能が高い(CoW/MoR の約 2 倍高速) 読み取り性能も v2
MoR より大幅に高速 スケールしやすい 読み取り中心のワークロードでは Copy-on-Write 読み取り性能が最も高い ただし、削除・更新には時間がかかる点に注意 21
最後に 今後も Apache Iceberg を中心とした Data Lake 整備が進んで行くと考えています。 データ整備の1案としてご利用ください 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}