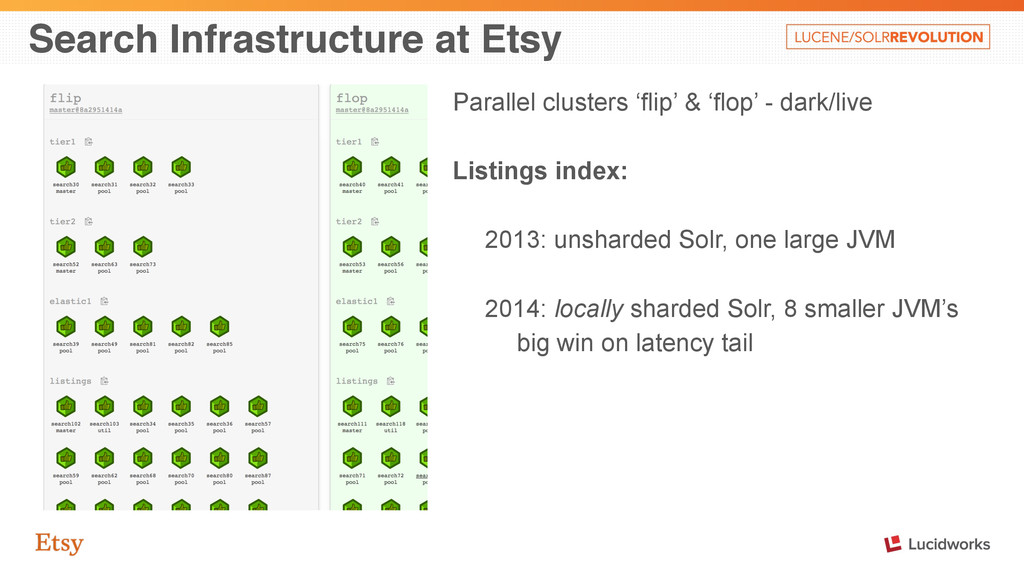
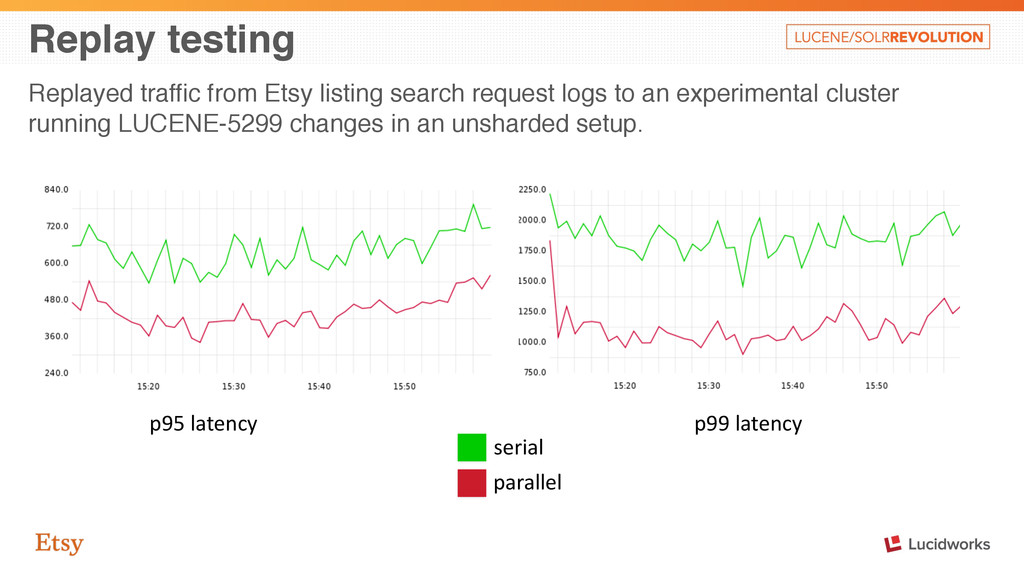
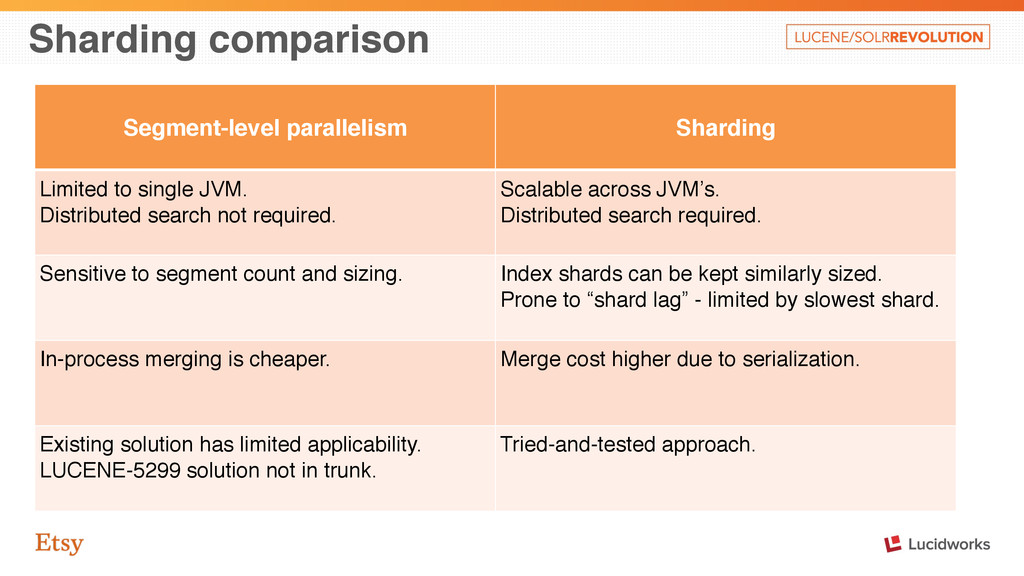
some examples: • More moving parts and failure modes to deal with • Missing features with distributed search • Index statistics on shards can vary, distorting IDF Tempting to defer sharding if not necessary due to index size.
abstraction. • Invoked for every hit that matches the Query. • Has the Scorer available to get the score for current hit if needed. • Output - e.g. top N hits, number of hits, grouped hits - can be retrieved when done.
matches the query. Can expect a lot of contention! protected void search( List<LeafReaderContext> leaves, Weight weight, Collector collector ) throws IOException { // TODO: should we make this // threaded...? the Collector could be sync'd? // always use single thread: for (LeafReaderContext ctx : leaves) { // search each subreader … IndexSearcher.java
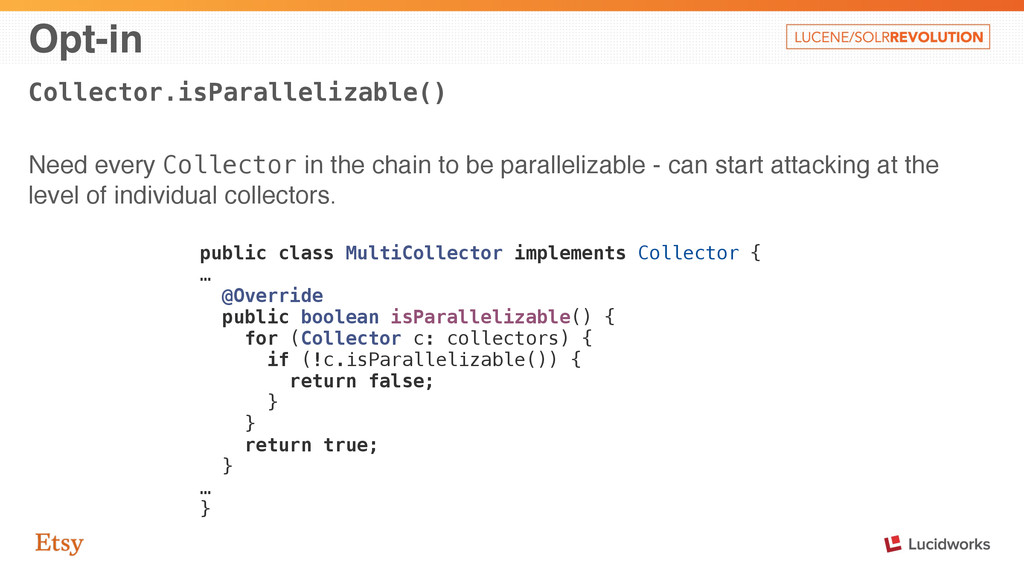
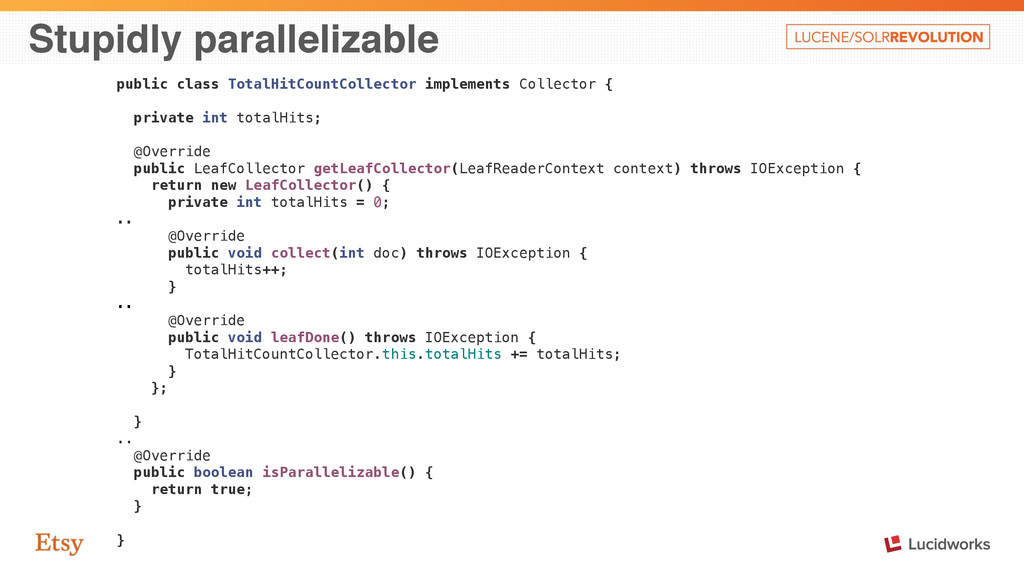
parallelizable - can start attacking at the level of individual collectors. public class MultiCollector implements Collector { … @Override public boolean isParallelizable() { for (Collector c: collectors) { if (!c.isParallelizable()) { return false; } } return true; } … }
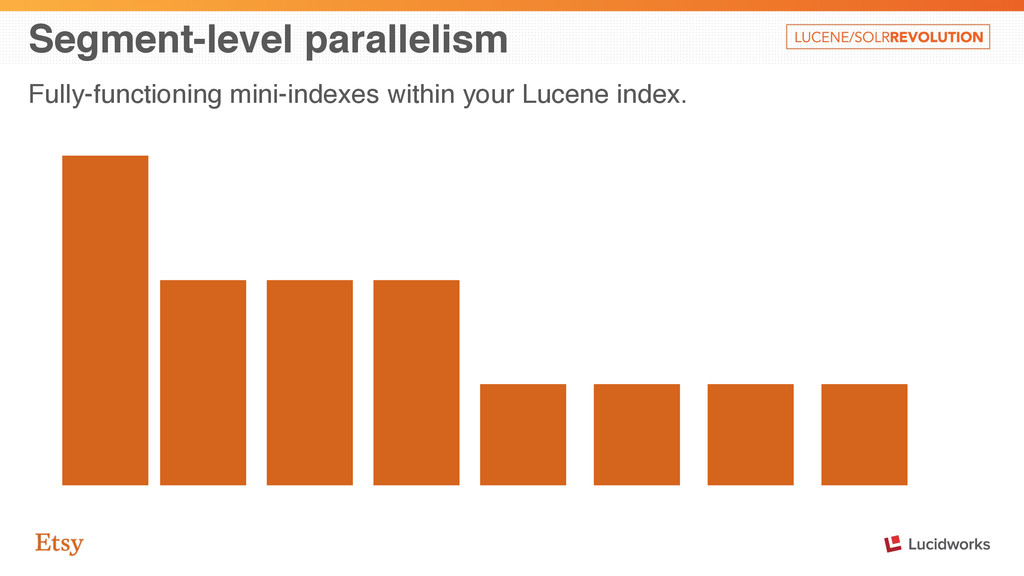
and segment-level. • Collection is also segment-level, but typically computes its outcome as shared state between leafs e.g. TopDocs over your index. • By making Collector API parallelism-friendly, we can parallelize search as a whole.
- internally a long[] To address possible race condition at segment boundaries, when parallelized: • collect() first and last 64 document ID’s for the segment into LeafCollector- private longs, all others into shared bitset. • when leafDone() merge these boundary document ID’s into shared bitset. leaf docBase maxDoc docId range 0 0 42 [0 -‐ 41] 1 42 20 [42 -‐ 61]
serial case. When parallelized: • More memory: lazy pool of HitQueue - grab when getLeafCollector(), return when leafDone(), merge when done(). • More computation: in addition to the merge step - less likely to immediately discard hits that won’t eventually make it, as using multiple priority queues.
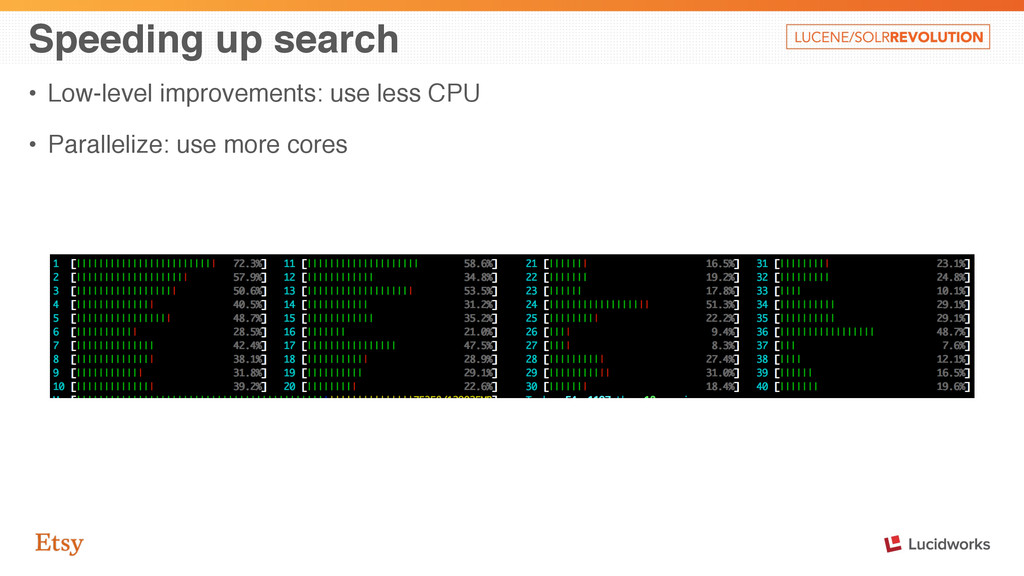
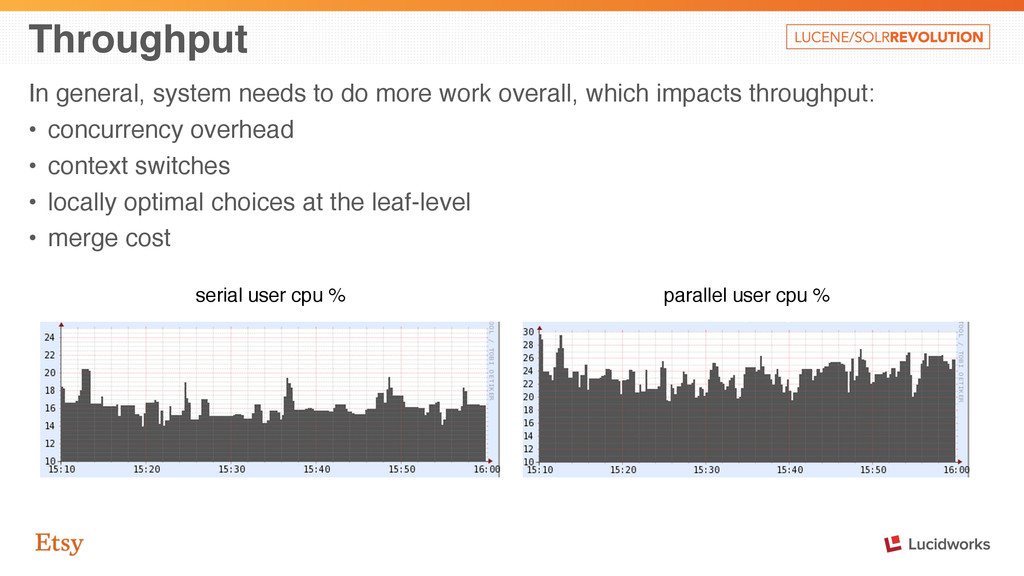
which impacts throughput: • concurrency overhead • context switches • locally optimal choices at the leaf-level • merge cost serial user cpu % parallel user cpu %
search not required. Scalable across JVM’s. Distributed search required. Sensitive to segment count and sizing. Index shards can be kept similarly sized. Prone to “shard lag” - limited by slowest shard. In-process merging is cheaper. Merge cost higher due to serialization. Existing solution has limited applicability. LUCENE-5299 solution not in trunk. Tried-and-tested approach.
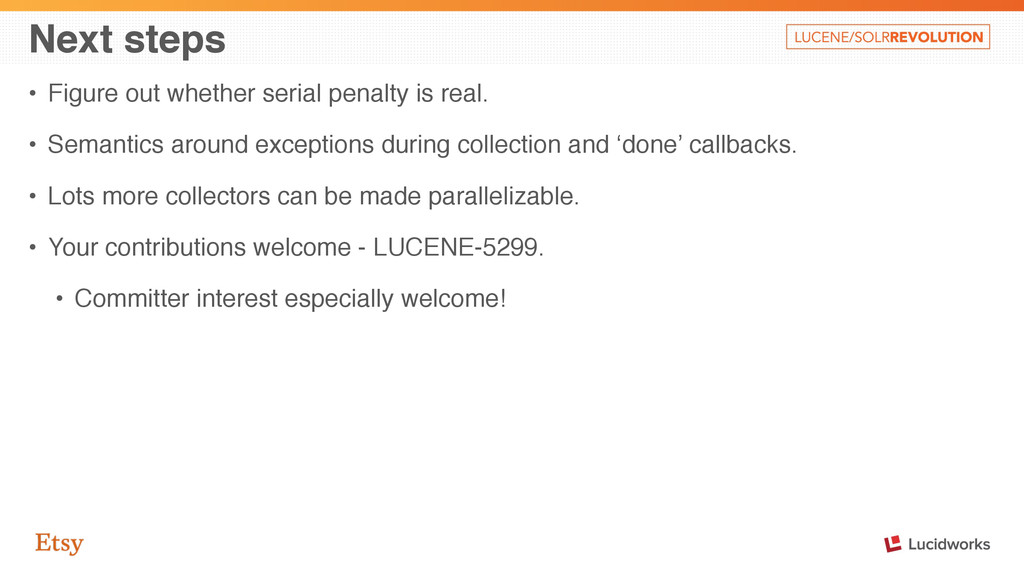
• Semantics around exceptions during collection and ‘done’ callbacks. • Lots more collectors can be made parallelizable. • Your contributions welcome - LUCENE-5299. • Committer interest especially welcome!
{kind=link}
![Search-time Parallelism Shikhar Bhushan, Etsy Inc. [email protected] @shikhrr](https://files.speakerdeck.com/presentations/25ed0199886849d5ba7744370d27250b/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks Shikhar Bhushan [email protected] @shikhrr codeascraft.com etsy.com/careers](https://files.speakerdeck.com/presentations/25ed0199886849d5ba7744370d27250b/slide_34.jpg){kind=link}