モンスターストライクにおけるメトリクス監視、死活監視についての話です。
以下のイベントの登壇資料になります。
◆うちのDevOps事情〜大規模サービスのモニタリングあれこれ〜
DevOpsについての進捗共有をする「うちのDevOps事情」シリーズ。
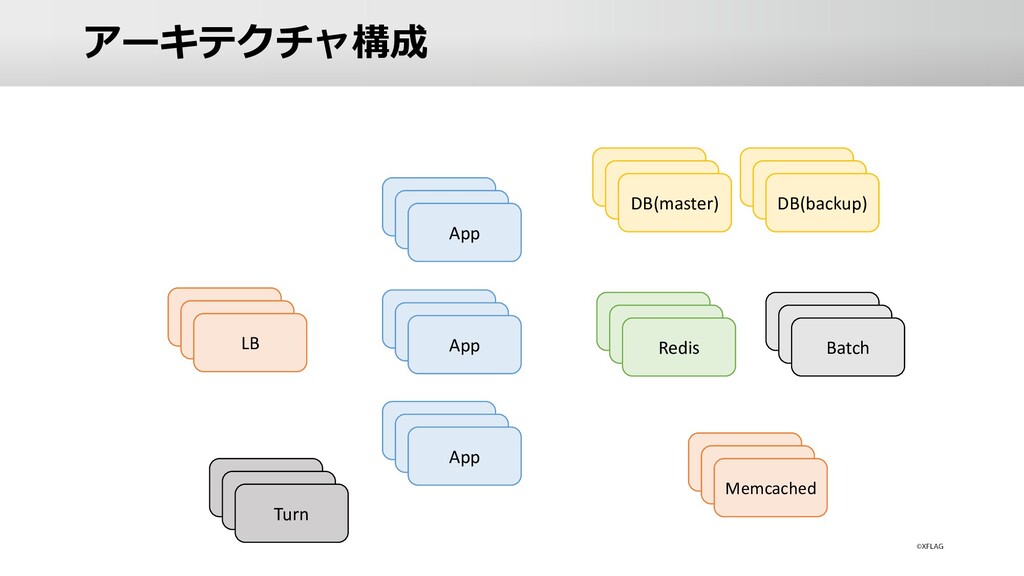
今回のテーマは【大規模サービスのモニタリング】です。
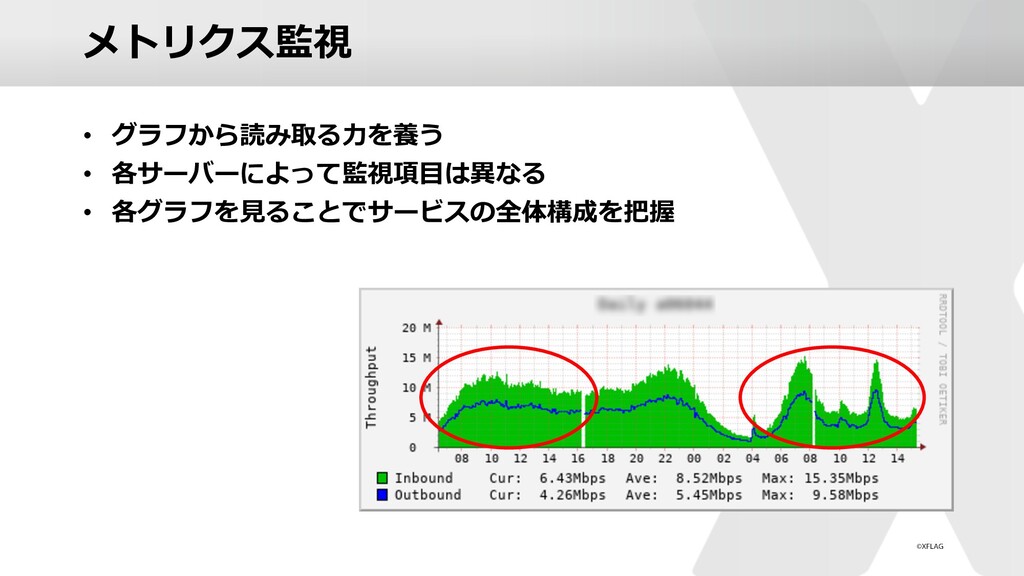
どのような項目を監視/モニタリングするのか?
利用ツールを選択した理由とは?そのツール利用した結果どうだった?
運用しながら改善していく時の優先順位の付け方は?
など、DevOpsを推進していくときに参考にしていただきたい事例を4名からお伝えします!
https://techplay.jp/event/765163
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
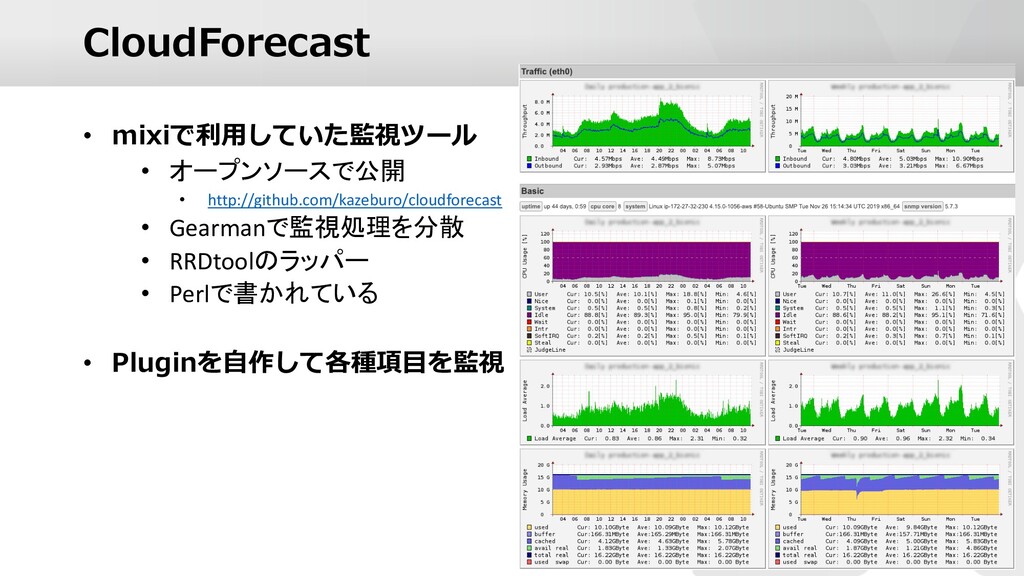{kind=link}
{kind=link}
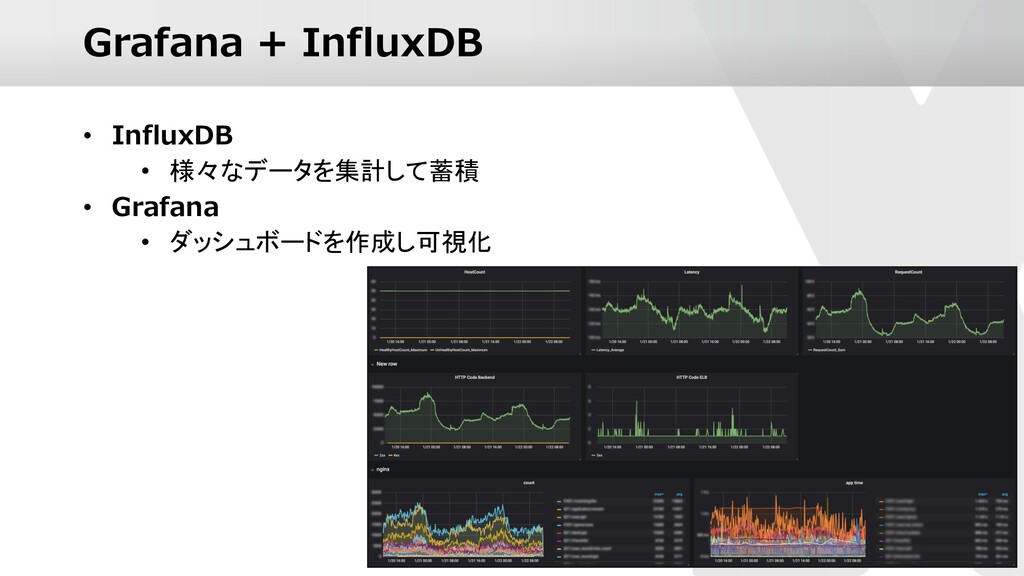{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
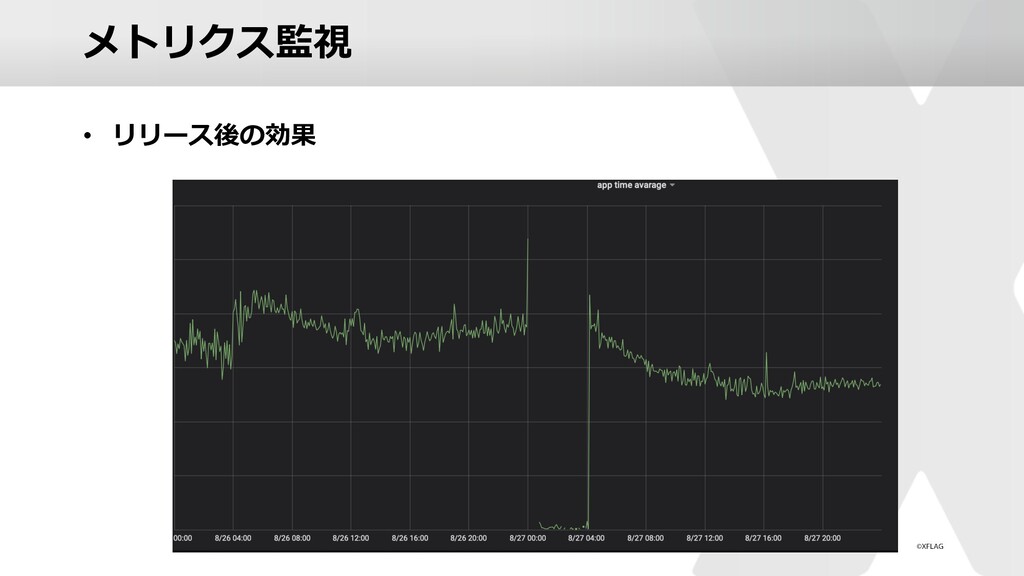{kind=link}
{kind=link}
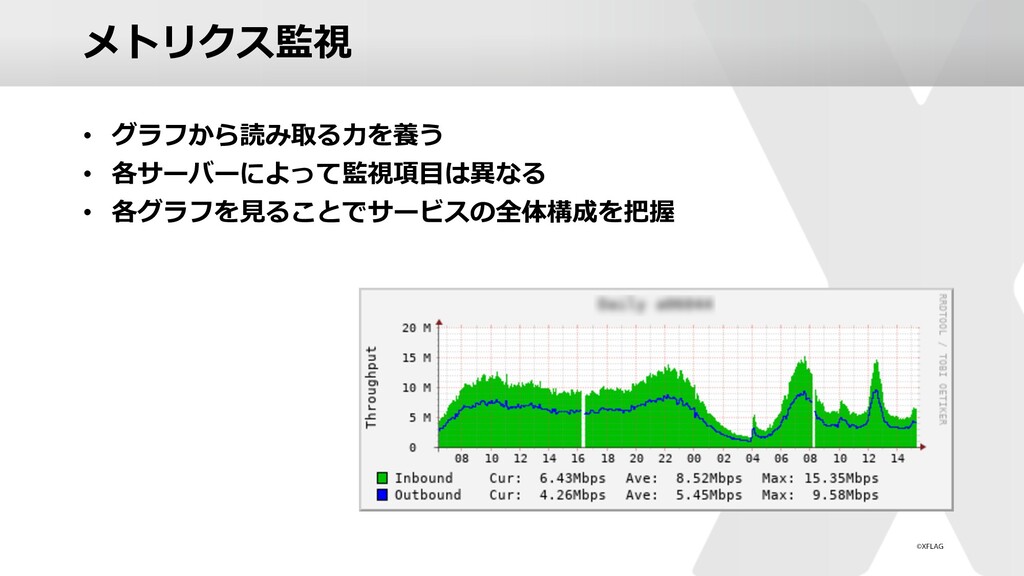{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}