Share
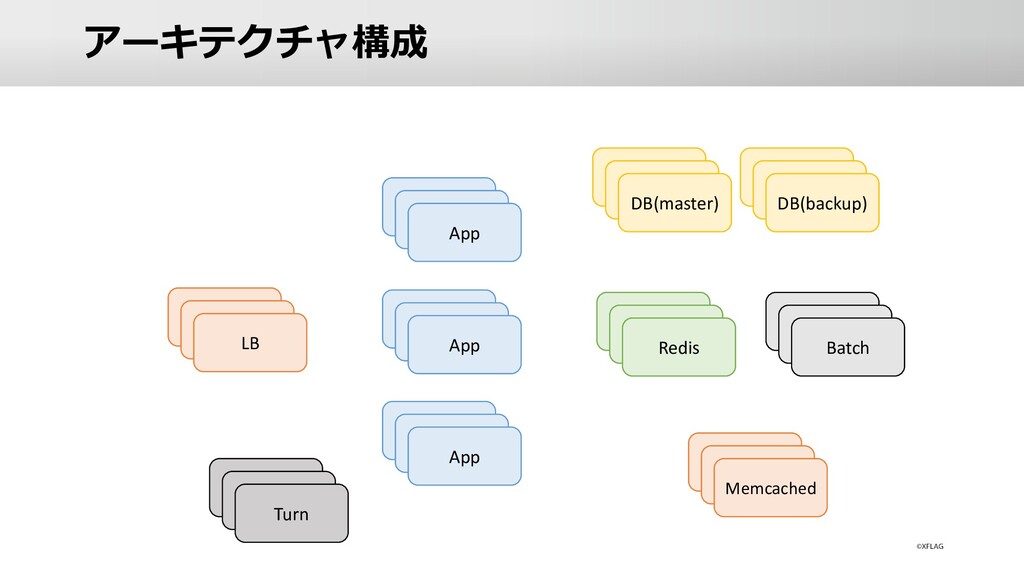
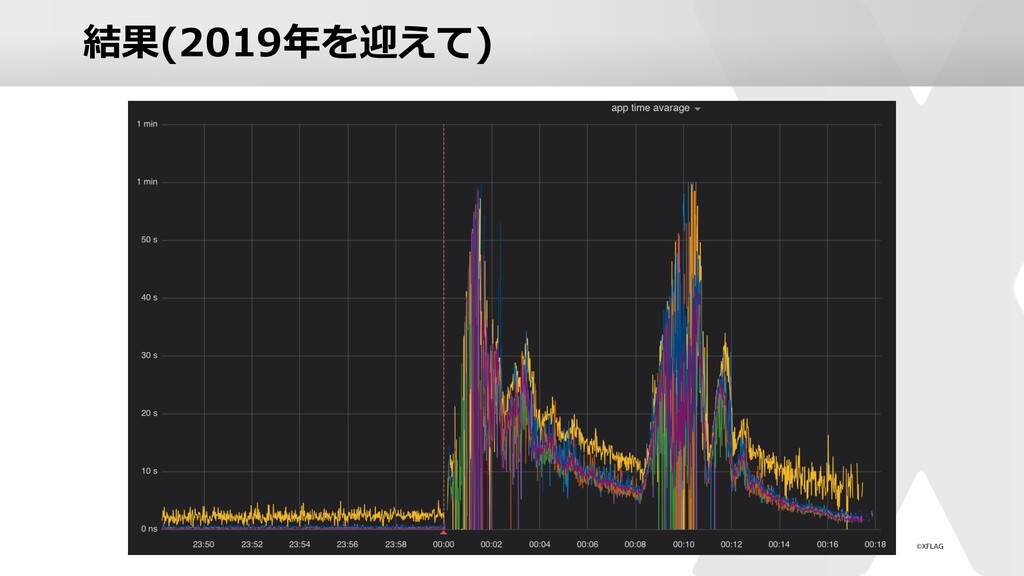
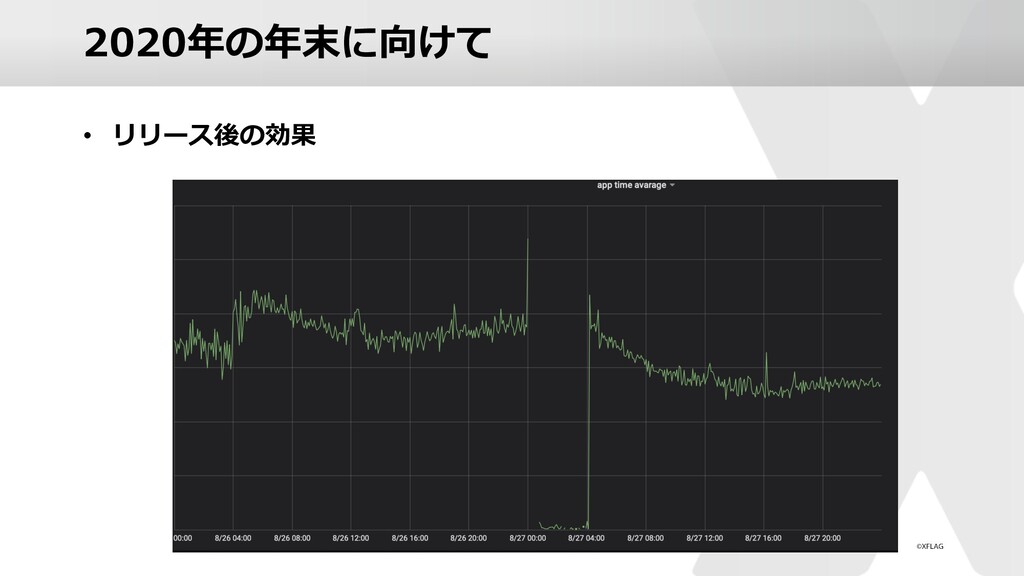
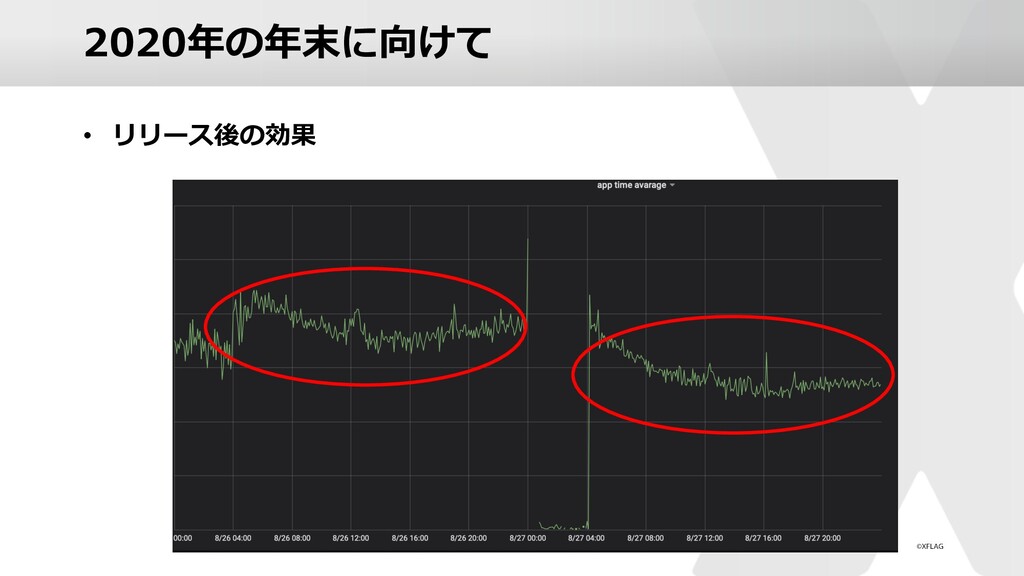
スマホアプリ「モンスターストライク」の運営においてどのような負荷対策を実施しているのかを、昨年末のキャンペーン時の実例を元にご紹介していきます。 ゲームならではの傾向やそれに対する対策、他のwebサービス同様に発生するであろう高負荷への対策など様々なアプローチでの解決方法を実施しております。 本セッションでは、技術的な部分からのアプローチやユーザビリティの向上を目指した取り組みなどをご紹介いたします。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
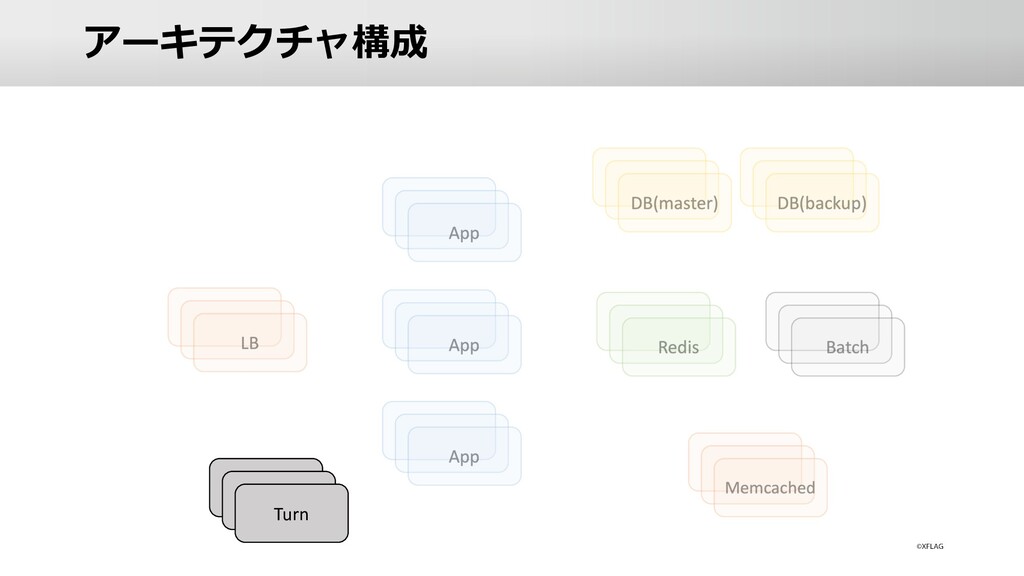{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
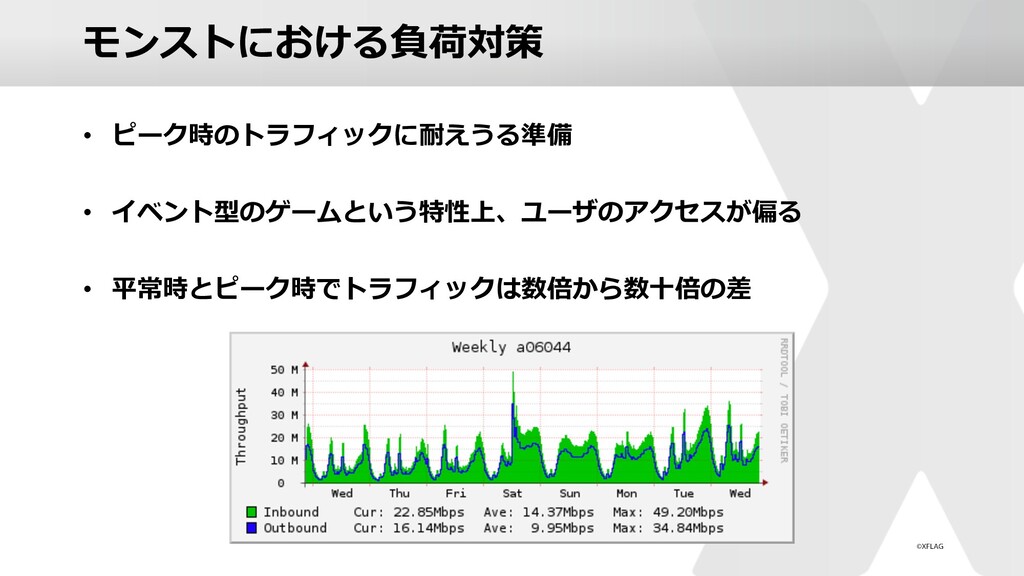{kind=link}
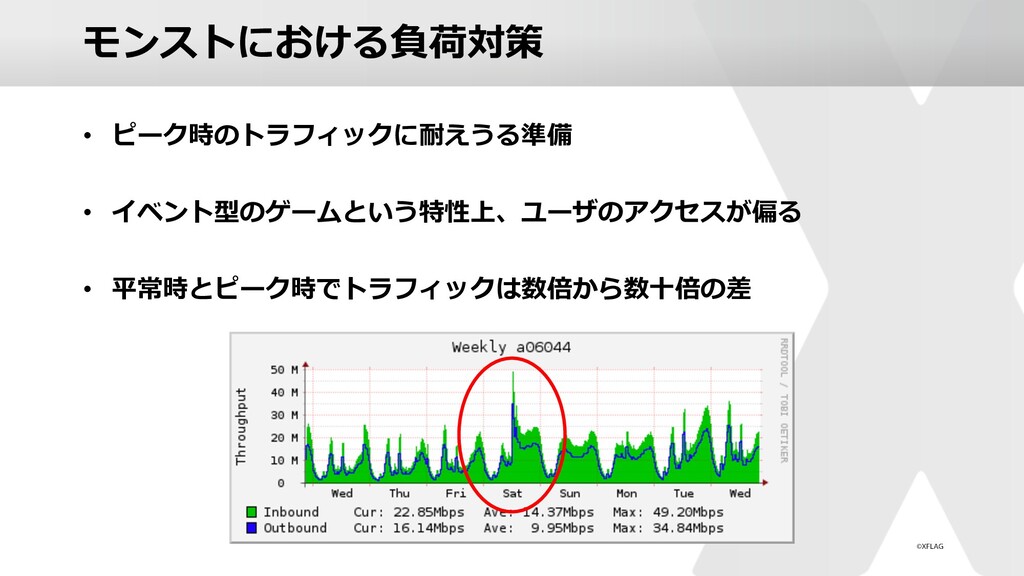{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
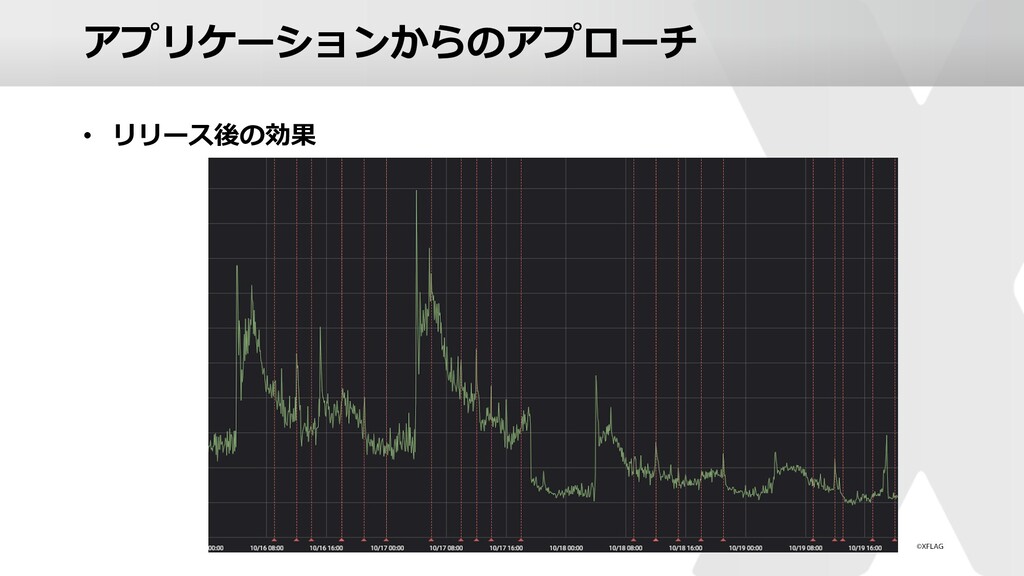{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}