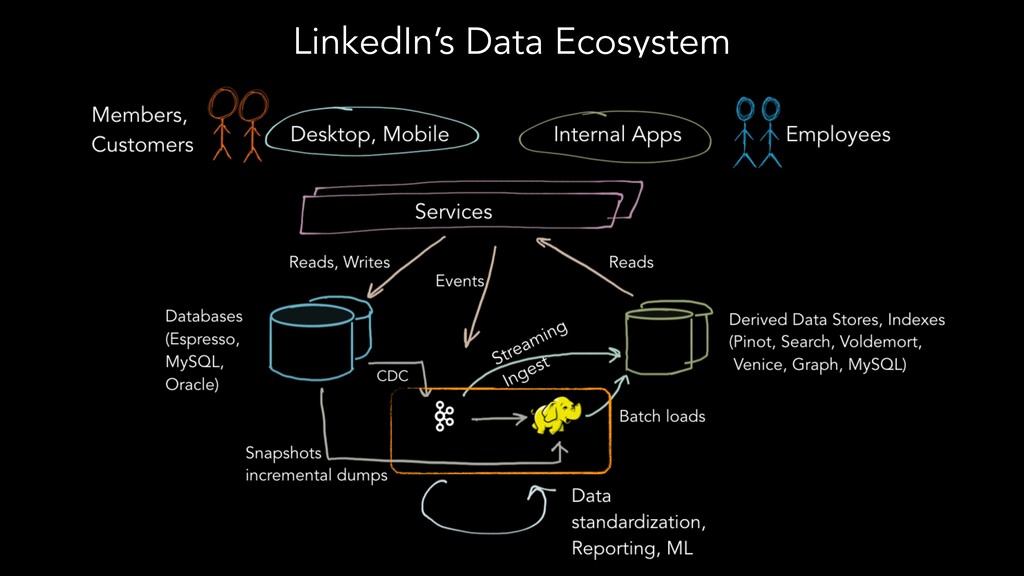
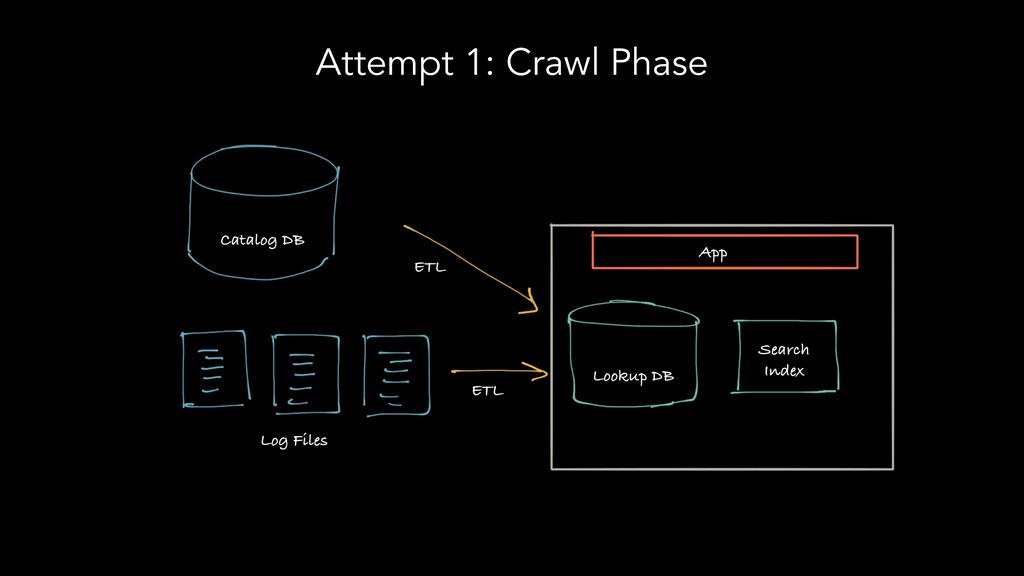
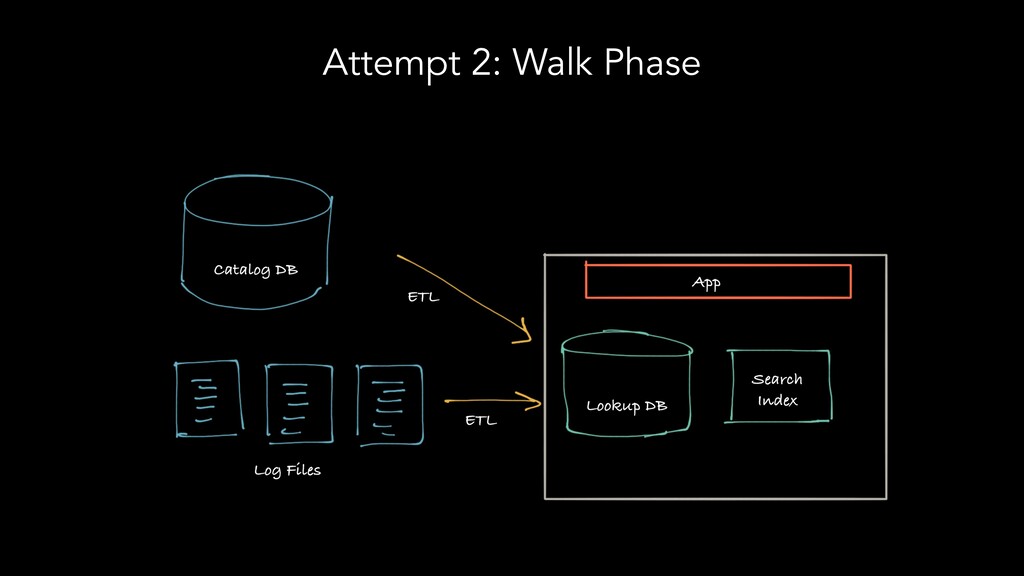
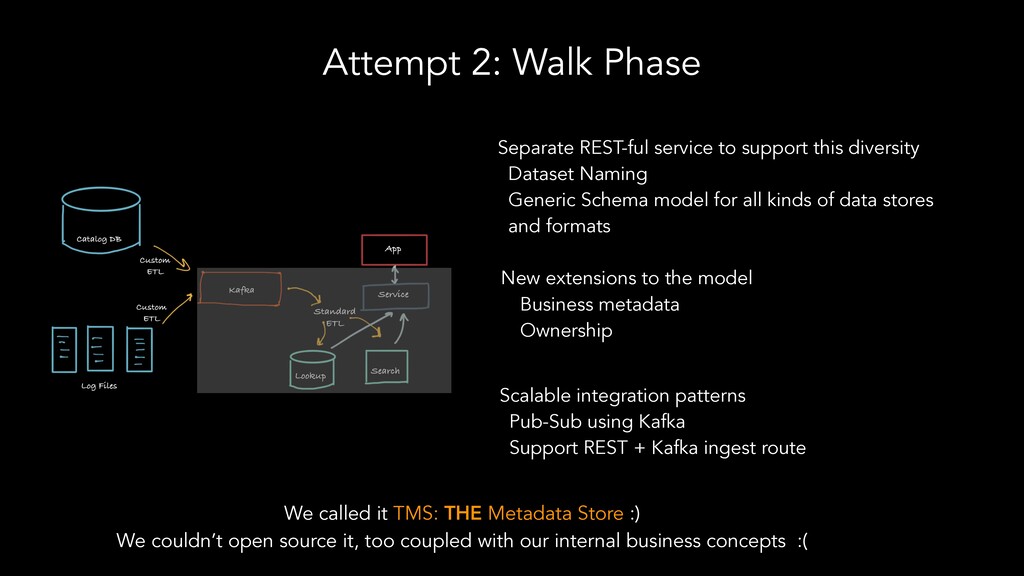
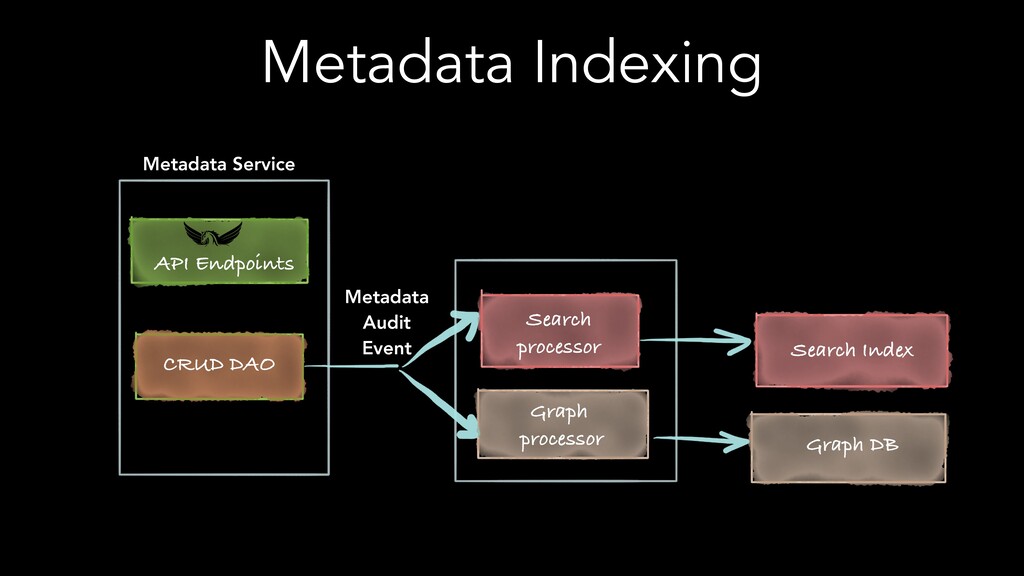
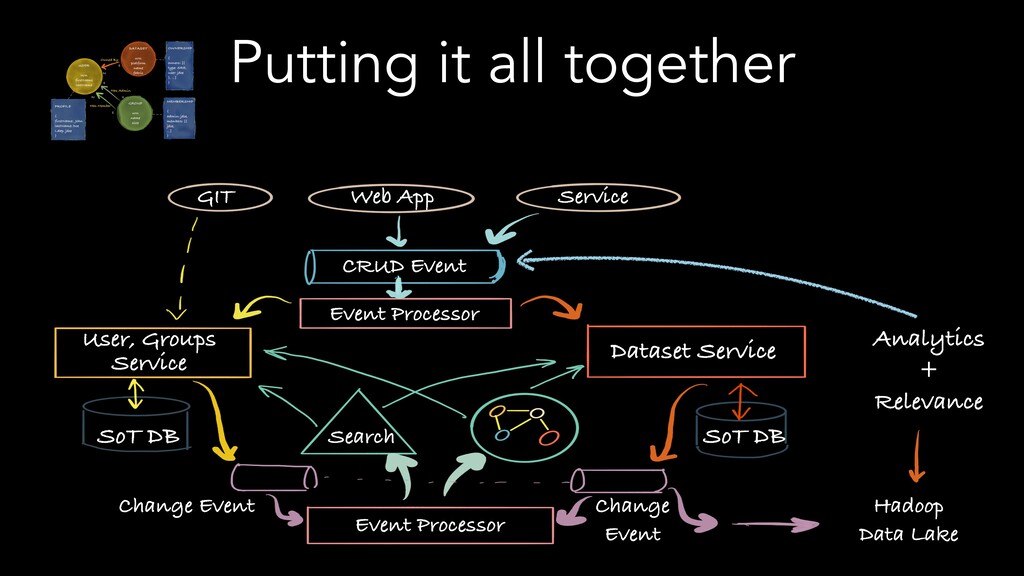
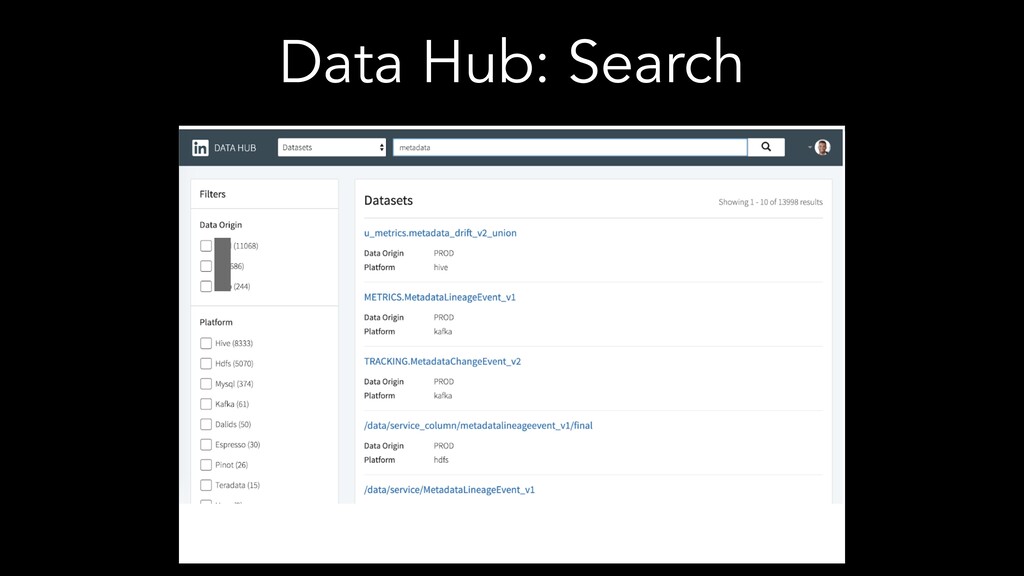
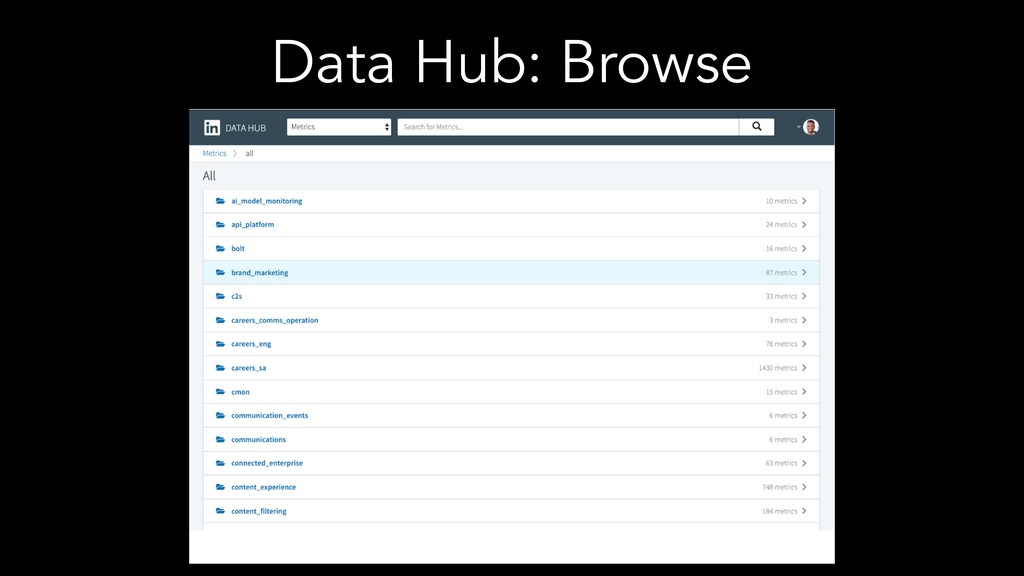
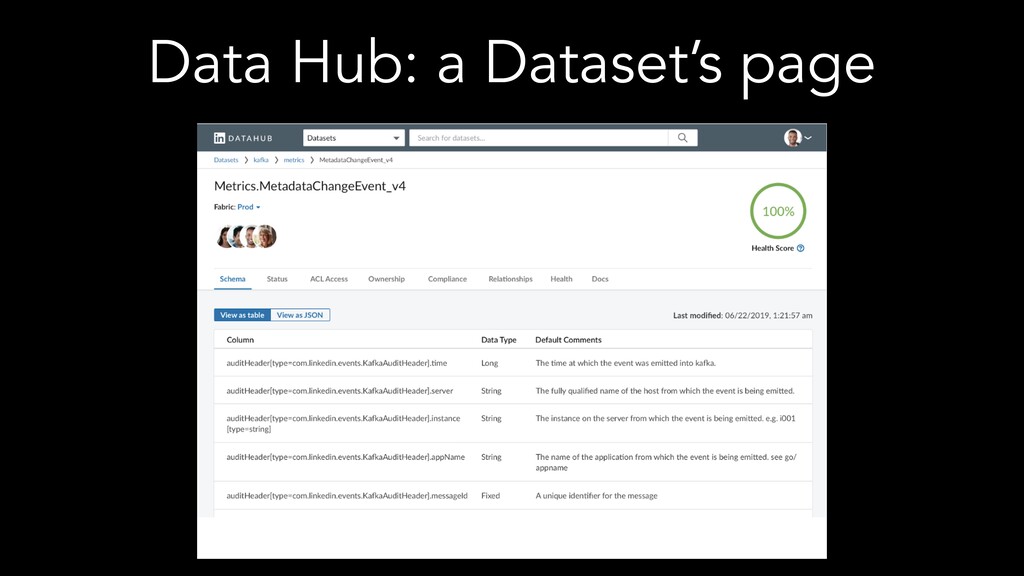
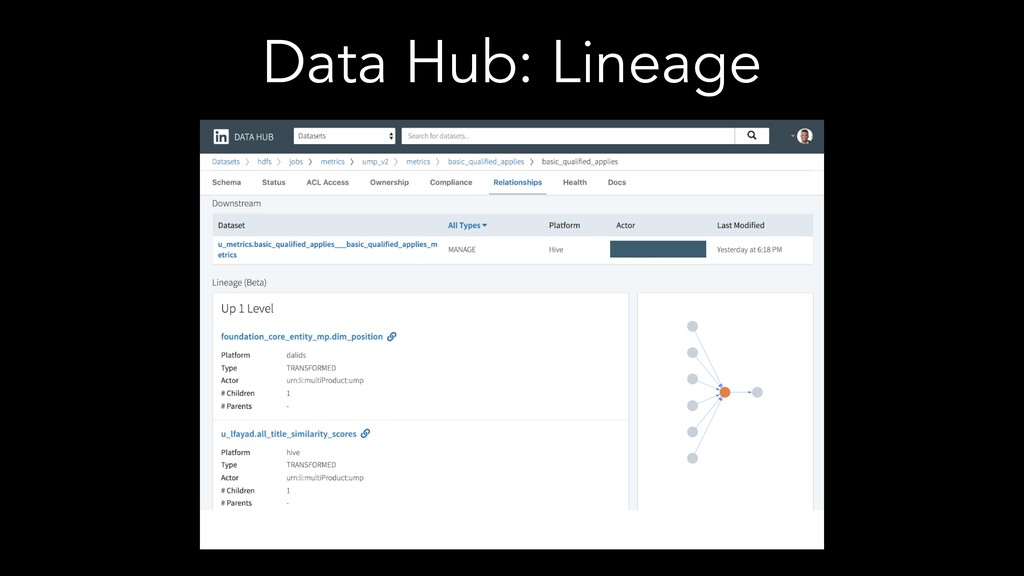
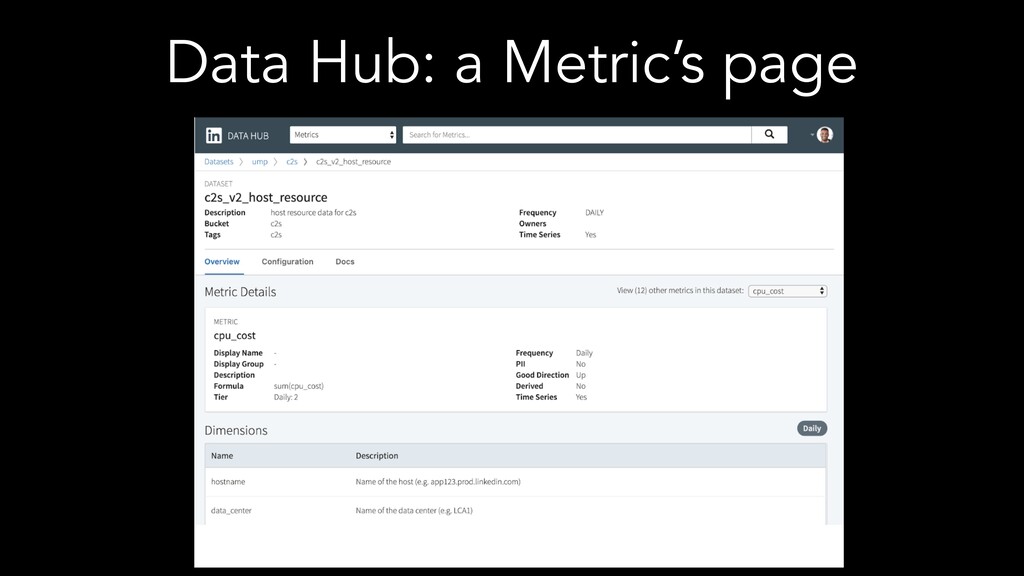
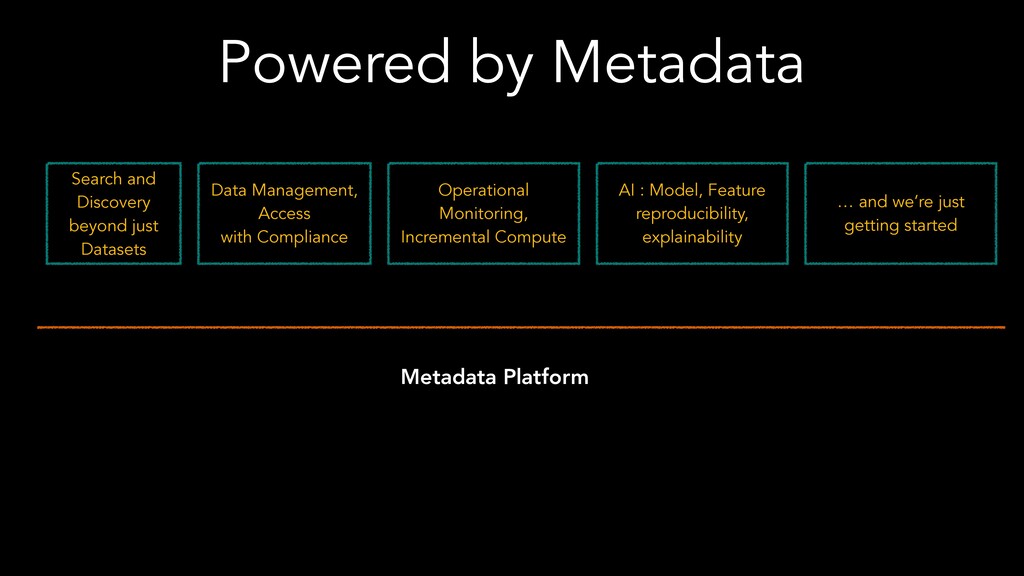
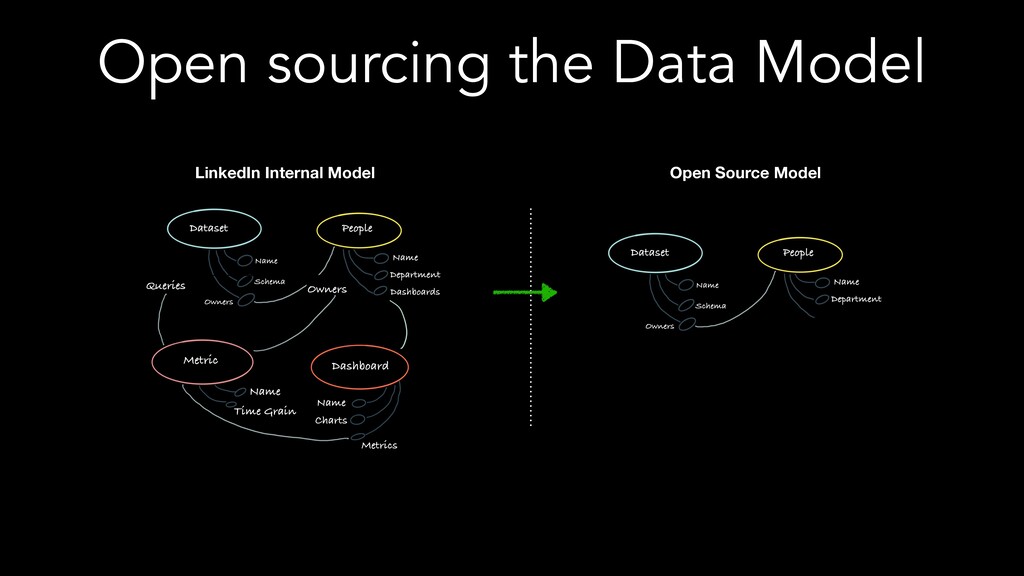
The speakers examine different metadata strategies for modeling metadata, storing metadata, and then scaling the acquisition and refinement of metadata for thousands of metadata authors and producing systems. They dive into the pros and cons of each strategy and in which scenarios they think organizations should deploy them. They explore strategies including generic types versus specific types, crawling versus publish/subscribe, single source of truth versus multiple federated sources of truth, automated classification of data, lineage propagation, and more.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Open Source : what’s coming next! More Entities: [Jobs, Flows]](https://files.speakerdeck.com/presentations/3eafe0175bb34c798f2a77fbe2156678/slide_35.jpg){kind=link}
{kind=link}