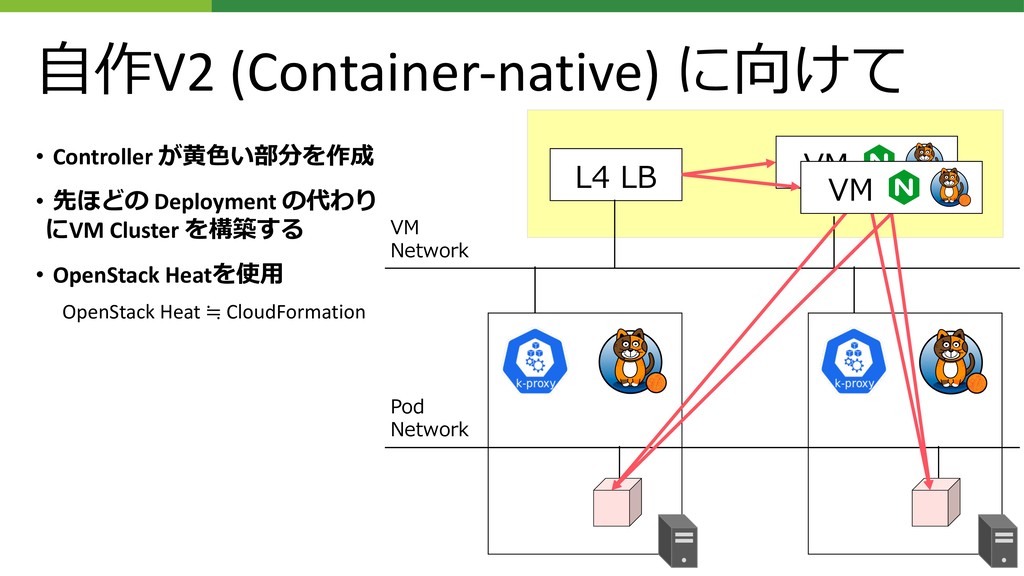
Web Service, Google Compute Engine, On-premise Data Center, etc. 弊業界に限らないかもしれません • その時点で使えるもののうちで、最も適したもの選んで使う これができるのが弊社の強みです • On-premise環境にOpenStackでプライベートクラウド環境を構築
D., Tune, E., & Wilkes, J. (2015, April). Large-scale cluster management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems (p. 18). ACM. • ⾃分「いや、疎通できないの困らないの︖」 • 紙⽈く、In Borg, all tasks on a machine use the single IP address of their host, and thus share the host’s port space. … Kubernetes can take a more user-friendly approach that eliminates these complications: every pod and service gets its own IP address, allowing developers to choose ports… 超約︓ホストのIPを共有、ポートをやりくりする • つまりKubernetesは(他のやり⽅もあるので)Borgよりマシ(↑紙⽈く) 論⽂から察するにBorgの⽬的は「巨⼤な計算資源を効率よく使うこと」であって、コンテナとそのオーケ ストレーションは⼿段に過ぎなかった(と思われる) でもそれをインフラ抽象化としてOSSで売りに出したのはGoogleの巧みな術
No overlay required Pluggable Data Plane Integrated with all major cloud platforms Widely deployed, and proven at scale • TL;DR: BGPでコンテナへの経路を得る Pod IPへの経路を広報して、ホストのIPに吸い込む つまりBIRDのControllerとも⾔える それをやっちゃえば、それはできそう(⽇本語)
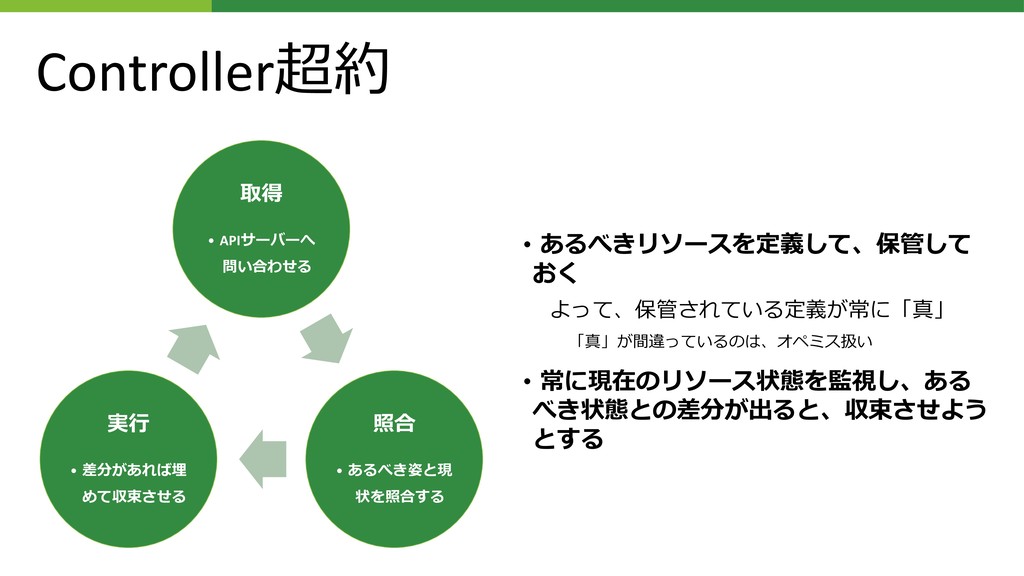
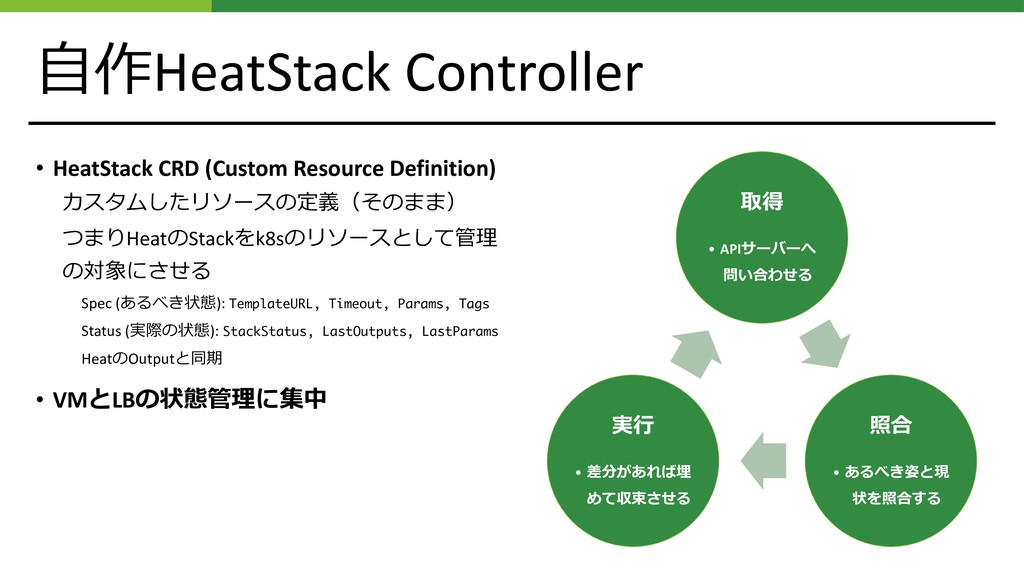
Controllerを分離 • Heatのスタック状態を⾒る部分を別のControllerとして分離 • 状態管理ループの中で⼤きな「待ち」を⼊れるのは、得策ではない • さっきの紙︓”Borgmaster was originally designed as a monolithic system, but over time, … , we split off the scheduler and the primary UI (Sigma) into separate processes, and added services for admission control, vertical and horizontal auto-scaling, re- packing tasks, periodic job submission (cron), workflow management, and archiving system actions for off-line querying.” • 超約︓Monolithicはやっぱりスケールしないわ • Heatの待ちが移動しただけだが、ロック粒度は⼩さくなった
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
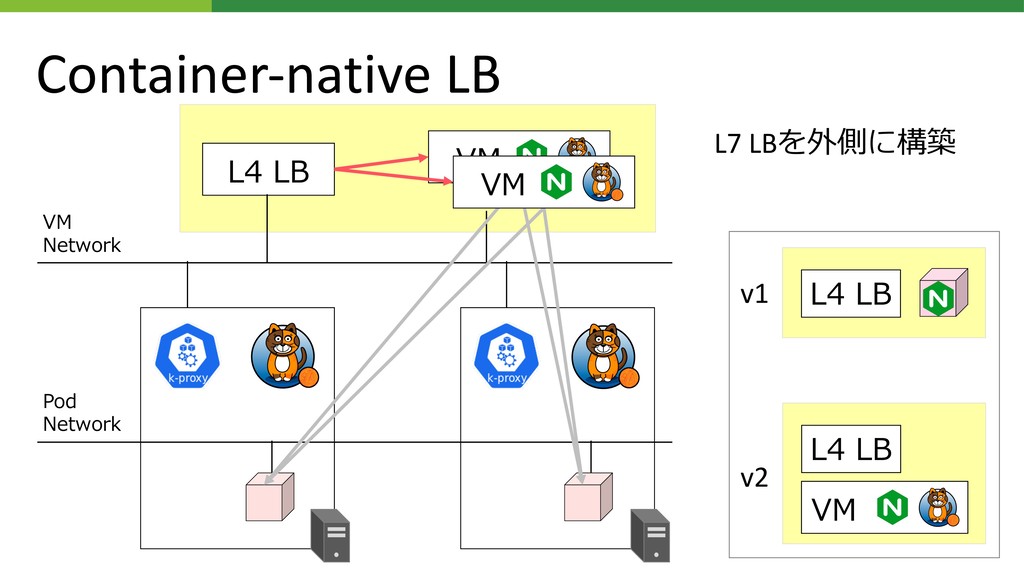{kind=link}
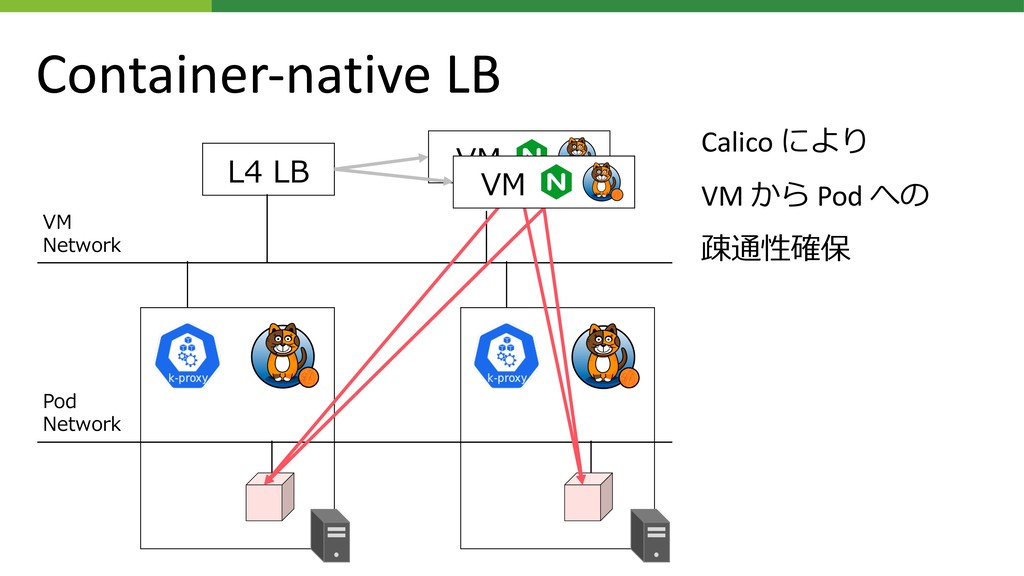{kind=link}
{kind=link}
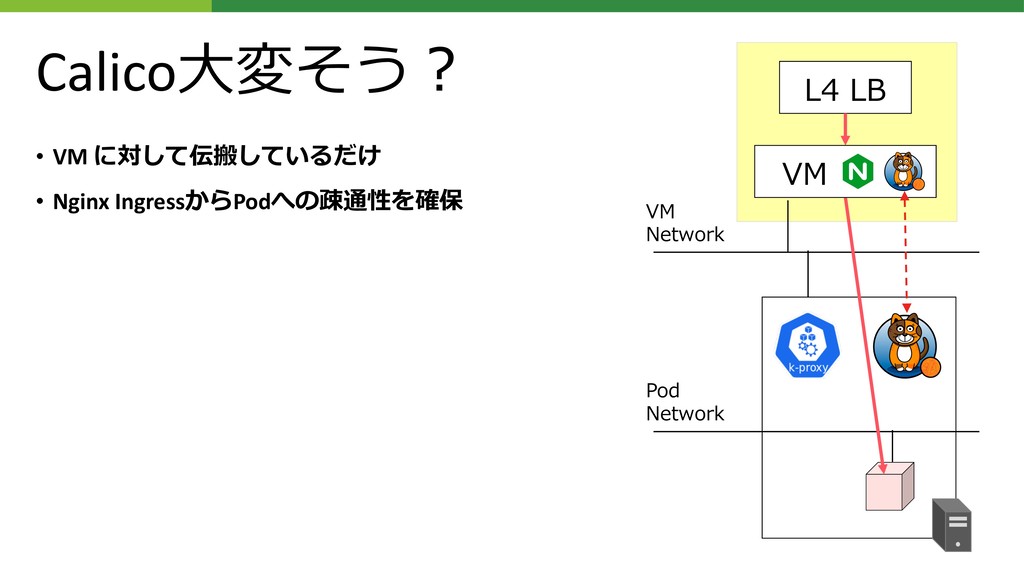{kind=link}
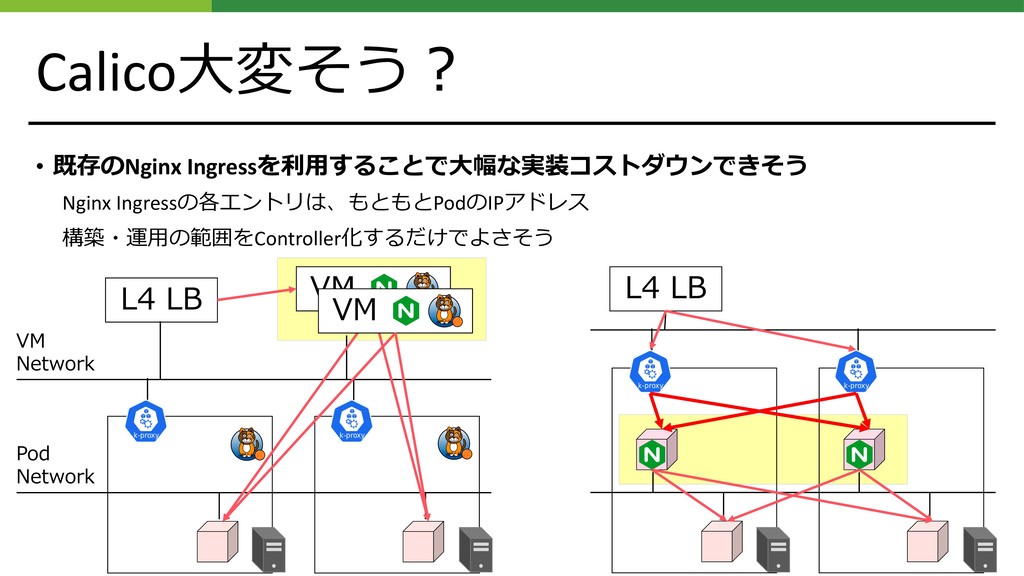{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}