Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ハイブリッドクラウドに対応したログ集約・解析プラットフォームのためのHEC活⽤法
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Shuichiro MAKIGAKI
June 21, 2019
Technology
200
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ハイブリッドクラウドに対応したログ集約・解析プラットフォームのためのHEC活⽤法
Shuichiro MAKIGAKI
June 21, 2019
More Decks by Shuichiro MAKIGAKI
See All by Shuichiro MAKIGAKI
「みんなのDWH」のためのSnowflake設計
shuichiromakigaki
0
1.1k
OpenStackとIngress Controllerで作るContainer-nativeロードバランシング
shuichiromakigaki
2
1.9k
Other Decks in Technology
See All in Technology
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
2
290
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
150
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
400
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
970
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
220
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
830
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
130
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
500
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
220
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
180
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.1k
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
120
Featured
See All Featured
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Building the Perfect Custom Keyboard
takai
2
820
Code Review Best Practice
trishagee
74
20k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
Code Reviewing Like a Champion
maltzj
528
40k
Making the Leap to Tech Lead
cromwellryan
135
10k
The Language of Interfaces
destraynor
162
27k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
740
Ethics towards AI in product and experience design
skipperchong
2
330
Transcript
ハイブリッドクラウドに対応したログ集約・解 析プラットフォームのためのHEC活⽤法 牧垣 秀⼀朗 (
[email protected]
) Shuichiro MAKIGAKI 株式会社サイバーエージェント 全社システム本部 GOJAS
2019-06
はじめに
はじめに • 好きです、Splunk 「⼀度Splunkに⼊れさえすれば、あとはなんとでもなる」という安⼼感 ログのパース・検索・データの統合・統計処理が強⼒ 運⽤する上で気にすることが少ない(ディスク容量とライセンス使⽤量くらい︖) グラフもアラートも作れる • 思考停⽌⽒「んーと……もうSplunkでいいんじゃね︖︖︖」
ご時世 • ハイブリッドクラウド • IBM「ハイブリッド・クラウドとは何か」https://www.ibm.com/blogs/solutions/jp-ja/what-is-hybrid-cloud/ 広く⼀般のユーザーと同じ環境を利⽤するパブリック・クラウド、専⽤の環境を利⽤するプライ ベート・クラウド、そしてすでに保有している⾃社のIT資産(オンプレミス)を組み合わせて最 適なITインフラを構築するという考え⽅を指します。 • RedHat「ハイブリッドクラウドとは」https://www.redhat.com/ja/topics/cloud-computing/what-is-hybrid-cloud
パブリッククラウドとプライベートクラウド環境を 1 つまたは複数組み合わせたものです。これ は、サードパーティ企業が所有し管理するハードウェアと、クラウドを使⽤する企業が所有して いるハードウェアからなる仮想リソースのプールです。
オンプレ+AWS • オンプレのActive Directory • オンプレのファイルサーバー • バッチ的なLambda • 社内サービスを集約したECSクラスタ
ちょっとしたもの、を動かすのに便利 SSOパスワード変更、サービスステータスページ、IPAM、など ……だけだったはずが、慣れてきて、社内端末のRadiusサーバーまでECSに乗せはじめる始末︕ • 多様な場所からログを集める必要がでてきた 認証周りのAuditとか、バッチのアラートとか
問題点1︓データの前処理 • データ解析でもっとも⼤変なのは「前処理」 クレンジング(表記揺れや誤記の修正)+フィルタリング(不要データの削除) ⼯数の9割が前処理(※個⼈の感s) • Splunkは「たった⼀つの重要なデータ」を発⾒できるてしまうので、 変なデータが混じっていて欲しくない 前処理しなくても⼊れちゃえばSplunkがなんとかしてくれるてしまう のだけれど、sourcetypeとfield
extractionがカオス化します(経験) 最初からJSONとかで⼊れてくれると全員の仕事が楽になる
問題点2︓データの⼊⼒ • データの冗⻑化と負荷分散 Indexerクラスタを作ってデータを冗⻑化したい +データ読み込み負荷を分散したい • Splunkフォワーダーの設定は難しい ⼝で⾔えない・テンプレ化が難しい・情報が少ない(vs. fluentd/logstash)・Splunk固有の単語が 多い・ドキュメントが英語か、または英語
• CloudWatch Logsも⼊⼒したい Lambdaが便利すぎて、ちょっとしたバッチもLambdaで書いていたらすごく増えてしまった が、CloudWatch Logs単体では検索・可視化・アラートの機能はイマイチ しかも意外とお⾼い(EBSを使う感覚)ので、Splunkに⼊れたものは削除したい
問題点3︓プラットフォーム化 • あまり質問されても困る ログ⼊れていいですか︖ → その量ならライセンス⾜りるしいいんじゃない︖としか…… → あ、でもIndexerへの転送が必要だからinputs.confとoutputs.conf書いて再起動しないと…… → え︖⼊れたのDebugレベルのログですか︖それ使います︖
このAppどう使うんですか︖ → 僕も知らないのでググっていただいて…… こういうのどうやったらできるんですか︖ → ちょっと僕もわからないです…… ゴミ⼊れすぎてわけがわからなくなったよ → つらい…… • 安全に「好きにデータ⼊れていじってもらっていいですよ」 と⾔いたい 使ってみてもらわないことには布教が進まない(布教したい)
やりたいこと • データ前処理の脱職⼈芸 • 簡単で安全なデータ⼊⼒ • プラットフォーム化による脱⼿運⽤ • ……による⼯数の削減と諦めの防⽌を狙う
これ、HTTP Event Collectorでなんと かできるのでは︖
Splunk側の実装 2
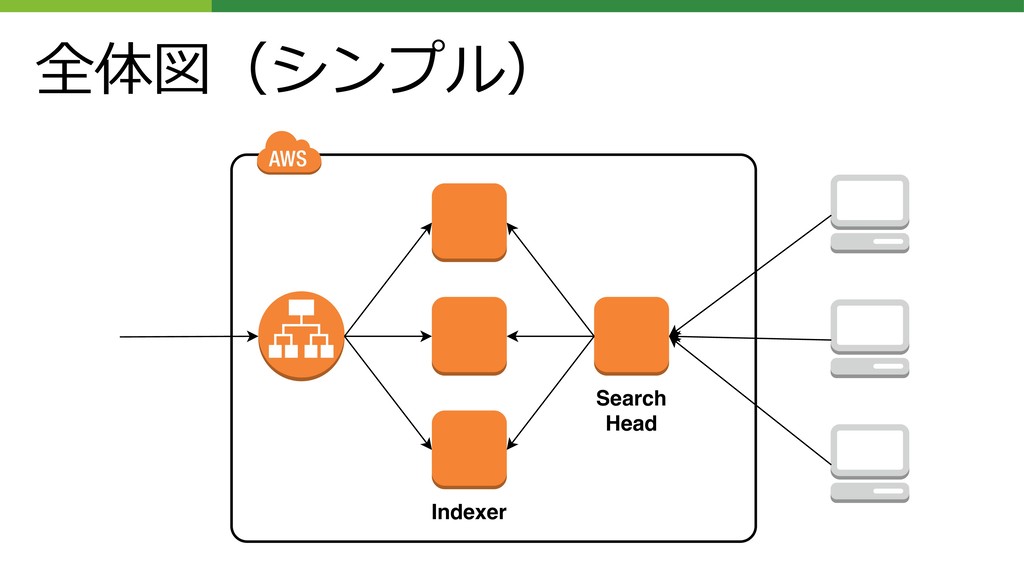
全体図(シンプル) Indexer Search Head
HTTP Event Collector (HEC) • HTTPでログ(イベント)を⼊⼒できる 既定のJSONフォーマットでエンドポイントにHTTP POSTする トークン認証 •
HTTPなので(⻑) HTTPバランサで冗⻑構成と負荷分散が可能 Fluentd、Logstash、AWS Kinesis Firehoseなど、HEC対応のログソースが多数 • HTTPなので(短) 速度はHTTPの程度 圧縮はできない(たぶん)
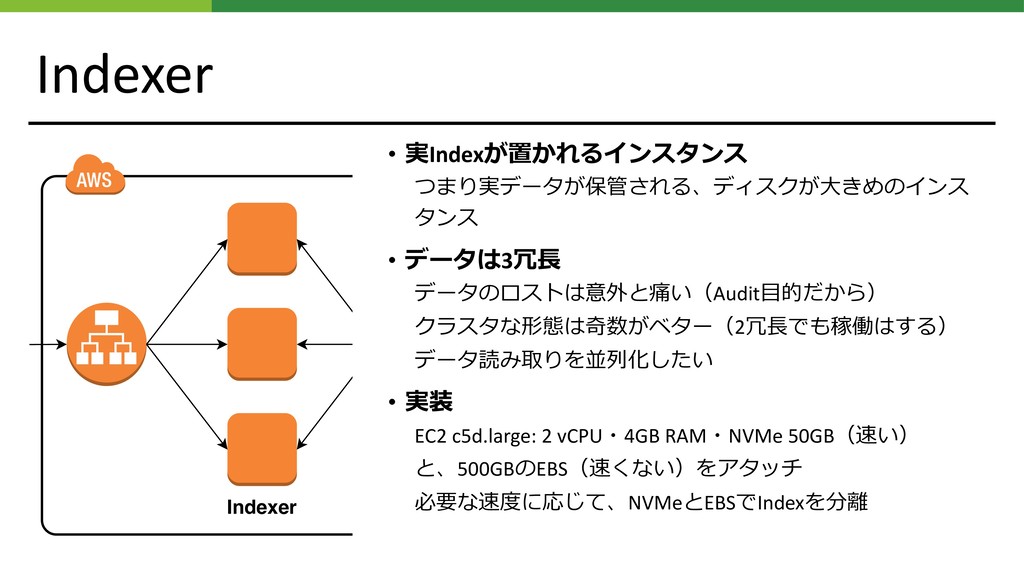
Indexer • 実Indexが置かれるインスタンス つまり実データが保管される、ディスクが⼤きめのインス タンス • データは3冗⻑ データのロストは意外と痛い(Audit⽬的だから) クラスタな形態は奇数がベター(2冗⻑でも稼働はする) データ読み取りを並列化したい
• 実装 EC2 c5d.large: 2 vCPU・4GB RAM・NVMe 50GB(速い) と、500GBのEBS(速くない)をアタッチ 必要な速度に応じて、NVMeとEBSでIndexを分離 Indexer Search Head
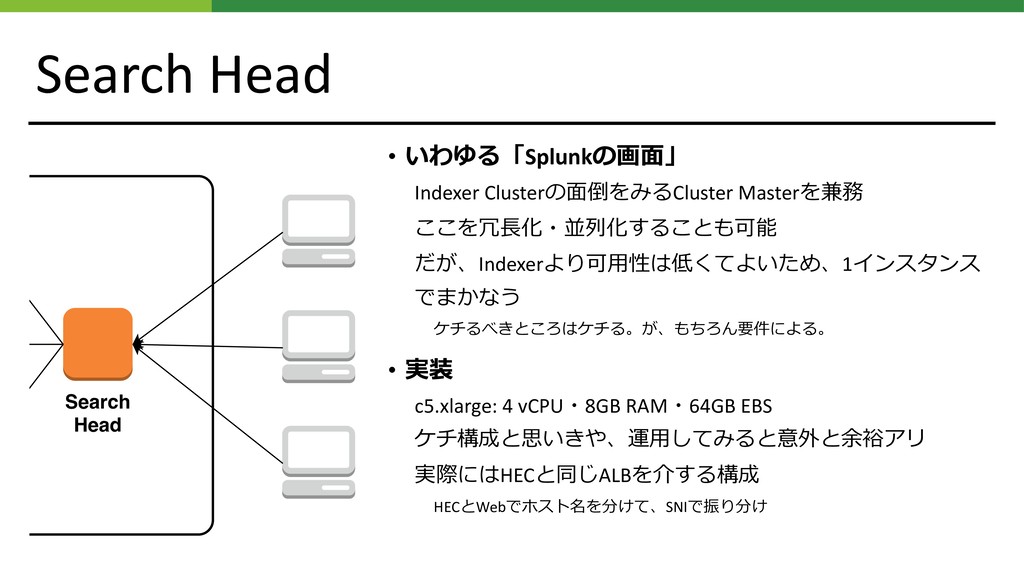
Search Head • いわゆる「Splunkの画⾯」 Indexer Clusterの⾯倒をみるCluster Masterを兼務 ここを冗⻑化・並列化することも可能 だが、Indexerより可⽤性は低くてよいため、1インスタンス でまかなう
ケチるべきところはケチる。が、もちろん要件による。 • 実装 c5.xlarge: 4 vCPU・8GB RAM・64GB EBS ケチ構成と思いきや、運⽤してみると意外と余裕アリ 実際にはHECと同じALBを介する構成 HECとWebでホスト名を分けて、SNIで振り分け Search Head
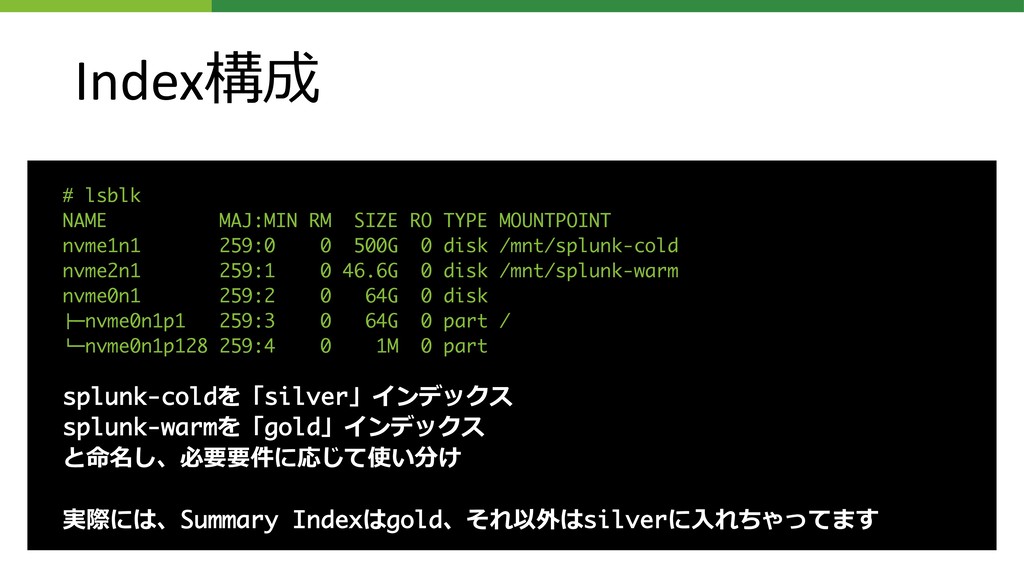
Index構成 # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
nvme1n1 259:0 0 500G 0 disk /mnt/splunk-cold nvme2n1 259:1 0 46.6G 0 disk /mnt/splunk-warm nvme0n1 259:2 0 64G 0 disk !"nvme0n1p1 259:3 0 64G 0 part / #"nvme0n1p128 259:4 0 1M 0 part splunk-coldを「silver」インデックス splunk-warmを「gold」インデックス と命名し、必要要件に応じて使い分け 実際には、Summary Indexはgold、それ以外はsilverに⼊れちゃってます
AWS側の実装 3
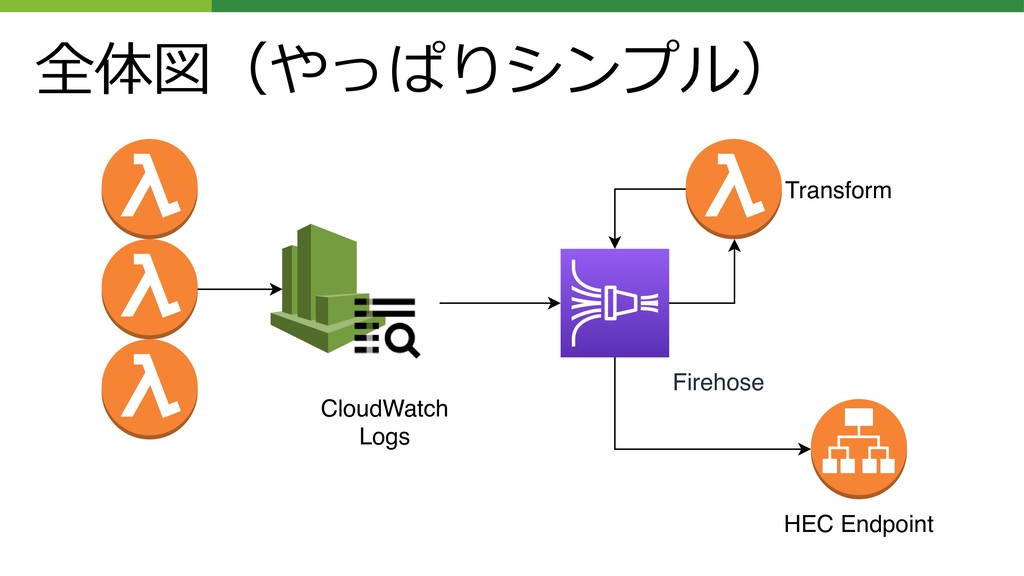
全体図(やっぱりシンプル) Firehose CloudWatch Logs Transform HEC Endpoint
AWS CloudWatch Logs • AWSで出るログはほとんどここに集まる Lambdaからも マネージドサービスのログも Subscription Filterという機能で、特定のログをFirehoseに転送 できる
そしてFirehoseからSplunkへ転送できる(後述) ログのライフサイクルは短めに設定する Firehose CloudWatch Logs Transform HEC Endpoint
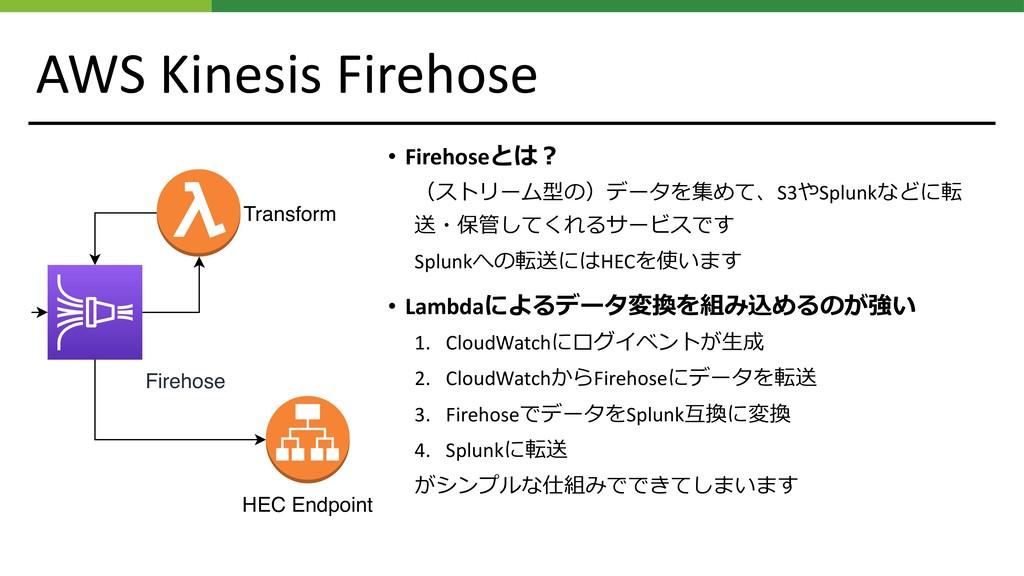
AWS Kinesis Firehose • Firehoseとは︖ (ストリーム型の)データを集めて、S3やSplunkなどに転 送・保管してくれるサービスです Splunkへの転送にはHECを使います • Lambdaによるデータ変換を組み込めるのが強い
1. CloudWatchにログイベントが⽣成 2. CloudWatchからFirehoseにデータを転送 3. FirehoseでデータをSplunk互換に変換 4. Splunkに転送 がシンプルな仕組みでできてしまいます Firehose Transform HEC Endpoint
⼯夫 4
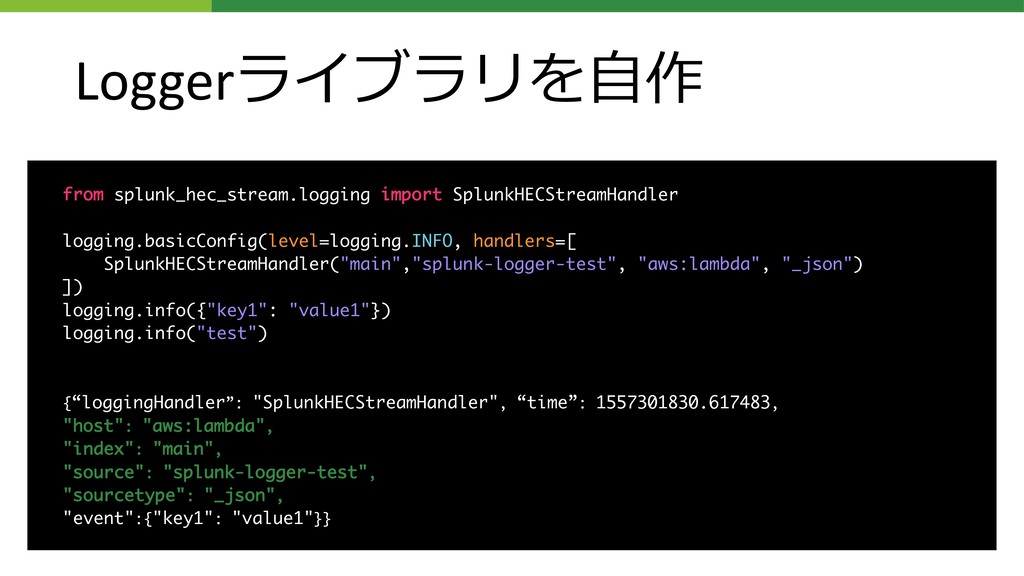
Loggerライブラリを⾃作 • Firehoseからの転送時にindexやsourcetypeの指定ができない なので、データはデフォルトIndexに⼊ります が、イベントにメタデータ(JSONのキー)として追記すれば指定が可能です • ということをするログライブラリを書きました Python⽤ 通常のインターフェースにログを書き出すだけで、Splunkに⼊る形にしてくれます pip
install splunk-hec-stream (https://github.com/shuichiro-makigaki/splunk_hec_stream) Lambda Layer化しており、layerを使うだけでライブラリが使えるようにしてます リポジトリにはTerraform、processorが含まれているので、同じ仕組みはすぐに作れます︕お試しを︕
Loggerライブラリを⾃作 from splunk_hec_stream.logging import SplunkHECStreamHandler logging.basicConfig(level=logging.INFO, handlers=[ SplunkHECStreamHandler("main","splunk-logger-test", "aws:lambda", "_json")
]) logging.info({"key1": "value1"}) logging.info("test") {“loggingHandler”: "SplunkHECStreamHandler", “time”: 1557301830.617483, "host": "aws:lambda", "index": "main", "source": "splunk-logger-test", "sourcetype": "_json", "event":{"key1": "value1"}}
App Homeをリッチ化
Sandboxの提供 • お試し⽤Index • 容量1G+保管期間7⽇というゴミ箱仕様 • 「あれやこれをしたい」→「いったんSandboxに⼊れてごにょごにょしてみる」 • 「承認」的な仕組み(Splunk使うの︖確認など)を省略できる やってみないとわからないことは、やってみるしかない
Terraform + Ansible • *.confの書き換え問題 Indexerが別ホストなので、転送設定が必要 Indexerクラスタ内のsilver indexを使って欲しい(Search Head内には保管しない) ⼿作業では変更履歴が追えない
→ 運⽤が属⼈化 → システムの維持可能性が低下 • そこでTerraformとAnsibleで構成を管理 • 設定変更︓Ansible書き換えて流すだけ • 構成管理︓トラブル時の差分チェック+修正+⾮常時の作り直し • ⼿運⽤が減り、本来の解析に集中できる
現在の様⼦ 5
例 • HEC経由 MACアドレス認証ログ Radius認証ログ テレビ会議端末監視(Zoom Rooms) • その他も ActiveDirectory認証ログ
Infoblox DHCPログ、など • AWS Appも使⽤ EC2インスタンス情報との統合検索が可能に
使⽤量
お⾦ 0 2 4 6 8 10 12 2019/6/17 2019/6/18
2019/6/19 2019/6/20 USD Kinesis Firehose EC2 その他 EC2 ELB EC2 インスタンス
まとめ 6
作ってみて • やりたかったことはおおむね実現 データの前処理の脱職⼈芸・簡単で安全なデータ⼊⼒・プラットフォーム化で脱⼿運⽤ • なにより、ログの集約や解析という⾏為が浸透した(と思う) 「ログ……︖は、特に⾒てないですね……。」といったことはなくなりつつある 作った物の使われ具合を⾒える化できるようになった • 解決できていない課題
検索クエリの書き⽅⾃体の助けにはなっていない もはやSplunkから抜け出せない︕
ありがとうございました
![ハイブリッドクラウドに対応したログ集約・解 析プラットフォームのためのHEC活⽤法 牧垣 秀⼀朗 ([email protected]) Shuichiro MAKIGAKI 株式会社サイバーエージェント 全社システム本部 GOJAS](https://files.speakerdeck.com/presentations/4ffddf7245ff4939ba59f239088e8943/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}