Lin, Yi-Chang Shih, and Ravi Ramamoorthi. Vision transformer for nerf-based view synthesis from a single input image. arXiv preprint arXiv:2207.05736, 2022. • [Ling2022] Selena Ling, Nicholas Sharp, and Alec Jacobson. Vectoradam for rotation equiv- ariant geometry optimization. arXiv preprint arXiv:2205.13599, 2022. • [Liu2019a] Liu, Shichen, et al. "Soft rasterizer: A differentiable renderer for image-based 3d reasoning." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019. • [Liu2019b] Liu, Shichen, et al. "Learning to infer implicit surfaces without 3d supervision." NeurIPS 2019. • [Liu2022] Hsueh-Ti Derek Liu, Francis Williams, Alec Jacobson, Sanja Fidler, and Or Litany. Learning smooth neural functions via lipschitz regularization. SIGGRAPH, 2022. • [Loper2014] Loper, Matthew M., and Michael J. Black. "OpenDR: An approximate differentiable renderer." European Conference on Computer Vision. Springer, Cham, 2014. • [Ma2021] Ma, Qianli, et al. "SCALE: Modeling clothed humans with a surface codec of articulated local elements." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. • [Maturana2015] Maturana, Daniel, and Sebastian Scherer. "Voxnet: A 3d convolutional neural network for real-time object recognition." 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2015. • [Mescheder2019] Mescheder, Lars, et al. "Occupancy networks: Learning 3d reconstruction in function space." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019. • [Mildenhall2020] Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." European conference on computer vision. Springer, Cham, 2020. • [Miangoleh2021] Miangoleh, S. Mahdi H., et al. "Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. • [Mueller2022] Thomas Mueller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. arXiv preprint arXiv:2201.05989, 2022. • [Newell2016] Newell, Alejandro, Kaiyu Yang, and Jia Deng. "Stacked hourglass networks for human pose estimation." European conference on computer vision. Springer, Cham, 2016. • [Nicolet2021] Baptiste Nicolet, Alec Jacobson, and Wenzel Jakob. Large steps in inverse rendering of geometry. ACM Transactions on Graphics (TOG), Vol. 40, No. 6, pp. 1–13, 2021. • [Park2019] Park, Jeong Joon, et al. "Deepsdf: Learning continuous signed distance functions for shape representation." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019. • [Peng2020] Peng, Songyou, et al. "Convolutional occupancy networks." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Springer International Publishing, 2020. • [Qi2016] Qi, Charles R., et al. "Volumetric and multi-view cnns for object classification on 3d data." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
{kind=link}
{kind=link}
{kind=link}
![• Hand-craftedͳࣄલ͕ෆཁ • σʔλͦͷͷ͔ΒෳࡶͳࣄલΛಘΔ͜ͱ͕Ͱ͖Δ ͳͥσʔλυϦϒϯͳ3࣍ݩ෮ݩʁ PIFuHD [Saito2020] ϚϯϋολϯϫʔϧυԾઆ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• ը૾σʔλͷ߹࠷৽ͷը૾ΤϯίʔμʔΛ͏ͷ͕جຊ e.g., VGG[Simonyan2014], ResNet[He2016], Hourglass[Newell2016] • λεΫʹԠͯ͡ޮՌΛൃش͢ΔΞʔΩςΫνϟ͕ҧ͏͜ͱ͋Δ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_8.jpg){kind=link}
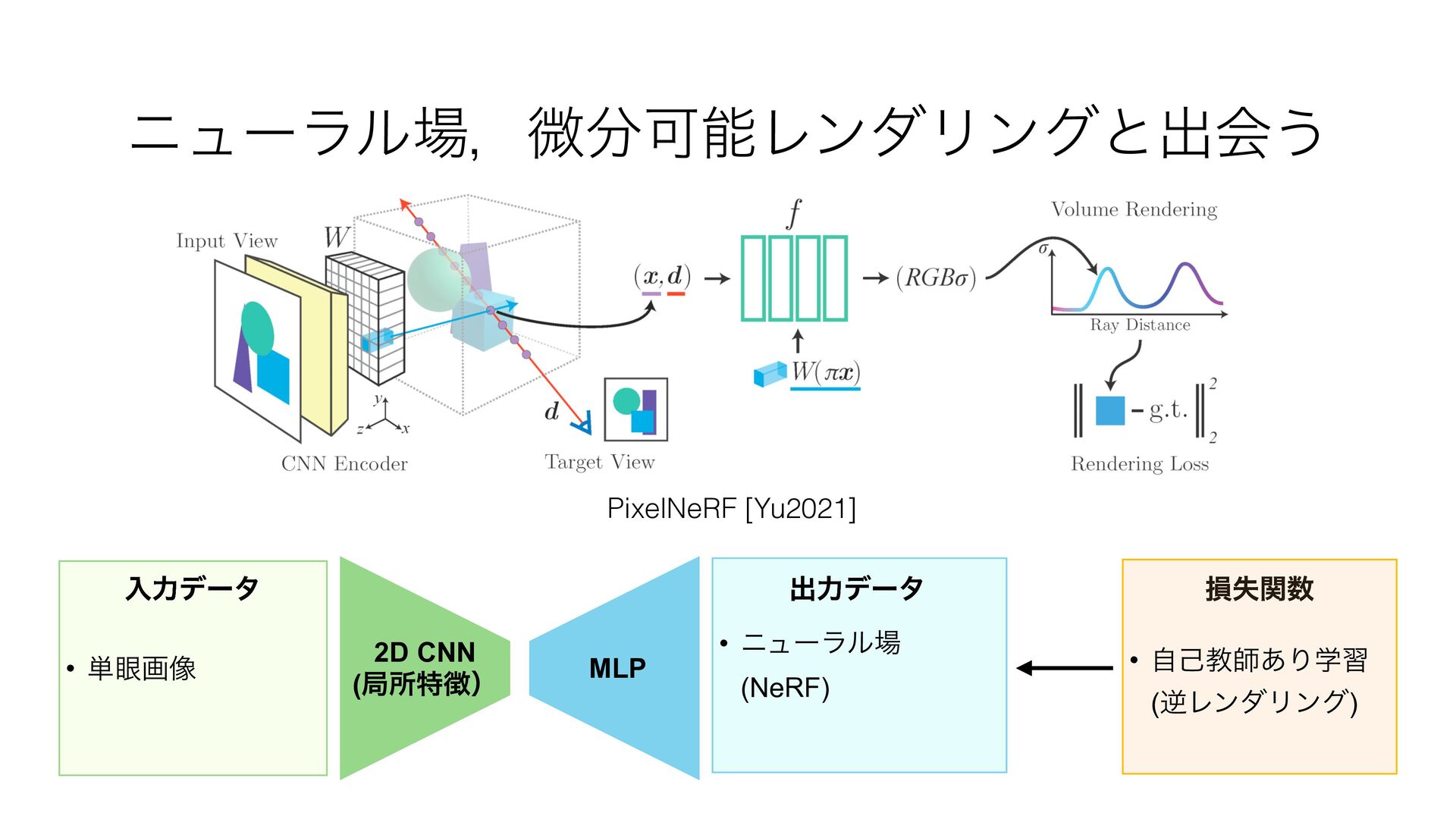
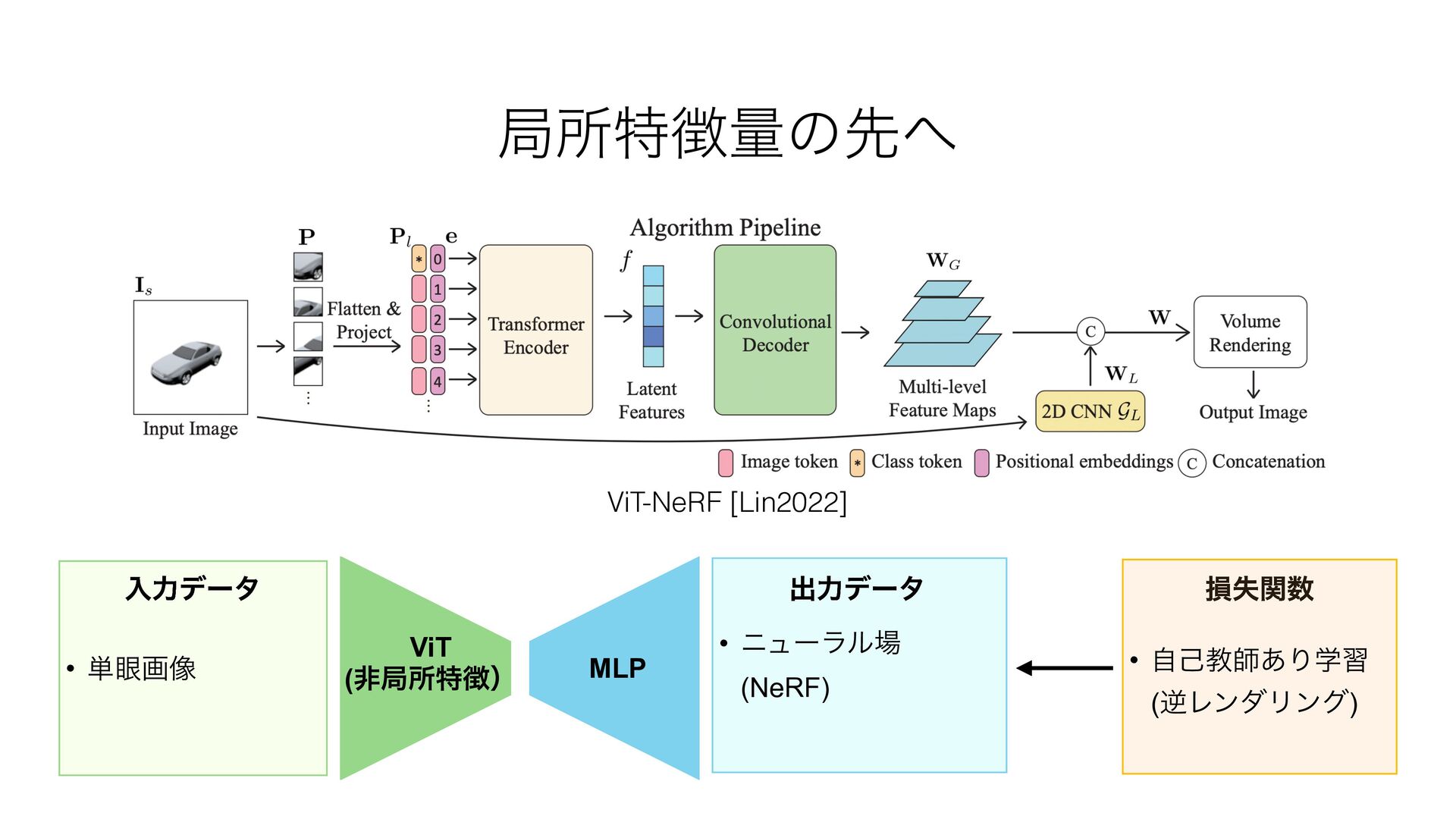
![• τϨϯυɿඇہॴతͳΤϯίʔμʔʢViT [Dosovitskiy2021]ͳͲʣ Τϯίʔμʔɿ୯؟ը૾ɺਂ͖ը૾ Lin [Lin2022]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_9.jpg){kind=link}
![• Χϝϥύϥϝʔλ͕طͷ߹ɺ زԿతؔΛωοτϫʔΫʹΈࠐΉ • ྫɿϗϞάϥϑΟʔ [Yao2018] Τϯίʔμʔɿෳࢹը૾ https://medium.com/@NegativeMind//2d-3d෮ݩٕज़ͰΘΕΔ༻ޠ·ͱΊ-27403689da1b](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_10.jpg){kind=link}
![• KinectLiDARͳͲ͔ΒಘΒΕΔೖྗ͕ओ • ը૾ϝογϡͱҟͳΓɺ܈͕มಈͨ͠Γॱং͕ͳ͍ • ܈ɾεΩϟϯͷಛੑʹରԠͨ͠ΞʔΩςΫνϟ͕ඞཁʹͳͬͯ͘Δ Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ PointNet [Qi2017a]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_11.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ PointNet [Qi2017a]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_12.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ PointNet [Qi2017a]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_13.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ PointNet [Qi2017a] https://github.com/ThibaultGROUEIX/AtlasNet/blob/master/model/model_blocks.py x: ೖྗಛྔʢ࠲ඪɺ๏ઢͳͲʣ MLPͰ֤ͷxΛજࡏมʹม ֤ͷજࡏมΛmax poolingͰ౷߹ ౷߹͞Εͨજࡏมʹ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_14.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ PointNet [Qi2017a]ͷ • શମͷಛ͕̍ճͷMax poolingͰ౷߹ˠ֊తͳߏཧղ͕ࠔ • ֊తͳMax poolingͷಋೖ (PointNet++](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_15.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ Sparse Convolution 3D Convolution [Wu2015]: O(kdmn) ϧʔϜαΠζͷεΩϟϯʹద༻ෆՄ Sparse](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_16.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ Ԡ༻ྫɿSparse Convolution େنͳεΩϟϯͷิ [Dai2020]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_17.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ PointNet + 2D Convolutions [Peng2020] ܈ΛPointNetͰॲཧ͠ಛۭؒʹϚοϐϯάͨ͠ͷͪ 2࣍ݩฏ໘܈ʢTri-plane)ʹసࣸͯ͠ΈࠐΈωοτϫʔΫͰॲཧ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_18.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ τϨϯυᶃɿ3࣍ݩੜϞσϧͷͨΊͷTri-planeදݱ EG3D [Chan2022]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_19.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ τϨϯυᶃɿ3࣍ݩੜϞσϧͷͨΊͷTri-planeදݱ EG3D [Chan2022]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_20.jpg){kind=link}
![Τϯίʔμʔɿ܈ɺεΩϟϯσʔλ τϨϯυᶄɿճసෆมɾಉมΤϯίʔμʔ Vector Neurons [Deng2022] ௨ৗͷશ݁߹ εΧϥʔ Vector Neurons 3࣍ݩϕΫτϧ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
![Instant-NGP [Mueller2022] ΤϯίʔμʔϨεࡾ࣍ݩ෮ݩ τϨϯυᶃɿσʔλߏͷվળʹΑΔ࠷దԽʹΑΔߴ෮ݩ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_24.jpg){kind=link}
![Nerfies [Park2021] ΤϯίʔμʔϨεࡾ࣍ݩ෮ݩ τϨϯυᶄɿมܗͷಉֶ࣌शˠಈతମͷରԠ BANMO [Yang2022]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_25.jpg){kind=link}
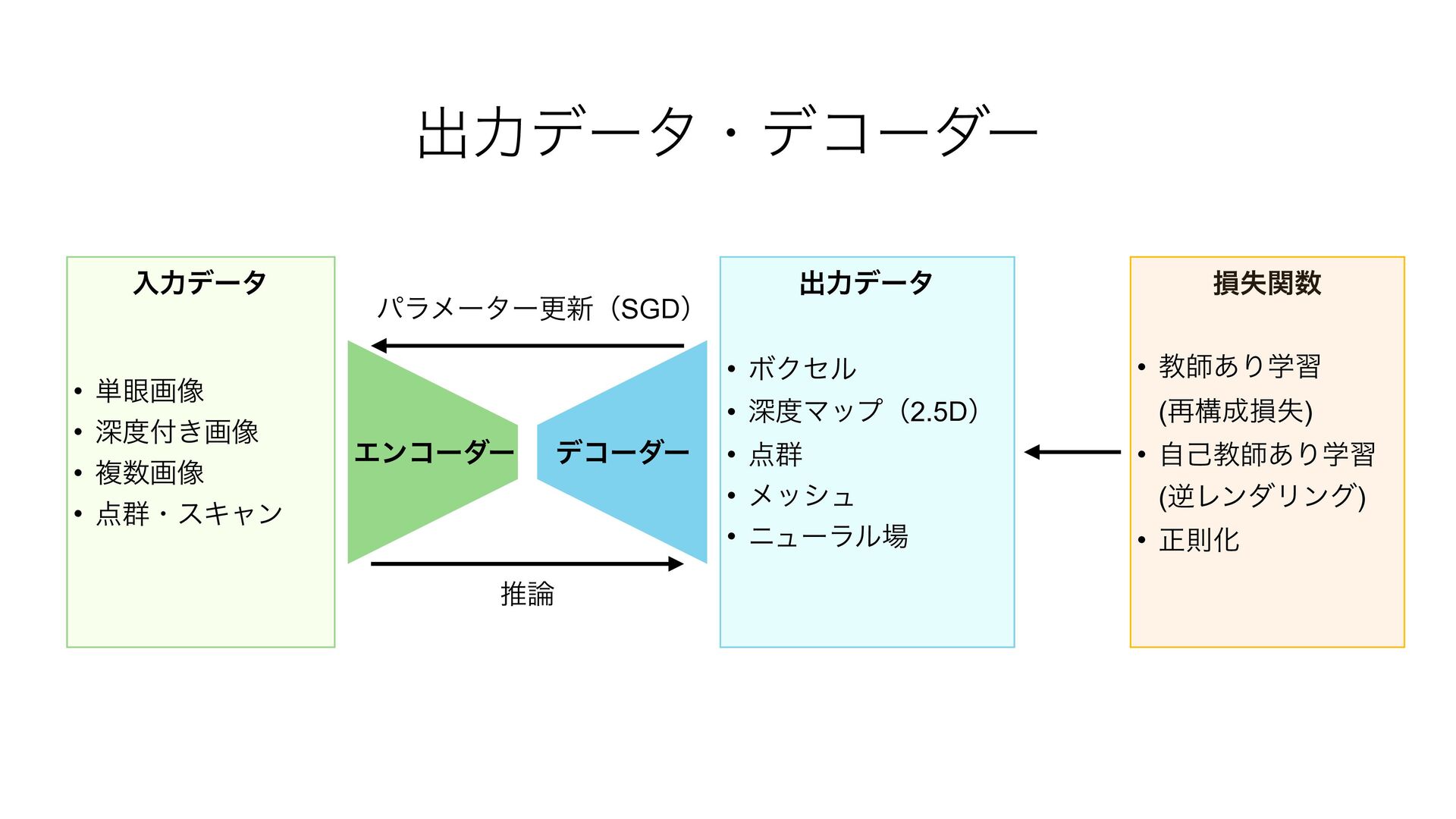{kind=link}
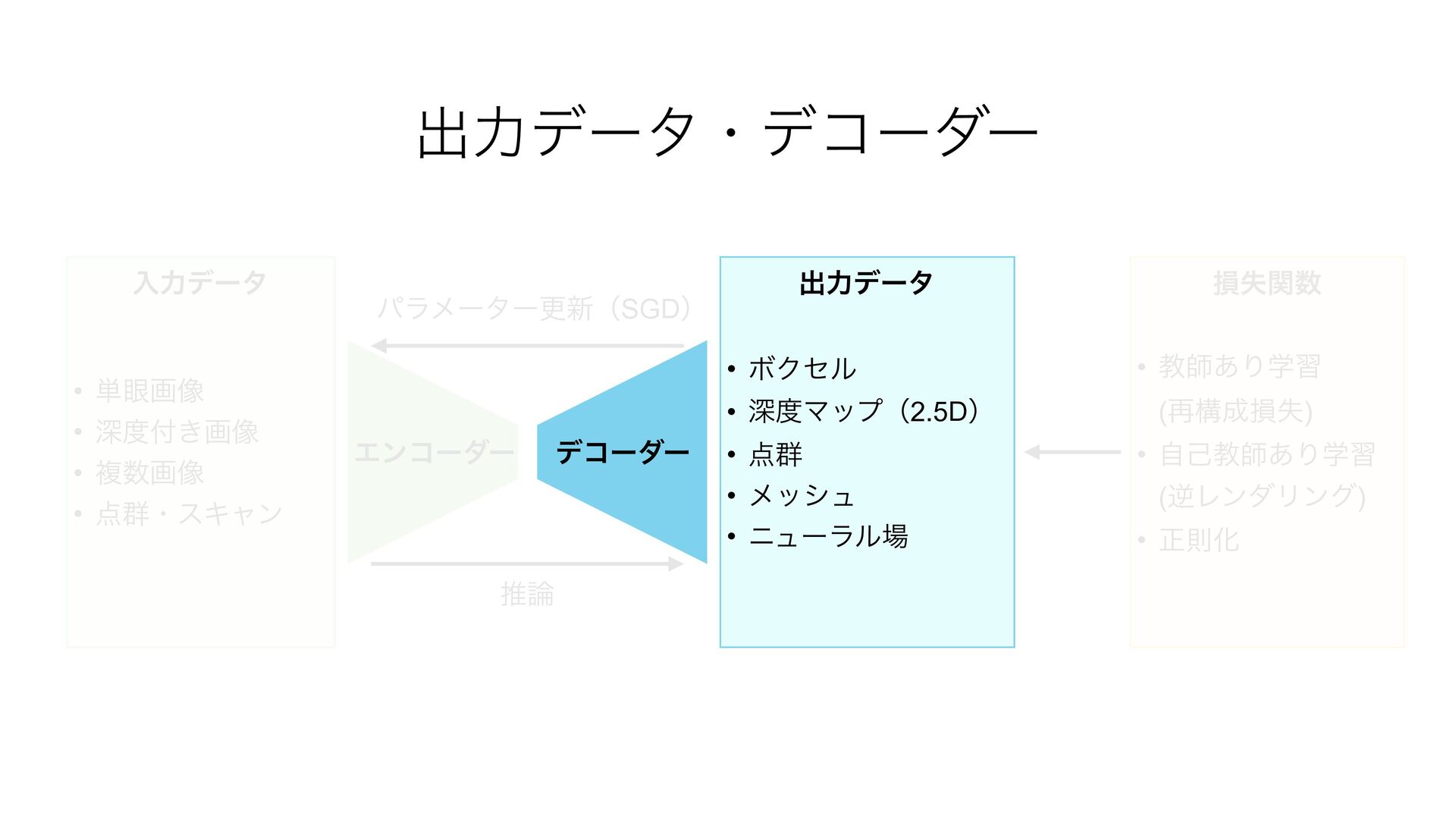{kind=link}
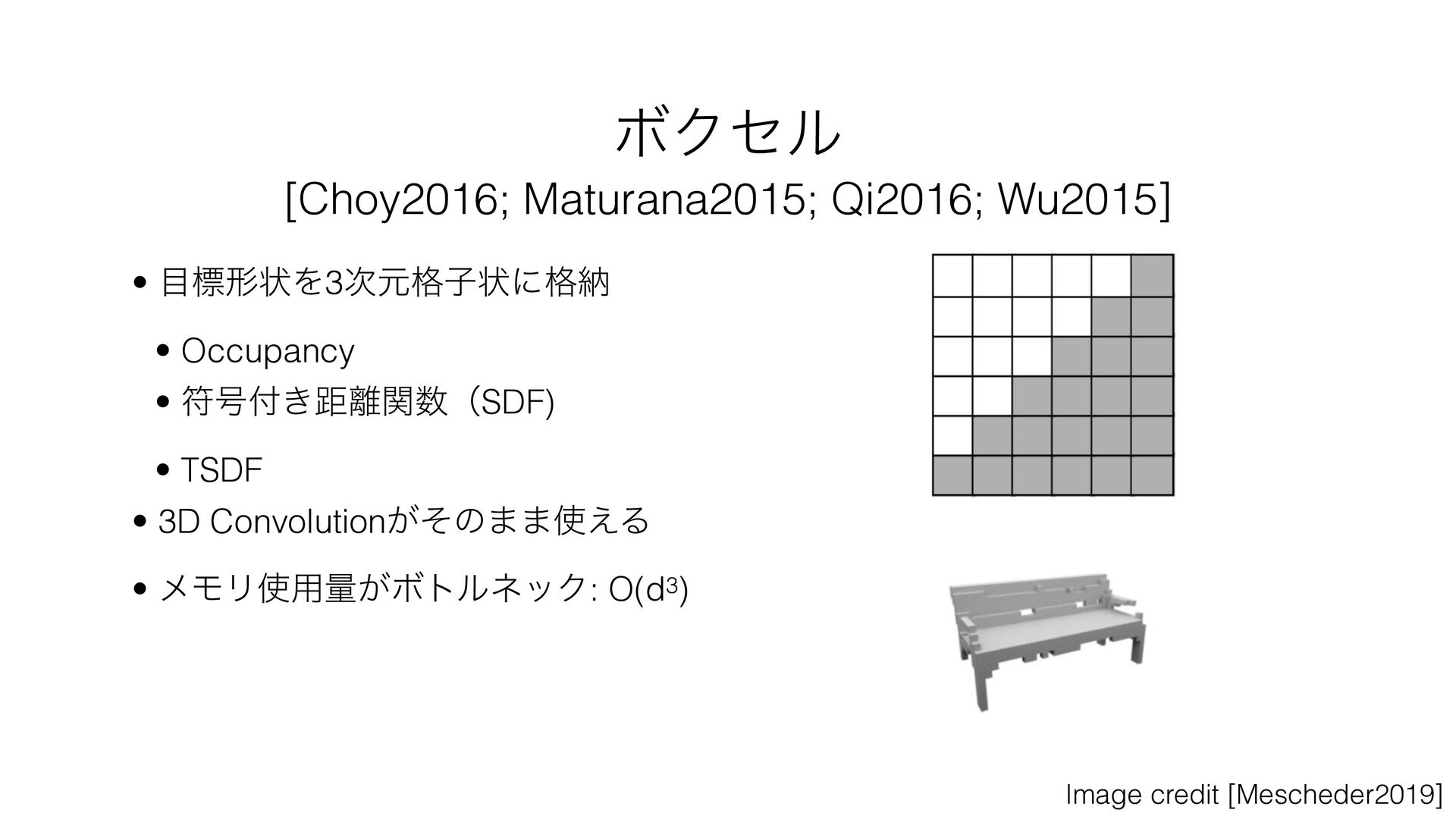{kind=link}
![ϘΫηϧ Ԡ༻ྫɿ̍ຕը૾͔ΒͷNon-parametricͳ3࣍ݩإ෮ݩ [Jackson2017]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_29.jpg){kind=link}
![ϘΫηϧ Ԡ༻ྫɿܕͷύϥϝʔλԽٴͼը૾͔Βͷਪఆ [Saito2018]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_30.jpg){kind=link}
![[Saito2018]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_31.jpg){kind=link}
![[Saito2018]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_32.jpg){kind=link}
![ϘΫηϧ 8ߏΛ༻͍ͨޮతͳ3࣍ݩܗঢ়෮ݩ [Reigler2017, Tatarchenko2017]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_33.jpg){kind=link}
{kind=link}
![ਂϚοϓ Ԡ༻ྫɿ֦ࢄϞσϧΛ༻͍ͨଟࢹεςϨΦ [Shao2022]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_35.jpg){kind=link}
![܈ [Fan2017] • ඪܗঢ়Λͷू߹ͱͯ͠දݱ • શΛಉ࣌ʹग़ྗ͢ΔΞϓϩʔν͕ओྲྀ • τϙϩδʔͷมԽʹॊೈͰେ͖ͳมܗʹରԠՄ • ܈͔ΒϨϯμϦϯάͷͨΊʹϝογϡԽ͢Δ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_36.jpg){kind=link}
![܈ [Fan2017] ը૾͔ΒજࡏมΛճؼ͢ΔΤϯίʔμʔͱ જࡏม͔Β܈Λు͖ग़͢σίʔμʔΛֶश͢Δ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_37.jpg){kind=link}
![܈ͷԠ༻ྫ ਖ਼نʹԊͬͯ αϯϓϧ͞Εͨ܈ λʔήοτ3࣍ݩܗঢ় ࿈ଓਖ਼نԽྲྀ ࿈ଓਖ਼نԽྲྀʹΑΔ܈ϞσϦϯά [Yang2020]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_38.jpg){kind=link}
![࿈ଓਖ਼نԽྲྀʹΑΔ܈ϞσϦϯά [Yang2020] ֶश࣌ʢΦʔτΤϯίʔμʔʣ ਪʢαϯϓϦϯάʣ ܈ͷԠ༻ྫ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_39.jpg){kind=link}
![܈Λ༻͍ͨଟࢹεςϨΦ [Chen2020] ܈ͷԠ༻ྫ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_40.jpg){kind=link}
![܈Λ༻͍ͨଟࢹεςϨΦ [Chen2020] CNNʹΑΔ ଟہॴಛྔ CNN ૈ͍ਂϚοϓ ਖ਼ղ ࠩ ܈্Ͱͷվྑ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_41.jpg){kind=link}
![܈ͷԠ༻ྫ ܈Λ༻͍ͨNeRF [Xu2022] ߴਫ਼ˍߴͳֶशΛ࣮ݱ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_42.jpg){kind=link}
{kind=link}
![ϝογϡ Graph Convolution [Ranjan2020] શ݁߹Ͱͳ͘ɺ֊తͳܗঢ়ͷֶश͕Ͱ͖ΔͷͰ গͳ͍ύϥϝʔλʔͰΑΓදݱྗͷ͋ΔϞσϧ͕࣮ݱͰ͖Δ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_44.jpg){kind=link}
![ϝογϡ જࡏม શͷू߹ มܗޙͷ3࣍ݩ࠲ඪ Ξτϥε [Groueix2018; Yang2018] MLP z MLP](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_45.jpg){kind=link}
![ϝογϡ มܗޙͷ3࣍ݩ࠲ඪ Ξτϥε [Groueix2018; Yang2018] MLP z P • ܗঢ়શମͷ࠲ඪͷΛֶश͢Δ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_46.jpg){kind=link}
![ϝογϡ Ξτϥε [Groueix2018; Yang2018] • ܗঢ়શମͷ࠲ඪͷΛֶश͢Δ ΘΓʹɺ֤ฏ໘ͷ“มܗ”ͱֶͯ͠शʂ ˠςΫενϟϚοϐϯάͷཁྖ • ද໘ܗঢ়ͷ࿈ଓੑΛߟྀ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_47.jpg){kind=link}
![ϝογϡ Ξτϥε [Groueix2018; Yang2018] • ܗঢ়શମͷ࠲ඪͷΛֶश͢Δ ΘΓʹɺ֤ฏ໘ͷ“มܗ”ͱֶͯ͠शʂ ˠςΫενϟϚοϐϯάͷཁྖ • ද໘ܗঢ়ͷ࿈ଓੑΛߟྀ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_48.jpg){kind=link}
![ϝογϡʗΞτϥε Ԡ༻ྫɿϦΪϯάΛߟྀͨ͠Ξτϥε܈ʹΑΔணҥΞόλʔ[Ma2021]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_49.jpg){kind=link}
![ϝογϡʗΞτϥε [Ma2021] Ԡ༻ྫɿϦΪϯάΛߟྀͨ͠Ξτϥε܈ʹΑΔணҥΞόλʔ[Ma2021]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_50.jpg){kind=link}
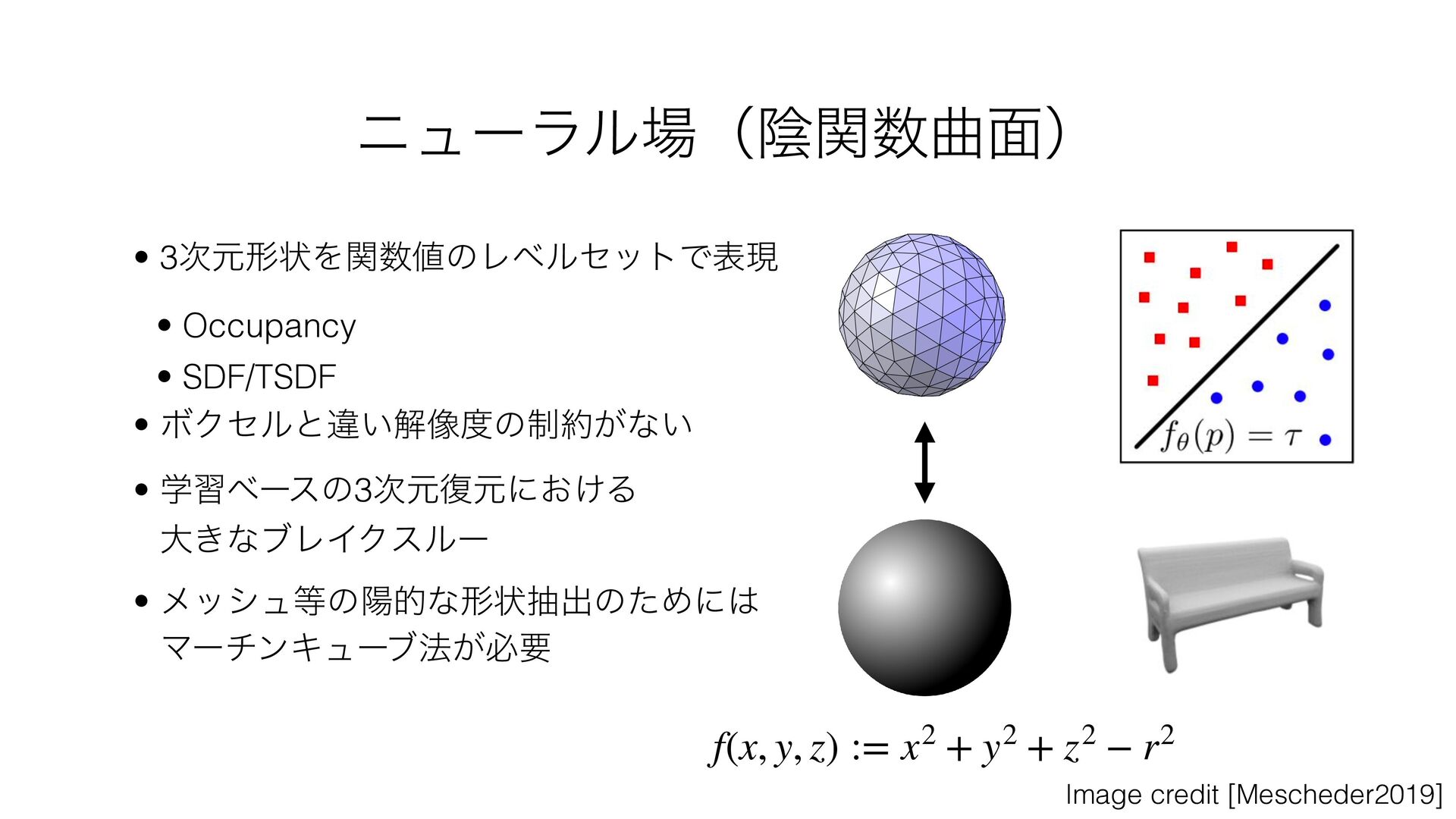{kind=link}
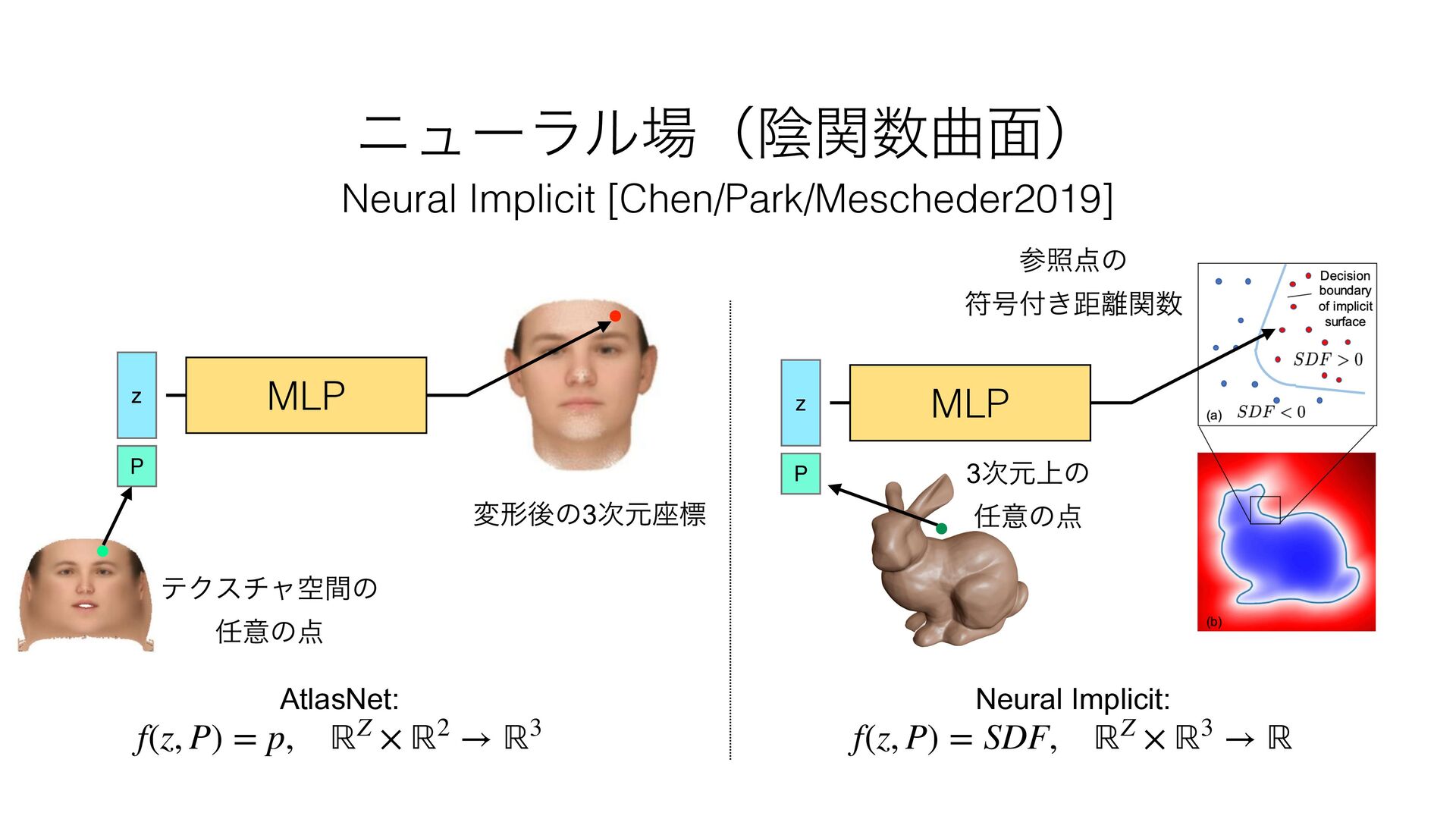{kind=link}
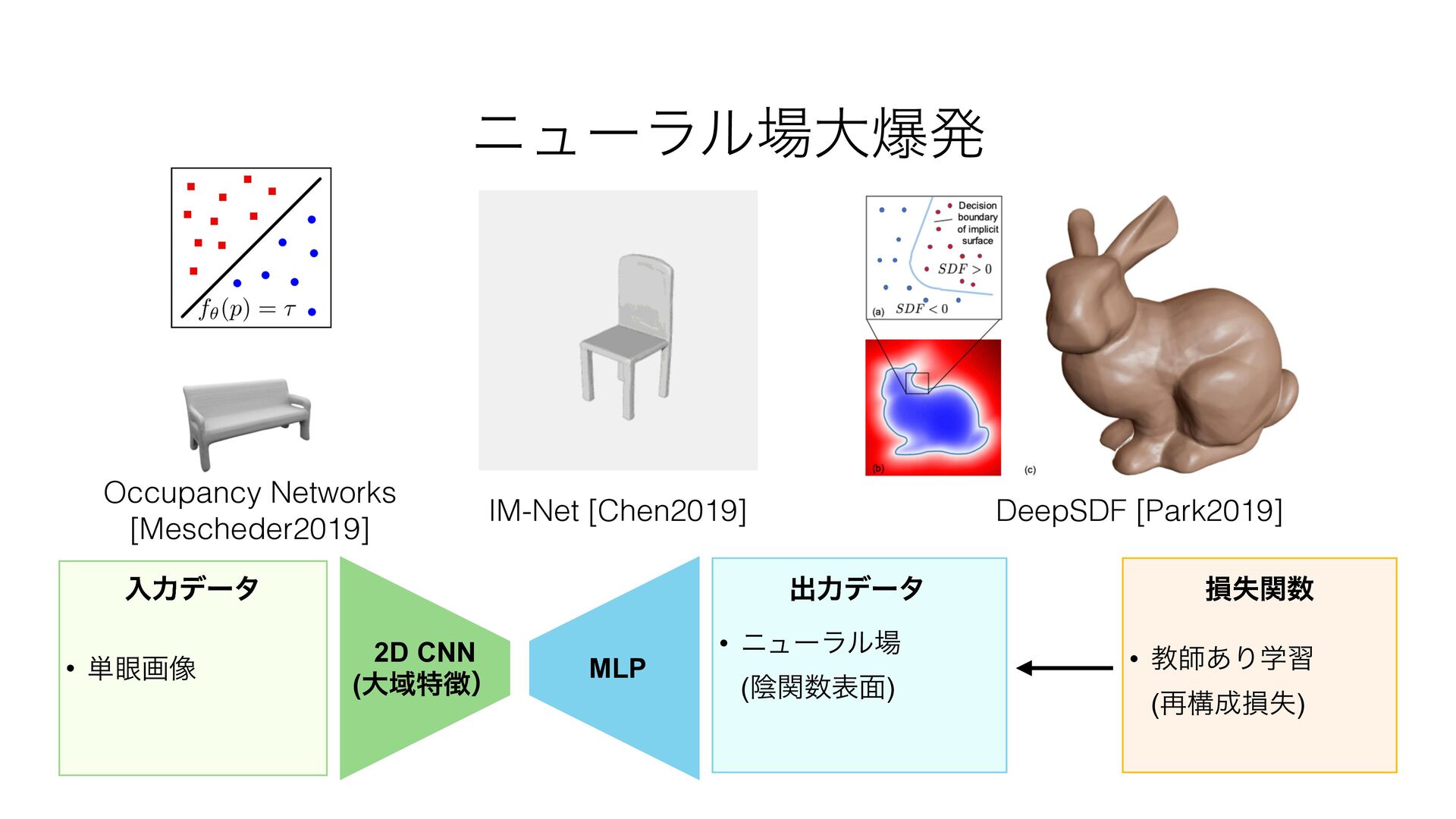
![Neural Implicit [Chen/Park/Mescheder2019] χϡʔϥϧʢӄؔۂ໘ʣ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_53.jpg){kind=link}
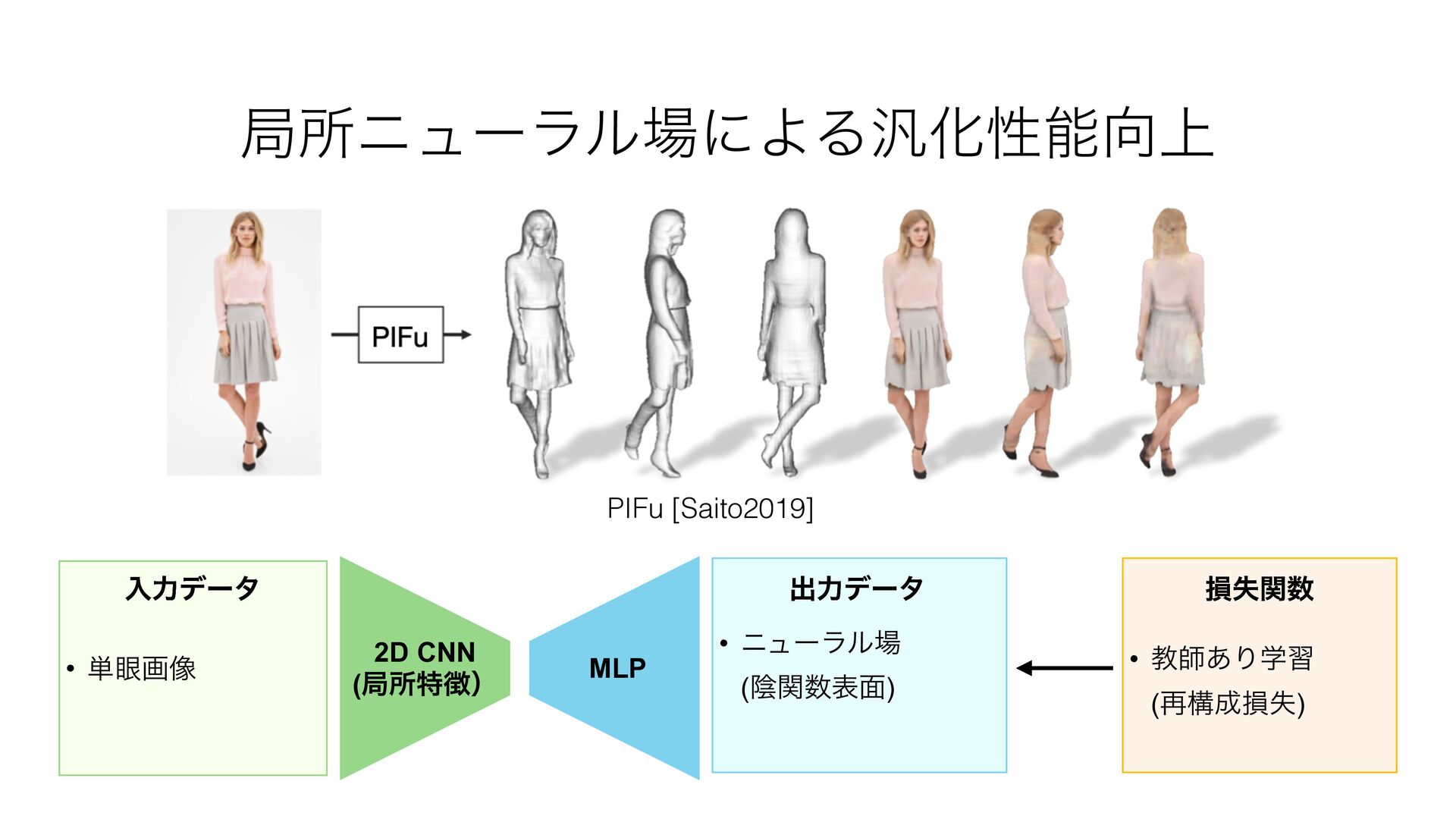
![ըૉ୯ҐͷӄؔදݱʢPIFu) [Saito2019/2020] RC • ࡉ෦ͷσΟςʔϧ͕ࣦΘΕͨΓɺଟ༷ͳܗঢ়ͷόϦΤʔγϣϯʹରԠͰ͖ͳ͍ • ෳࢹͷը૾Λ߹ੑΛอͬͨ··౷߹͢Δ͜ͱ͕ࠔ େҬతͳΤϯίʔσΟϯά MLP χϡʔϥϧʢӄؔۂ໘ʣ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_54.jpg){kind=link}
![େҬతͳΤϯίʔσΟϯά • ࡉ෦ͷσΟςʔϧ͕ࣦΘΕͨΓɺଟ༷ͳܗঢ়ͷόϦΤʔγϣϯʹରԠͰ͖ͳ͍ • ෳࢹͷը૾Λ߹ੑΛอͬͨ··౷߹͢Δ͜ͱ͕ࠔ RC ըૉ୯ҐͷӄؔදݱʢPIFu) [Saito2019/2020] MLP χϡʔϥϧʢӄؔۂ໘ʣ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_55.jpg){kind=link}
![RW×H×C ըૉ୯ҐͷӄؔදݱʢPIFu) [Saito2019/2020] • ہॴతͳը૾ಛྔΛ͏͜ͱͰɺগͳ͍σʔλ͔ΒͰߴਫ਼ͳ෮ݩΛ࣮ݱ • 3࣍ݩ্ۭؒͰಛΛ౷߹Ͱ͖ΔͷͰҙͷೖྗࢹʹରԠ͕Մೳ ըૉϨϕϧͰͷΤϯίʔσΟϯά MLP χϡʔϥϧʢӄؔۂ໘ʣ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_56.jpg){kind=link}
![[Saito2019]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_57.jpg){kind=link}
![PIFuHD [Saito2020] PIFu [Saito2019]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_58.jpg){kind=link}
![[Saito2020]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_59.jpg){kind=link}
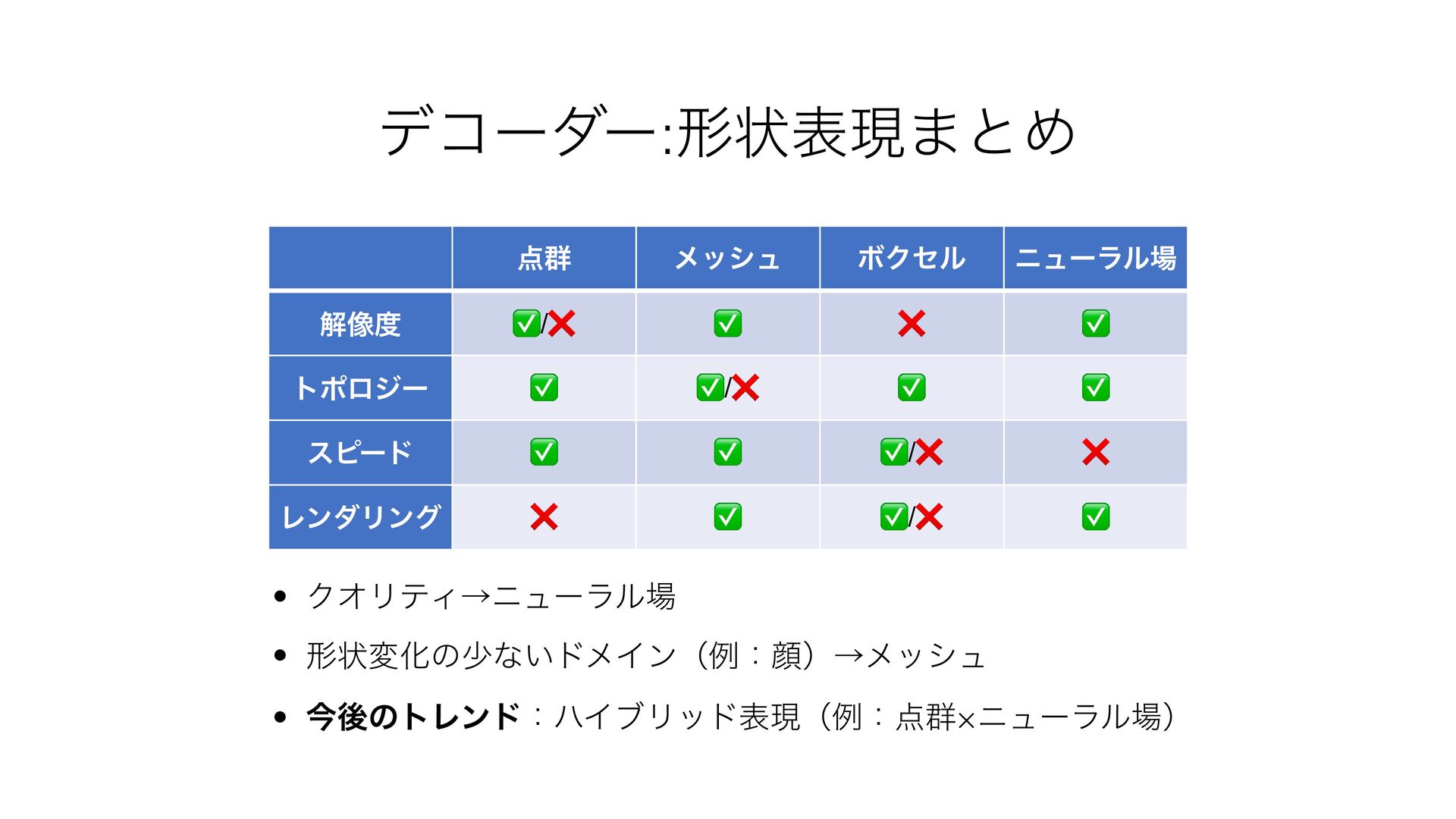{kind=link}
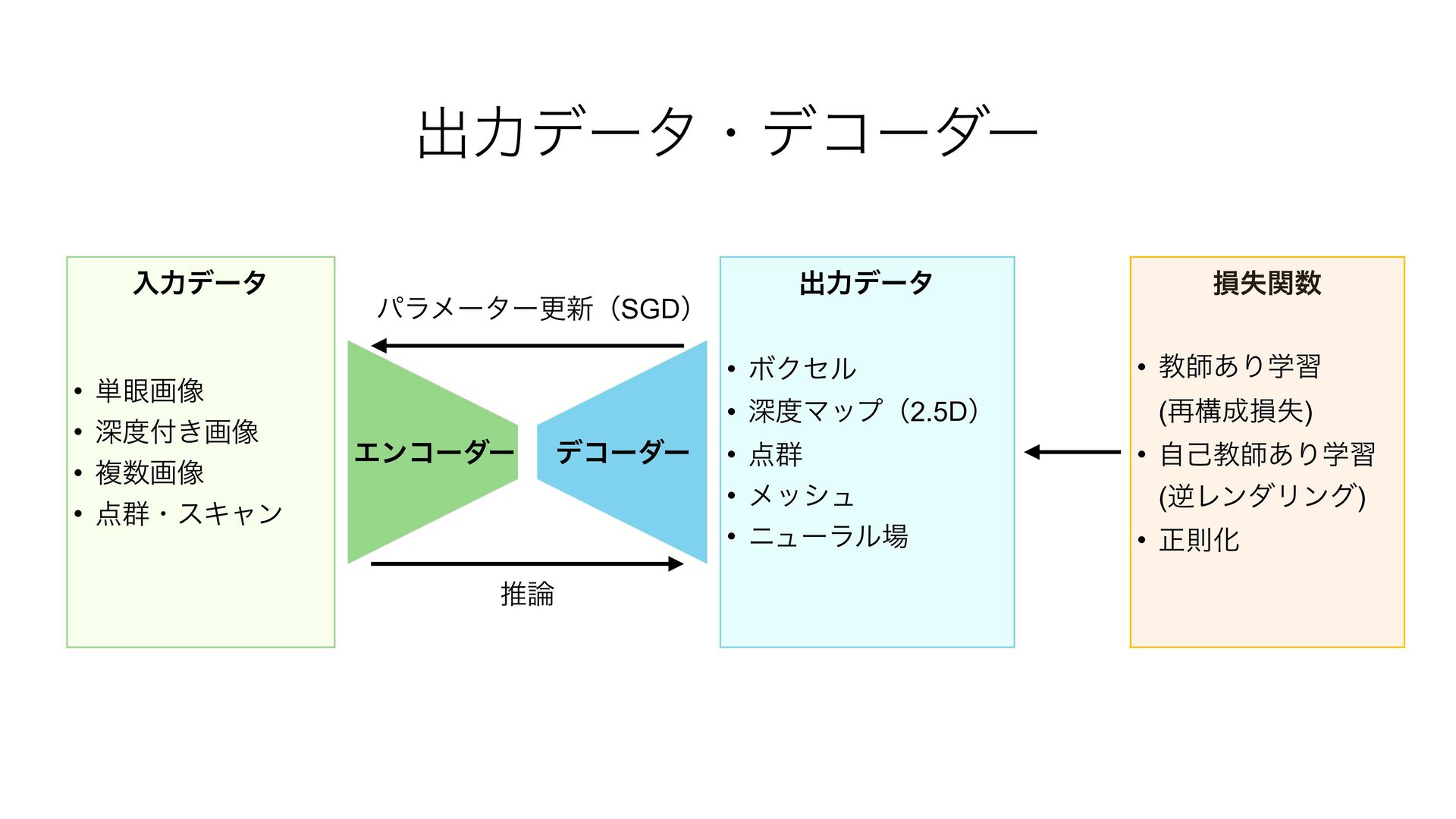{kind=link}
{kind=link}
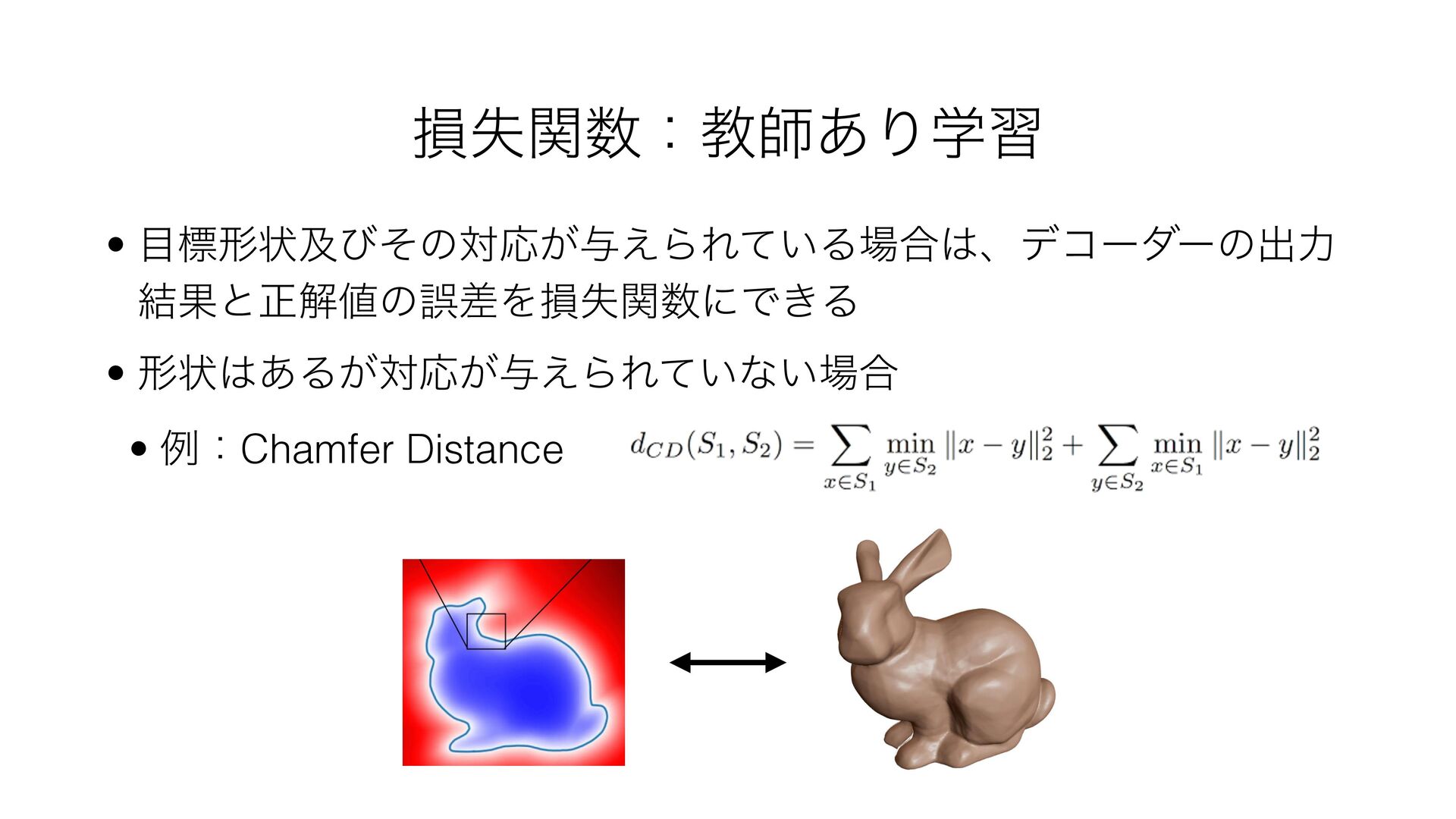{kind=link}
{kind=link}
![• ਖ਼ଇԽ߲ΛΈ߹ΘͤΔ͜ͱͰܗঢ়ʹ੍Λ͔͚Δ͜ͱ͕Ͱ͖Δ • Ill-posedͳઃఆͰಛʹ༗ޮ ଛࣦؔɿਖ਼ଇԽ߲ ଌઢ੍ʢLIMP [Cosmo2020]) ӄؔͷද໘๏ઢͷLpϊϧϜͷ૯Λ੍߲ʹ [Liu2019b]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_65.jpg){kind=link}
![ଛࣦؔɿਖ਼ଇԽ߲ Ԡ༻ྫɿԁ੍Λ׆༻ͨ͠4DεΩϟϯ͔ΒͷΞόλʔֶश [Saito2021] LBS−1 xs xc](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_66.jpg){kind=link}
![ଛࣦؔɿਖ਼ଇԽ߲ Ԡ༻ྫɿԁ੍Λ׆༻ͨ͠4DεΩϟϯ͔ΒͷΞόλʔֶश [Saito2021] LBS−1 LBS xs xc xp](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_67.jpg){kind=link}
![ଛࣦؔɿਖ਼ଇԽ߲ Ԡ༻ྫɿԁ੍Λ׆༻ͨ͠4DεΩϟϯ͔ΒͷΞόλʔֶश [Saito2021] LBS−1 LBS xs xc xp ಉ͡ܗঢ়ʹҰக͢Δͣ xs](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_68.jpg){kind=link}
![[Saito2021]](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_69.jpg){kind=link}
![ଛࣦؔɿਖ਼ଇԽ߲ χϡʔϥϧͷϦϓγοπ࿈ଓਖ਼نԽ [Liu2022] τϨϯυᶃɿதؒͷਖ਼ଇԽ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_70.jpg){kind=link}
![ଛࣦؔɿਖ਼ଇԽ߲ ޯͷϥϓϥγΞϯਖ਼ଇԽ [Nicolet2021] τϨϯυᶄɿޯͷਖ਼ଇԽ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_71.jpg){kind=link}
![ଛࣦؔɿਖ਼ଇԽ߲ ճసಉมͳOptimizerʢVectorAdam [Ling2022]ʣ τϨϯυᶅɿOptimizerͷਖ਼ଇԽ](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_72.jpg){kind=link}
{kind=link}
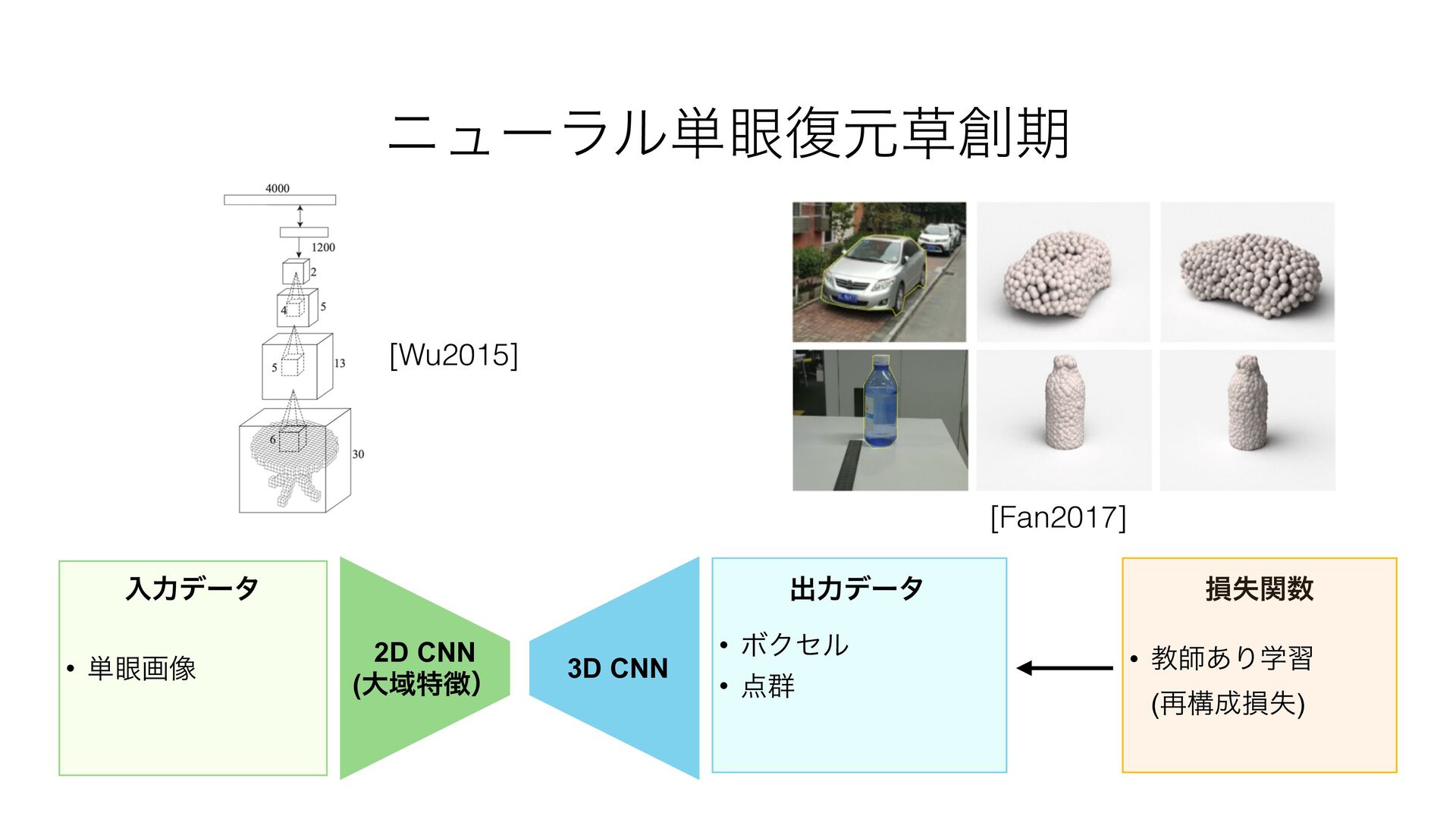{kind=link}
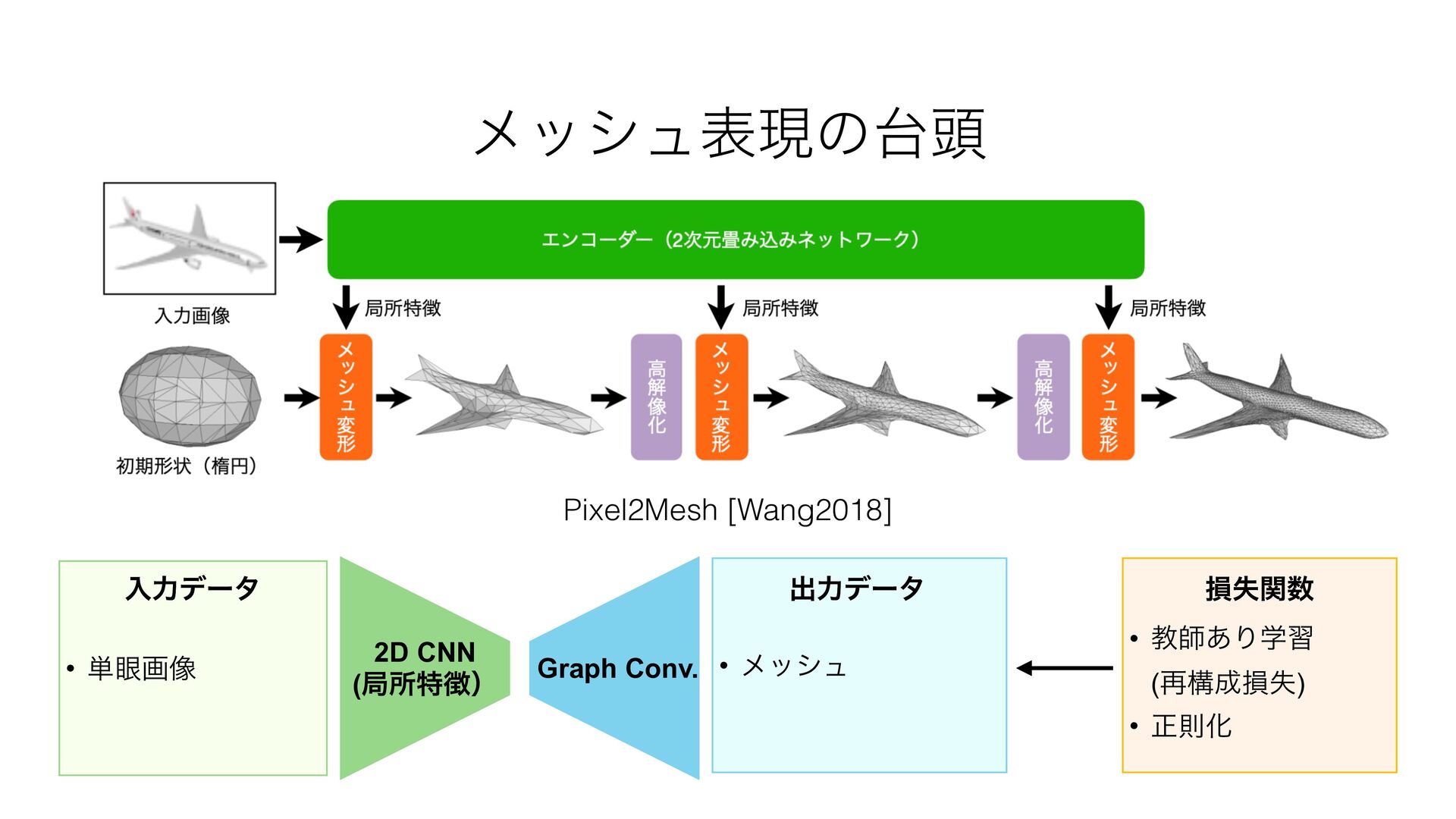{kind=link}
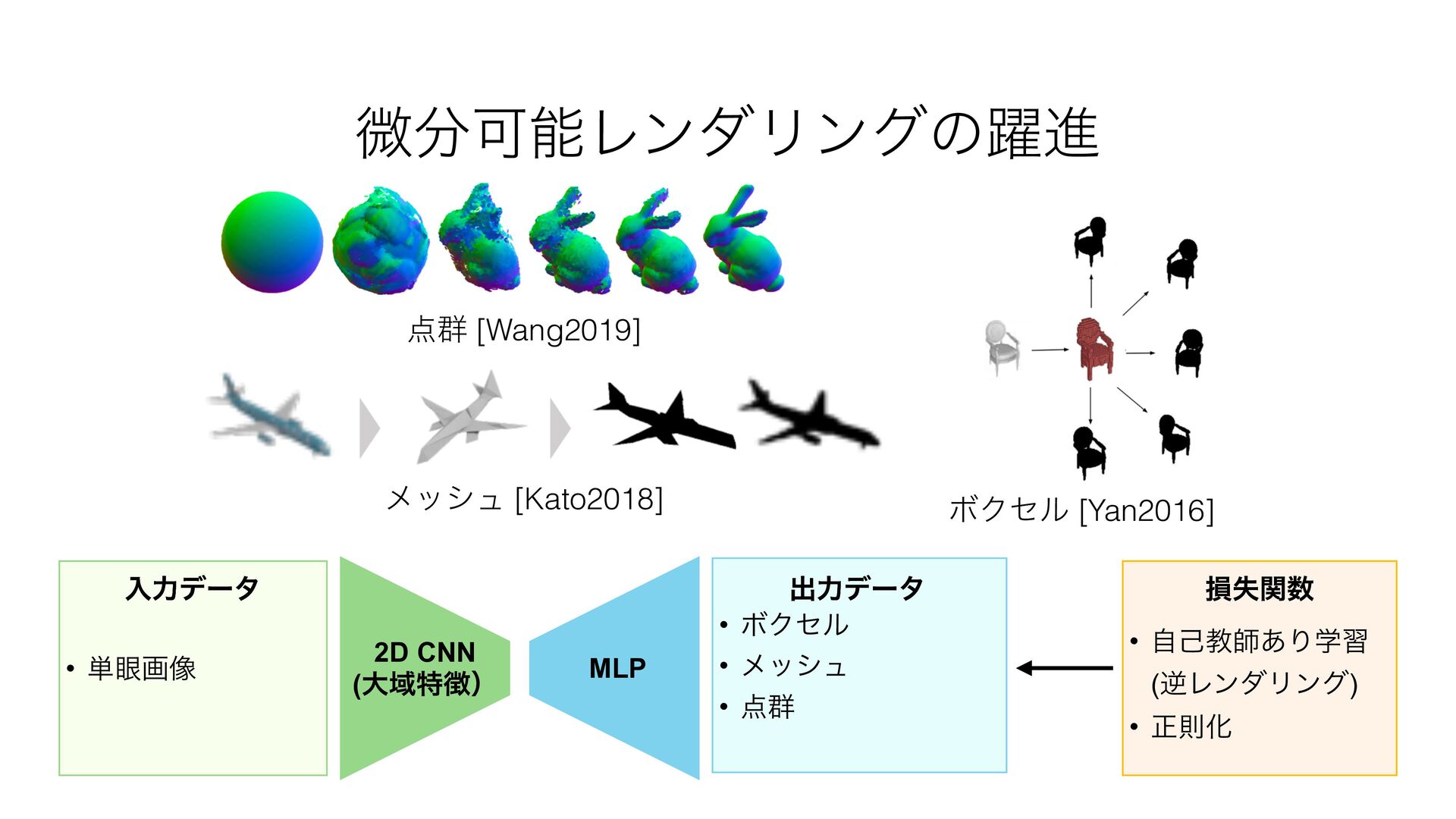{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
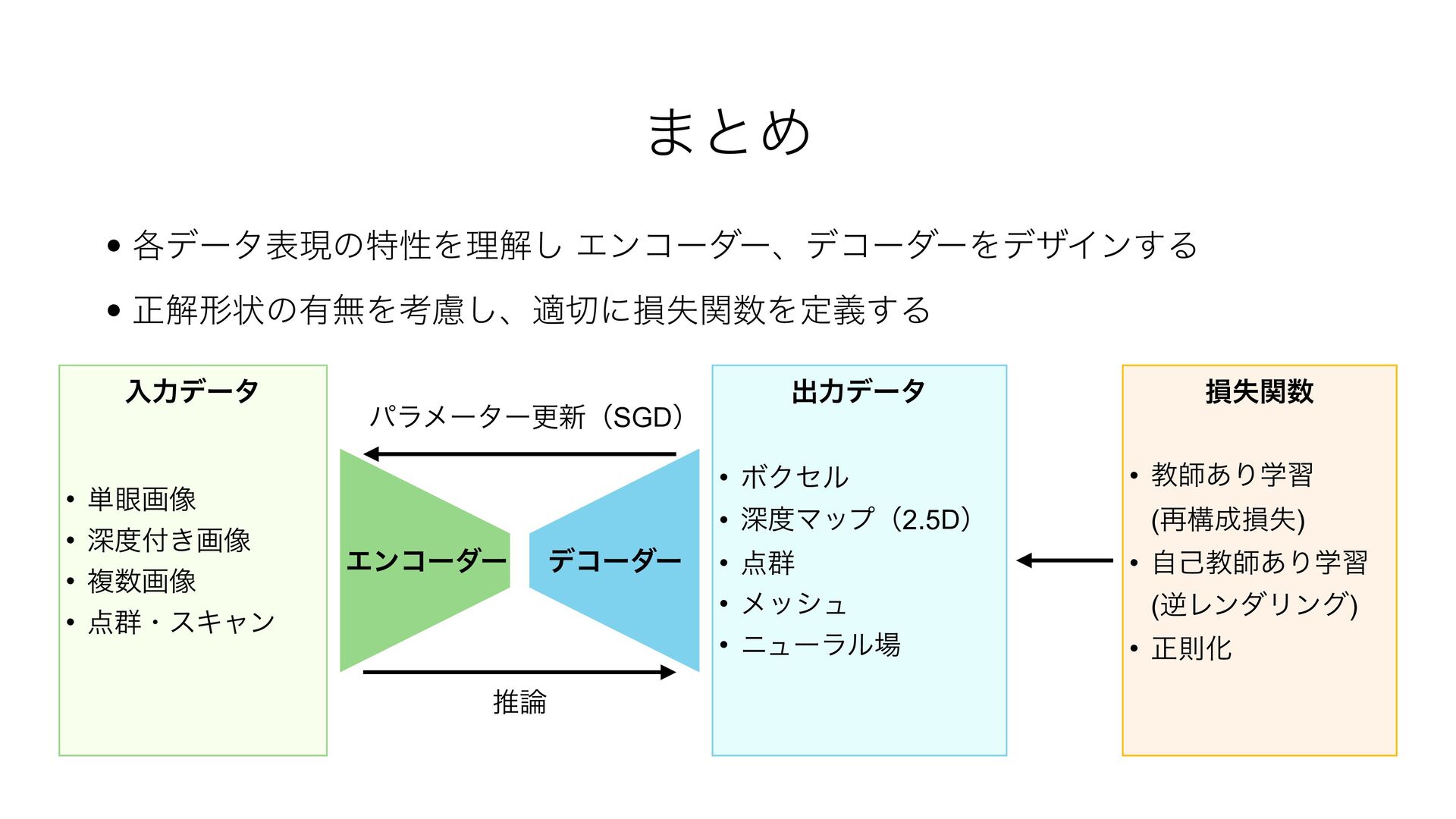{kind=link}
![Ҿ༻Ϧετᶃ • [Blanz1999] Blanz, Volker, and Thomas Vetter. "A morphable](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_82.jpg){kind=link}
![Ҿ༻Ϧετᶄ • [Lin2022] Kai-En Lin, Lin Yen-Chen, Wei-Sheng Lai, Tsung-Yi](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_83.jpg){kind=link}
![Ҿ༻Ϧετᶅ • [Qi2017] Qi, Charles R., et al. "Pointnet: Deep](https://files.speakerdeck.com/presentations/12baa864805b4eb4a03f1178dc3e497d/slide_84.jpg){kind=link}