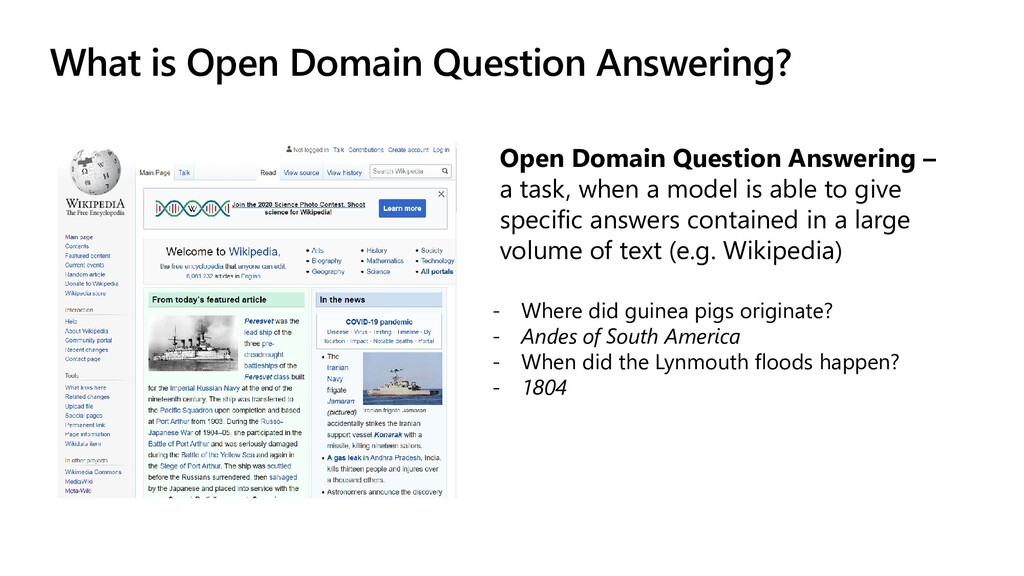
– a task, when a model is able to give specific answers contained in a large volume of text (e.g. Wikipedia) - Where did guinea pigs originate? - Andes of South America - When did the Lynmouth floods happen? - 1804
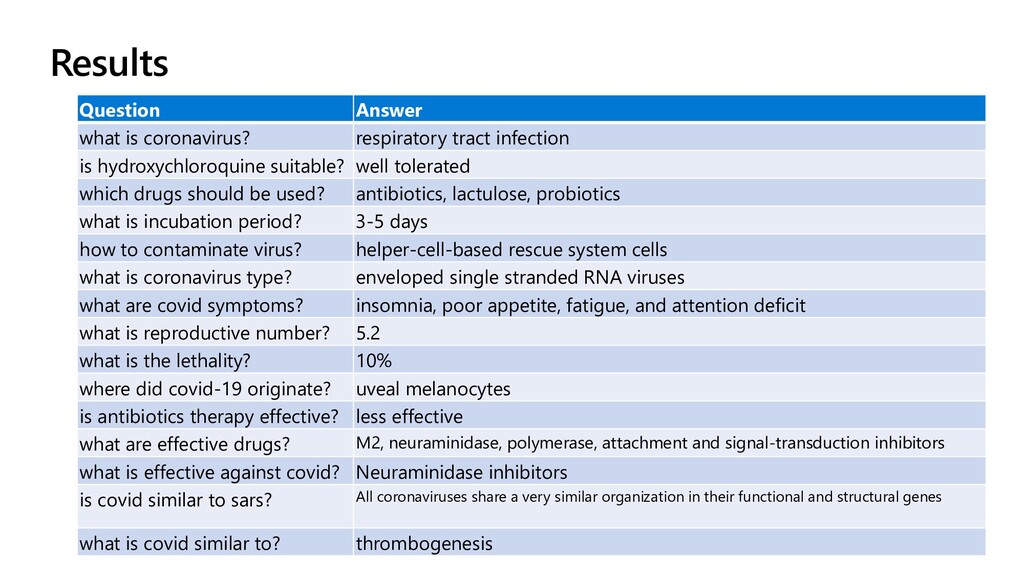
respiratory tract infection - what is reproductive number? - 5.2 - Is COVID similar to SARS? - All coronaviruses share a very similar organization in their functional and structural genes https://allenai.org/data/cord-19 CORD-19 Dataset Contains over 63,000 scholarly articles about COVID-19 and the coronavirus family of viruses for use by the global research community
Named Entity Recognition (NER) • Keyword Extraction • Text Summarization • Question Answering Open Domain Question Answering – a task, when a model is able to give specific answers contained in a large volume of text (e.g. Wikipedia) - Where did guinea pigs originate? - Andes of South America - When did the Lynmouth floods happen? - 1804 Neural Language Models: • Recurrent Neural Network (RNN) • LSTM, GRU • Transformers • GPT-2 • BERT • Microsoft Turing-NLG
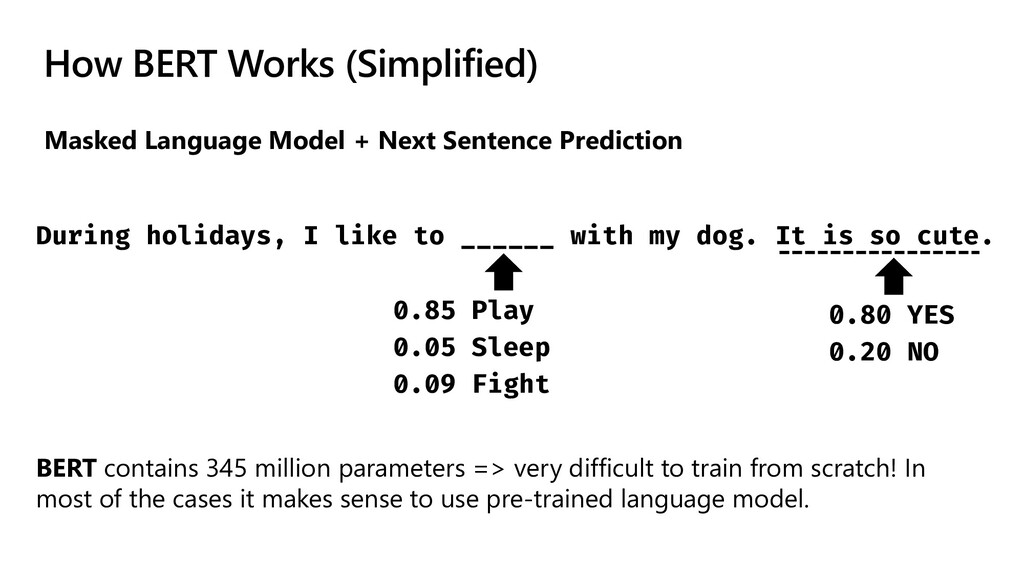
Prediction During holidays, I like to ______ with my dog. It is so cute. 0.85 Play 0.05 Sleep 0.09 Fight 0.80 YES 0.20 NO BERT contains 345 million parameters => very difficult to train from scratch! In most of the cases it makes sense to use pre-trained language model.
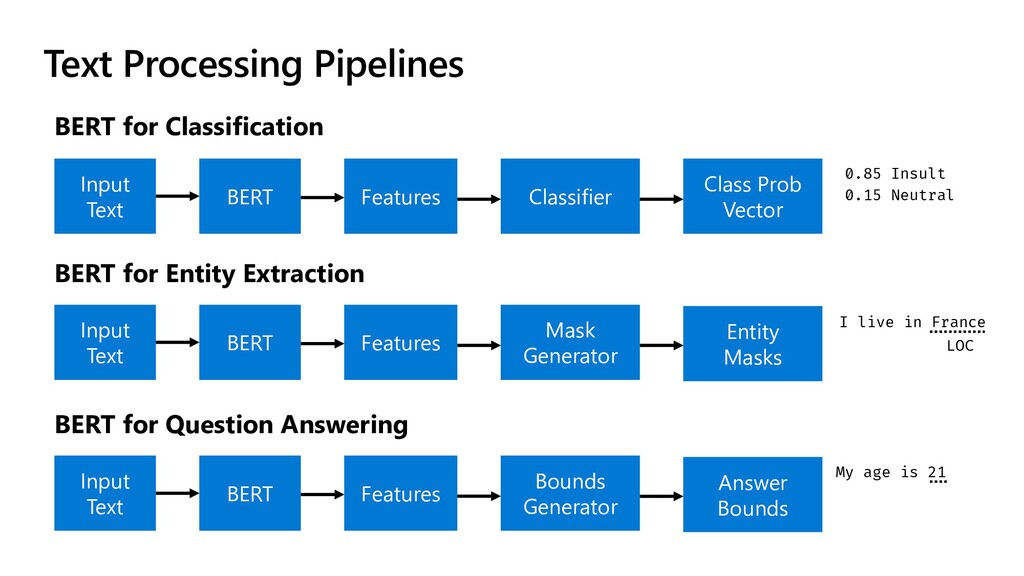
Classifier BERT for Entity Extraction Input Text BERT Features Mask Generator Class Prob Vector Entity Masks BERT for Question Answering Input Text BERT Features Bounds Generator Answer Bounds 0.85 Insult 0.15 Neutral I live in France My age is 21 LOC
install deeppavlov python -m deeppavlov install config.json python -m deeppavlov download config.json python -m deeppavlov train config .json Text processing pipeline is defined in JSON config: • Processing steps, their inputs and outputs • Weight location for pre-trained models • Data shape and location • Training parameters
{ "class_name": "basic_classification_reader", "x": "text", "y": "intents", "data_path": "./snips"}, "dataset_iterator": { "class_name": "basic_classification_iterator", "field_to_split": "train", "split_fields": ["train","valid"]}, "chainer": { "in": ["x"], "in_y": ["y"], "out": ["y_pred"], "pipe": [ ... ] } Sample on github "train": { "batch_size": 64, "metrics": ["accuracy"] } Add Live from Aragon Ballroom to Trapeo, AddToPlaylist add Unite and Win to my night out, AddToPlaylist Add track to my Digster Future Hits, AddToPlaylist add the piano bar to my Cindy Wilson, AddToPlaylist text intents
The best way to start with Azure ML using VS Code • Using Azure ML for Hyperparameter Optimization • Training GAN to Produce Art • Training BERT Question Answering with DeepPavlov ❶ ❷ Try it out: http://github.com/CloudAdvocacy/AzureMLStarter
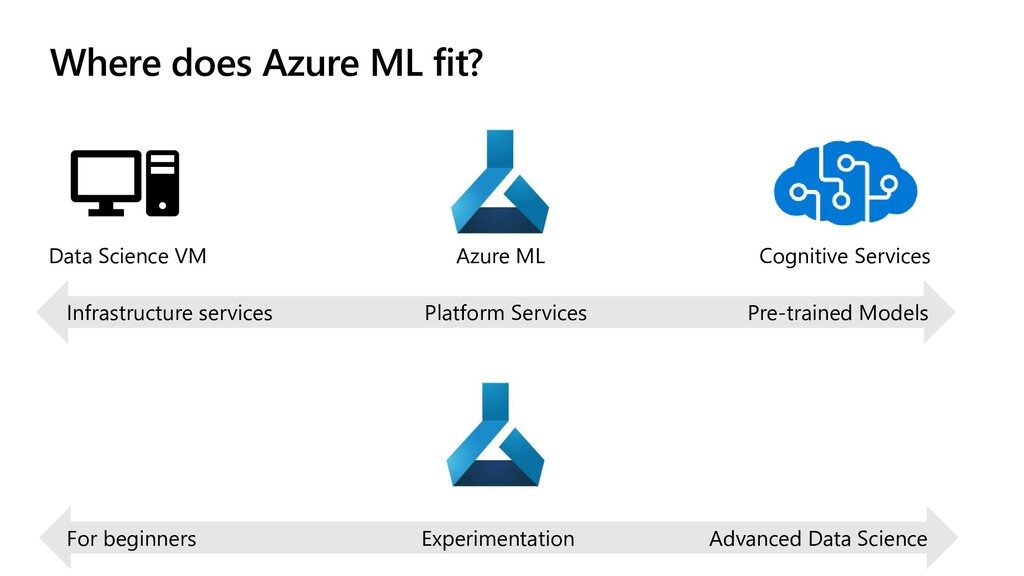
To reduce time to market Azure Databricks Machine Learning VMs Popular frameworks To build advanced deep learning solutions TensorFlow Pytorch Onnx Azure Machine Learning Language Speech … Search Vision Productive services To empower data science and development teams Powerful infrastructure To accelerate deep learning Scikit-Learn PyCharm Jupyter Familiar Data Science tools To simplify model development Visual Studio Code Command line CPU GPU FPGA From the Intelligent Cloud to the Intelligent Edge
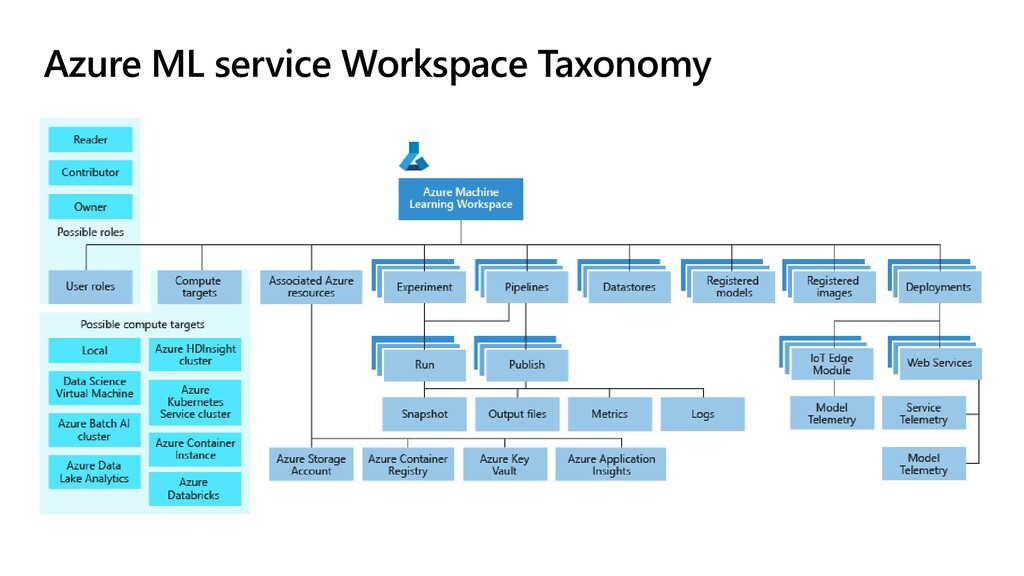
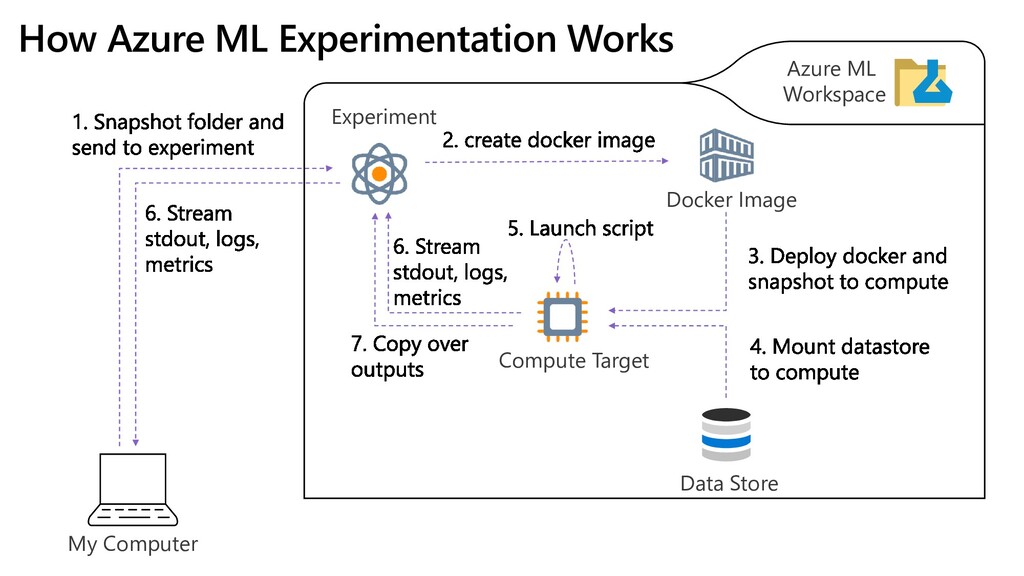
encapsulates it all: 1. Storage 2. Datasets 3. Compute 4. Notebooks 5. Experiment Results 6. Models 7. Deployments ❶ az extension add -n azure-cli-ml az group create -n ml -l westus2 az ml workspace create -w AzML -g ml az ml folder attach -w AzML -g ml Create Workspace using Azure CLI: az ml computetarget create amlcompute -n cpu --min-nodes 0 --max-nodes 2 -s STANDARD_D3_V2 Create Cluster using Azure CLI: MS Docs: HERE
Script + Environment that run on Compute (Local Compute, Azure ML Cluster or Databricks) 1. Auto-package code 2. Keep track of results 3. Store models 4. Queue runs 5. Programmatically spawn many runs with different parameters ❷ az ml run submit-script -c sklearn –e MyExp train.py Submit Experiment using CLI: Log Metrics in the script: from azureml.core.run import Run run = Run.get_submitted_run() run.log('accuracy', acc)
of training, it makes sense to store data inside the workspace. To run Python code inside the workspace – use Notebooks! You need to create separate compute (not cluster) to do that! ❸
use the following features of Azure ML: • Define file dataset that points to data location • Create cheap non-GPU compute for data exploration and preparation • Use GPU-enabled compute on the same data to train the model • All code would be in the form of Jupyter Notebooks We do not use training on Azure ML Cluster in this case to have better control on the environment. DeepPavlov downloads large amounts of pre-trained data from the network, and for simple cases it is better to use single node. Link to the non-commercial CORD-19 dataset: here (.tar.gz)
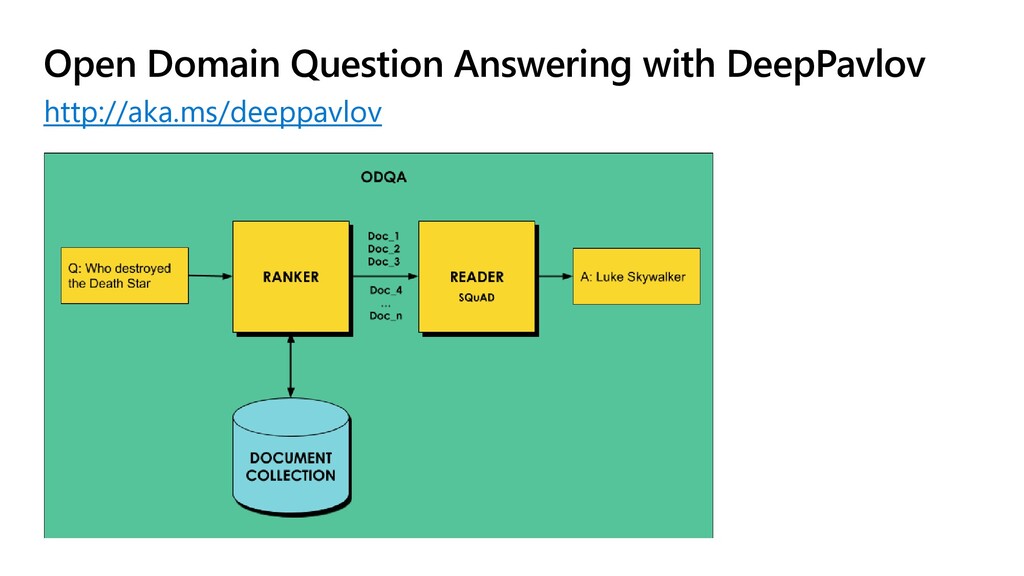
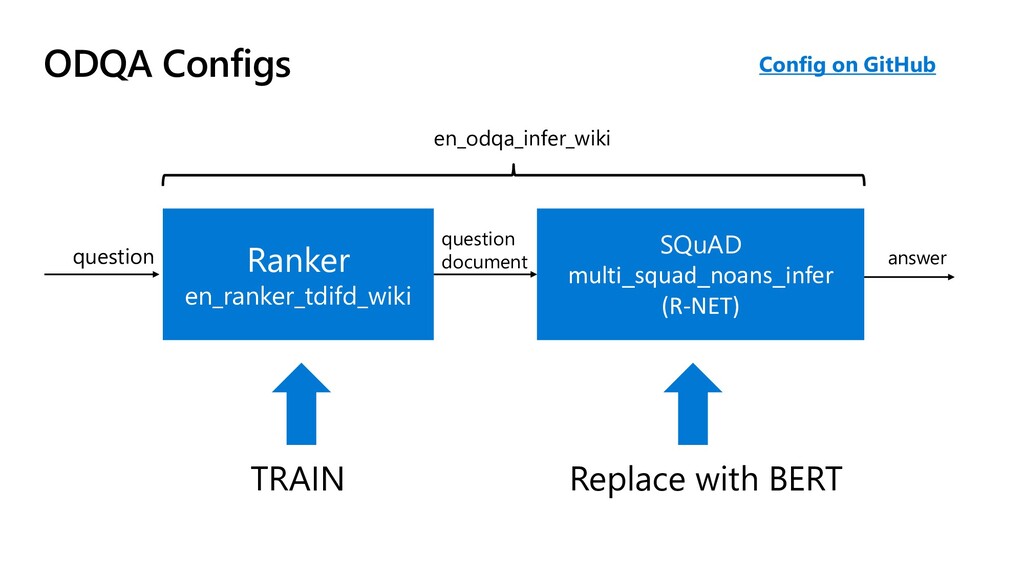
pip install deeppavlov !{sys.executable} -m deeppavlov install en_odqa_infer_wiki !{sys.executable} -m deeppavlov download en_odqa_infer_wiki from deeppavlov import configs from deeppavlov.core.commands.infer import build_model odqa = build_model(configs.odqa.en_odqa_infer_wiki) answers = odqa([ "Where did guinea pigs originate?", "When did the Lynmouth floods happen?" ]) # Get the Library and Required Models # Build Model from Config and Run Inference ['Andes of South America', '1804']
model_config["dataset_reader"]["data_path"] = os.path.join(os.getcwd(),"text") model_config["dataset_reader"]["dataset_format"] = "txt" model_config["train"]["batch_size"] = 1000 # Specify Data Path & Format doc_retrieval = train_model(model_config) doc_retrieval(['hydroxychloroquine']) # Train the Model and See the Results "dataset_reader": { "class_name": "odqa_reader", "data_path": "{DOWNLOADS_PATH}/odqa/enwiki", "save_path": "{DOWNLOADS_PATH}/odqa/enwiki.db", "dataset_format": "wiki" } Part of en_ranker_tfidf_wiki config
True) # Do not download the ODQA models, we've just trained it odqa = build_model(configs.odqa.en_odqa_infer_wiki, download = False) odqa(["what is coronavirus?","is hydroxychloroquine suitable?"]) ['an imperfect gold standard for identifying King County influenza admissions', 'viral hepatitis']
suitable? well tolerated which drugs should be used? antibiotics, lactulose, probiotics what is incubation period? 3-5 days how to contaminate virus? helper-cell-based rescue system cells what is coronavirus type? enveloped single stranded RNA viruses what are covid symptoms? insomnia, poor appetite, fatigue, and attention deficit what is reproductive number? 5.2 what is the lethality? 10% where did covid-19 originate? uveal melanocytes is antibiotics therapy effective? less effective what are effective drugs? M2, neuraminidase, polymerase, attachment and signal-transduction inhibitors what is effective against covid? Neuraminidase inhibitors is covid similar to sars? All coronaviruses share a very similar organization in their functional and structural genes what is covid similar to? thrombogenesis Results
Smart search on paper corpus • Clustering papers based on terminology / semantics • Trend monitoring • Automatic summarization ❶ ❷ Try out Azure Machine Learning: • http://github.com/CloudAdvocacy/AzureMLStarter • http://aka.ms/azmlstarter - Blog Post
to generate paintings http://aka.ms/azml_gan Can AI be creative http://aka.ms/creative_ai Creating interactive exhibit based on cognitive portraits http://aka.ms/cognitive_portrait_exhibit Training COVID ODQA on Azure ML: http://aka.ms/deeppavlov
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Pipeline "chainer": { "in": ["x"], "in_y": ["y"], "out": ["y_pred"], "pipe":](https://files.speakerdeck.com/presentations/a01a0dc8a8d74b85927a8c5dfd54686d/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}