A DevOps perspective on GeoServer: Deployment planning guidelines
If you intend to deploy GeoServer or if you are already managing a GeoServer deployment, we believe this webinar can help provide some good hints based on our experience with real world use cases.
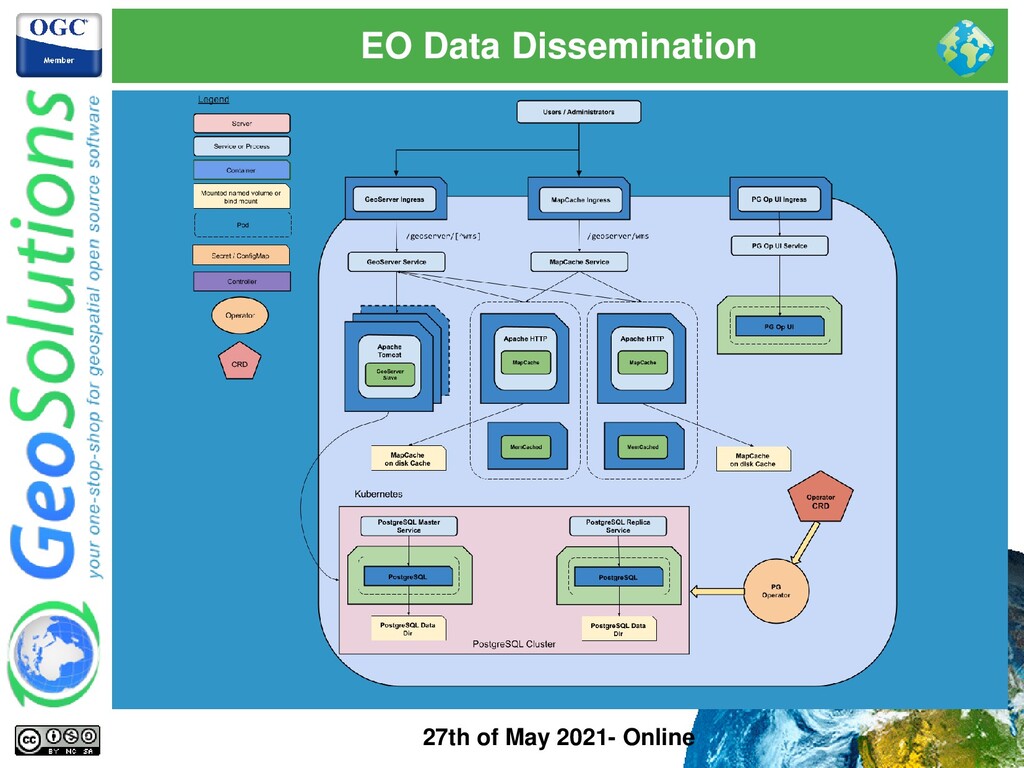
to start ⚫ GeoServer key facts ⚫ Analyzing your data & scenario ⚫ Common Mistakes ⚫ Real World Use Cases ⚫ Conclusions & Next Steps 27th of May 2021- Online
⚫ Our core products ⚫ Our offer Enterprise Support Services Deployment Subscription Professional Training Customized Solutions GeoNode 27th of May 2021- Online
core We actively participate in OGC working groups and get funded to advance new open standards We support standards critical to GEOINT 27th of May 2021- Online
and GeoNetwork ⚫ Vast experience with Raster Serving ⚫ Designed and developed JAI-Ext ⚫ Designed and developed ImageIO-Ext ⚫ Design and Developed most raster code in GeoTools/GeoServer ⚫ Vast Experience with Vector Data Serving ⚫ WFS, WMS, Vector Tiles with OGV ⚫ Extensive Experience with Spatial DBMS ⚫ Oracle, SQL Server, Postgis, MongoDB, etc.. ⚫ Extensive Experience with creating webgis applications ⚫ OpenLayers, Leaflet, Cesium, MapboxGL ⚫ Ext-JS, JQuery, Bootstrap, Angular, React, Redux ⚫ Extensive Experience with OGC Protocols ⚫ Extensive Experience in Performance and Scalability (Big Data and Cloud) ⚫ Unparalleled multi-industry experience 27th of May 2021- Online
Scalable ⚫ We should be able to accommodate more users by adding more hardware/software resources without code refactoring (within reason…) ⚫ Robust ⚫ Simply put, it is up most of the time with no intervention ⚫ Performant ⚫ Who likes slow maps? ⚫ Maintainable ⚫ Adding data, upgrading components, refining the configuration should not be unnecessarily hard and automated when possible ⚫ Observable ⚫ When something goes wrong, we need to have actionable insights to tell us what to do ⚫ Repeatable ⚫ Many more…
Reality check ⚫ If you never have problems in production, it means nobody is using your services! ⚫ Be Prepared ⚫ Set up a representative STG environment ⚫ Set up Monitoring/Logging ⚫ Set up Analytics/Metering ⚫ Set up Alerts ⚫ Set up Watchdogs ⚫ Set up Troubleshooting tools/procedures ⚫ Be Proactive ⚫ Periodic Automated/Manual Preventive Checks ⚫ Periodic Automated/Manual Load Tests ⚫ Keep technical debts under control (easier said than done…)
data ✓ Study/Analyze your users/scenario ✓ Study/Analyze the deployment environment ✓ Study/Analyze GeoServer strengths and limitations wrt to the above (we can help here ) ✓ Prepare a deployment plan ✓ Repeat → perfect comes from practice! • Do your homework or suffer forever!
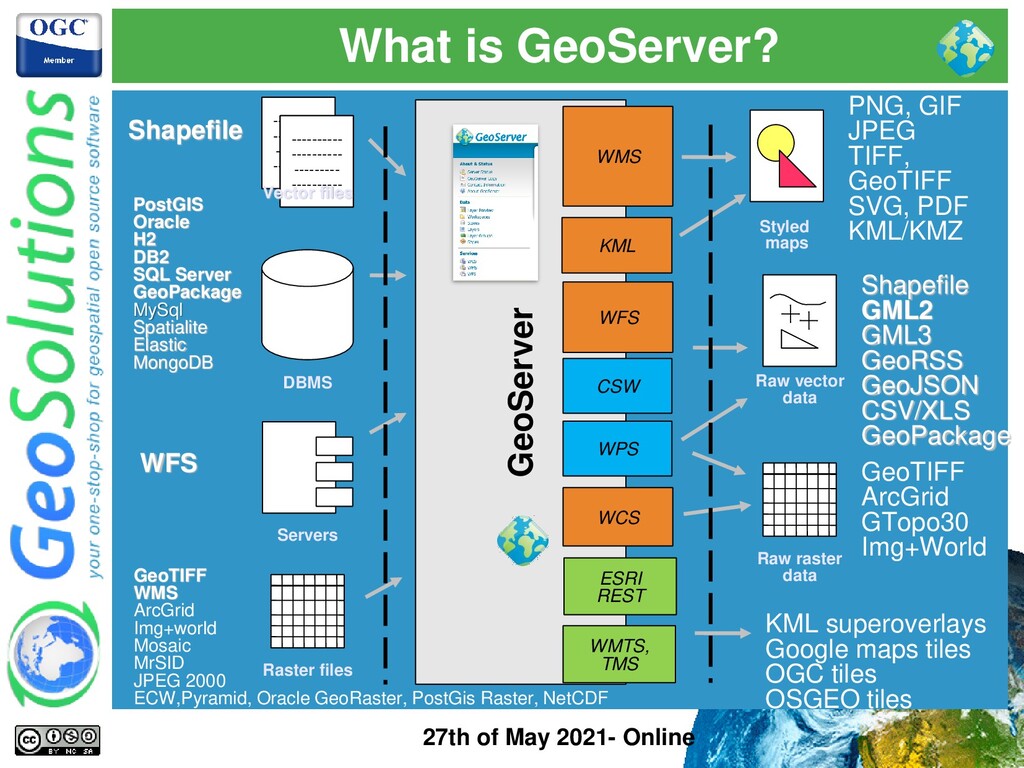
GeoServer Data Directory ⚫ Where GeoServer stores configuration in files ⚫ No automatic way to pick up config changes from files ⚫ Data can live in it, but we do not recommend it in enterprise set ups ⚫ Manually messing with the configuration files is dangerous ⚫ Memory-bound configuration ⚫ GeoServer loads data configuration in memory at startup (configuration not data itself) ⚫ GeoServer exposes GUI and REST endpoints to reload config when needed ⚫ Configuration reloading does not break OGC services ⚫ Configuration reloading blocks GUI and REST API
Global Configuration Locks ⚫ GeoServer internal configuration not thread-safe → can handle high volume parallel reads (e.g. GetMaps) but shall serialize writes (e.g. REST API POST calls) ⚫ Access to GUI and REST API on a single instance is serialized + GUI does not like load balancers ⚫ OGC Requests can go in parallel (actually MUST) ⚫ Make sure you move expensive operation outside configuration changes (large file uploads, importer tasks, etc..) ⚫ Default Java Opts & Config ⚫ Heap Memory must be tuned ⚫ JNDI & Connections Pool must be properly configured ⚫ Resource Limits must be properly configured ⚫ Control Flow must be installed and must be properly configured
a lot of memory ⚫ With properly configured data and styles the bottleneck is usually the CPU not the memory ⚫ Our reference dimensioning is 4CPU, 2 to 4 GB of HEAP ⚫ Do you have 1M+ layers? If no, 4GB is enough ⚫ Do you generate large PDF prints of PNG maps? If no, 4GB is enough ⚫ Do you have 8 or more CPUs? If no, 4B is enough ⚫ GeoServer is slow ⚫ Are you expecting GeoServer to serve a 1TB striped Bigtiff with no overviews? ⚫ Are you trying to visualize 10M points from a corporate Oracle table? ⚫ Did you optimize the standard configuration? ⚫ Are you running PROD with the prototype cross-platform binary?
slow ⚫ You have deployed a single GeoServer instance with 2 CPUs, no caching and you expect it to handle 200 req/sec? ⚫ Serving a large number of layers ⚫ Large usually mean 50k or more ⚫ Start up times / Reload times can grow (e.g. Oracle tables) ⚫ Heap Memory usage might grow ⚫ GetCapabilities documents become slow and hard to parse for clients (e.g. bloated 100MB+ files) ⚫ Partitioning with Virtual Services can help ⚫ Sharding on different instances can help
production webinar ⚫ Available here ⚫ Covers input data preparation ⚫ Covers Styling Optimization ⚫ Covers JVM Options tuning ⚫ Covers Configuration for robustness (resource limits and control flow) ⚫ Covers the basic info for tile caching ⚫ GeoServer in production presentations ⚫ Our Training material ⚫ Advanced GeoServer Configuration ⚫ Enterprise Set-up Recommendations ⚫ WE WON’T COVER THIS AGAIN → it is a precondition for what we talk about here
can be Containerized ⚫ Several implementations available ⚫ GeoSolutions one here ⚫ Official image coming soon ⚫ Advantages ⚫ We did some of the work for you ⚫ Flexible portable and repeatable ⚫ Orchestrators can help ⚫ Disadvantages ⚫ Require some prior knowledge ⚫ Debugging can be a headache
to store in the images ⚫ Requirements and Code ⚫ Configuration ⚫ Data? Not recommended ⚫ Monitor your containers ⚫ Centralized logging ⚫ Parametrize logs and audits file paths ⚫ Sharing of files and directories is not implicit ⚫ Logging to stdout ⚫ File permissions ⚫ Watch your user IDs and GeoServer user permissions ⚫ Users on the host system are not the same as the ones in the container
⚫ Environment specific things ⚫ Disk Quota ⚫ Controlflow ⚫ GeoFence ⚫ Security ⚫ DNS can help too ⚫ Parameterized Configuration ⚫ Database URLs ⚫ Usernames and Passwords ⚫ Backup & Restore Plugin ⚫ Port changes between Environments for you ⚫ No restart, possibility to Dry-run ⚫ Possibility to filter per layer or workspace ⚫ Experimental but getting more mature
Test and prototype without impacting the end users ⚫ Test code changes ⚫ Intranet vs Internet facing services ⚫ Allow multiple teams to work in parallel ⚫ How? ⚫ Automate migration between environments ⚫ Make you data directory portable ☺ ⚫ Use containers ⚫ Use backup and restore
+ High Availability ⚫ Scaling out – Horizontal Scalability ⚫ Having more similar nodes in parallel ⚫ Natural fit for elastic computing environments ⚫ Autoscaling ⚫ Scaling up – Vertical Scalability ⚫ More HW resources to a single machine ⚫ Natural fit for legacy static environments ⚫ GeoServer can cope with both ⚫ Scaling up to 64 cores has been proven in the past ⚫ Scaling up requires fine tuningfull to be CPU bound rather than I/O bound as we seek CPU utilization ⚫ Scaling out has been done in K8s, AWS, Azure, GCP, etc… ⚫ Multiple strategies for scaling out
– Vertical Scalability ⚫ Single powerful HW ⚫ Single fine tuned GeoServer will give you scalability but not availability ⚫ No autoscaling, configured for largest expected/handled load ⚫ HW is a hard bottleneck ⚫ Scaling out – Horizontal Scalability ⚫ Many smaller GeoServer instances working in parallel ⚫ Sharding and grouping by data/functionality is an option ⚫ Superior Scalability, Superior Availability ⚫ If autoscaling is allowed, no need to configure for worst case scenario ⚫ Mixed Approach ⚫ Multiple larger compute instances with multiple GeoServer instances → common in legacy virtualized environments
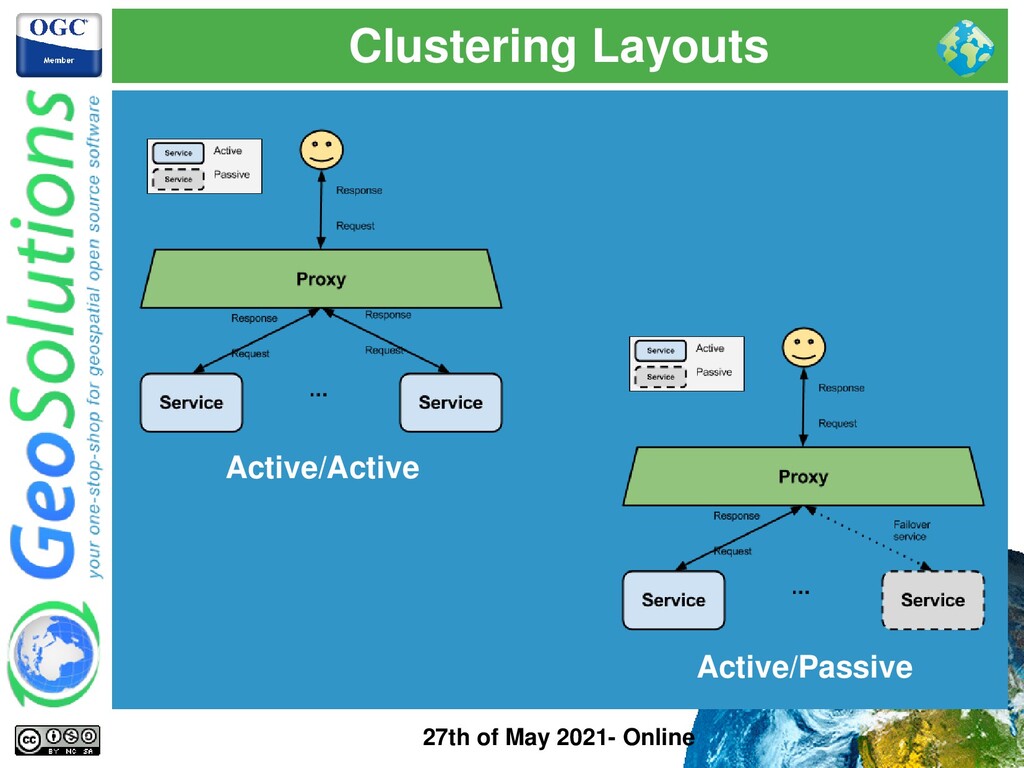
⚫ Passive Clustering → GS instances ignore each other ⚫ Active Clustering → GS instances talk to each other ⚫ Active Clustering ⚫ Config Changes propagate between instances ⚫ Requires specific extensions (JMS Clustering, Hazelcast, Stratus, GeoServer Cloud) ⚫ More moving parts, more maintenance work! ⚫ Use it wisely ⚫ Passive Clustering ⚫ No special plugins ⚫ Config Changes do not propagate → reload is required ⚫ No additional moving parts ⚫ Can cover 90% of use cases → our focus for this webinar
⚫ Backoffice instance is for administration ⚫ Changes via GUI or via REST Interface ⚫ Can do Active/Passive ⚫ Productions instances are for data serving ⚫ No config changes ⚫ Can scale horizontally! ⚫ Data is centralized and shared between instances ⚫ Configuration promotion requires reload ⚫ With some tricks it can cover most use cases
stores its config in files in the data directory ⚫ GS load its config in memory at startup ⚫ GS does not automatically pick up config changes from the data directory (needs explicit config reload via GUI or REST) ⚫ GeoServer GUI does not work well behind a randomizing load balancer ⚫ GS startup/reload times can be long with 10k+ layers ⚫ GS continuously write to log files ⚫ GS TileCache can work in clustering
GeoServer seems hard! ⚫ Before thinking about active clustering plugins make sure you need such layout! ⚫ 95% of cases Passive Clustering with Backoffice- Production is enough! ⚫ We will focus on Active Clustering in a separate webinar
is not cloud-native ⚫ It was born when cloud meant this → ⚫ We can’t depend on any cloud provider ⚫ GeoServer is cloud-ready ⚫ It is known to run in AWS, Azure, GCP, OpenShift, IBM Cloud, etc.. ⚫ It is known to run in K8s, Rancher ⚫ It can autoscale (CPU is the resource to look at) ⚫ It can use Object Storage (Tile Cache, COG, etc..) ⚫ Prefers compute intensive instances ⚫ Likes Containers ⚫ Likes Automation! (Azure Pipelines, Jenkins, etc..)
We assume basic optimizations are done ⚫ Input data is optimized ⚫ Styles are optimized ⚫ Resource Limits are in place (for robustness) ⚫ Control Flow is properly tuned (for robustness and fairness) ⚫ Here our webinar on performance optimizations ⚫ Clustering Questionnaire ⚫ How frequently does your data change? Are changes additive or not? ⚫ How frequently does your configuration change? New/Updated layers, new/updated styles, etc… ⚫ How quickly do you need to deliver changes to PROD? ⚫ Do you need/want a formal QA process on data and configuration?
data ⚫ Data is added or removed to GS ⚫ Data is rarely updated ⚫ E.g. data from EO, MetOc, Drones, IOT Sensors ⚫ Refrain from creating millions of layers, it won’t scale → organize your data properly ⚫ Use ImageMosaic for rasters if possible ⚫ Use TIME and other dimensions ⚫ Use CQL_Filter ⚫ Keep # of layers low if not constant ⚫ Manager data via REST API → no configuration reload ⚫ Use single tables for vector if possible ⚫ Use TIME and other dimensions ⚫ Use CQL_Filter or Parametric SQL View ⚫ Keep # of layers low if not constant
single tables for vector if possible ⚫ Ingest data directly in DBMS ⚫ Use indexing, partitions and sharding ⚫ Less layers, less configuration changes, easier clustering ⚫ Faster startup/reload time ⚫ Infrequent need for reload
⚫ Do I need to reflect changes in PROD immediately? ⚫ This is not true in most cases ⚫ DAAS platforms have strict QA process for this ⚫ DAAS platforms use multiple environments to test data & config changes (new layers, new styles, etc..) ⚫ DAAS platforms tend to group data and config changes in small isolated, testable batches → reloading GS config does not add burden during a release ⚫ We can treat data and GS configuration as code! GitHub, Docker Images and so on ⚫ Bonus point, tile caching, HTTP caching is well suited
GS binary in prod? ⚫ Use the WAR, use an Application Server at your choice ⚫ Not enough HW resources ⚫ Your deployment has less cores than your laptop? ⚫ Data not optimized ⚫ Serving a 1TB GeoTiff with no overviews? ⚫ Styling not optimized ⚫ Are you sure you need this much data at all zoom levels? ⚫ GeoServer not optimized ⚫ Did you tweak the Java opts? ⚫ Wrong Expectations ⚫ Speedy rendering 10M points with 1 CORE? ⚫ Serving maps nationwide with a single instance on a VPS?
layers ⚫ Use ImageMosaic for TIME Series data ⚫ Use Parametric SQL Views ⚫ Shard if no other ways around ⚫ No Test / QA Environment ⚫ No possibility to experiment, everything happens in PROD ⚫ No monitoring, metering or logging ⚫ Do you like driving blindfolded? ⚫ No Caching ⚫ TileCaching and HTTP Caching are crucial when possible ⚫ Choosing Memory Optimize Instances ⚫ The first bottleneck you hit with a properly configured GeoServer is the CPU !!!
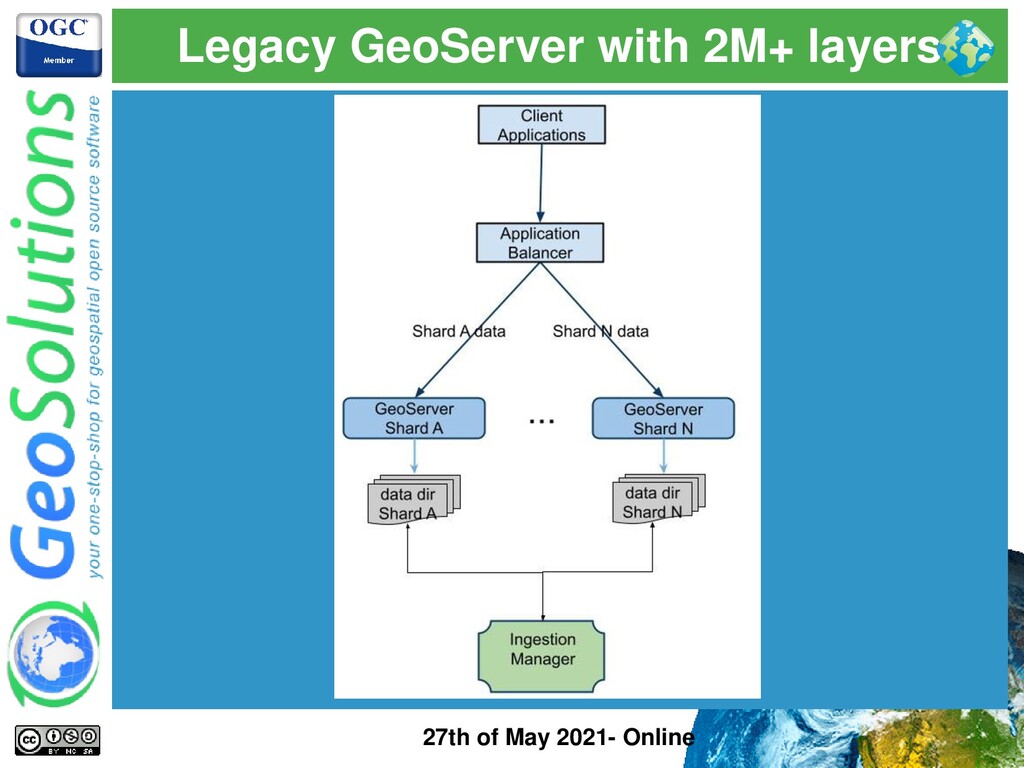
⚫ Legacy instance ⚫ Bloated number of layers → large usually means 50k or more ⚫ Start up times / Reload times can grow (e.g. Oracle tables) ⚫ Heap Memory usage might grow ⚫ GetCapabilities documents become slow and hard to parse for clients (e.g. bloated 100MB+ files ⚫ Cannot easily restructure GeoServer config to reduce # of layers ⚫ Analysis ⚫ We can mitigate not completely solve ⚫ Partitioning with Virtual Services ⚫ Sharding layers on different GS instances ⚫ Mosaicking + Single Table approach should be the ideal approach
⚫ Mitigation Approach ⚫ Partitioning layers in virtual services to improve GetCapabilities size and response time (if clients allow it) ⚫ Sharding with multiple separated instances + caching + clustering → introduce an Application Load Balancer ⚫ Increased HEAP Size to account for large in memory config
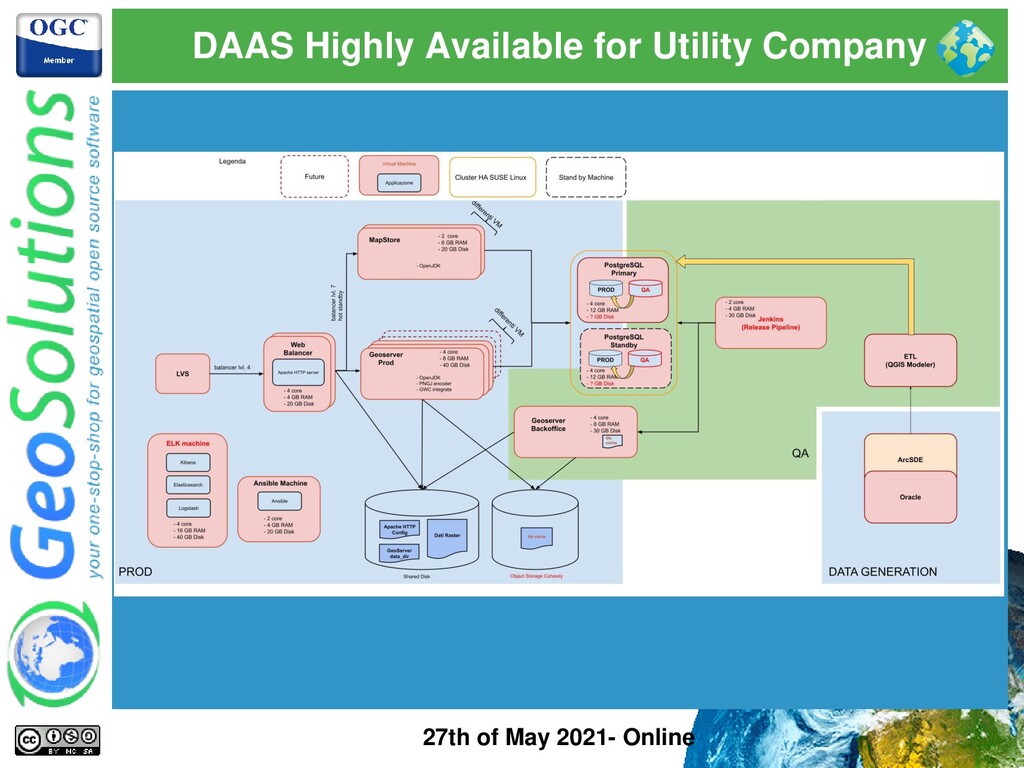
Online ⚫ Private Data Center ⚫ No elasticity, VMWare based ⚫ Highly Available, no SPF ⚫ Data production with monthly data and configuration release ⚫ QA separate environment ⚫ Automation with Jenkins for data & configuration promotion ⚫ GitHub to version configuration (configuration as code) ⚫ NAGIOS Monitoring ⚫ Elastic for logging & metering ⚫ (Hybrid GIS Infrastructure) ⚫ (Data production with ArcGIS on ArcSDE) ⚫ (ETL with QGIS modeler to perform import in QA)
⚫ Possible Scenarios ⚫ Publishing of EO time series ⚫ Publishing of Drone data time series ⚫ Publishing of Sensor Time Series ⚫ Publishing of MetOc or Atmospheric Model time series ⚫ Publishing of positions for moving objects ⚫ Publishing of related products ⚫ Key points ⚫ Recognizable flows of harmonized data ⚫ Data is added along one or more dimensions (TIME, ELEVATION, FlightUUID, etc..) ⚫ Data is (sometimes) removed as it falls out of a window of validity ⚫ Data is rarely modified, at most is removed
⚫ ImageMosaic to the rescue ⚫ Use ImageMosaic with one or more dimensions ⚫ Put index in the DBMS ⚫ Put data in a shared storage ⚫ Data can be published continuously → no configuration changes ⚫ Serve petabyte of data with a few time series layers ⚫ Start up / loading time very quick ⚫ Scaling out and autoscaling is possible → share data and index between all instances ⚫ Eventually reproject data to a common CRS per mosaic
⚫ Parametric SQL View to the rescue ⚫ Use single table approach with pivot attributes (time, elevation, run-time, flightUUID, etc..) ⚫ Use DBMS magic to scale the performance of the table (partitioning, sharding, clustering) ⚫ Ingest data continuously in the DBMS → no configuration changes ⚫ Serve terabytes of data with a few (Parameteric SQL View) ⚫ Start up / loading time very quick ⚫ Scaling out and autoscaling is possible → share same DBMS between all instances ⚫ Eventually reproject data to a common CRS per mosaic
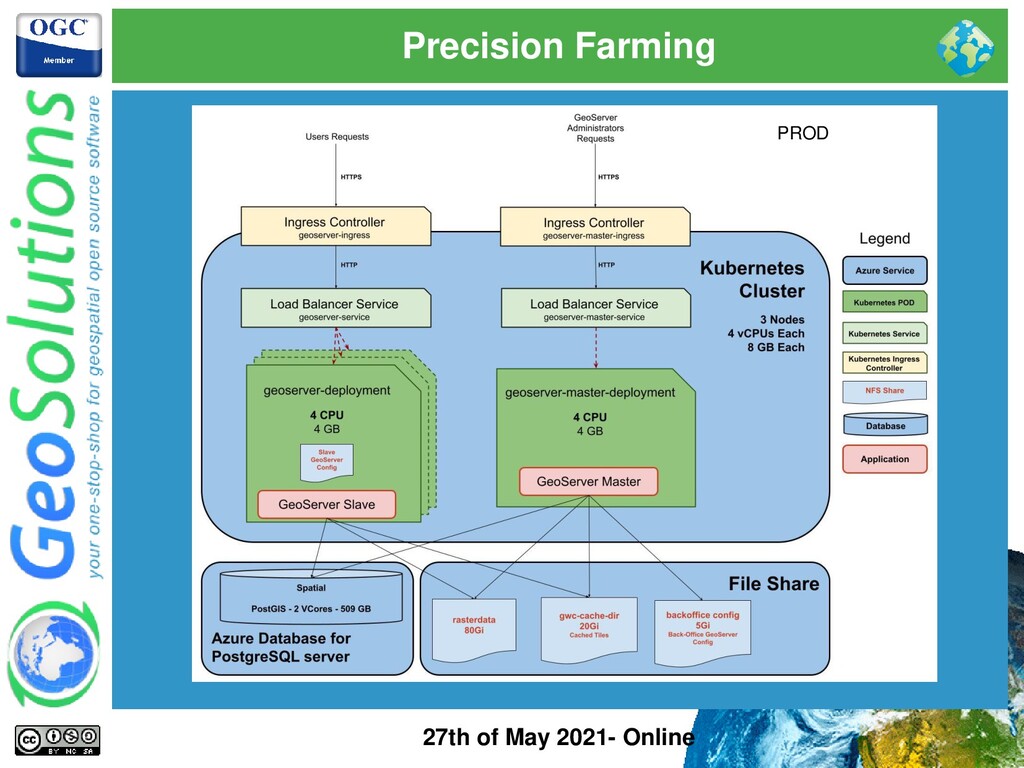
ImageMosaic and Parametric Views ⚫ Passive Cluster ⚫ Data coming from tractors is ingested continuously with unfrequent data or config updates (position, speed, crop, yield, …) ⚫ Stored on shared storage (Azure Databases and File Share) ⚫ GeoServer production instances configuration is immutable ⚫ Kubernetes cluster and deployments can be easily scaled ⚫ Infrastructure monitoring options available like Prometheus
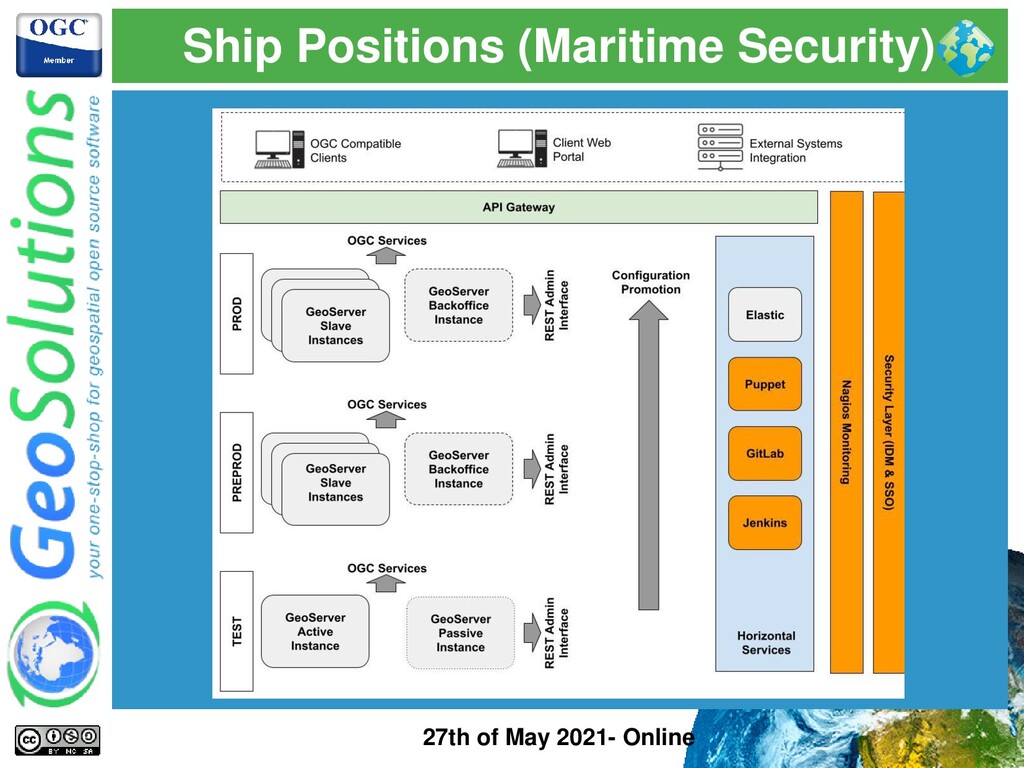
On-Premises infrstructure based on virtual machines ⚫ Machines and Software deployments are managed by configuration management system (Puppet) and Pipelines (Jenkins) ⚫ Static cluster (not scaled dynamically) ⚫ Passive Cluster with dedicated Backoffice instance ⚫ Unfrequent configuration changes ⚫ Datadir versioned in a GitLab repository ⚫ Ship positions updated continuously ⚫ No tile caching
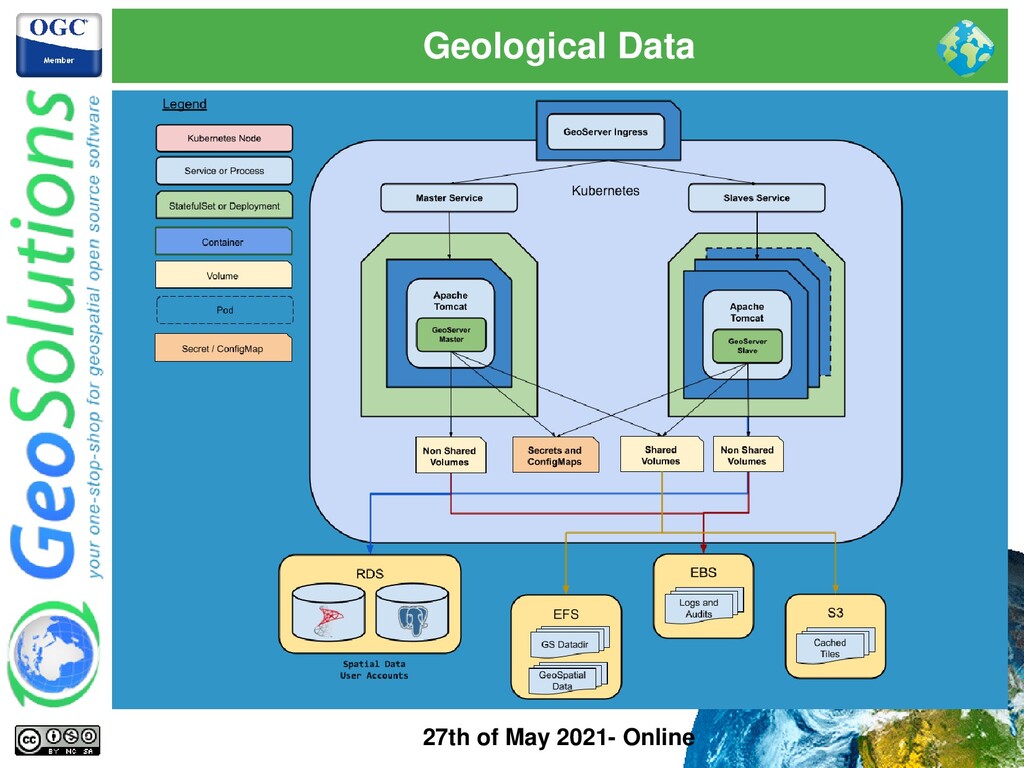
Analysis of Geological data ⚫ Cloud deployment on AWS using managed Kubernetes cluster ⚫ ImageMosaic with Time dim and SQL Views for geological eras ⚫ Passive Cluster ⚫ Monthly configuration and data updates ⚫ Cached tiles stored on object storage
fit for caching ⚫ Data is not changing over time ⚫ Cached tiles can often be removed after some time (only “recent” data is interesting?) ⚫ Configuration changes are unfrequent ⚫ Data growth need to be handled ⚫ PostgreSQL read-only replica implemented with Zalando operator to handle ingestion and serving of data at the same time
& Resources Usage ⚫ Most important resource to monitor is CPU ⚫ Memory is also important ⚫ Don’t be afraid to keep CPUs at 100% under load ⚫ Control Flow shall be used to protect us ⚫ Control Flow shall be tuned properly to achieve max resource usage ⚫ Passive ⚫ Most important resource to monitor is CPU ⚫ Memory is also important ⚫ Autoscaling & Resources Usage ⚫ Most important resource to monitor is CPU ⚫ Memory is also important
Do your homework ⚫ Study the data flow ⚫ Study user interactions (both admins and end users) ⚫ Study deployment platform ⚫ Investigate GeoServer point of strengths and shortcomings ⚫ Do some tests and measure performance ⚫ Optimize data and GeoServer config ⚫ Performance basic speed enhancements before you look for scalability ⚫ Leverage the KISS principle for clustering ⚫ Try to use the simplest possible deployment layout ⚫ Don’t rush to active clustering ⚫ Monitor and meter everything ⚫ Data should tell you what to improve or refactor ⚫ Random changes can be dangerous
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![That’s all folks! Questions? [email protected] 27th of May 2021- Online](https://files.speakerdeck.com/presentations/b7ba1e2697814abfae204abe26ecb89a/slide_65.jpg){kind=link}