Most web applications need to offer search functionality. Open source tools like Solr and Elasticsearch are a powerful option for building custom search engines… but it turns out they can be used for way more than just search.
By treating your search engine as a denormalization layer, you can use it to answer queries that would be too expensive to answer using your core relational database. Questions like “What are the top twenty tags used by my users from Spain?” or “What are the most common times of day for events to start?” or “Which articles contain addresses within 500 miles of Toronto?”.
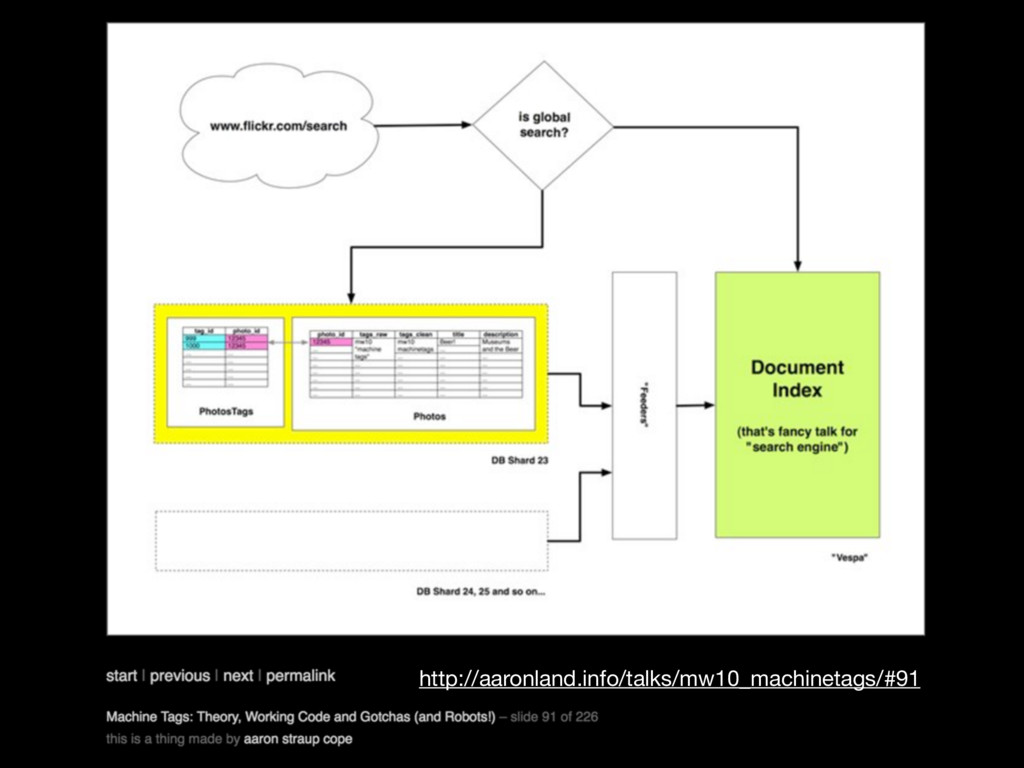
With the denormalized query engine design pattern, modifications to relational data are published to a denormalized schema in Elasticsearch or Solr. Data queries can then be answered using either the relational database or the search engine, depending on the nature of the specific query. The search engine returns database IDs, which are inflated from the database before being displayed to a user - ensuring that users never see stale data even if the search engine is not 100% up to date with the latest changes. This opens up all kinds of new capabilities for slicing, dicing and exploring data.
In this talk, I’ll be illustrating this pattern by focusing on Elasticsearch - showing how it can be used with Django to bring new capabilities to your application. I’ll discuss the challenge of keeping data synchronized between a relational database and a search engine, and show examples of features that become much easier to build once you have this denormalization layer in place.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}