J. Franklin Samuel Madden Alan Fekete† University of California, Berkeley MIT †University of Sydney {kraska, gpang, franklin}@cs.berkeley.edu [email protected][email protected] Abstract Replicating data across multiple data centers allows using data closer to the client, reducing latency for applications, and increases the availability in the event of a data cen- ter failure. MDCC (Multi-Data Center Consistency) is an optimistic commit protocol for geo-replicated transactions, that does not require a master or static partitioning, and is strongly consistent at a cost similar to eventually consis- tent protocols. MDCC takes advantage of Generalized Paxos for transaction processing and exploits commutative updates with value constraints in a quorum-based system. Our exper- iments show that MDCC outperforms existing synchronous taken between data centers, and desirable to avoid waiting for the slowest data center to respond. For database-backed applications, it is a very valuable feature when the system supports transactions: multiple op- erations (such as individual reads and writes) grouped to- gether, with the system ensuring at least atomicity so that all changes made within the transaction are eventually persisted or none. The traditional mechanism for transactions that are distributed across databases is two-phase commit (2PC), but this has serious drawbacks in a geo-replicated system. 2PC depends on a reliable coordinator to determine the outcome of a transaction, so it will block for the duration of a coordi- • Read committed を保証する楽観的分散トランザクションコミットプロトコル MDCC [1] を 提案.行ごとに Generalized Paxos を実行し,トランザクションの可換性を活用しながら高 速クォーラムでのコミットを試みることで,通常 1 RTT のコミット遅延を実現. • 2PC や Megastore と比較してコミット遅延を約 50 % 削減,ログレプリケーションのボト ルネックを解消してスケーラビリティを向上. 1
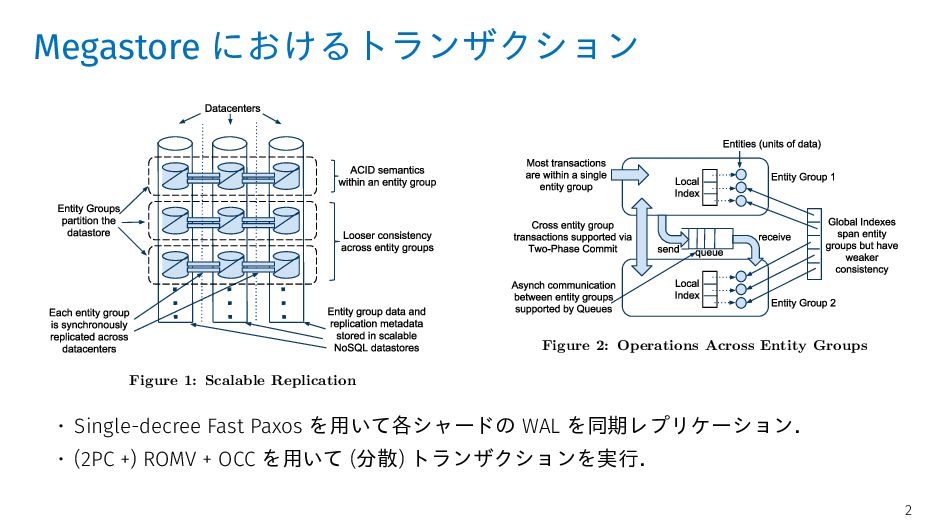
no single permanent owner. We create a second class of entity groups to hold the posts and metadata for each blog. A third class keys off the unique name claimed by each blog. The appli- cation relies on asynchronous messaging when a sin- gle user operation affects both blogs and profiles. For a lower-traffic operation like creating a new blog and claiming its unique name, two-phase commit is more convenient and performs adequately. Maps Geographic data has no natural granularity of any consistent or convenient size. A mapping application can create entity groups by dividing the globe into non- overlapping patches. For mutations that span patches, the application uses two-phase commit to make them atomic. Patches must be large enough that two-phase transactions are uncommon, but small enough that each patch requires only a small write throughput. Unlike the previous examples, the number of entity groups does not grow with increased usage, so enough patches must be created initially for sufficient aggre- gate throughput at later scale. Nearly all applications built on Megastore have found nat- ural ways to draw entity group boundaries. Figure 1: Scalable Replication Figure 2: Operations Across Entity Groups replicated via Paxos). Operations across entity groups could rely on expensive two-phase commits, but typically leverage Megastore’s efficient asynchronous messaging. A transac- tion in a sending entity group places one or more messages in a queue; transactions in receiving entity groups atomically consume those messages and apply ensuing mutations. Note that we use asynchronous messaging between logi- cally distant entity groups, not physically distant replicas. All network traffic between datacenters is from replicated M ur 2 st ar ac ti se w us gr m of fo • Single-decree Fast Paxos を用いて各シャードの WAL を同期レプリケーション. • (2PC +) ROMV + OCC を用いて (分散) トランザクションを実行. 2
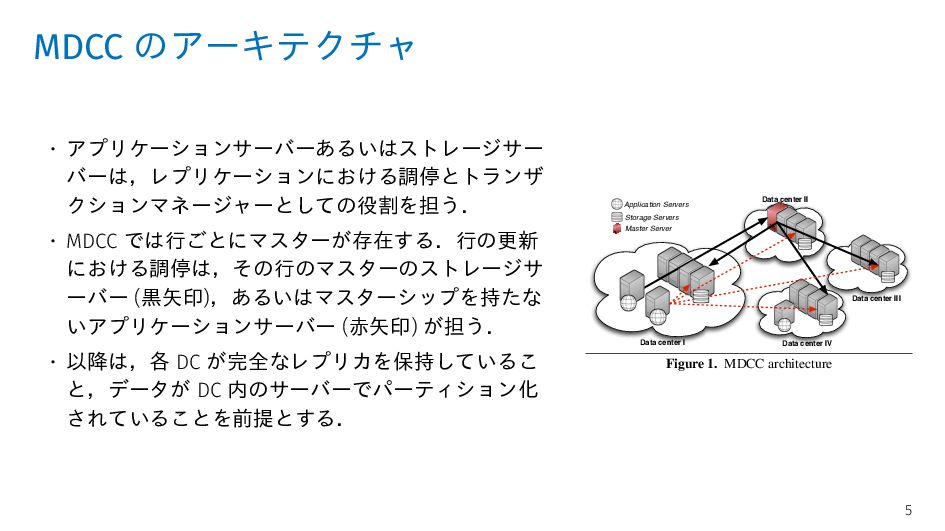
ーバー (黒矢印),あるいはマスターシップを持たな いアプリケーションサーバー (赤矢印) が担う. • 以降は,各 DC が完全なレプリカを保持しているこ と,データが DC 内のサーバーでパーティション化 されていることを前提とする. Data center IV Data center III Data center I Data center II Application Servers Storage Servers Master Server Figure 1. MDCC architecture more horizontal partitions. Although not required, we as- sume for the remainder of the paper that every data center contains a full replica of the data, and the data within a sin- gle data center is partitioned across machines. The DB library provides a programming model for trans- actions and is mainly responsible for coordinating the repli- cation and consistency of the data using MDCC’s commit protocol. The DB library also acts as a transaction manager 5
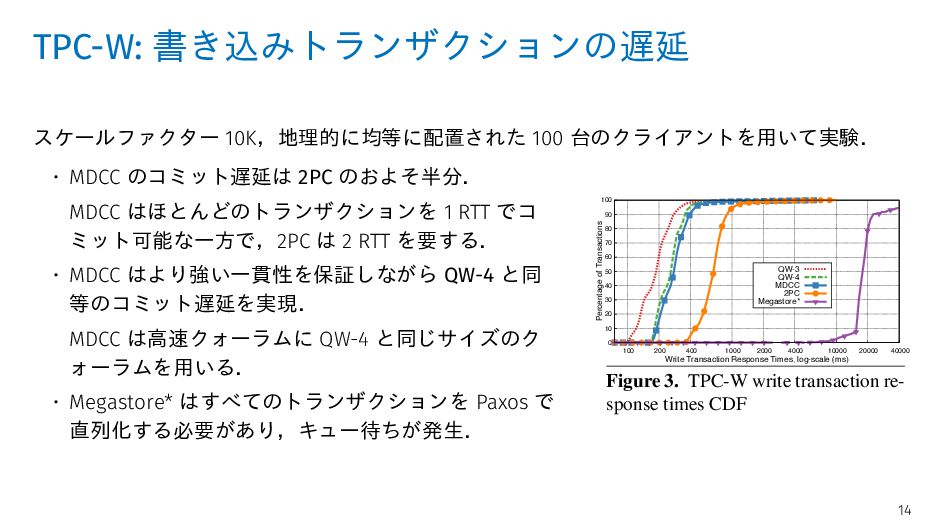
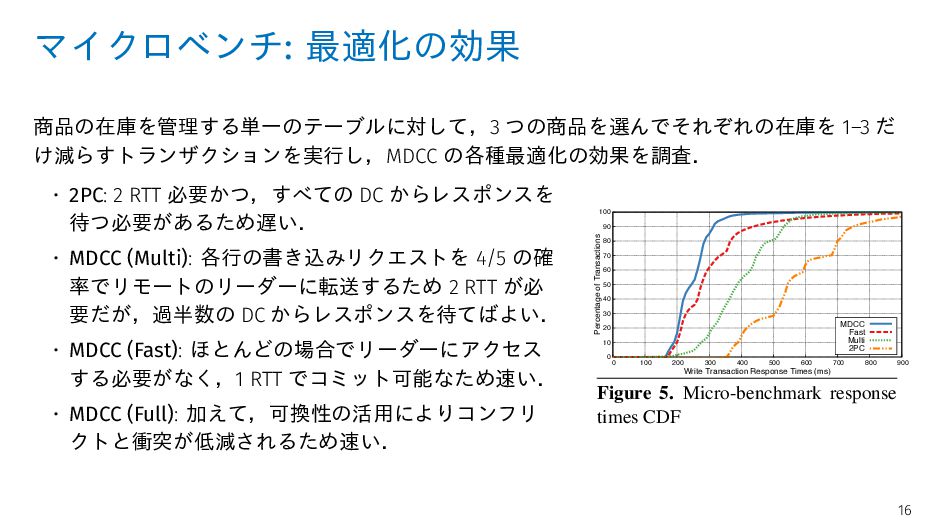
2 RTT 必要かつ,すべての DC からレスポンスを 待つ必要があるため遅い. • MDCC (Multi): 各行の書き込みリクエストを 4/5 の確 率でリモートのリーダーに転送するため 2 RTT が必 要だが,過半数の DC からレスポンスを待てばよい. • MDCC (Fast): ほとんどの場合でリーダーにアクセス する必要がなく,1 RTT でコミット可能なため速い. • MDCC (Full): 加えて,可換性の活用によりコンフリ クトと衝突が低減されるため速い. 200 400 1000 2000 4000 10000 20000 40000 Write Transaction Response Times, log-scale (ms) QW-3 QW-4 MDCC 2PC Megastore* 0 200 400 600 800 1000 1200 1400 1600 50 100 200 Transactions per Second # Concurrent Clients QW-3 QW-4 MDCC 2PC Megastore* 0 10 20 30 40 50 60 70 80 90 100 0 100 200 300 400 500 600 700 800 900 Percentage of Transactions Write Transaction Response Times (ms) MDCC Fast Multi 2PC e 3. TPC-W write transaction re- e times CDF Figure 4. TPC-W transactions per sec- ond scalability Figure 5. Micro-benchmark response times CDF ally Megastore* with slowest times. The median re- times are: 188ms for QW-3, 260ms for QW-4, 278ms CC, 668ms for 2PC, and 17,810ms for Megastore*. e MDCC uses fast ballots whenever possible, MDCC (200 clients, 20,000 items). For each configuration, we fixed the amount of data per storage node to a TPC-W scale-factor of 2,500 items and scaled the number of nodes accordingly (keeping the ratio of clients to storage nodes constant). For 16
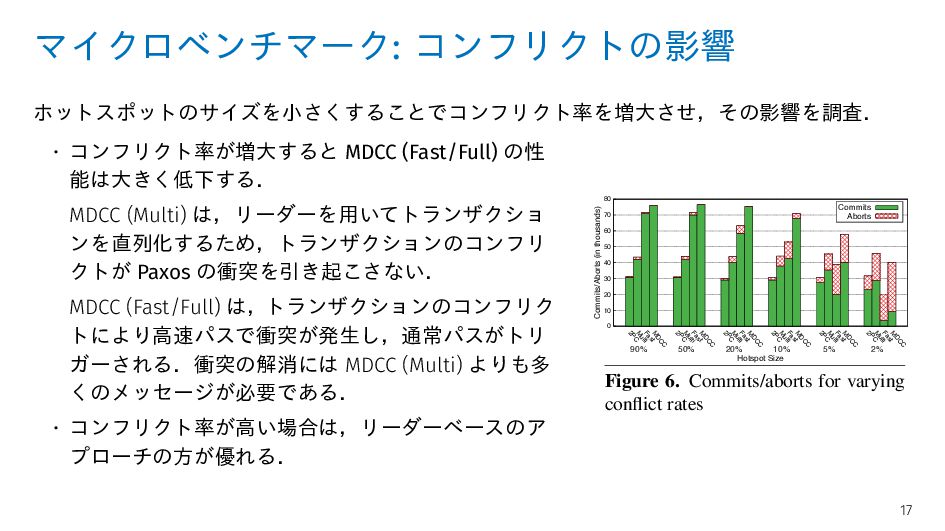
(Multi) は,リーダーを用いてトランザクショ ンを直列化するため,トランザクションのコンフリ クトが Paxos の衝突を引き起こさない. MDCC (Fast/Full) は,トランザクションのコンフリク トにより高速パスで衝突が発生し,通常パスがトリ ガーされる.衝突の解消には MDCC (Multi) よりも多 くのメッセージが必要である. • コンフリクト率が高い場合は,リーダーベースのア プローチの方が優れる. 0 10 20 30 40 50 60 70 80 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC Commits/Aborts (in thousands) Hotspot Size Commits Aborts 2% 5% 10% 20% 50% 90% 0 200 400 600 800 1000 Response Times (ms) Figure 6. Commits/aborts for varying conflict rates Fi ma Phase 1). The experiment ran for 3 minutes af warm-up. Figure 5 shows the cumulative dist tions (CDF) of response times of the successfu The median response times are: 245ms 17
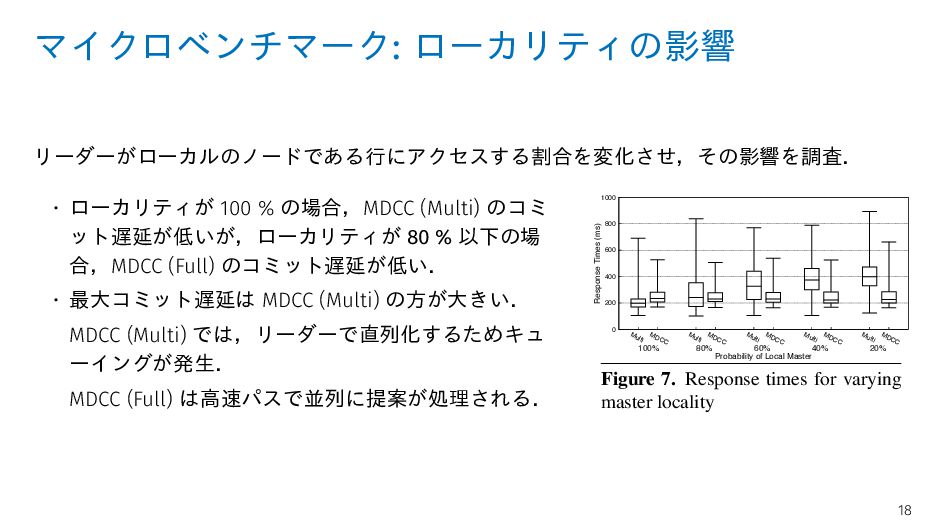
ット遅延が低いが,ローカリティが 80 % 以下の場 合,MDCC (Full) のコミット遅延が低い. • 最大コミット遅延は MDCC (Multi) の方が大きい. MDCC (Multi) では,リーダーで直列化するためキュ ーイングが発生. MDCC (Full) は高速パスで並列に提案が処理される. 0 10 20 30 40 50 60 70 80 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC 2PC M ulti Fast M DCC Commits/Aborts (in thousands) Hotspot Size Commits Aborts 2% 5% 10% 20% 50% 90% 0 200 400 600 800 1000 Multi MDCC Multi MDCC Multi MDCC Multi MDCC Multi MDCC Response Times (ms) Probability of Local Master 100% 80% 60% 40% 20% 0 100 200 300 400 500 Response Time (ms) Figure 6. Commits/aborts for varying conflict rates Figure 7. Response times for varying master locality Fig tim Phase 1). The experiment ran for 3 minutes after a 1 minute warm-up. Figure 5 shows the cumulative distribution func- tions (CDF) of response times of the successful transactions. The median response times are: 245ms for MDCC, independent of transac Fast Paxos, collisions a collision/conflict occ not agree on the same 18
consistency. In Proc. EuroSys ’13, page 113–126, 2013. [2] Jason Baker et al. Megastore: Providing scalable, highly available storage for interactive services. In Proc. CIDR ’11, pages 223–234, 2011. [3] James C. Corbett et al. Spanner: Google’s globally-distributed database. In Proc. OSDI’12, page 251–264, 2012.
Concurrency control and availability in multi-datacenter datastores. Proc. VLDB Endow., 5(11):1459–1470, 2012. [5] Leslie Lamport. Fast Paxos. Distrib. Comput., 19(2):79–103, 2006. [6] Leslie Lamport. Generalized consensus and Paxos. Technical Report MSR-TR-2005-33, Microsoft Research, 2004.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Megastore とその系譜の問題点 • Megastore [2] は,コミット時にシャードごとに Paxos を実行してログエントリに対する合 意を形成し,トランザクションの全順序を決定する.すなわち,各シャードで一度に 1](https://files.speakerdeck.com/presentations/dc6bbf427a754192805be8e23d98f7d6/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![高速クォーラムと可換性を用いた最適化 • Fast Paxos [5] に基づいて,高速クォーラムを用いた 1 RTT でのコミットを試みる. •](https://files.speakerdeck.com/presentations/dc6bbf427a754192805be8e23d98f7d6/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 (1) [1] Tim Kraska et al. MDCC: Multi-data center](https://files.speakerdeck.com/presentations/dc6bbf427a754192805be8e23d98f7d6/slide_25.jpg){kind=link}
![参考文献 (2) [4] Stacy Patterson et al. Serializability, not serial:](https://files.speakerdeck.com/presentations/dc6bbf427a754192805be8e23d98f7d6/slide_26.jpg){kind=link}
![参考文献 (3) [7] Fay Chang et al. Bigtable: A distributed](https://files.speakerdeck.com/presentations/dc6bbf427a754192805be8e23d98f7d6/slide_27.jpg){kind=link}