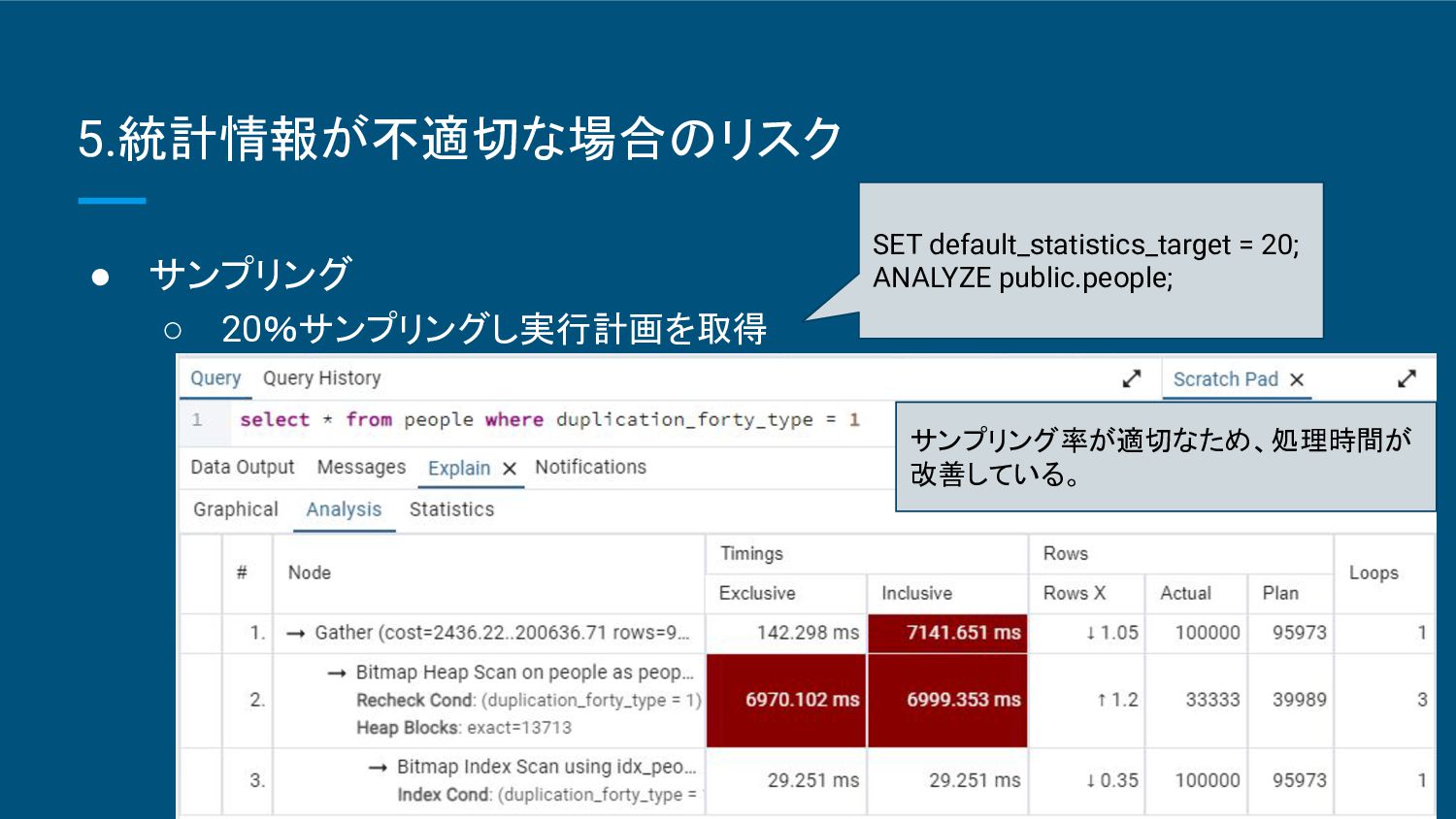
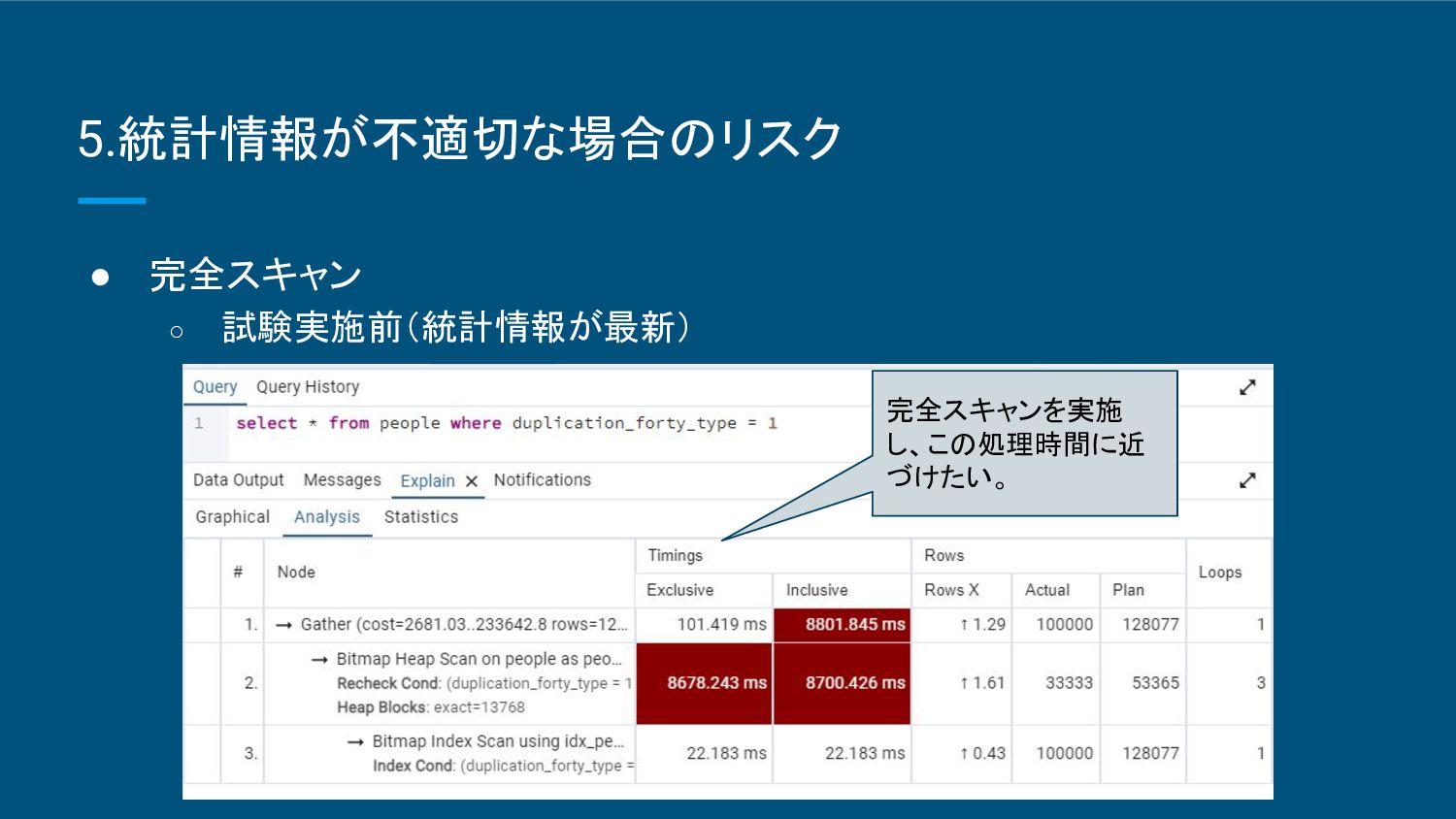
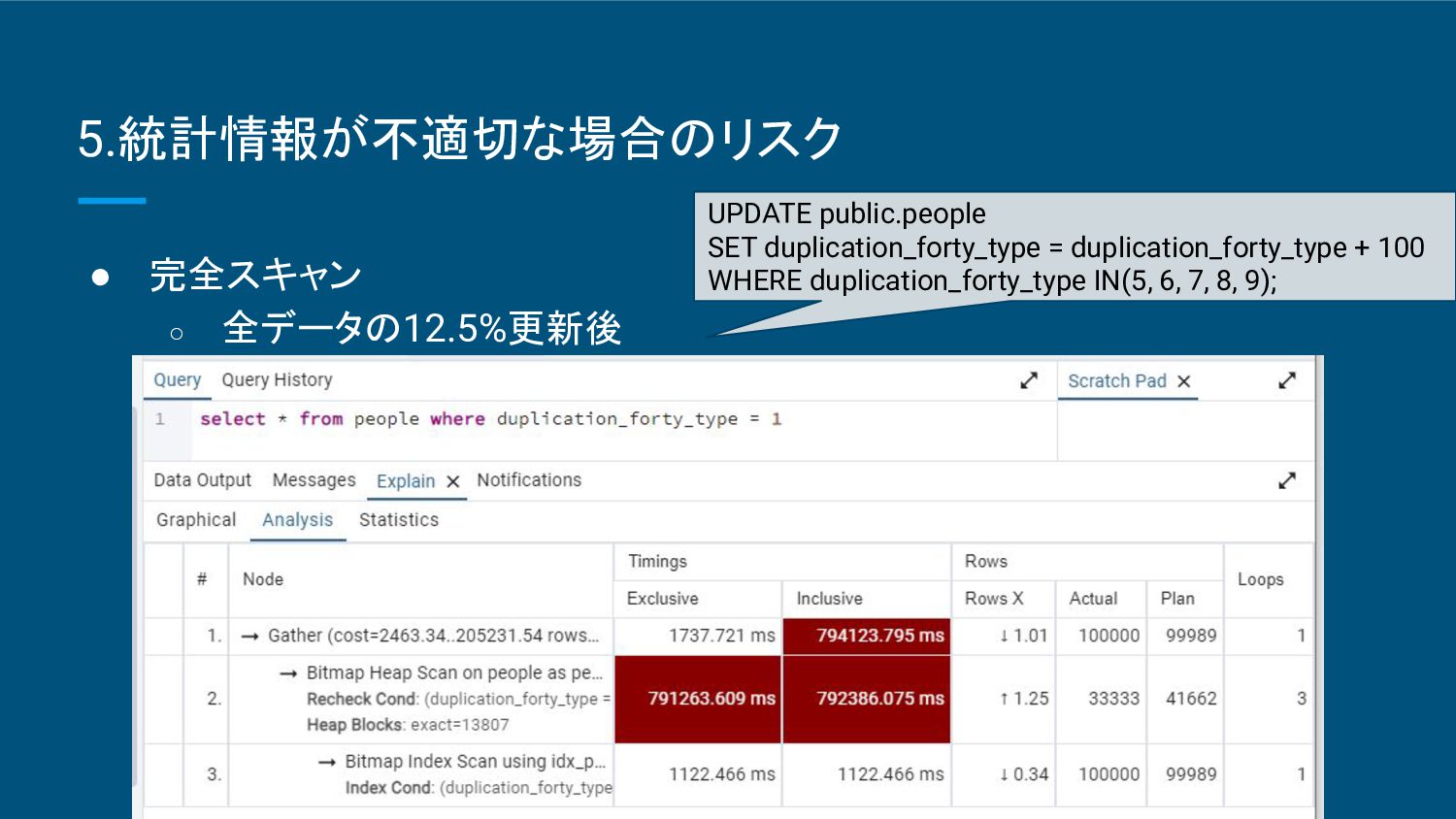
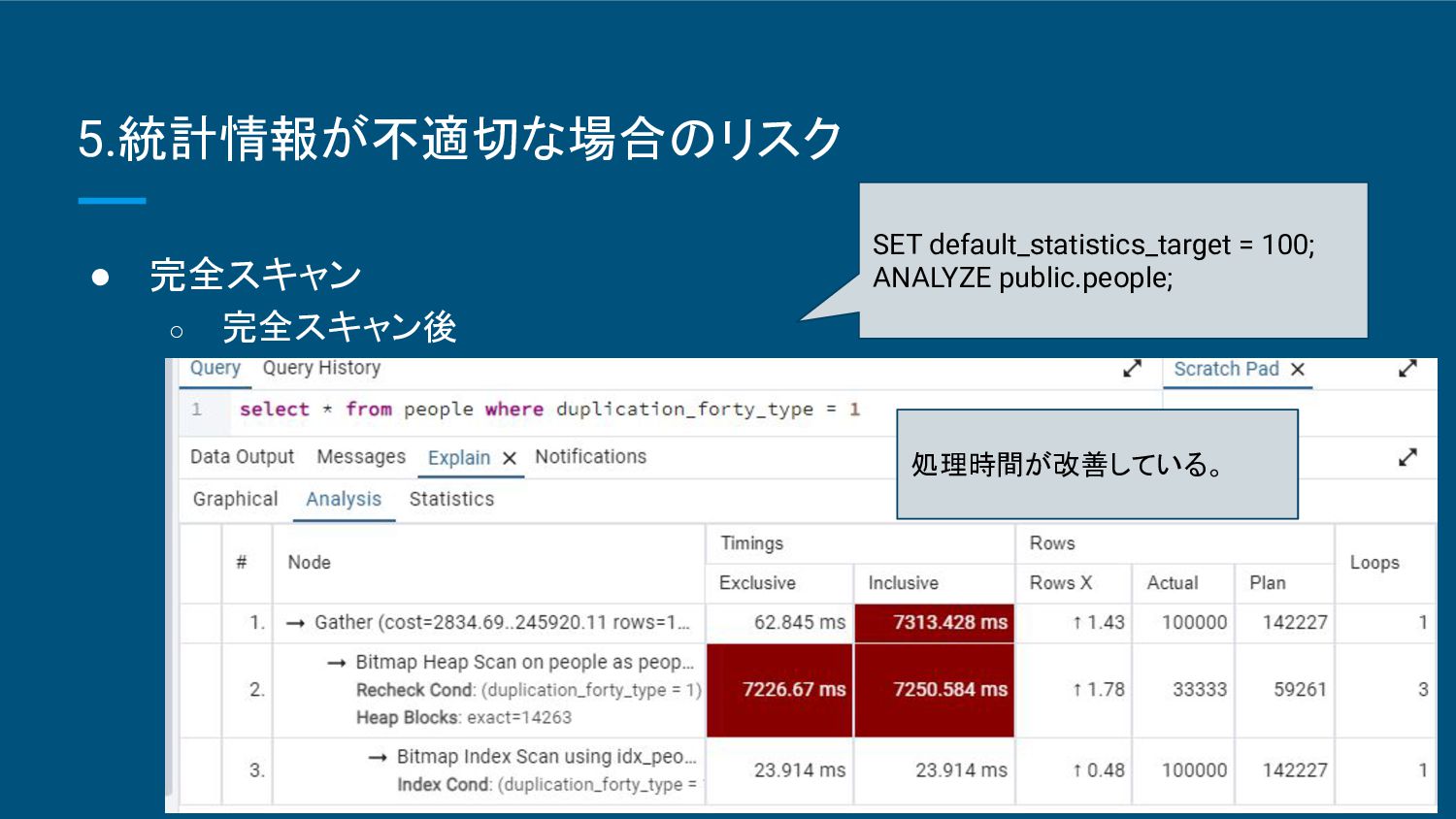
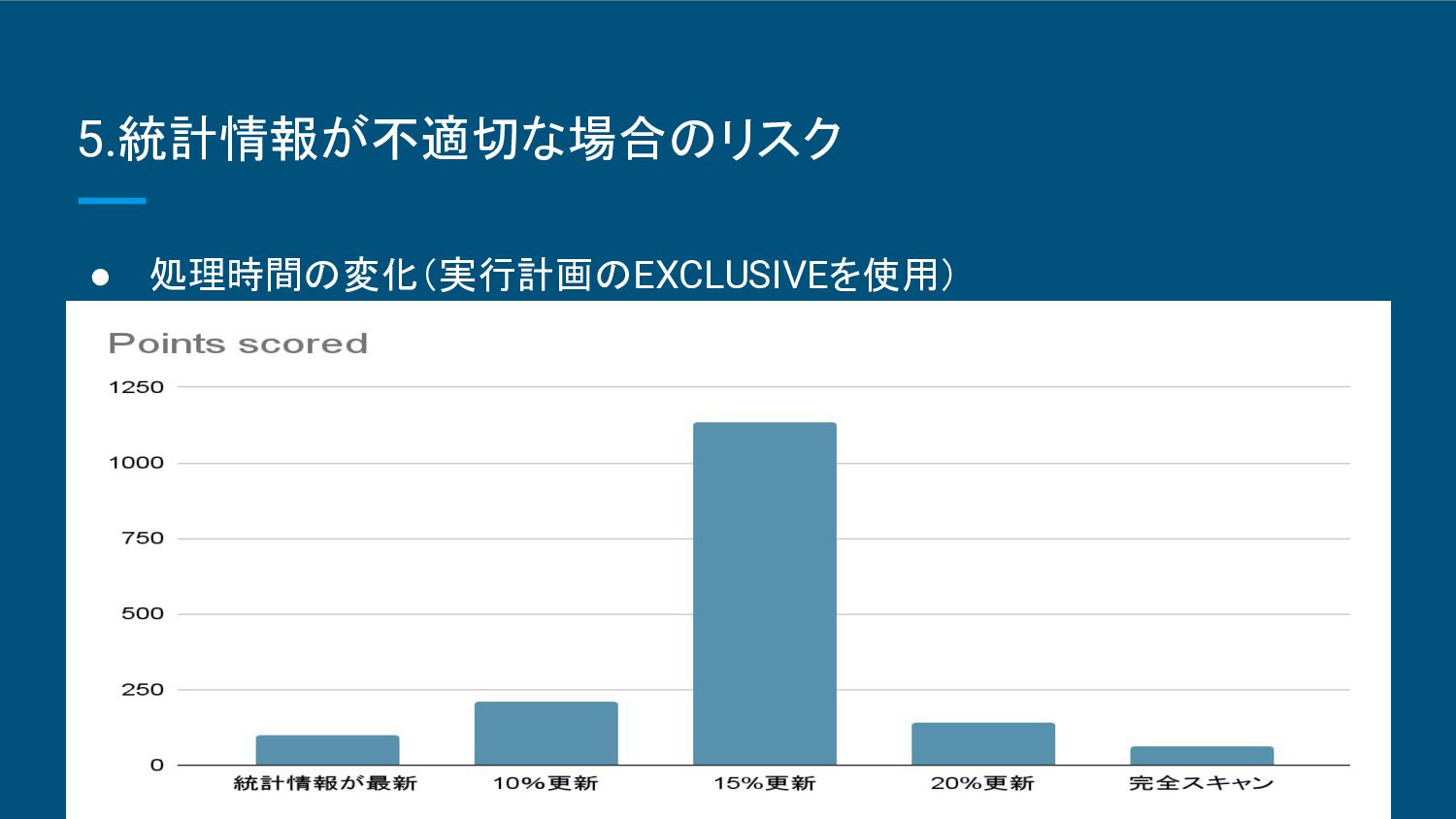
精度が完全スキャンに比べて低くなる ことがある。 ▪ ヒストグラム(重複度や最大最小値等)に依存するため継続した検証が必要 。 ◦ 適した状況 ▪ 大規模なデータベースや、リアルタイム性が求められるシステム。 ▪ 頻繁に統計情報を更新 する必要がある場合に有効。 • 完全スキャン ◦ 特徴 ▪ データ全体をスキャンして統計情報を収集するため非常に正確。 ▪ 処理負荷が大きく、大規模なデータベースでは時間がかかる。 ◦ 適した状況 ▪ 中小規模のデータベースや、クエリのパフォーマンスが非常に重要なシステム。 ▪ 正確な統計情報が必要 な場合に適している。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
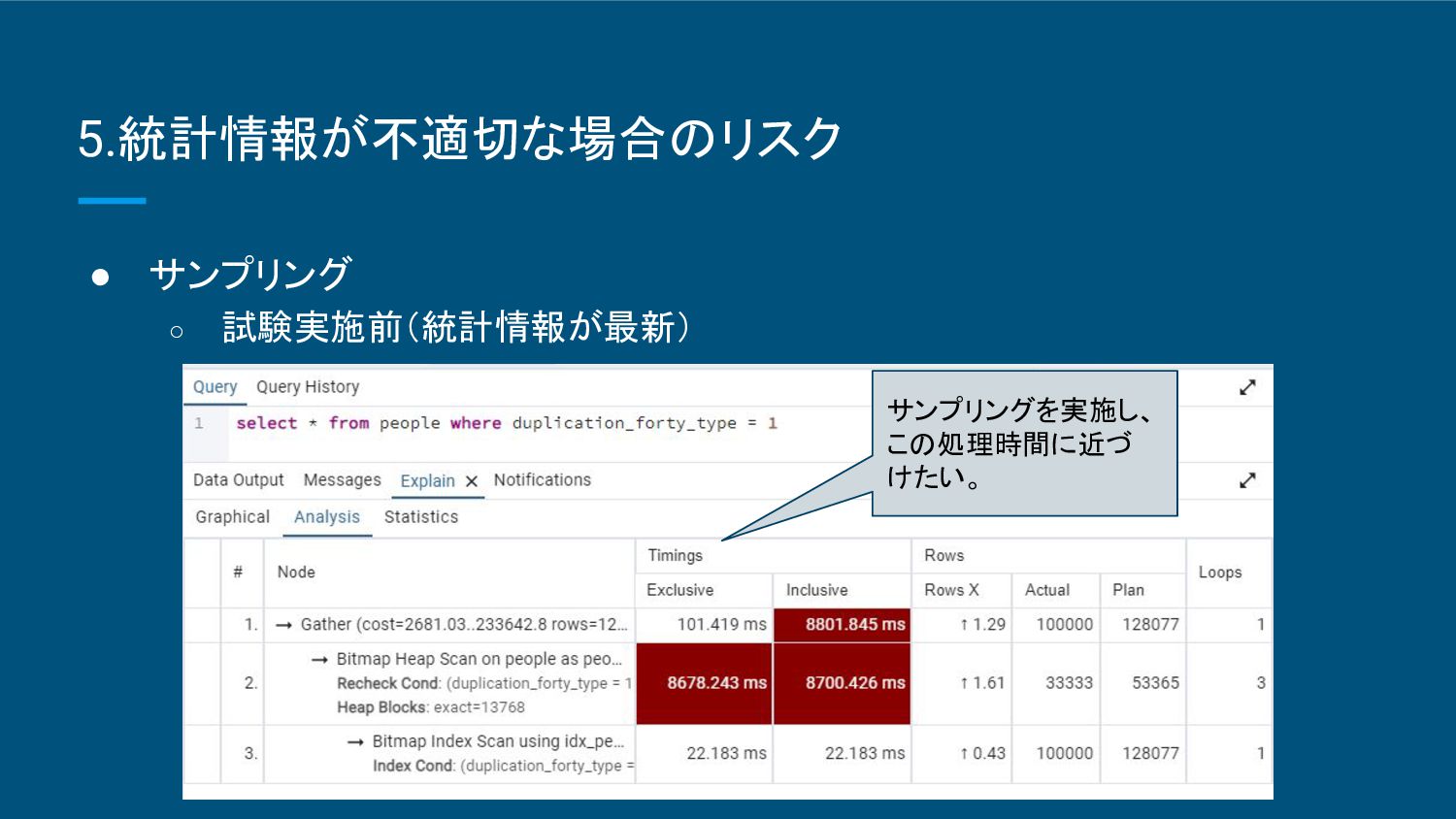{kind=link}
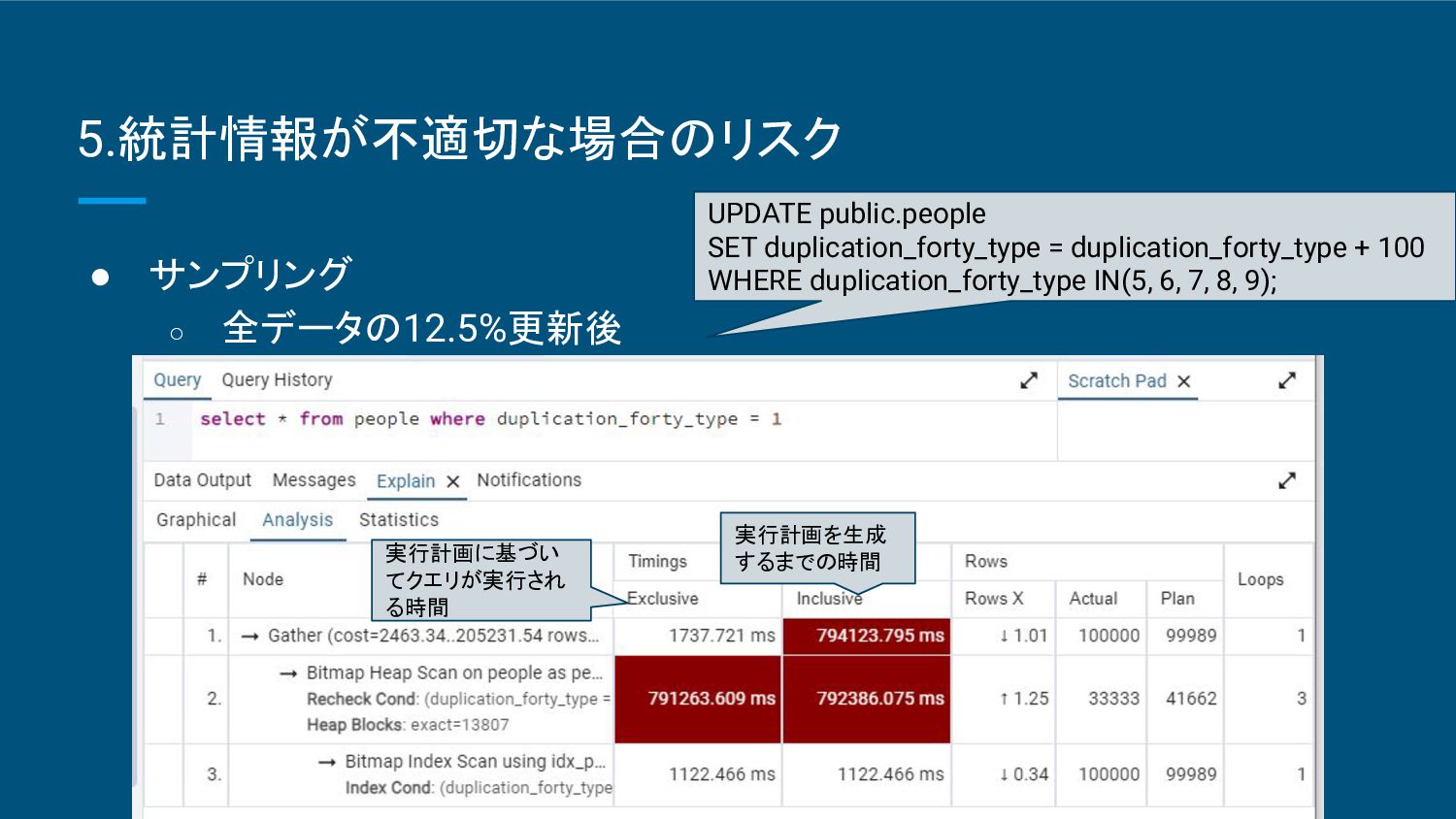{kind=link}
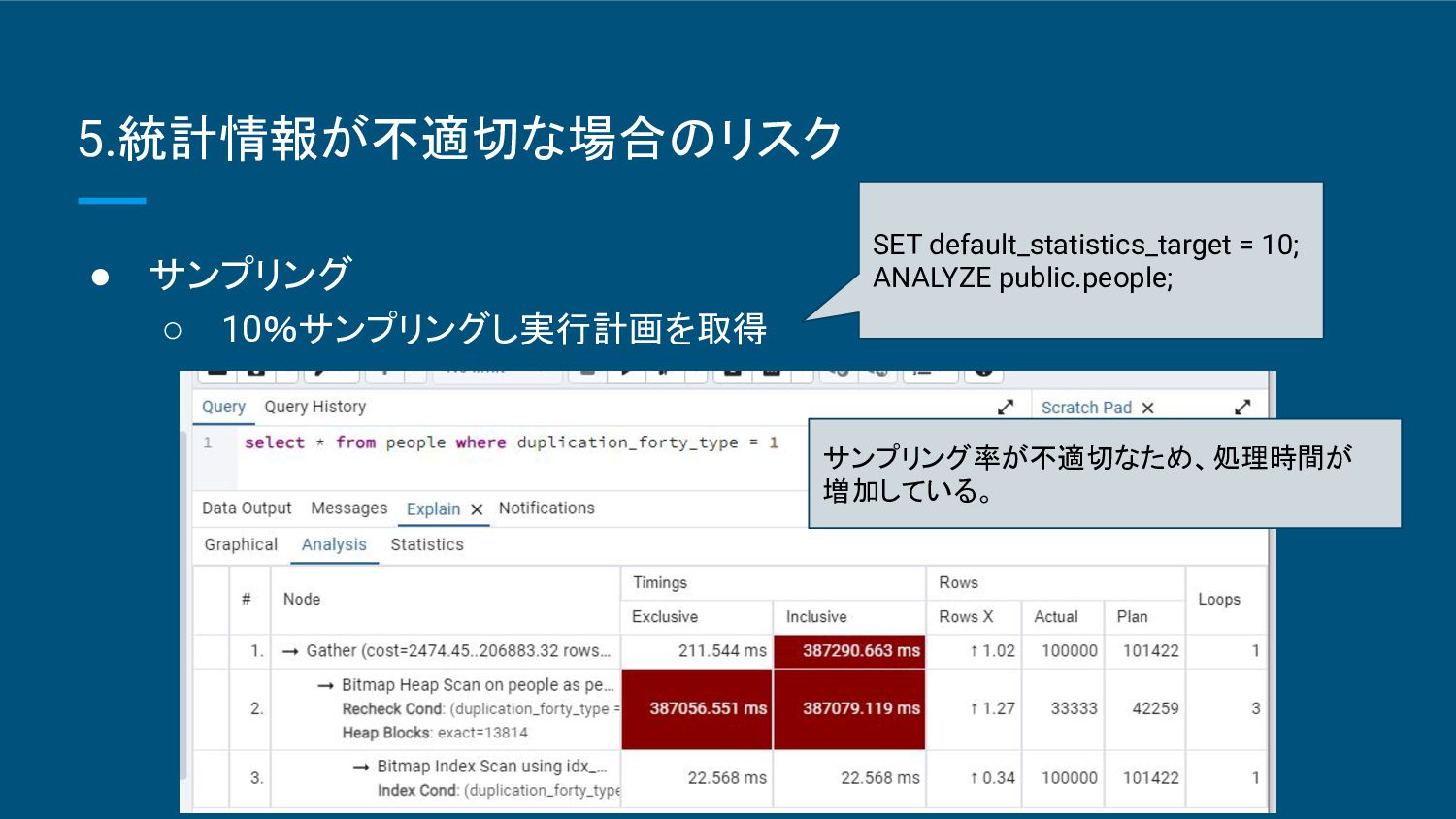{kind=link}
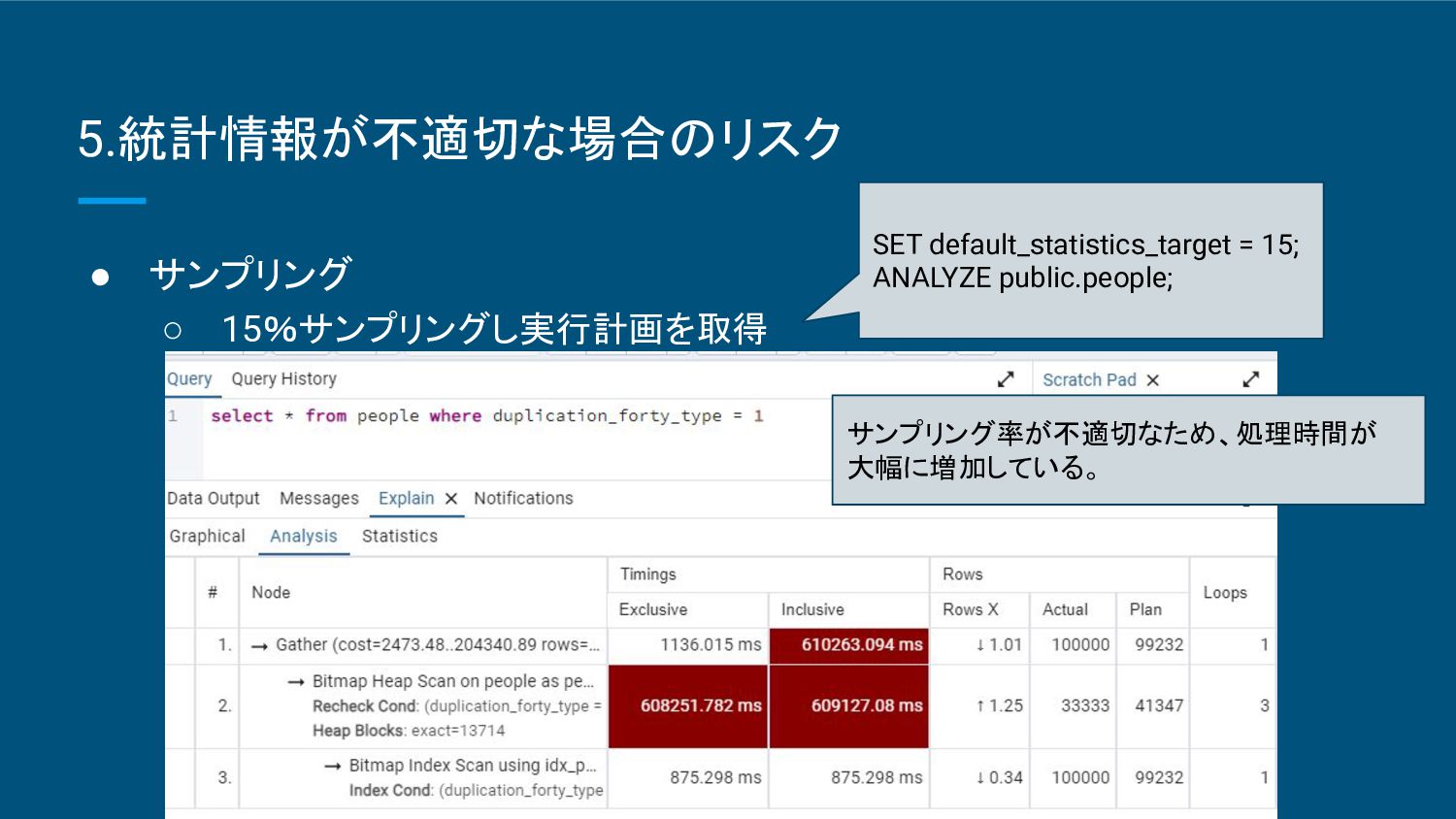{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}