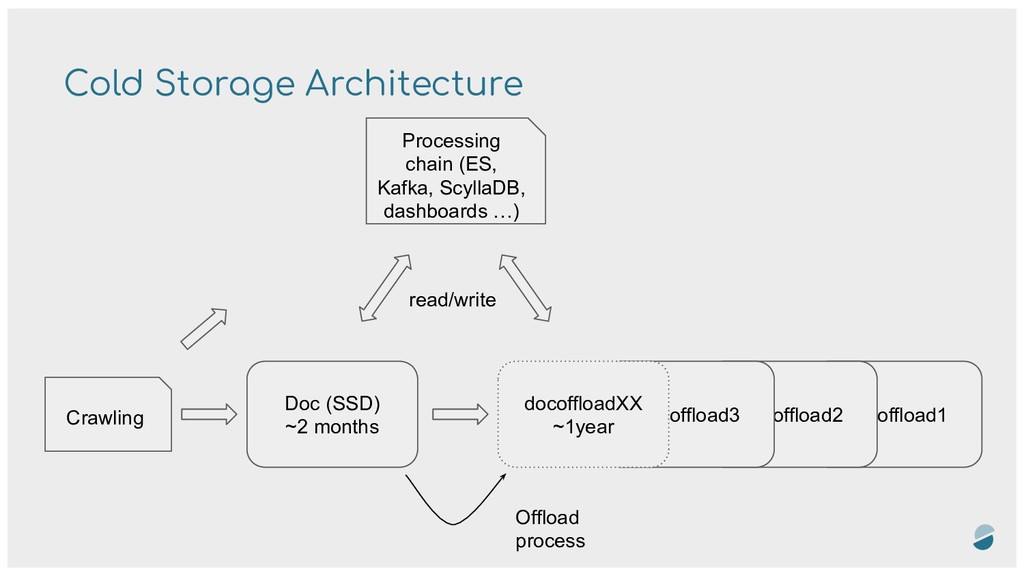
since 10 years - Around 60 millions new documents by days, dozens of billions of documents stored 4 MySQL clusters, around 50TB of data (without replication): - One cluster for “new” mentions (last ~2 months), on SSD disks, with compressed InnoDB (ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8 ) - 3 clusters for oldest data with spinning disks (slooooow, but lots of space), with MyRocks Engine - New MySQL tables every ~40 millions documents - More than 3500 tables - Tables are automagically offloaded from InnoDB to RocksDB every days.
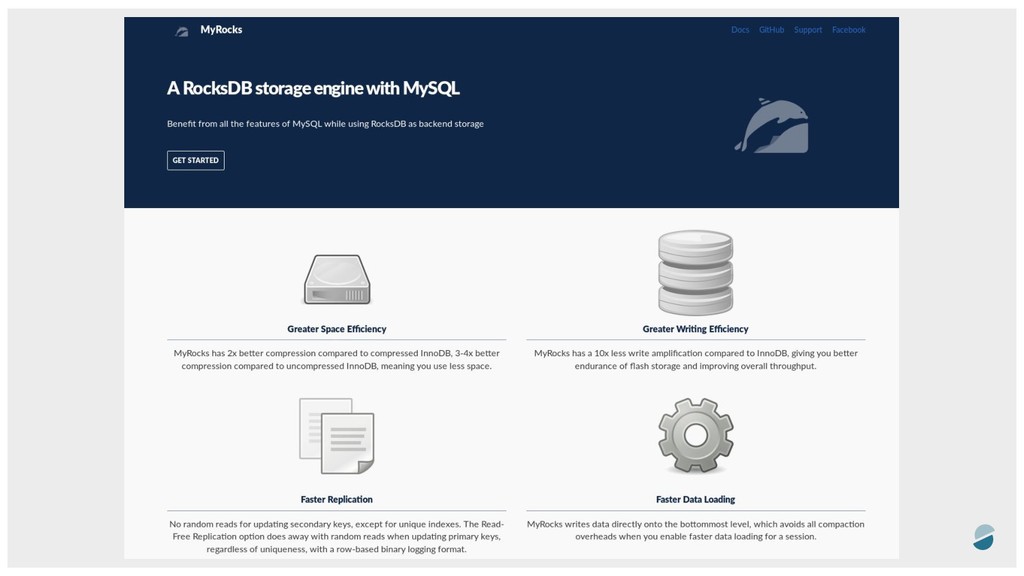
converts your MySQL requests into requests for the RocksDB engine - Created and maintained by Facebook, based on MySQL 5.6. They use it for “UDB” (User DataBase), their social graph, Messenger - Supported by Percona and MariaDB - Benefit from (almost) all the features of MySQL while using RocksDB as backend storage (you don’t need to change your application) - MyRocks focuses on space and write efficiency - MyRocks can be 4x smaller than compressed InnoDB
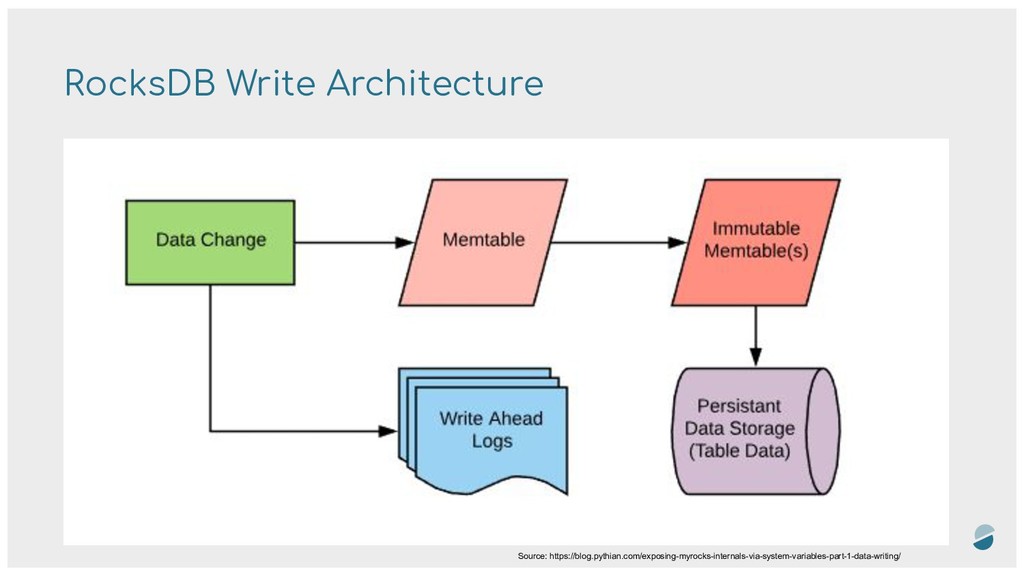
fork of LevelDB - High Performance, uses a log structured database engine (LSM tree) - Optimized for flash drives and SSD - Write data in “sstables”. Immutable data, once written (sequentially), no update-in-place is done. - New data are written sorted, in new files, read operations can read multiples sstables. - Compactions are made in background to merge sstables in new one and reduce read amplification (but with write amplification) - Features: Secondary indexes, bloom filtering, snapshots… - Created and maintained by Facebook, used in dozen of projects: TiDB, YugaByte, Apache Samza, CockroachDB, TiKV …
that make it attractive for providing indexed access to files with high insert volum - Designed to provide better write throughput than traditional B+ tree - Sequential writes. No need to “read before write” - Write immediately (in-memory), do the heavy work “sometime” - later - Reads are more costly than writes (but bloom filter helps !) - Compactions are used to reorder/merge/delete data, and spread sstables in “levels” (in leveled implementations) - Concept used in BigTables, HBase, Cassandra/ScyllaDB, RocksDB, InfluxDB, even in Prometheus
level. So use a “fast” compression for all level, except the bottommost, where you can use a slower but better one, like kZSTD. - compression=kLZ4Compression;bottommost_compression=kZSTD
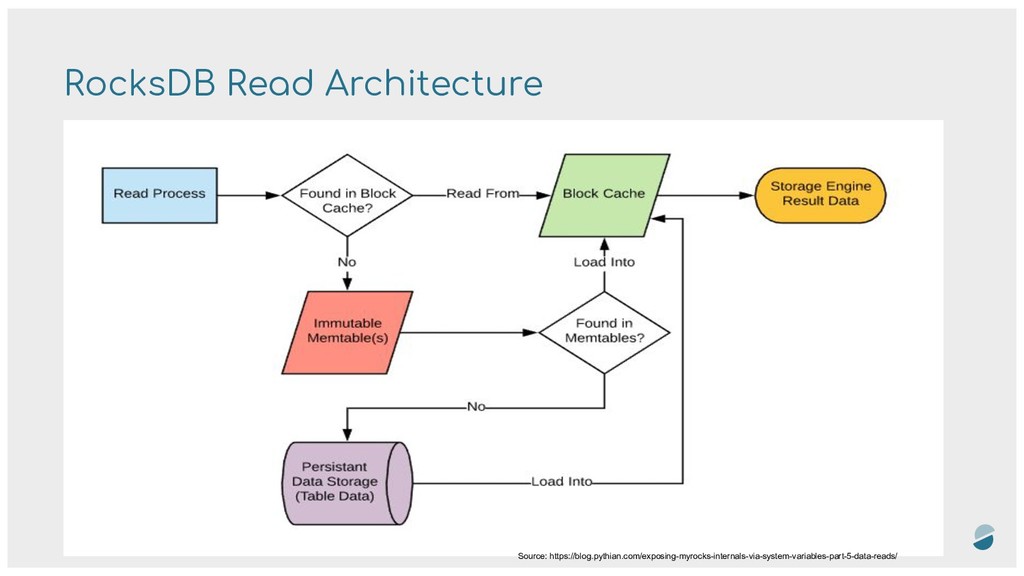
element is a member of a set. - False positives are possible, but false negatives are not ! - It can determines if a data is in a sstable or not - It helps to limit the number of read
on every transaction commit, similar to innodb_flush_log_at_trx_commit . - We use rocksdb_flush_log_at_trx_commit : do not sync on transaction commit. This provides better performance, but may lead to data inconsistency in case of a crash. - We have replica and failover - Big Data means you can lose a little bit of data and nobody will notice, right ?
but fast index creation! - No foreign key or fulltext index support - No Transportable tablespace - Replication exclusively row-based. - No easy “hot backup” solution - fixed with percona 8 and mariadb ! Not really a limitation: - Must have a primary key on table
engine - InnoDB favor read at cost of write and space - MyRocks favor write and space at cost of read - Both are ACID compliant - Compressed InnoDB is roughly 2x smaller than uncompressed InnoDB - MyRocks can be 4x smaller to compressed InnoDB ! - Decompression cost on read - No Galera/XtraCluster support for MyRocks
do a delete, you *write* a new entry saying ‘this data does not exist anymore’ (this is called tombstone) - Then on next read, the engine will read the data, the tombstone and say “meh, the data is in fact deleted” - On next round of compaction, tombstone and data will merge, to really drop the data. - RocksDB have some mechanisms to avoid theses steps when possible (when you remove a key, named SingleDelete) RocksDB Delete Architecture
data. PRIMARY KEY (`id`) COMMENT 'cf_id_pk' means the primary key will be stored in cf_id_pk column family (auto created) KEY `id1_topic` (`id1`,`idTopic`) COMMENT 'rev:cf_topic' Secondary index. Reference the primary index internally. In ASC order by default. Set “rev” to force a DESC order (based on your needs). Each column family have its own config, resources, data files, memory caches. At Synthesio we only use 1 CF because all our MyRocks tables use the same and needs the same options
short transactions, and not for data loading. MyRocks has a couple of special session variables to speed up data loading dramatically. SET session rocksdb_bulk_load=1; - This will force all data to be inserted directly to the bottommost level ! Your data need to be ordered by primary key before insertion (already the case if you have a primary key) - Remove secondary indexes from the schema, re-add them after loading !
snapshot (hard link), and you are done ! > set rocksdb_create_checkpoint=mysnapshot; This will create a snapshot in $datadir/.rocksdb/mysnapshot/ This is what is used by xtrabackup/mariabackup (with extra step for the global coherence with InnoDB/MyISAM tables in mysql database)
- Can’t be used with our Percona flavor because MySQL 5.7 uses innodb for some mysql system tables - MariaDB provides mariabackup (a xtrabackup fork) with myrocks hotbackup support. It uses snapshot feature for the rocksdb part - xtrabackup only support myrocks hot backup starting version 8.0 (and will not backport it to 5.7 branch) - We are using Percona Server 5.7, so, what to do ? Take mariabackup’s MyRocks patch, and backport it to xtrabackup 2.4 ! Surprise, it worked ! Not perfectly, but enough to create a new replica from another instance.
- Legacy codebase with old PHP versions which only speaks MySQL - It’s MySQL ! So no need to change our application ! We know how to operate and deploy it - Once in the “offload” process, we almost never update the data - BUT, when we need to update backdata, we may need to update millions of mentions (for compliance purpose for example) and it takes ages. So a better write performance is a good deal - Space costs money (remember, TB of data)
from the schema - s/ENGINE=InnoDB/ENGINE=ROCKSDB/ - Reinject to the MyRocks servers , with rocksdb_bulk_load=1 - Add back secondary indexes with alter table - Update the map for the application - Do this ~ 3500 times during 4 months - ??? - Profit ! Migration process
30% of disk space saved ! - From 60TB - To 39TB - Better read/writes performances than InnoDB from what we saw - From 150 updates/seconds - To 600 updates/seconds - Used on spinning disks (!) - Replication is done via traditional MySQL way, so we know how it works - Hot Backup is done with our own fork of Percona Xtrabackup (with patches based on mariabackup) - Tons of rocksdb options, that’s why we need to read the rocksdb source code (and comments) to really understand them (well, not all… yet !)
so far - Creation of a new server with the patched xtrabackup works - Next step: upgrade to Percona Server 8.0 to benefit from native xtrabackup support and performance gains.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}