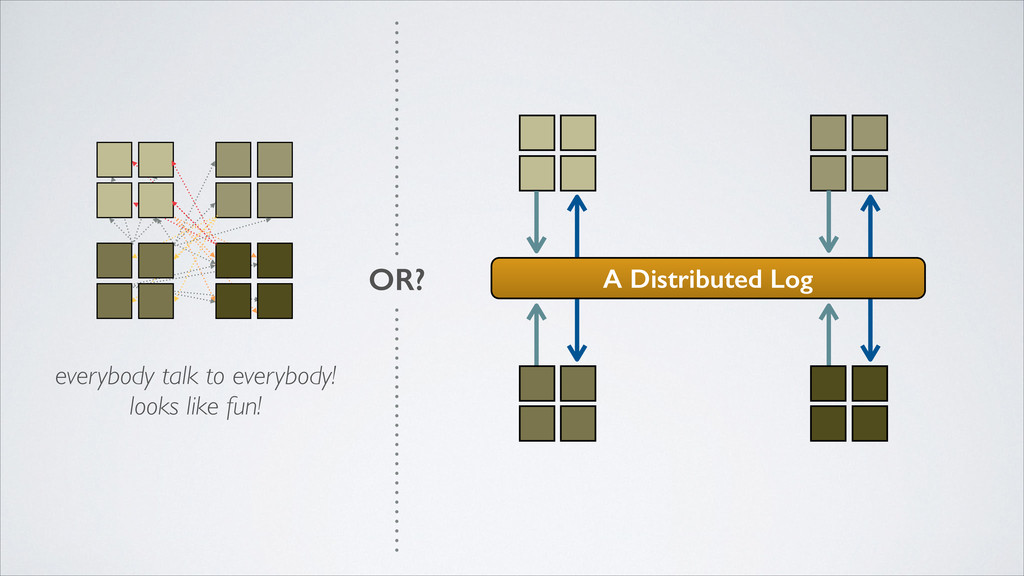
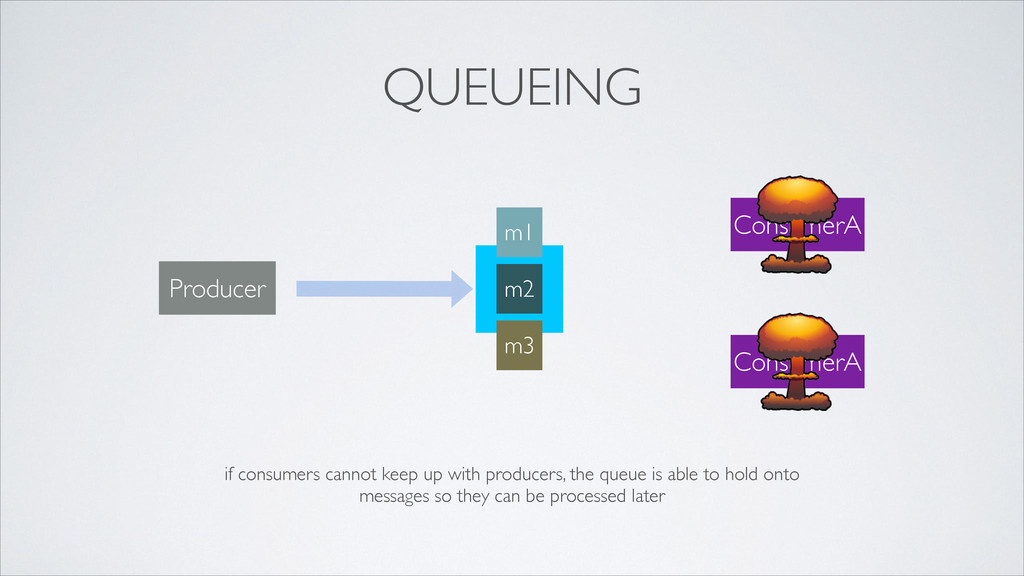
well •de-couple and separate based on responsibility •avoid SPOFs •provide flexibility in deployment and topology •perform work asynchronously •communicate via messaging - how?
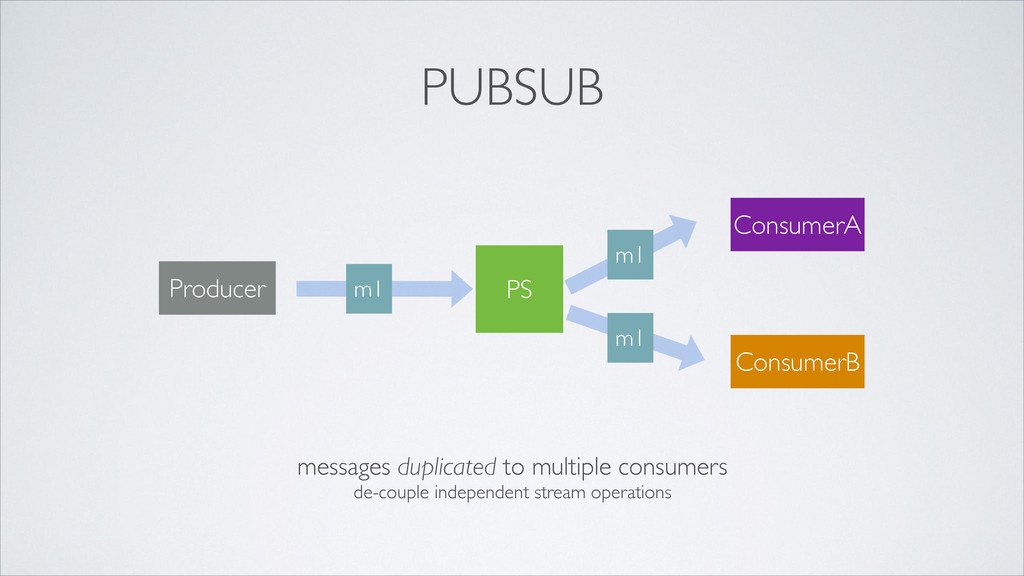
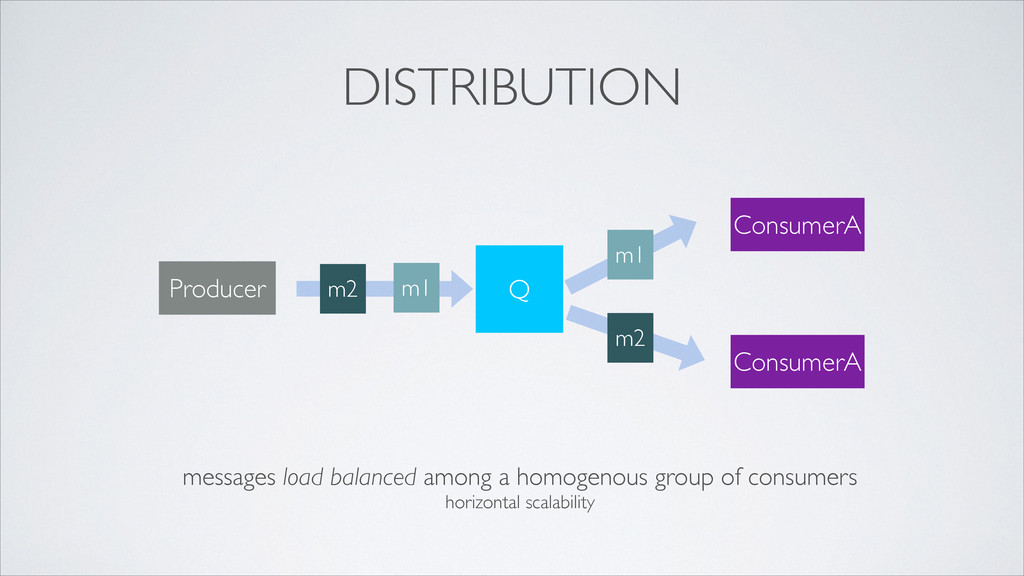
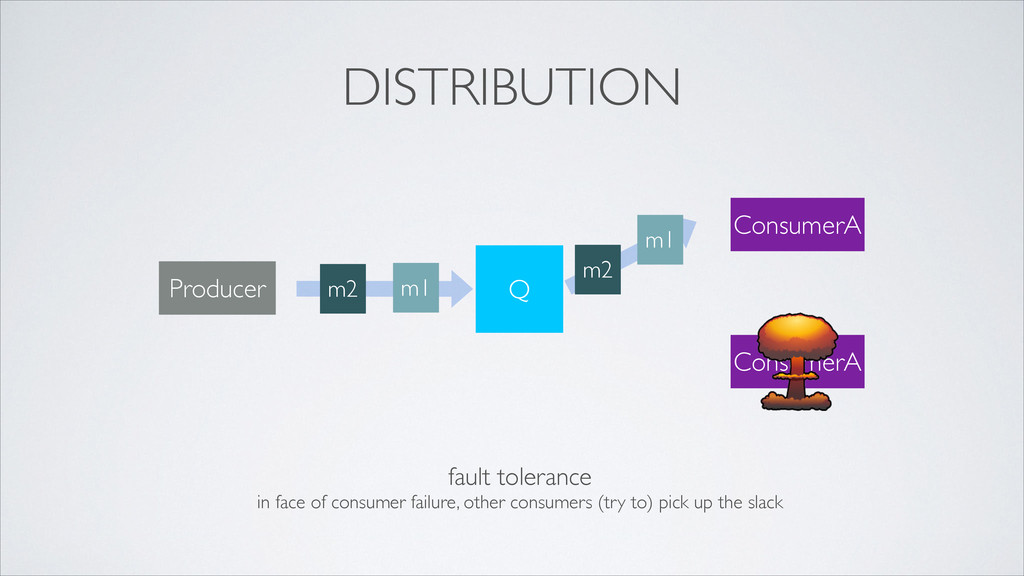
•how do all interested services access data? •how do we maintain loose coupling? •how do we keep it simple? provide a unifying distributed system to receive and disseminate event data
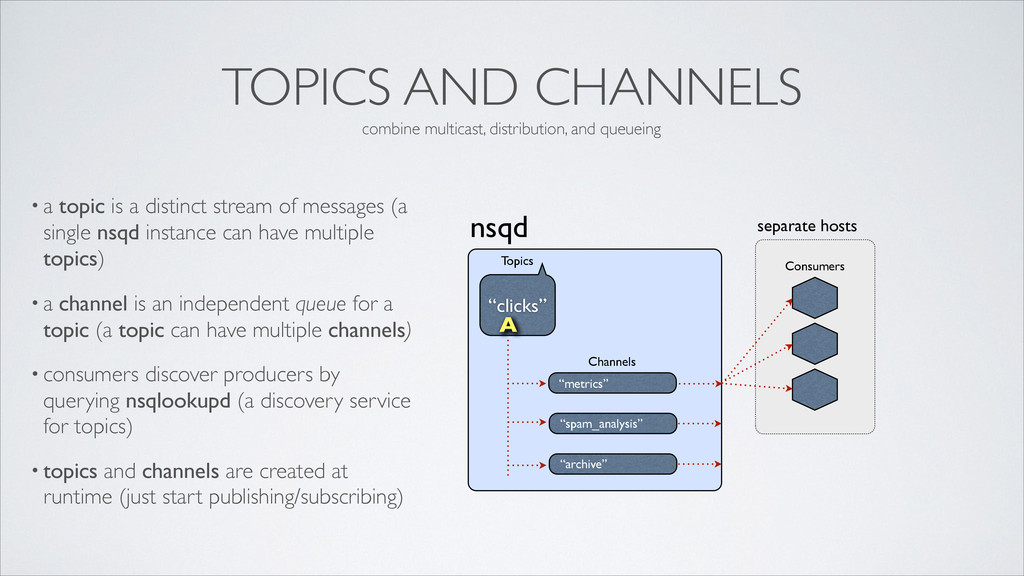
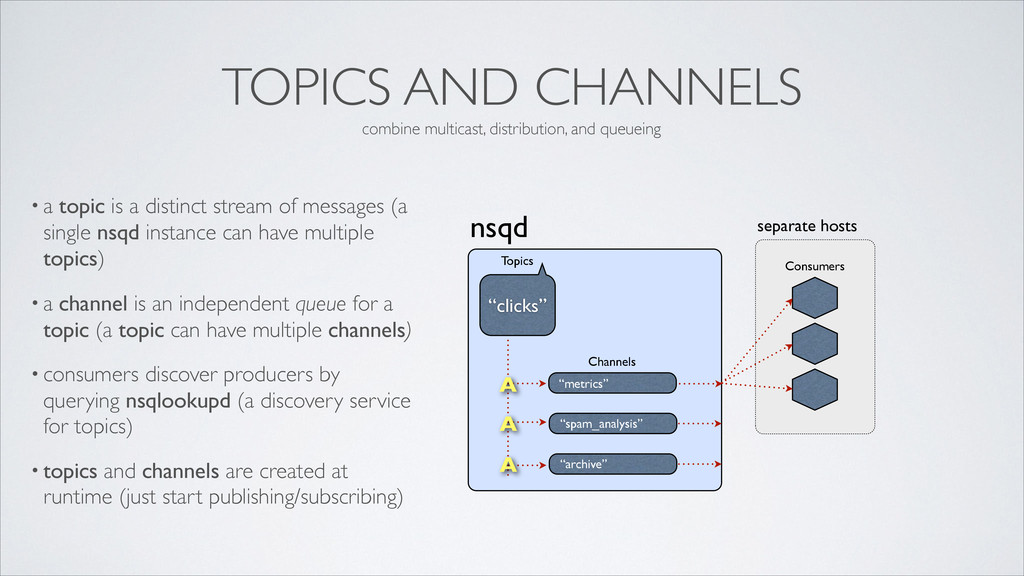
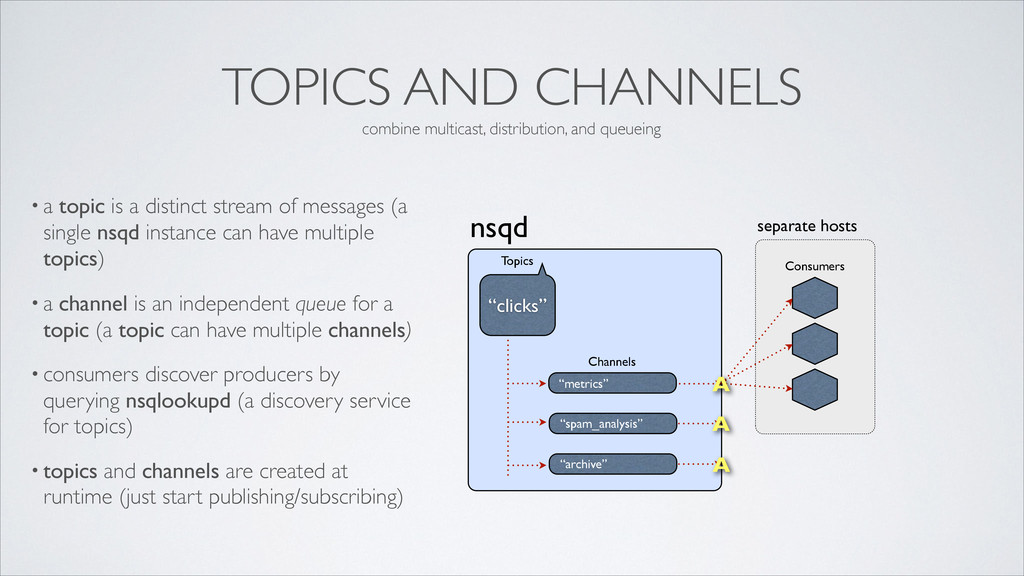
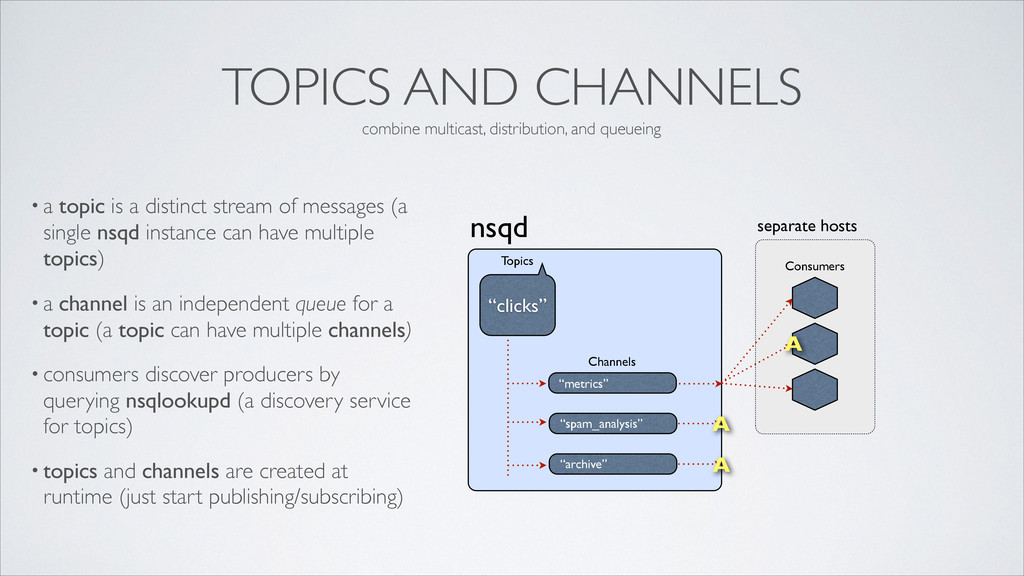
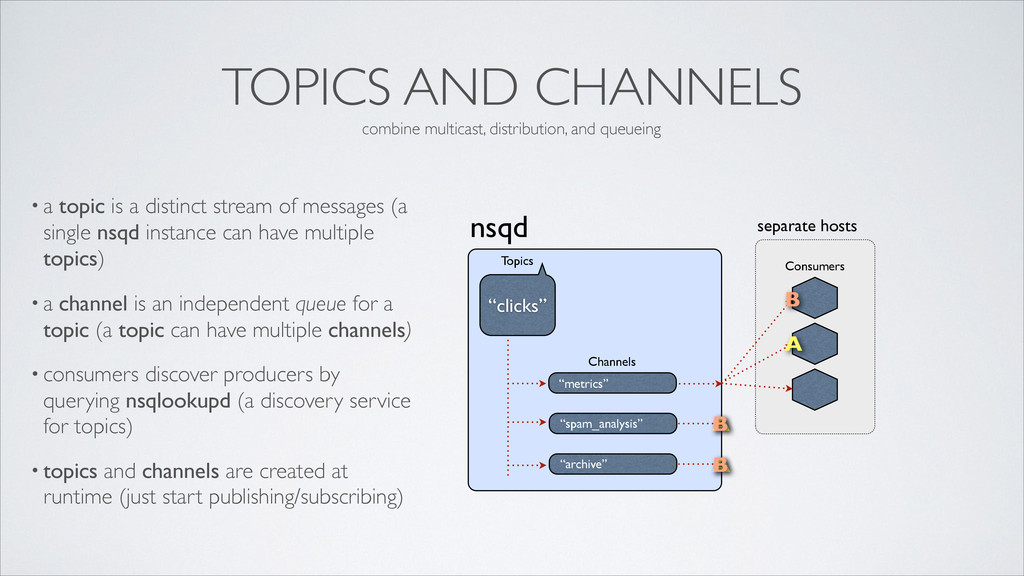
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A combine multicast, distribution, and queueing
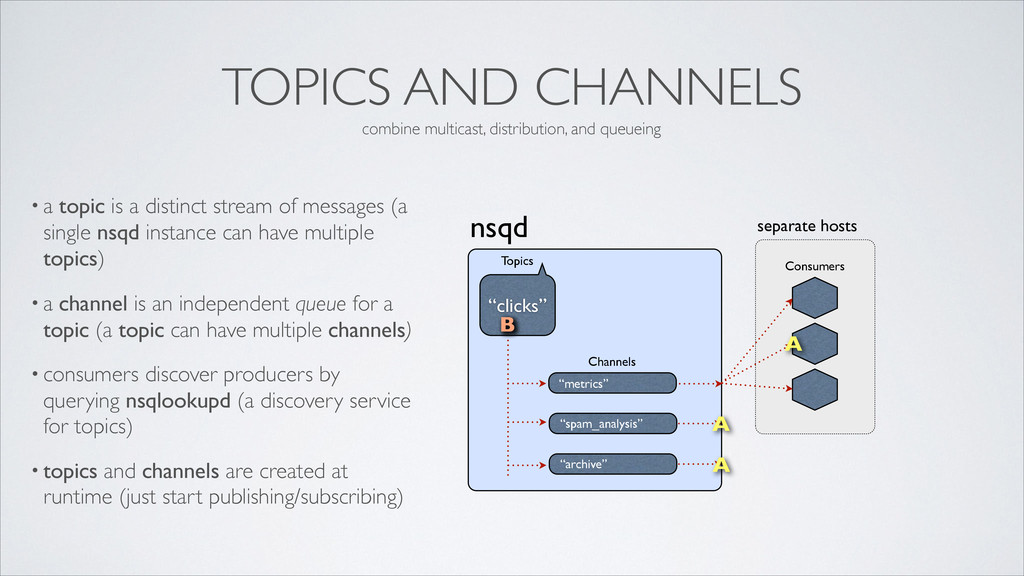
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A combine multicast, distribution, and queueing
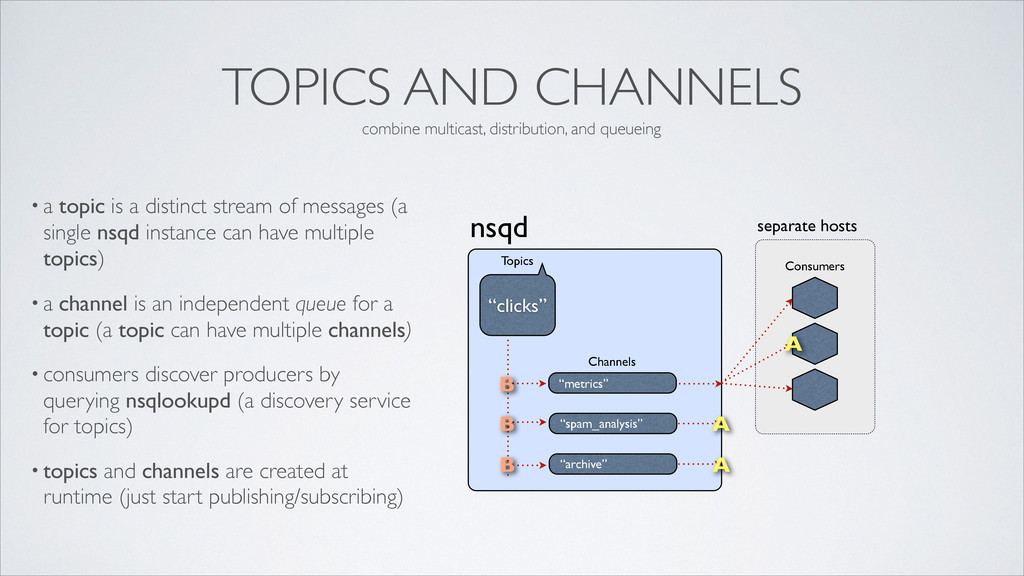
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A combine multicast, distribution, and queueing
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A combine multicast, distribution, and queueing
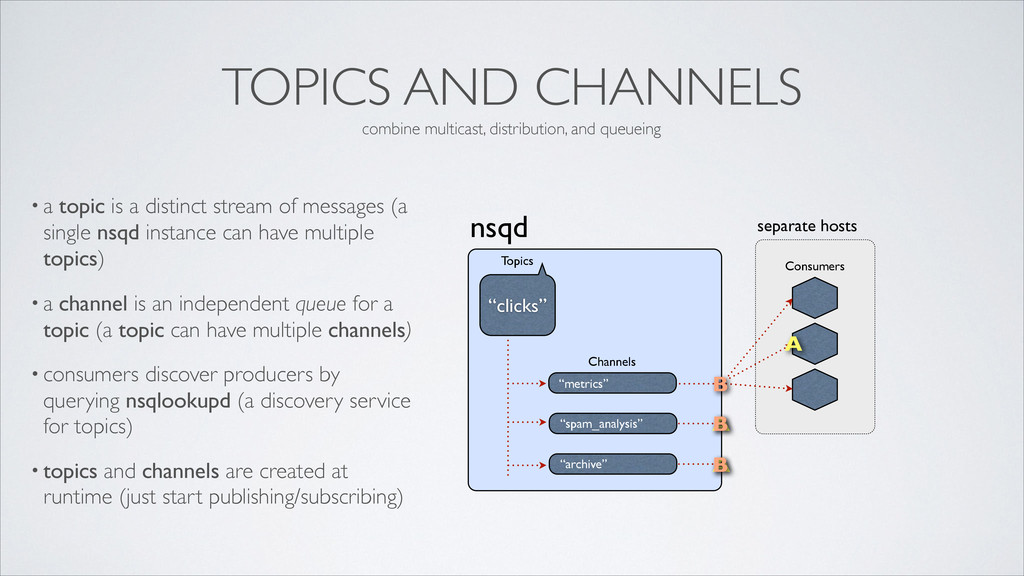
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A B B B combine multicast, distribution, and queueing
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A B B B combine multicast, distribution, and queueing
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A B B B combine multicast, distribution, and queueing
distinct stream of messages (a single nsqd instance can have multiple topics) • a channel is an independent queue for a topic (a topic can have multiple channels) • consumers discover producers by querying nsqlookupd (a discovery service for topics) • topics and channels are created at runtime (just start publishing/subscribing) nsqd “metrics” Channels “clicks” Topics “spam_analysis” “archive” Consumers A A A B B B combine multicast, distribution, and queueing
high water marks (after which messages transparently read/write to disk, bounding memory footprint) •supports channel-independent degradation and recovery buffer this channel high water mark persisted messages
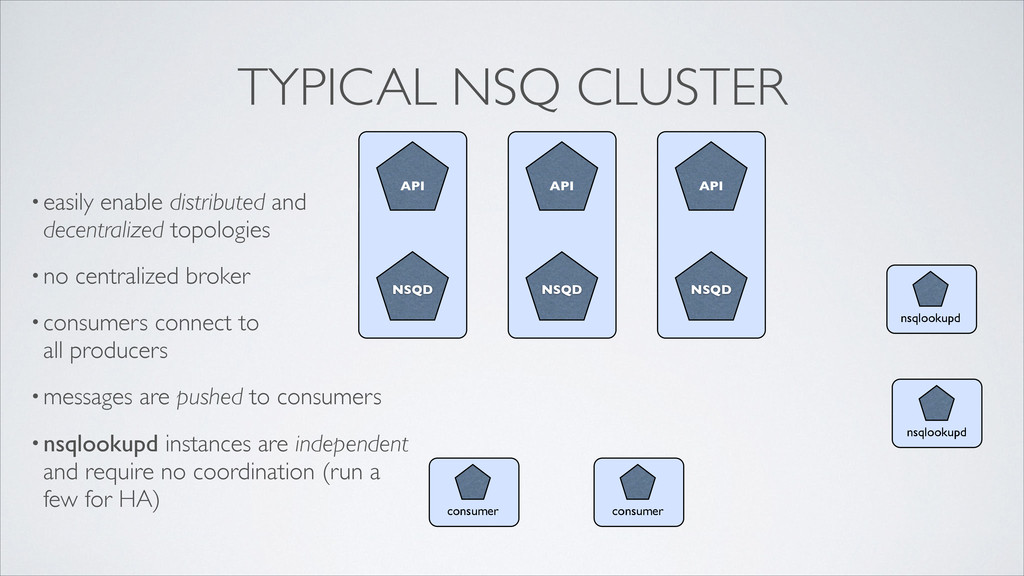
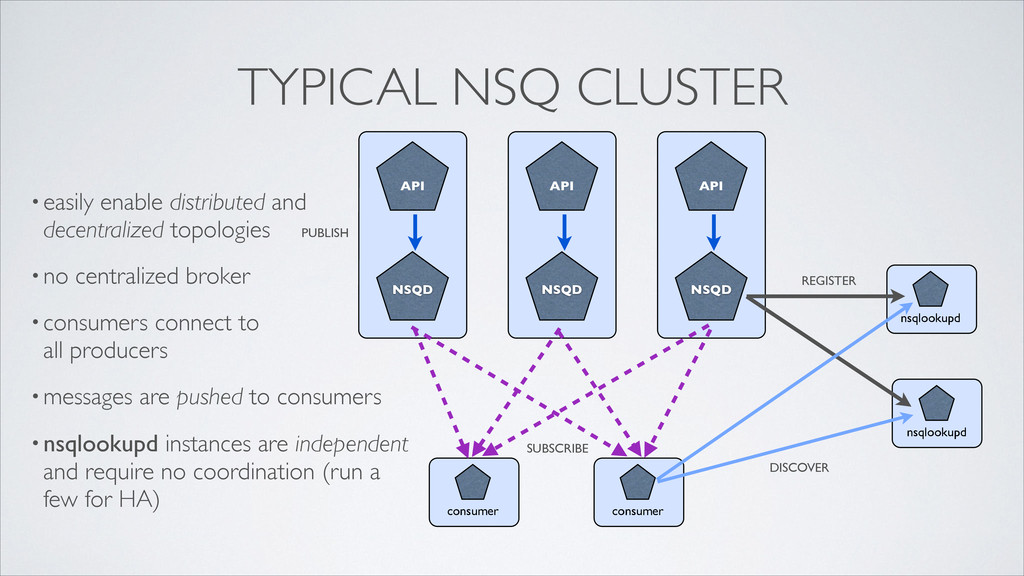
consumer nsqlookupd nsqlookupd TYPICAL NSQ CLUSTER •easily enable distributed and decentralized topologies •no centralized broker •consumers connect to all producers •messages are pushed to consumers •nsqlookupd instances are independent and require no coordination (run a few for HA)
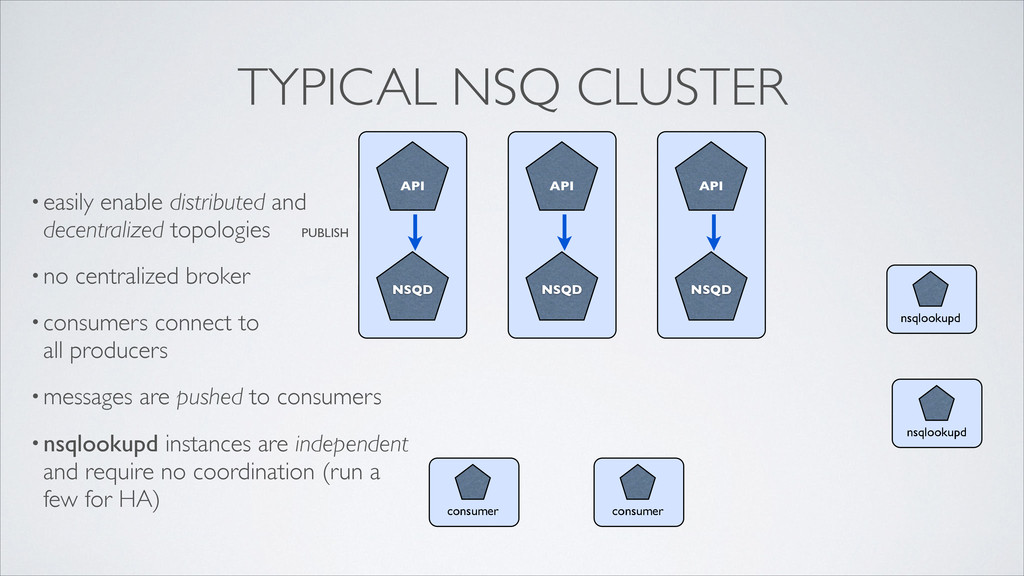
consumer nsqlookupd nsqlookupd PUBLISH TYPICAL NSQ CLUSTER •easily enable distributed and decentralized topologies •no centralized broker •consumers connect to all producers •messages are pushed to consumers •nsqlookupd instances are independent and require no coordination (run a few for HA)
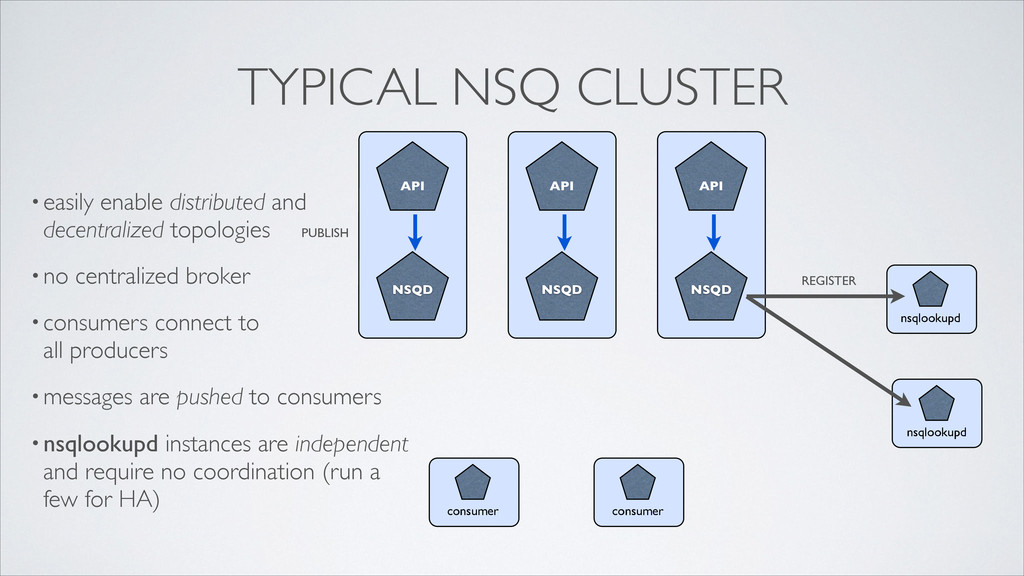
consumer nsqlookupd nsqlookupd PUBLISH REGISTER TYPICAL NSQ CLUSTER •easily enable distributed and decentralized topologies •no centralized broker •consumers connect to all producers •messages are pushed to consumers •nsqlookupd instances are independent and require no coordination (run a few for HA)
consumer nsqlookupd nsqlookupd PUBLISH REGISTER DISCOVER TYPICAL NSQ CLUSTER •easily enable distributed and decentralized topologies •no centralized broker •consumers connect to all producers •messages are pushed to consumers •nsqlookupd instances are independent and require no coordination (run a few for HA)
consumer nsqlookupd nsqlookupd PUBLISH REGISTER DISCOVER SUBSCRIBE TYPICAL NSQ CLUSTER •easily enable distributed and decentralized topologies •no centralized broker •consumers connect to all producers •messages are pushed to consumers •nsqlookupd instances are independent and require no coordination (run a few for HA)
is built-in •goroutines (lightweight userland threads) •“don’t communicate by sharing memory, share memory by communicating” •small (easy to learn) •statically linked (no external dependencies) •good C interoperability •vast standard library (HTTP server, network IO, RPC, JSON, buffered IO, etc.) •… it keeps getting better / faster with each new release
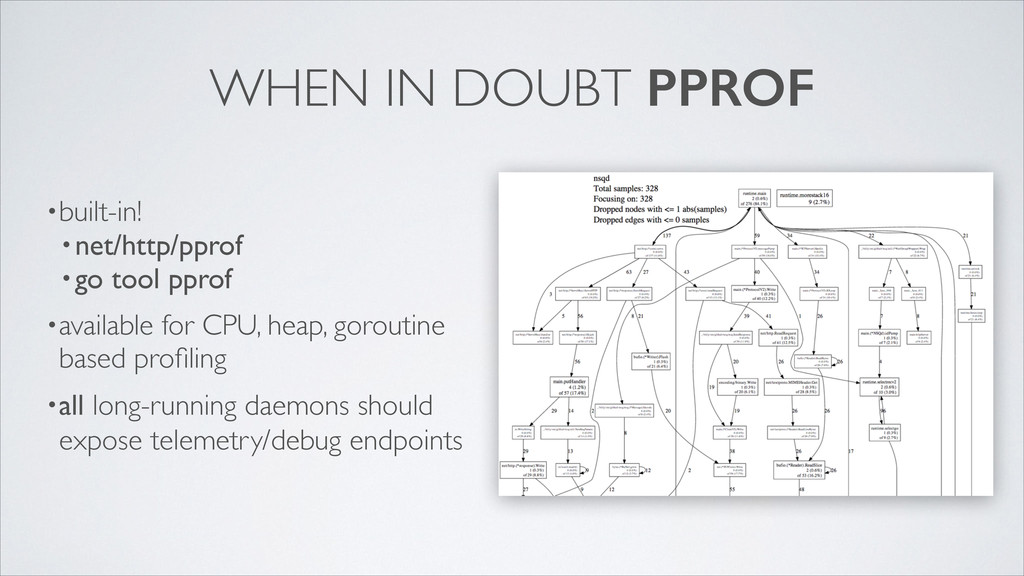
(production?) •publish metrics to statsd (graphed in nsqadmin) •then understand where garbage is generated •go test -benchmem (profile allocations) •go build -gcflags -m (output escape analysis) UNDERSTANDING THE GC
or objects (use sync.Pool in Go 1.3) •pre-allocate slices make([]byte, 0, 1024) •explicitly specify number/size of items on the wire •leave nothing unbounded •apply sane limits to configurable dials (message size, # of messages) •avoid boxing (use of interface{}) or unnecessary wrapper types •avoid the use of defer in hot code paths (it allocates)
•channels are overkill for primitives •goroutines are cheap not free (~4k per) •use worker pools rather than “goroutine per X” •synchronizing goroutine exit and cleanup is hard •all IO must have timeouts (guarantee progress) •wrap IO with bufio.Reader/Writer to reduce context switches (syscalls) •select skips nil channels
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![REDUCING GC PRESSURE •avoid []byte to string conversions •re-use buffers](https://files.speakerdeck.com/presentations/a67a65808c9301319a381659f8c2cbb1/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
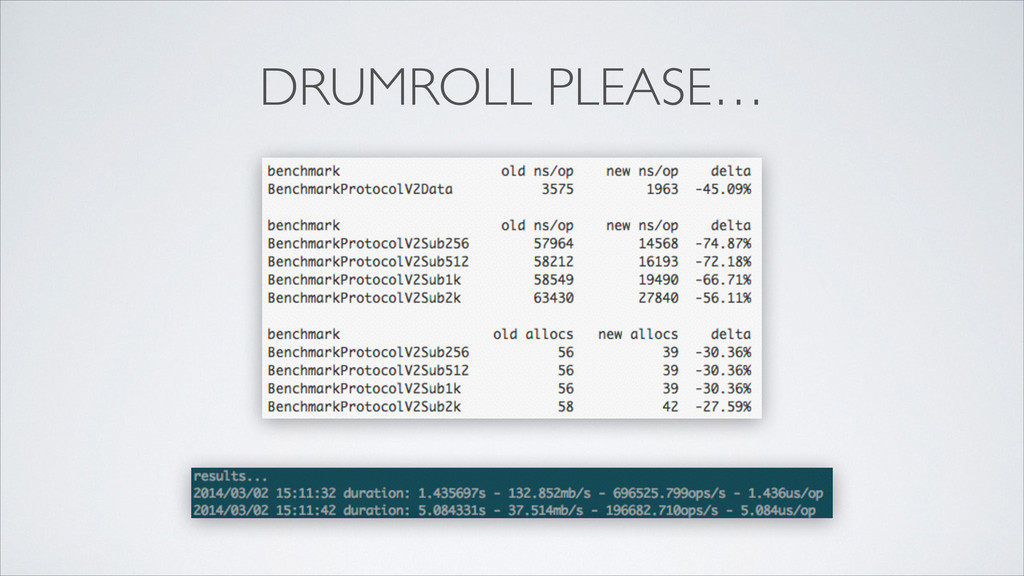{kind=link}
{kind=link}