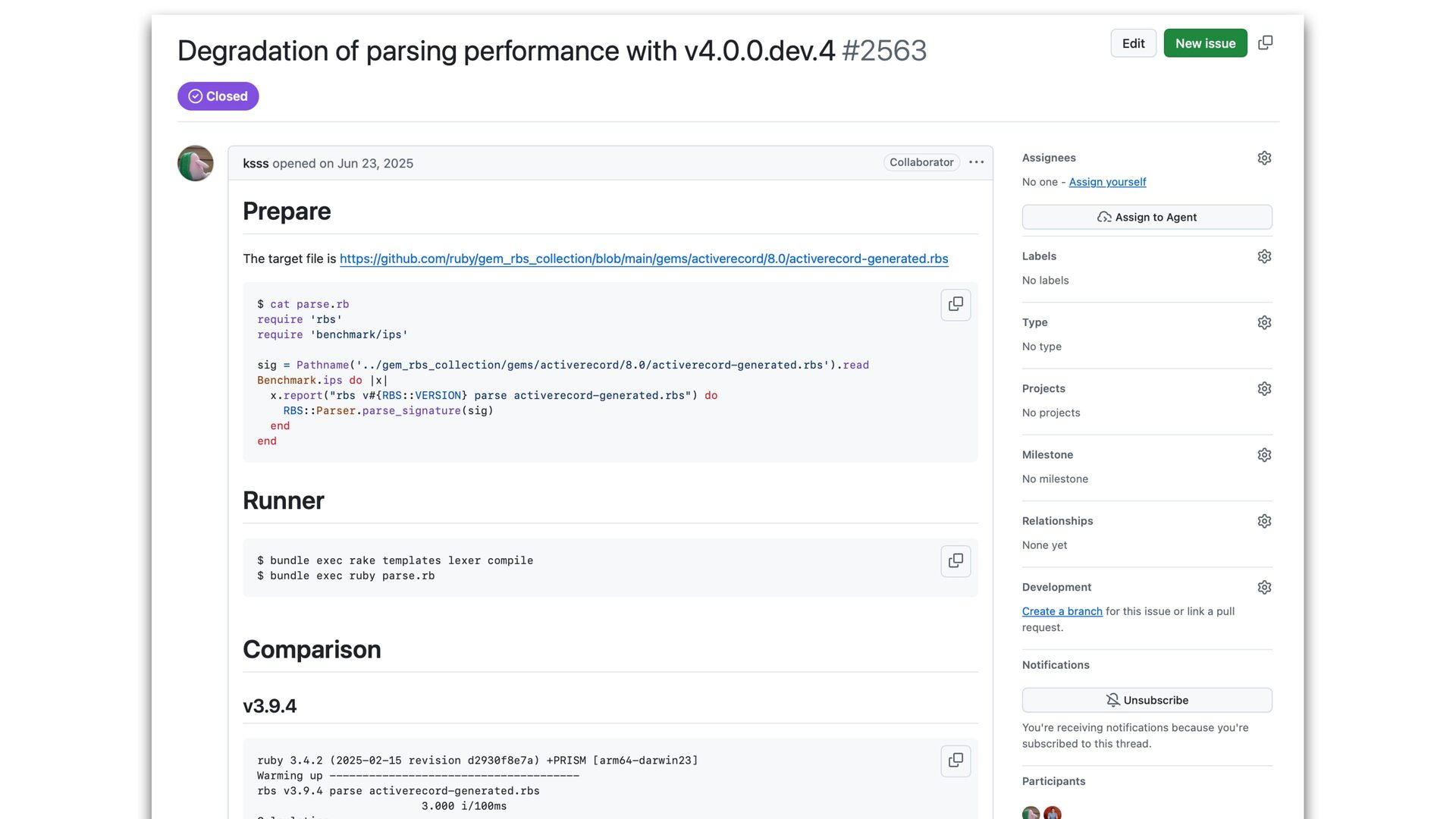
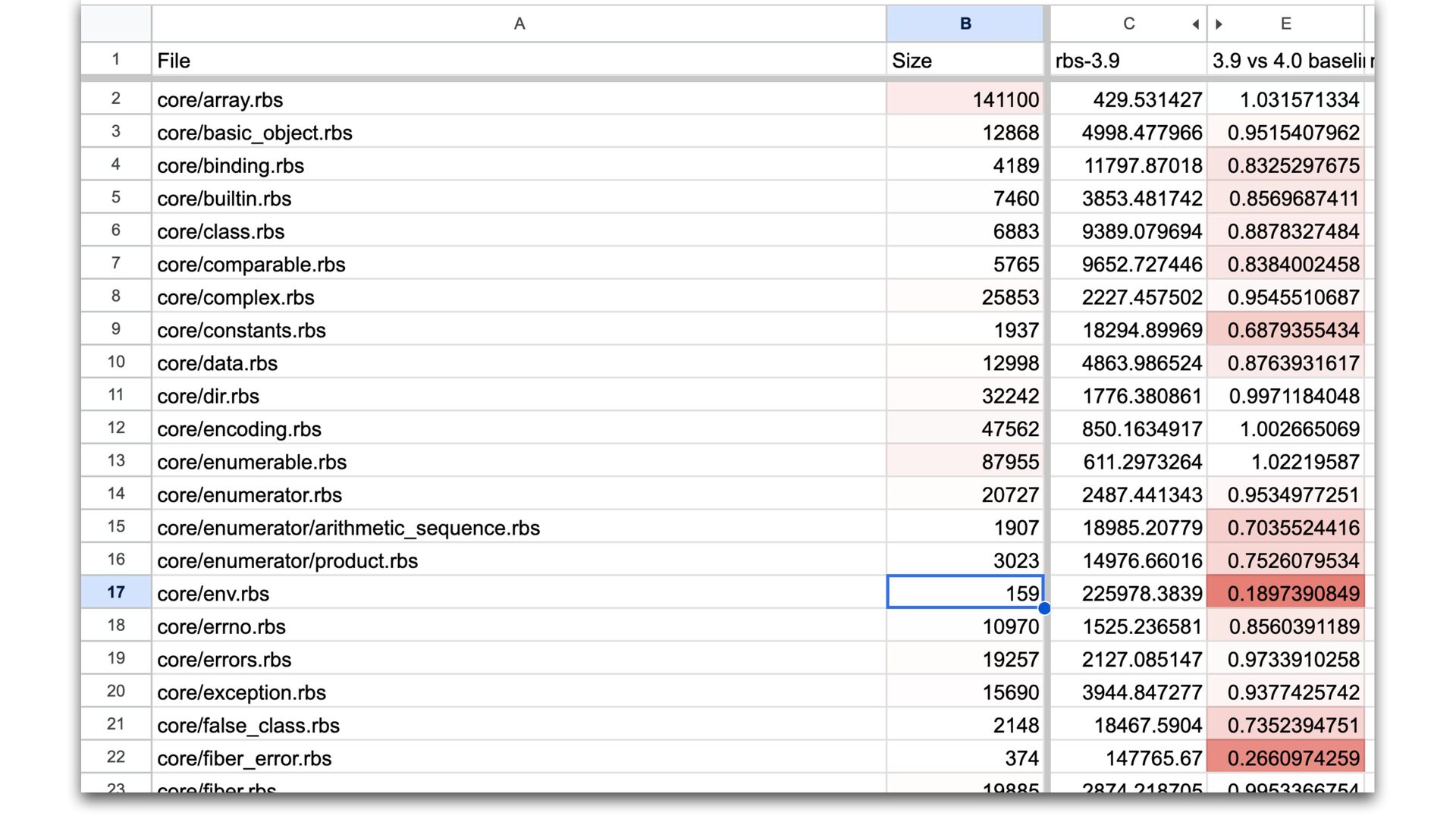
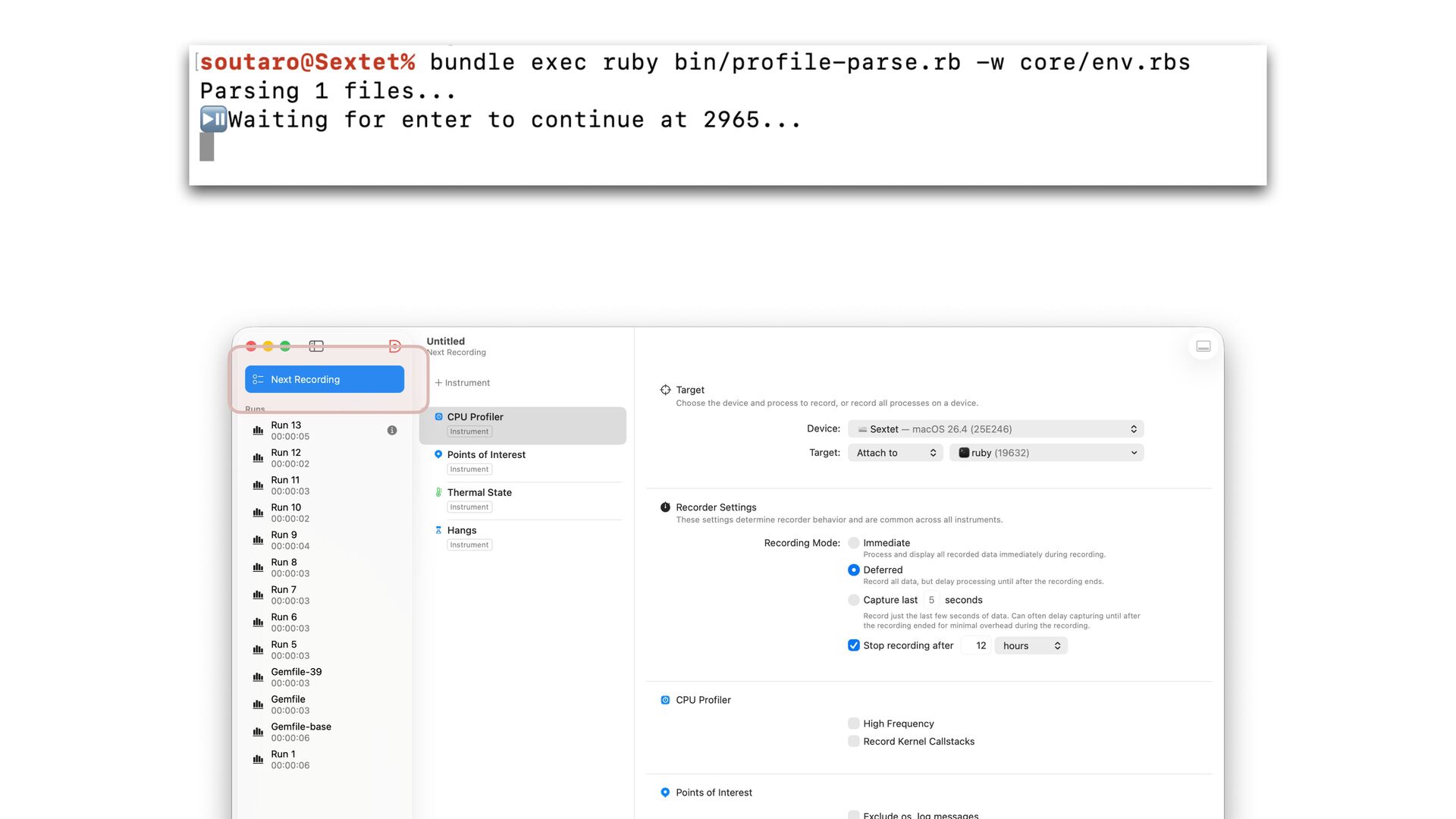
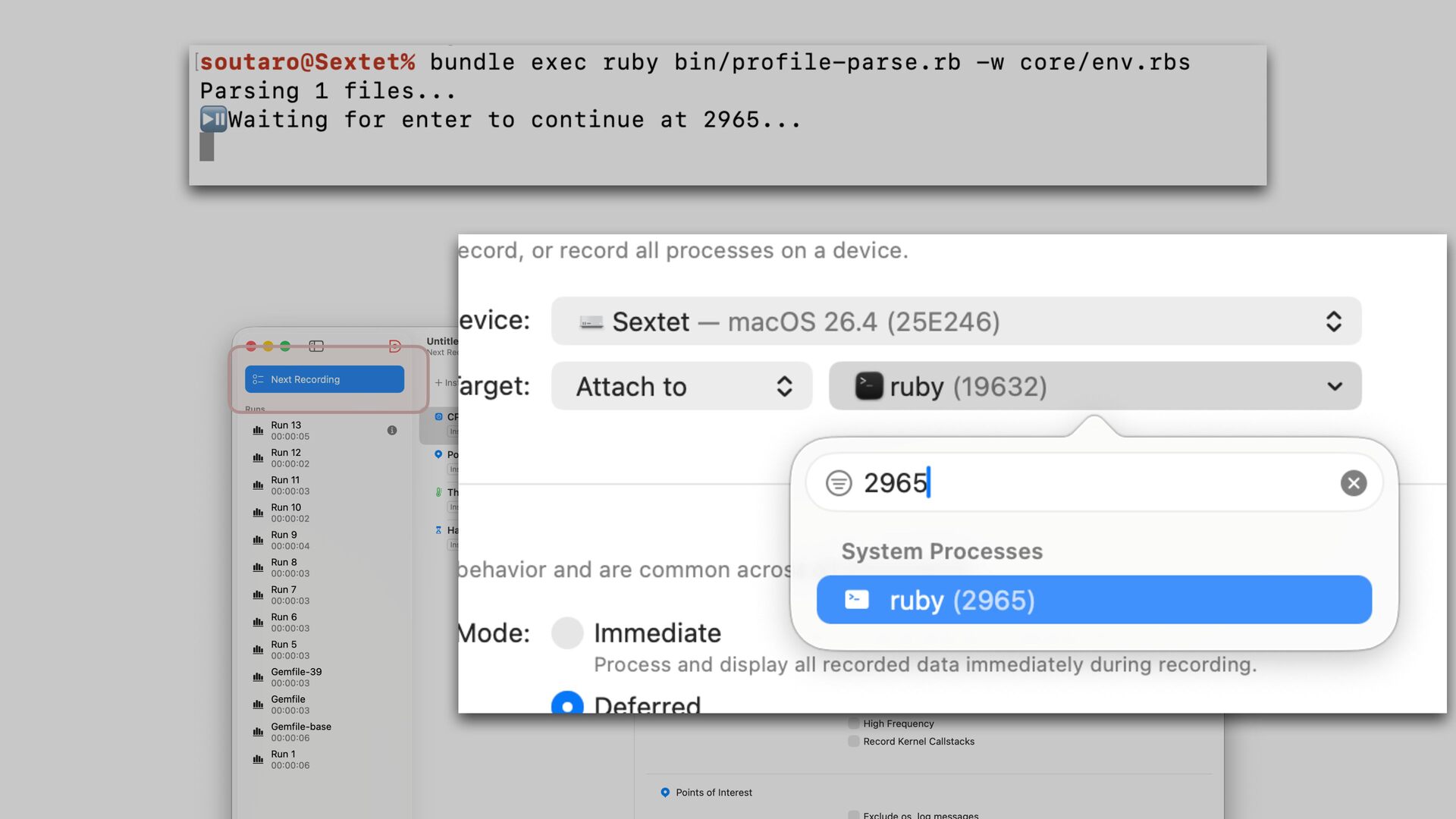
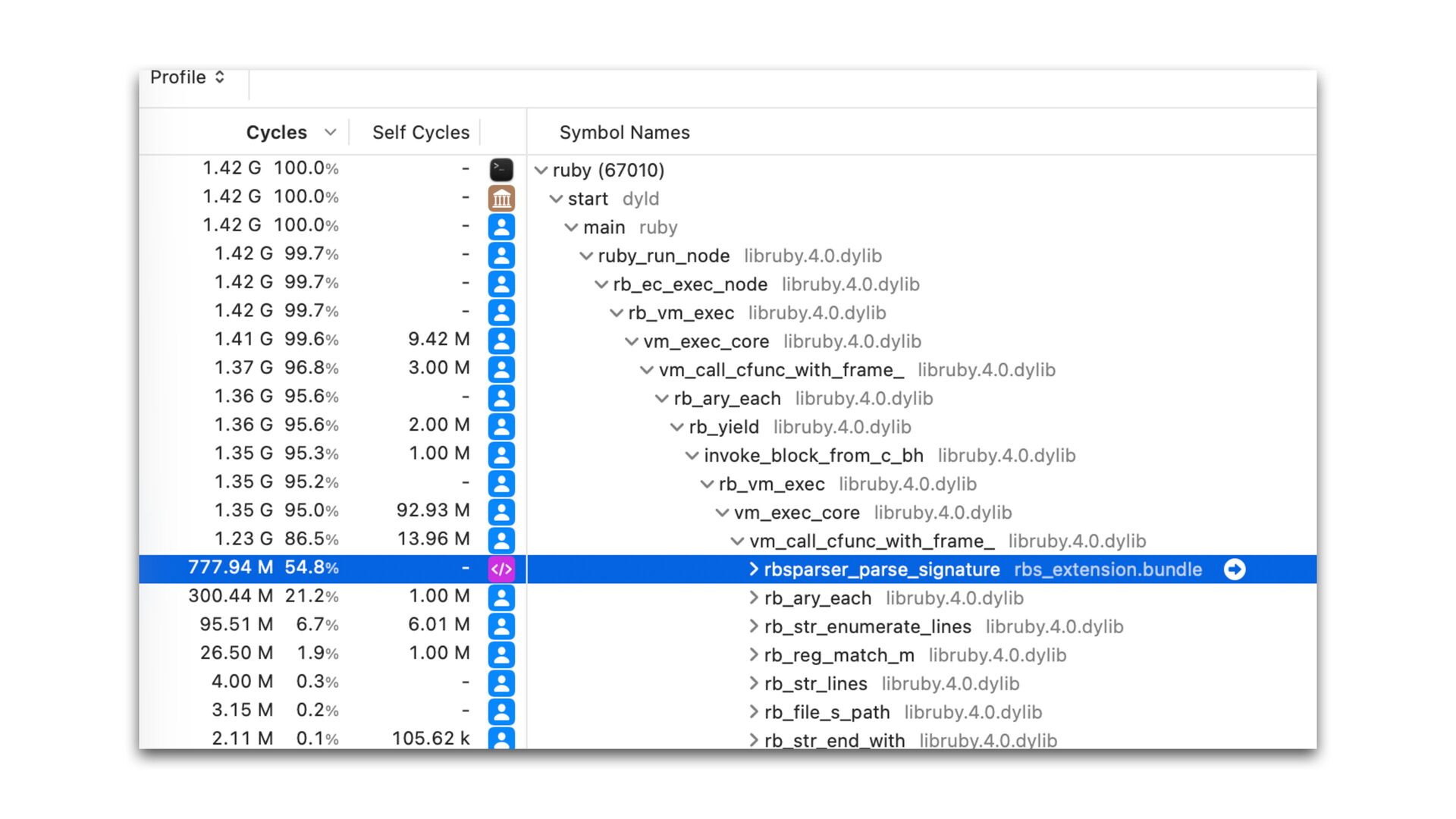
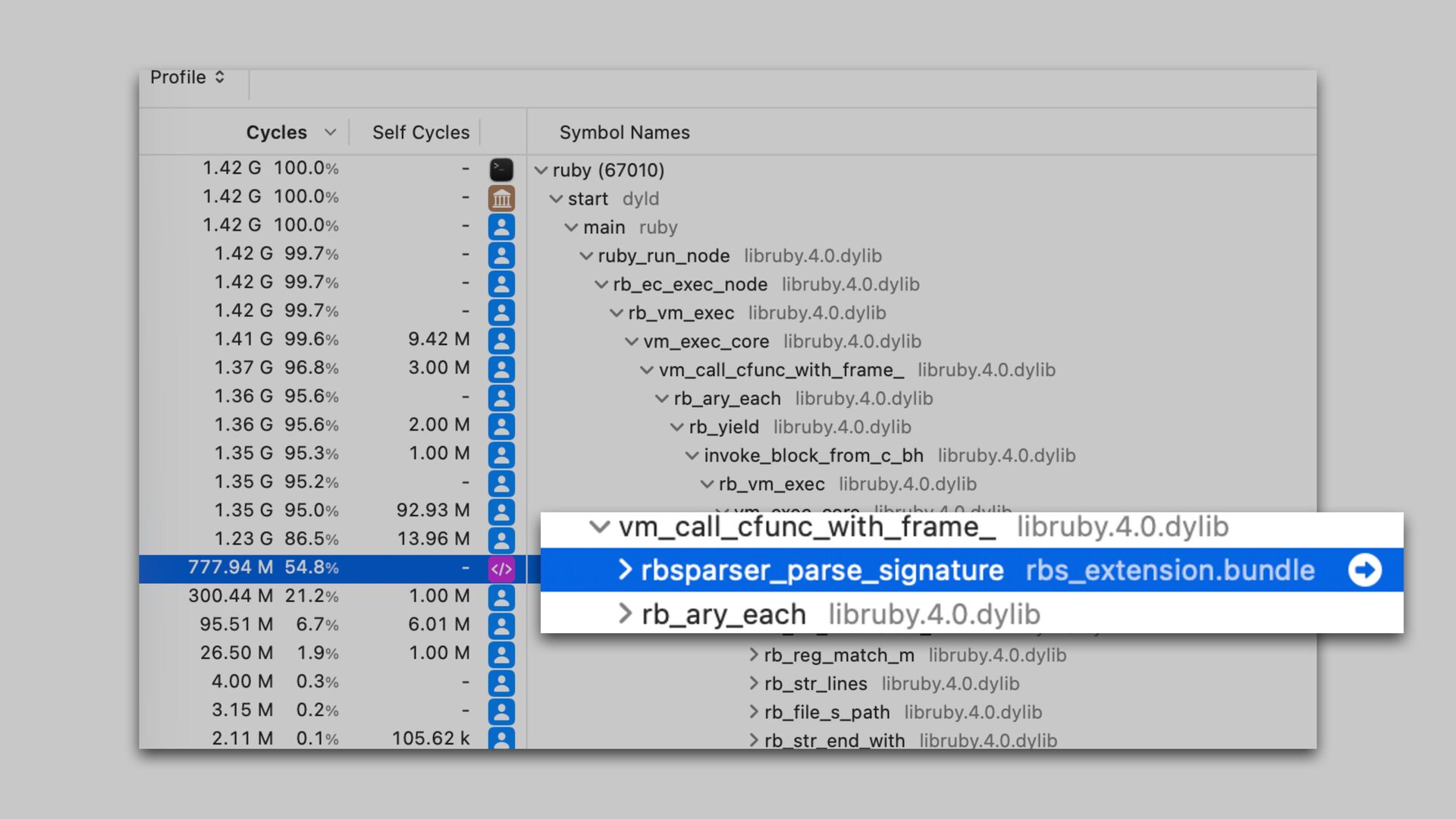
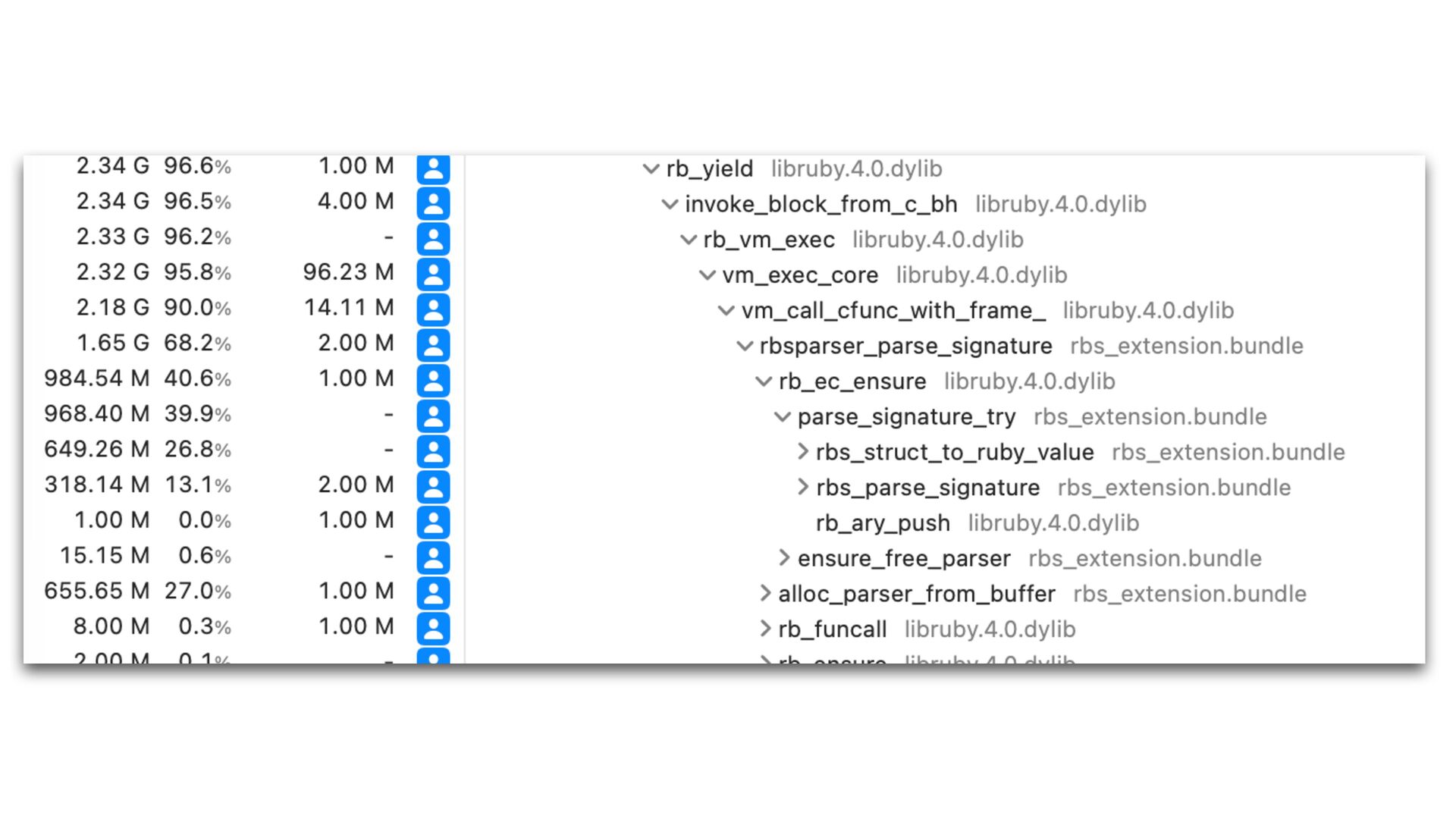
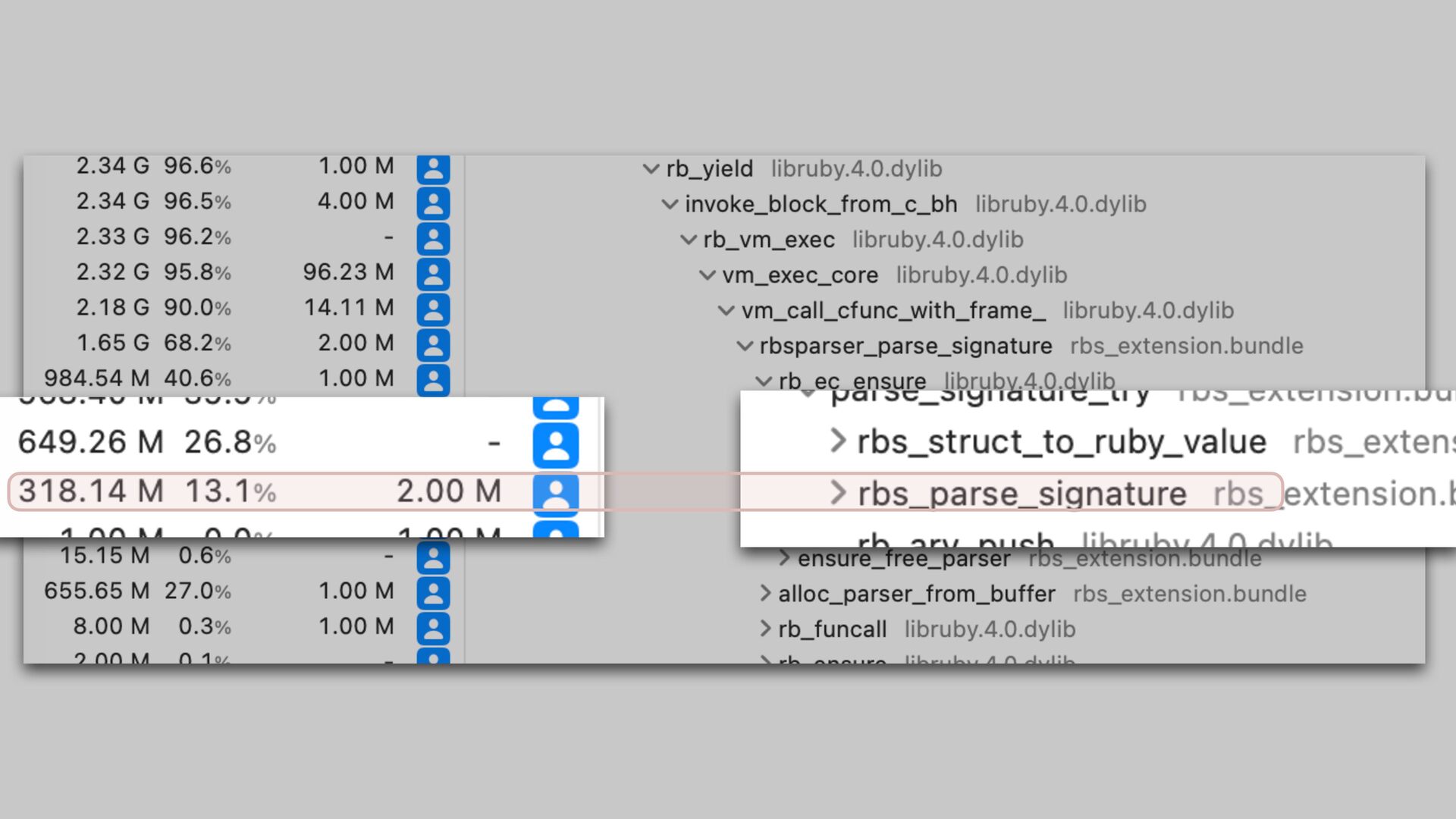
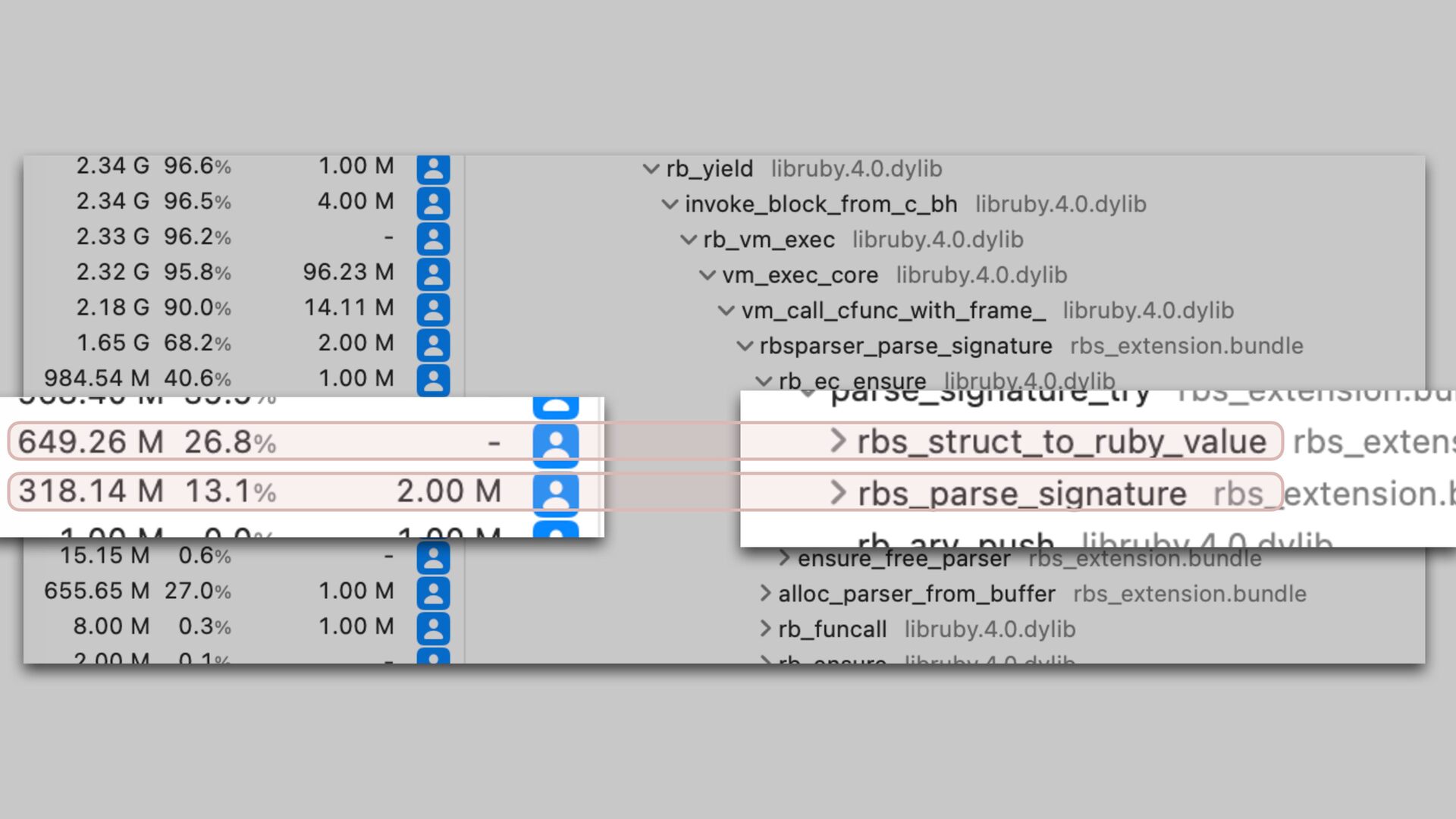
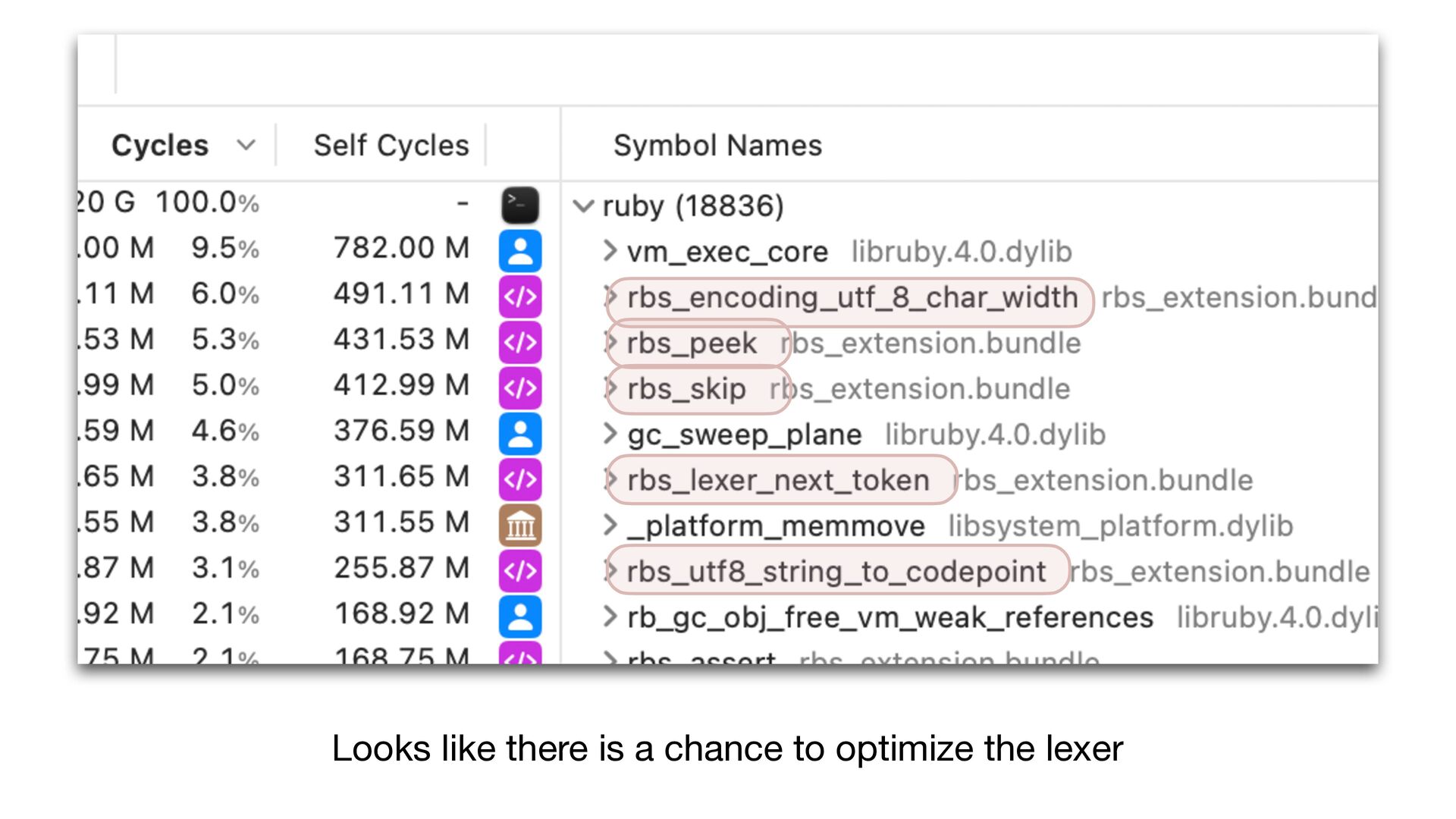
only a small portion of total tool execution time The new parser scans the input twice. It is inevitable. We could parallelize parsing for better performance if needed.
only a small portion of total tool execution time The new parser scans the input twice. It is inevitable. We could parallelize parsing for better performance if needed.
only a small portion of total tool execution time The new parser scans the input twice. It is inevitable. We could parallelize parsing for better performance if needed.
only a small portion of total tool execution time The new parser scans the input twice. It is inevitable. We could parallelize parsing for better performance if needed.
only a small portion of total tool execution time The new parser scans the input twice. It is inevitable. We could parallelize parsing for better performance if needed.
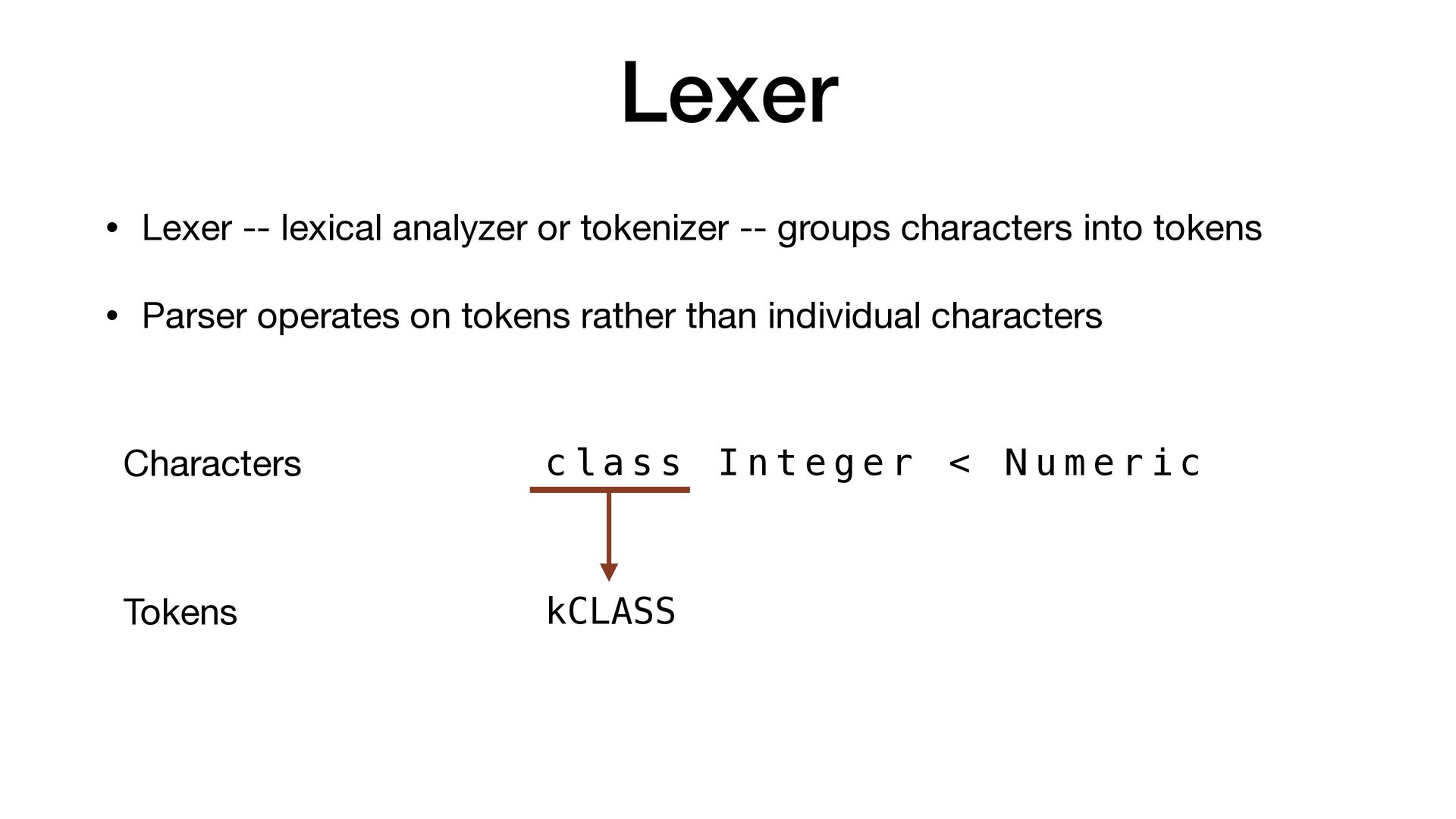
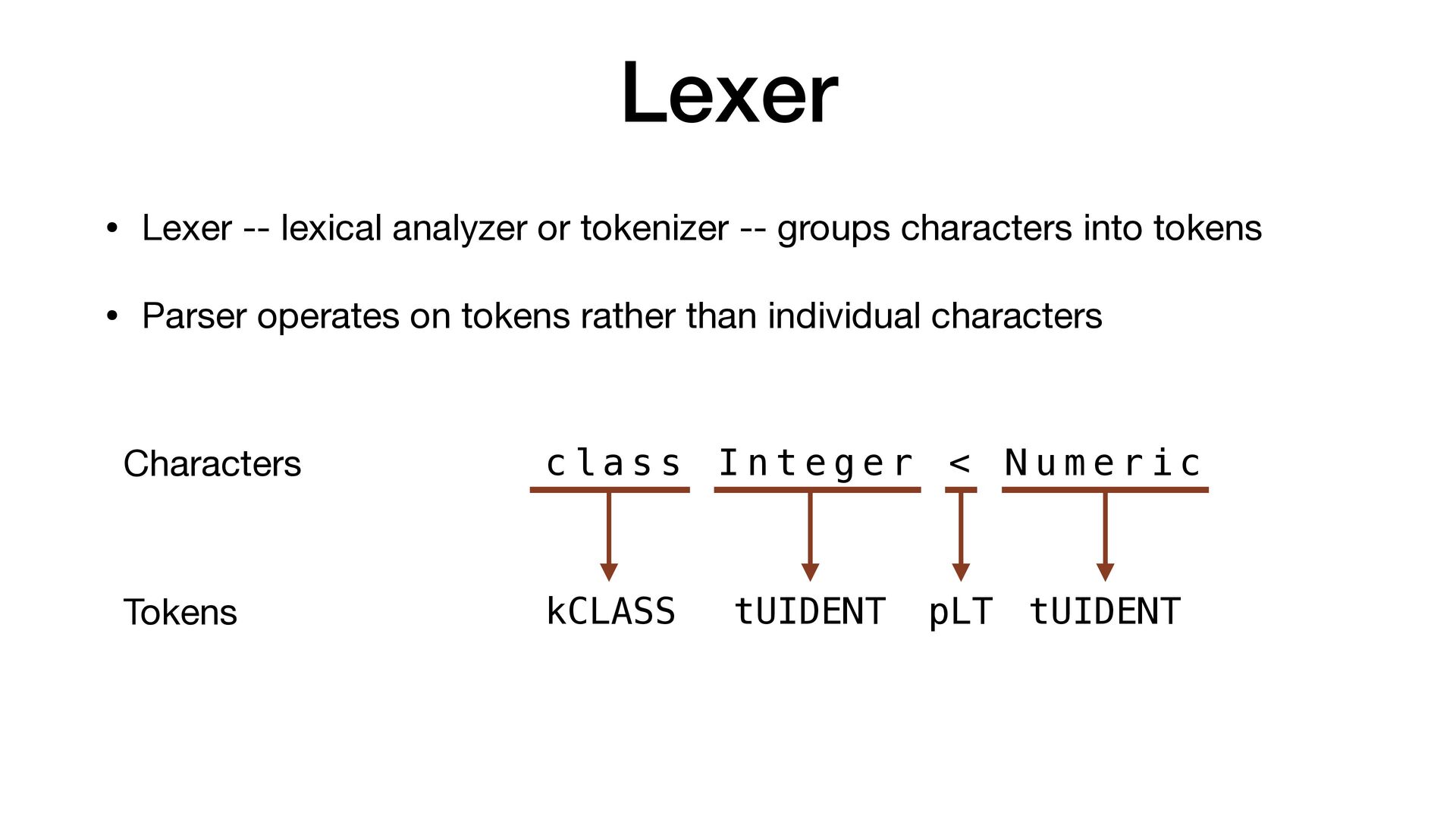
characters into tokens • Parser operates on tokens rather than individual characters c l a s s I n t e g e r < N u m e r i c Characters Tokens kCLASS tUIDENT
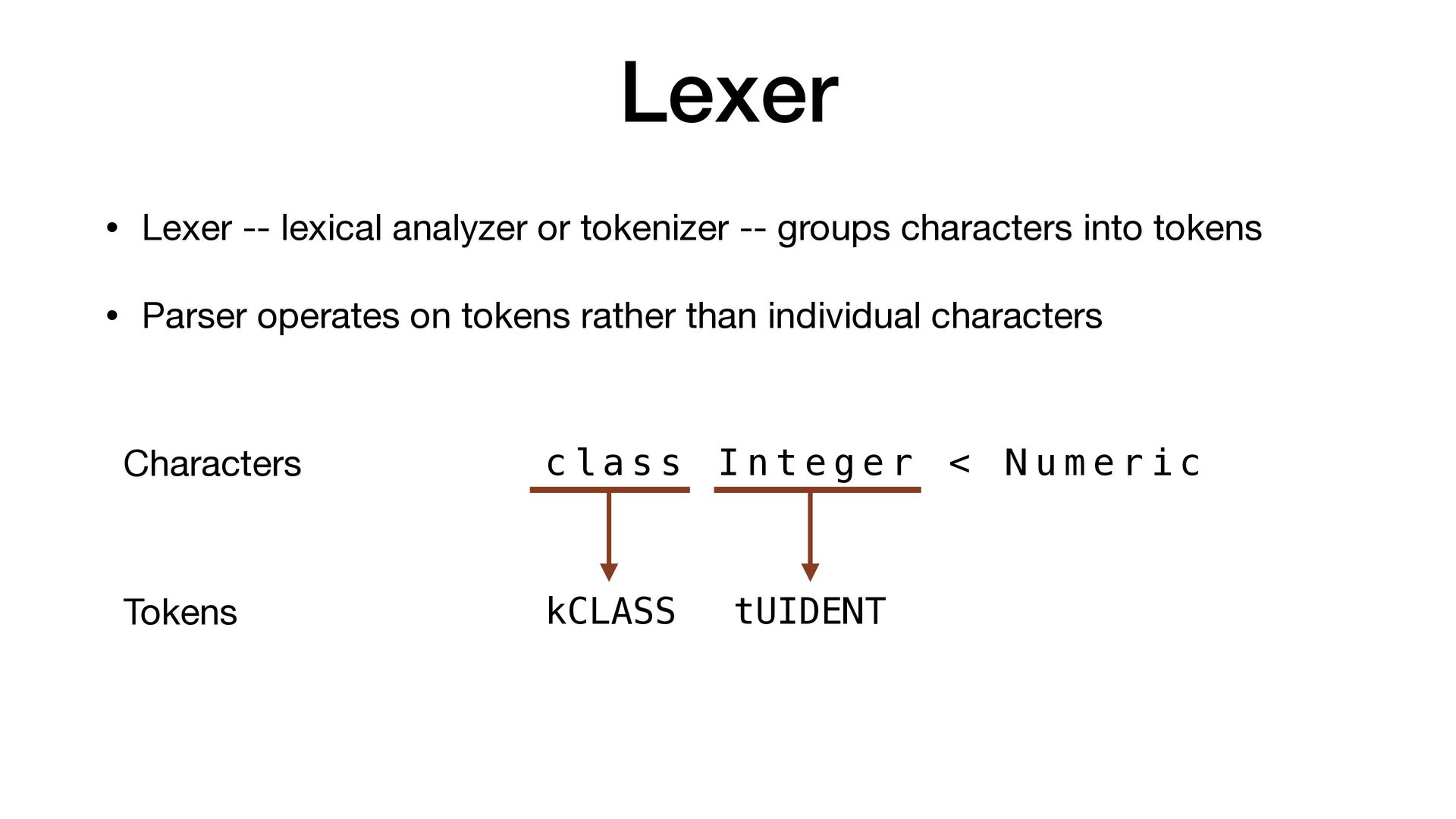
characters into tokens • Parser operates on tokens rather than individual characters c l a s s I n t e g e r < N u m e r i c Characters Tokens kCLASS tUIDENT pLT
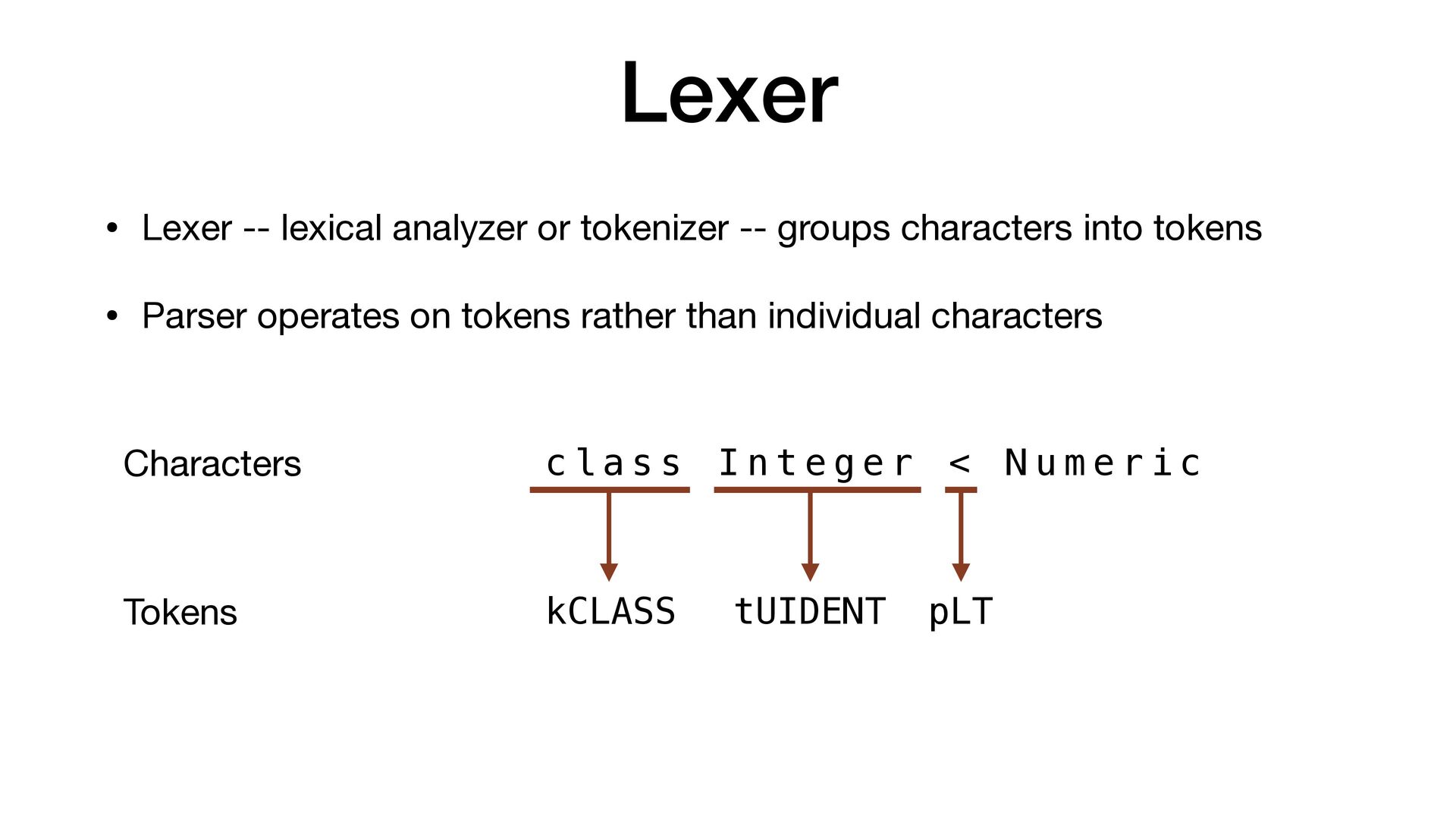
characters into tokens • Parser operates on tokens rather than individual characters c l a s s I n t e g e r < N u m e r i c Characters Tokens kCLASS tUIDENT pLT tUIDENT
fi cation of encoding of RBS source text • De fi ne an encoding spec 💪 • Follow Ruby's spec • It supports multi-byte encoding, but they must be ASCII compatible • UTF-8, SJIS, EUC-JP are fi ne, UTF-16 and UTF-32 are not
"ϧϏʔ" type language = "ϥετ" # ू߹Λදݱ͢ΔΫϥε class Set[T] end # ϧϧϧϧϧϧϧϧϧϧ class Set[T] end Only comments and string literal types allow non-ASCII characters
returning any Unicode codepoint works • If it's a single-byte character, it's an ASCII character • The actual comment/string content can be fetched from the bu ff er
returning any Unicode codepoint works • If it's a single-byte character, it's an ASCII character • The actual comment/string content can be fetched from the bu ff er
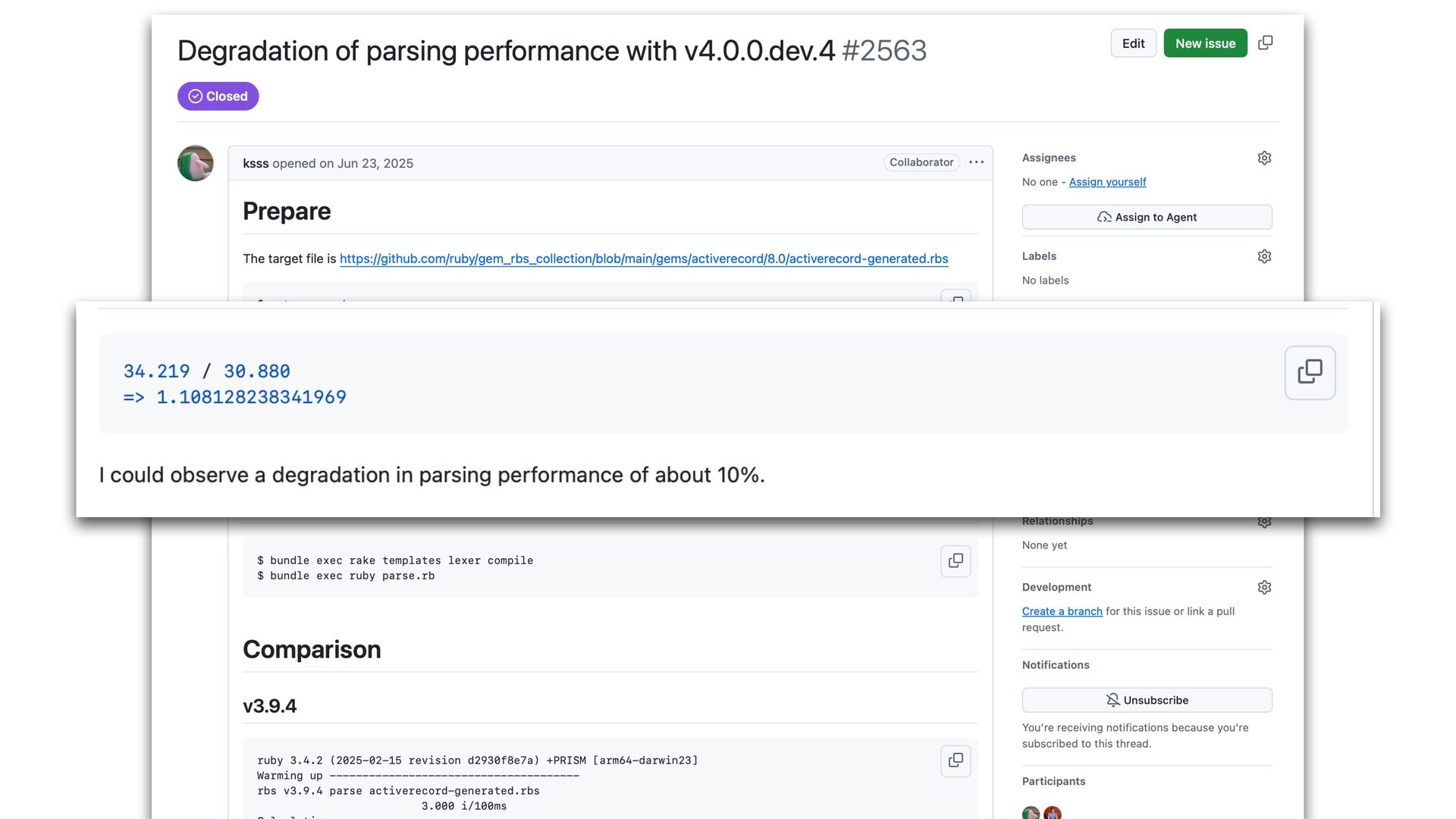
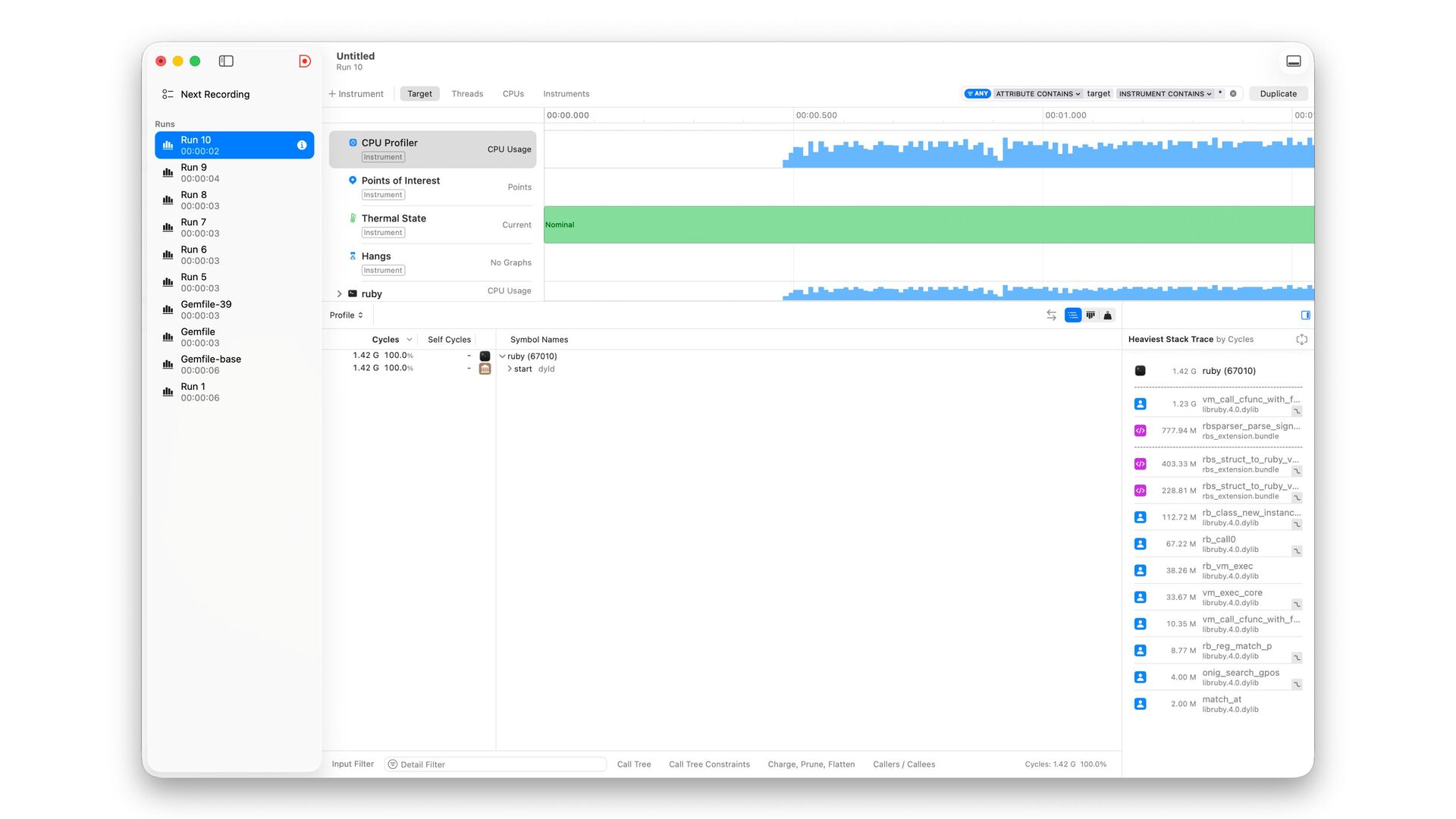
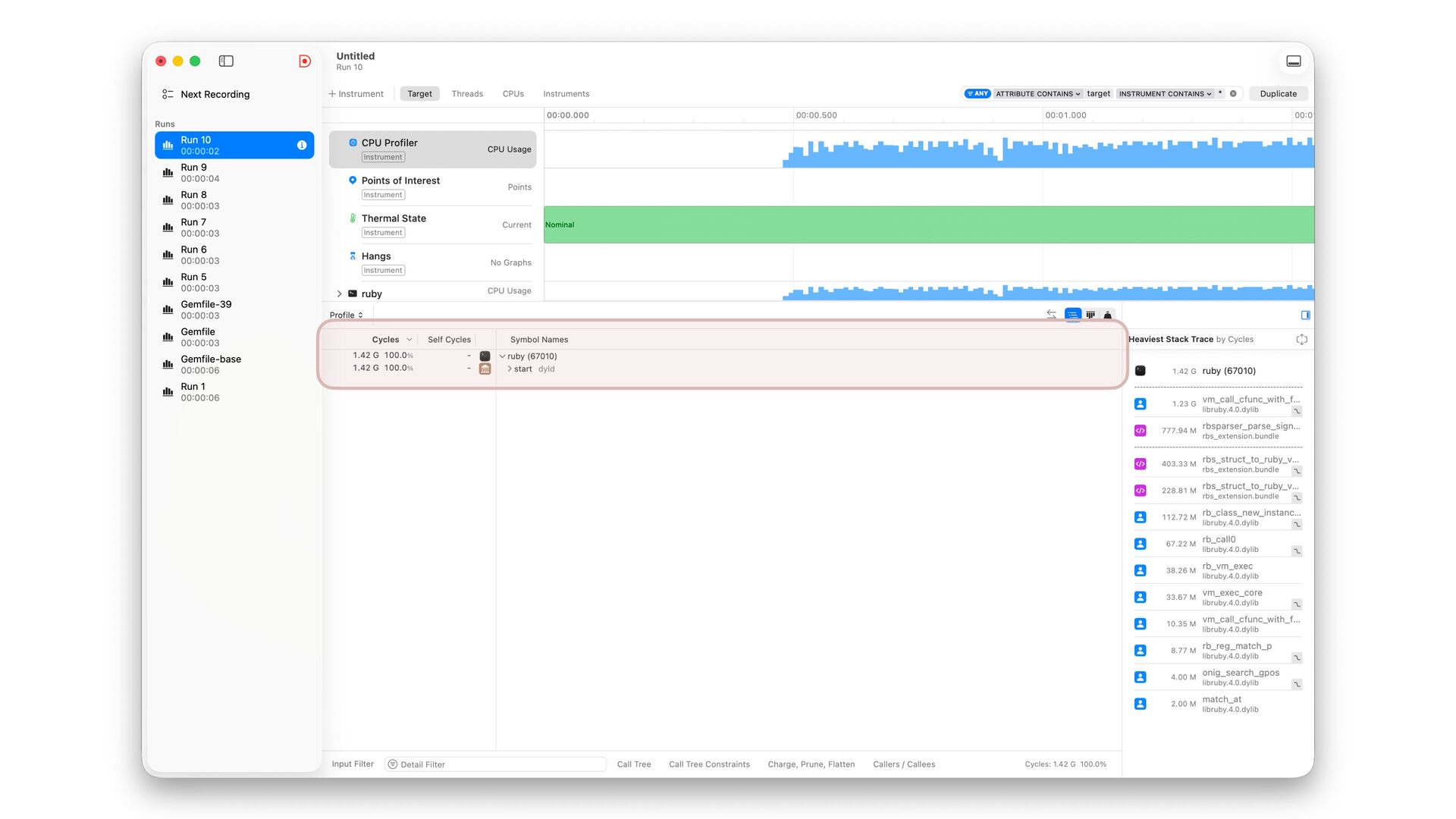
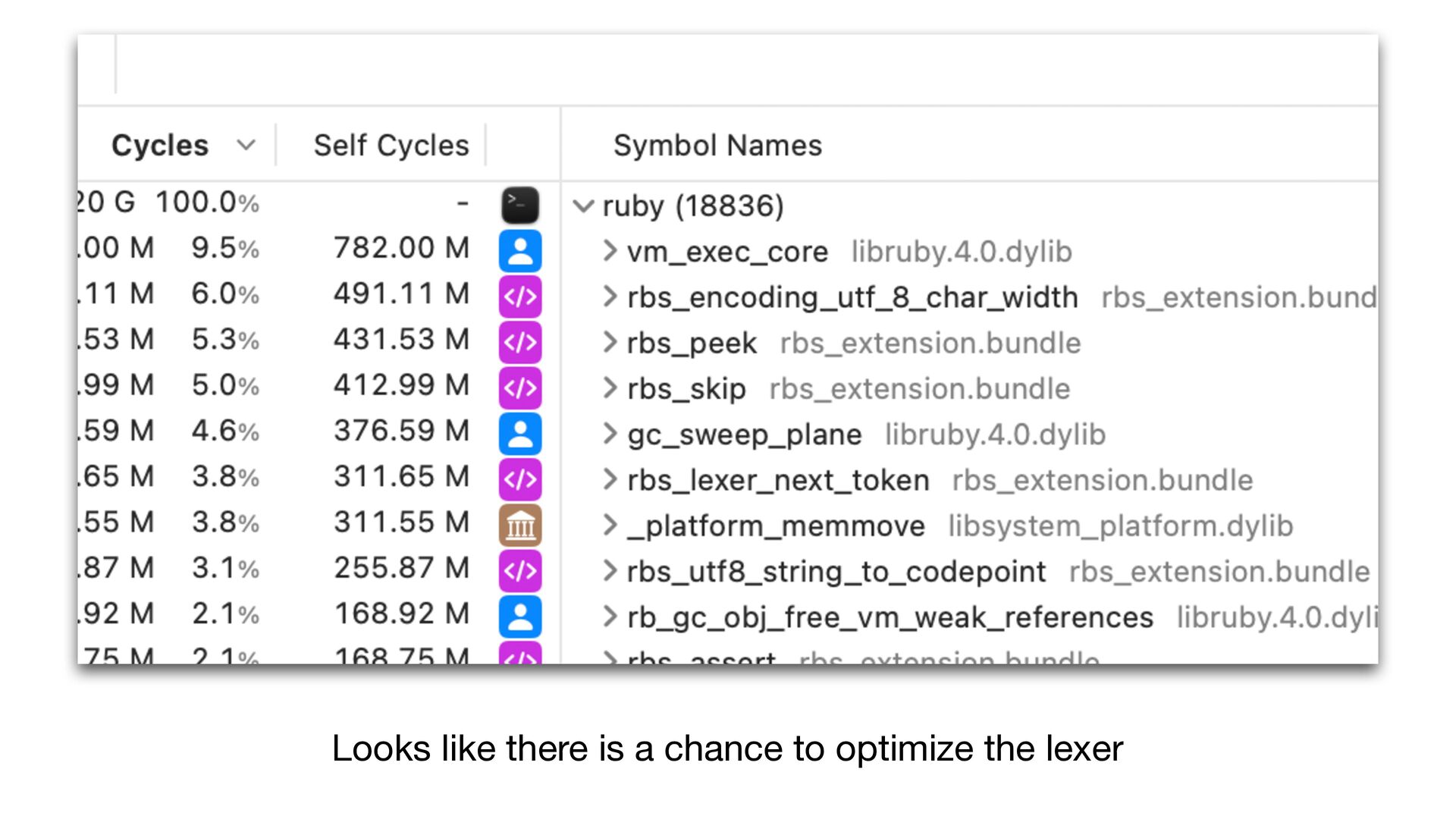
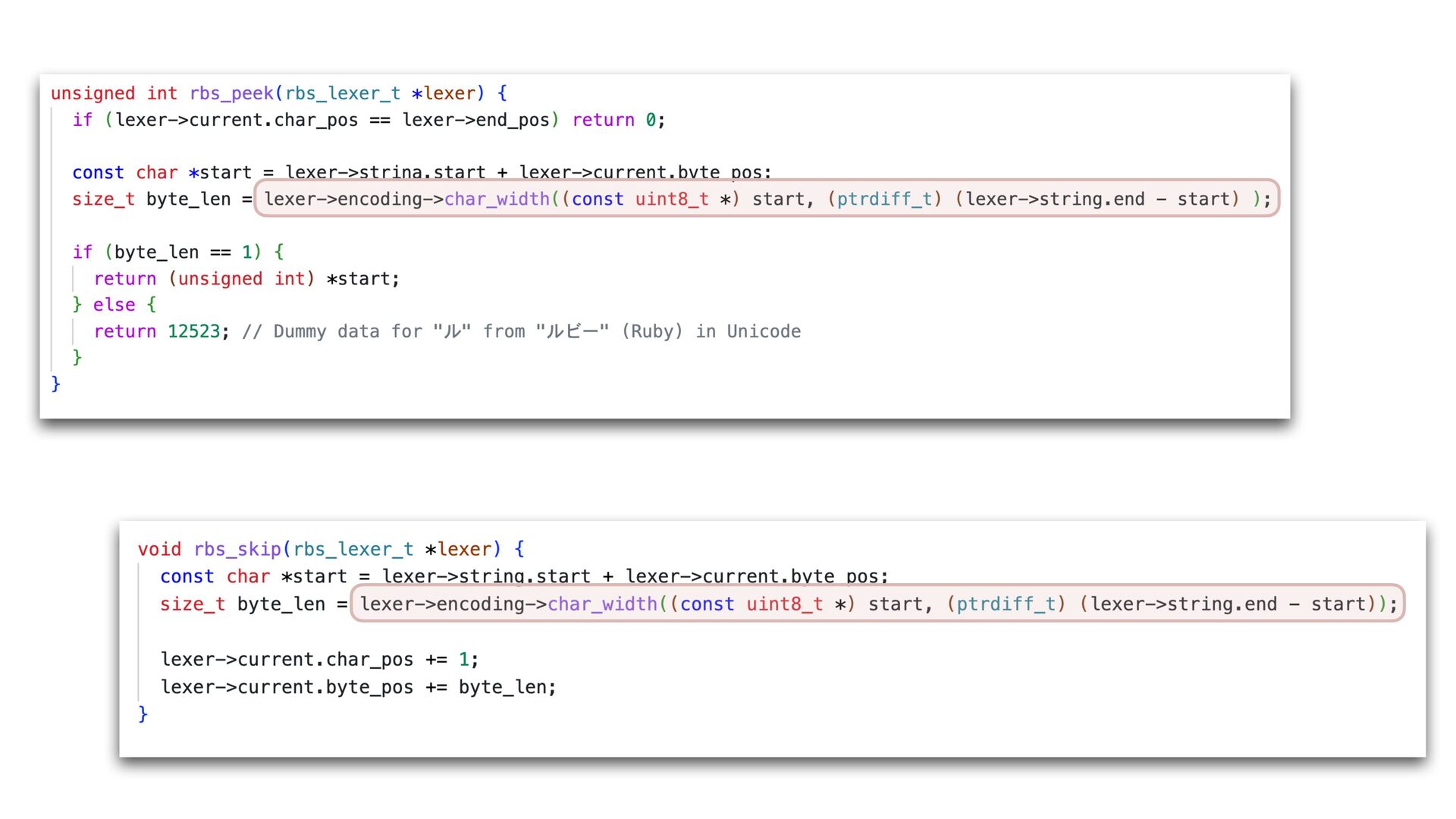
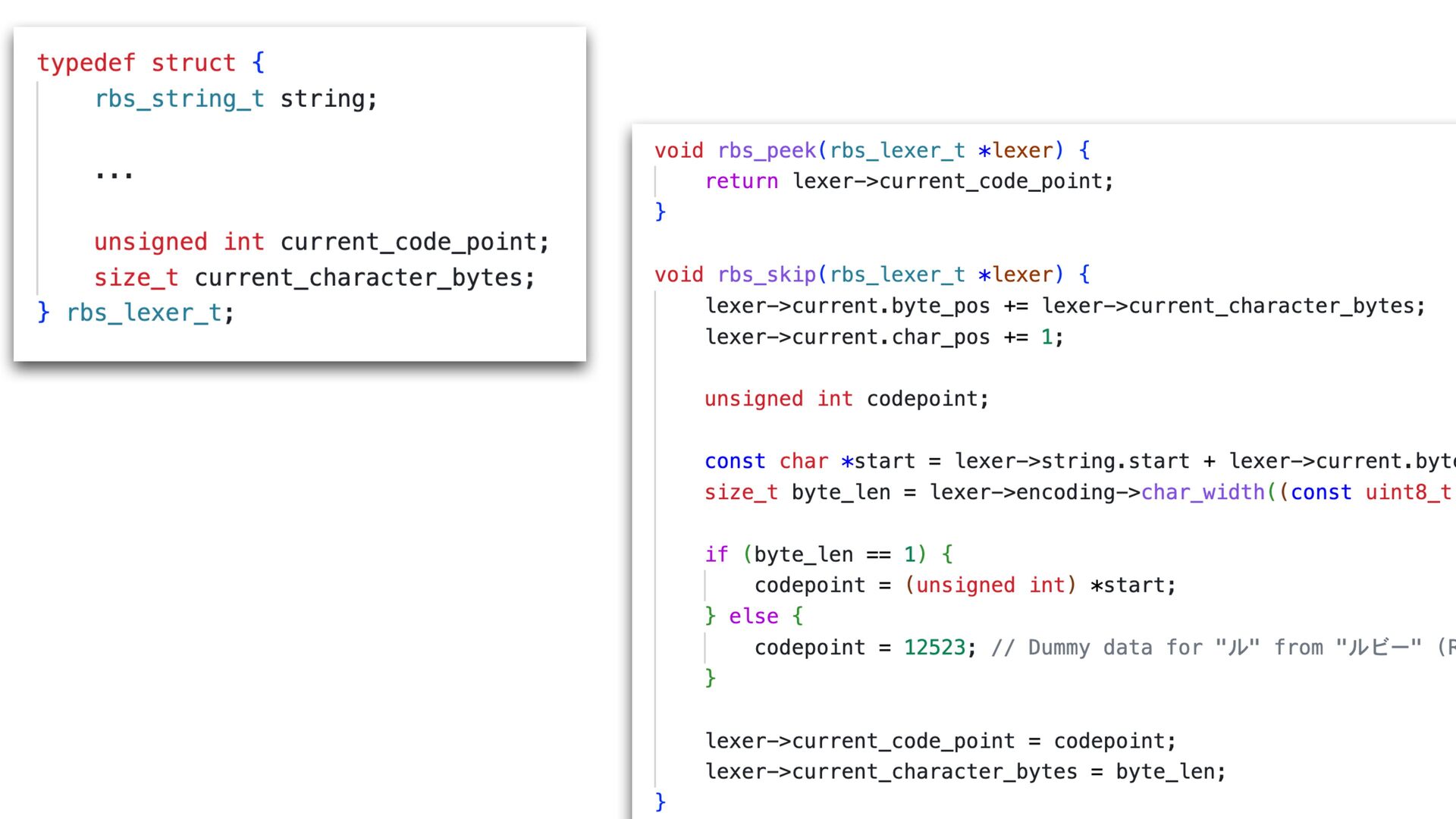
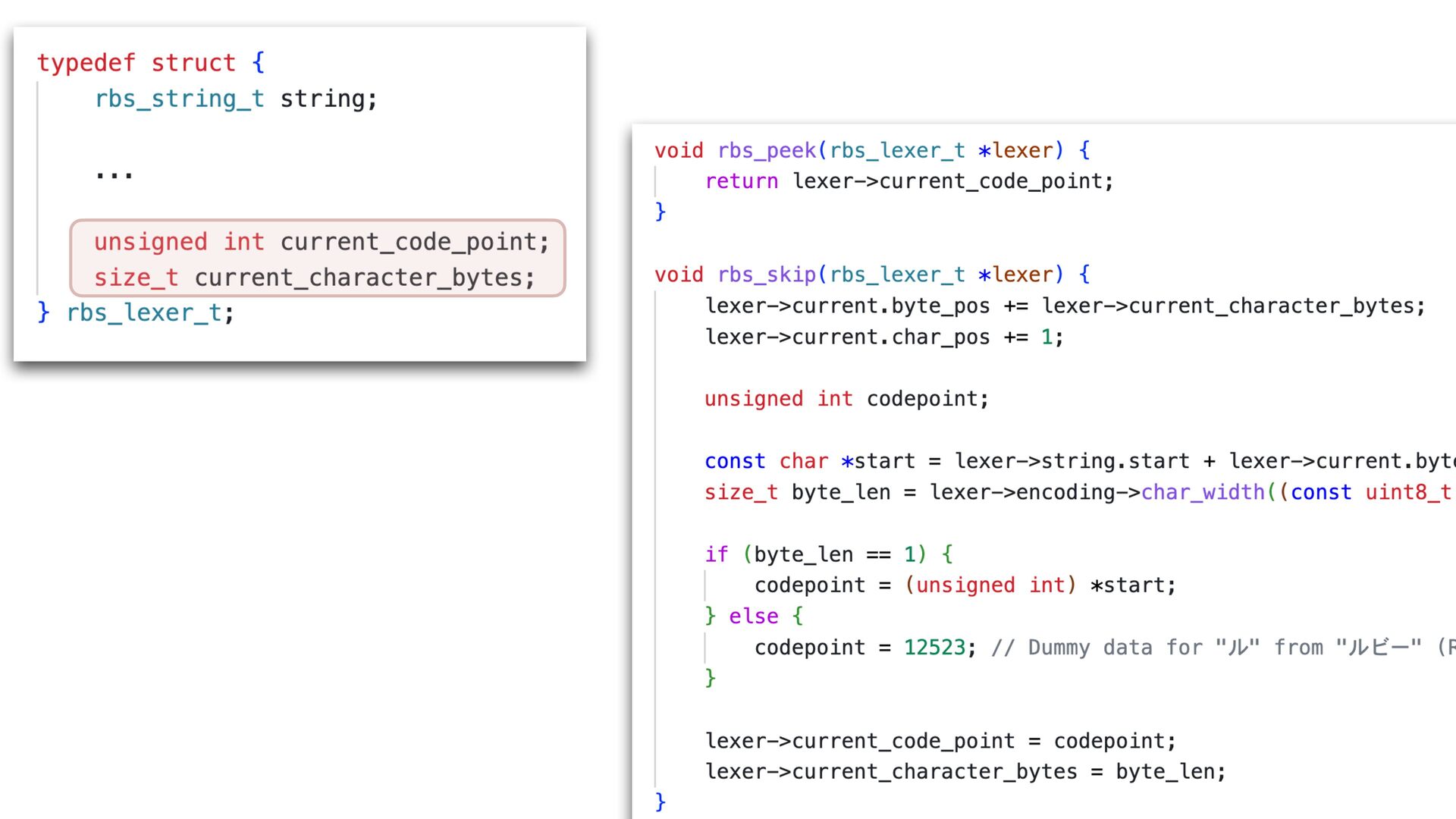
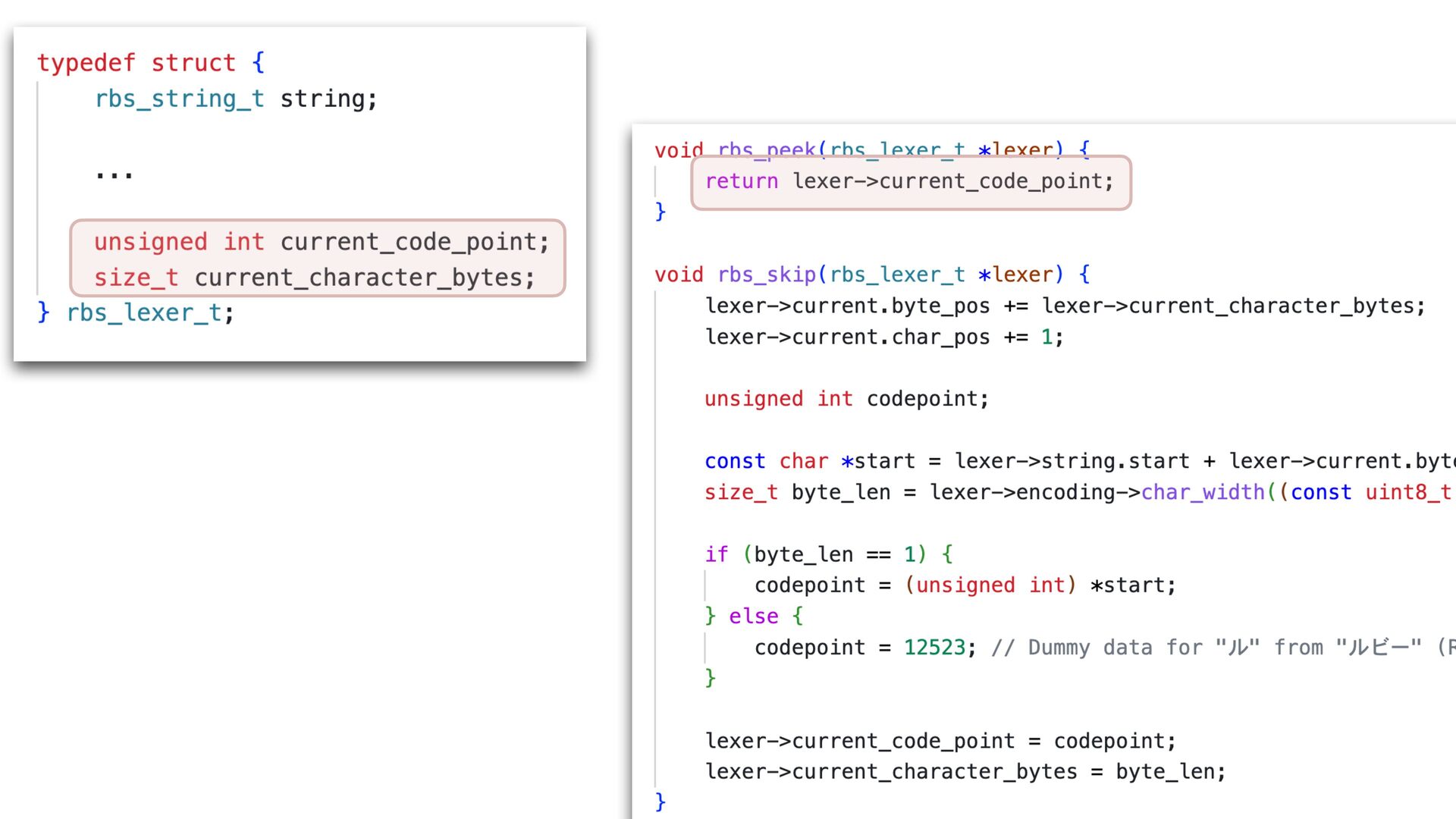
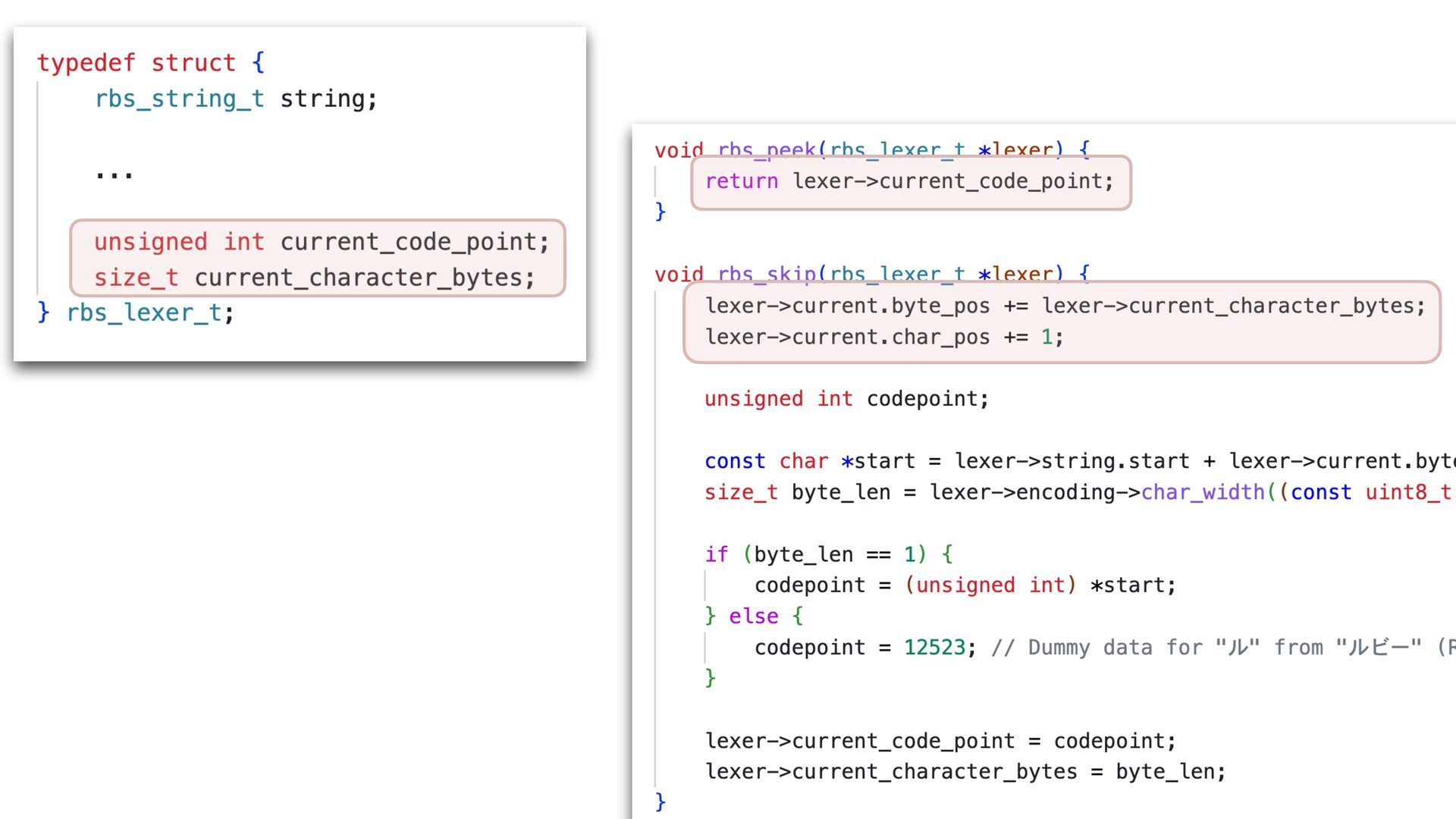
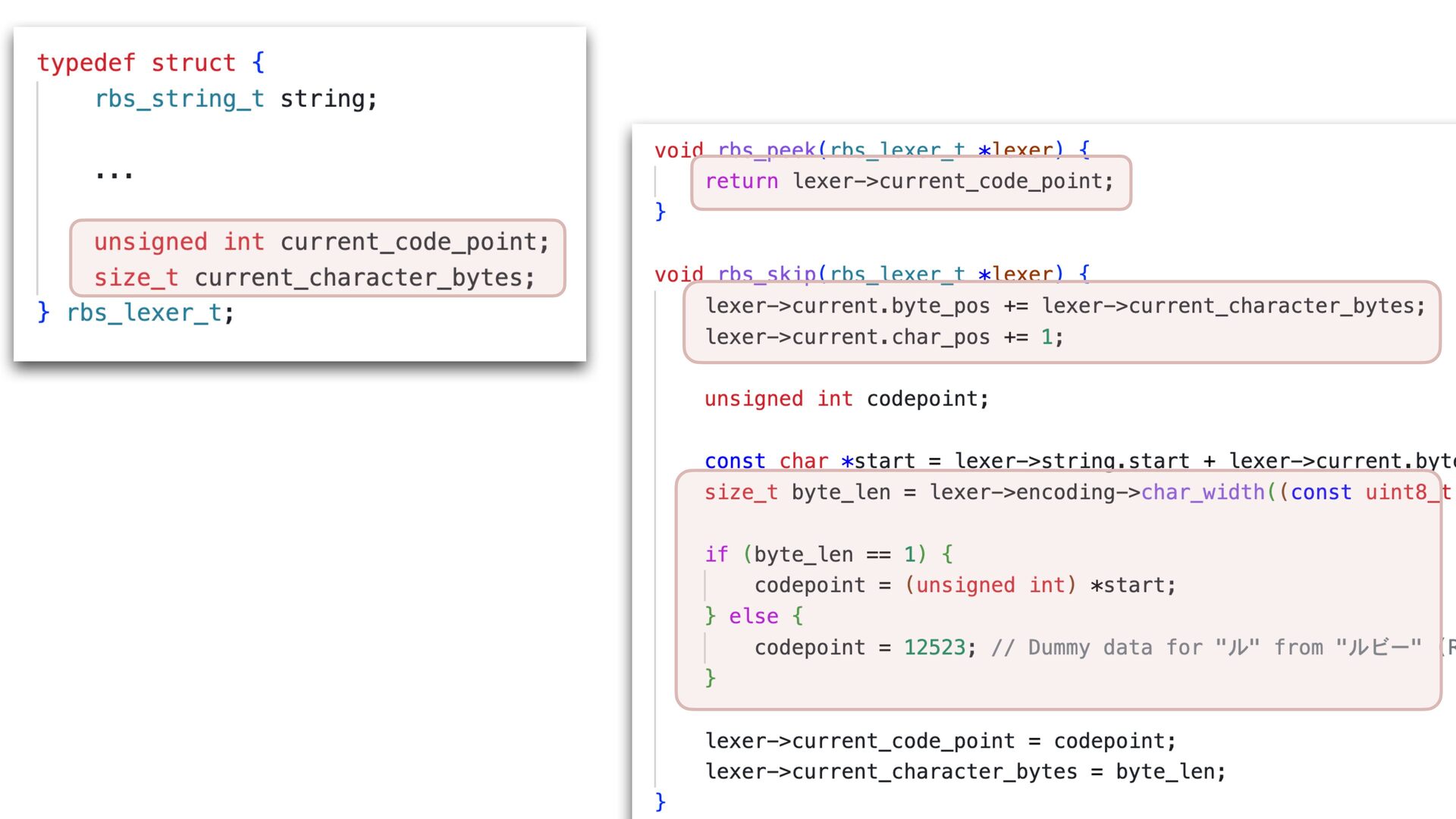
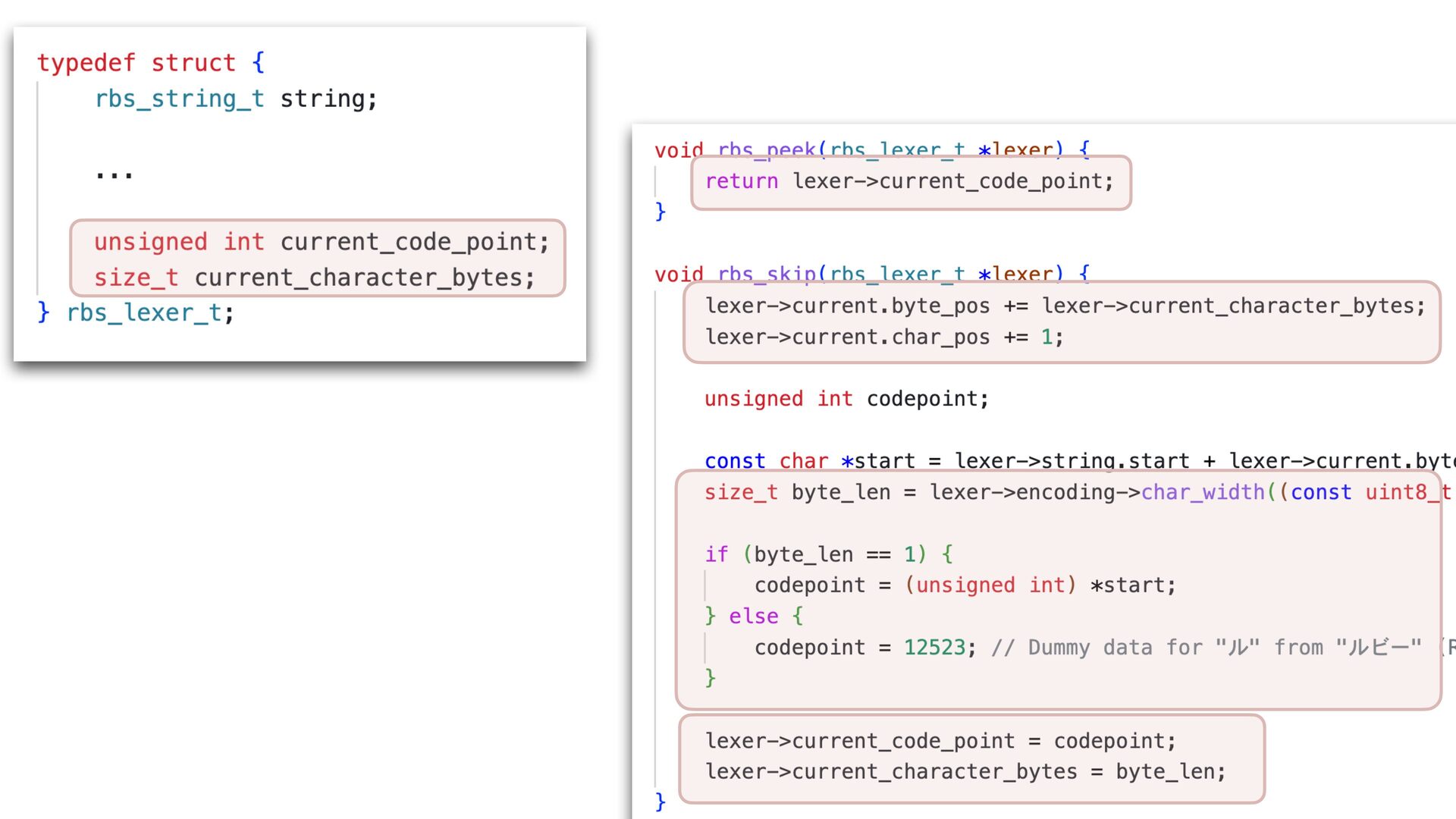
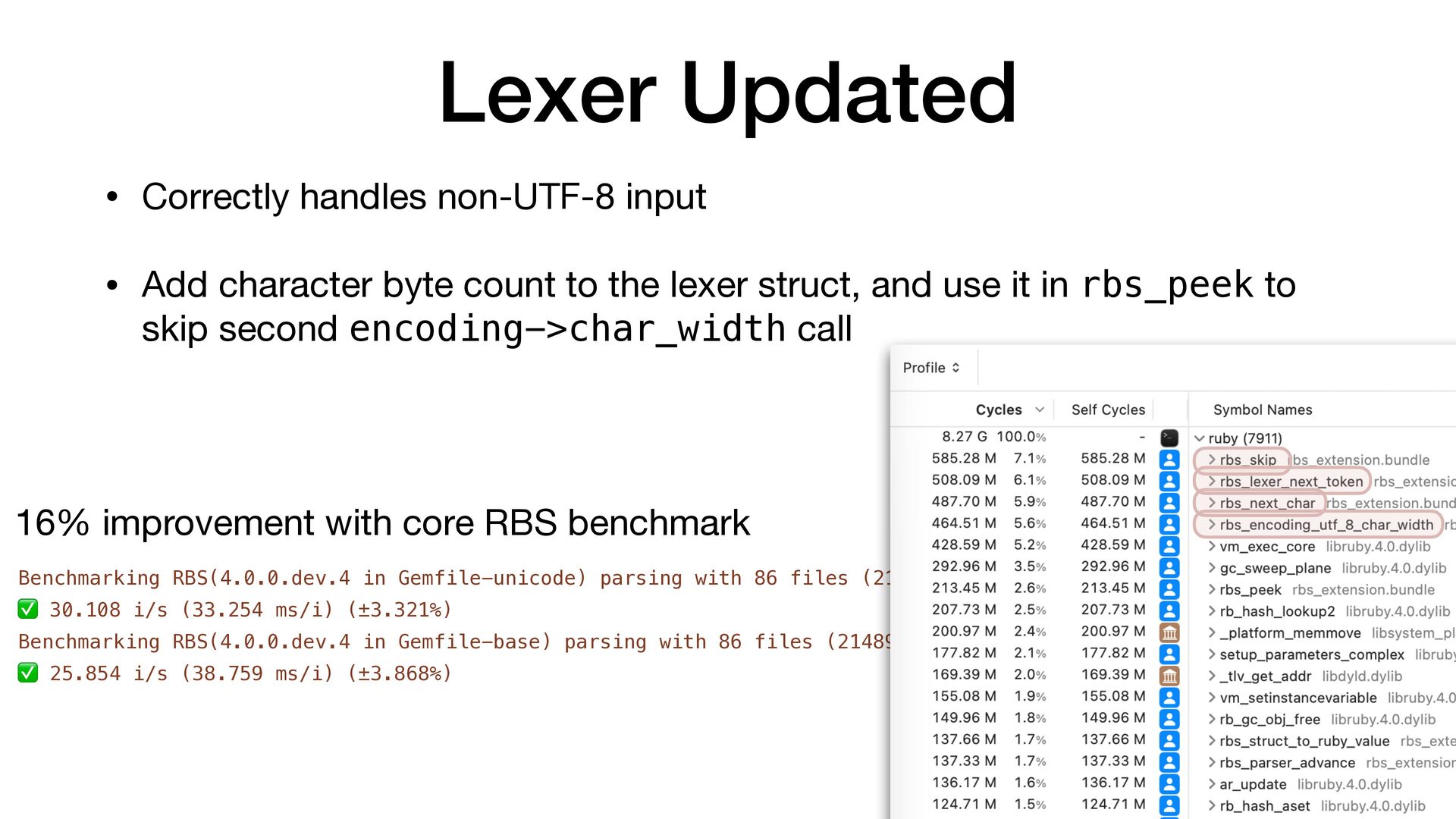
✅ 30.108 i/s (33.254 ms/i) (±3.321%) Benchmarking RBS(4.0.0.dev.4 in Gemfile-base) parsing with 86 files (2148952 bytes)... ✅ 25.854 i/s (38.759 ms/i) (±3.868%) Lexer Updated • Correctly handles non-UTF-8 input • Add character byte count to the lexer struct, and use it in rbs_peek to skip second encoding->char_width call 16% improvement with core RBS benchmark
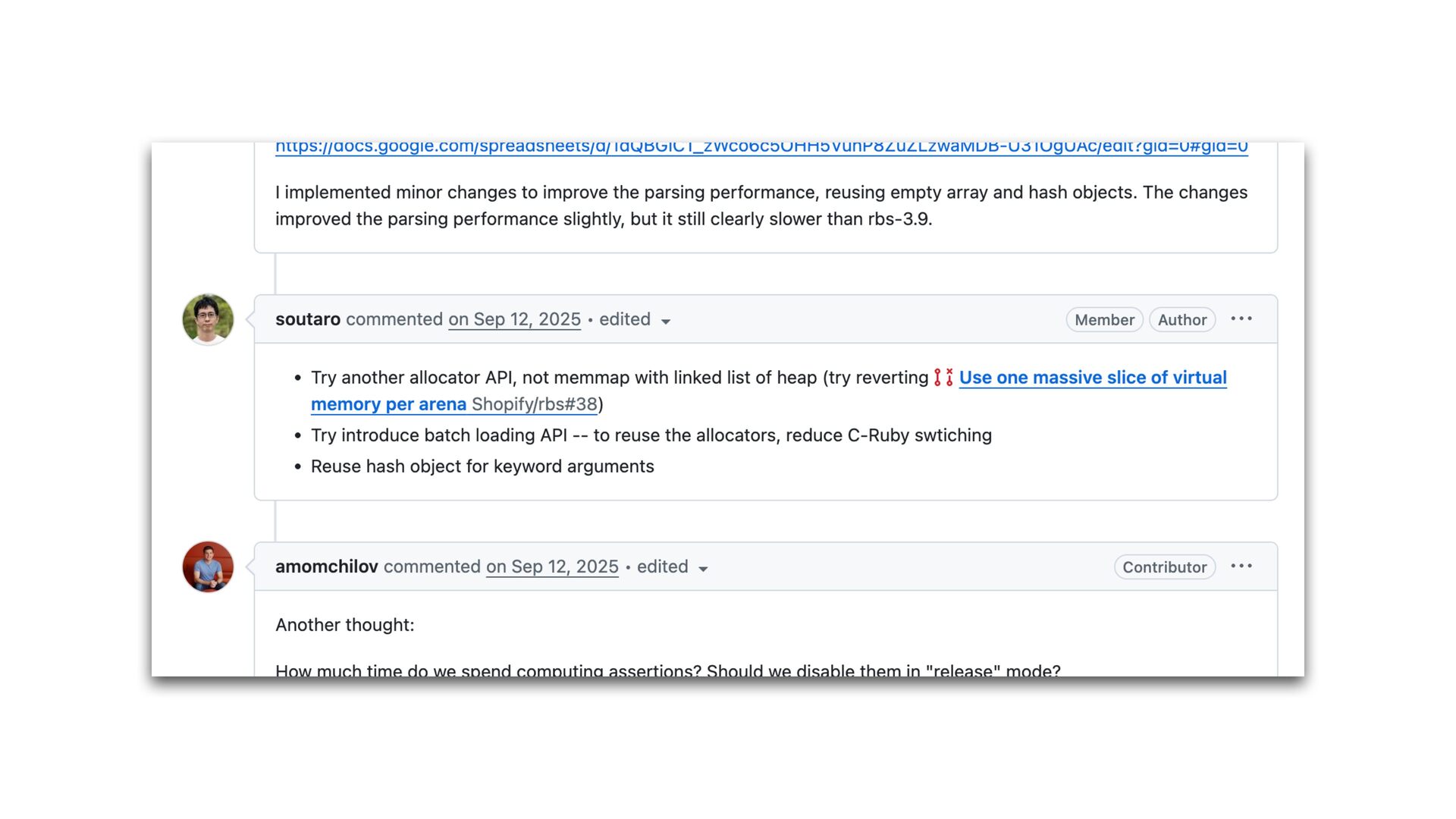
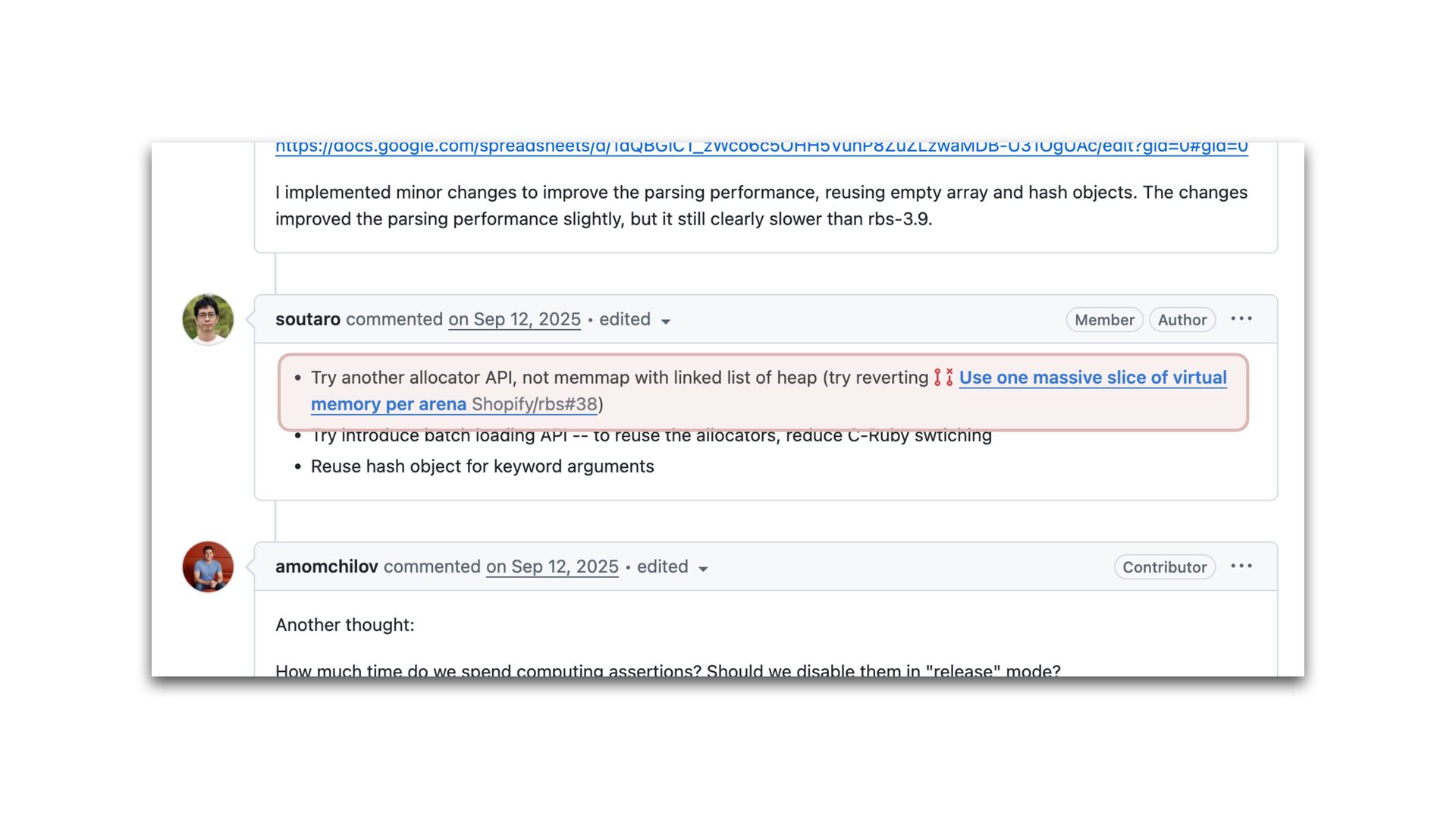
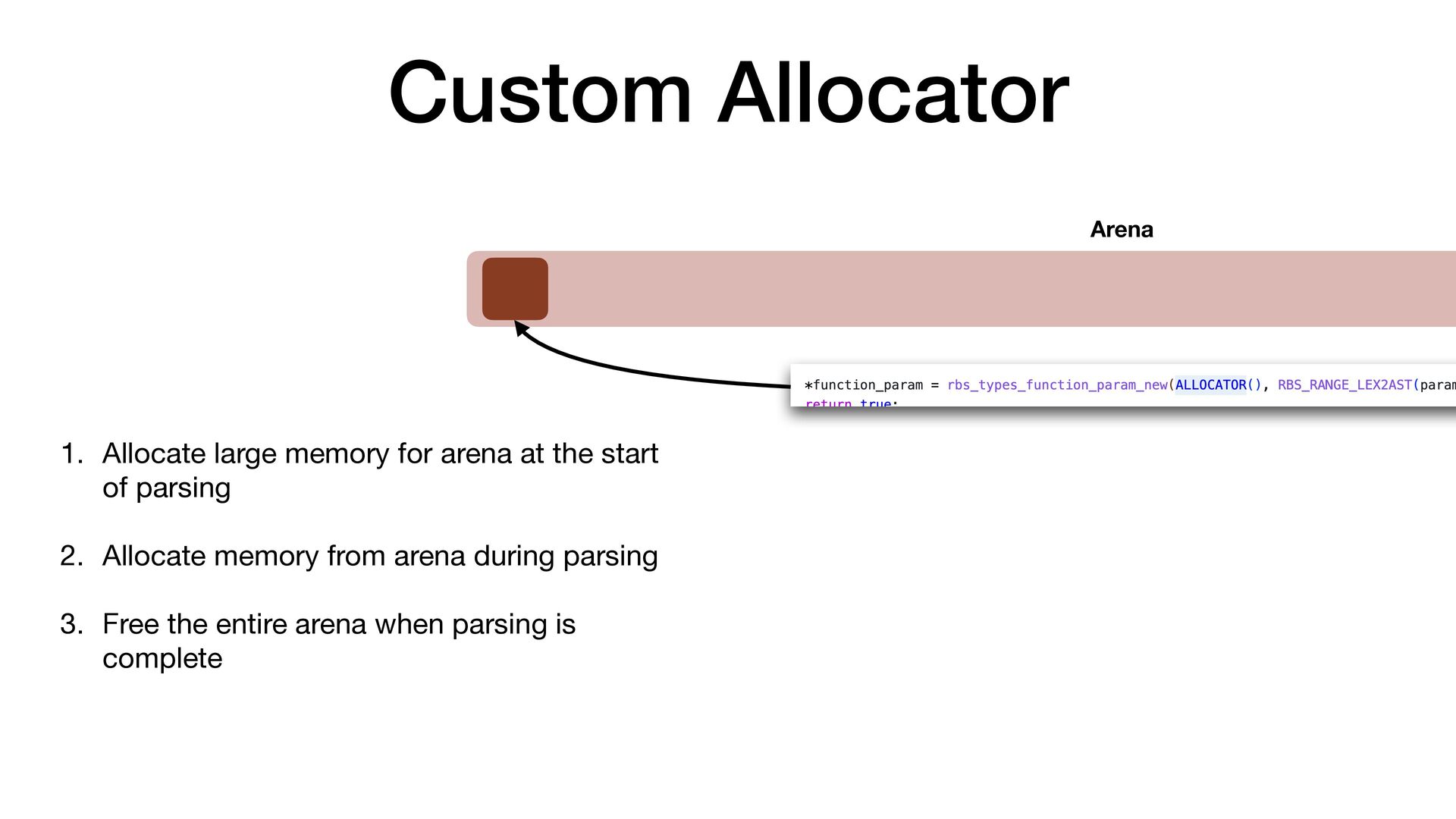
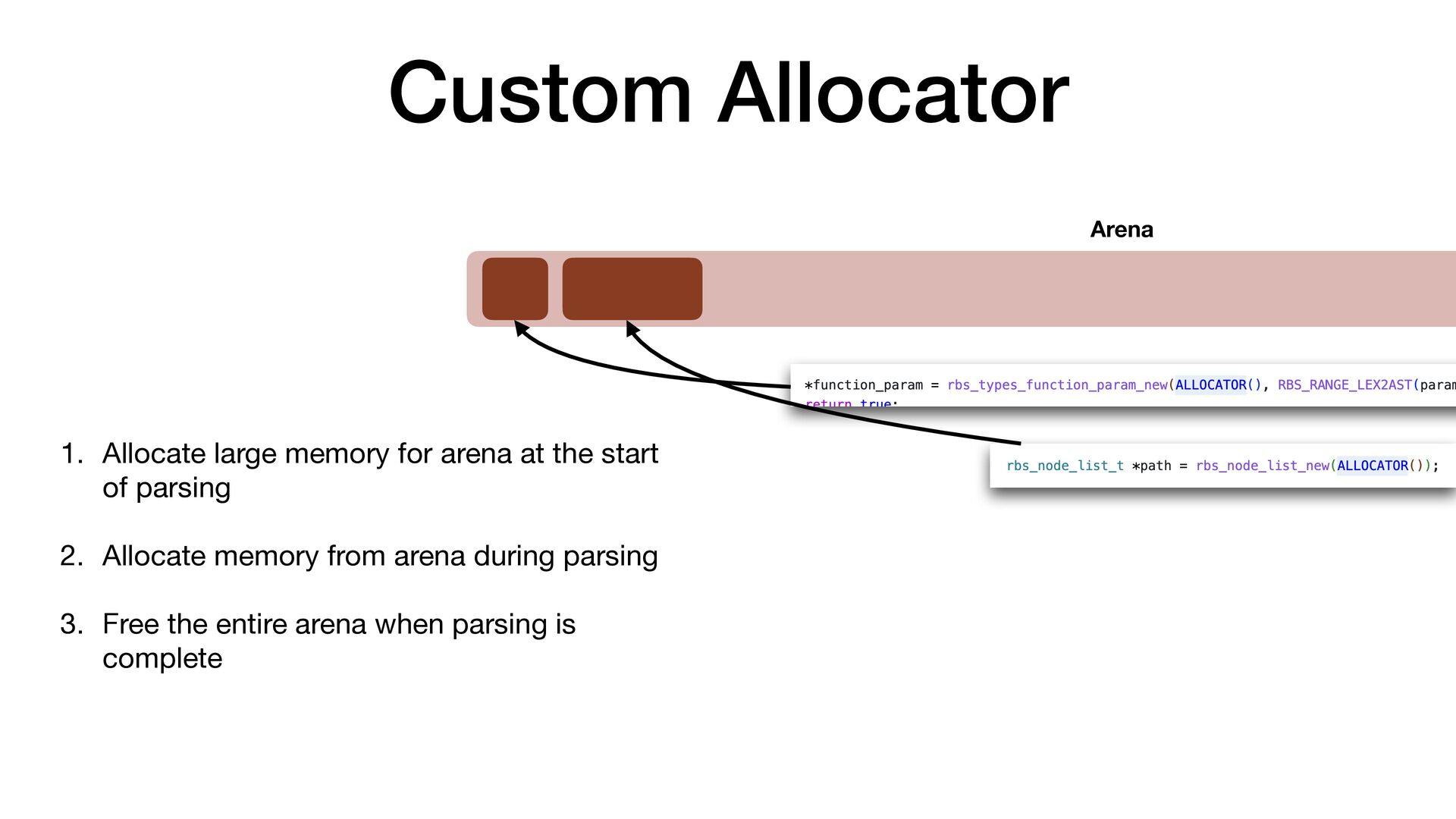
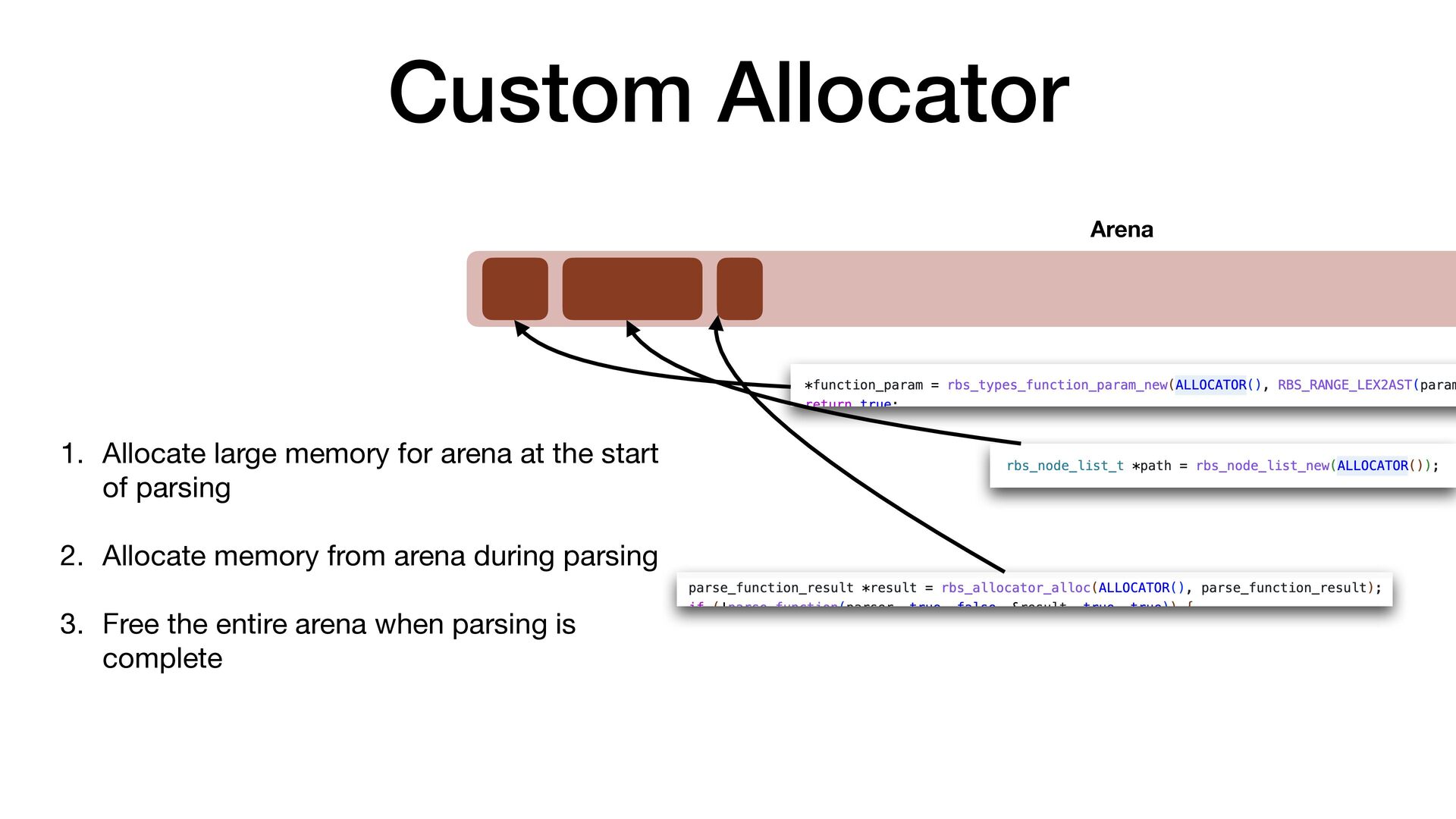
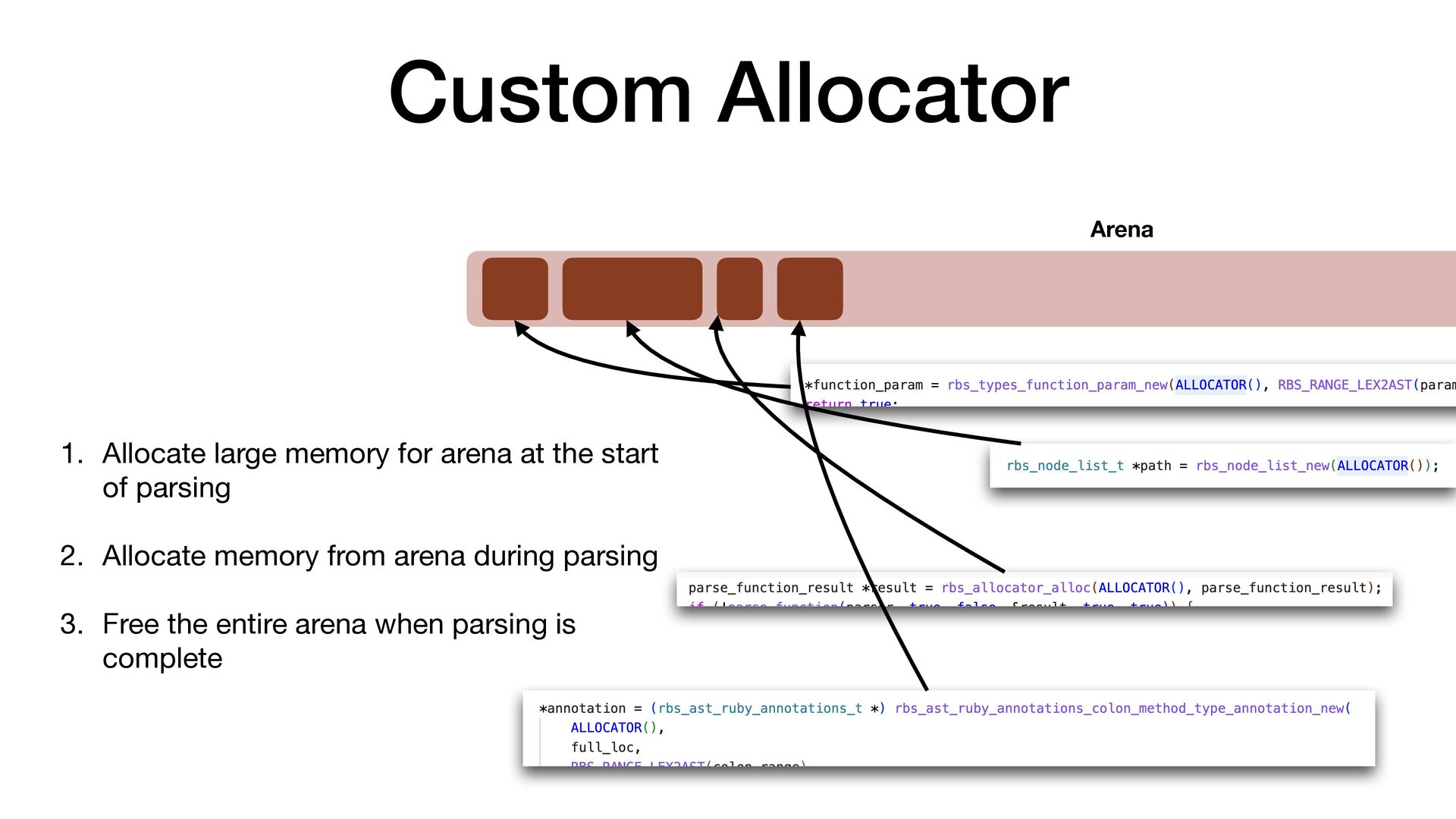
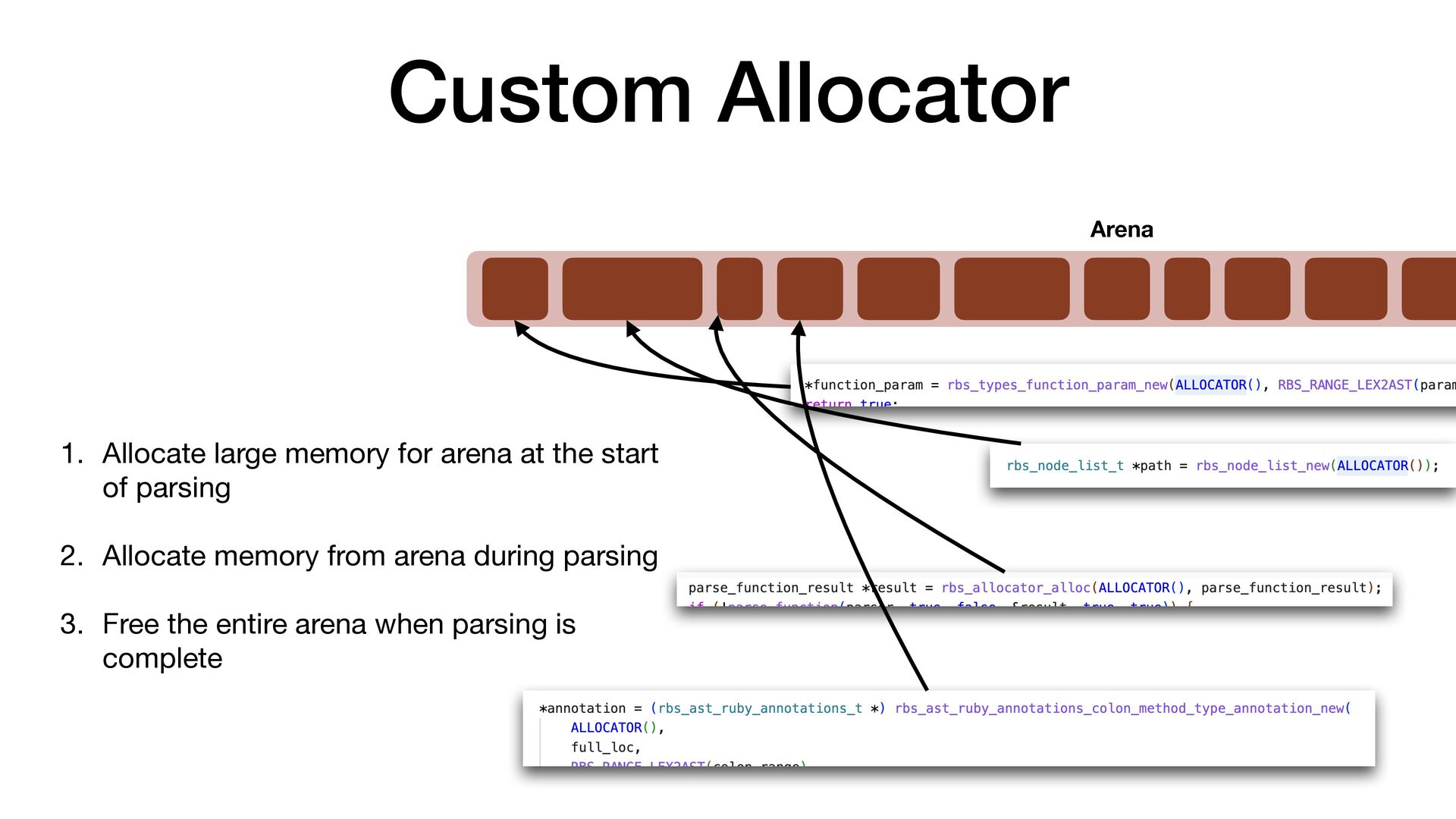
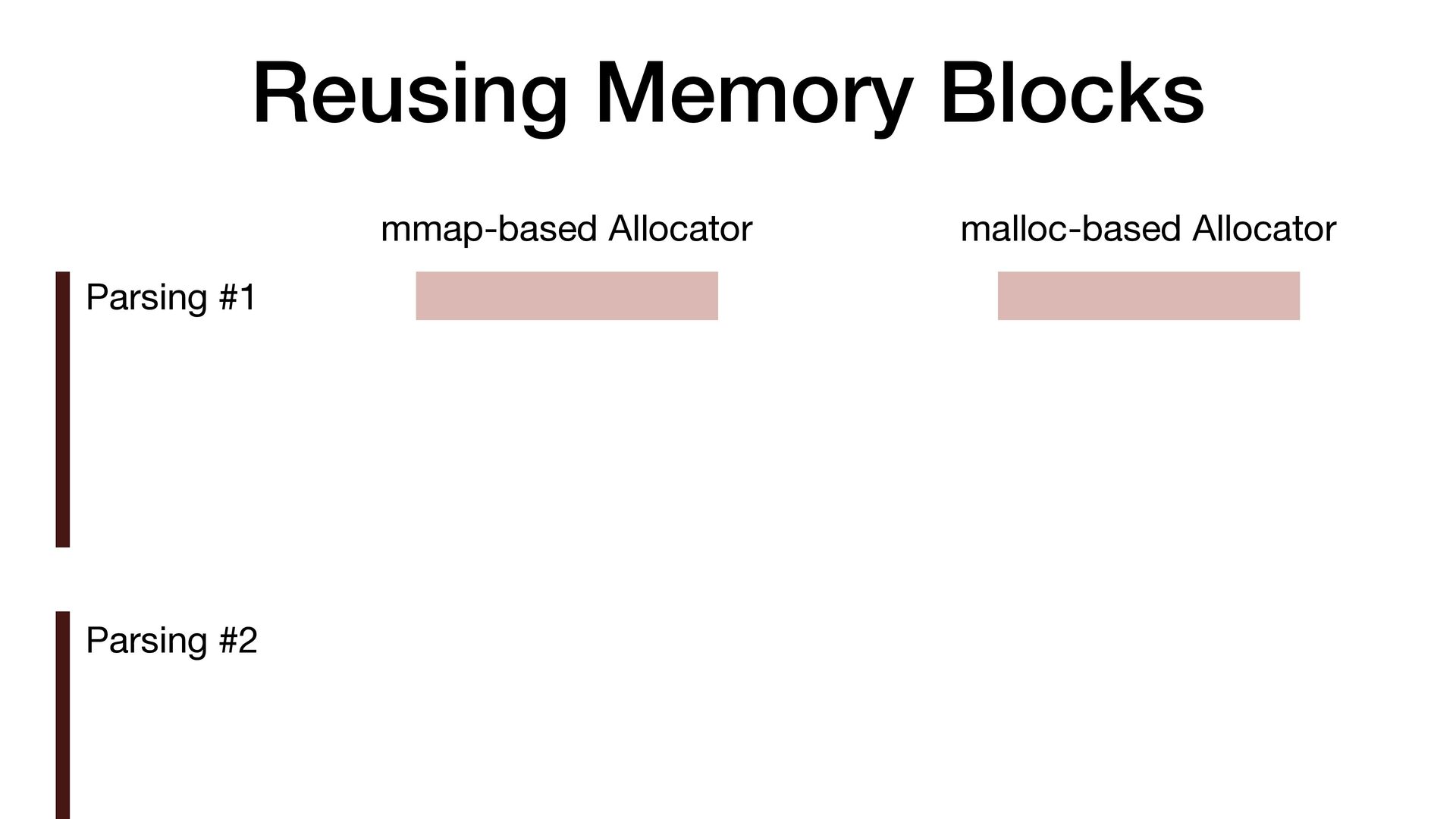
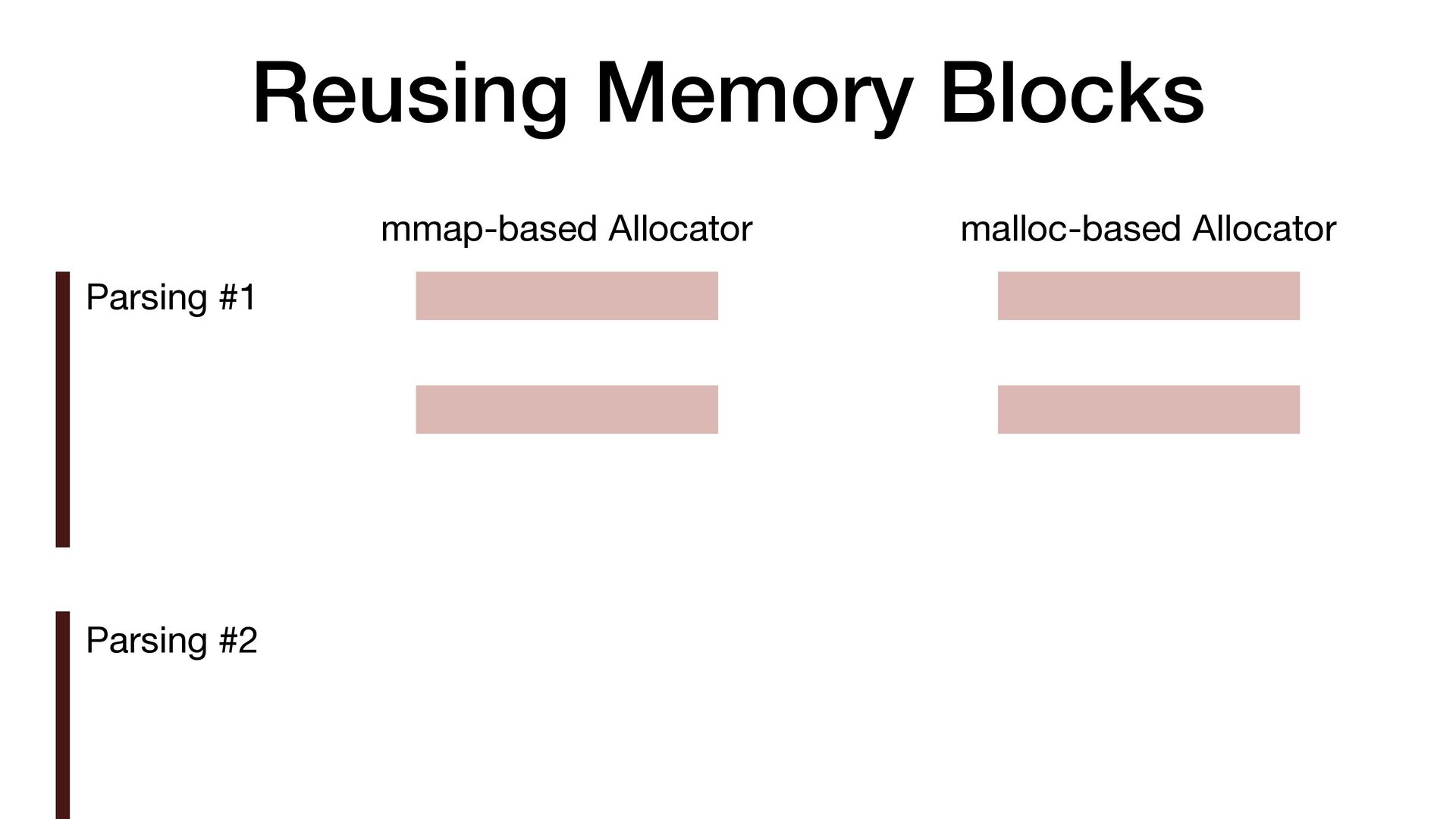
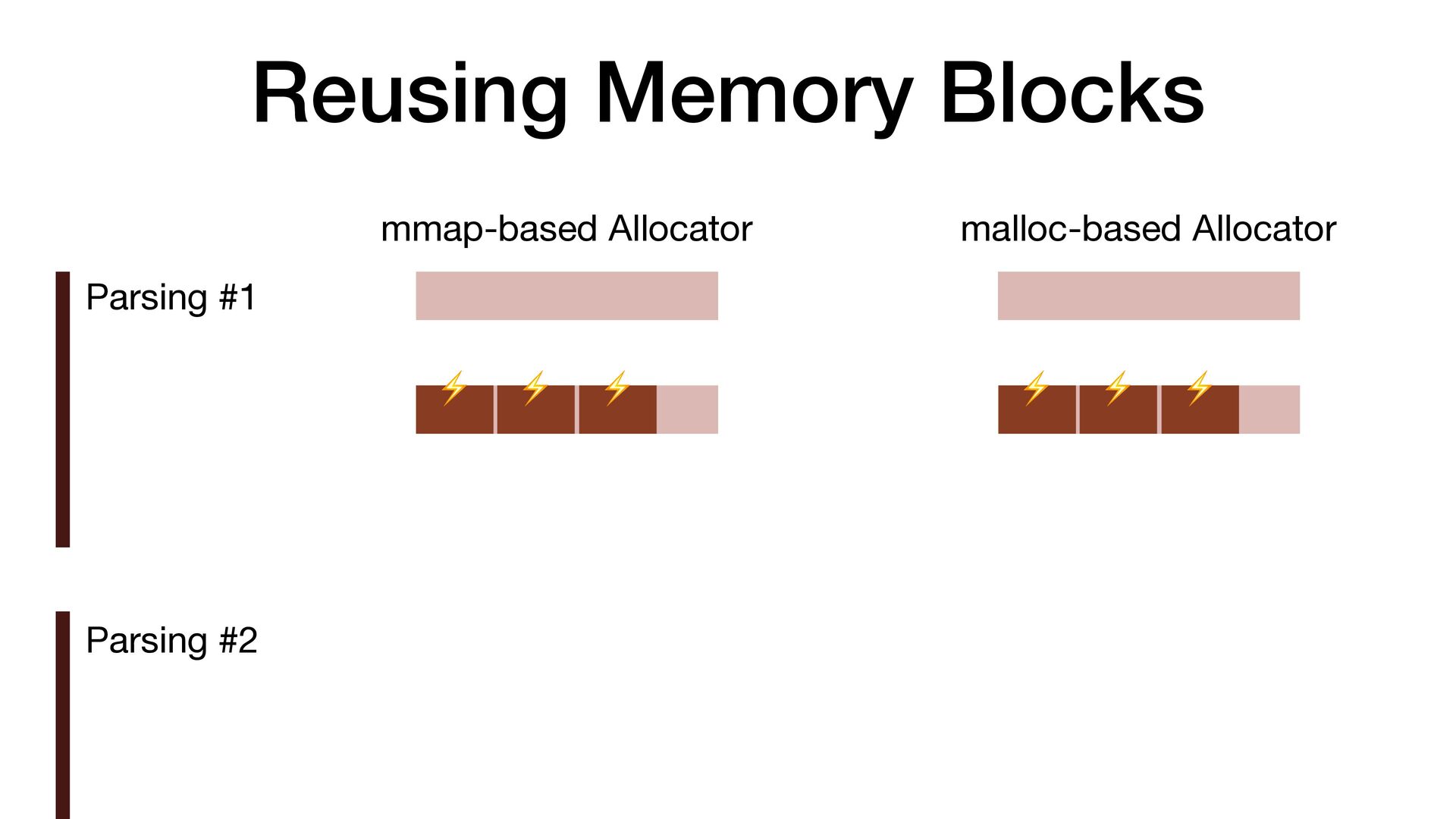
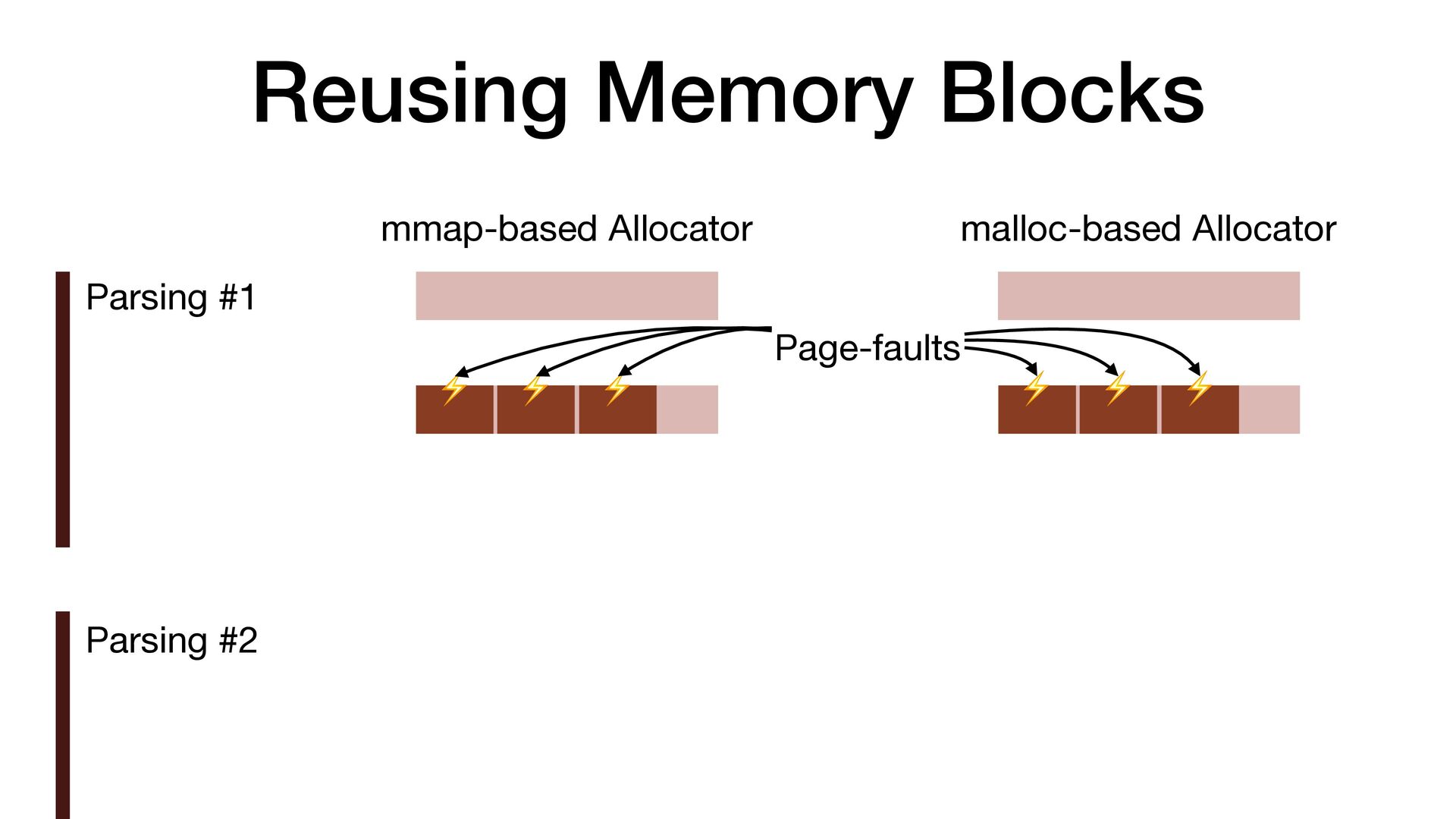
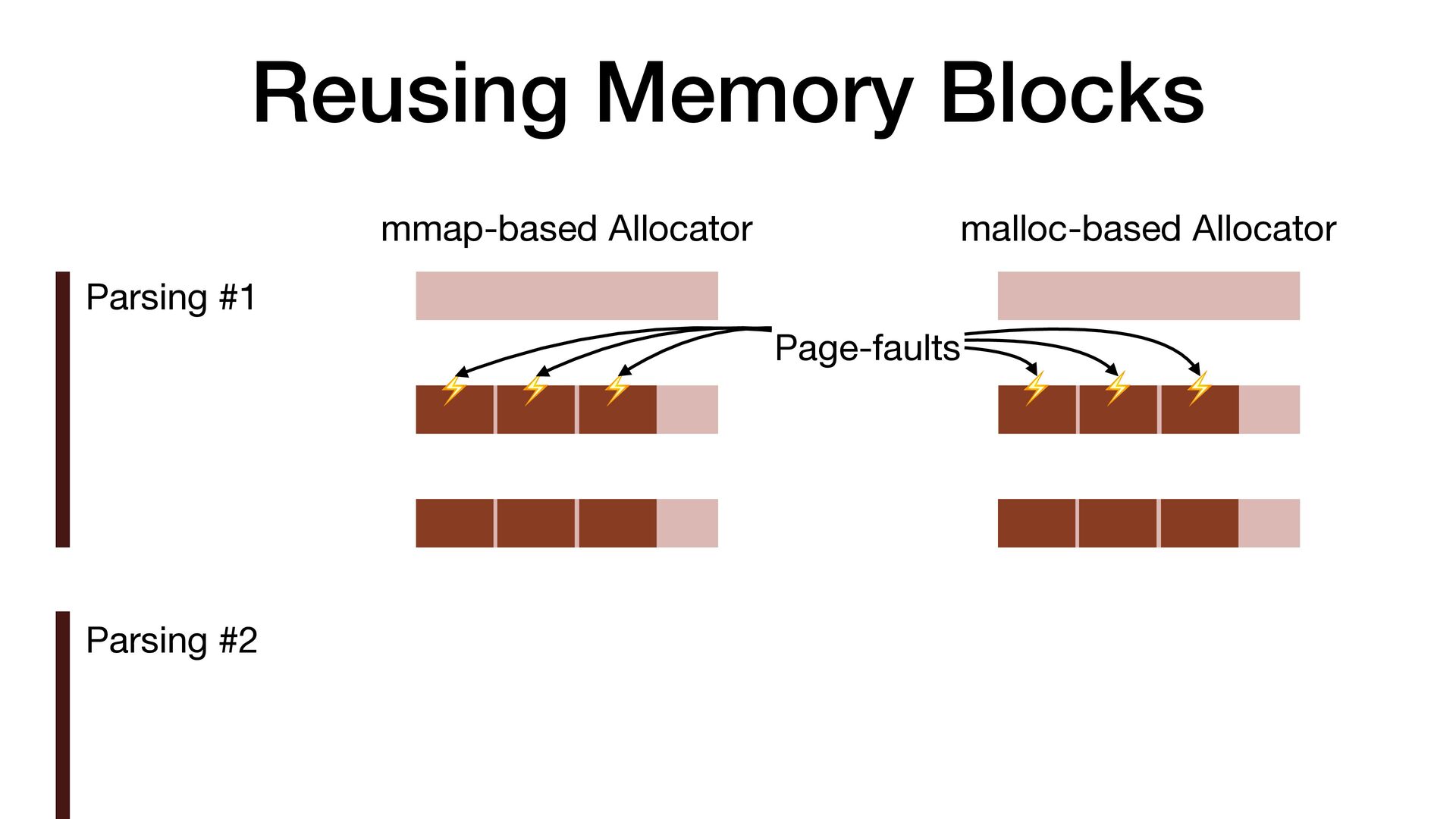
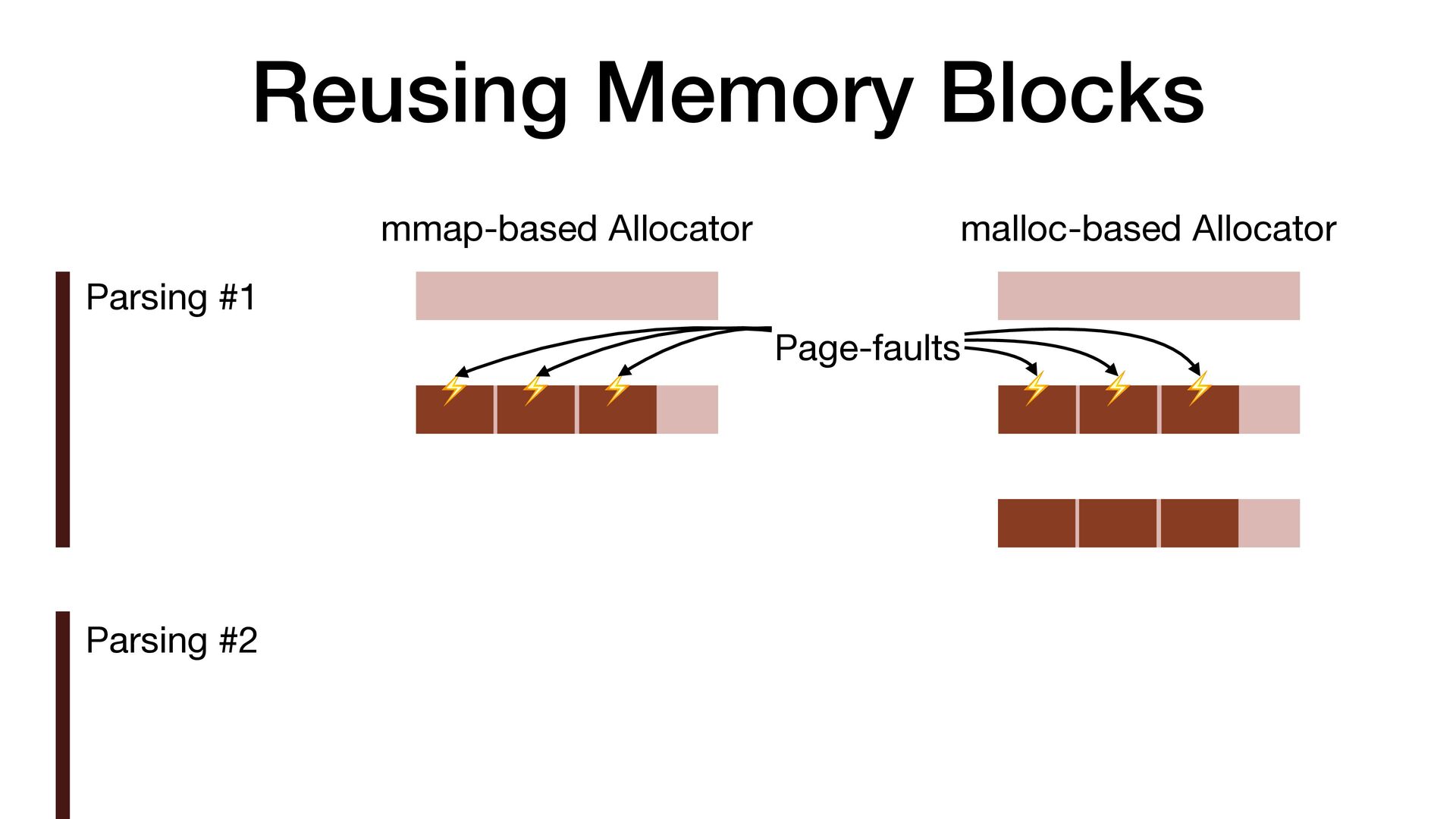
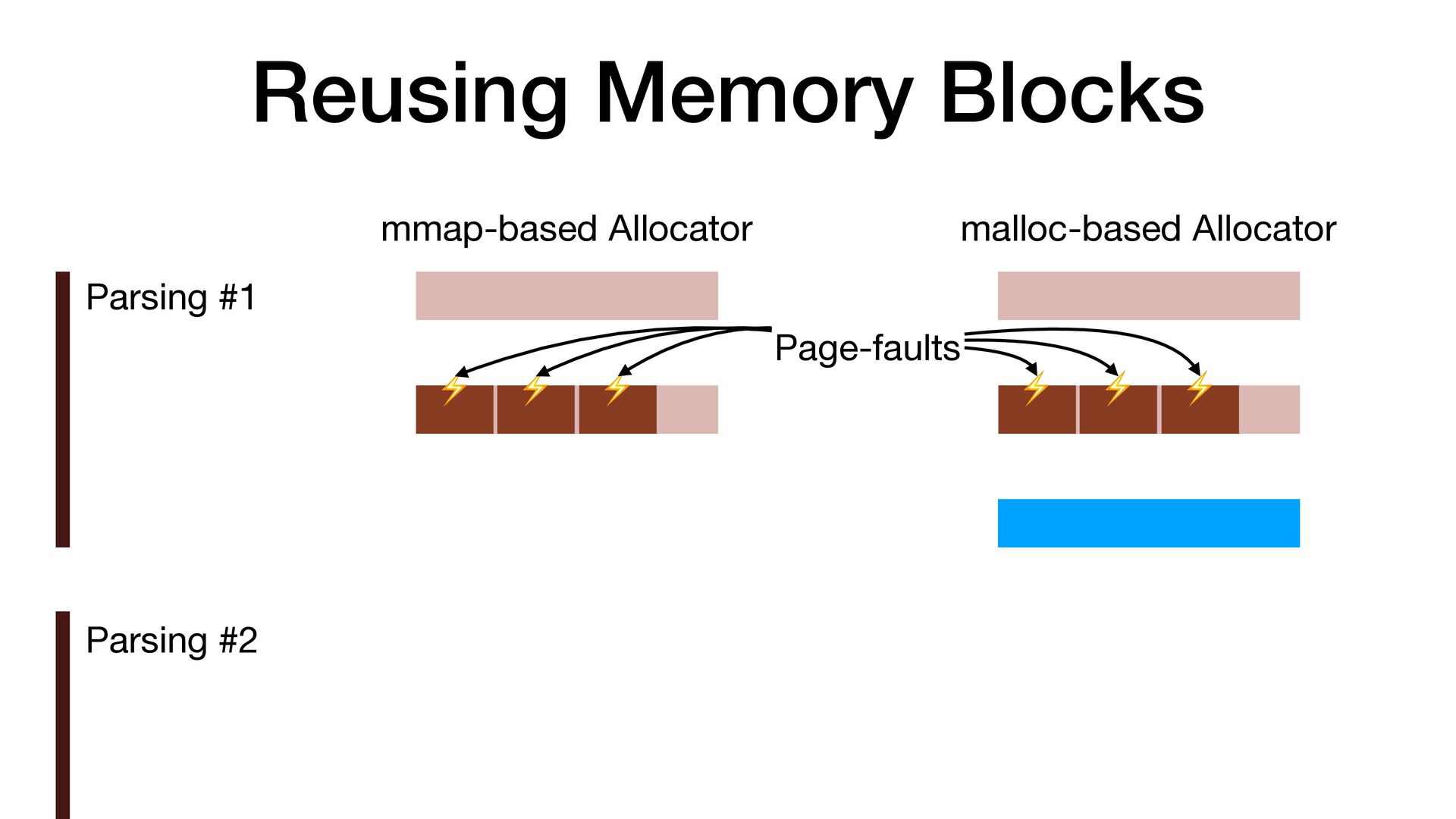
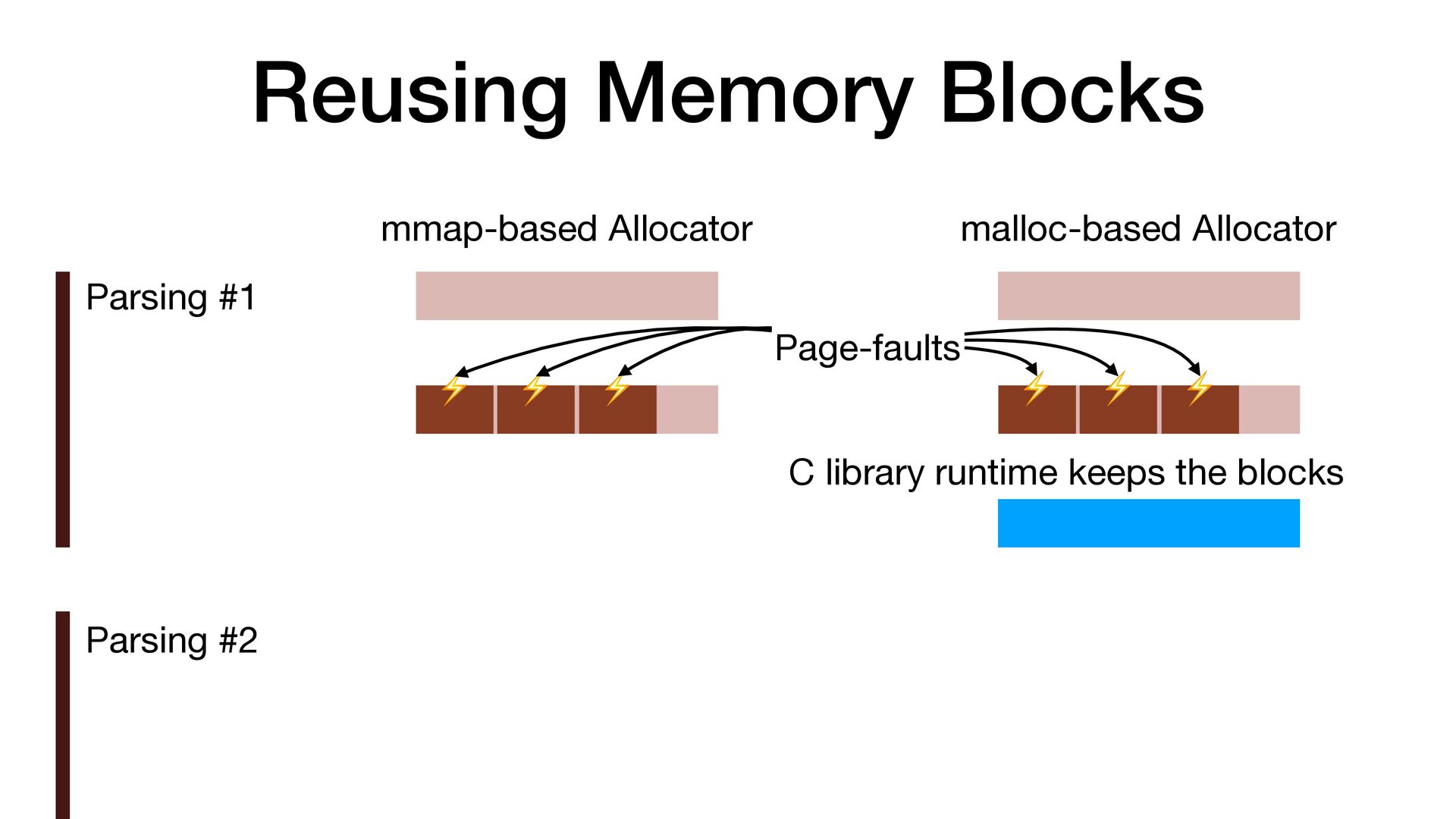
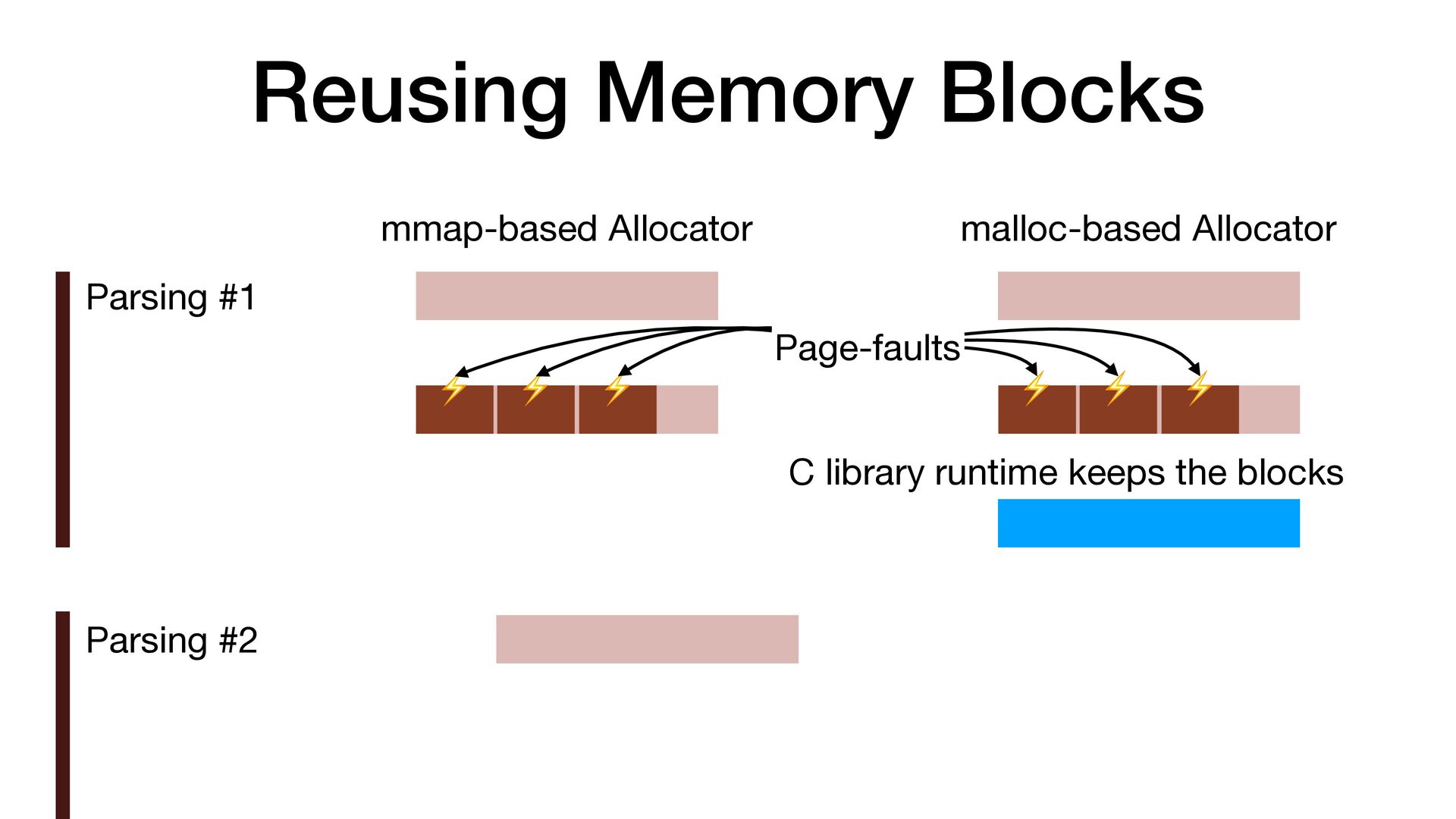
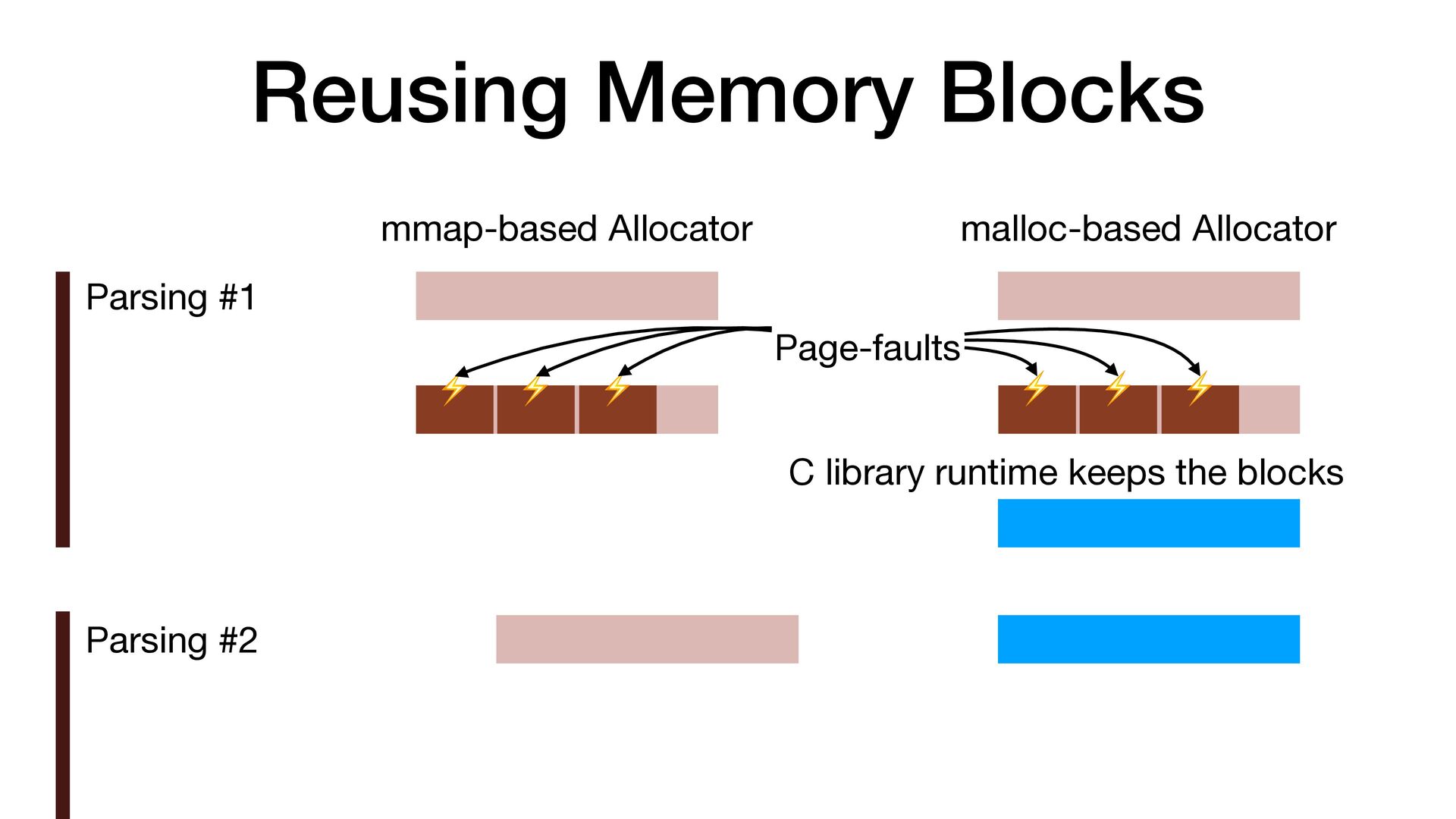
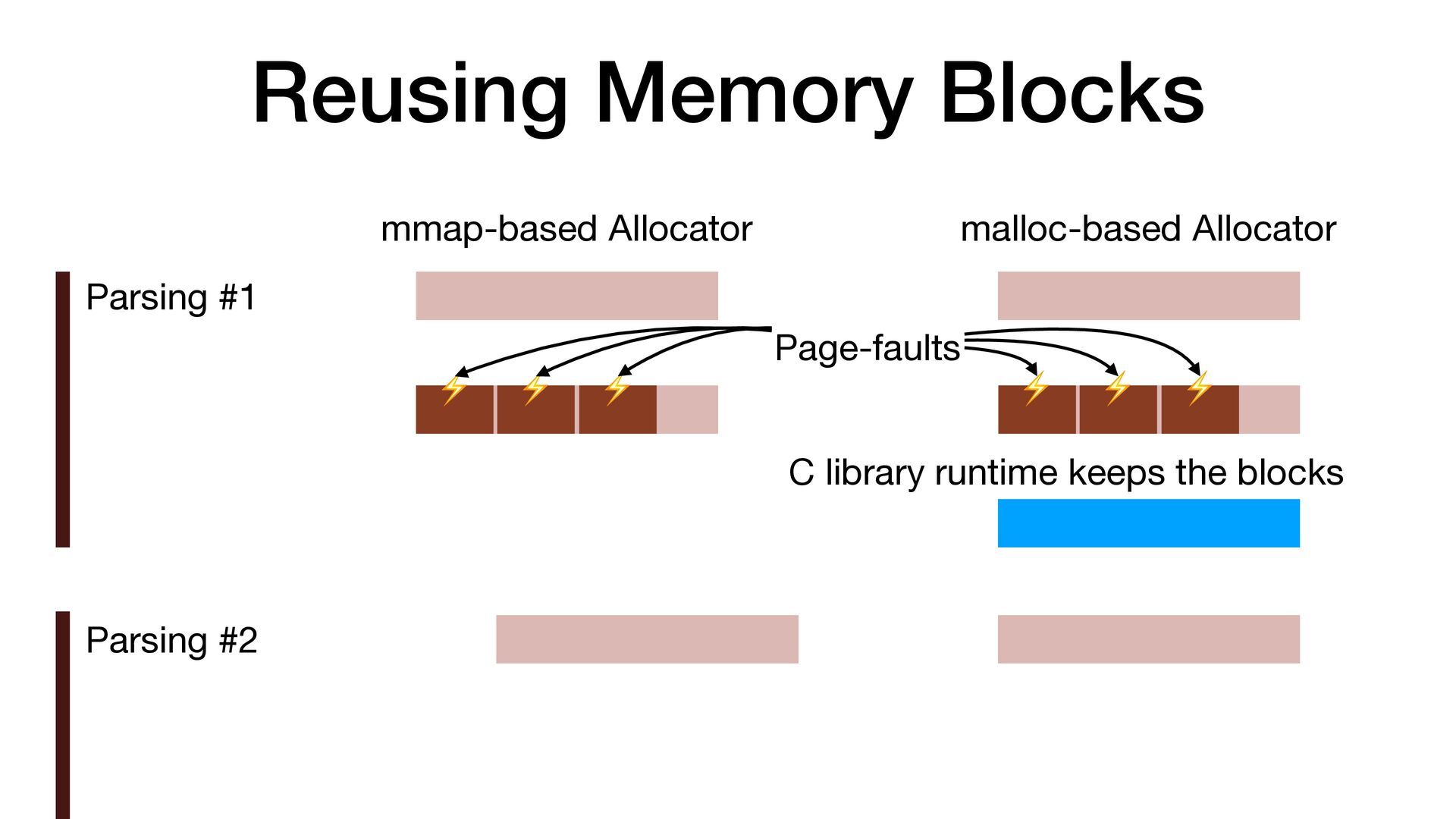
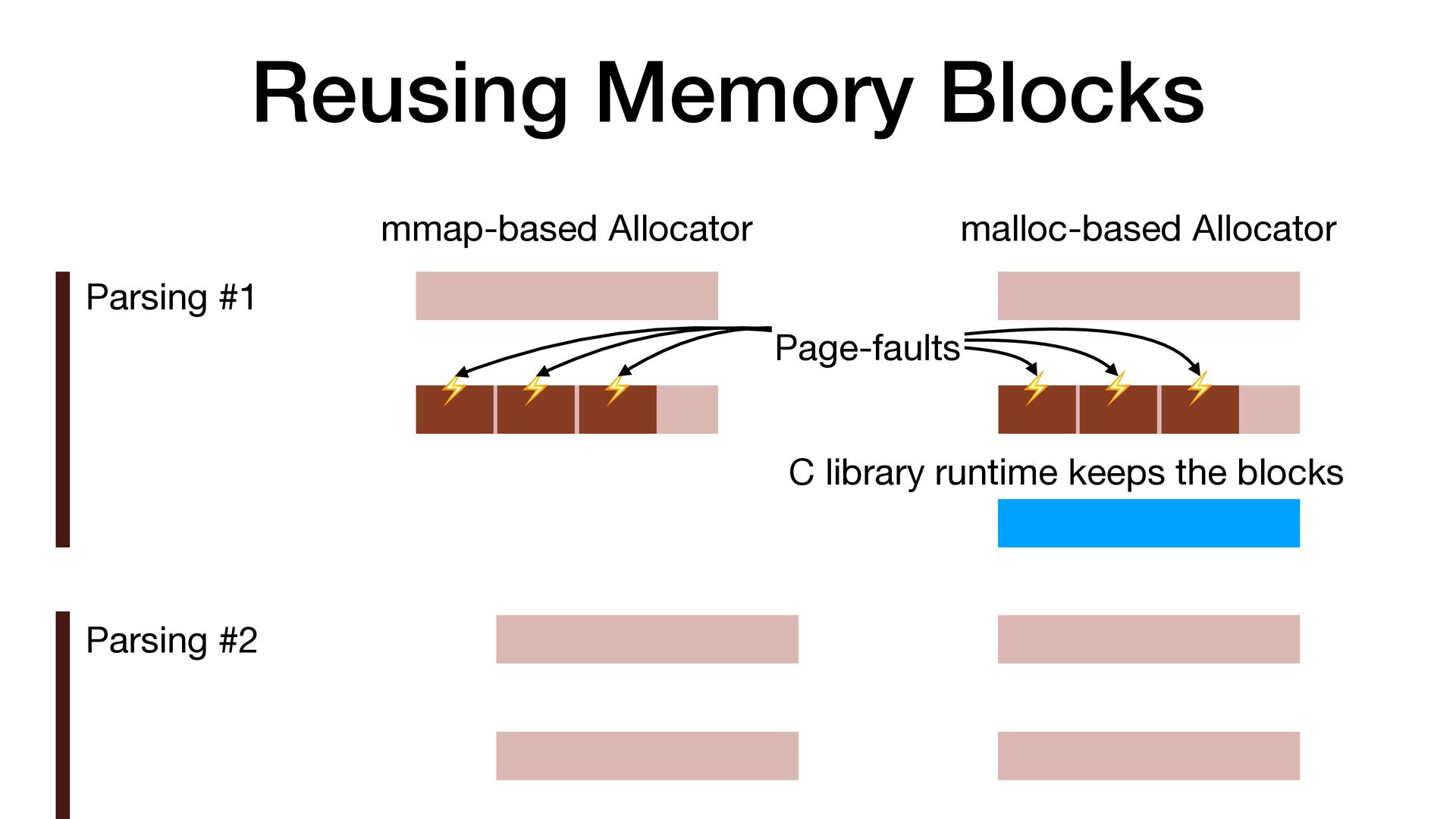
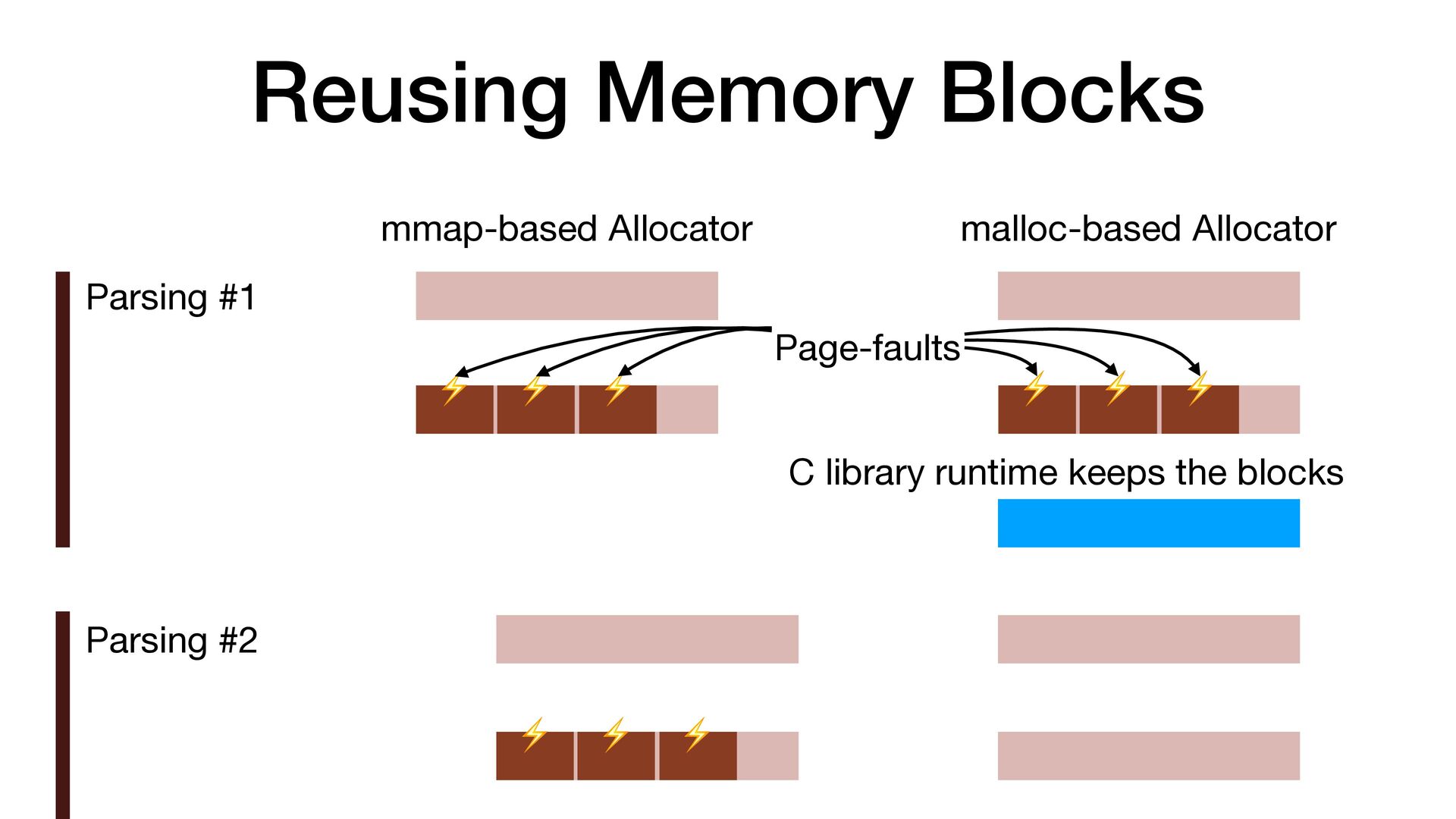
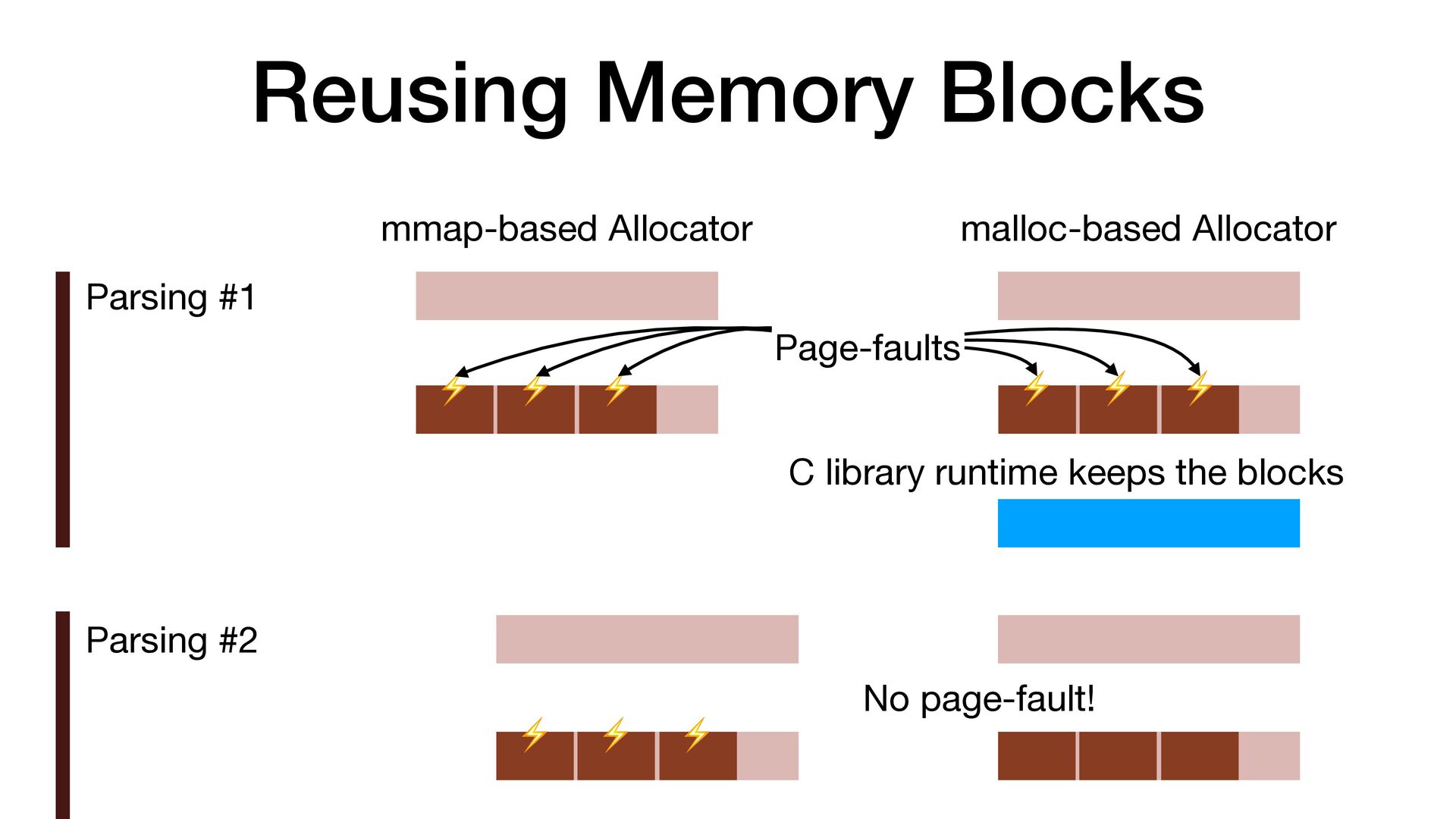
maps fi les directly into a process's address space • We use mmap simply to allocate a large contiguous block of memory for our custom allocator • munmap to return the memory to OS
to release the memory • malloc/free actually uses mmap/munmap internally, but the C library runtime usually reuse the memory blocks for better performance
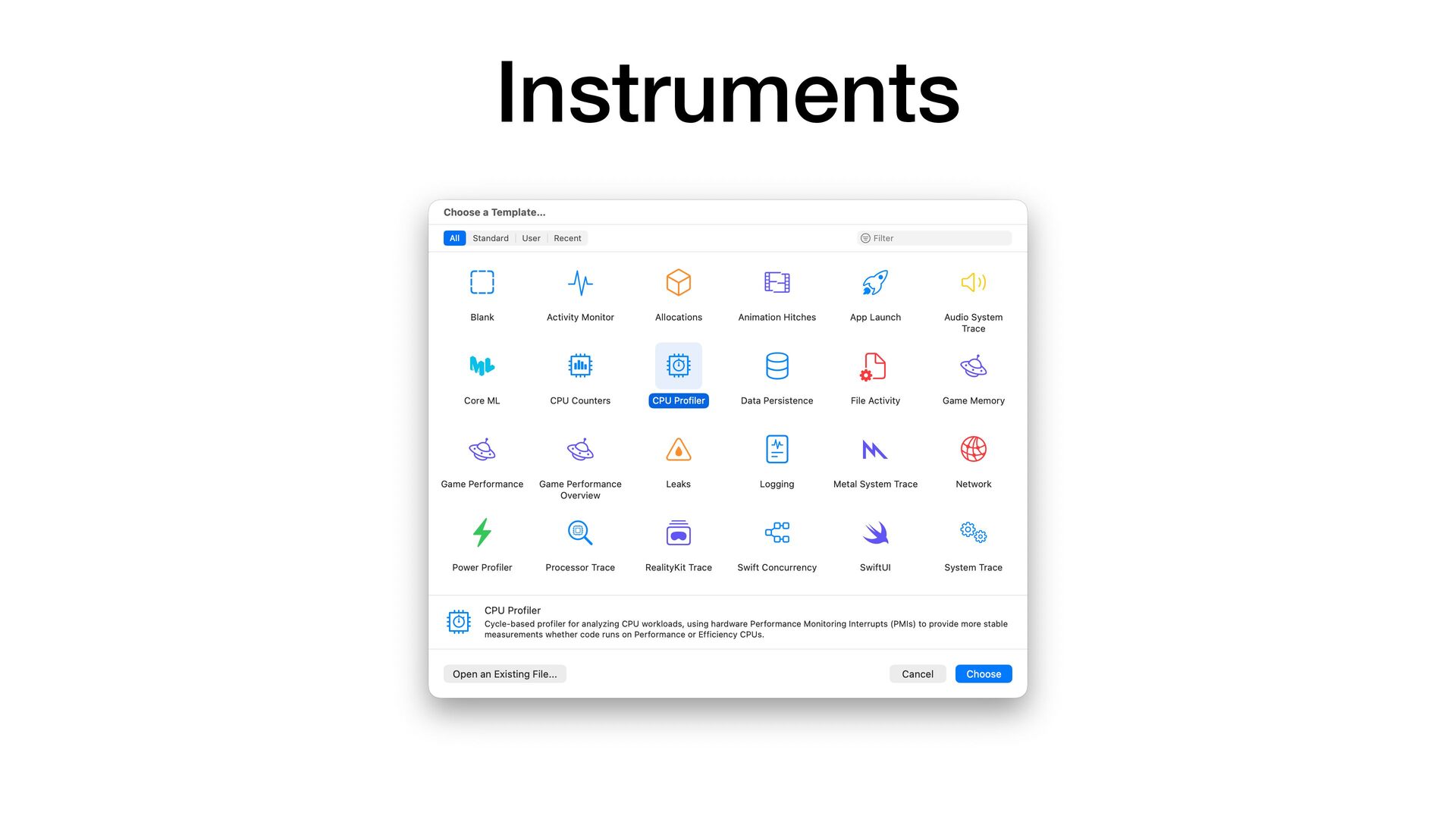
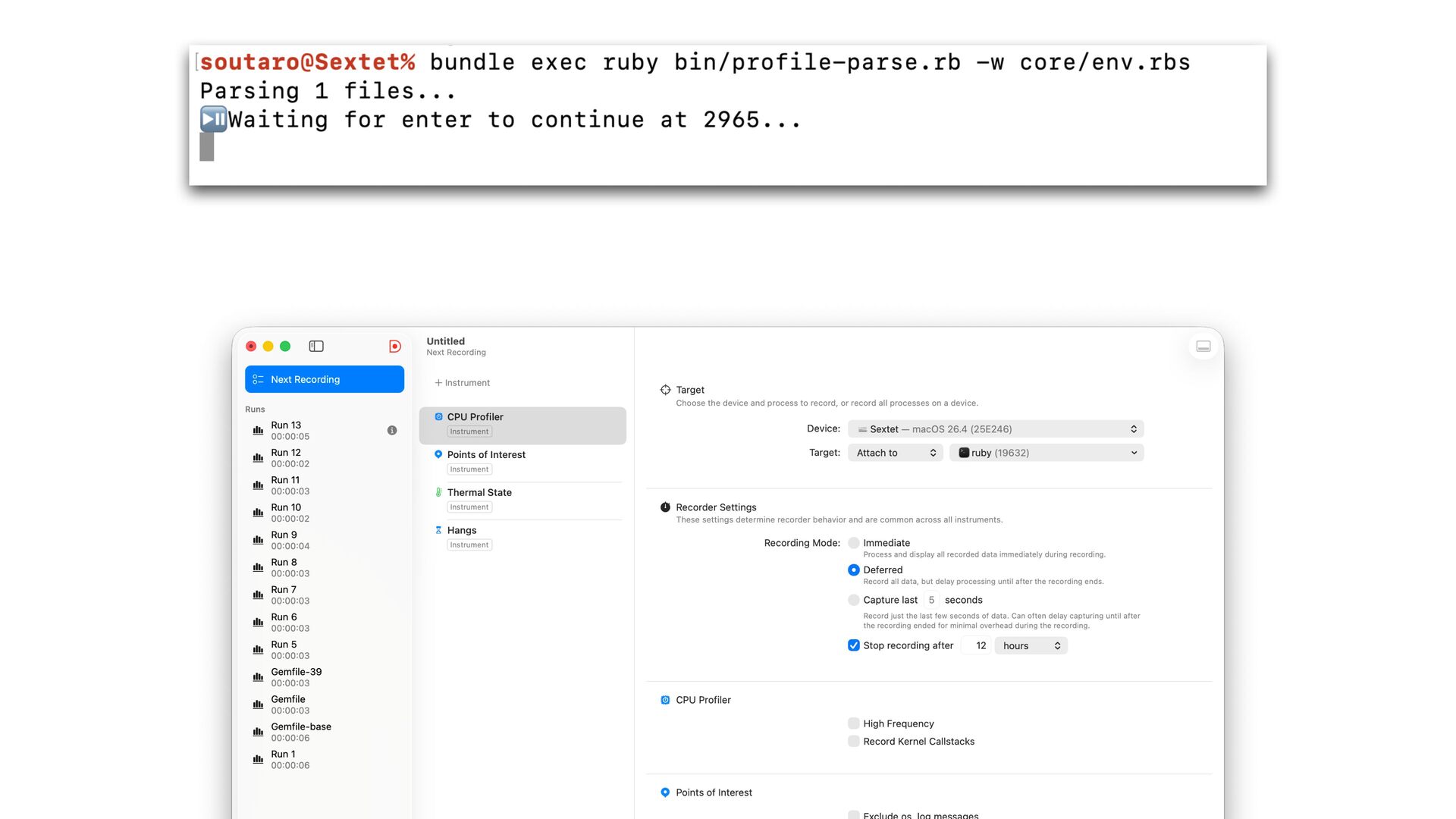
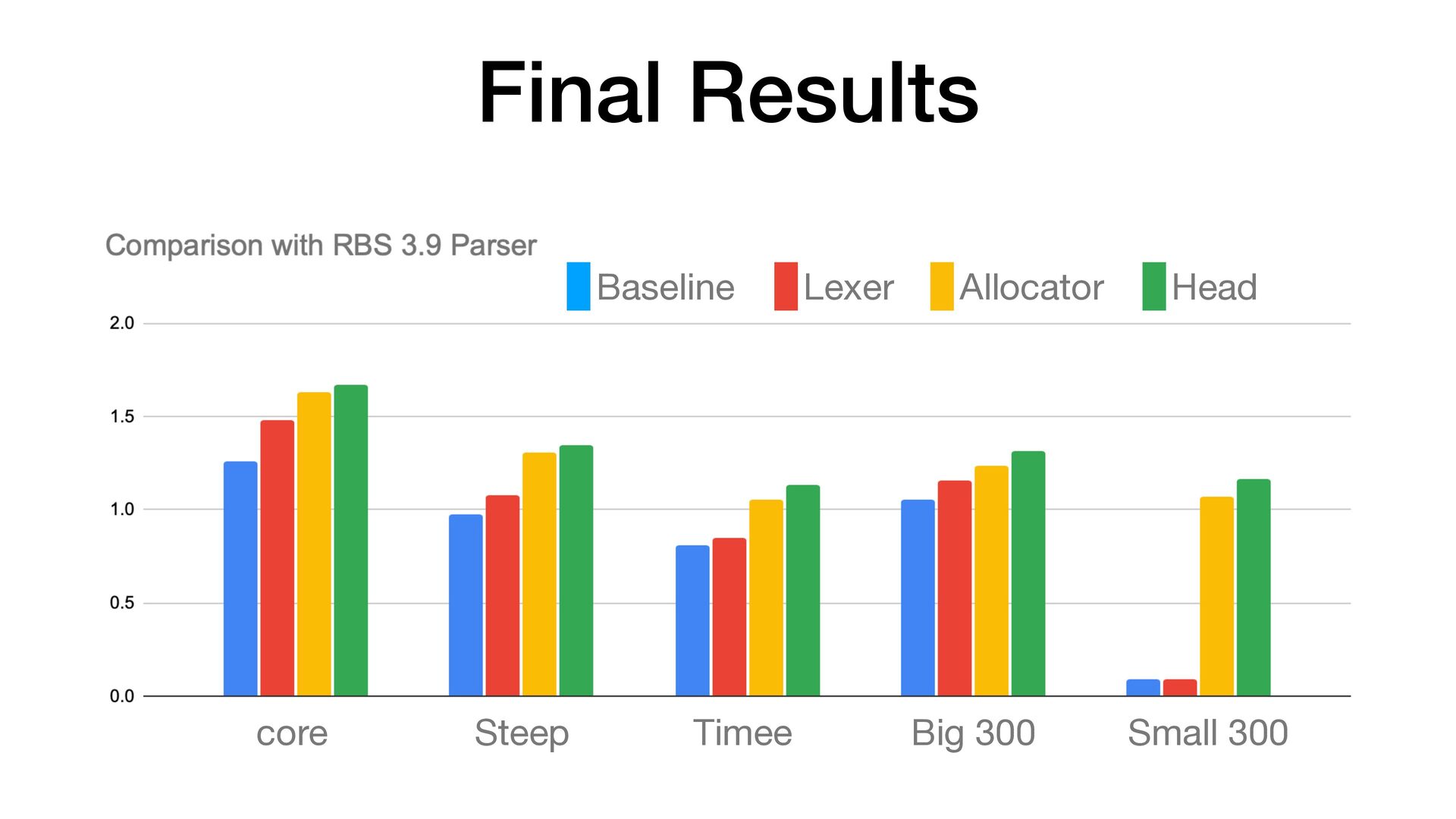
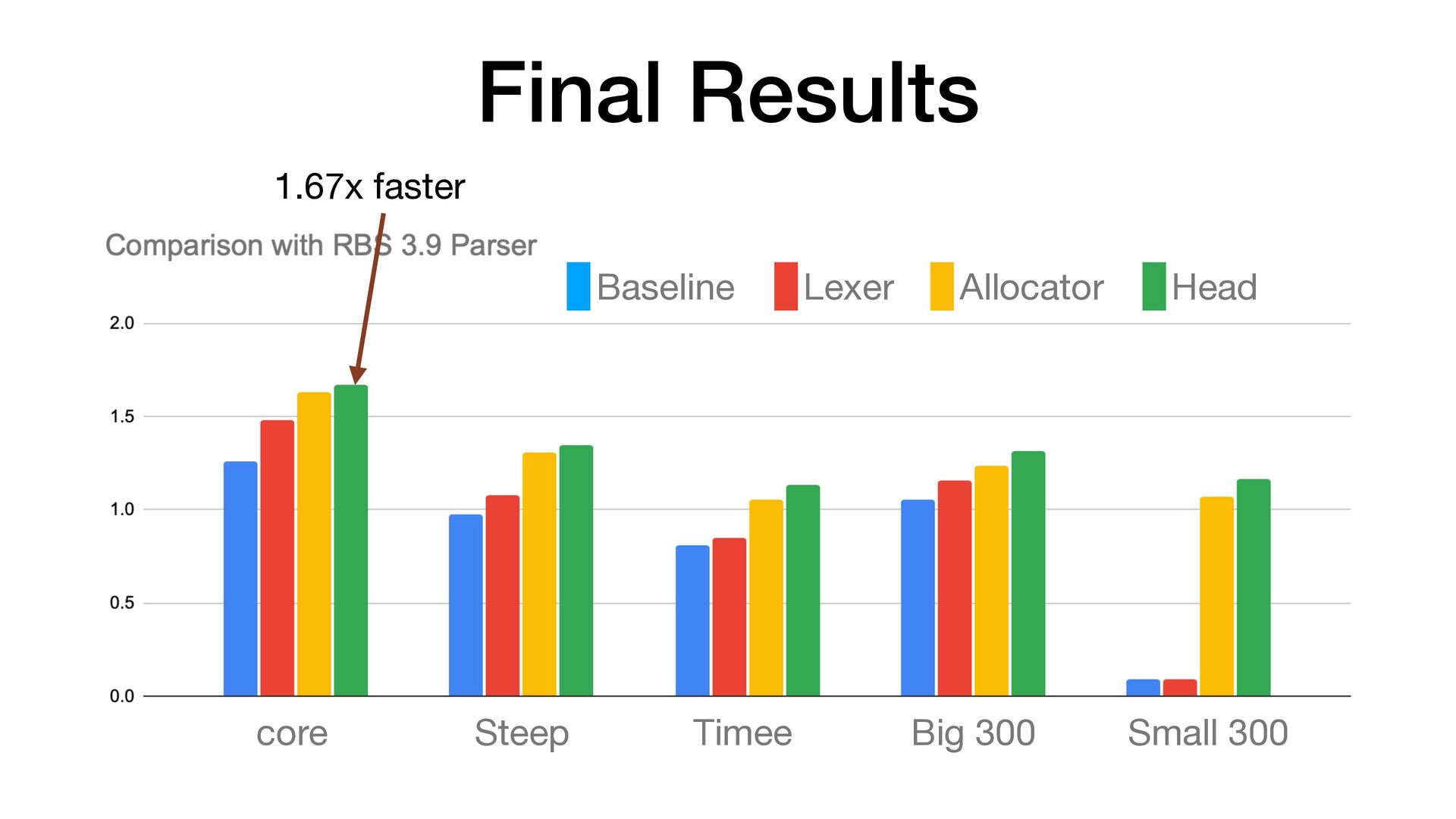
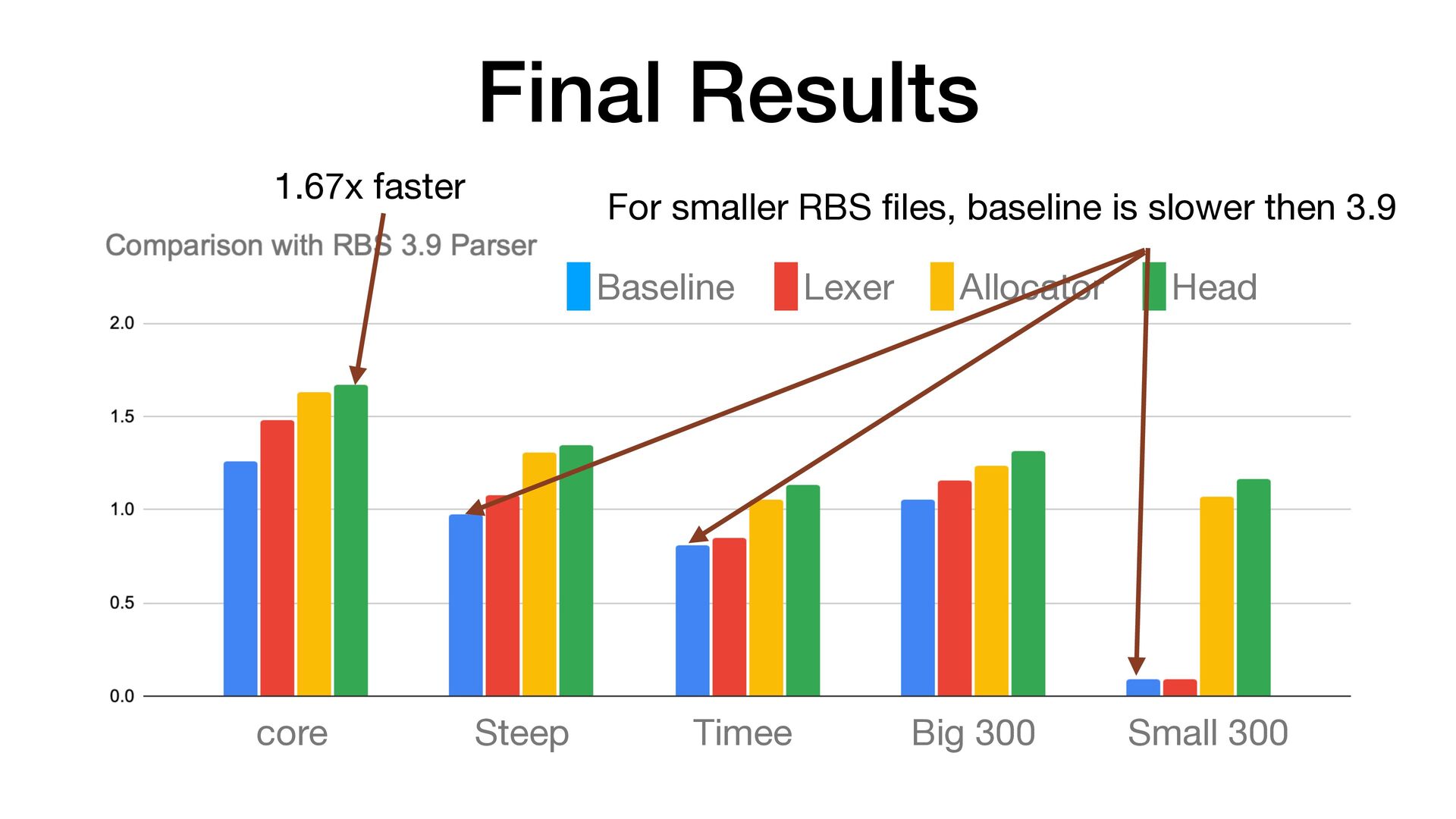
faster than RBS 3.9 • It correctly handles UTF-8 and other encoding inputs • Pro fi lers are useful, but they are not a silver bullet • For this parser optimization, the biggest improvement didn't come from pro fi ling 🤷 • RBS 4 and Steep 2 are out 📣
{kind=link}
{kind=link}
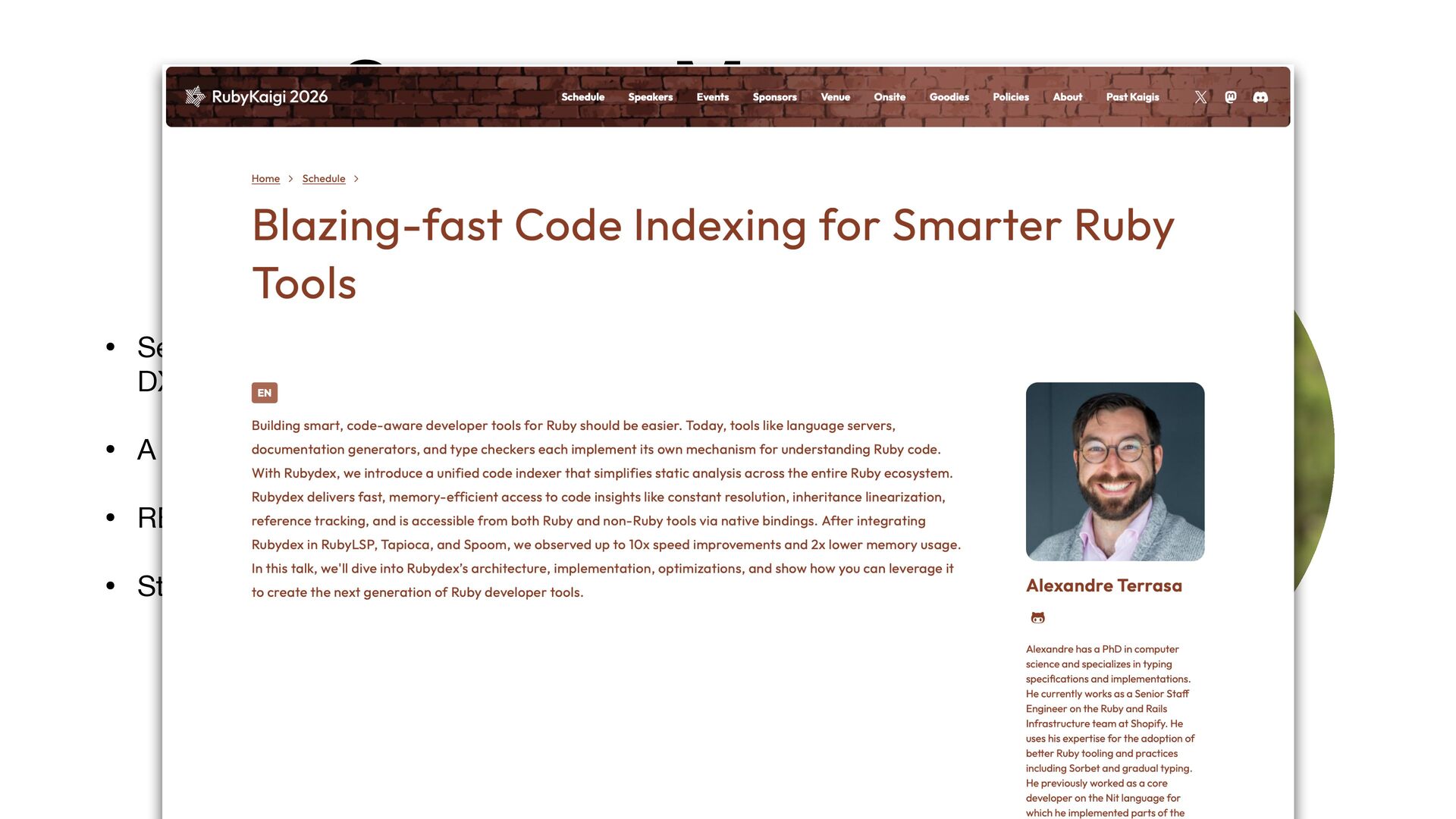{kind=link}
{kind=link}
{kind=link}
![steep server singleton(T)[S] type Generics lower bounds: T > S](https://files.speakerdeck.com/presentations/a3fb6d5767a54ab2847df5add405a2e4/slide_5.jpg){kind=link}
![steep server Inline RBS declaration support 🎉 singleton(T)[S] type Generics](https://files.speakerdeck.com/presentations/a3fb6d5767a54ab2847df5add405a2e4/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
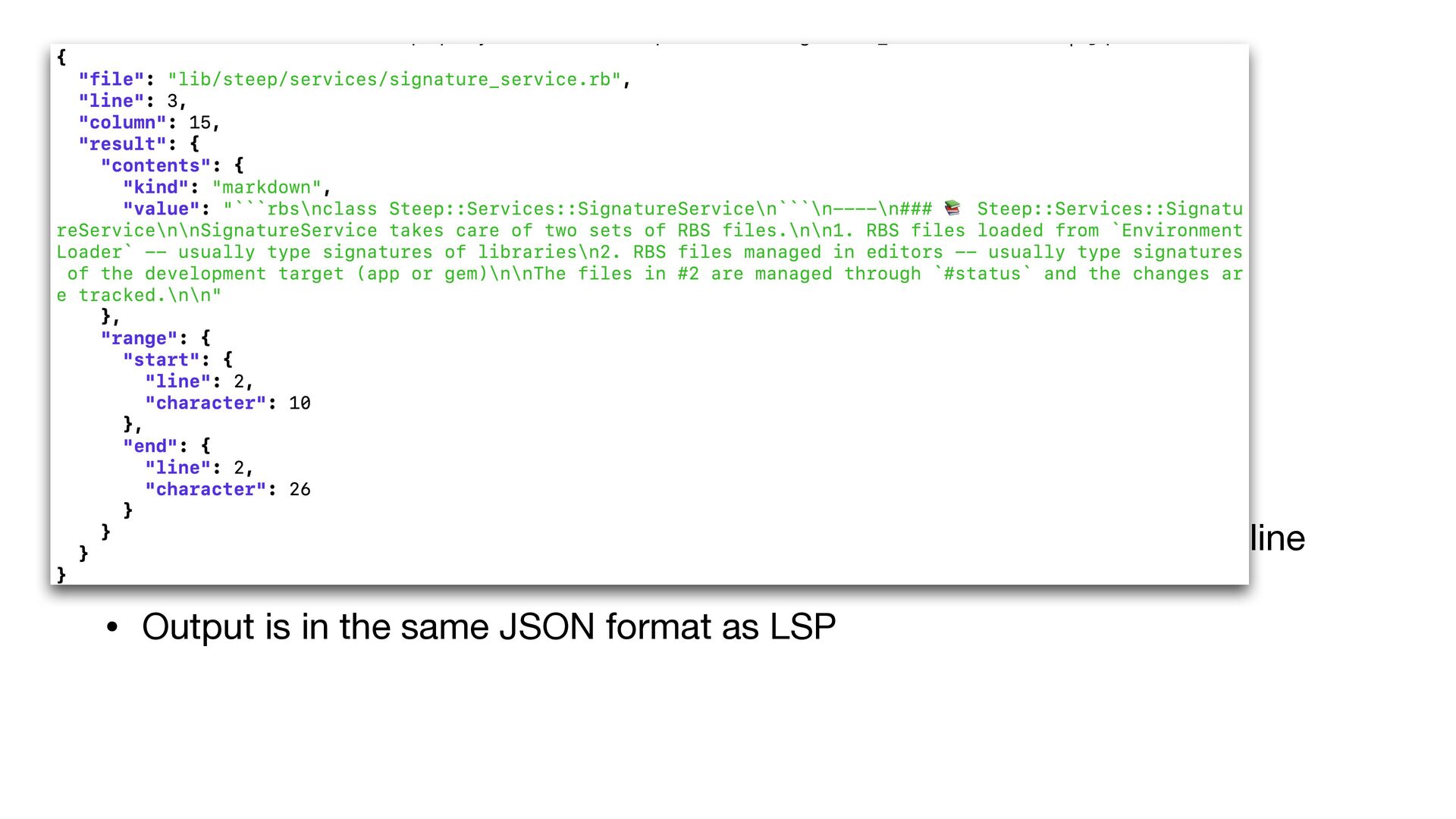{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}