Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Continuous 3D Perception Model with Persistent ...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Spatial AI Network
June 02, 2025
Technology
190
1
Share
Continuous 3D Perception Model with Persistent State
新しい入力画像が観測される度に更新する三次元再構成のフレームワーク(CUT3R)
Spatial AI Network
June 02, 2025
More Decks by Spatial AI Network
See All by Spatial AI Network
FastGS: Training 3D Gaussian Splatting in 100 Seconds (CVPR2026 Highlight)
spatial_ai_network
0
77
Uncalibrated Structure from Motion on a Sphere (ICCV 2025)
spatial_ai_network
0
190
Understanding multi-view transformers (and VGGT)
spatial_ai_network
2
540
Preconditioned Single-step Transforms for Non-rigid ICP (Eurographics 2025)
spatial_ai_network
0
150
Human Mesh Modeling for Anny Body + α
spatial_ai_network
0
160
ChatGPTで論⽂は読めるのか
spatial_ai_network
12
33k
Exploring ways to enhance robustnessof 3D reconstruction using COLMAP
spatial_ai_network
1
210
CL-Splats: Continual Learning of Gaussian Splatting with Local Optimization
spatial_ai_network
0
130
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
spatial_ai_network
0
99
Other Decks in Technology
See All in Technology
Mastering Ruby Box
tagomoris
3
130
Platform Engineering as a Product: Criteria for Improvement and Multi-Tenant Design
kumorn5s
0
470
Javaで学ぶSOLID原則
negima
1
260
Unlocking the Apps
pimterry
0
170
Databricks 月刊サービスアップデート 2026年05月号
tyosi1212
0
200
インフラが苦手でも大丈夫! 紙芝居 Kubernetes -WWGT 10周年編-
aoi1
1
330
Datadog 認定試験の概要と対策
uechishingo
0
220
『家族アルバム みてね』における インシデント対応との向き合い方 / Approach incident response in Family Album
kohbis
2
290
JJUG CCC 2026 Spring AI時代の開発こそ標準化を武器に! ― 方式・プロセス・プラットフォームの標準化
s27watanabe
2
670
チームで実践する AI-DLC 思考の軌跡を残すチェックポイント設計
belongadmin
0
1.6k
コードレビューを制するチームがソフトウェアデリバリーのフローを制す / Beyond Code Review: Distributing Its Responsibilities Across the SDLC
mtx2s
3
630
React、まだ楽しくて草
uhyo
7
3.8k
Featured
See All Featured
Navigating Team Friction
lara
192
16k
Accessibility Awareness
sabderemane
1
130
Deep Space Network (abreviated)
tonyrice
0
160
Designing Powerful Visuals for Engaging Learning
tmiket
1
390
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
310
For a Future-Friendly Web
brad_frost
183
10k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
330
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
300
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Product Roadmaps are Hard
iamctodd
PRO
55
12k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
70
39k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Transcript
Continuous 3D Perception Model with Persistent State Qianqian Wang1,2∗, Yifei
Zhang1∗, Aleksander Holynski1,2, Alexei A. Efros1, Angjoo Kanazawa1 1University of California, Berkeley 2Google DeepMind CVPR 2025 (Oral) 2025/5/27 Spatial AI Network 勉強会 (株)サイバーエージェント 片桐 敬太
論文情報 Project page:https://cut3r.github.io/ 論文(arXiv):https://arxiv.org/abs/2501.12387 コード(GitHub):https://github.com/CUT3R/CUT3R ※以下、本論文の画像を引用 論文選定のモチベーション 3DGSをビジネス活用している立場で”社会実装”にフォーカスして論文を選定
概要 CUT3R: Continuous Updating Transformer for 3D Reconstruction 新しい入力画像が観測される度に更新する三次元再構成のフレームワーク 入力: 動画、画像群(順不同) 出力: 静的・動的な三次元空間(三次元点群)、カメラの内部・外部パラメータ
背景 タブラ・ラサ(白紙状態)からの再構成 SfMやSLAMはゼロから再構成する必要があり、動的シーンに対応困難 学習ベースの再構成 少ない画像ペアからの再構成DUSt3Rなどは静的シーンに特化 人間の視覚認知に基づくアプローチ ・人間は過去の知識を活用し、継続的に新しい観測から学習 ・少ない情報から3Dの世界を解釈し、観測が増えるにつれて精緻化 ・観測していない領域も推論
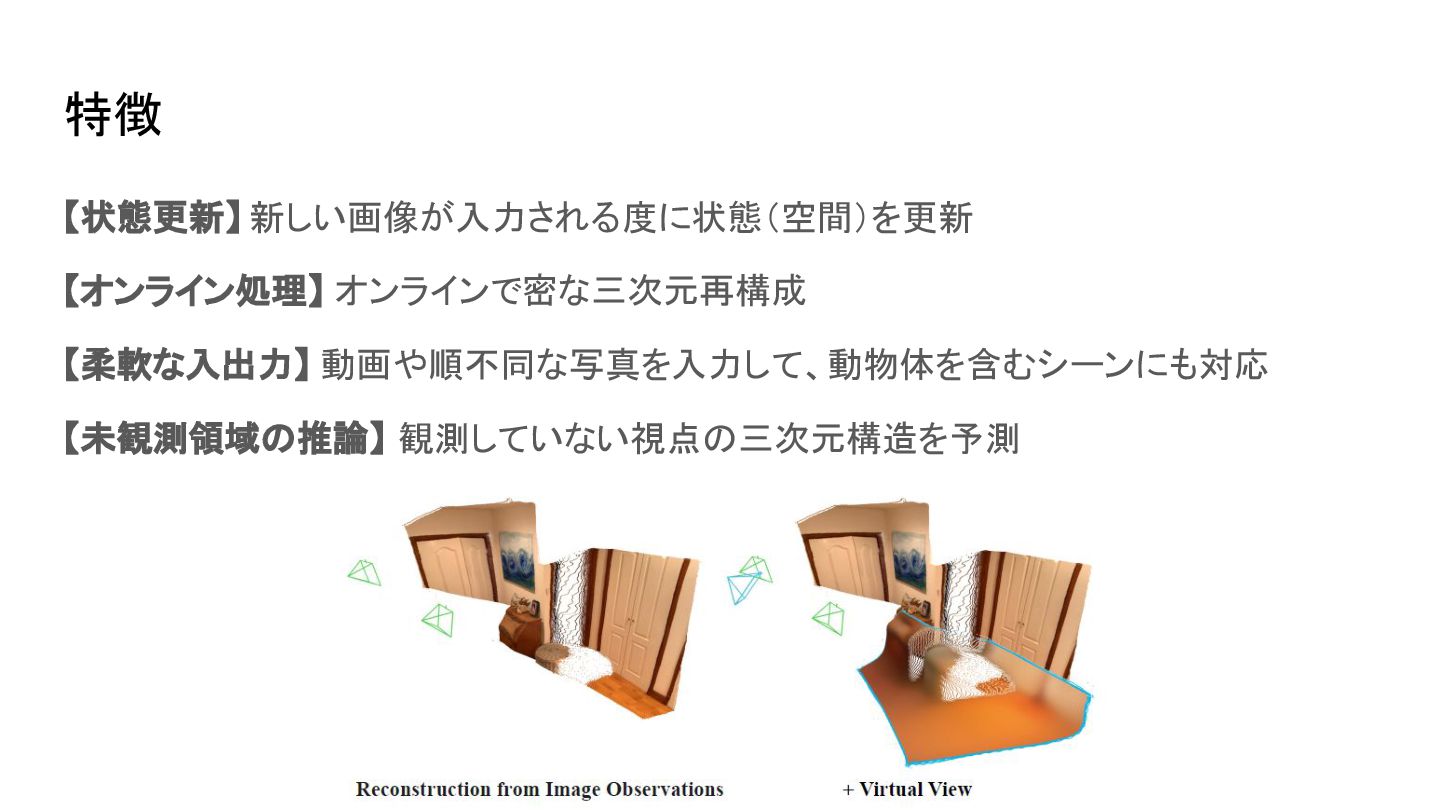
特徴 【状態更新】 新しい画像が入力される度に状態(空間)を更新 【オンライン処理】 オンラインで密な三次元再構成 【柔軟な入出力】 動画や順不同な写真を入力して、動物体を含むシーンにも対応 【未観測領域の推論】 観測していない視点の三次元構造を予測
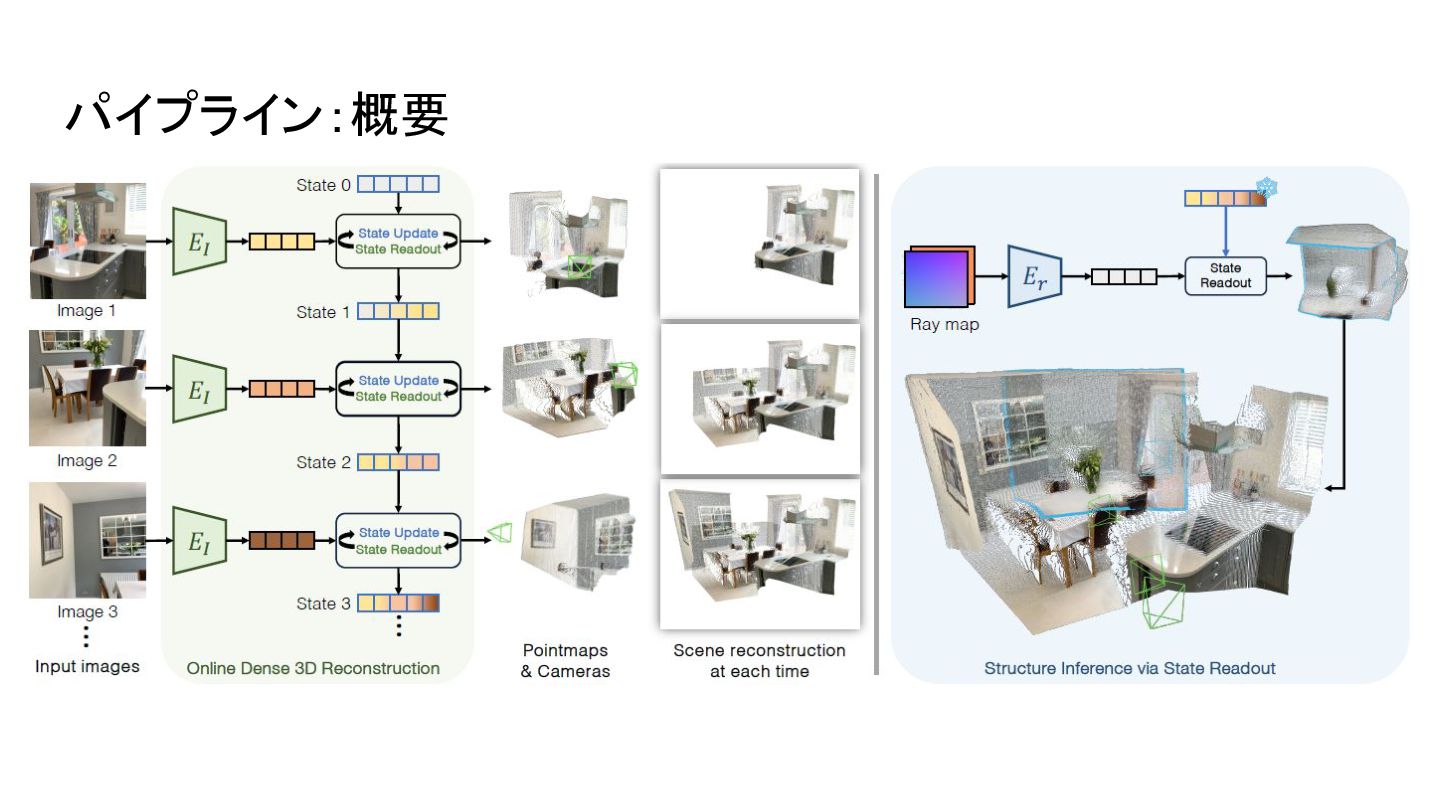
パイプライン:概要
パイプライン:入力からの状態更新&読み出し ・各入力画像はViTエンコーダで画像トークンに変換 ・状態トークンは現在の3Dシーンの情報を保持 ・入力の画像トークンは相互接続されたViTデコーダにより 状態トークンと相互作用 ・State Update: 現在の画像情報を状態に統合 ・State Readout: 状態に保存された過去の状態を読み 出して予測に利用
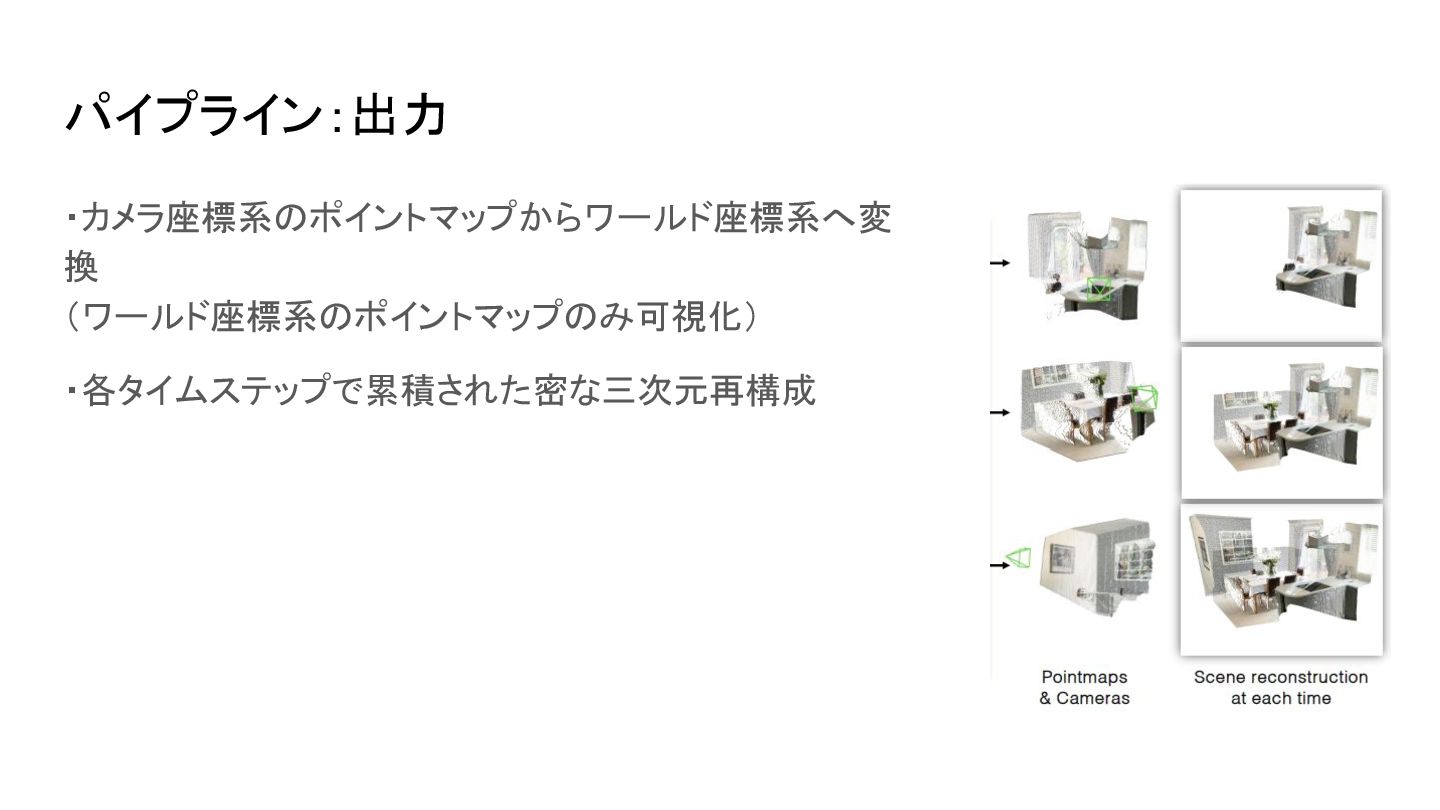
パイプライン:出力 ・カメラ座標系のポイントマップからワールド座標系へ変 換 (ワールド座標系のポイントマップのみ可視化) ・各タイムステップで累積された密な三次元再構成
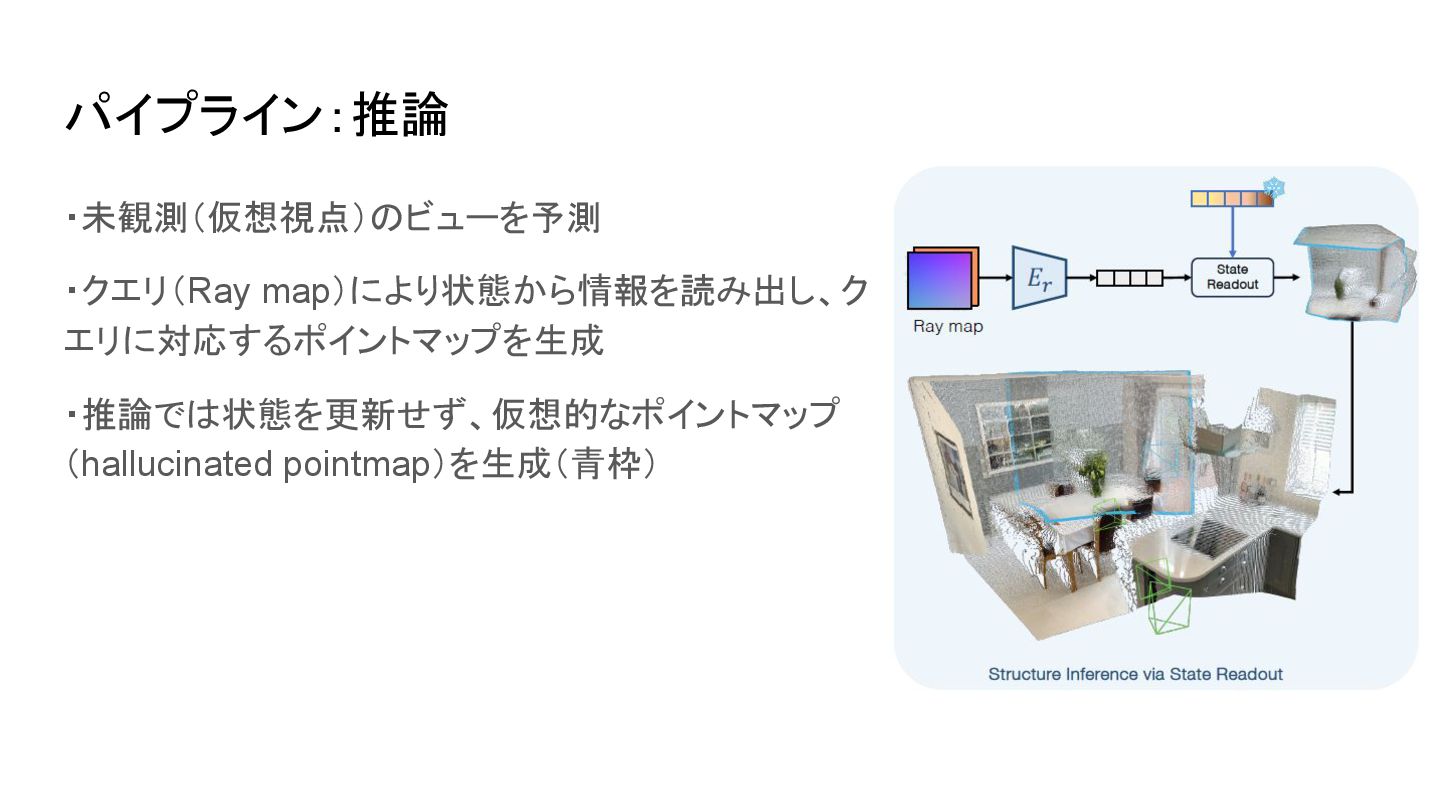
パイプライン:推論 ・未観測(仮想視点)のビューを予測 ・クエリ(Ray map)により状態から情報を読み出し、ク エリに対応するポイントマップを生成 ・推論では状態を更新せず、仮想的なポイントマップ (hallucinated pointmap)を生成(青枠)
提案手法:State-Input Interaction Mechanism ・状態の更新と読み出しは式(2)のCross-Attentionで相互作用 状態更新: 現在の画像情報から状態を更新 状態読み出し: 過去の情報を状態から読み出す 画像トークンと相互作用す る前後の状態トークン カメラのポーズトークン ViTによる画像トークン
状態に基づくカメラの ポーズトークン 状態に基づく画像トークン 入力画像
提案手法:State-Input Interaction Mechanism ・相互作用後にペアの入力画像から3D表現(ポイントマップ)を抽出 ・新たな観測により不確かだった領域の信頼度は向上していく DPT (Dense Prediction Transformer)で実装 MLPで実装
世界座標系の 位置姿勢(剛体) ポイントマップ ポイントマップに対応す る信頼度マップ
提案手法:Querying the State with Unseen Views ・仮想視点の内部・外部パラを各ピクセルの光線の原点と方向をエンコードしたレイマッ プで表現 ・レイマップはクエリとしてのみ機能して状態は更新されない クエリカメラのレイマップ
レイマップのトークン レイマップの各光線の色 式(2)と同様に状態を読 み込んだトークン
提案手法:Training Objective ・L_conf: MASt3Rによるポイントマップに信頼度cを考慮した回帰損失を適用 ・L_pose: カメラポーズを四元数qと並進τとして、予測と真値のL2ノルムを最小化 ・L_rgb: 色Iの予測と真値を一致させるMSE損失も適用 低い信頼度の学習を防止 レイマップが入力さ れる場合に適用 三次元構造の予測 カメラポーズの予測
光線の色を予測
提案手法:Training Strategy 【学習データ】 ・合成と実世界、静的と動的、空間と物体、屋内と屋外をカバーした32のデータセット ・静的シーンでは4ビューシーケンス(224×224) ・動的シーンと部分的なアノテーション(カメラポーズ...)も組込み ・様々な解像度(最大幅:512)とアスペクト比
提案手法:Training Strategy 【実装】 ・画像エンコーダにはViT-Largeモデルを使用 ・DUSt3Rの学習済みの重みで初期化 ・デコーダにはViT-Baseを使用 ・エンコーダとデコーダは16×16ピクセルのパッチで動作 ・状態は768次元の768トークンで構成 ・レイマップエンコーダは2ブロックの軽量エンコーダ ・初期学習率1e-4のAdam-Wオプティマイザを使用
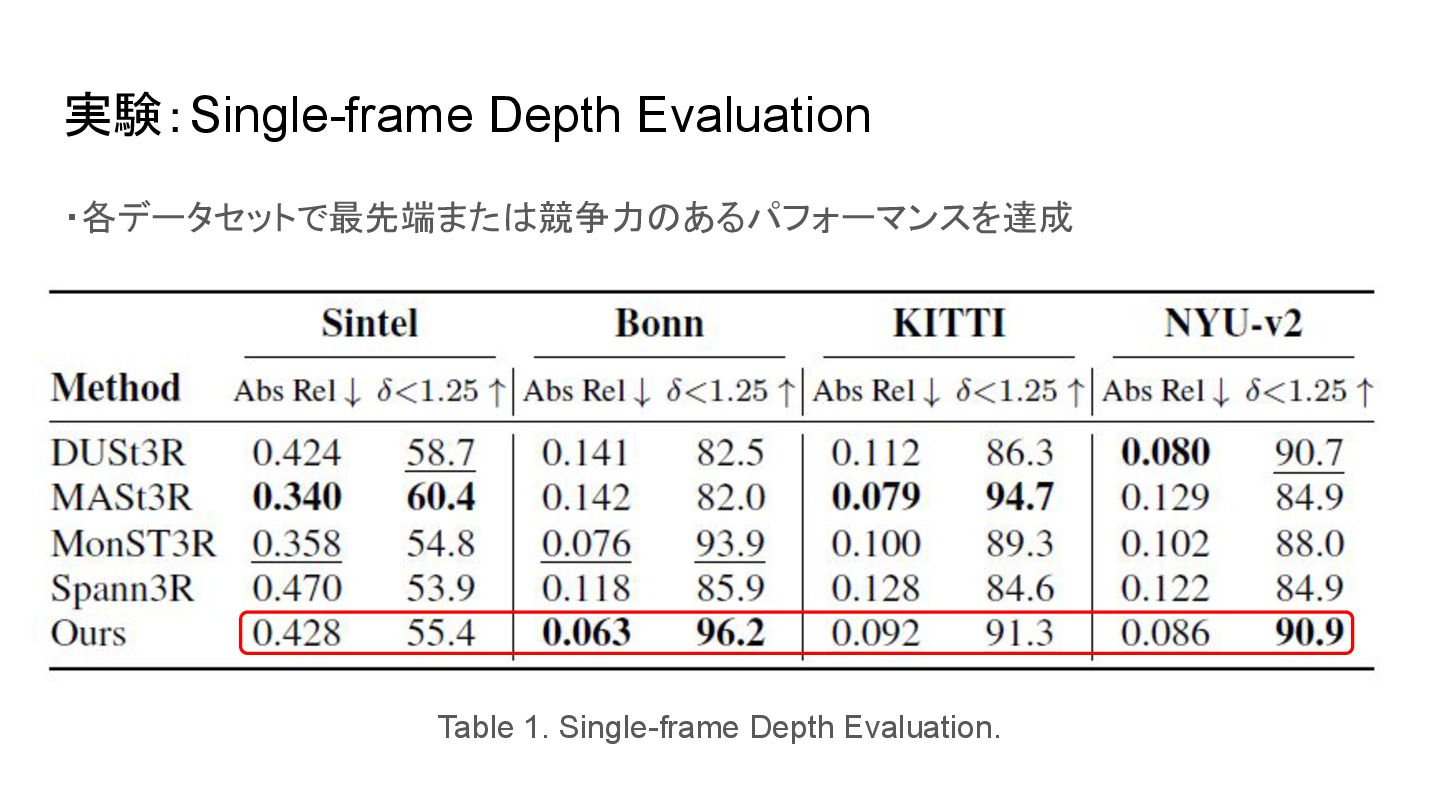
実験:Single-frame Depth Evaluation ・各データセットで最先端または競争力のあるパフォーマンスを達成 Table 1. Single-frame Depth Evaluation.
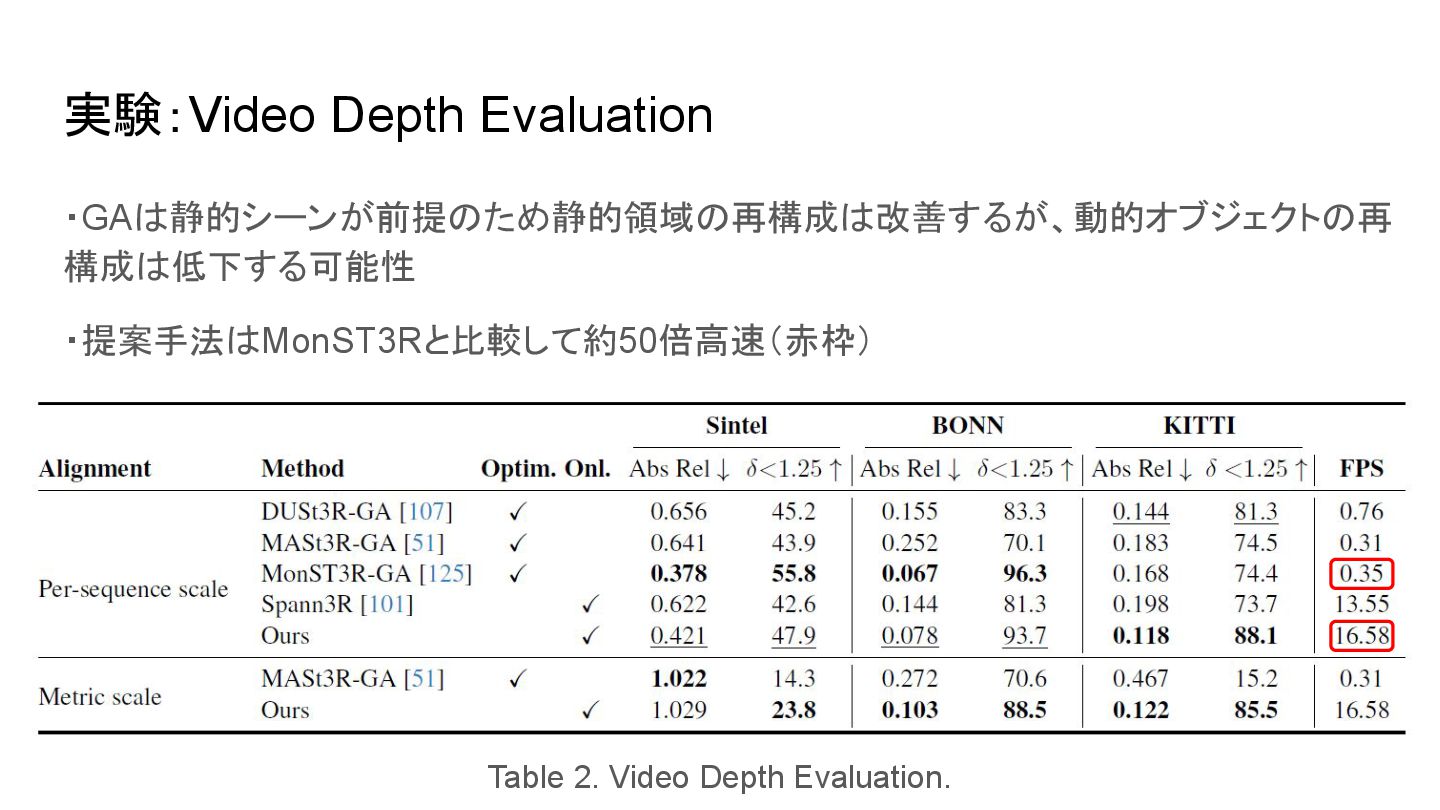
実験:Video Depth Evaluation ・GAは静的シーンが前提のため静的領域の再構成は改善するが、動的オブジェクトの再 構成は低下する可能性 ・提案手法はMonST3Rと比較して約50倍高速(赤枠) Table 2. Video Depth
Evaluation.
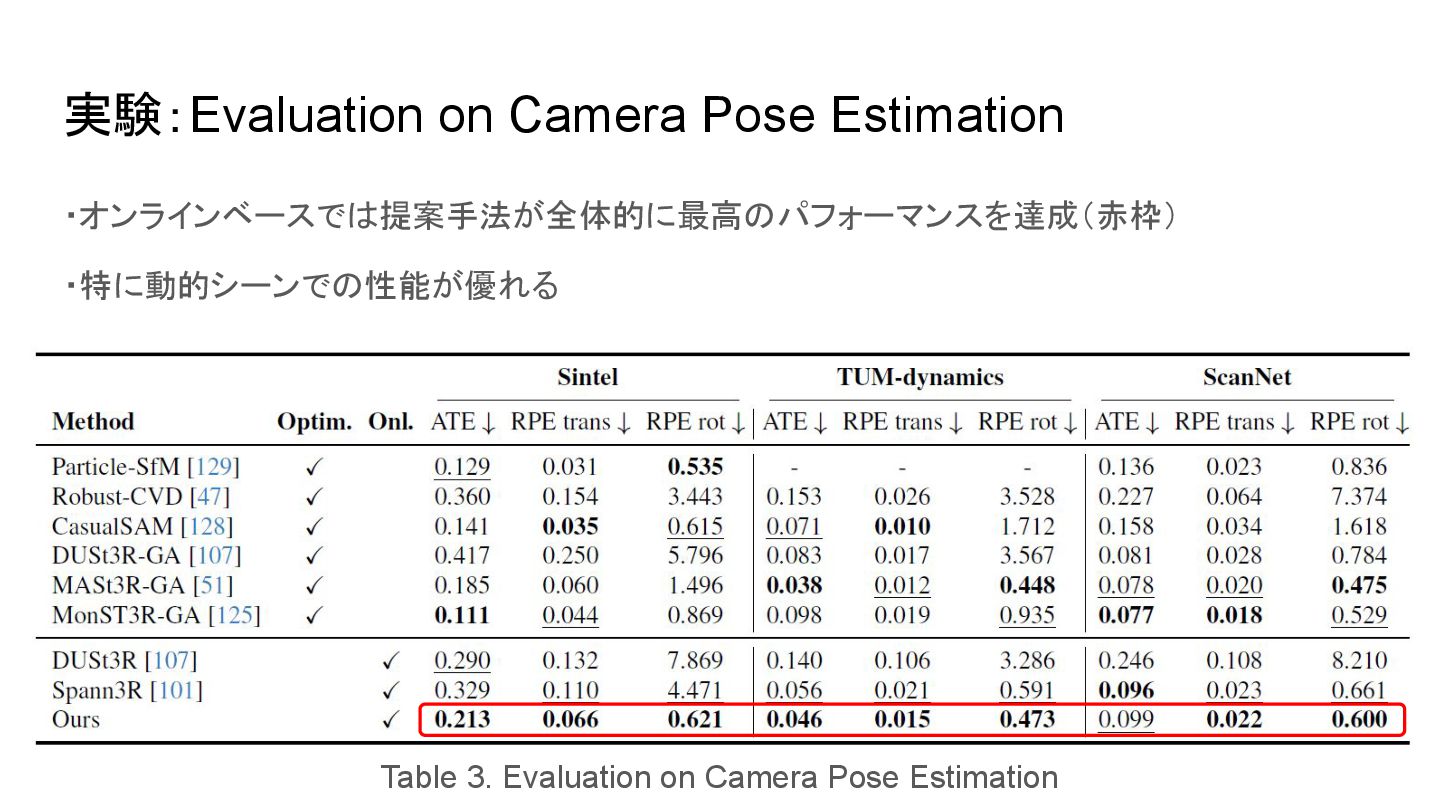
実験:Evaluation on Camera Pose Estimation ・オンラインベースでは提案手法が全体的に最高のパフォーマンスを達成(赤枠) ・特に動的シーンでの性能が優れる Table 3. Evaluation
on Camera Pose Estimation
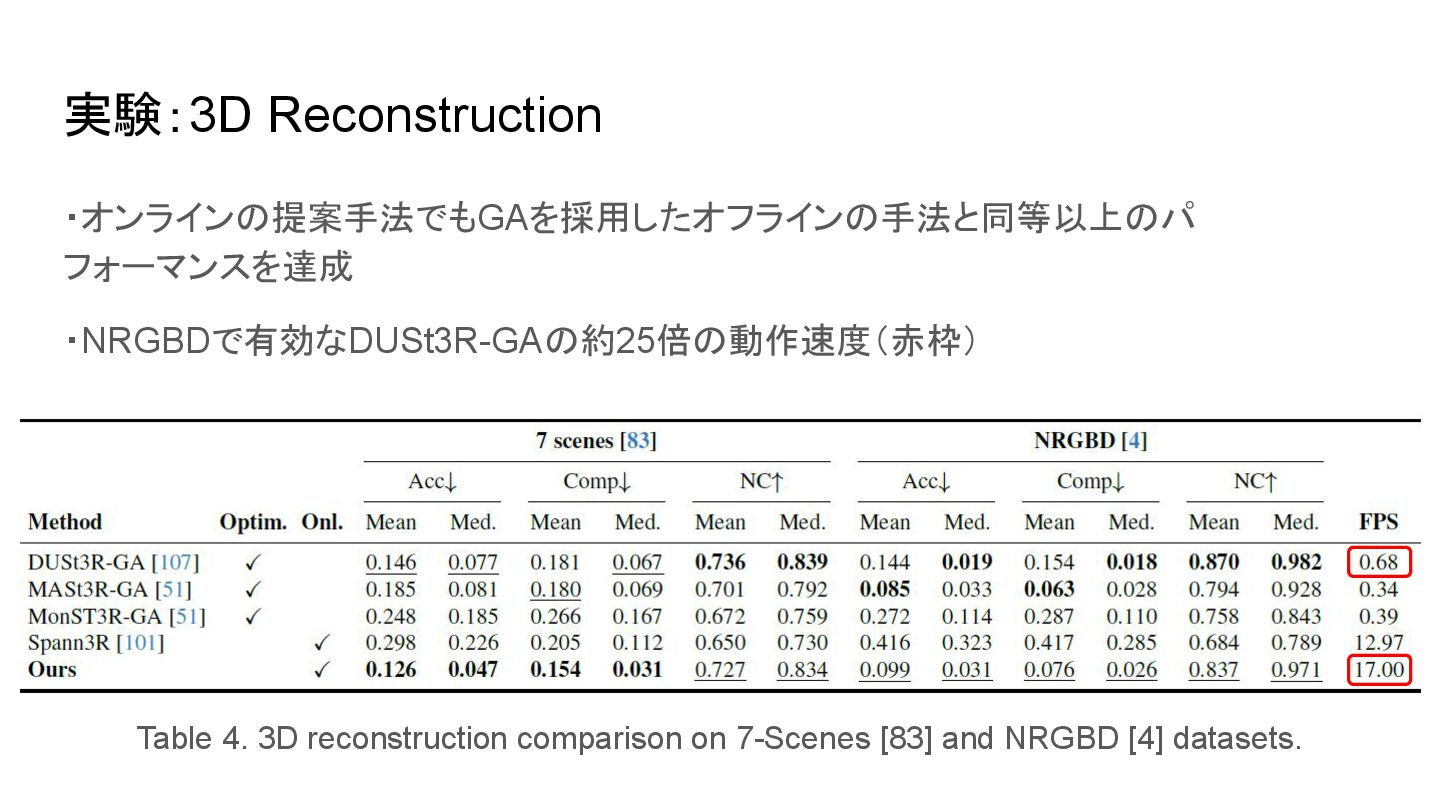
実験:3D Reconstruction ・オンラインの提案手法でもGAを採用したオフラインの手法と同等以上のパ フォーマンスを達成 ・NRGBDで有効なDUSt3R-GAの約25倍の動作速度(赤枠) Table 4. 3D reconstruction comparison
on 7-Scenes [83] and NRGBD [4] datasets.
実験:3D Reconstruction(可視化) Figure 4. Qualitative Results on In-the-wild Internet Videos.
制限 ・長いシーケンスではグローバルアラインメントがないためドリフトの可能性 ・生成的ではなく決定論的アプローチのため、視点から遠く離れた視点を外挿する場 合にボケやすい ・再帰型ネットワークのトレーニングでは時間がかかる
まとめ ・状態表現を更新可能なオンラインの三次元再構成モデル(CUT3R)を提案 ・ビデオや写真コレクションの入力と、静的・動的シーンの出力に対応 所感 ・CUT3Rから3DGS等の自由視点画像生成のタスクへ応用できると価値が高まる ・大容量、高解像度のデータセットにも適用できると実運用しやすい ・動的シーンの中でも長い年月で変化する環境に対してもワークできると面白い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}