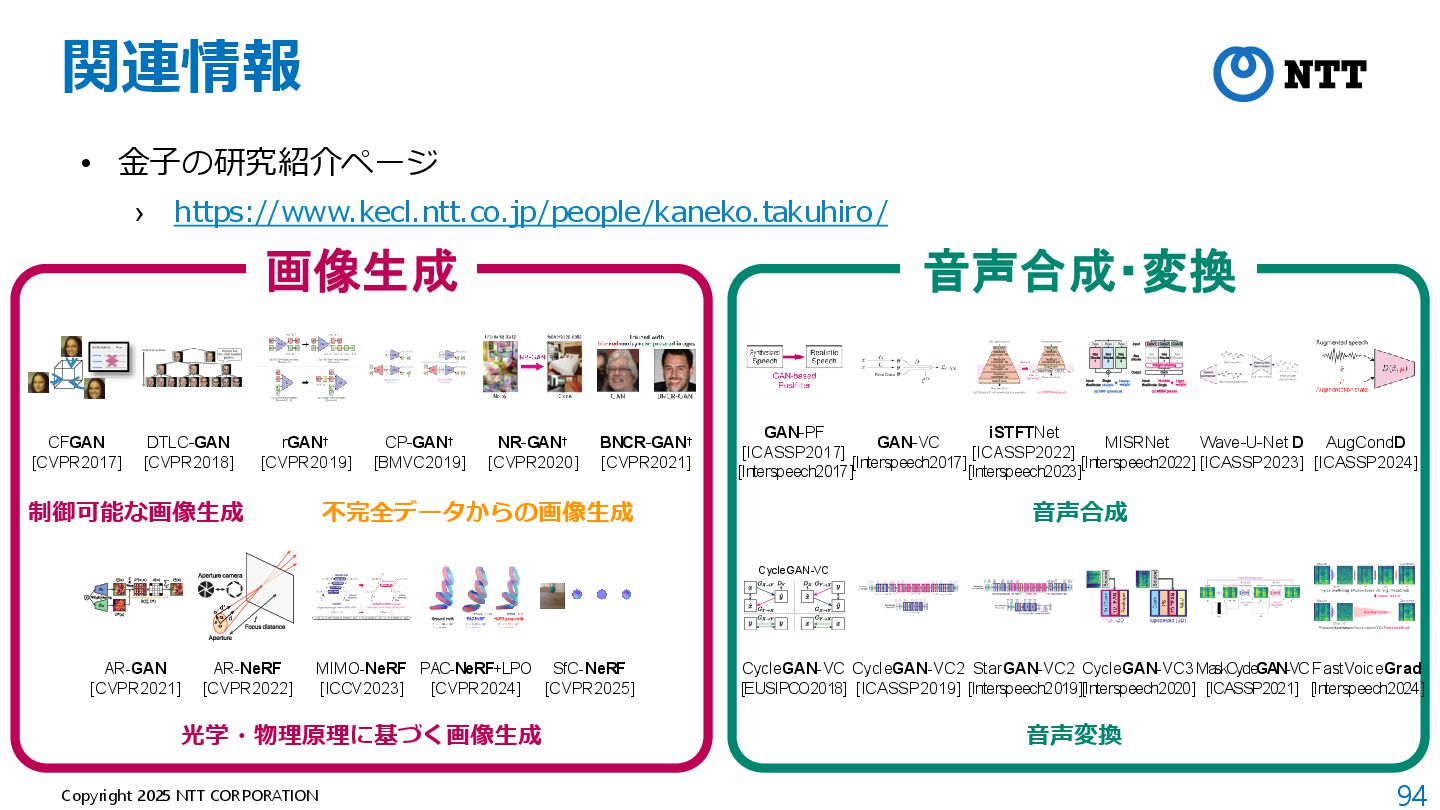
例:OpenAI Sora, Google Veo 2, Kuaishou Kling, Luma Ray2, … Q. 生成動画はどれ? X. Peng et al., “Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k,” arXiv 2025. 動画:https://github.com/hpcaitech/Open-Sora
例:OpenAI Sora, Google Veo 2, Kuaishou Kling, Luma Ray2, … X. Peng et al., “Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k,” arXiv 2025. A. 全部 by Open-Sora 2.0 動画:https://github.com/hpcaitech/Open-Sora
Bansal et al., “VideoPhy-2: A Challenging Action-Centric Physical Commonsense Evaluation in Video Generation,” arXiv 2025. Model: Wan2.1 Text Prompt: A small rock tumbles down a steep, rocky hillside, displacing soil and small stones. 重力を無視 Model: Hunyuan Text Prompt: A leaf blower is pointed at a patch of leaves on a lawn; the leaves are forcefully displaced in a specific direction. 運動量保存則を無視 Model: Sora Text Prompt: A canoeist uses a single-bladed paddle to propel their canoe across a lake, the paddle's movement visible against the still water. 反射を無視 動画:https://videophy2.github.io/
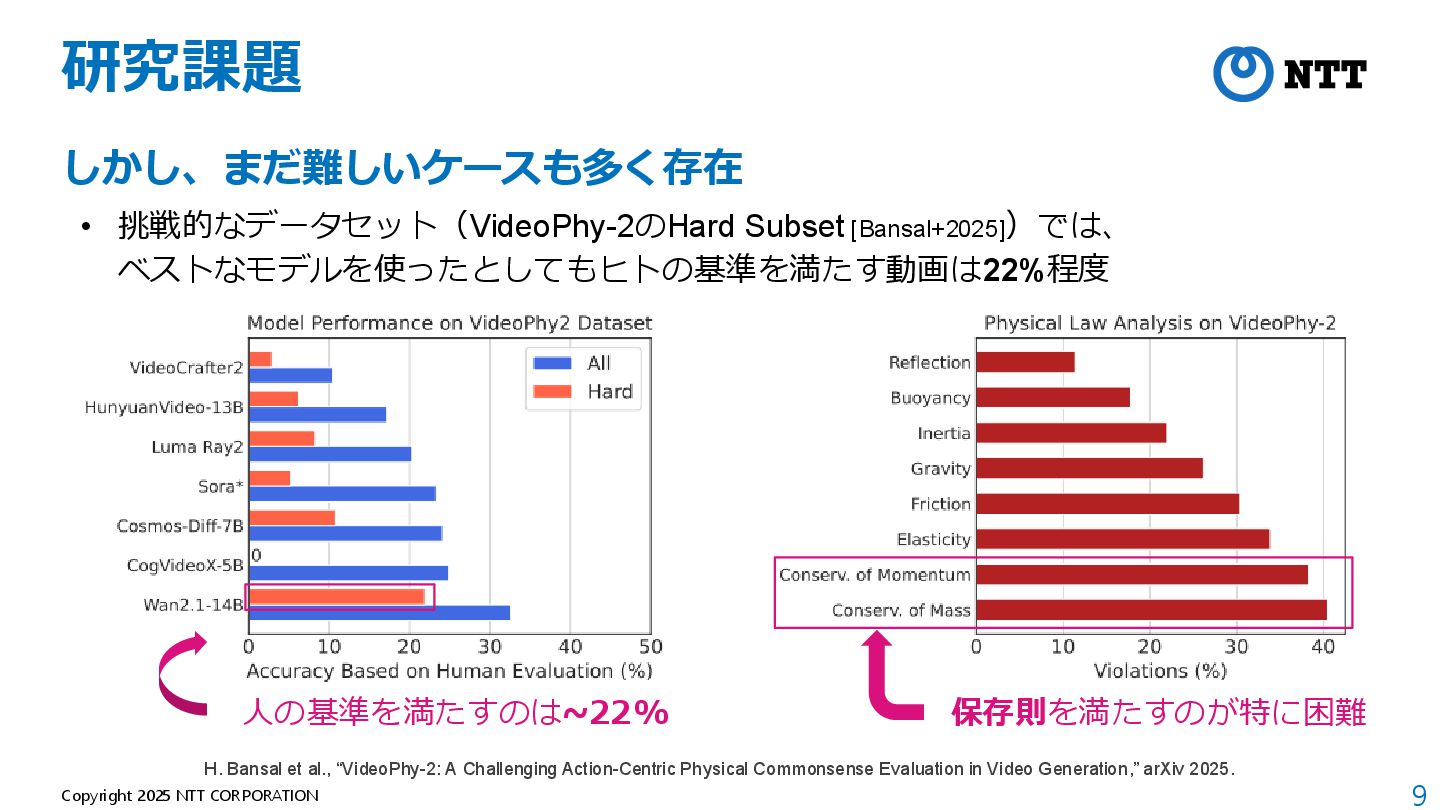
[Bansal+2025])では、 ベストなモデルを使ったとしてもヒトの基準を満たす動画は22%程度 H. Bansal et al., “VideoPhy-2: A Challenging Action-Centric Physical Commonsense Evaluation in Video Generation,” arXiv 2025. 人の基準を満たすのは~22% 保存則を満たすのが特に困難
[Bansal+2025])では、 ベストなモデルを使ったとしてもヒトの基準を満たす動画は22%程度 H. Bansal et al., “VideoPhy-2: A Challenging Action-Centric Physical Commonsense Evaluation in Video Generation,” arXiv 2025. 人の基準を満たすのは~22% 保存則を満たすのが特に困難 キーアイディア 光学・物理原理をモデルに導入しては?
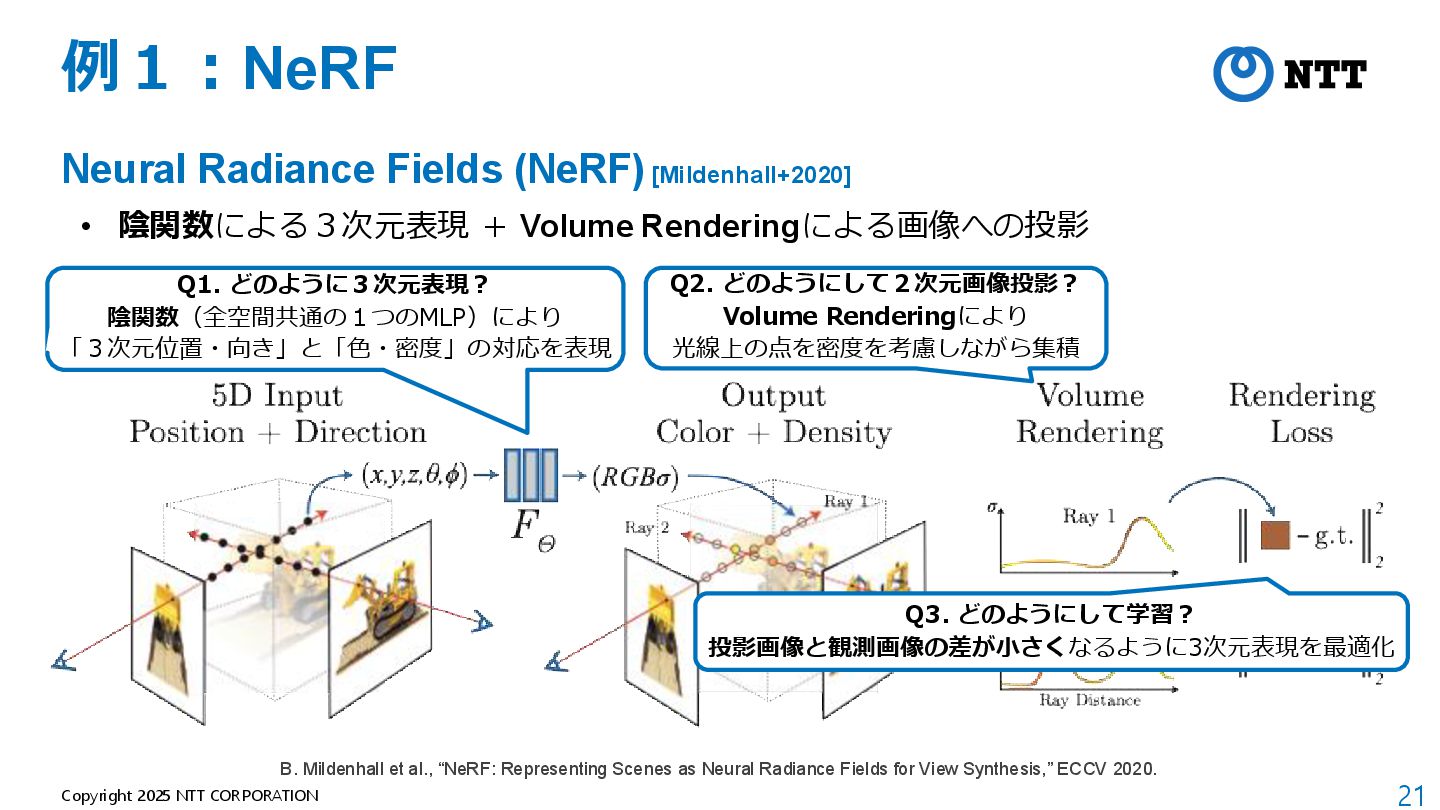
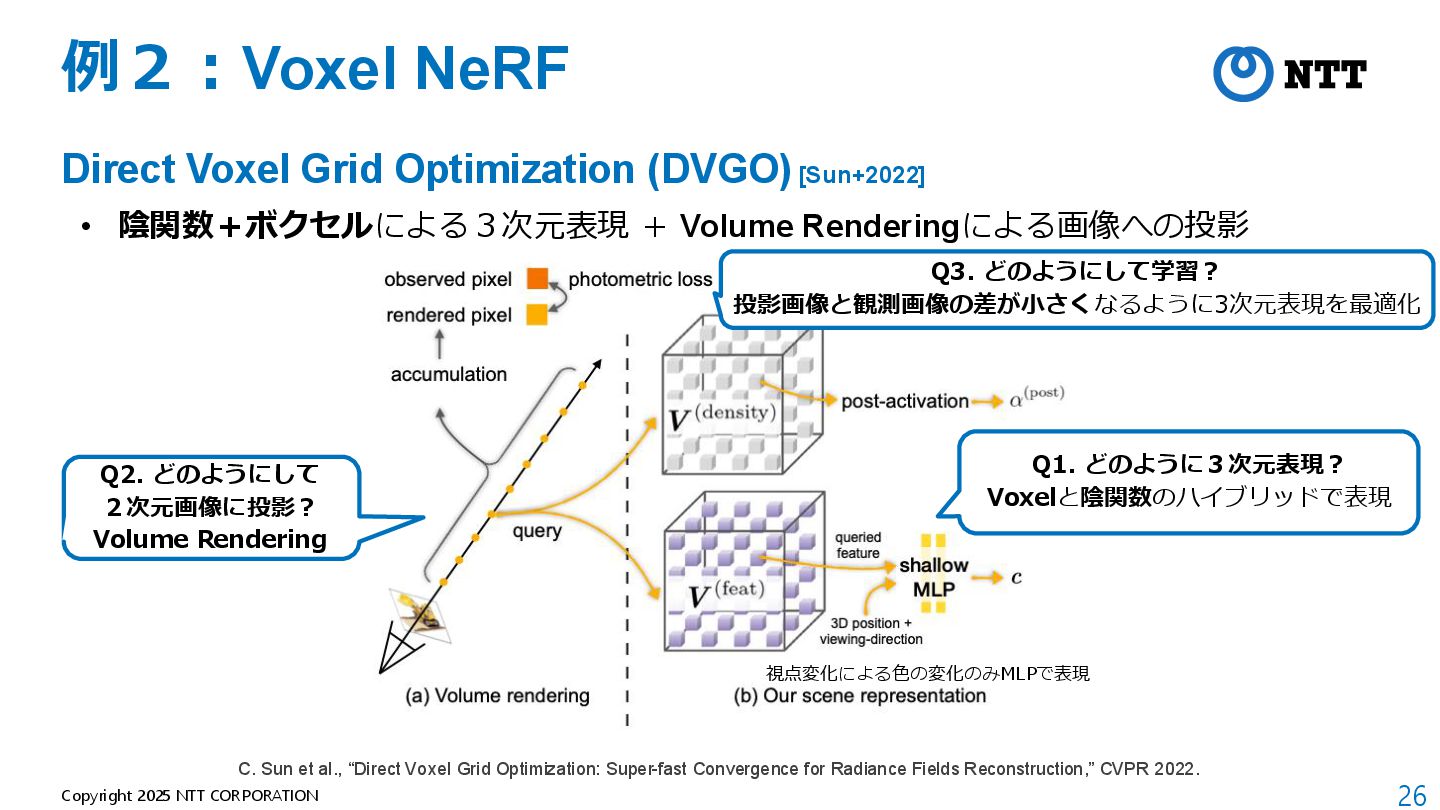
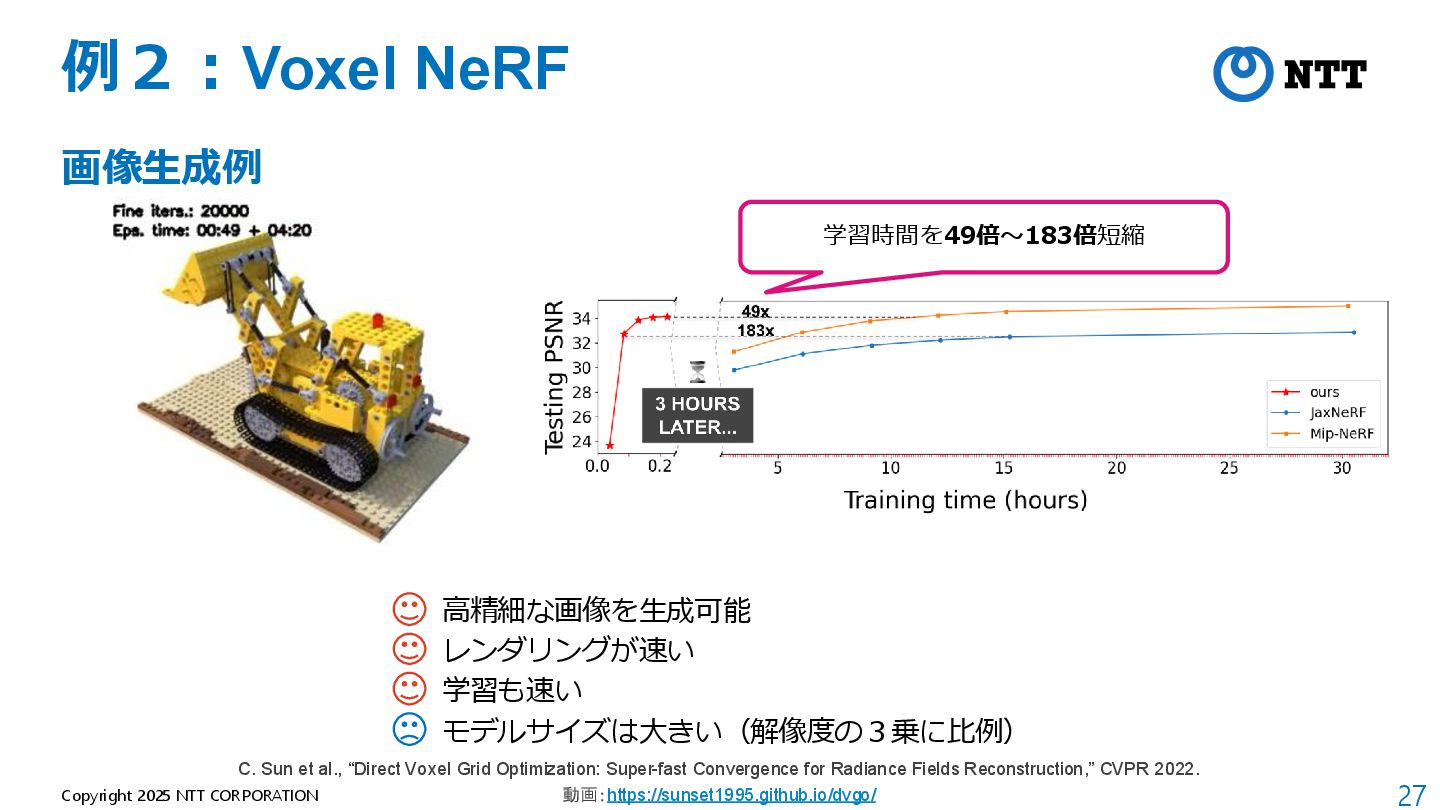
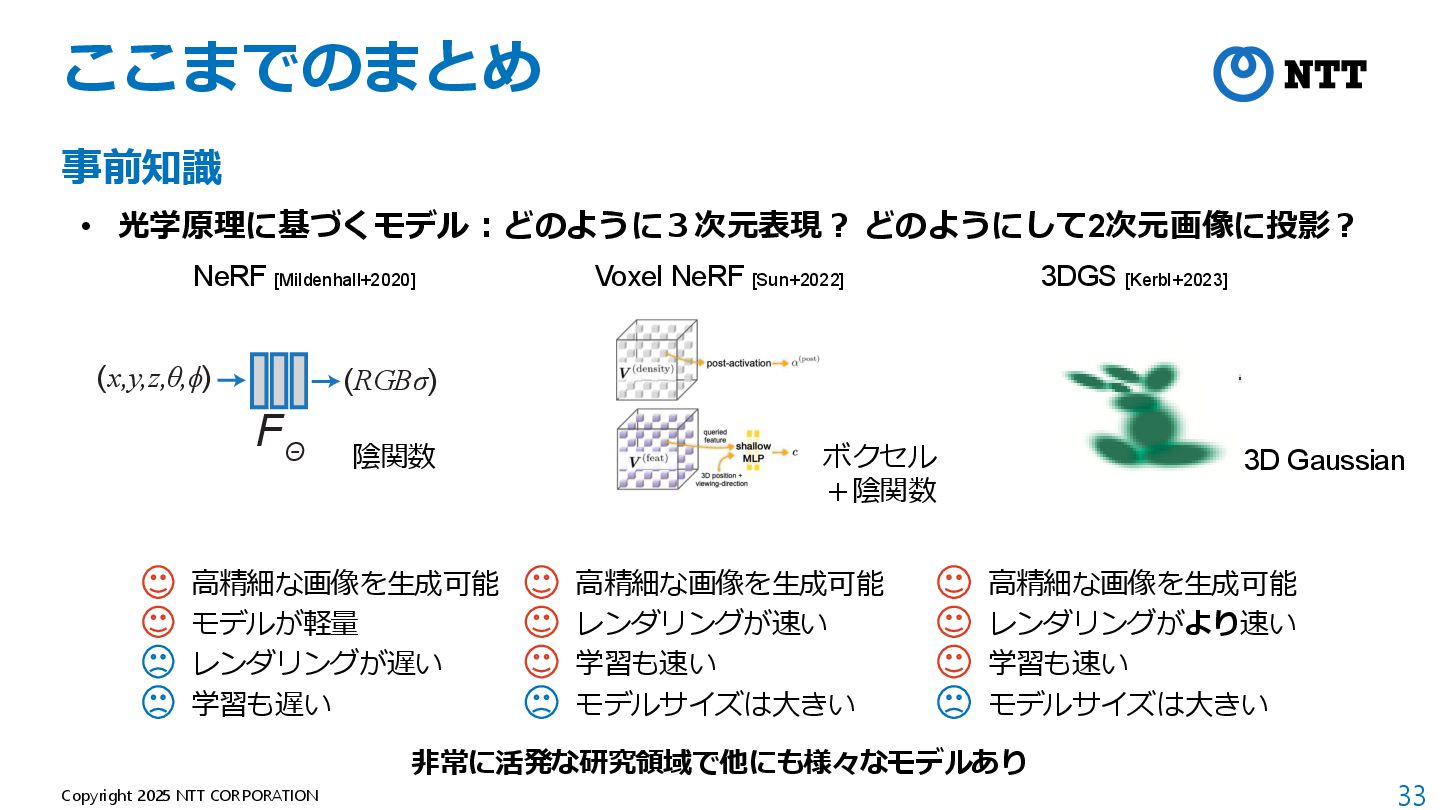
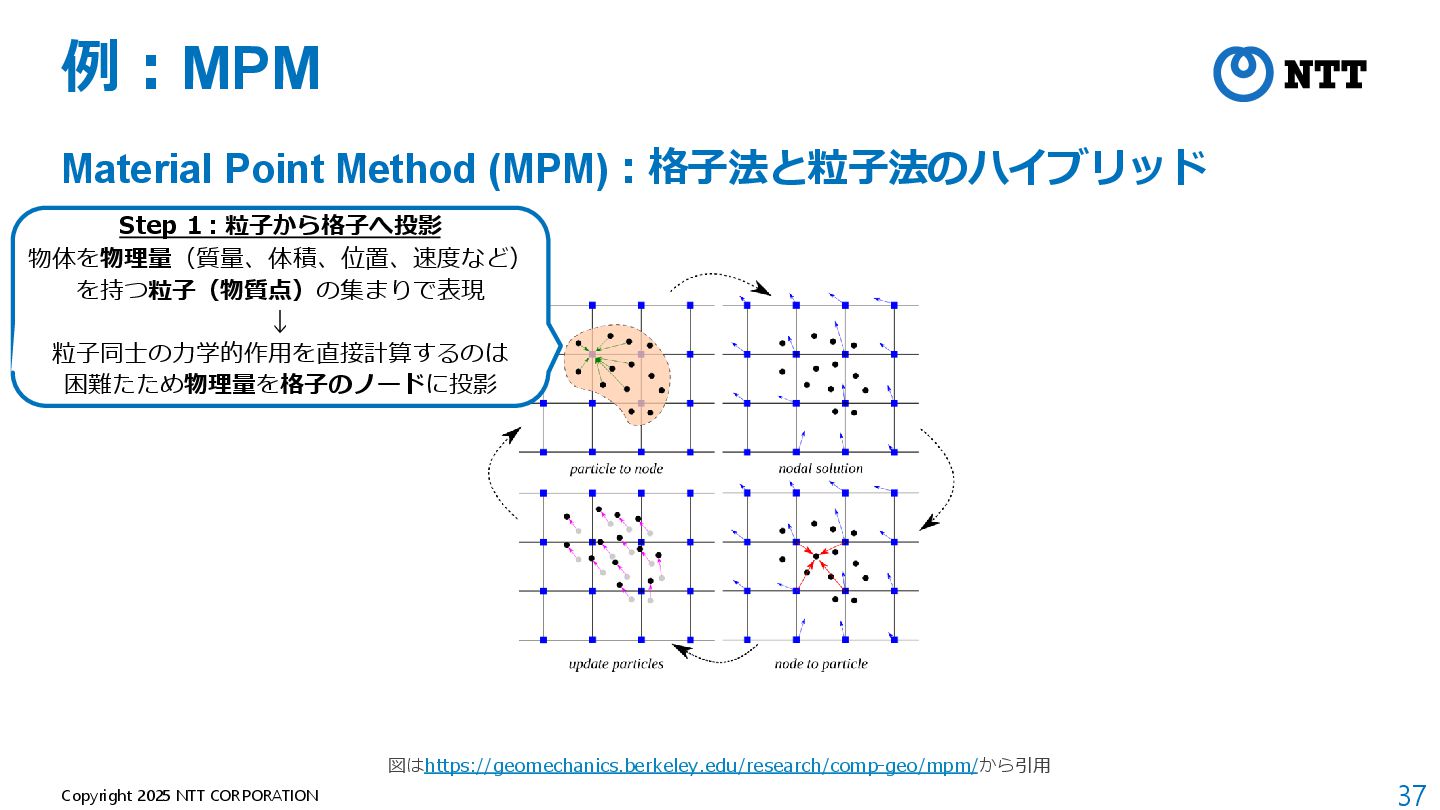
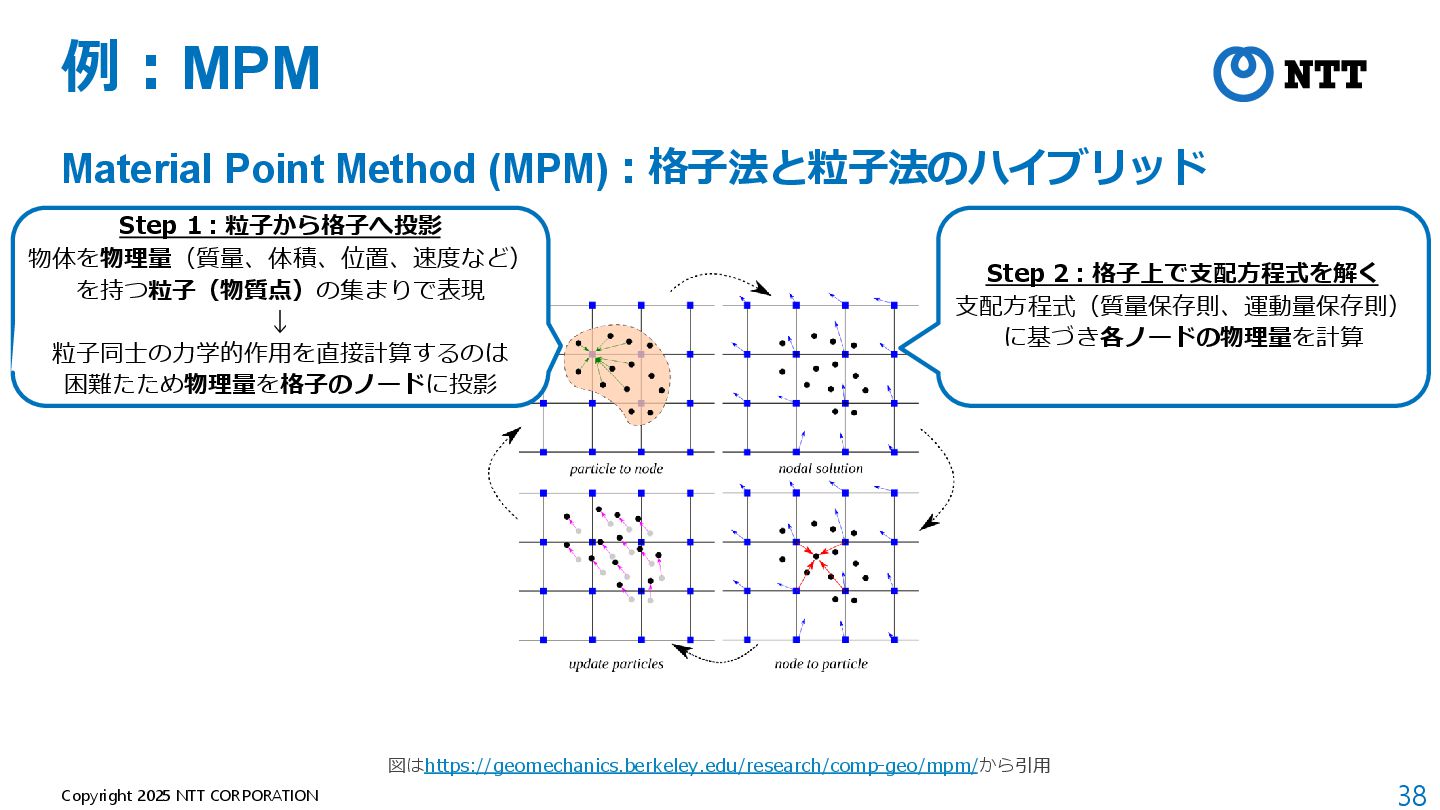
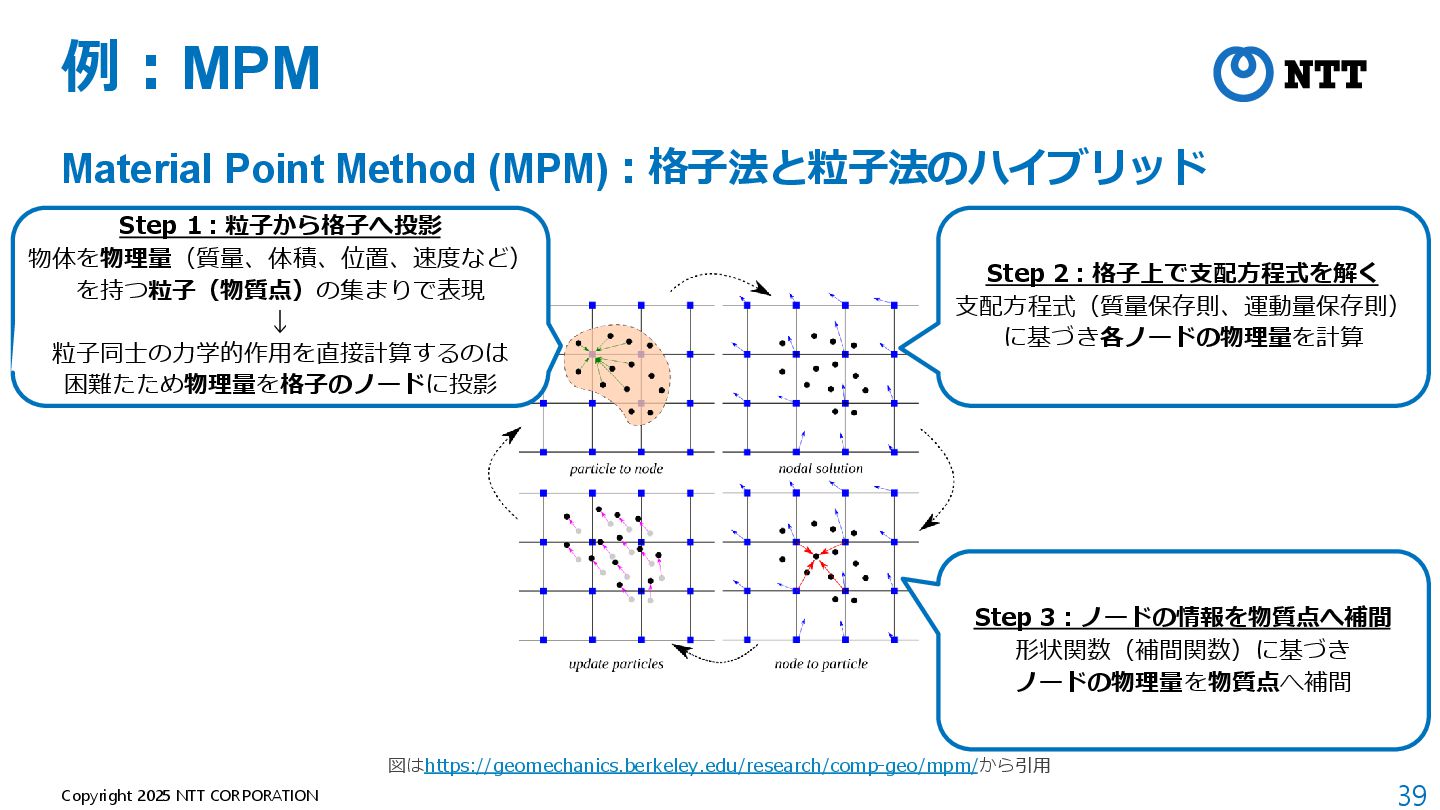
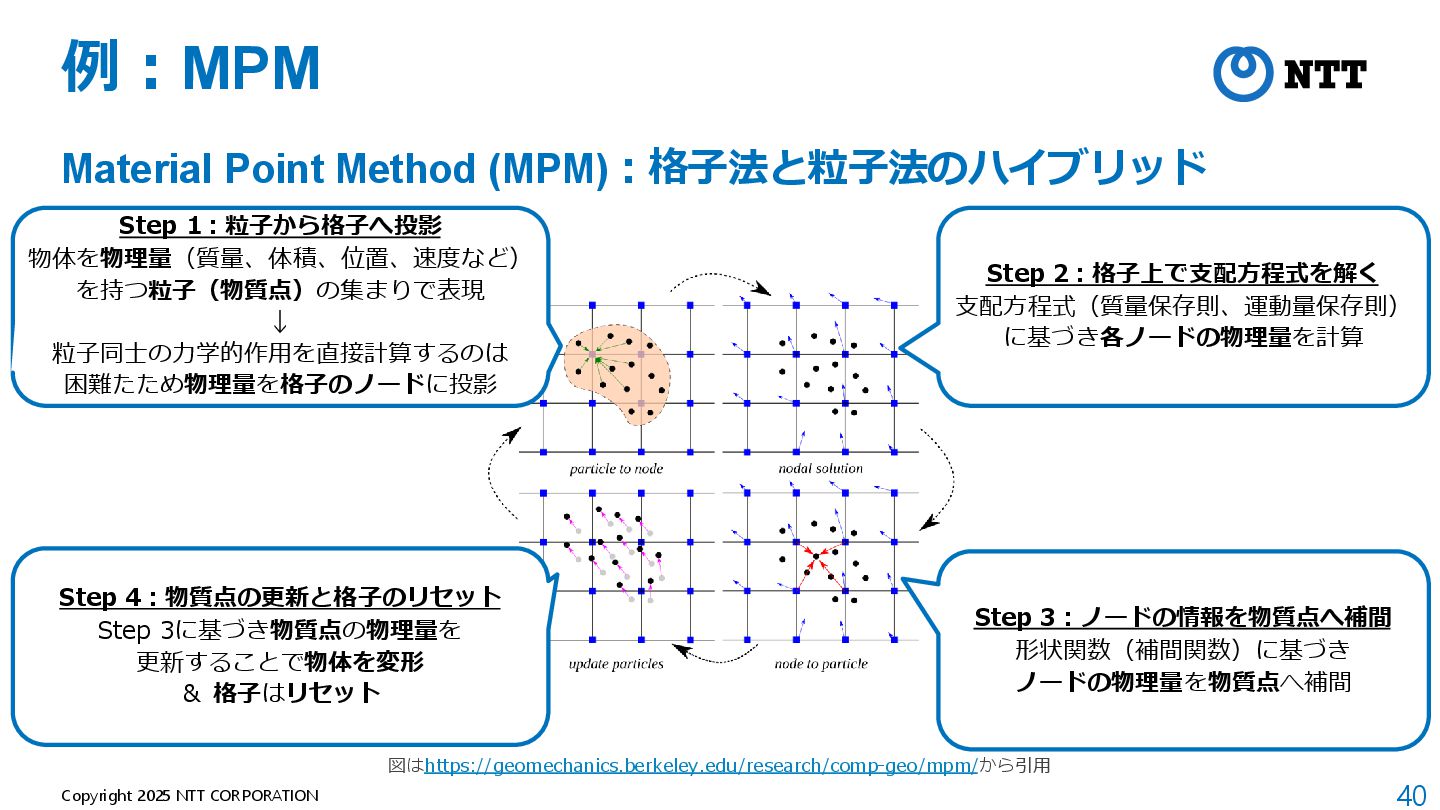
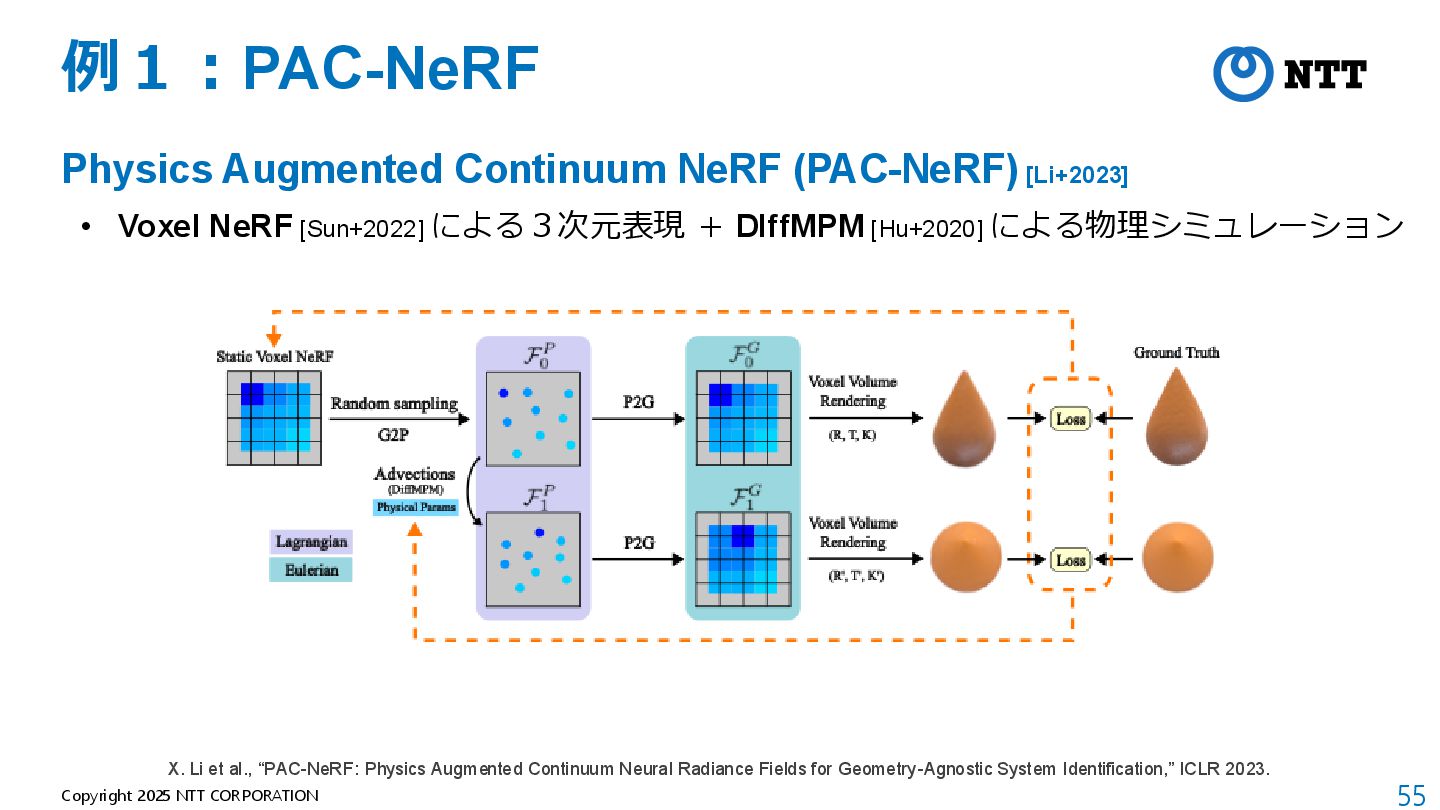
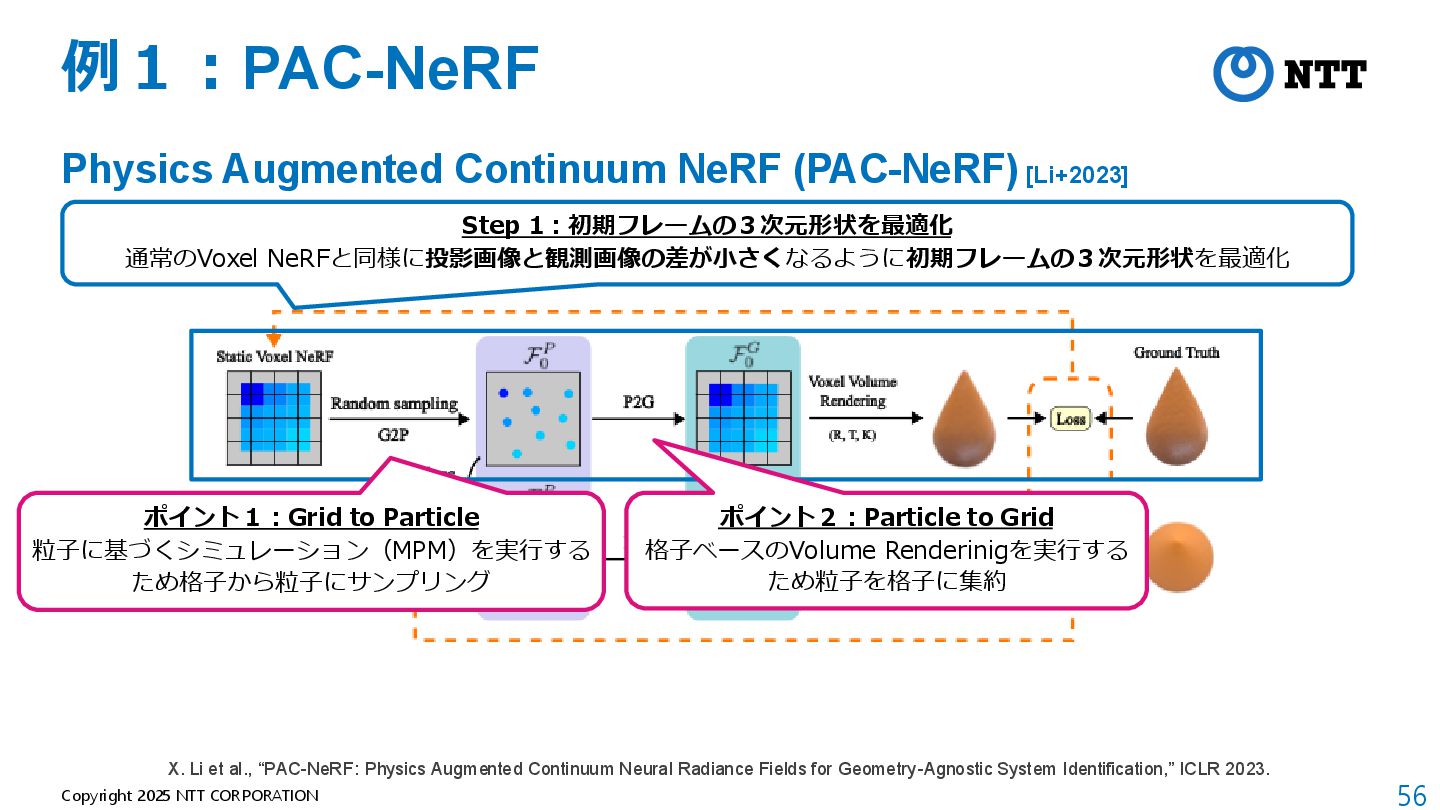
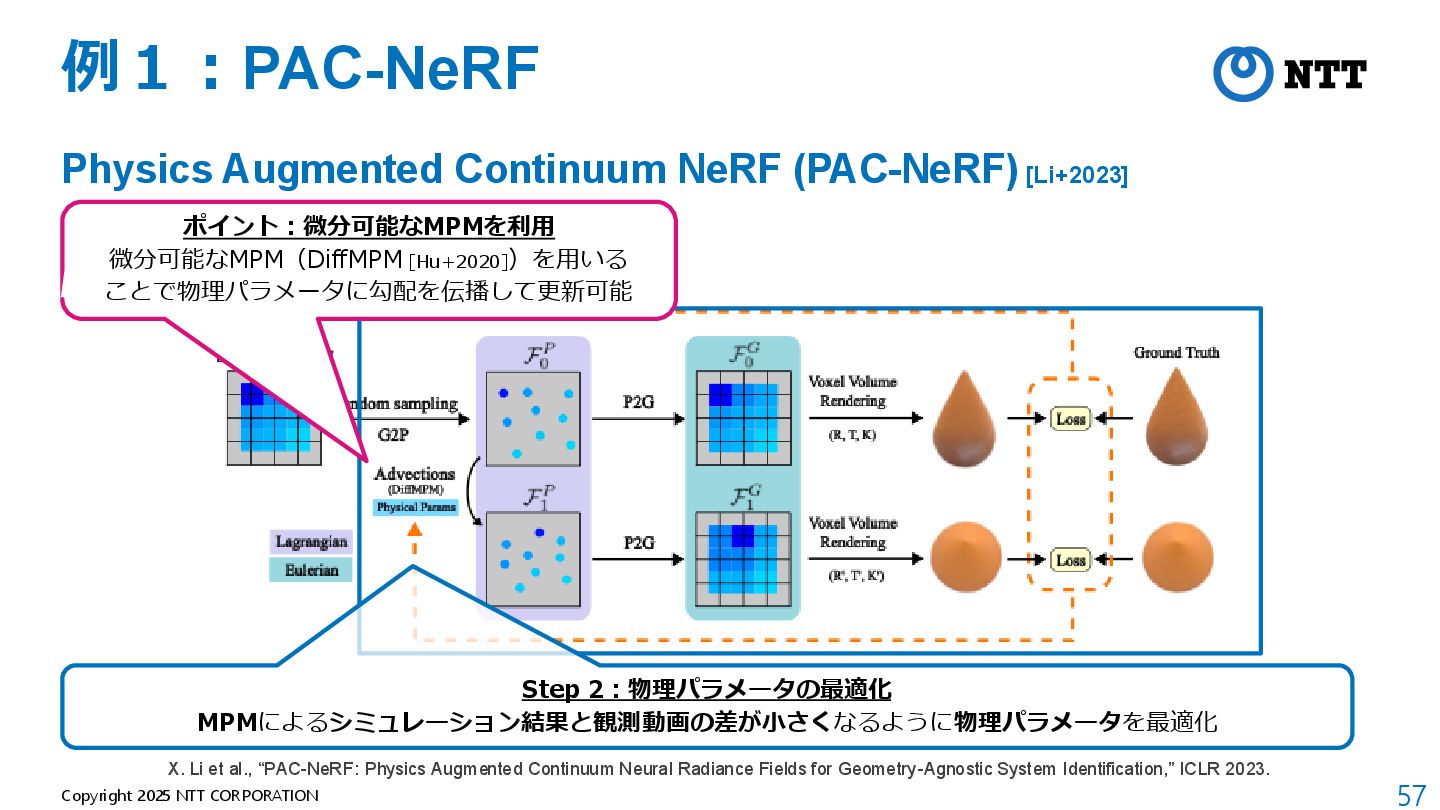
モデルが軽量(全空間共通の1つのMLPのみ) B. Mildenhall et al., “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,” ECCV 2020. 動画:https://www.matthewtancik.com/nerf
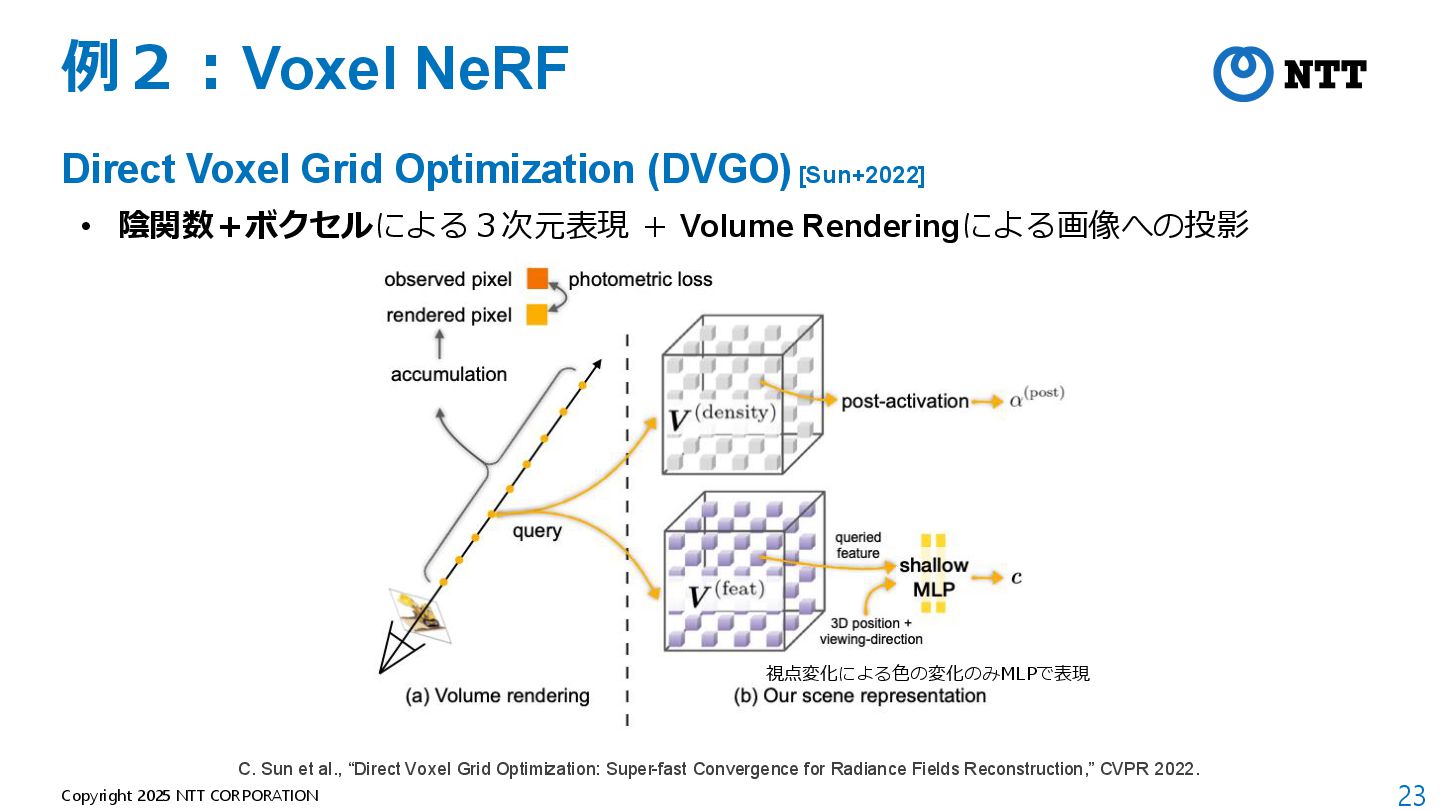
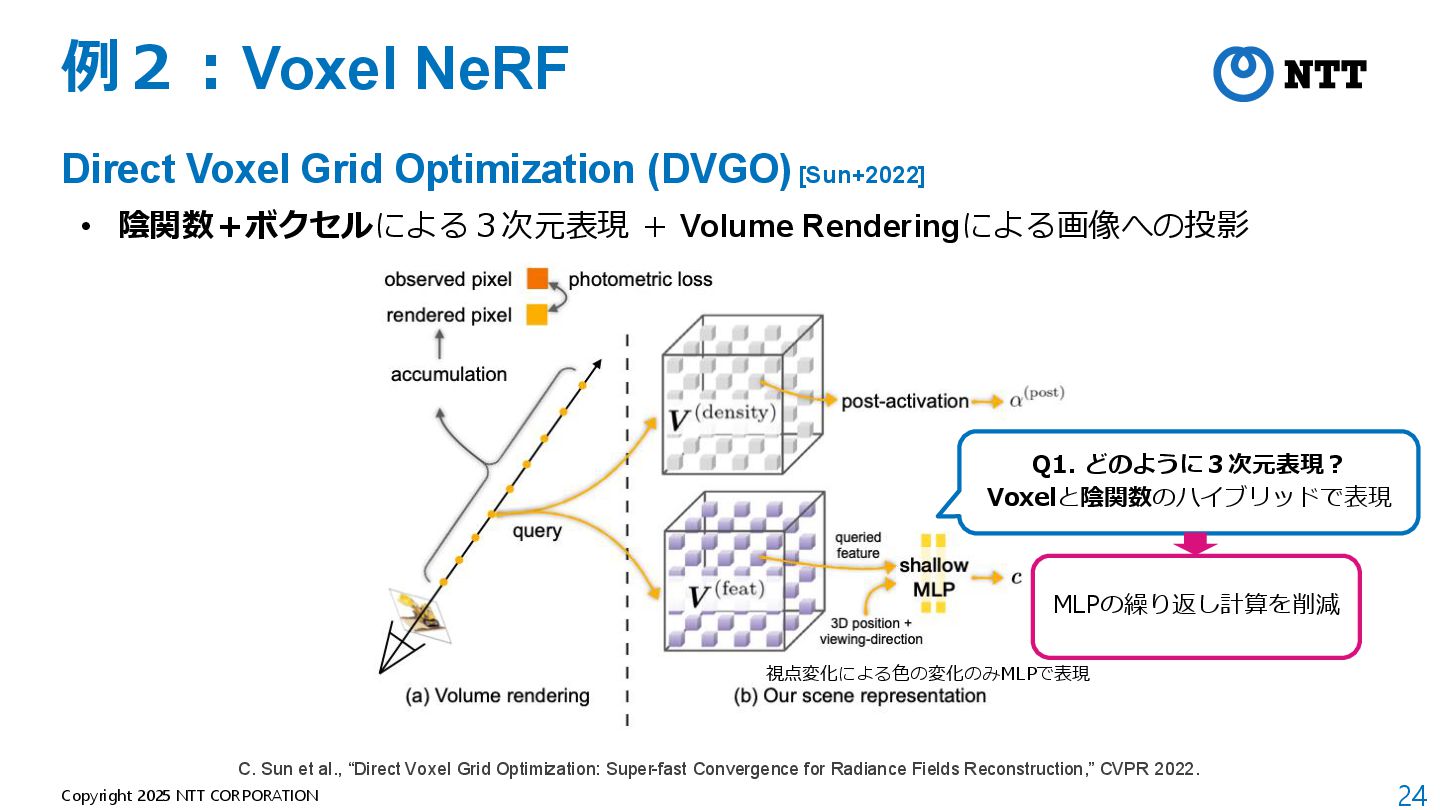
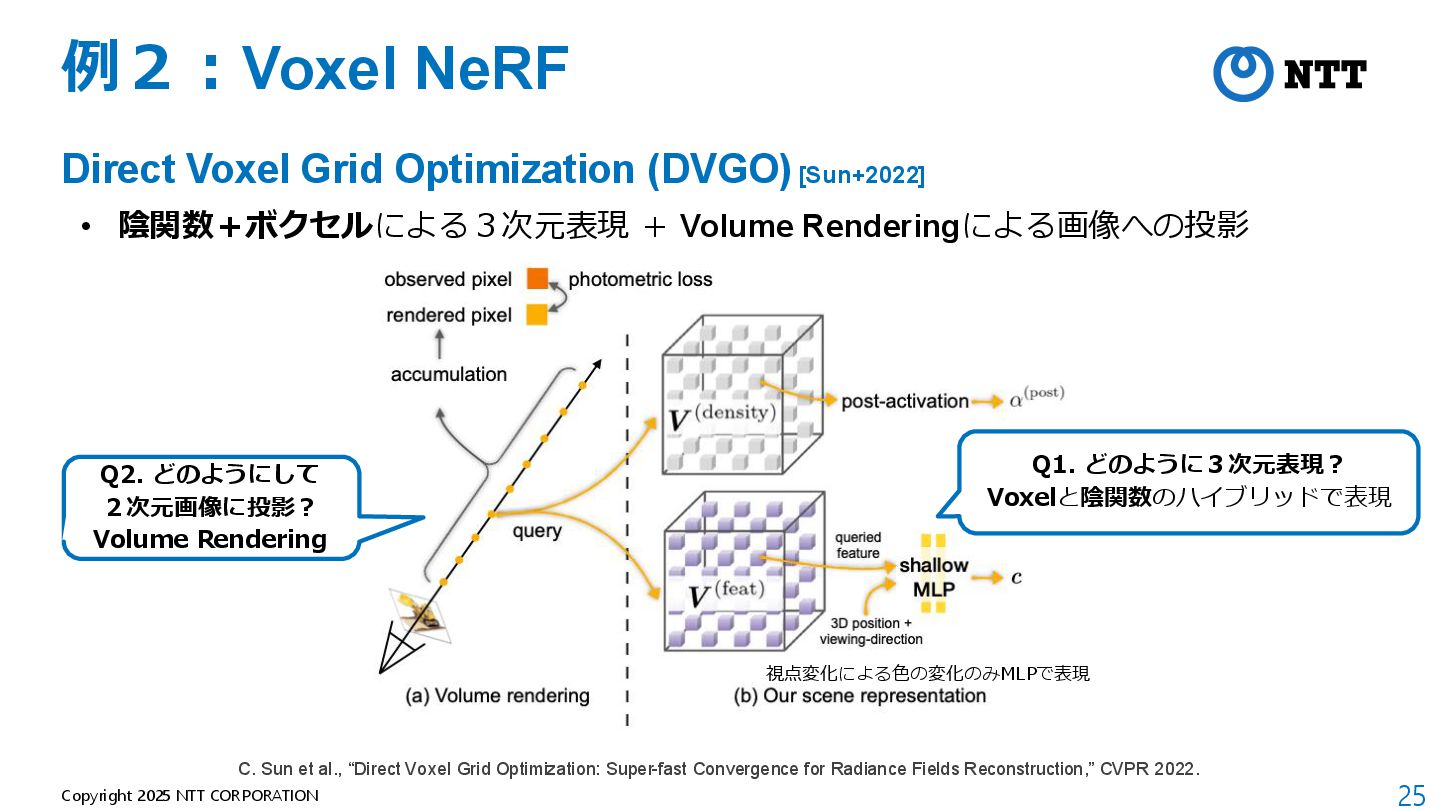
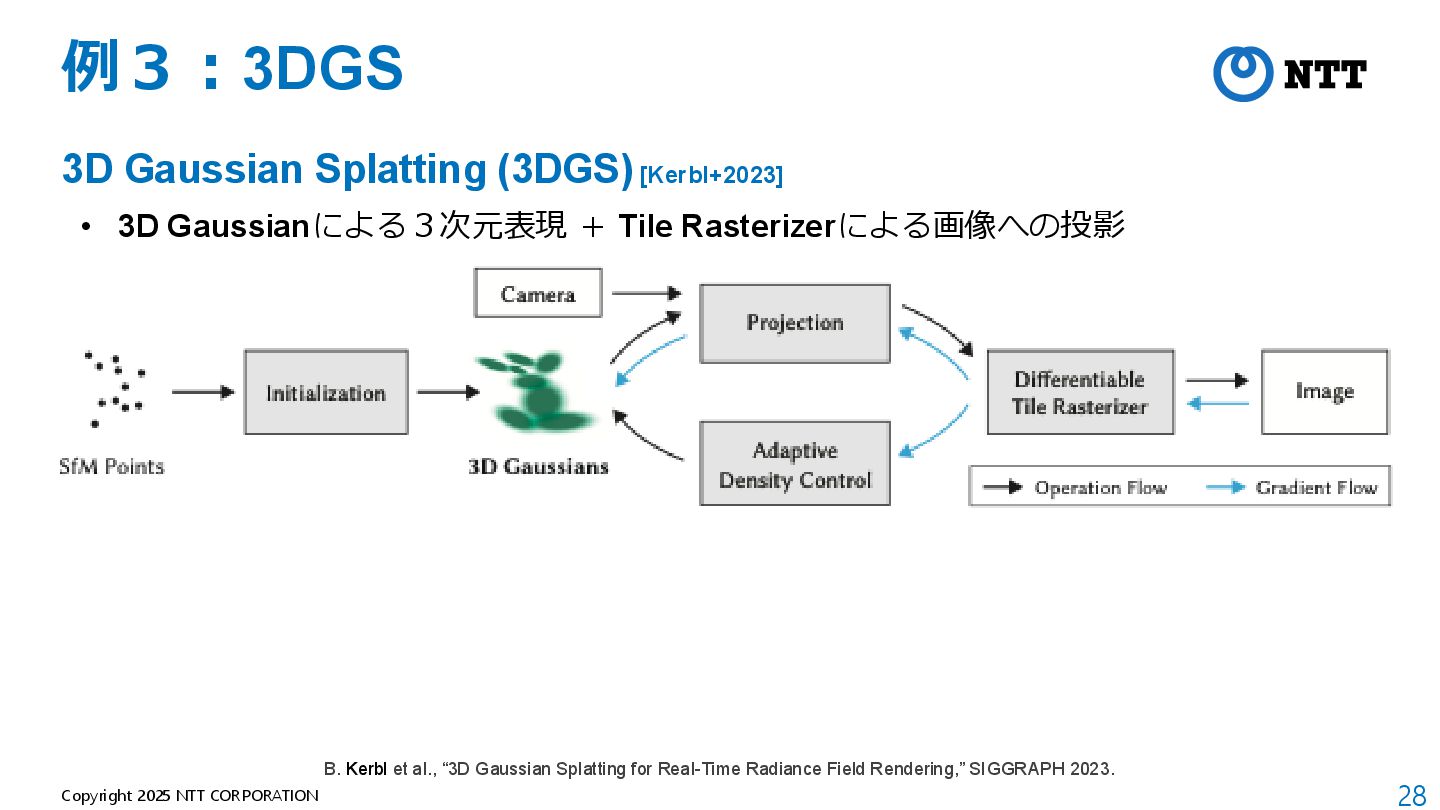
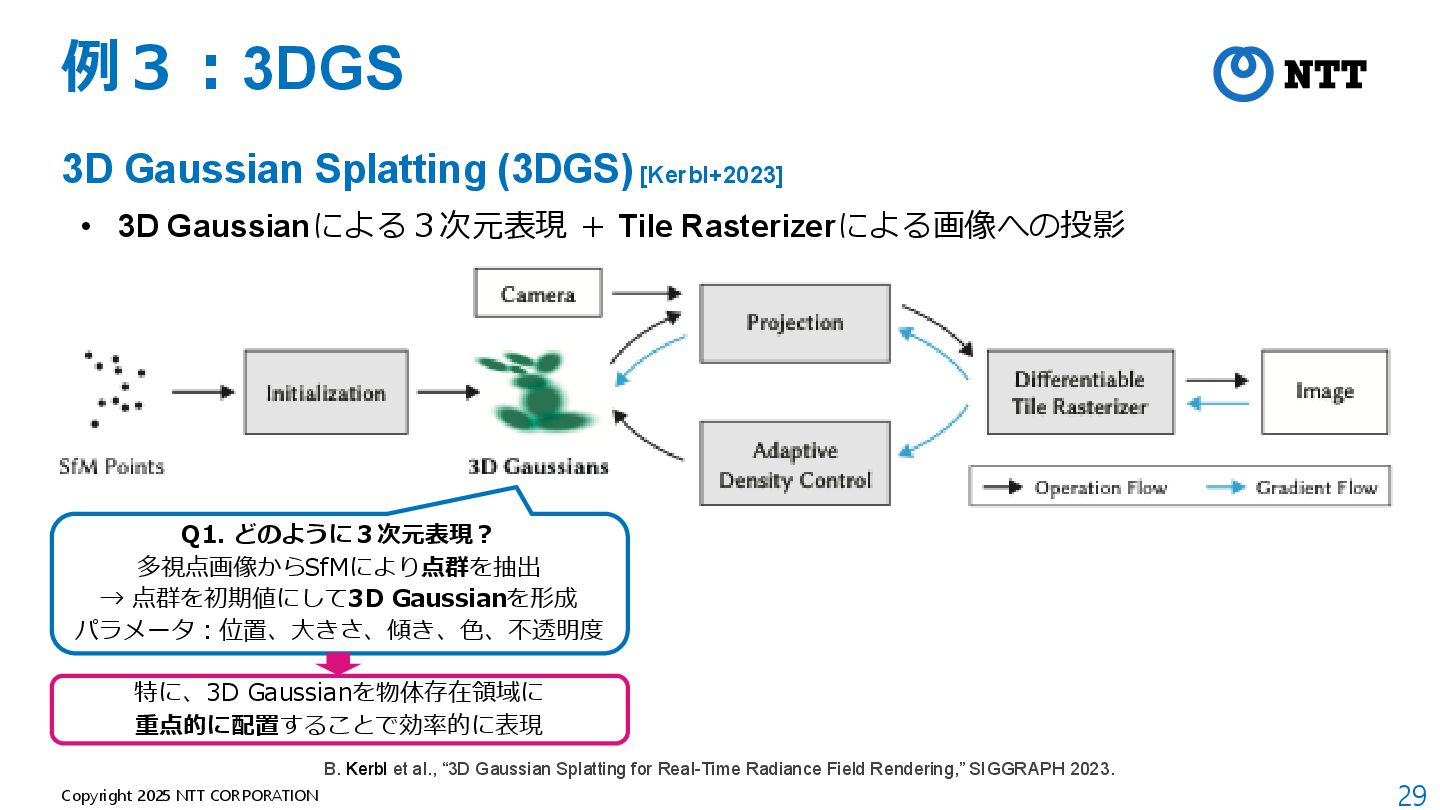
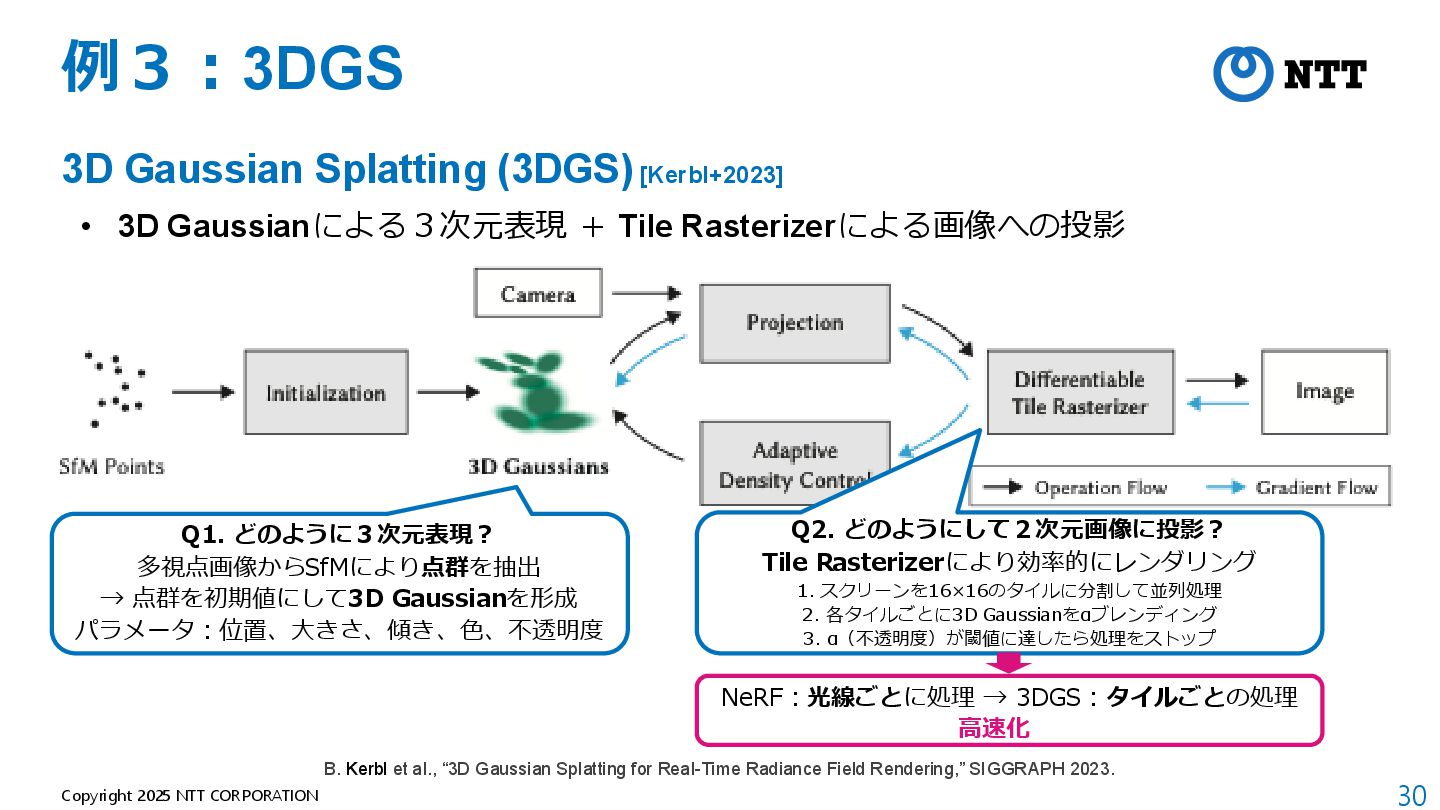
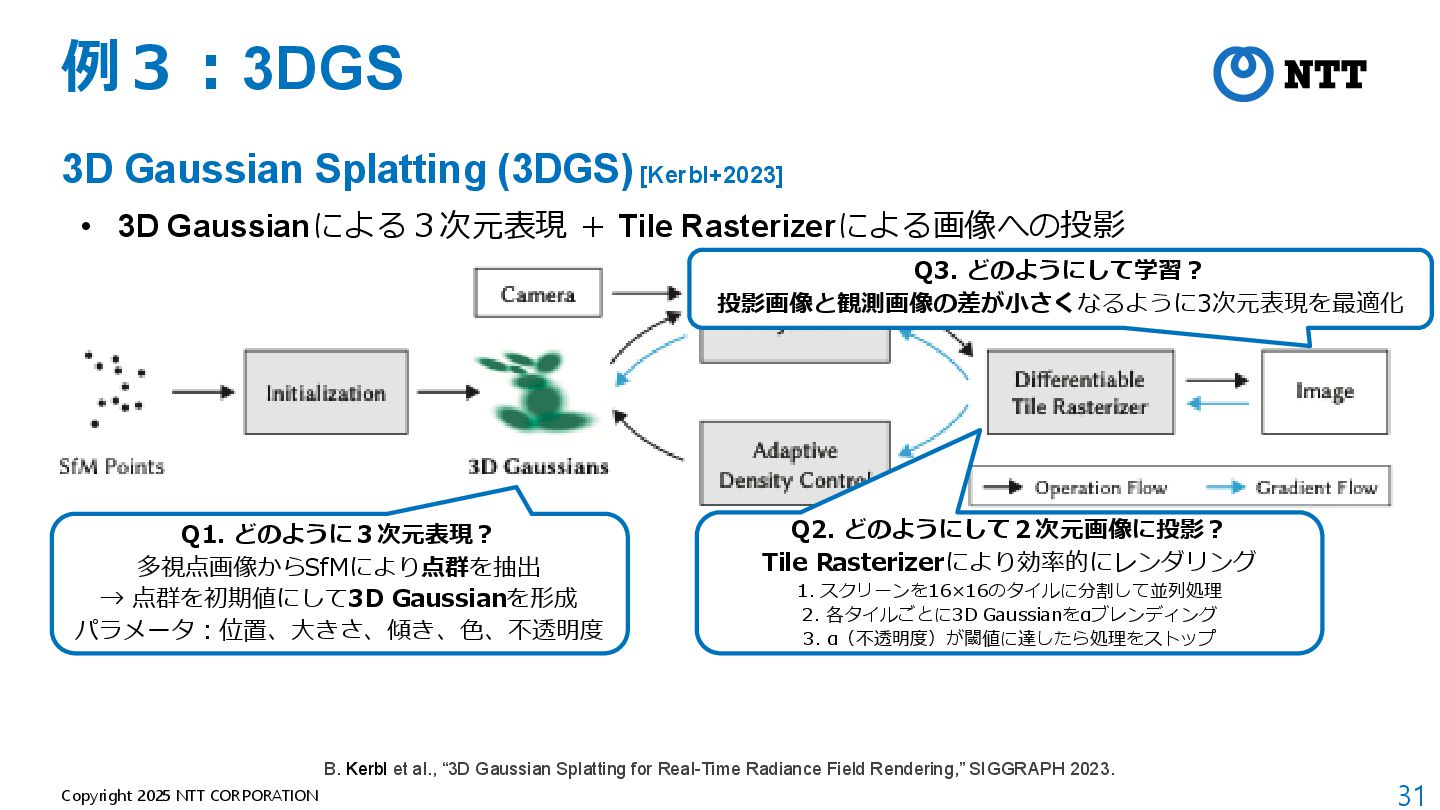
[Kerbl+2023] • 3D Gaussianによる3次元表現 + Tile Rasterizerによる画像への投影 B. Kerbl et al., “3D Gaussian Splatting for Real-Time Radiance Field Rendering,” SIGGRAPH 2023.
al., “A Moving Least Squares Material Point Method with Displacement Discontinuity and Two-Way Rigid Body Coupling,” SIGGRAPH 2018. パラメータを変えた時の挙動の比較 挙動予測 動画: https://github.com/yuanming-hu/taichi_mpm
T. Xie et al., “PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics,” CVPR 2024. Step 1:3次元表現の獲得 3D Gaussian Splattingを用いて 多視点画像から3D Gaussianを獲得
T. Xie et al., “PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics,” CVPR 2024. Step 1:3次元表現の獲得 3D Gaussian Splattingを用いて 多視点画像から3D Gaussianを獲得 Step 2:MPMの適用 3D Gaussianに対してMPMを適用し 物理シミュレーション 3D Gaussian (位置、大きさ、向き) の変形の定式化 球面調和関数 (視点依存の色)の 変形による変化も考慮
T. Xie et al., “PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics,” CVPR 2024. Step 1:3次元表現の獲得 3D Gaussian Splattingを用いて 多視点画像から3D Gaussianを獲得 Step 3:動画の生成 3次元的な物理シミュレーションの 結果を画像に投影して動画を生成 Step 2:MPMの適用 3D Gaussianに対してMPMを適用し 物理シミュレーション
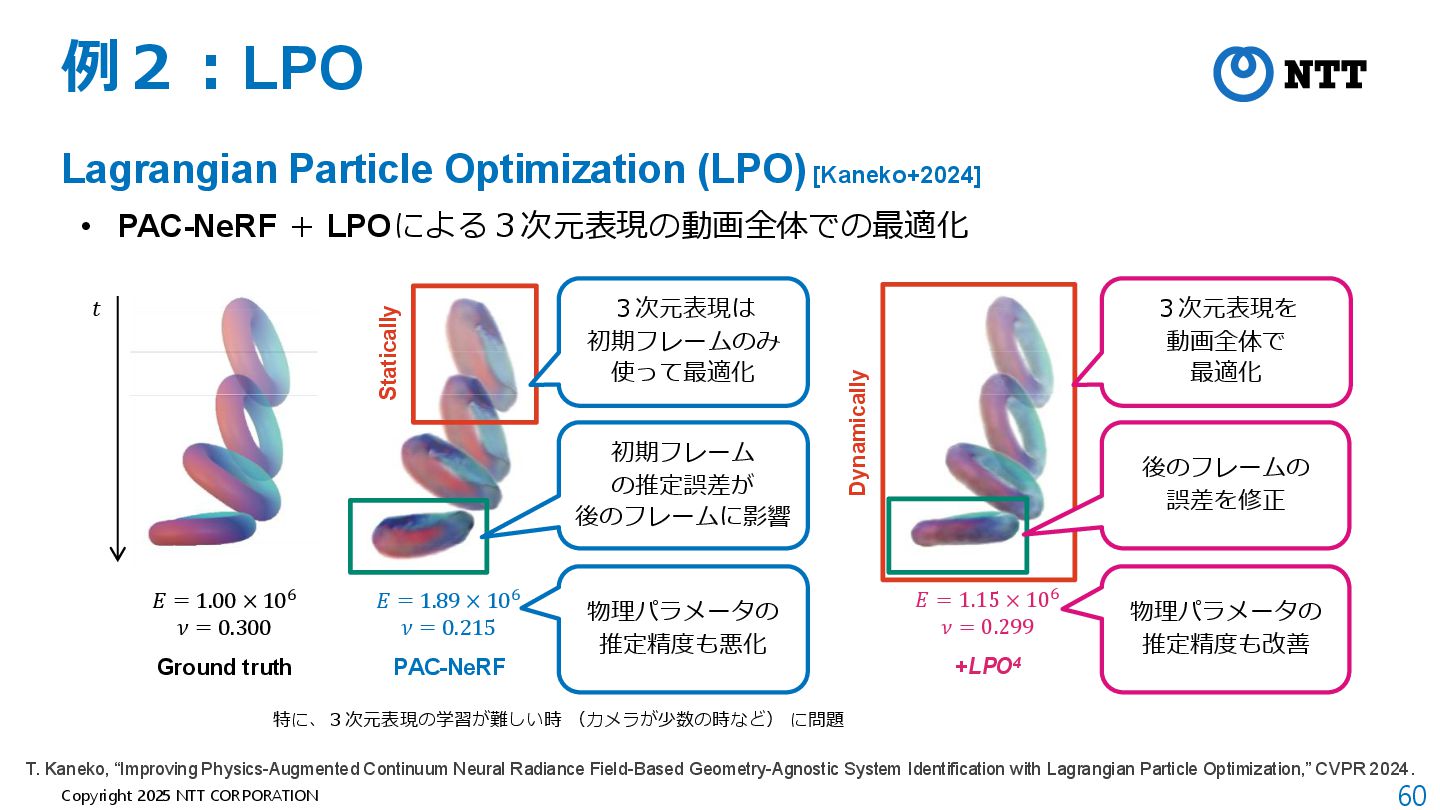
• アプリケーション:未来予測、物理量を変えた時のシミュレーションなど J. Cai et al., “GIC: Gaussian-Informed Continuum for Physical Property Identification and Simulation,” NeurIPS 2024. 真値 再構成 + 未来予測 硬質化 重力ゼロ化 動画:https://jukgei.github.io/project/gic/
• 3DGS [Kerbl+2023] による3次元表現 + MPMによる物理シミュレーション J. Cai et al., “GIC: Gaussian-Informed Continuum for Physical Property Identification and Simulation,” NeurIPS 2024.
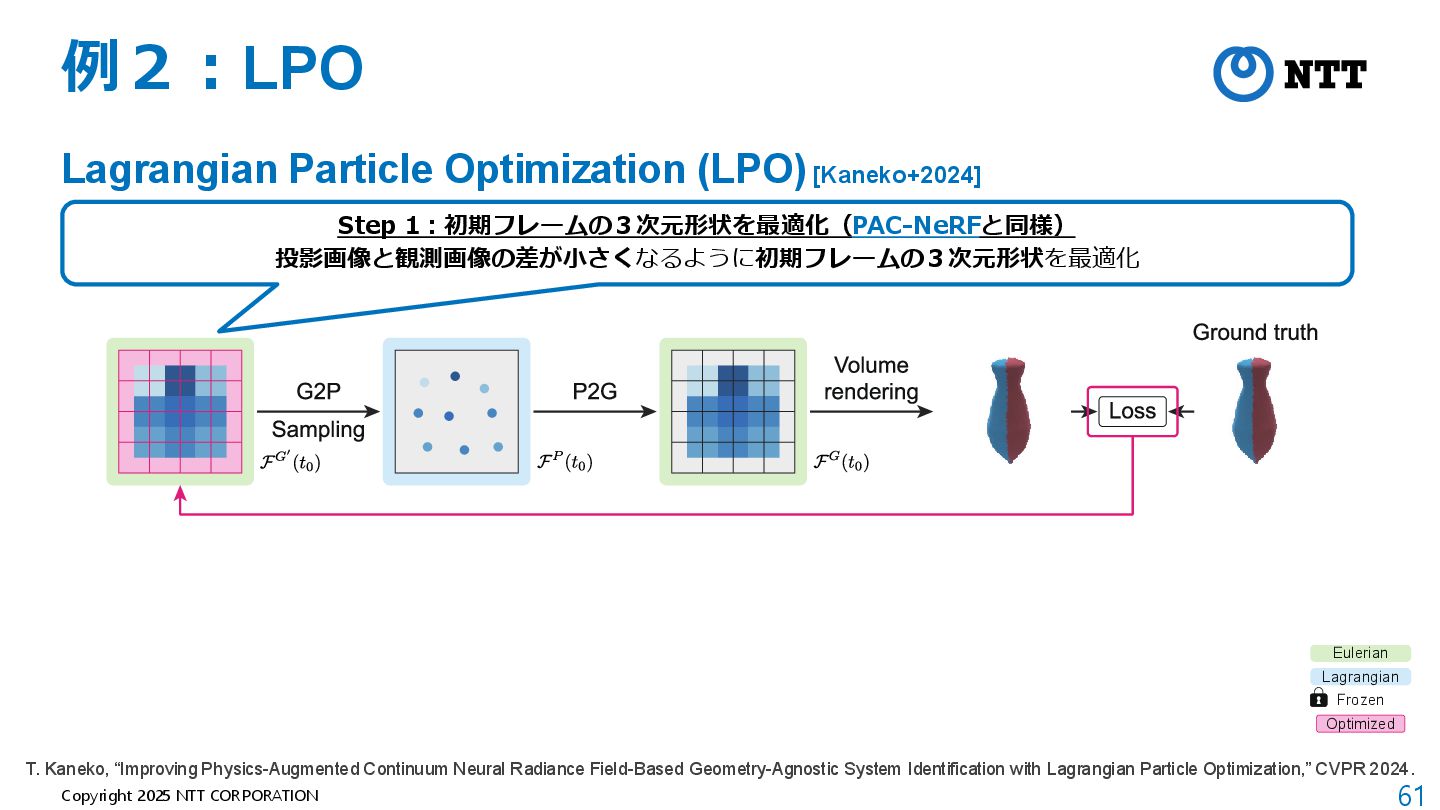
J. Cai et al., “GIC: Gaussian-Informed Continuum for Physical Property Identification and Simulation,” NeurIPS 2024. Step 1:動画全体で3次元形状を最適化 モーション分解型動的3D Gaussian Networkを使って投影動画と観測動画の差が小さくなるように3D Gaussianを最適化 ポイント1:モーションを複数の基底の集合で表現 ポイント2: モーションの 差分をモデル化
J. Cai et al., “GIC: Gaussian-Informed Continuum for Physical Property Identification and Simulation,” NeurIPS 2024. Step 2:連続体の算出と表面の抽出 物理シミュレーションを行うため連続体を算出、また、表面も抽出し目的関数の算出に利用
J. Cai et al., “GIC: Gaussian-Informed Continuum for Physical Property Identification and Simulation,” NeurIPS 2024. Step 3:物理パラメータの最適化 MPMによるシミュレーション結果と対象データの差が小さくなるように物理パラメータを最適化 ポイント 物体の2次元マスクに加えて 3次元表面も一致するようにすることで 高精度化
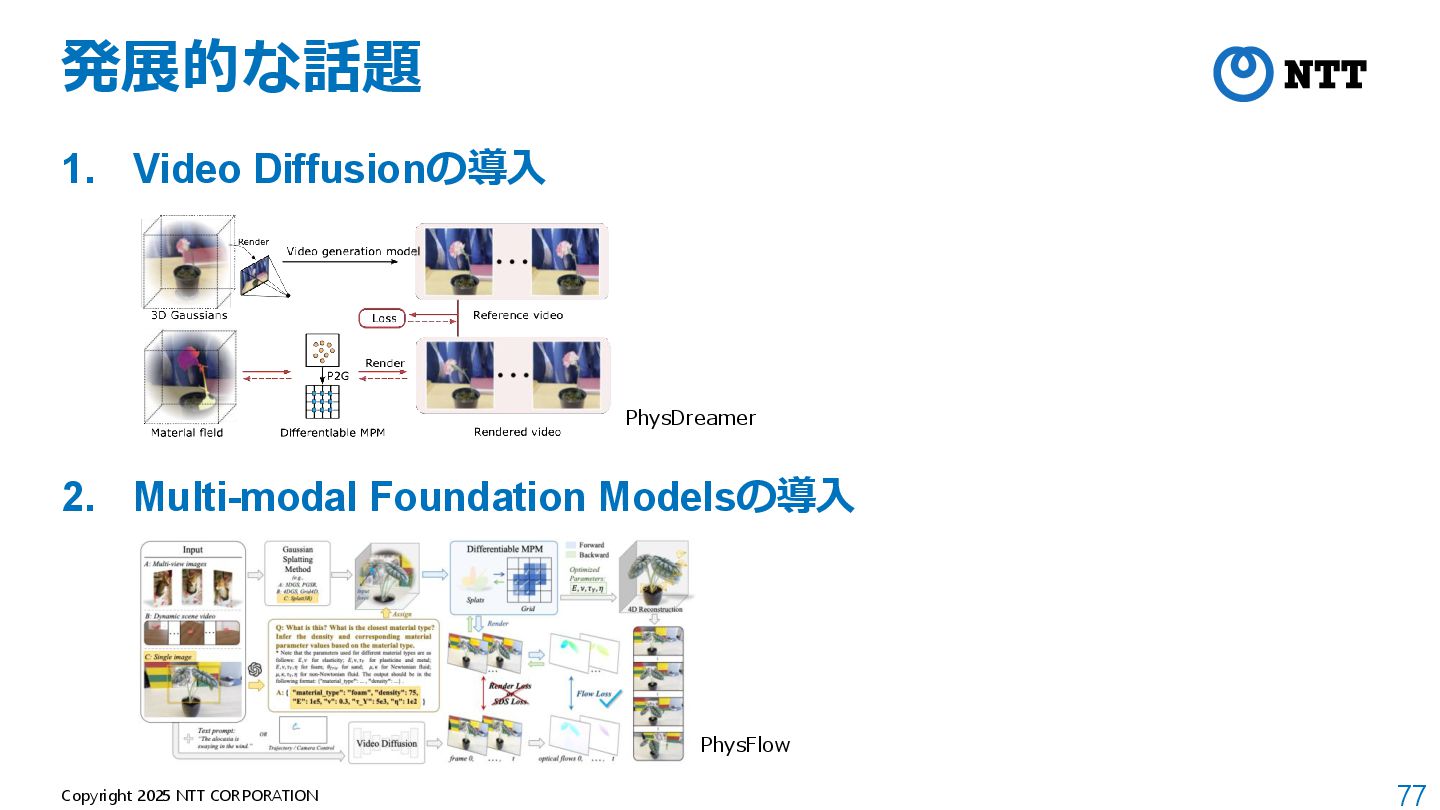
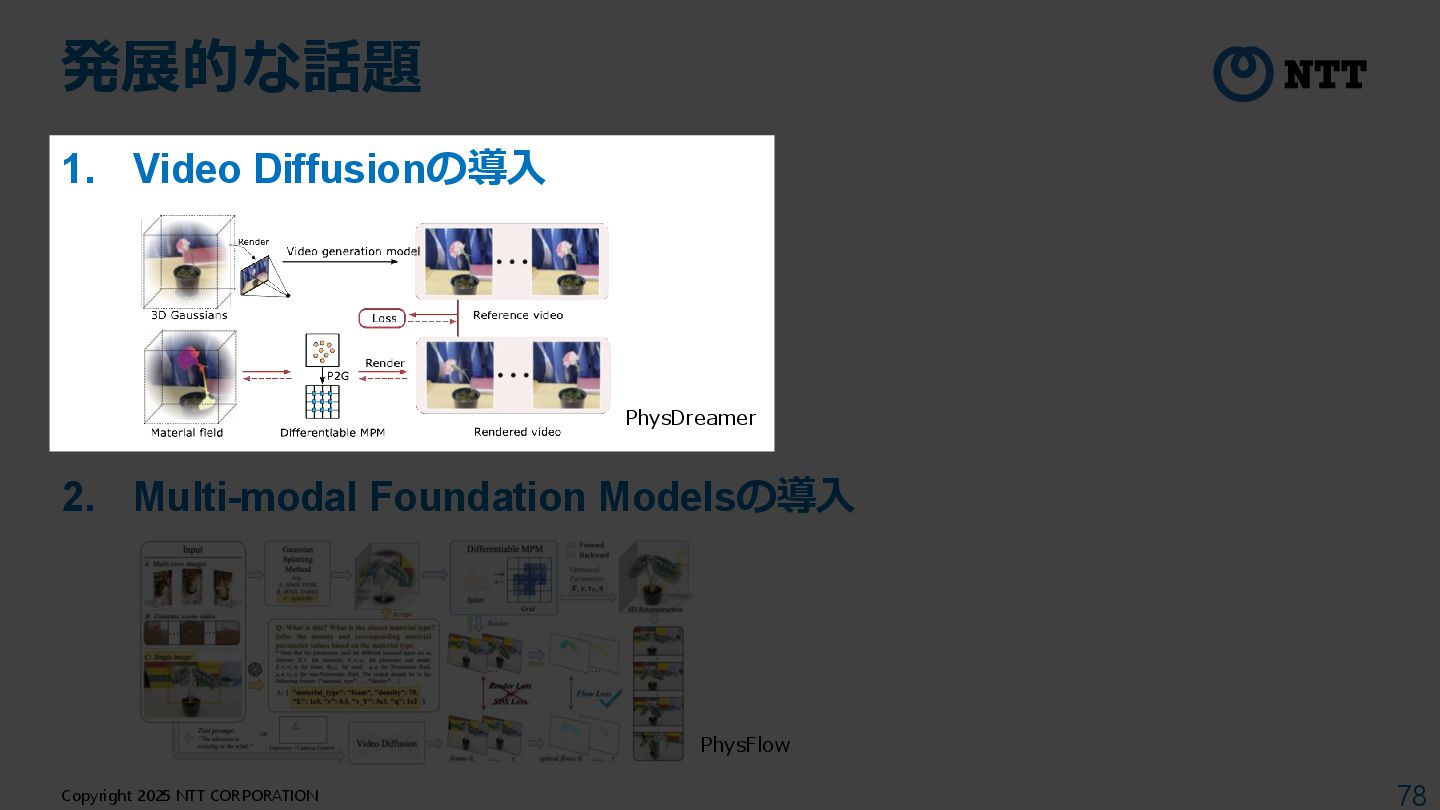
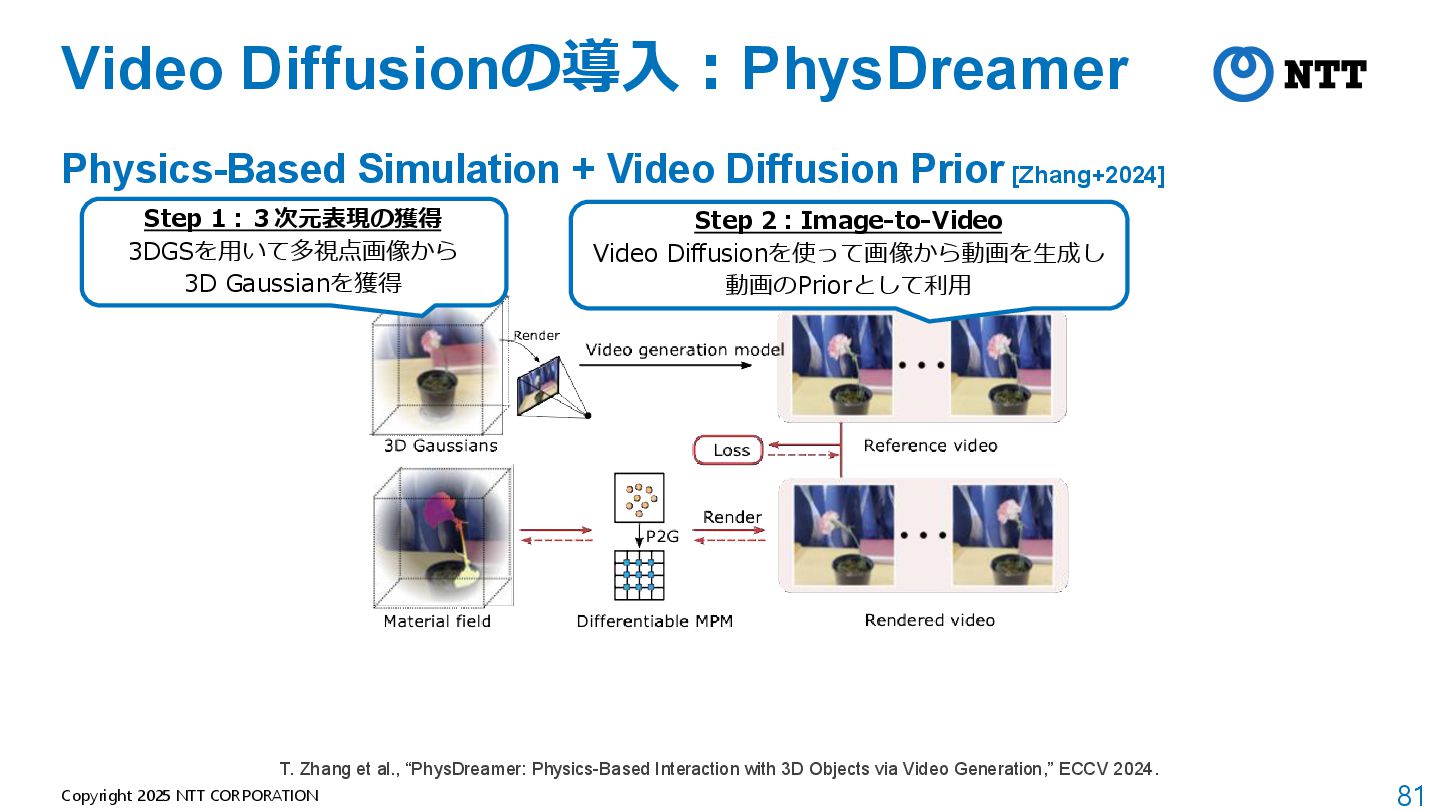
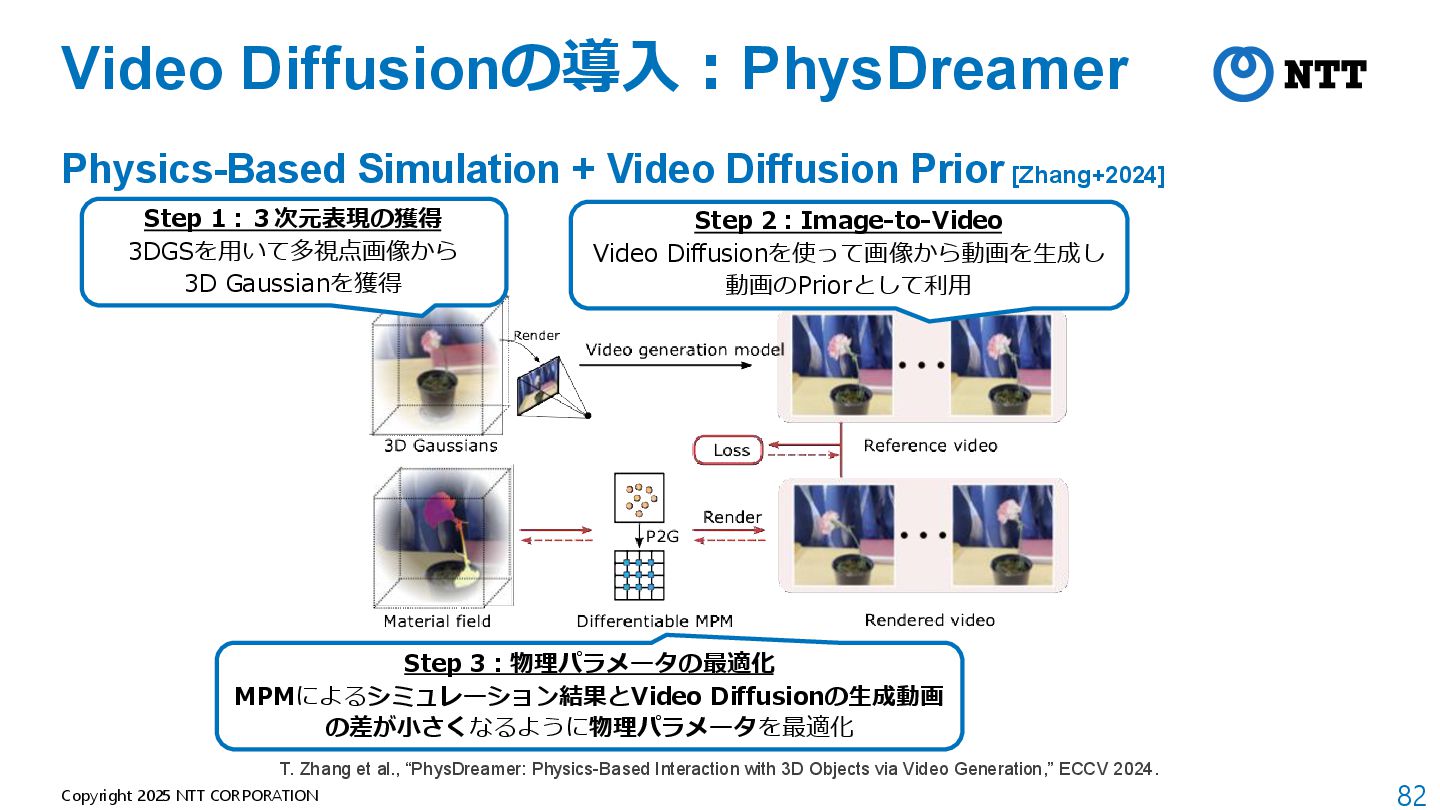
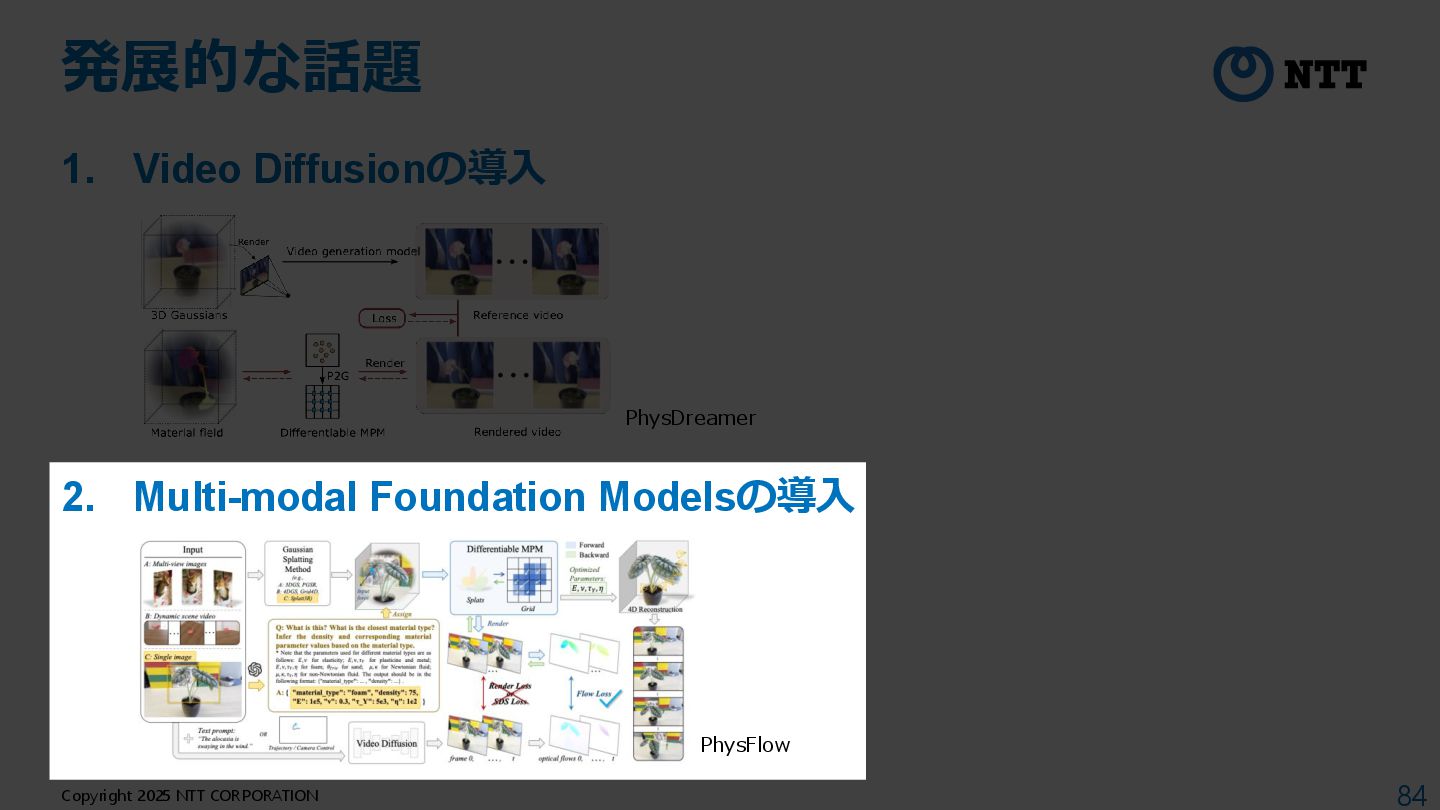
Video Diffusion Prior [Zhang+2024] • Q. 静止画だけからReverse Engeneering(物理パラメータの推定)するためには? → A. Video Diffusionで動画を生成して動画のPriorとして利用 T. Zhang et al., “PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation,” ECCV 2024.
Video Diffusion Prior [Zhang+2024] T. Zhang et al., “PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation,” ECCV 2024. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得
Video Diffusion Prior [Zhang+2024] T. Zhang et al., “PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation,” ECCV 2024. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得 Step 2:Image-to-Video Video Diffusionを使って画像から動画を生成し 動画のPriorとして利用
Video Diffusion Prior [Zhang+2024] T. Zhang et al., “PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation,” ECCV 2024. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得 Step 2:Image-to-Video Video Diffusionを使って画像から動画を生成し 動画のPriorとして利用 Step 3:物理パラメータの最適化 MPMによるシミュレーション結果とVideo Diffusionの生成動画 の差が小さくなるように物理パラメータを最適化
et al., “PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation,” ECCV 2024. 実データ PhysDreamer PhysGaussian DreamGaussian4D 静止画だけからより自然なダイナミクスを生成 動画:https://physdreamer.github.io/
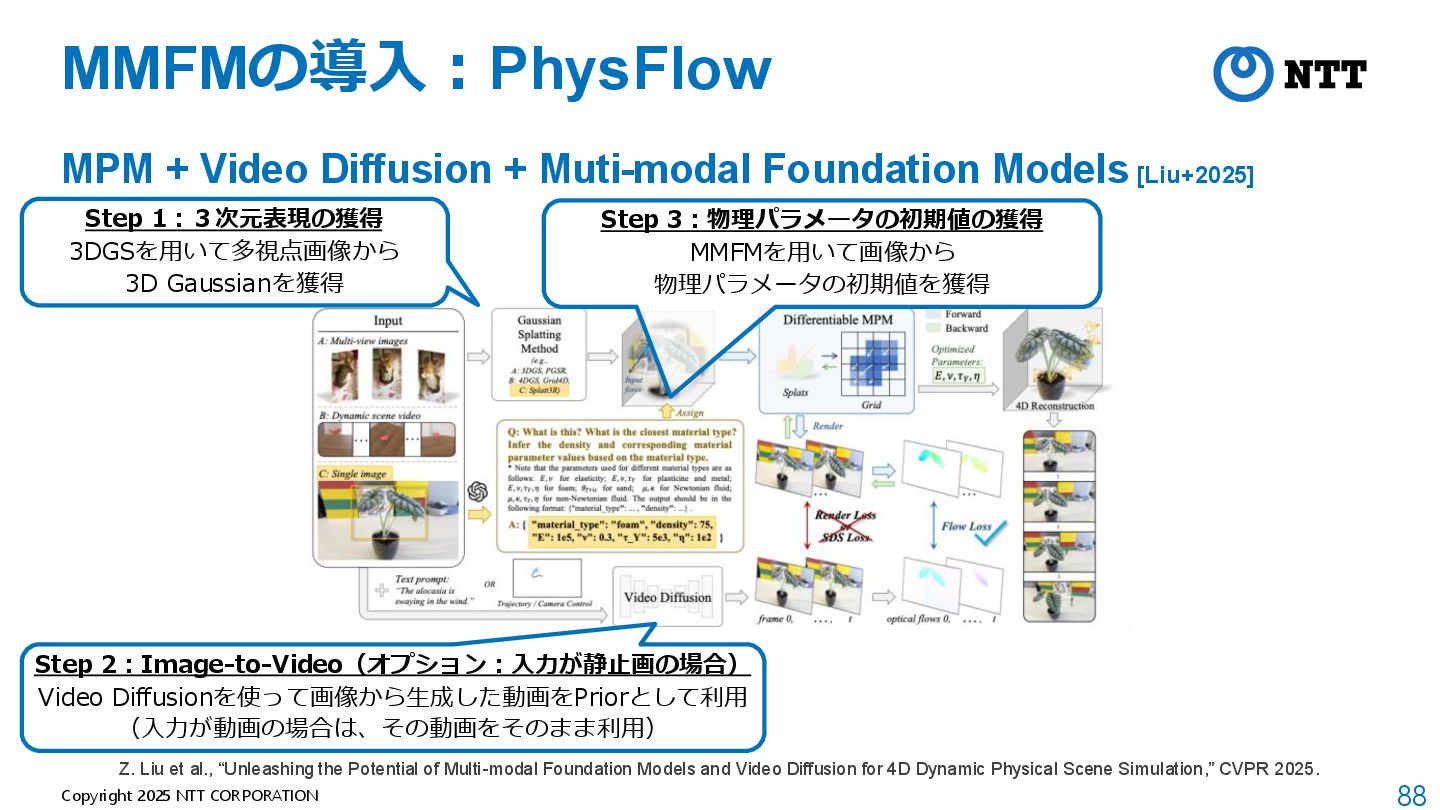
+ Muti-modal Foundation Models [Liu+2025] • Q. 物理パラメータのよい初期値を得るためには? → A. Multi-modal Foundation Models (MMFMs) を利用 Z. Liu et al., “Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation,” CVPR 2025.
+ Muti-modal Foundation Models [Liu+2025] Z. Liu et al., “Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation,” CVPR 2025. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得
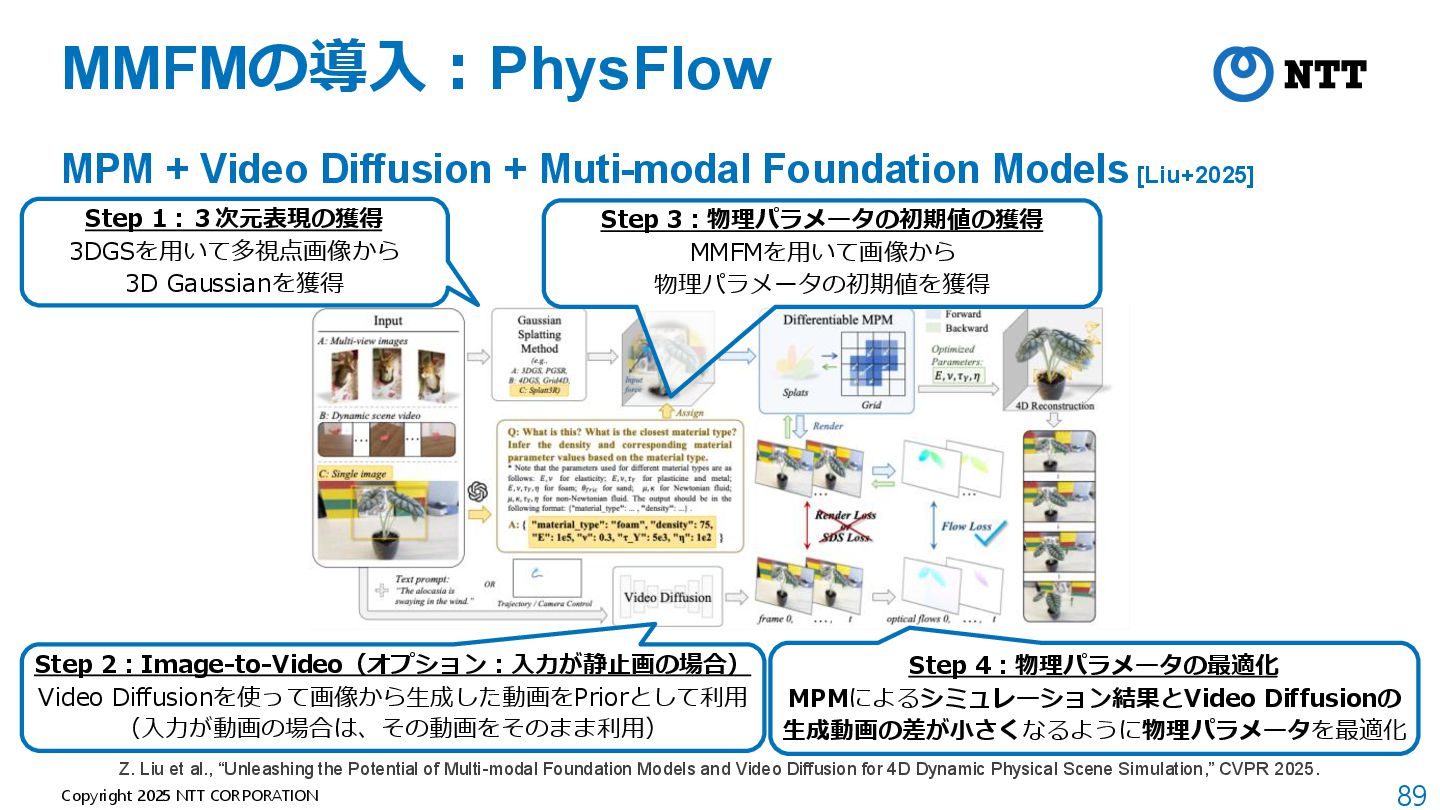
+ Muti-modal Foundation Models [Liu+2025] Z. Liu et al., “Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation,” CVPR 2025. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得 Step 2:Image-to-Video(オプション:入力が静止画の場合) Video Diffusionを使って画像から生成した動画をPriorとして利用 (入力が動画の場合は、その動画をそのまま利用)
+ Muti-modal Foundation Models [Liu+2025] Z. Liu et al., “Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation,” CVPR 2025. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得 Step 3:物理パラメータの初期値の獲得 MMFMを用いて画像から 物理パラメータの初期値を獲得 Step 2:Image-to-Video(オプション:入力が静止画の場合) Video Diffusionを使って画像から生成した動画をPriorとして利用 (入力が動画の場合は、その動画をそのまま利用)
+ Muti-modal Foundation Models [Liu+2025] Z. Liu et al., “Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation,” CVPR 2025. Step 1:3次元表現の獲得 3DGSを用いて多視点画像から 3D Gaussianを獲得 Step 3:物理パラメータの初期値の獲得 MMFMを用いて画像から 物理パラメータの初期値を獲得 Step 4:物理パラメータの最適化 MPMによるシミュレーション結果とVideo Diffusionの 生成動画の差が小さくなるように物理パラメータを最適化 Step 2:Image-to-Video(オプション:入力が静止画の場合) Video Diffusionを使って画像から生成した動画をPriorとして利用 (入力が動画の場合は、その動画をそのまま利用)
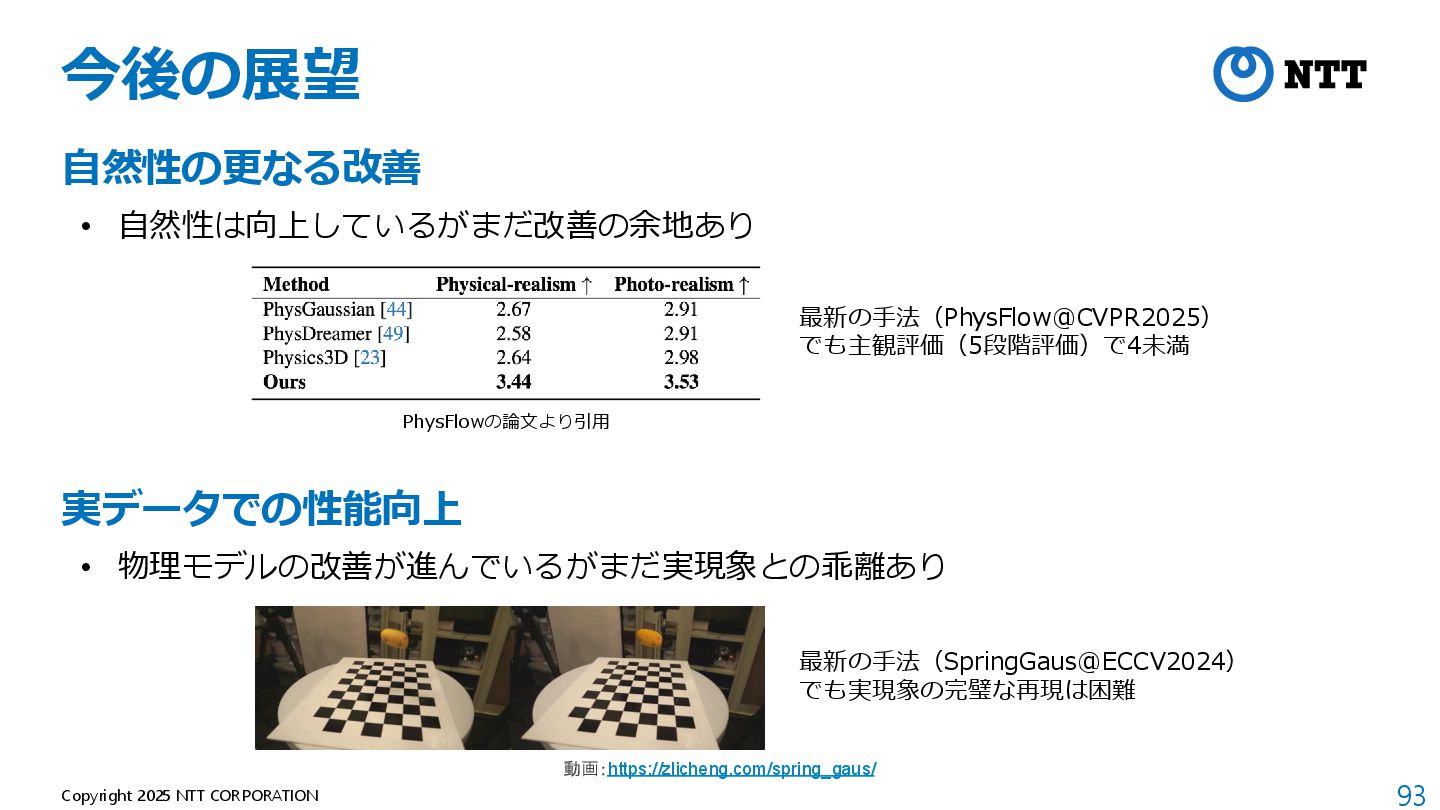
al., “Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation,” CVPR 2025. 入力画像 PhysFlow PhysGaussian PhysDreamer Physics3D 静止画だけからさらに自然なダイナミクスを生成 動画:https://zhuomanliu.github.io/PhysFlow/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![46 Copyright 2025 NTT CORPORATION 例:PhysGaussian Physics-Integrated 3D Gaussians [Xie+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_46.jpg){kind=link}
![47 Copyright 2025 NTT CORPORATION 例:PhysGaussian Physics-Integrated 3D Gaussians [Xie+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_47.jpg){kind=link}
![48 Copyright 2025 NTT CORPORATION 例:PhysGaussian Physics-Integrated 3D Gaussians [Xie+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_48.jpg){kind=link}
![49 Copyright 2025 NTT CORPORATION 例:PhysGaussian Physics-Integrated 3D Gaussians [Xie+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_49.jpg){kind=link}
{kind=link}
![51 Copyright 2025 NTT CORPORATION PhysGaussianの限界 Physics-Integrated 3D Gaussians [Xie+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
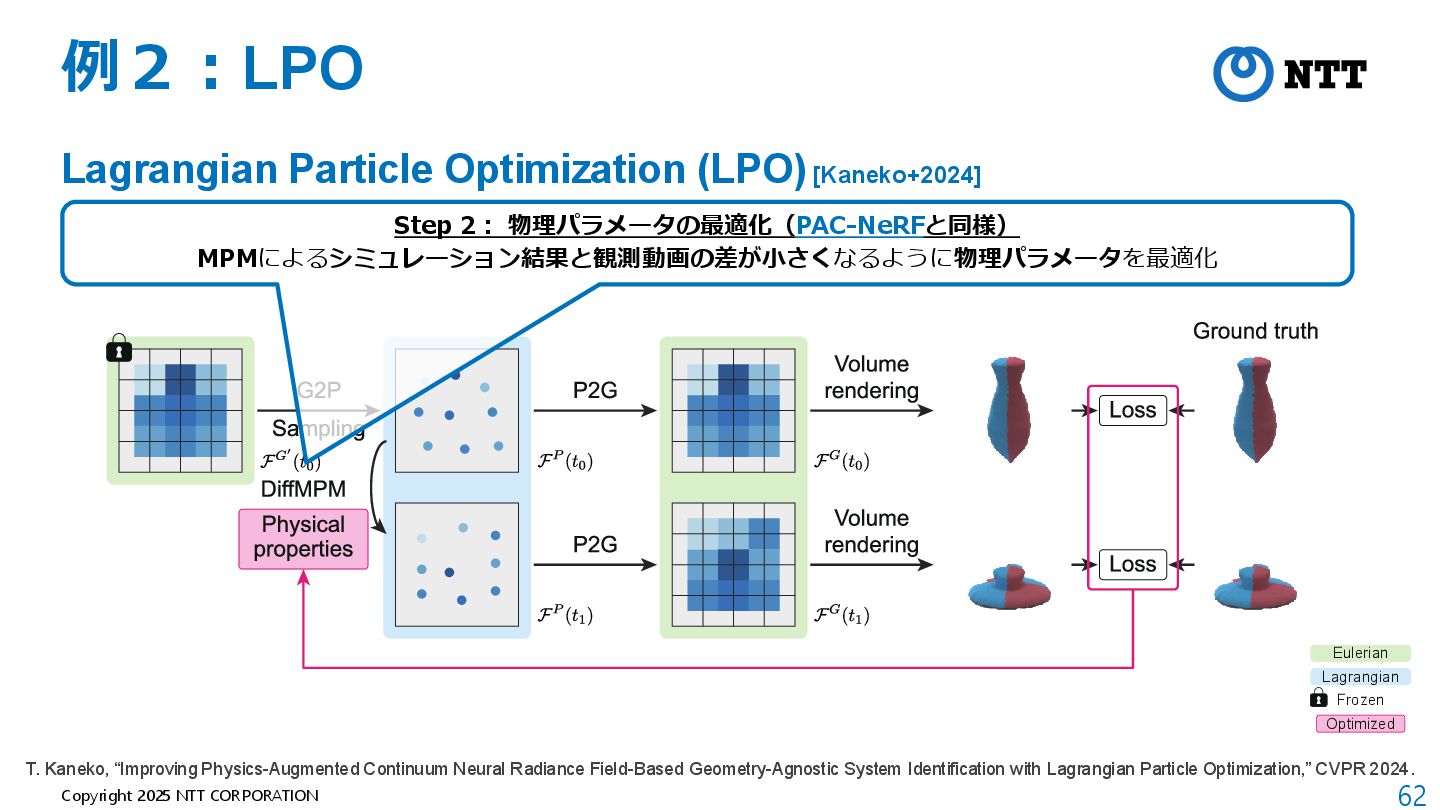{kind=link}
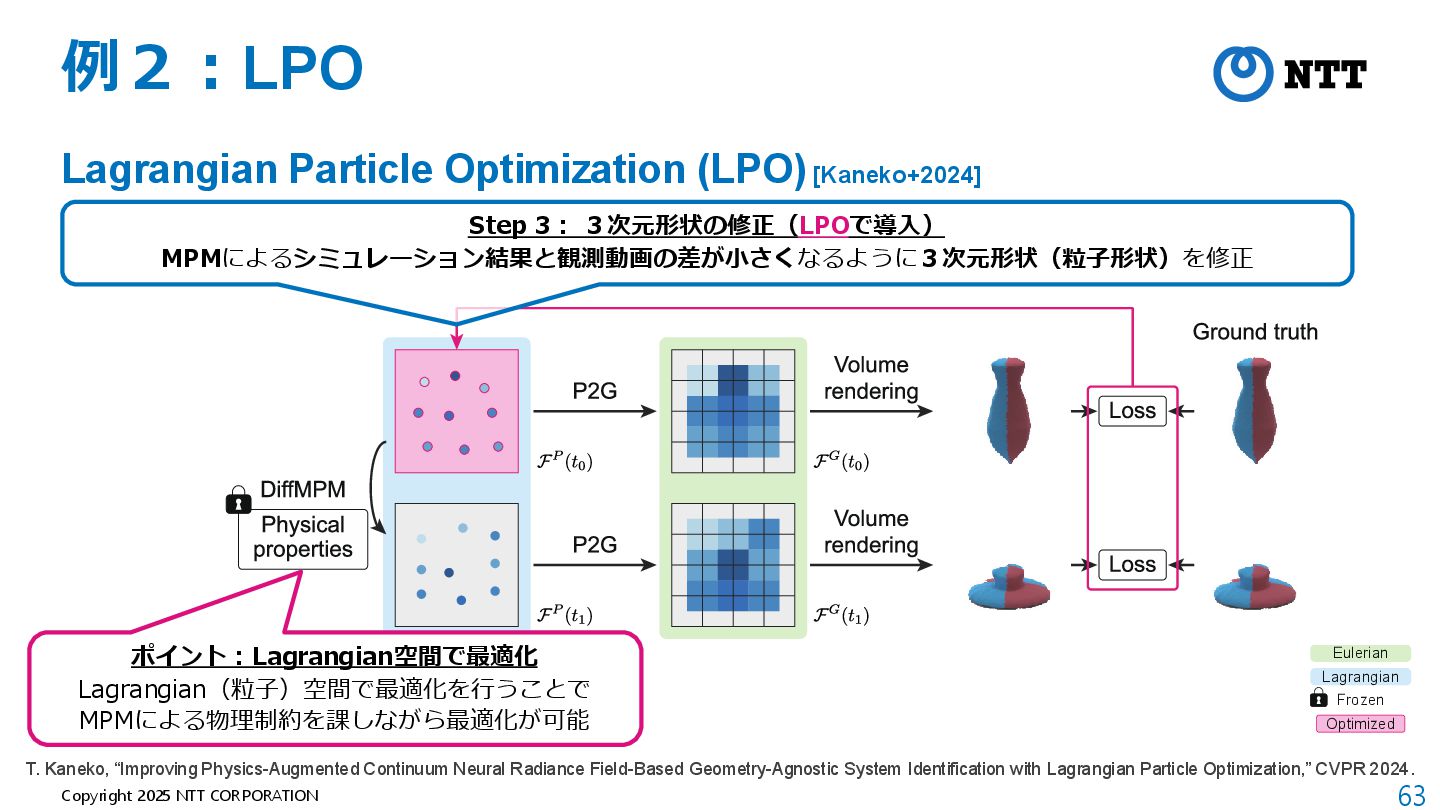{kind=link}
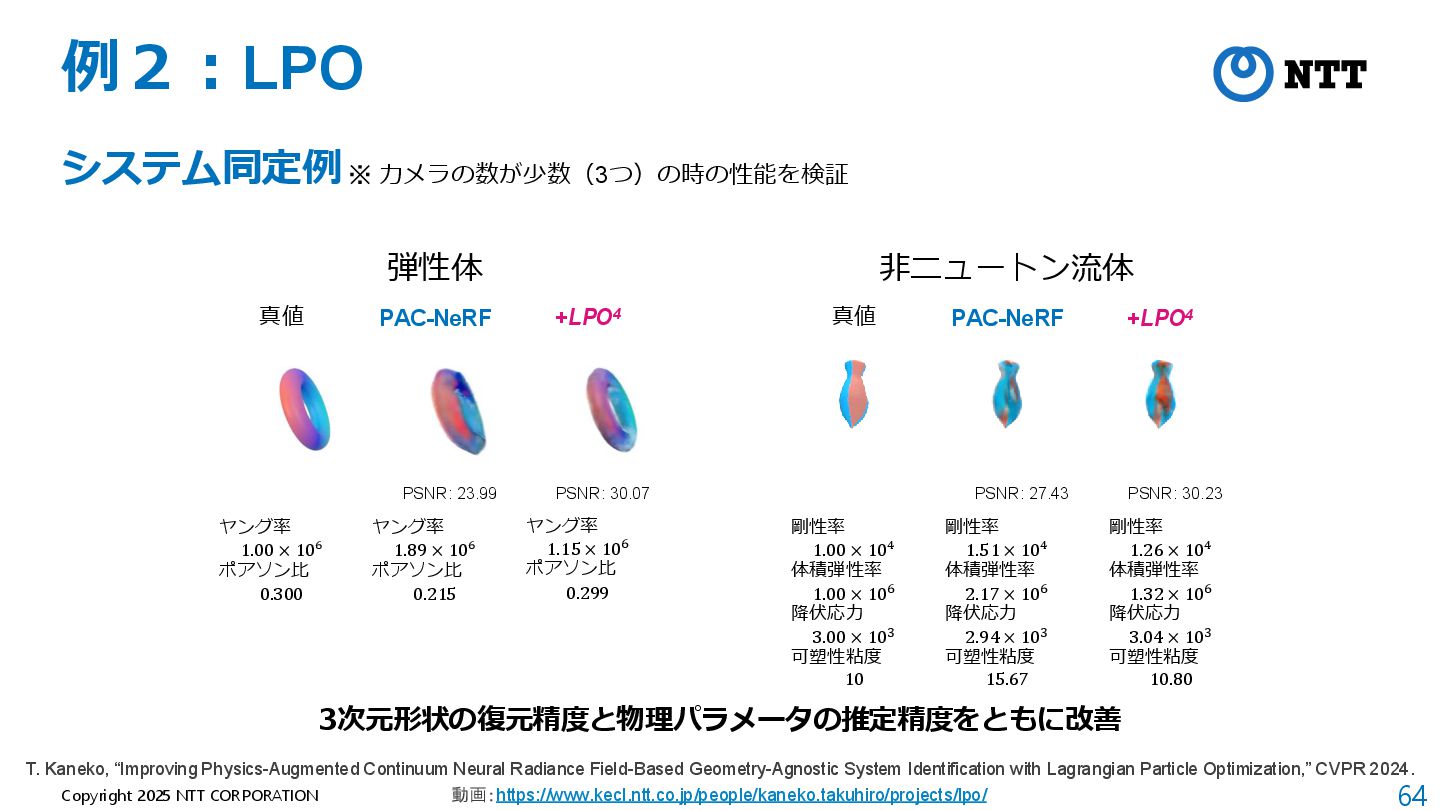{kind=link}
![65 Copyright 2025 NTT CORPORATION 例3:GIC Gaussian-Informed Continuum (GIC) [Cai+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_65.jpg){kind=link}
![66 Copyright 2025 NTT CORPORATION 例3:GIC Gaussian-Informed Continuum (GIC) [Cai+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_66.jpg){kind=link}
![67 Copyright 2025 NTT CORPORATION 例3:GIC Gaussian-Informed Continuum (GIC) [Cai+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_67.jpg){kind=link}
![68 Copyright 2025 NTT CORPORATION 例3:GIC Gaussian-Informed Continuum (GIC) [Cai+2024]](https://files.speakerdeck.com/presentations/cb5c4704bbb040c2a1d8c785a843ef2d/slide_68.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
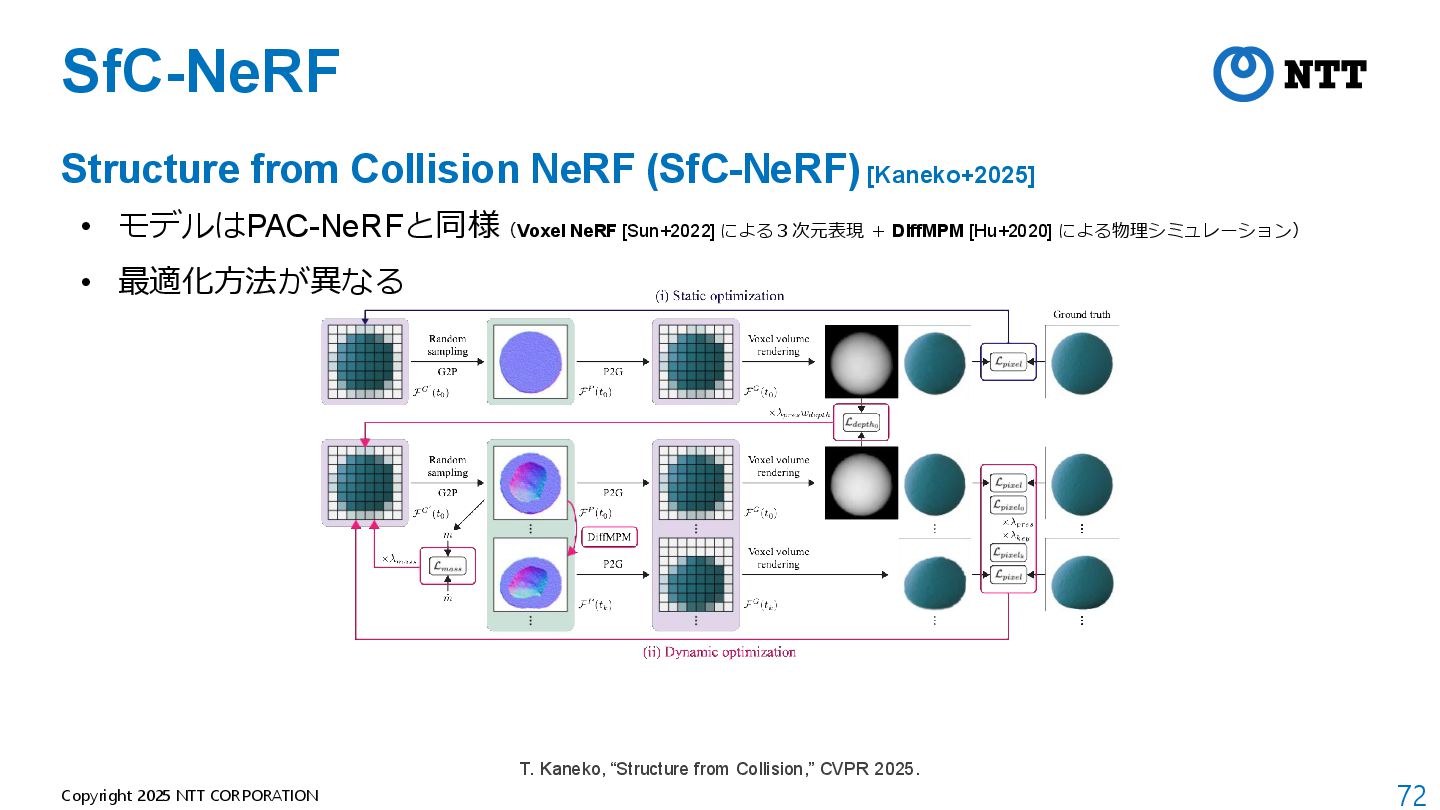{kind=link}
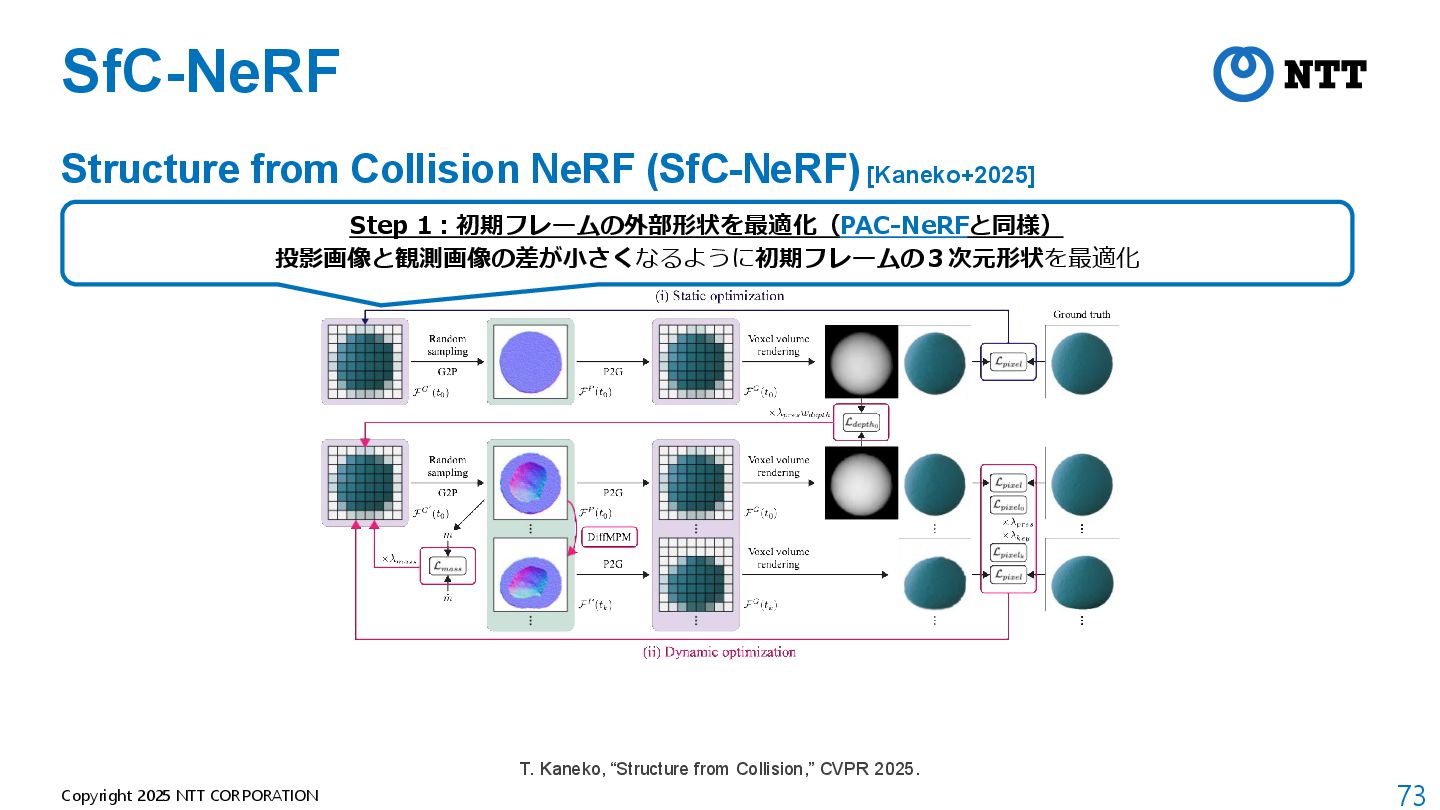{kind=link}
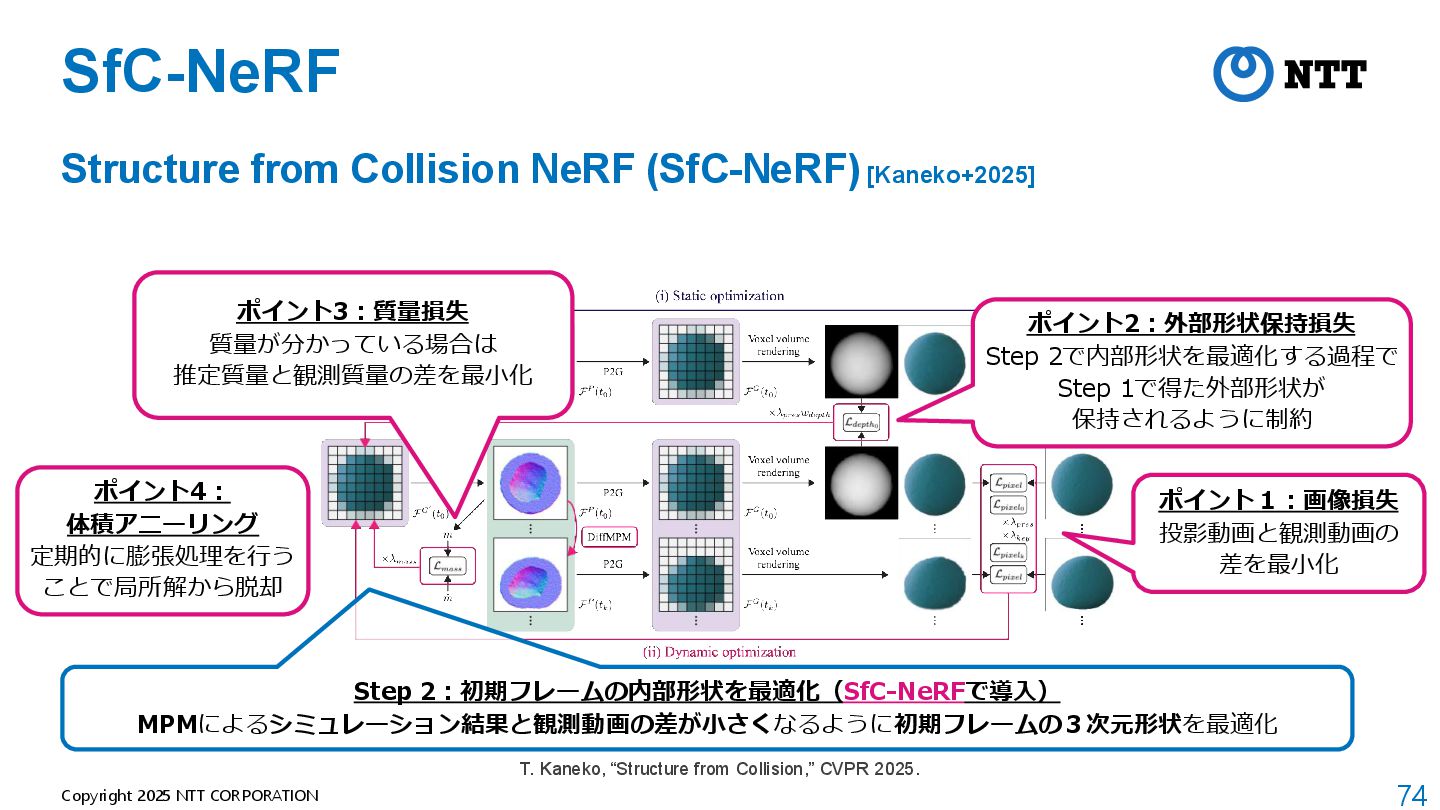{kind=link}
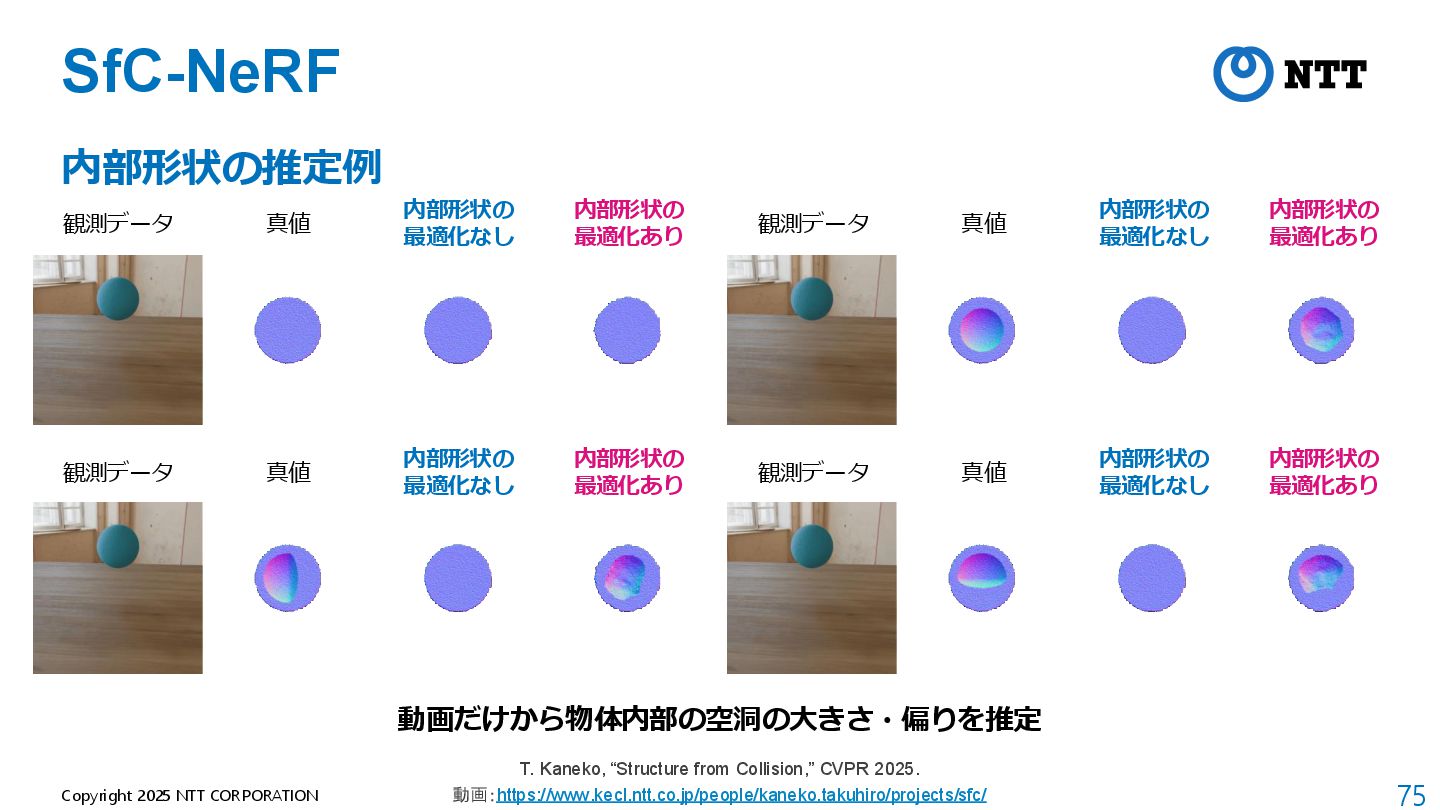{kind=link}
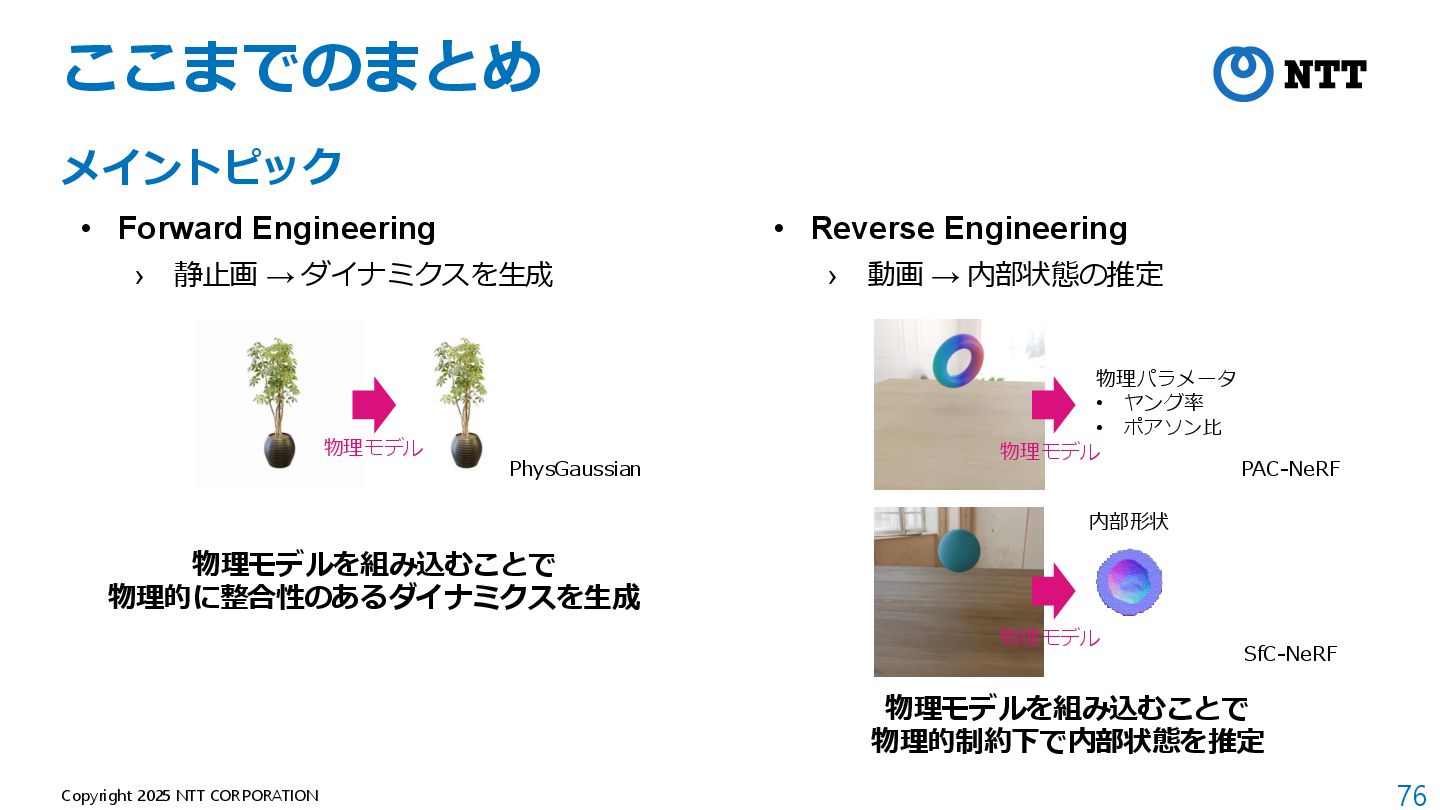{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}