Share
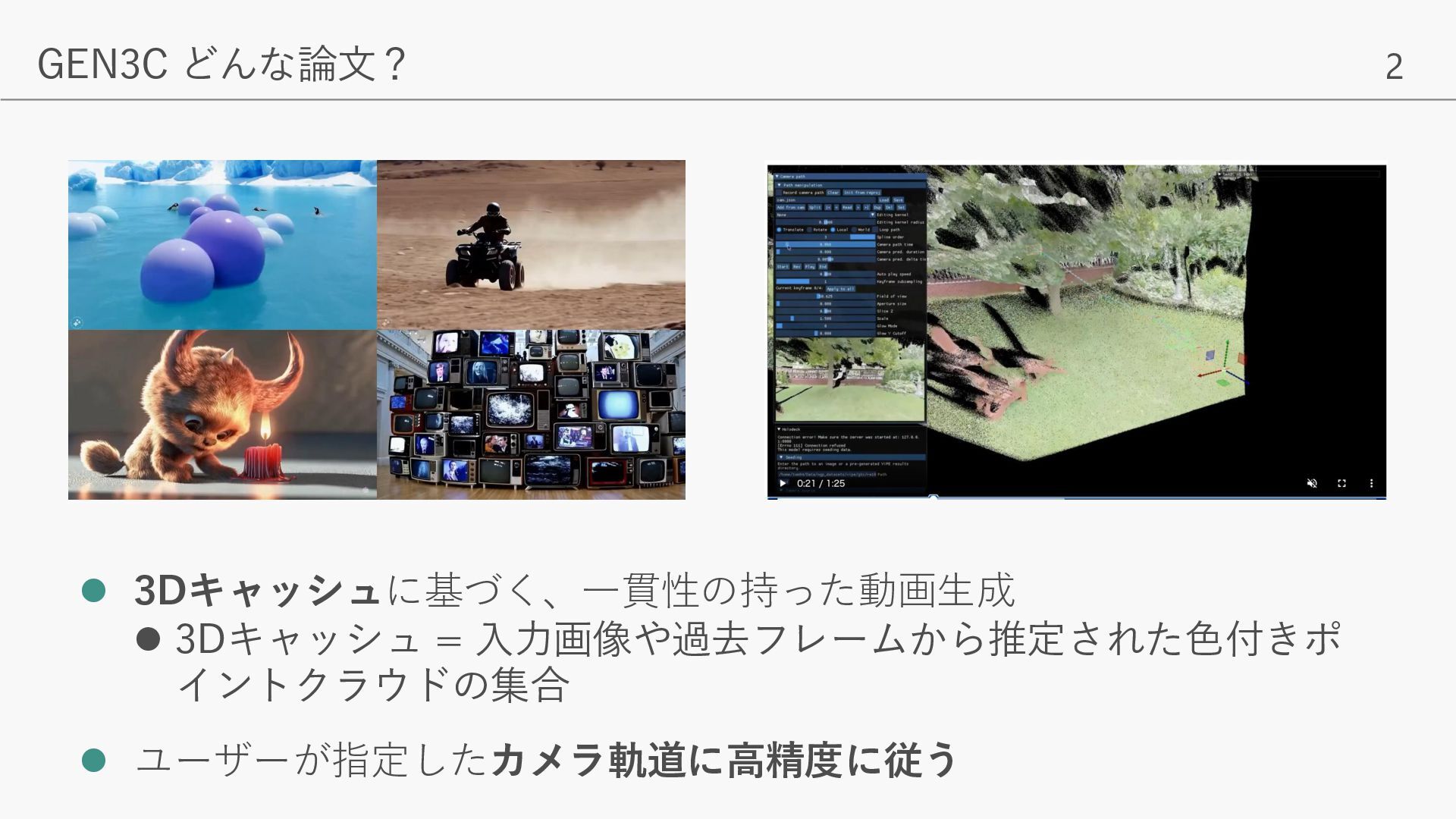
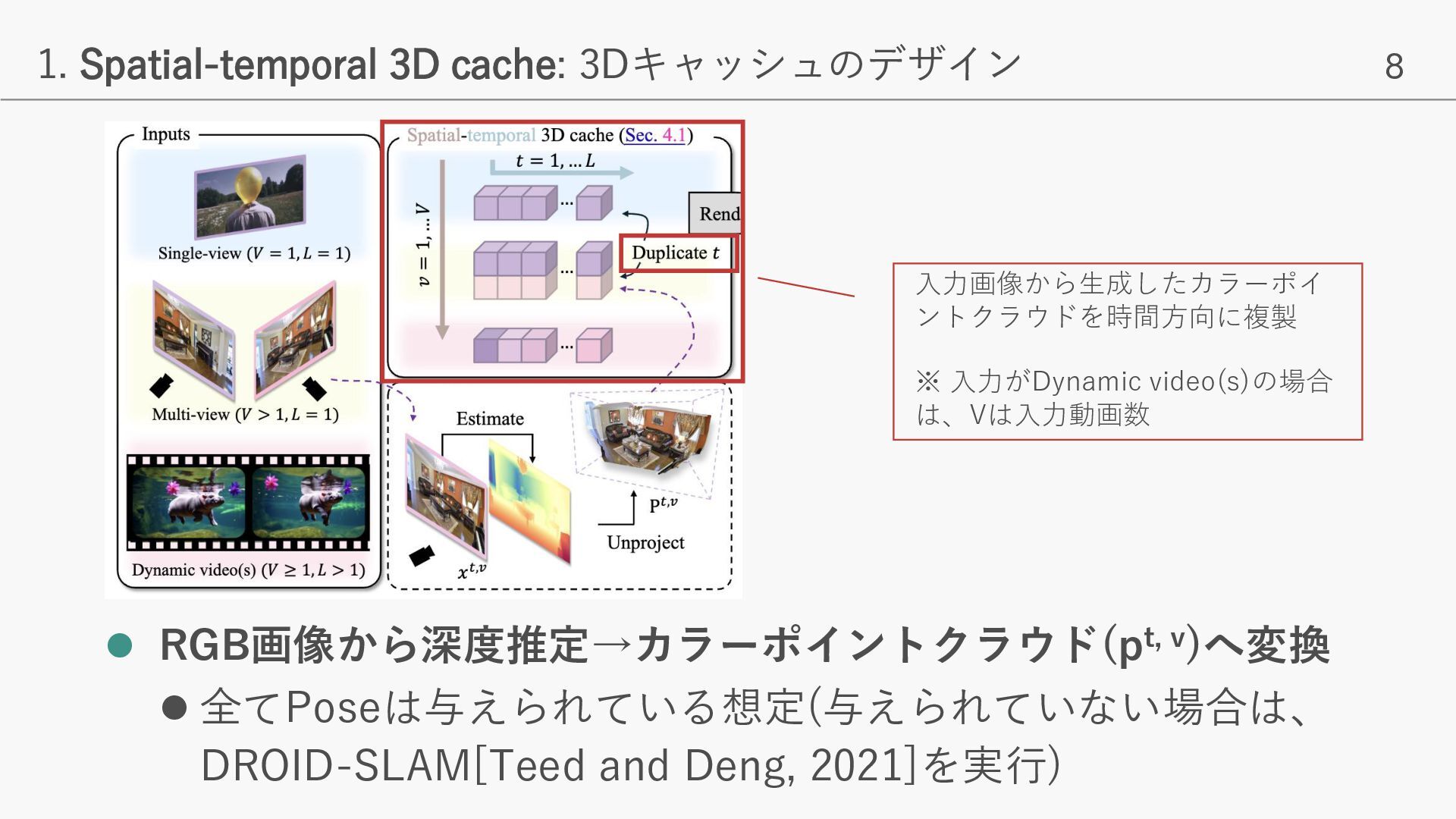
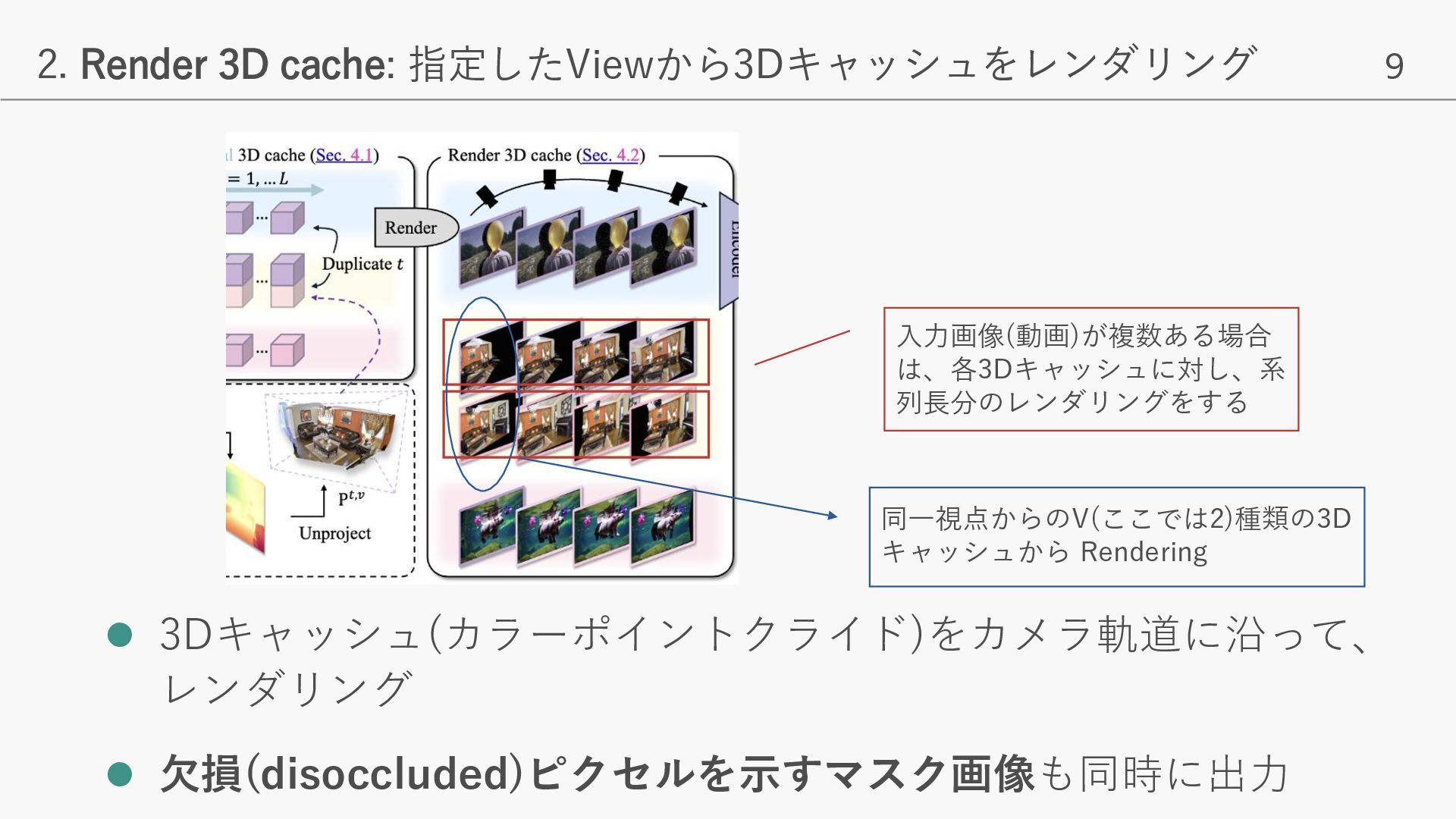
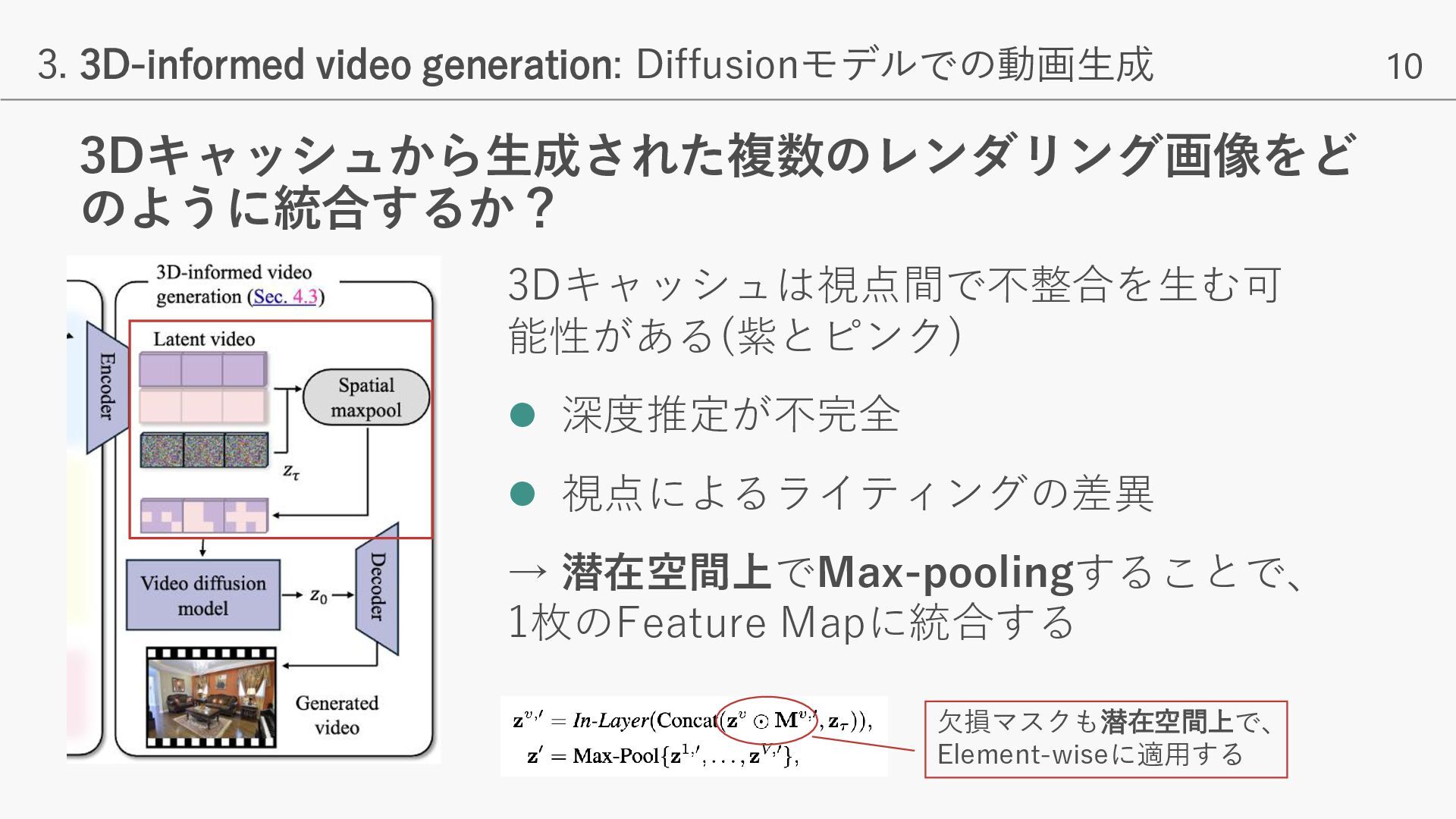
- 入力フレームから取得した色付きポイントクラウド(3Dキャッシュ)に基づき、ユーザーが指定したカメラ軌道に従った、一貫性のある動画生成を実現 - 入力画像/動画と矛盾がなく、かつPhoto-realisticな動画生成が可能となり、様々なNVSタスクでSOTAを達成
{kind=link}
{kind=link}
{kind=link}
![4 カメラ制御可能な動画生成モデルにおけるシーンの一貫性 従来の動画生成モデルの問題点 先行研究(CameraCtrl[He et al, 2024])ではカメラを前後に 動かした時に、前フレームの情報を保持できていない](https://files.speakerdeck.com/presentations/348b54a63e5f4a54b362c5b533854f33/slide_3.jpg){kind=link}
{kind=link}
![6 1. Novel View Reconstruction ⚫ Nerfacto[Tancik et al, 2023]](https://files.speakerdeck.com/presentations/348b54a63e5f4a54b362c5b533854f33/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11 ⚫ ベースモデル: Stable Video Diffusion[Blattmann et al., 2023] ⚫](https://files.speakerdeck.com/presentations/348b54a63e5f4a54b362c5b533854f33/slide_10.jpg){kind=link}
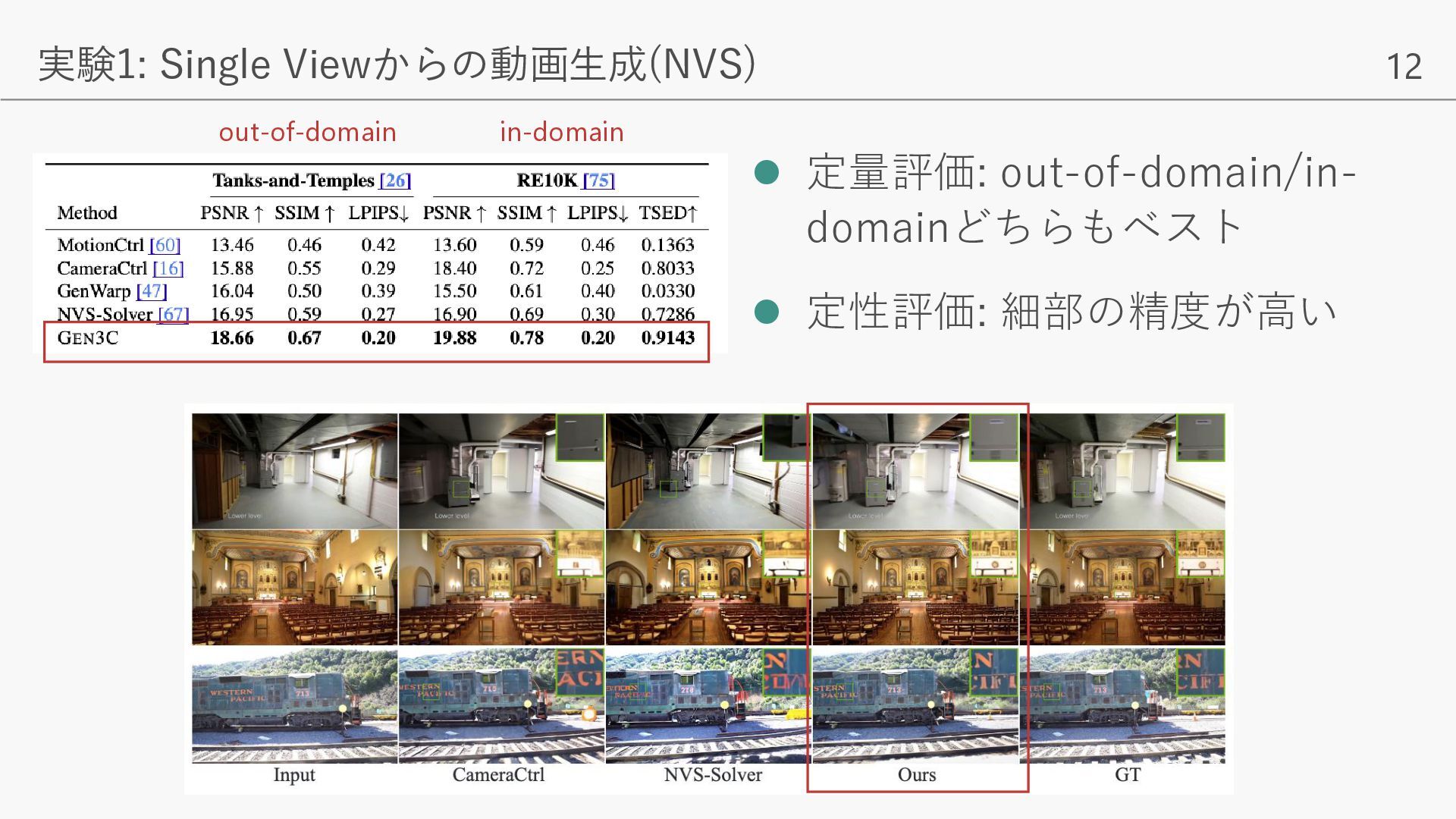{kind=link}
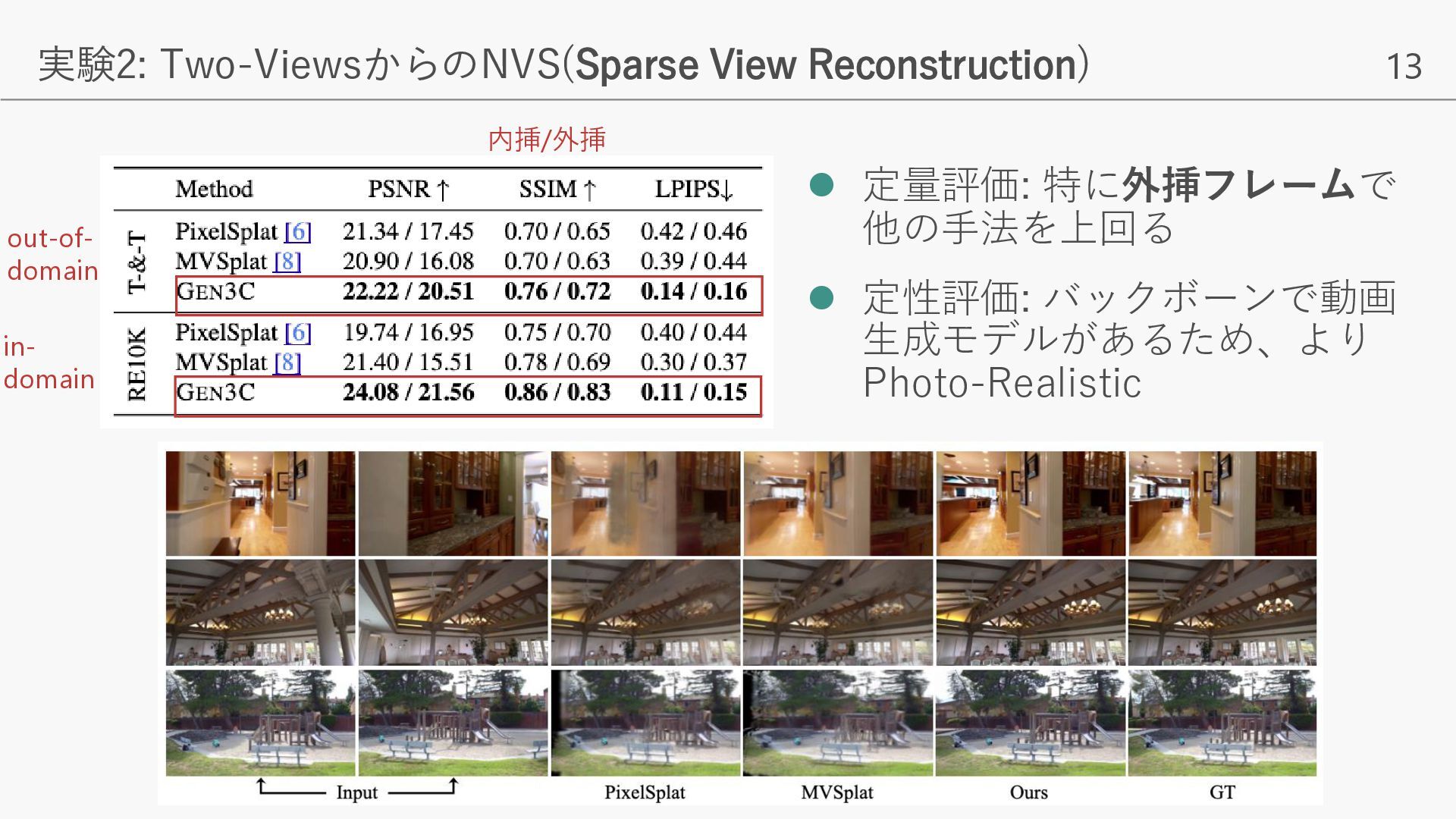{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}