Share
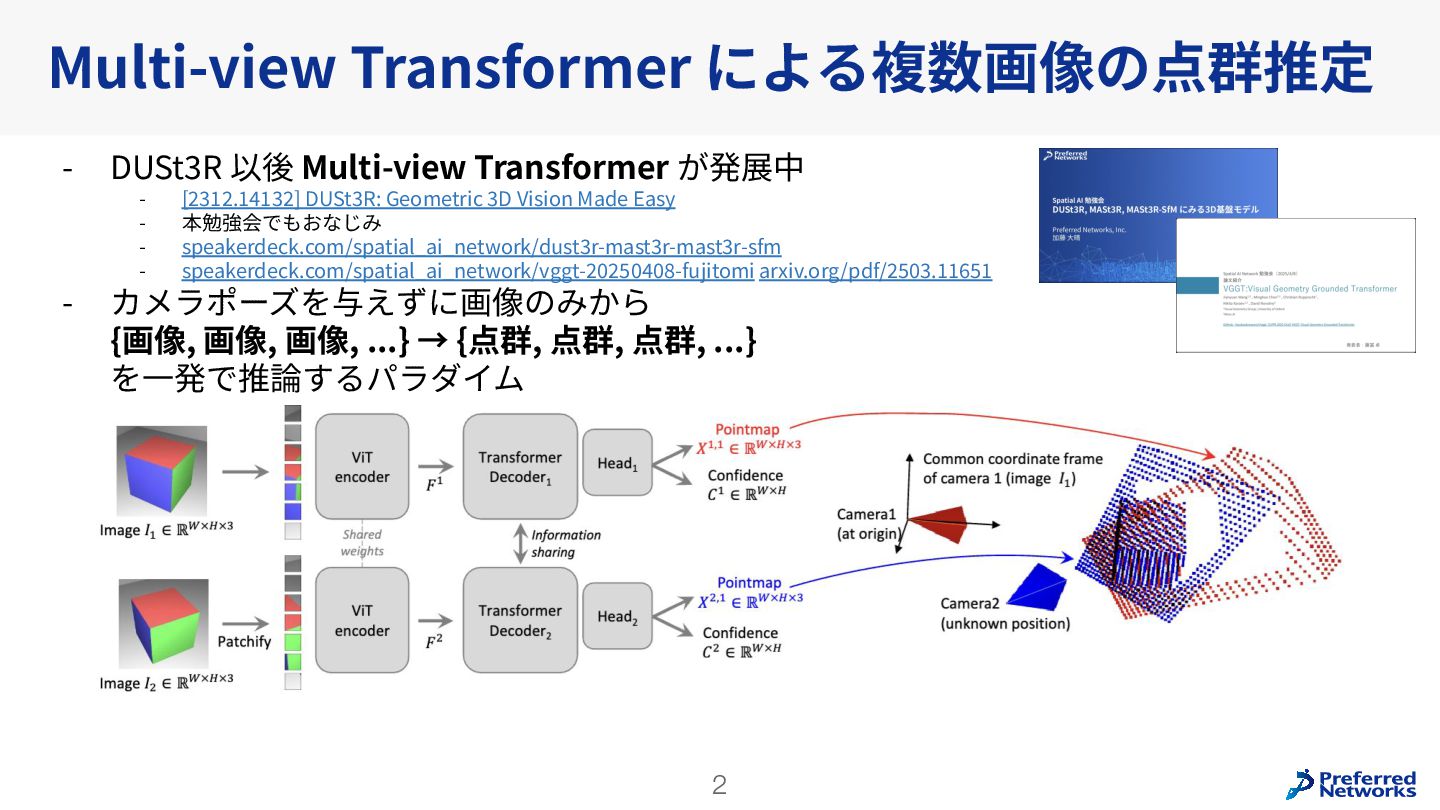
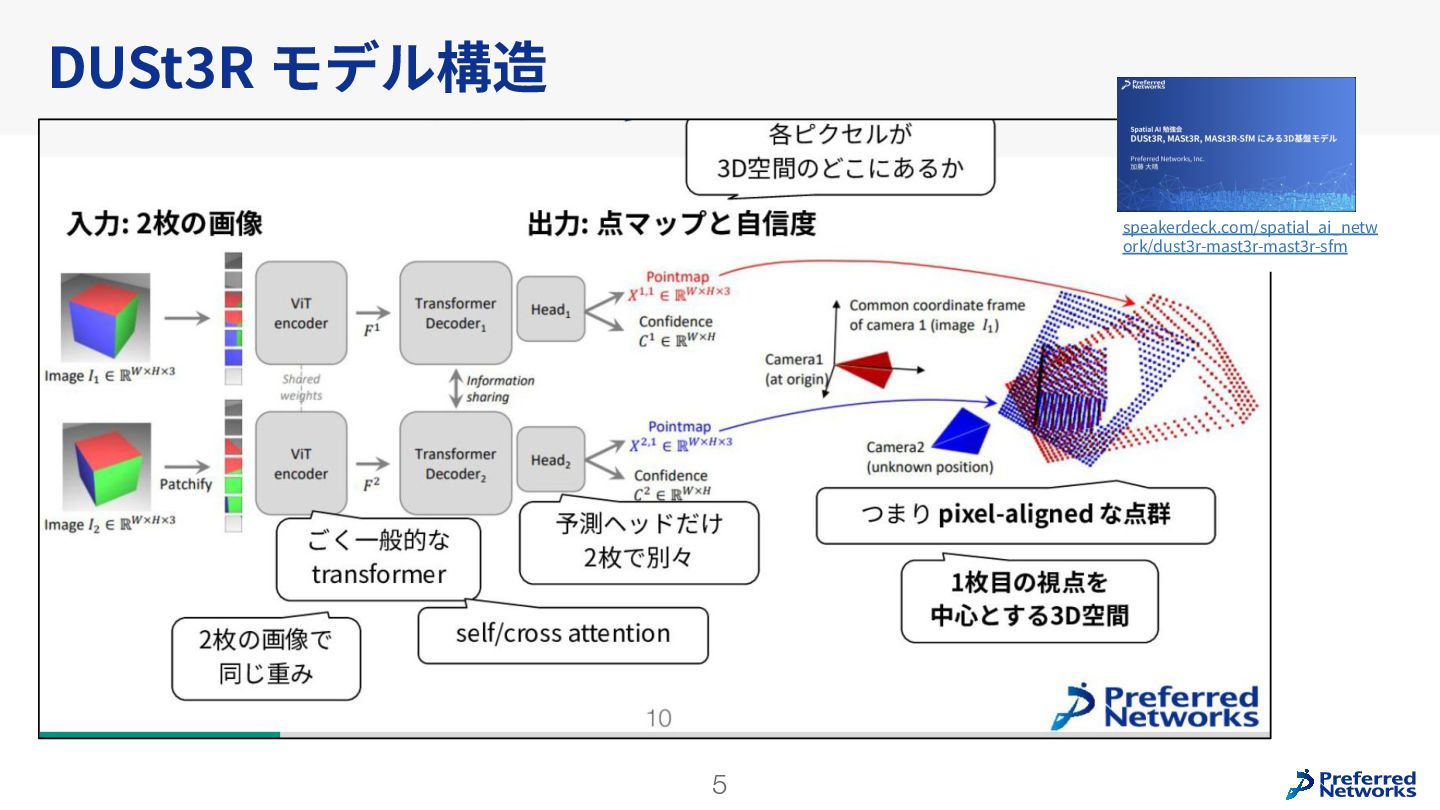
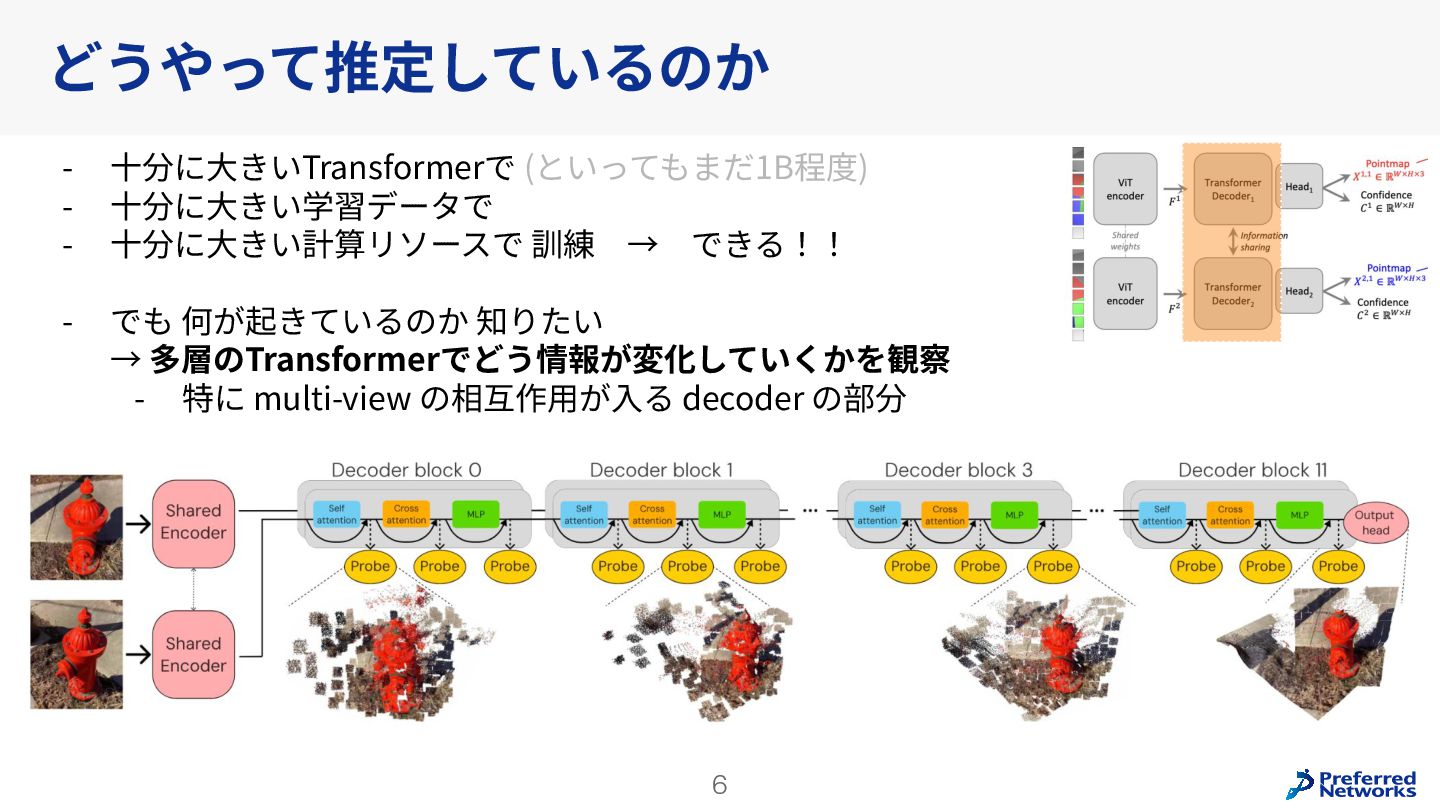
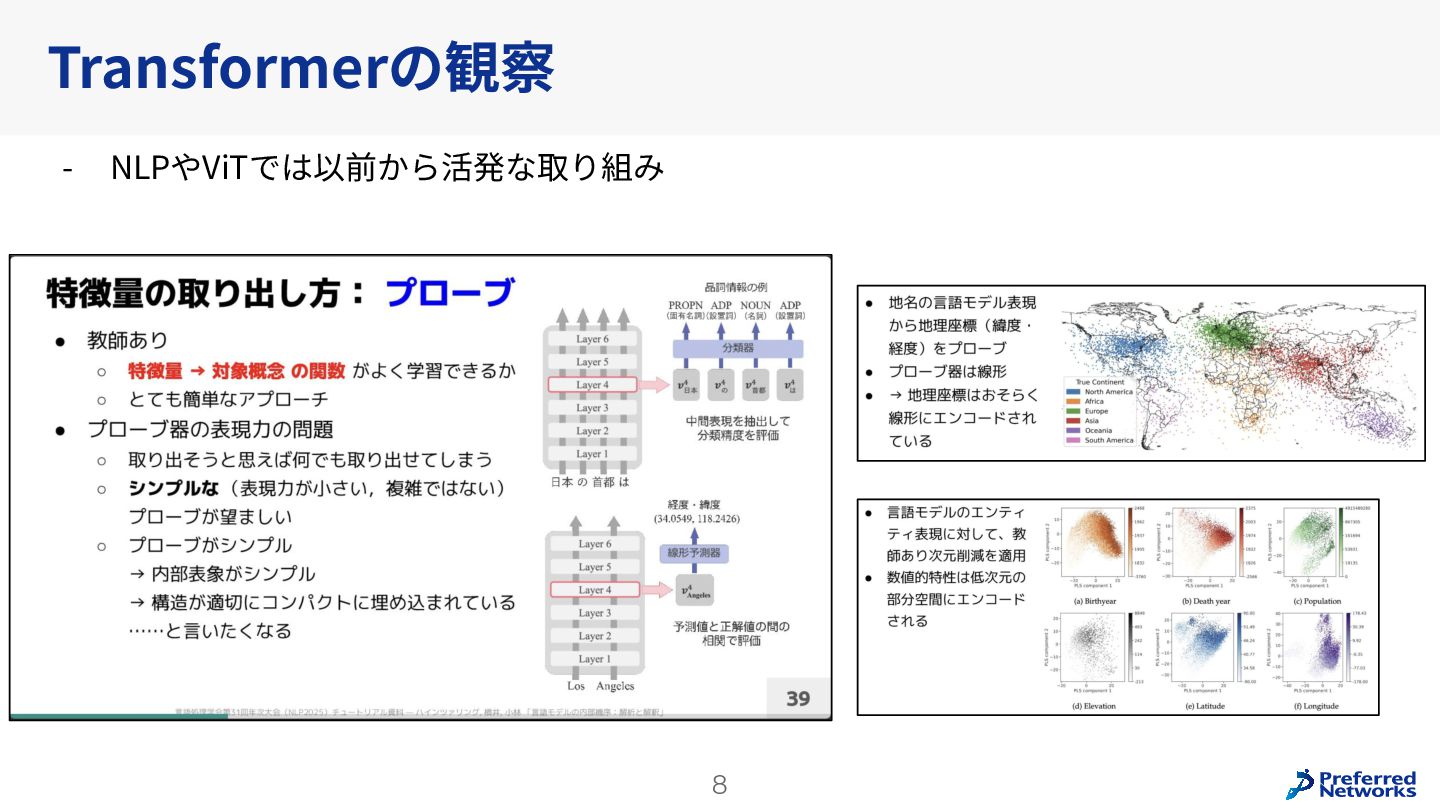
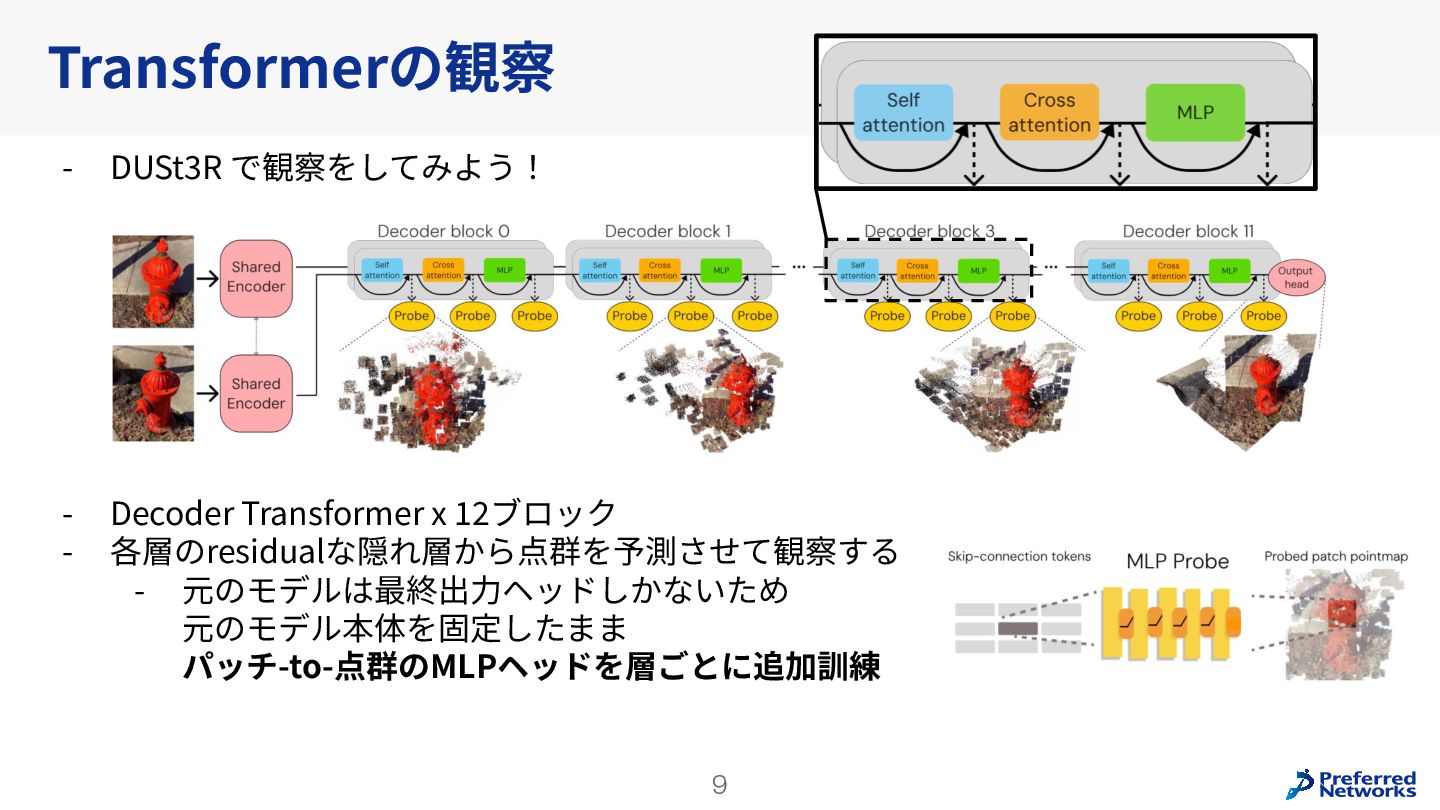
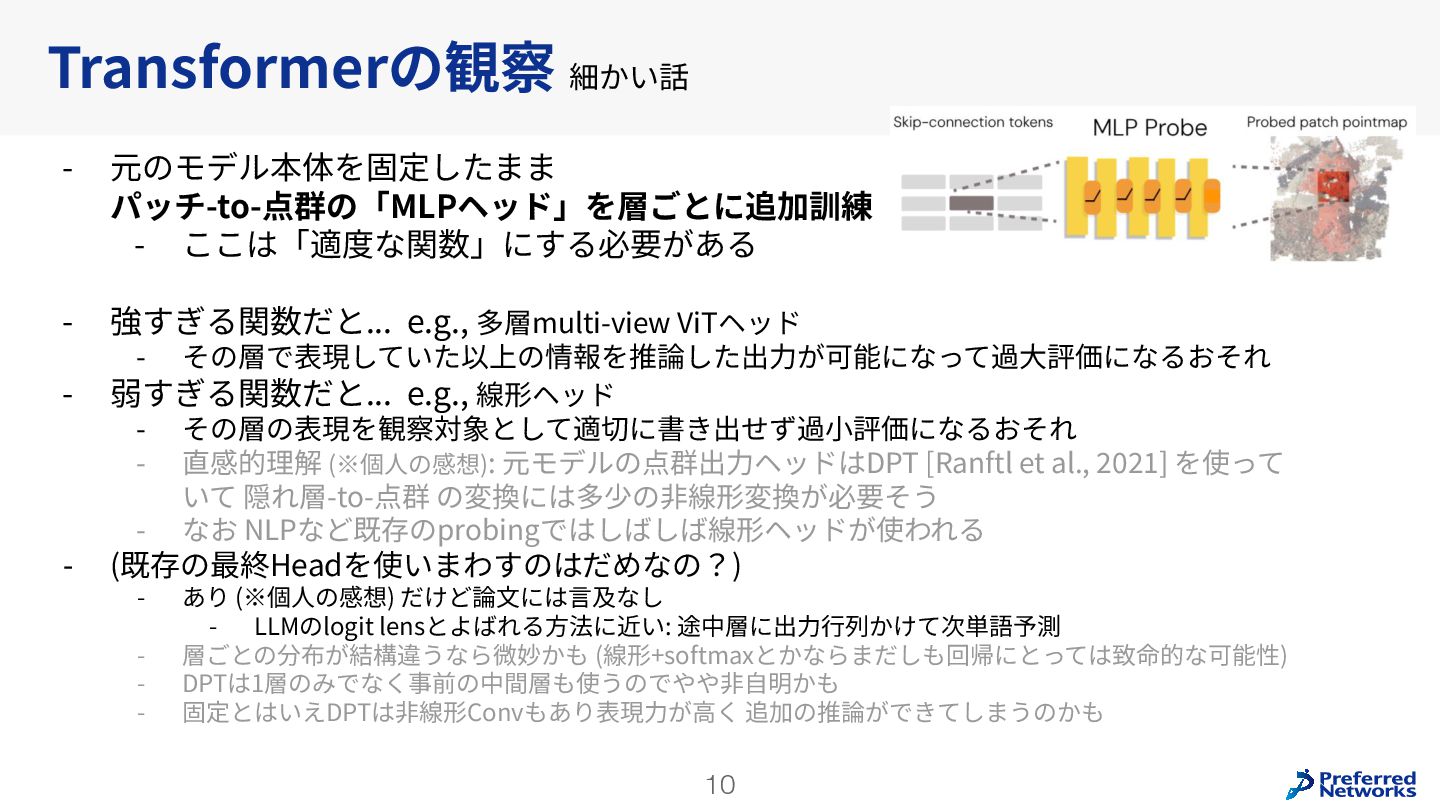
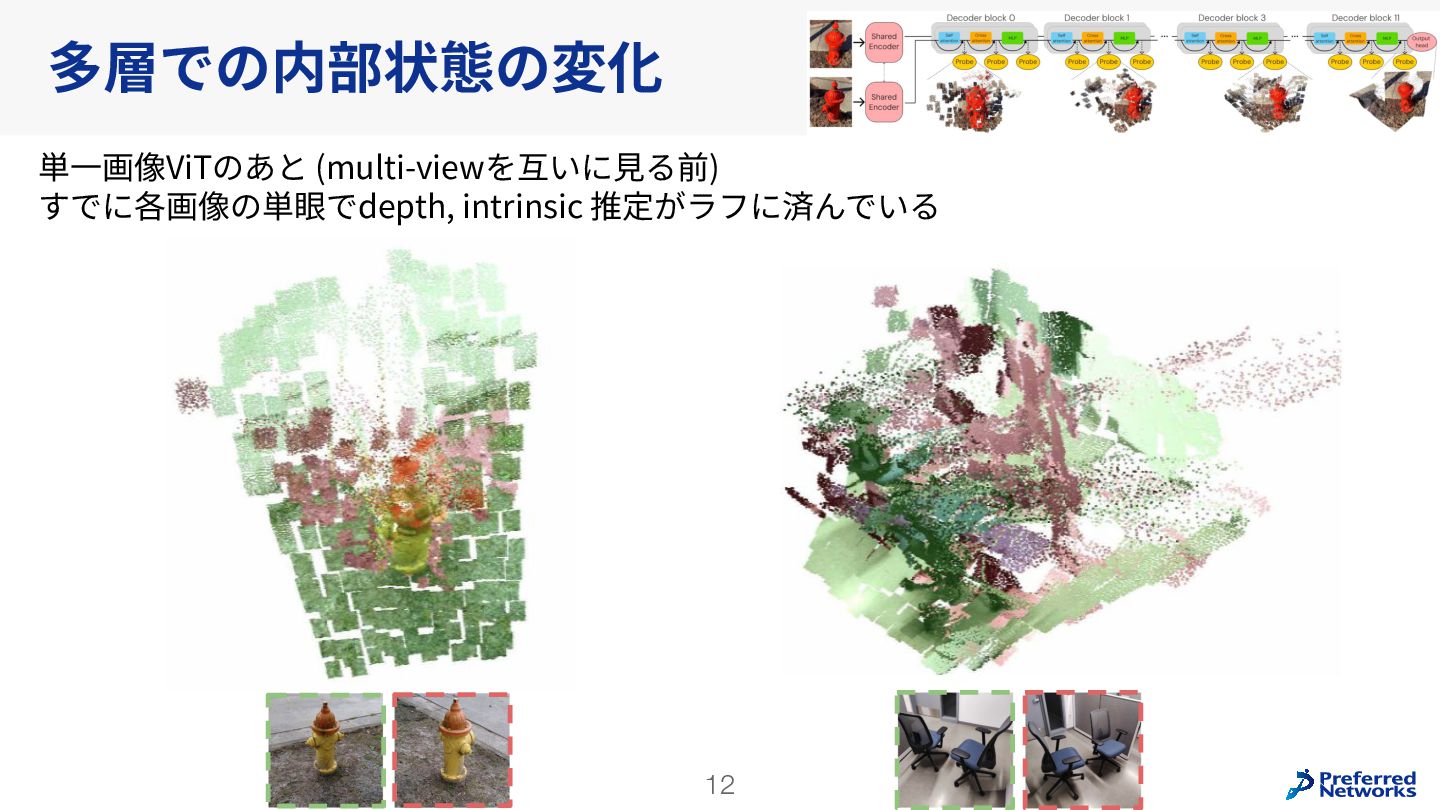
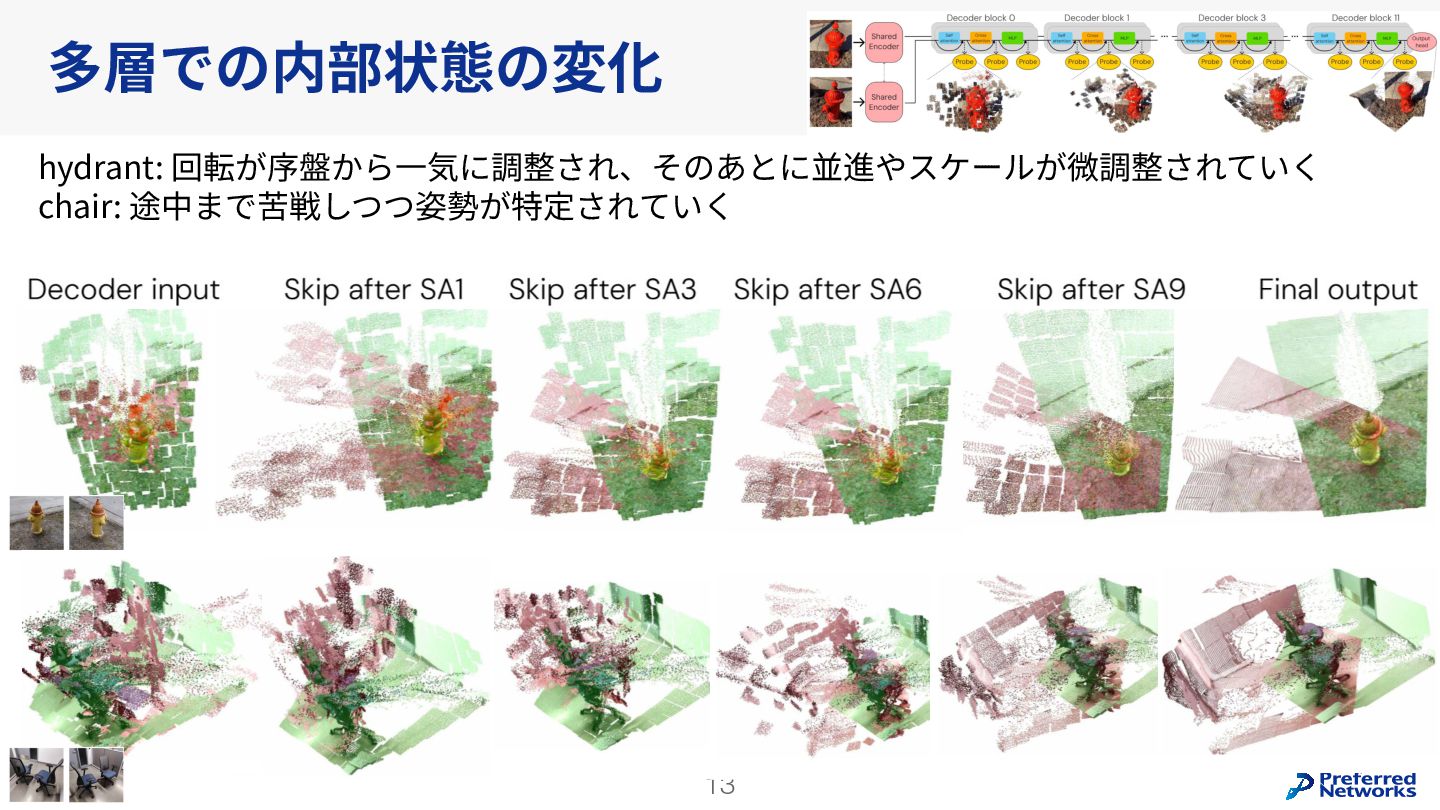
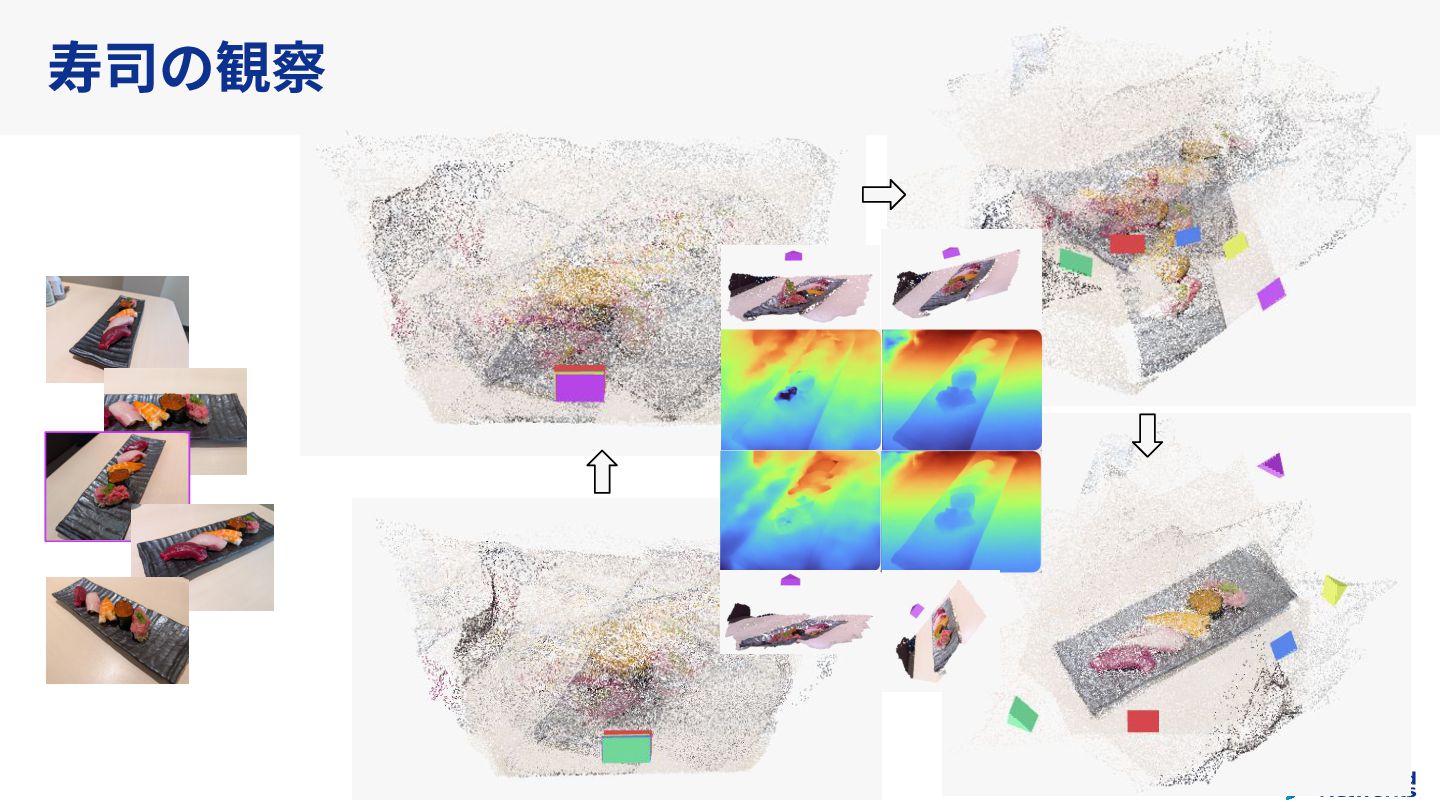
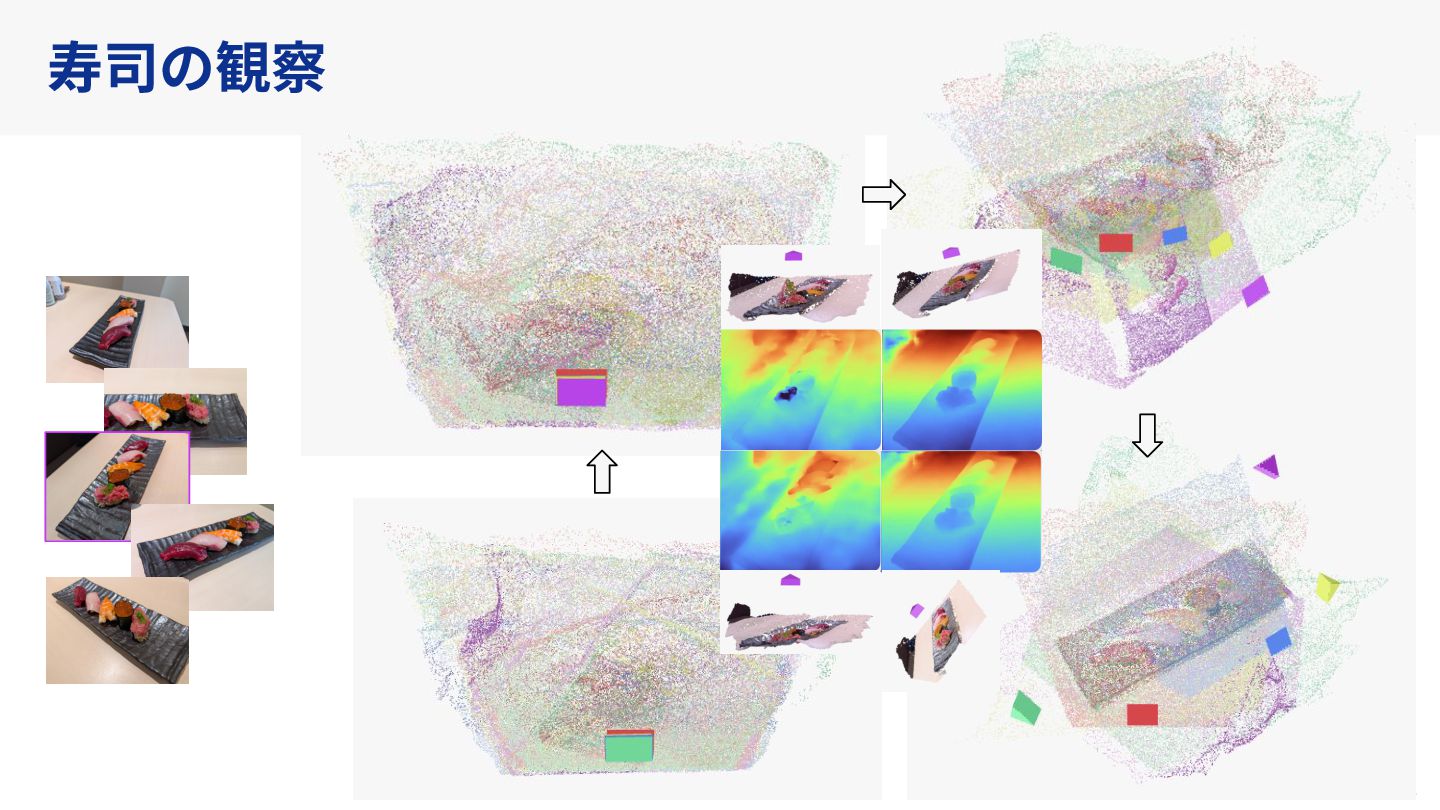
Understanding multi-view transformers https://arxiv.org/abs/2312.14132 カメラ位置姿勢なしの画像ペアから3D点群を求めるDUSt3Rの推論時のTransformerの挙動を分析。
おまけとしてVGGTでも実験。 https://github.com/soskek/understand_vggt
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
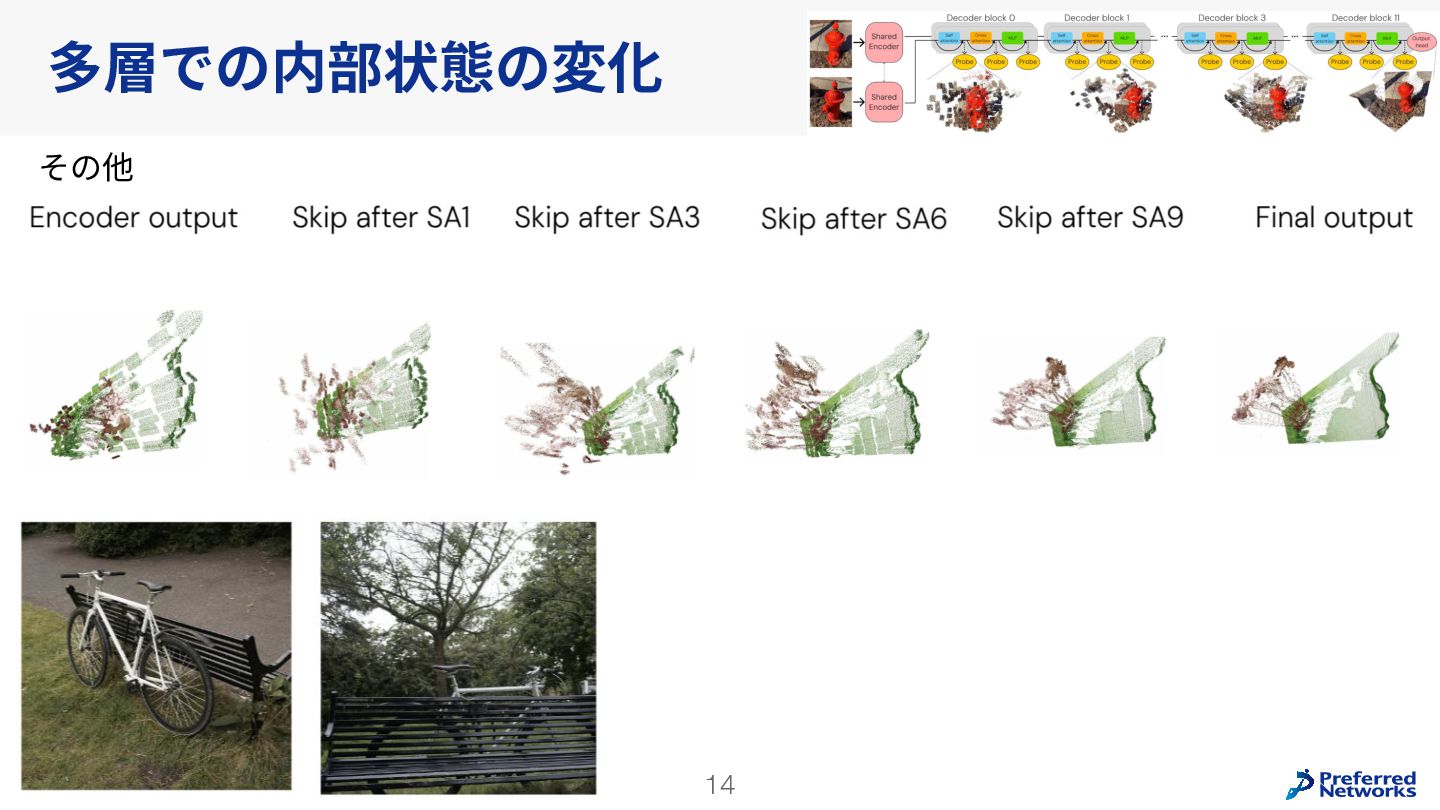{kind=link}
{kind=link}
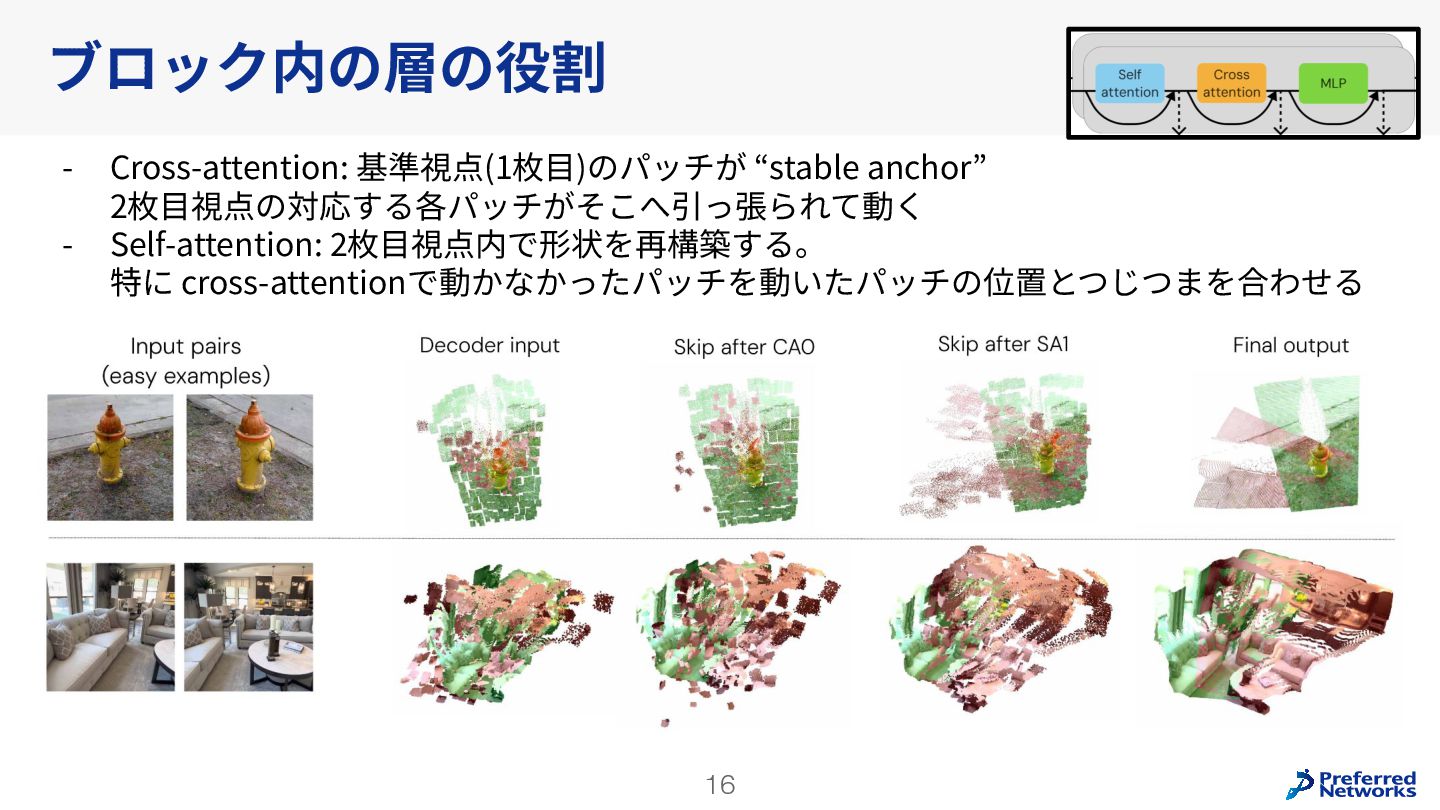{kind=link}
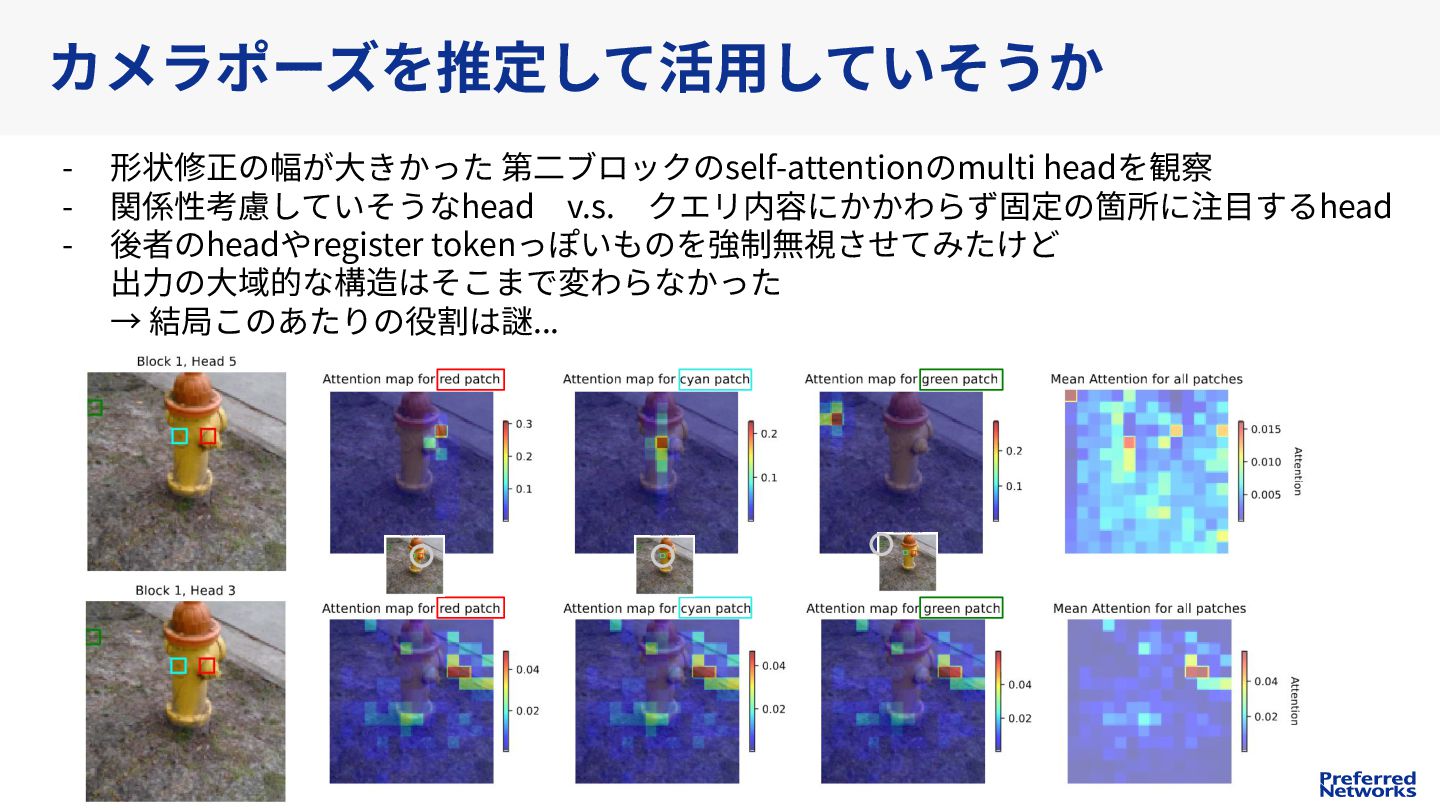{kind=link}
{kind=link}
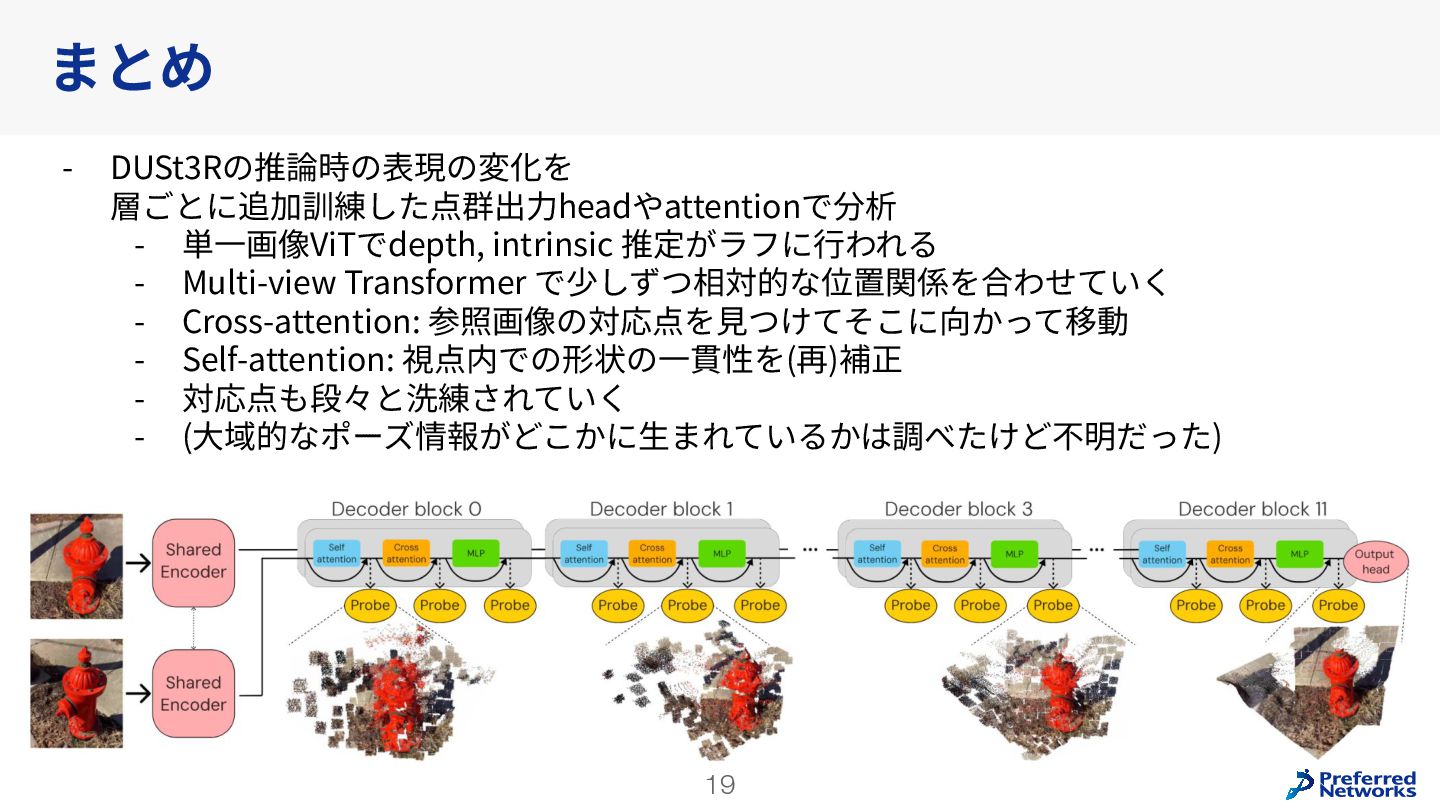{kind=link}
![20 おまけ VGGTの観察 - ⾃分で実装して [2503.11651] VGGT: Visual Geometry Grounded Transformer](https://files.speakerdeck.com/presentations/65f4ddc9f2d6477b95c5474bcb6abc57/slide_19.jpg){kind=link}
![21 おまけ VGGTの観察 - ⾃分で実装して [2503.11651] VGGT: Visual Geometry Grounded Transformer](https://files.speakerdeck.com/presentations/65f4ddc9f2d6477b95c5474bcb6abc57/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}