Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
3D Prior is All You Need: Cross-Task Few-shot 2...
Search
Spatial AI Network
November 04, 2025
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
学習済みの3次元視線方向推定モデルを少数枚の画像でファインチューニングすることで、スクリーンとカメラ間の外部キャリブレーションを行わずに高精度な2次元注視点推定を実現する
Spatial AI Network
November 04, 2025
More Decks by Spatial AI Network
See All by Spatial AI Network
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
130
MeshFlow : Efficient Artistic Mesh Generation via MeshVAE and Flow-based Diffusion Transformer
spatial_ai_network
0
60
EcoSplat: Efficiency-controllable Feed-forward 3D Gaussian Splatting from Multi-view Images
spatial_ai_network
0
65
3DCodeBench: Benchmarking Agentic Procedural 3D Modeling Via Code
spatial_ai_network
0
97
Differentiable Adaptive 4D Structured Illumination for Joint Capture of Shape and Reflectance
spatial_ai_network
0
100
FastGS: Training 3D Gaussian Splatting in 100 Seconds (CVPR2026 Highlight)
spatial_ai_network
0
120
Uncalibrated Structure from Motion on a Sphere (ICCV 2025)
spatial_ai_network
0
220
Understanding multi-view transformers (and VGGT)
spatial_ai_network
2
610
Preconditioned Single-step Transforms for Non-rigid ICP (Eurographics 2025)
spatial_ai_network
0
180
Other Decks in Technology
See All in Technology
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
4
3.9k
AI Driven AI Governance
pict3
0
470
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.3k
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
230
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
450
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.4k
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
アカウントが増えてからでは遅い? ~ マルチアカウント統制の勘所 ~
kenichinakamura
0
250
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3.2k
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
280
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
300
発表と総括 / Presentations and Summary
ks91
PRO
0
130
Featured
See All Featured
Ruling the World: When Life Gets Gamed
codingconduct
0
280
The untapped power of vector embeddings
frankvandijk
2
1.8k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
First, design no harm
axbom
PRO
2
1.2k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Music & Morning Musume
bryan
47
7.3k
Agile that works and the tools we love
rasmusluckow
331
22k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Transcript
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze
Estimation 2025/10/14 Spatial AI Network勉強会 京都⼯芸繊維⼤学 橋本和希 Authors: Yihua Cheng, Hengfei Wang, Zhongqun Zhang, Yang Yue,Boeun Kim, Feng Lu, Hyung Jin Chang Venue: CVPR 2025 Web: https://www.yihua.zone/work/gaze322/
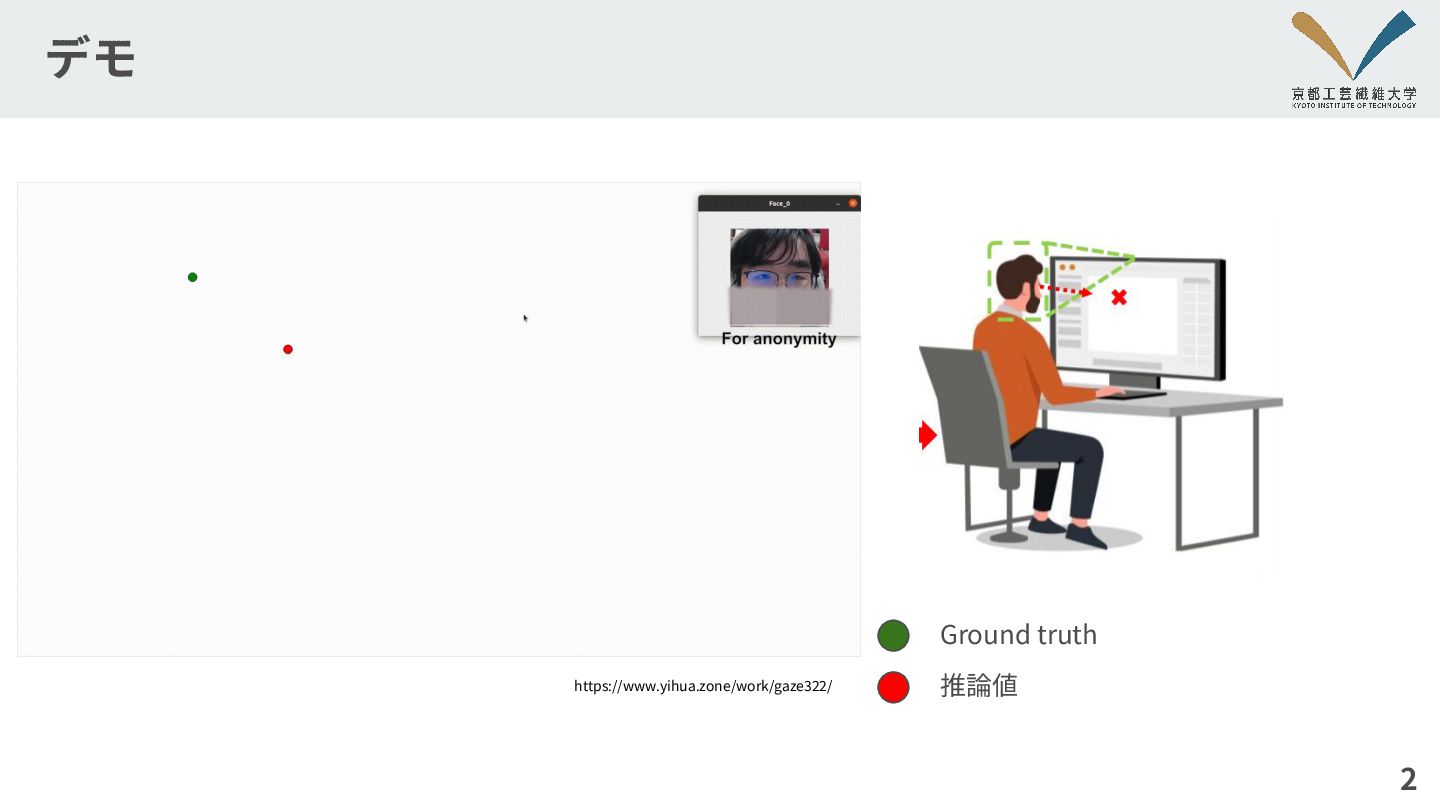
デモ 2 Ground truth 推論値 https://www.yihua.zone/work/gaze322/
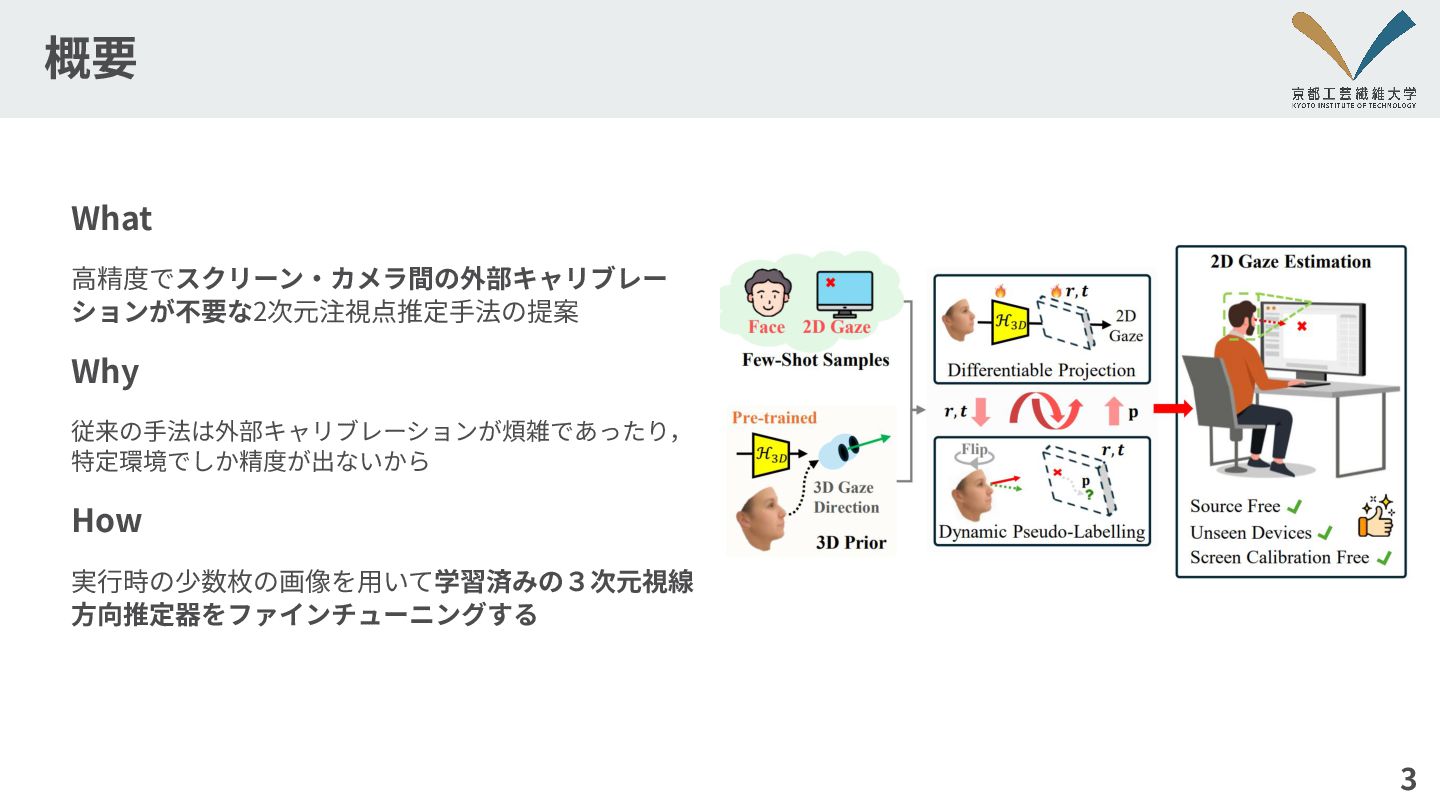
概要 3 What ⾼精度でスクリーン‧カメラ間の外部キャリブレー ションが不要な2次元注視点推定⼿法の提案 Why 従来の⼿法は外部キャリブレーションが煩雑であったり, 特定環境でしか精度が出ないから How 実⾏時の少数枚の画像を⽤いて学習済みの3次元視線
⽅向推定器をファインチューニングする
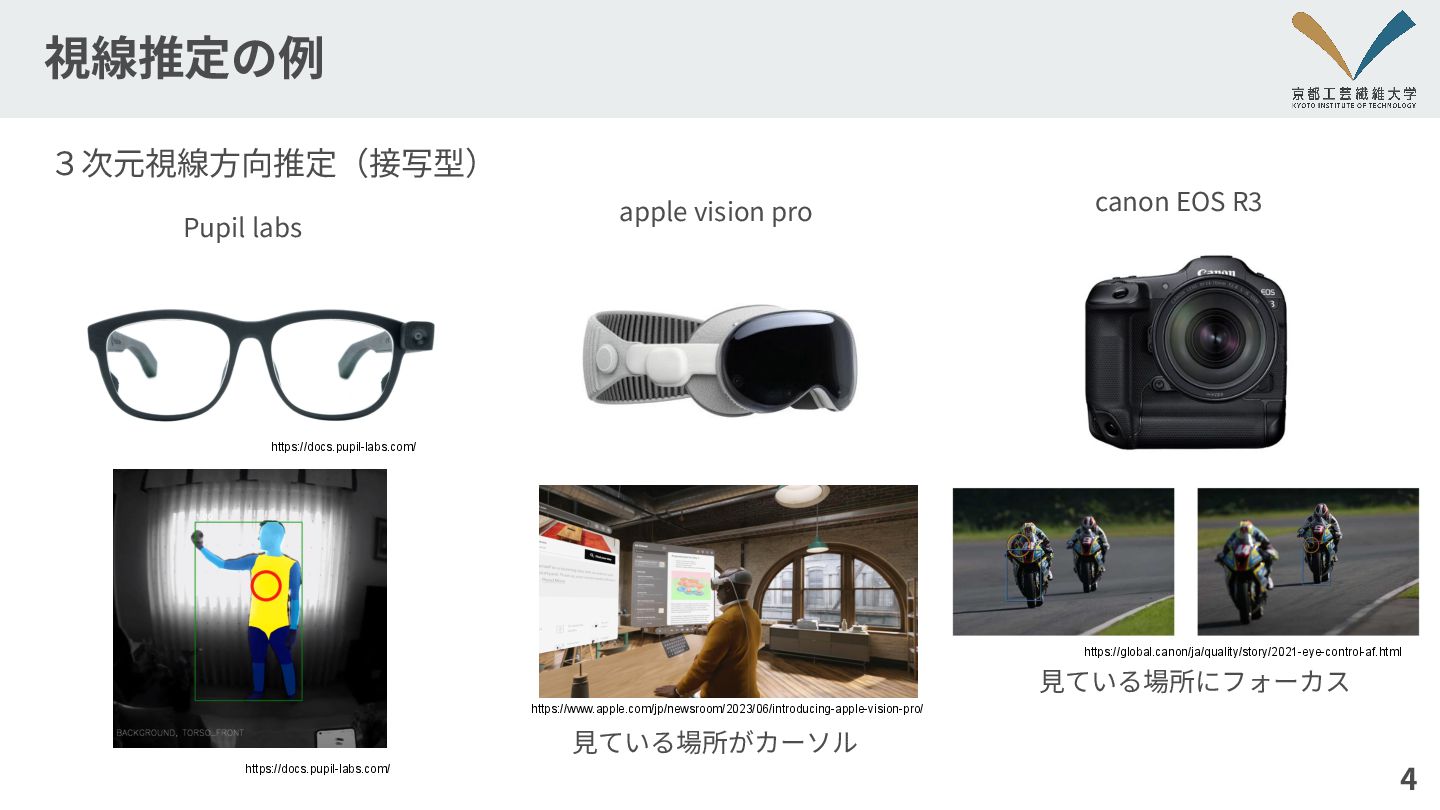
視線推定の例 4 3次元視線⽅向推定(接写型) Pupil labs apple vision pro canon EOS
R3 ⾒ている場所にフォーカス ⾒ている場所がカーソル https://global.canon/ja/quality/story/2021-eye-control-af.html https://www.apple.com/jp/newsroom/2023/06/introducing-apple-vision-pro/ https://docs.pupil-labs.com/ https://docs.pupil-labs.com/
視線計測の例 3次元視線⽅向推定(俯瞰カメラ) 5 Dynamic 3D Gaze from Afar:Deep Gaze Estimation
from Temporal Eye-Head-Body CoordinationPermalink[Soma Nonaka+ , CVPR2022] Gaze estimation using transformer [ Yihua Cheng+, ICPR2022]
視線計測の例 6 2次元注視点計測(画像内) Object-aware Gaze Target Detection[Francesco Tonini+ , ICCV
2023]
視線計測の例 7 2次元注視点推定 https://www.tobii.com/ja
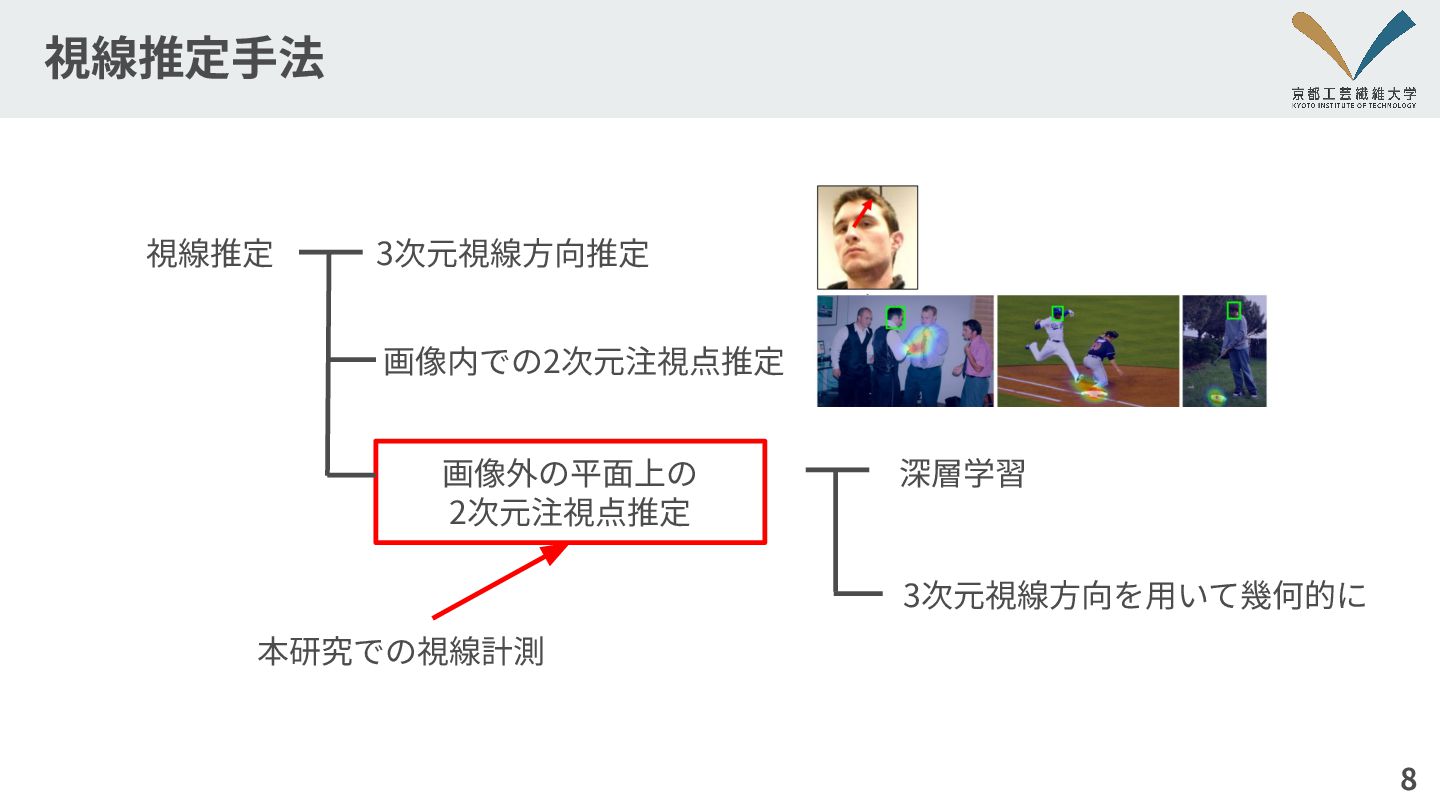
視線推定⼿法 8 3次元視線⽅向推定 視線推定 画像内での2次元注視点推定 深層学習 3次元視線⽅向を⽤いて幾何的に 本研究での視線計測 画像外の平⾯上の 2次元注視点推定
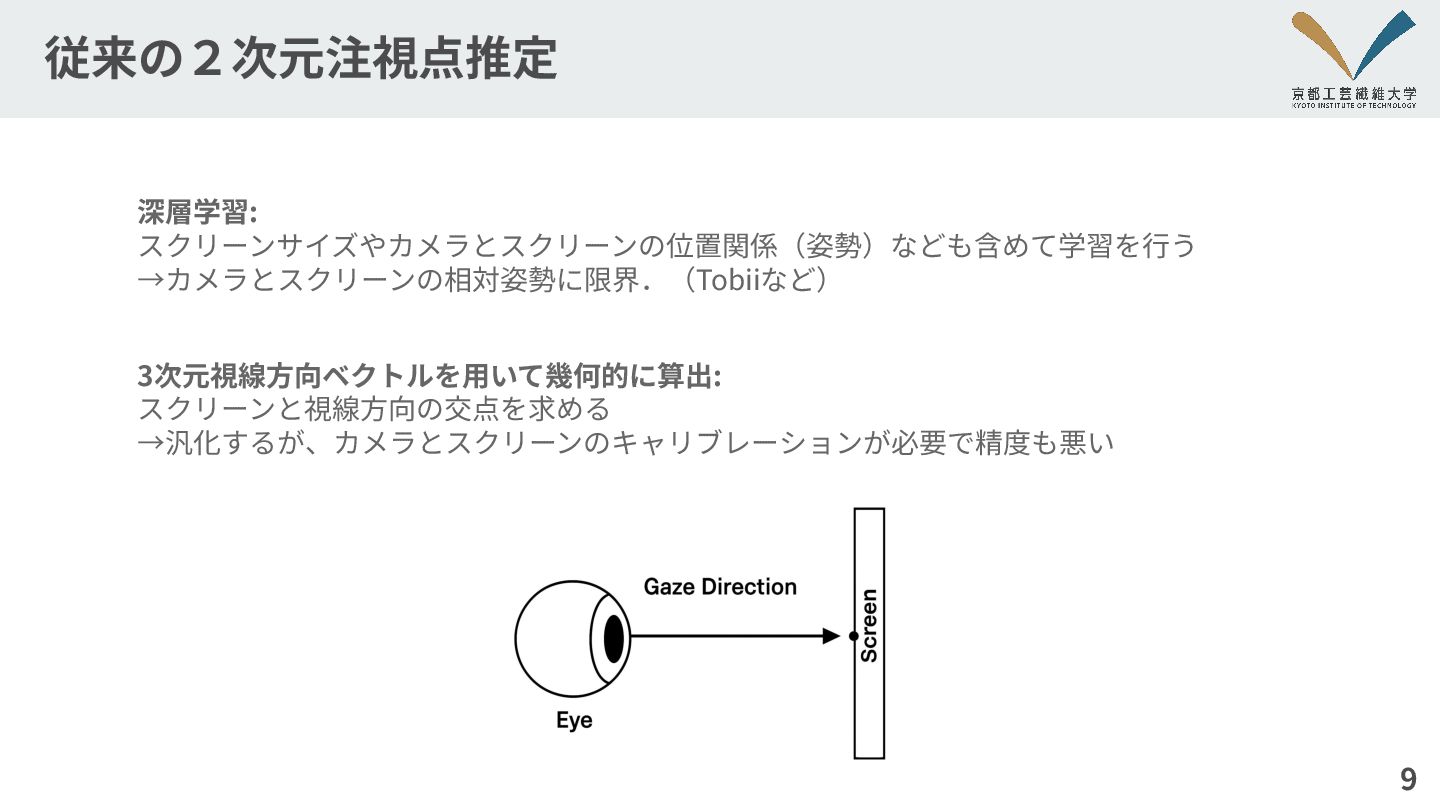
従来の2次元注視点推定 9 深層学習: スクリーンサイズやカメラとスクリーンの位置関係(姿勢)なども含めて学習を⾏う →カメラとスクリーンの相対姿勢に限界.(Tobiiなど) 3次元視線⽅向ベクトルを⽤いて幾何的に算出: スクリーンと視線⽅向の交点を求める →汎化するが、カメラとスクリーンのキャリブレーションが必要で精度も悪い
提案⼿法 スクリーンと視線⽅向の交点を求める⼿続きを微分可能にする 10 画像と2D注視点を使ってend-to-endに学習できる 外部キャリブレーション不要 ‧学習済みの3次元視線推定器をファインチューニング ‧スクリーンとカメラの外部パラメータを最適化対象に ‧3次元幾何に基づくデータ拡張 少数の画像で⾼精度な注視点推定
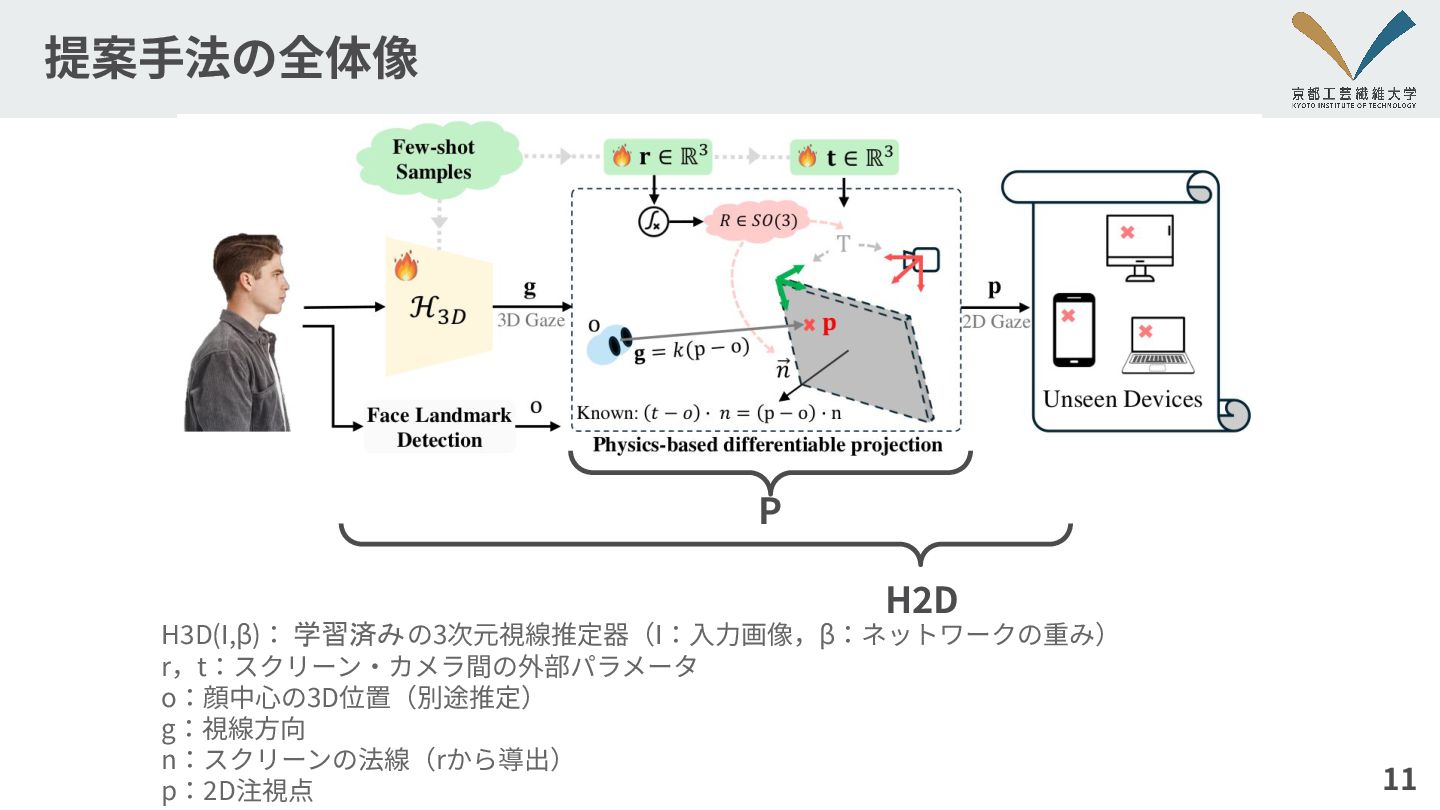
提案⼿法の全体像 11 H3D(I,β): 学習済みの3次元視線推定器(I:⼊⼒画像,β:ネットワークの重み) r,t:スクリーン‧カメラ間の外部パラメータ o:顔中⼼の3D位置(別途推定) g:視線⽅向 n:スクリーンの法線(rから導出) p:2D注視点 P
H2D
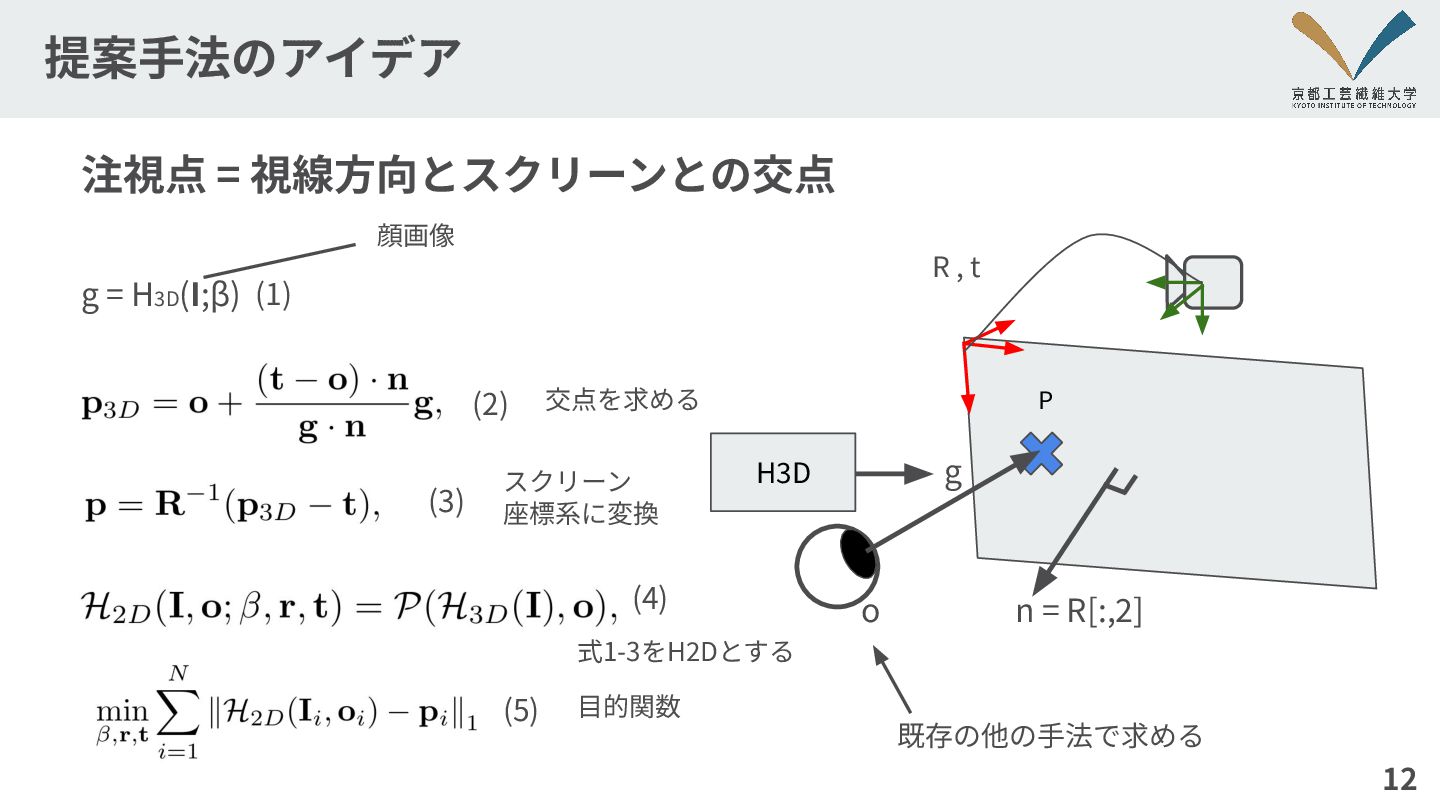
提案⼿法のアイデア 12 g = H3D(I;β) 注視点 = 視線⽅向とスクリーンとの交点 P g
o n = R[:,2] R , t H3D (1) (2) (3) (4) (5) 既存の他の⼿法で求める 交点を求める スクリーン 座標系に変換 式1-3をH2Dとする ⽬的関数 顔画像
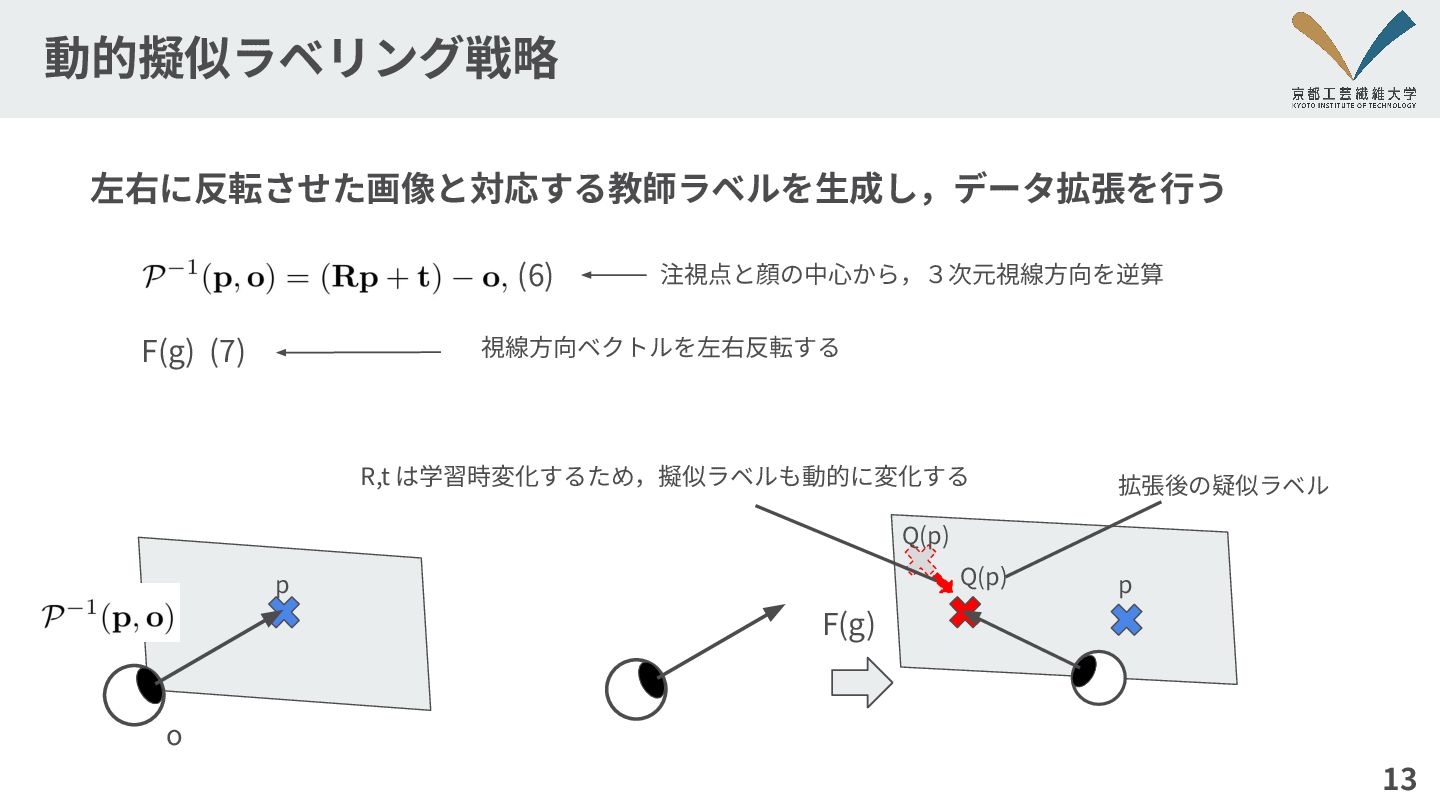
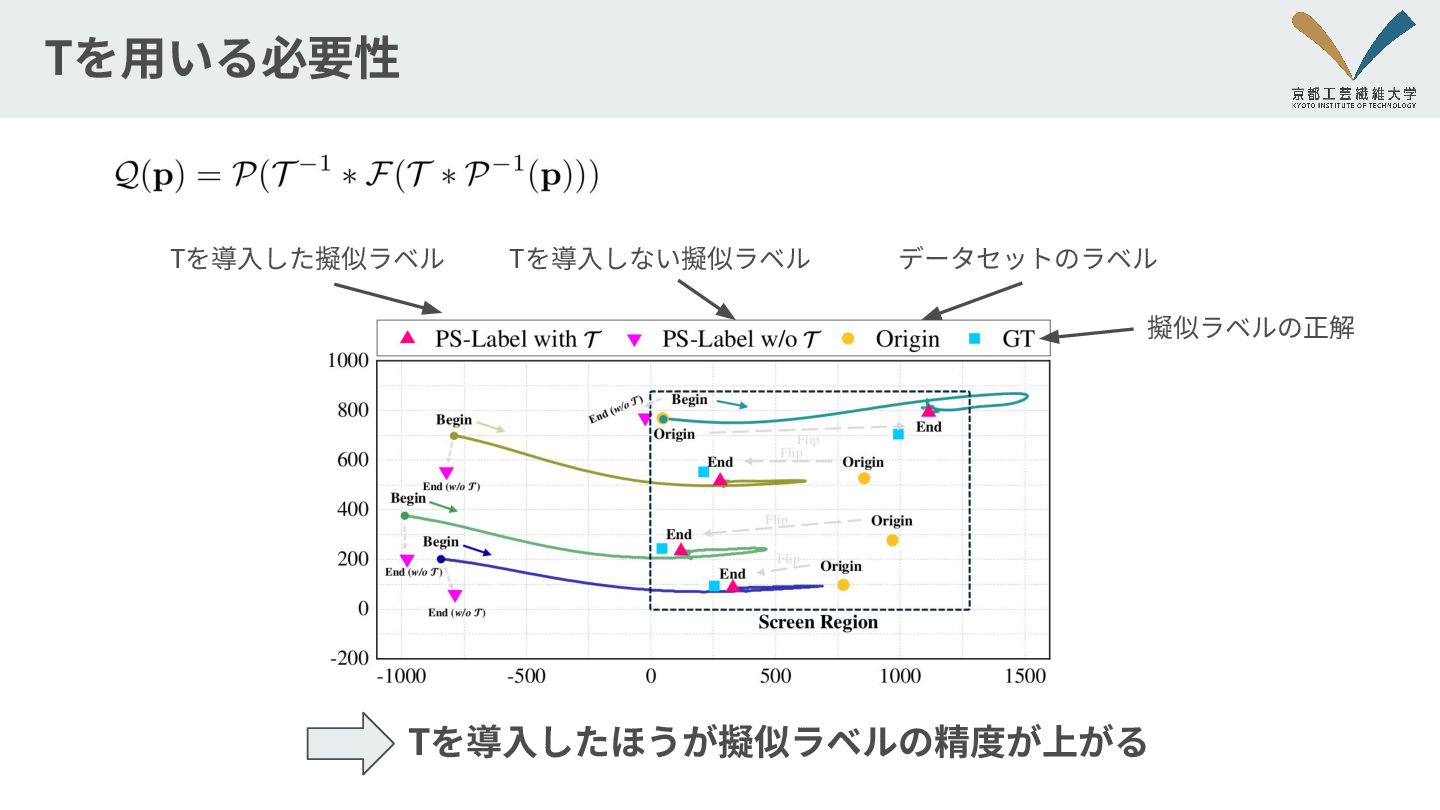
動的擬似ラベリング戦略 左右に反転させた画像と対応する教師ラベルを⽣成し,データ拡張を⾏う 13 F(g) 注視点と顔の中⼼から,3次元視線⽅向を逆算 o p 視線⽅向ベクトルを左右反転する F(g) (6)
(7) p Q(p) 拡張後の疑似ラベル Q(p) R,t は学習時変化するため,擬似ラベルも動的に変化する
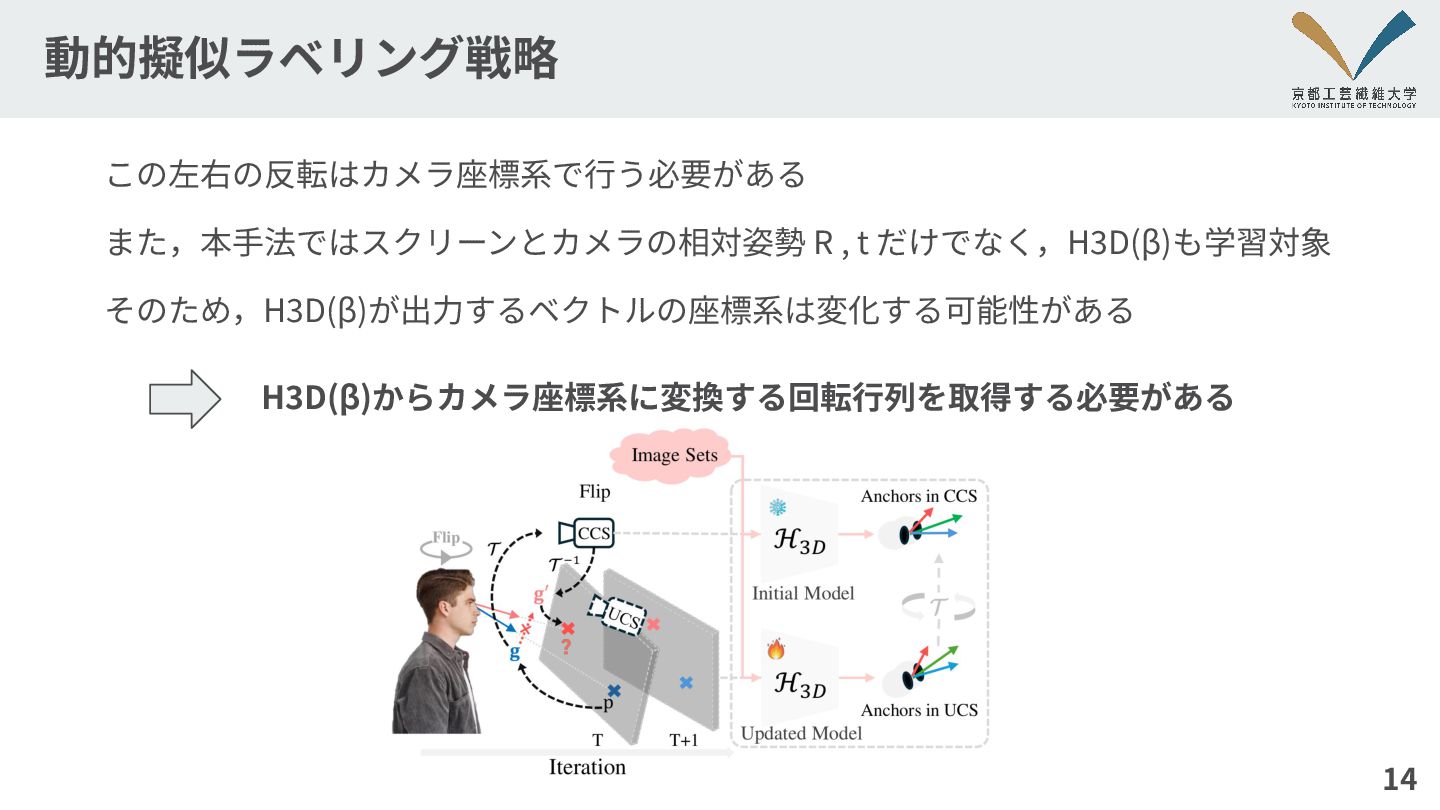
動的擬似ラベリング戦略 この左右の反転はカメラ座標系で⾏う必要がある また,本⼿法ではスクリーンとカメラの相対姿勢 R , t だけでなく,H3D(β)も学習対象 そのため,H3D(β)が出⼒するベクトルの座標系は変化する可能性がある 14 H3D(β)からカメラ座標系に変換する回転⾏列を取得する必要がある
動的擬似ラベリング戦略 追加学習をしていない初期H3D(β0 )はカメラ座標系である そのため,現在のH3D(β)から初期H3D(β0)に変換する回転⾏列 T を別途取得する 15 この式はOrthogonal Procrustes problemそのものであり,SVDで解くことができる
T = VUT 疑似ラベルQ(p)は (8) (9) (10) (11) 解決⽅法
データ拡張 16 カラージッターを⽤いた,データ拡張を⾏う (12) https://wiki.cloudfactory.com/docs/mp-wiki/augmentations/color-jitter データ拡張
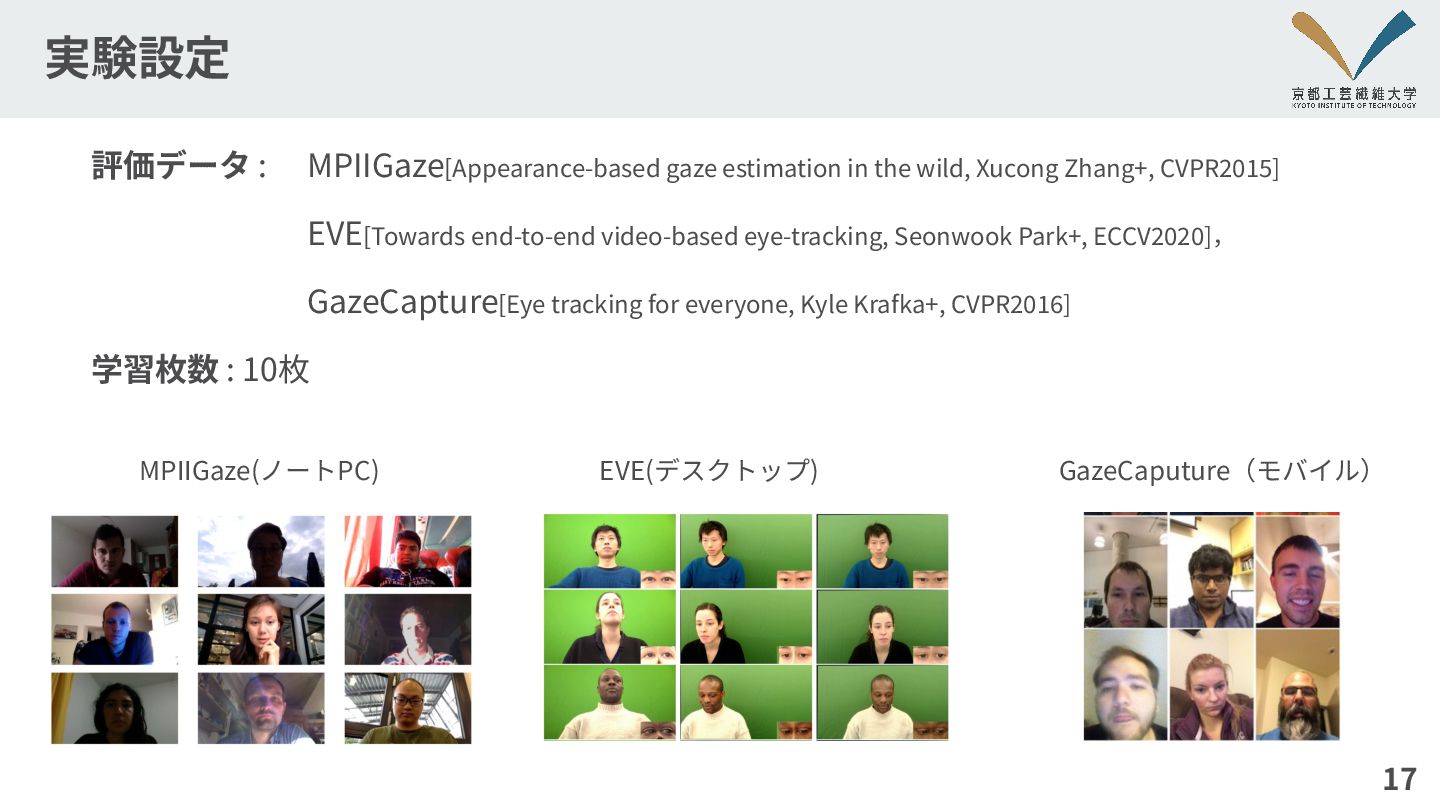
実験設定 評価データ : MPIIGaze[Appearance-based gaze estimation in the wild, Xucong
Zhang+, CVPR2015] EVE[Towards end-to-end video-based eye-tracking, Seonwook Park+, ECCV2020], GazeCapture[Eye tracking for everyone, Kyle Krafka+, CVPR2016] 学習枚数 : 10枚 17 MPIIGaze(ノートPC) EVE(デスクトップ) GazeCaputure(モバイル)
実験設定 使⽤したH3Dのネットワーク構造 : GazeTR [Yihua Cheng and Feng Lu, ICPR,
2022] 学習データセット : Gaze360 [Petr Kellnhofer+, ICCV2019] 18 Gaze360
実験設定 使⽤した3次元顔ランドマーク検出推定 : Towards fast, accurate and stable 3d dense
face alignment [Jianzhu Guo+, ECCV] 19 (5) (11) (12) ⽬的関数はこの3つ 1 0.4 0.25 重み
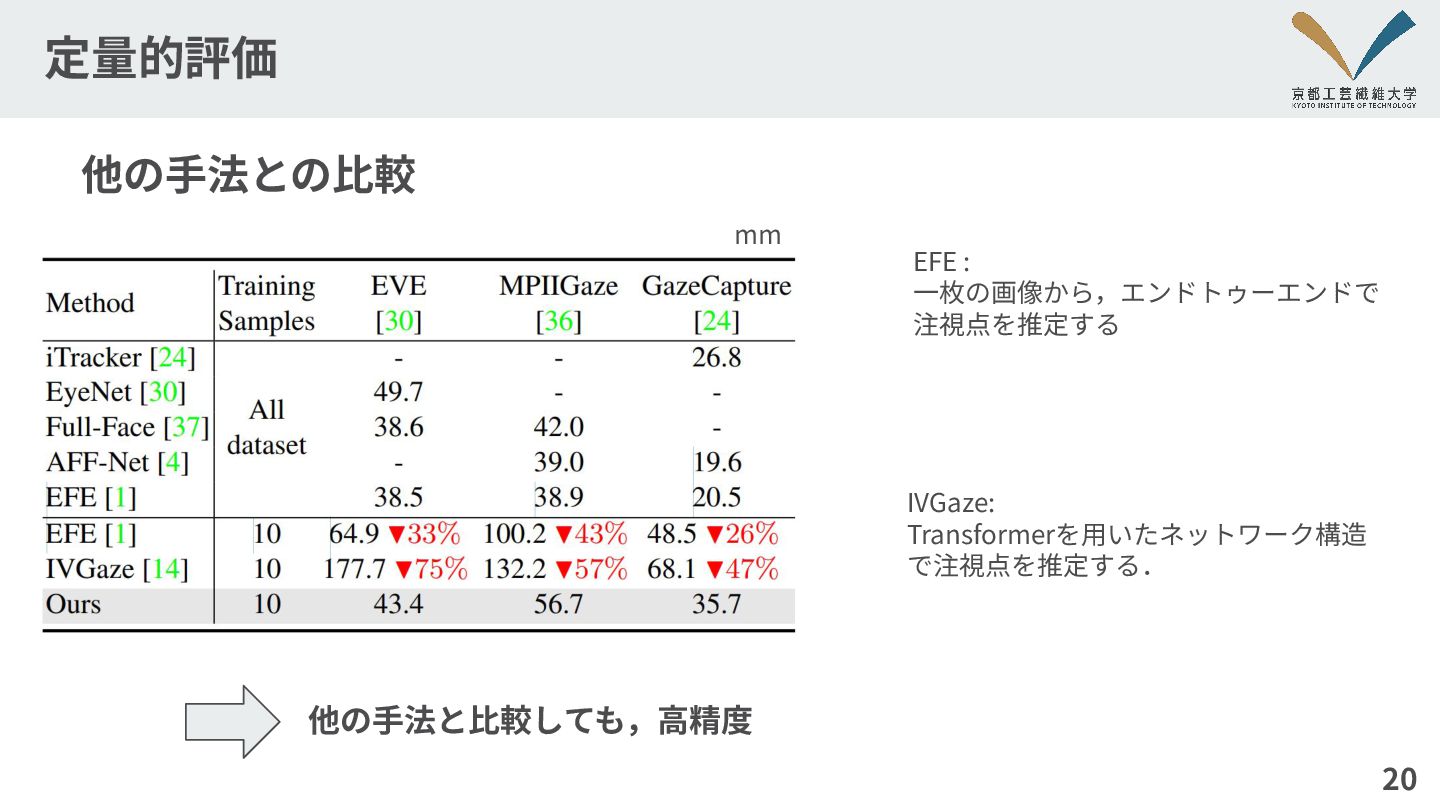
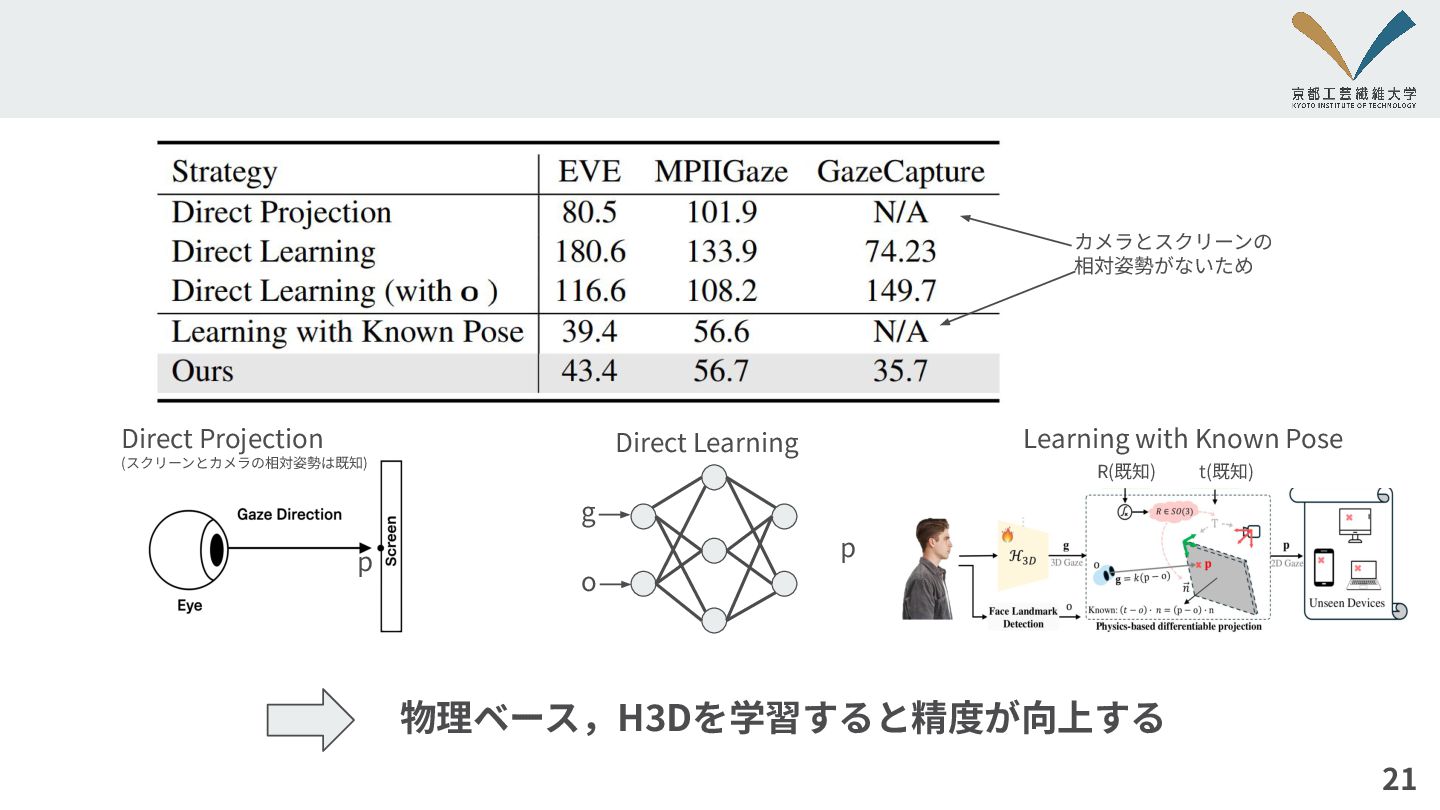
定量的評価 20 他の⼿法との⽐較 EFE : ⼀枚の画像から,エンドトゥーエンドで 注視点を推定する 他の⼿法と⽐較しても,⾼精度 mm IVGaze:
Transformerを⽤いたネットワーク構造 で注視点を推定する.
21 g o p カメラとスクリーンの 相対姿勢がないため Direct Projection (スクリーンとカメラの相対姿勢は既知) Direct
Learning p R(既知) t(既知) 物理ベース,H3Dを学習すると精度が向上する Learning with Known Pose
データ拡張の効果の評価結果 22 Proj : データ拡張なし PS-Label : 動的疑似ラベルを含める(+10枚) 𝓛unc :
ジッターのデータ拡張を含める(+40枚) ⼤きな精度向上はみられない
Tを⽤いる必要性 Tを導⼊した擬似ラベル Tを導⼊しない擬似ラベル データセットのラベル 擬似ラベルの正解 Tを導⼊したほうが擬似ラベルの精度が上がる
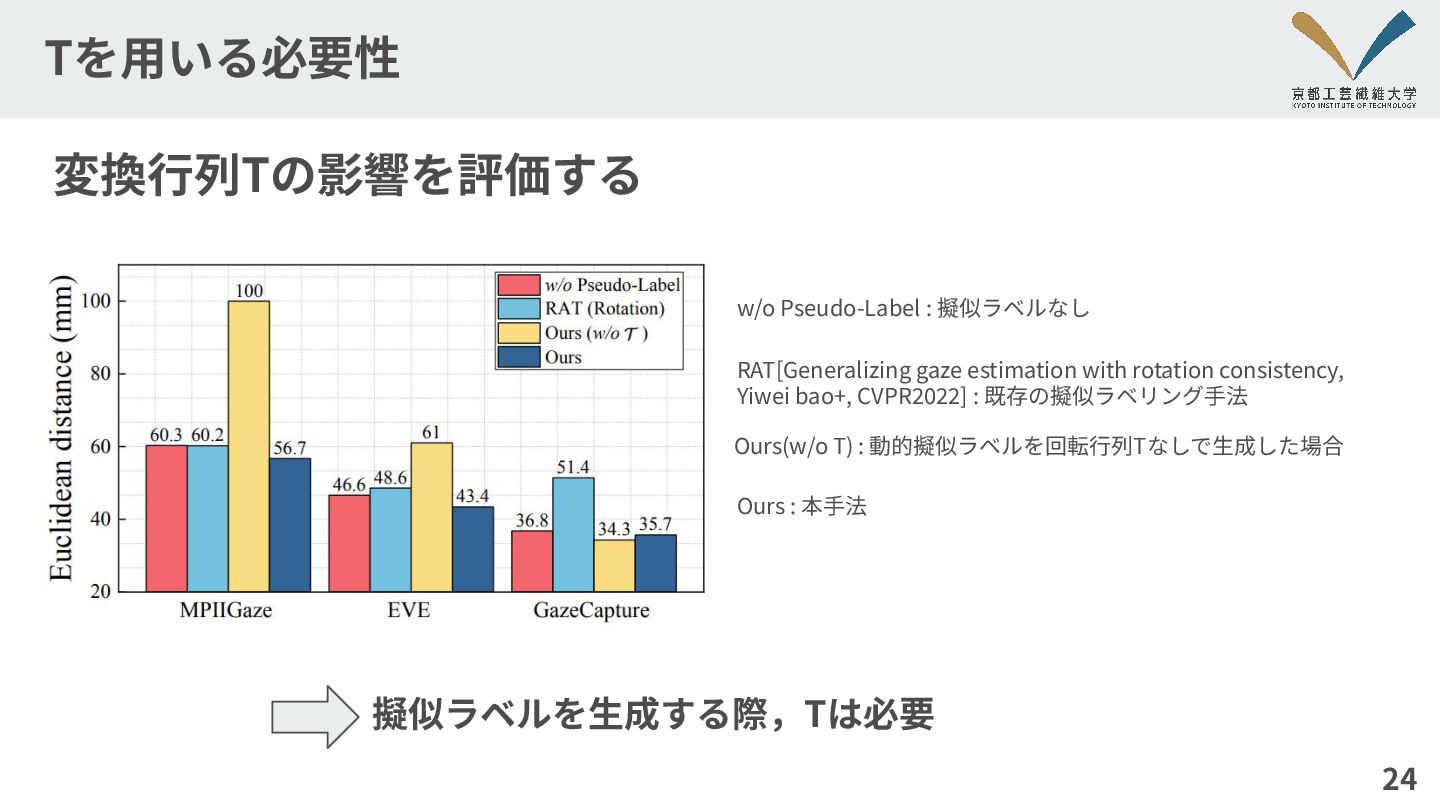
Tを⽤いる必要性 24 変換⾏列Tの影響を評価する RAT[Generalizing gaze estimation with rotation consistency, Yiwei
bao+, CVPR2022] : 既存の擬似ラベリング⼿法 w/o Pseudo-Label : 擬似ラベルなし Ours(w/o T) : 動的擬似ラベルを回転⾏列Tなしで⽣成した場合 Ours : 本⼿法 擬似ラベルを⽣成する際,Tは必要
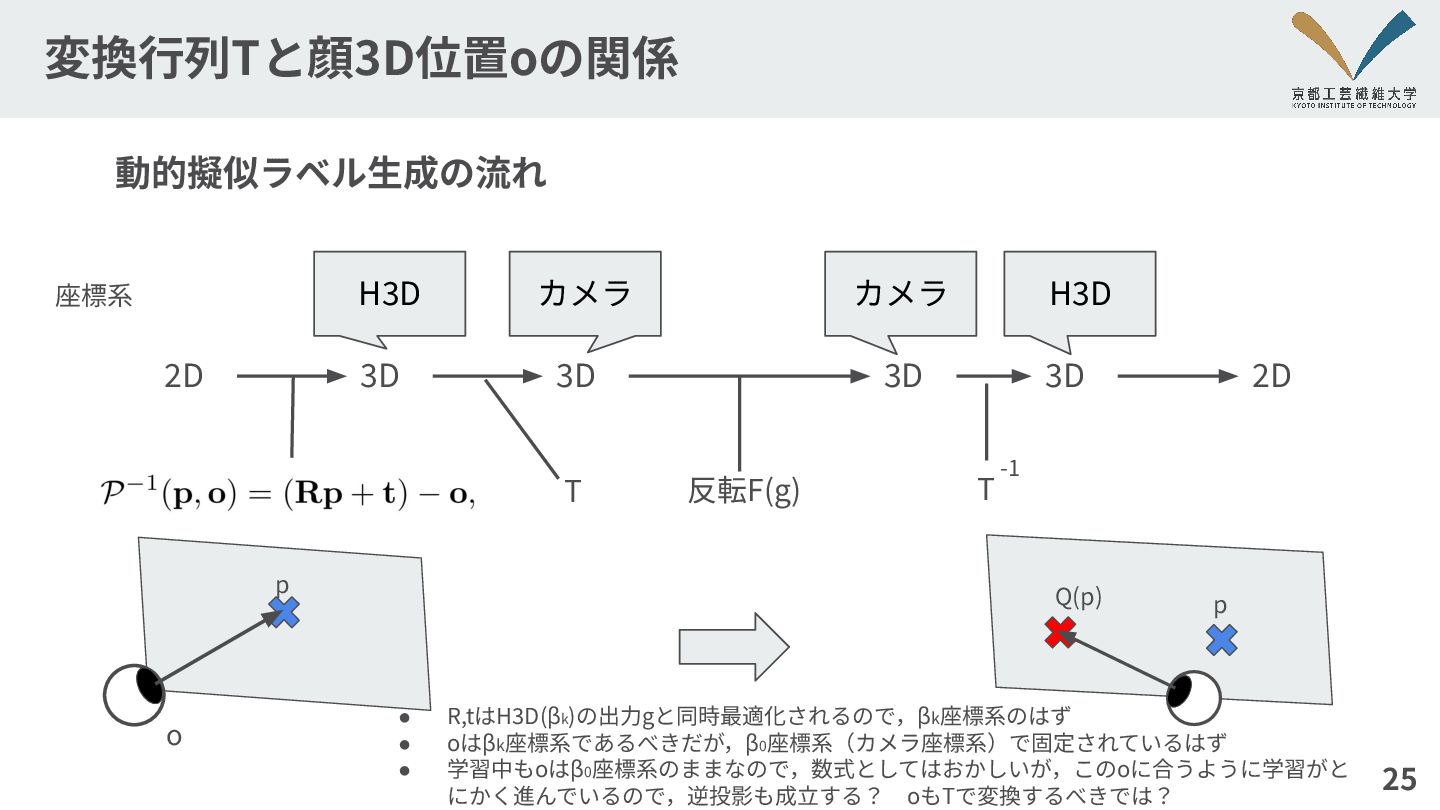
変換⾏列Tと顔3D位置oの関係 25 2D 2D 3D 3D 3D 3D 動的擬似ラベル⽣成の流れ 座標系
カメラ カメラ H3D H3D 反転F(g) T T -1 H3D カメラ カメラ H3D o p p Q(p) • R,tはH3D(βk)の出⼒gと同時最適化されるので,βk座標系のはず • oはβk座標系であるべきだが,β0座標系(カメラ座標系)で固定されているはず • 学習中もoはβ0座標系のままなので,数式としてはおかしいが,このoに合うように学習がと にかく進んでいるので,逆投影も成⽴する? oもTで変換するべきでは?
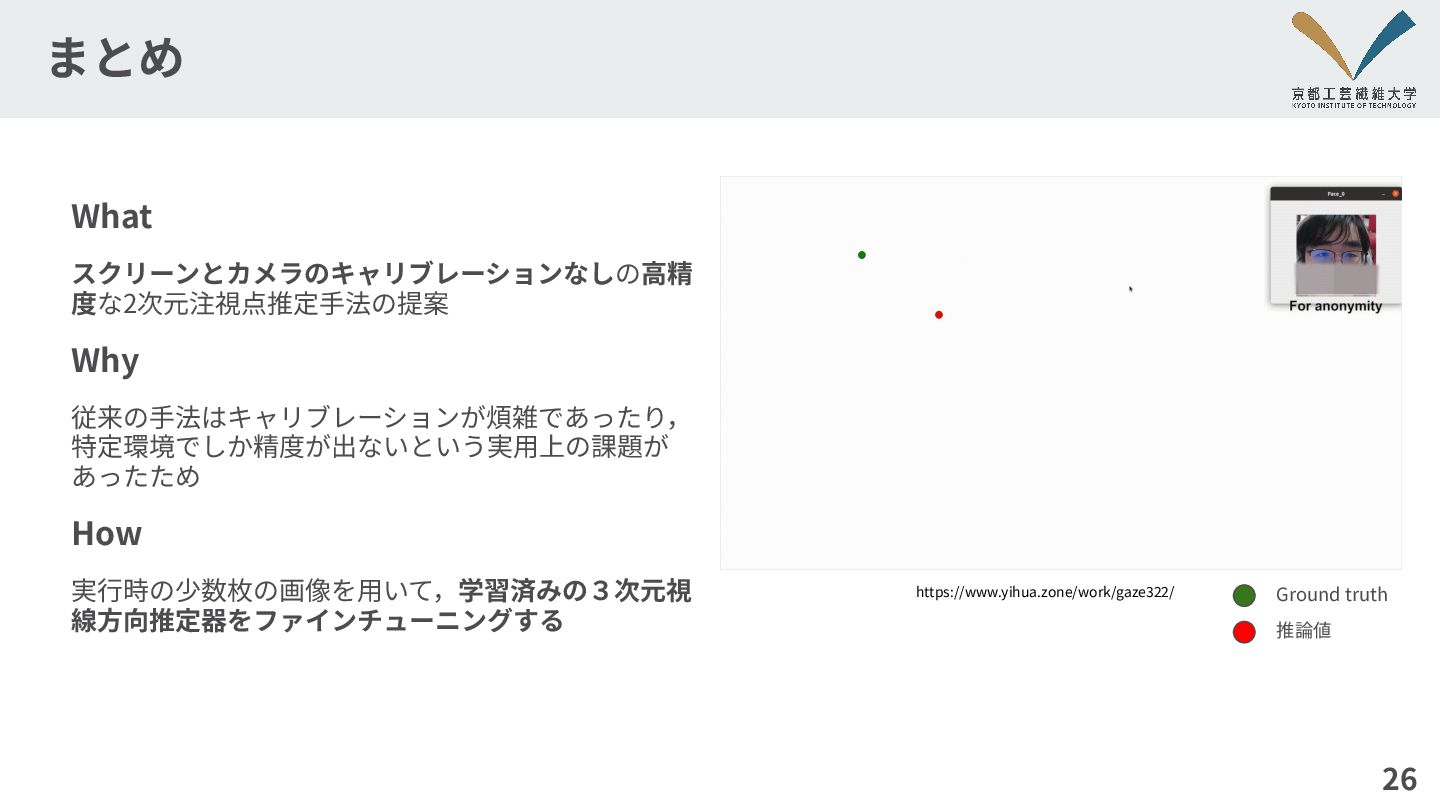
まとめ 26 What スクリーンとカメラのキャリブレーションなしの⾼精 度な2次元注視点推定⼿法の提案 Why 従来の⼿法はキャリブレーションが煩雑であったり, 特定環境でしか精度が出ないという実⽤上の課題が あったため How
実⾏時の少数枚の画像を⽤いて,学習済みの3次元視 線⽅向推定器をファインチューニングする Ground truth 推論値 https://www.yihua.zone/work/gaze322/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}