Sherwin Bahmani1,2,3 Tianchang Shen1,2,3 Jiawei Ren1 Jiahui Huang1 Yifeng Jiang1 Haithem Turki1 Andrea Tagliasacchi2,4 David B. Lindell2,3 Zan Gojcic1 Sanja Fidler1,2,3 Huan Ling1 Jun Gao1* Xuanchi Ren1,2,3* 1 NVIDIA 2 University of Toronto 3 Vector Institute 4 Simon Fraser University Spatial AI Network 勉強会 2025/10/28 野口敦裕 (Preferred Networks) ※特に注釈がなければ、図表は論文から引用しています
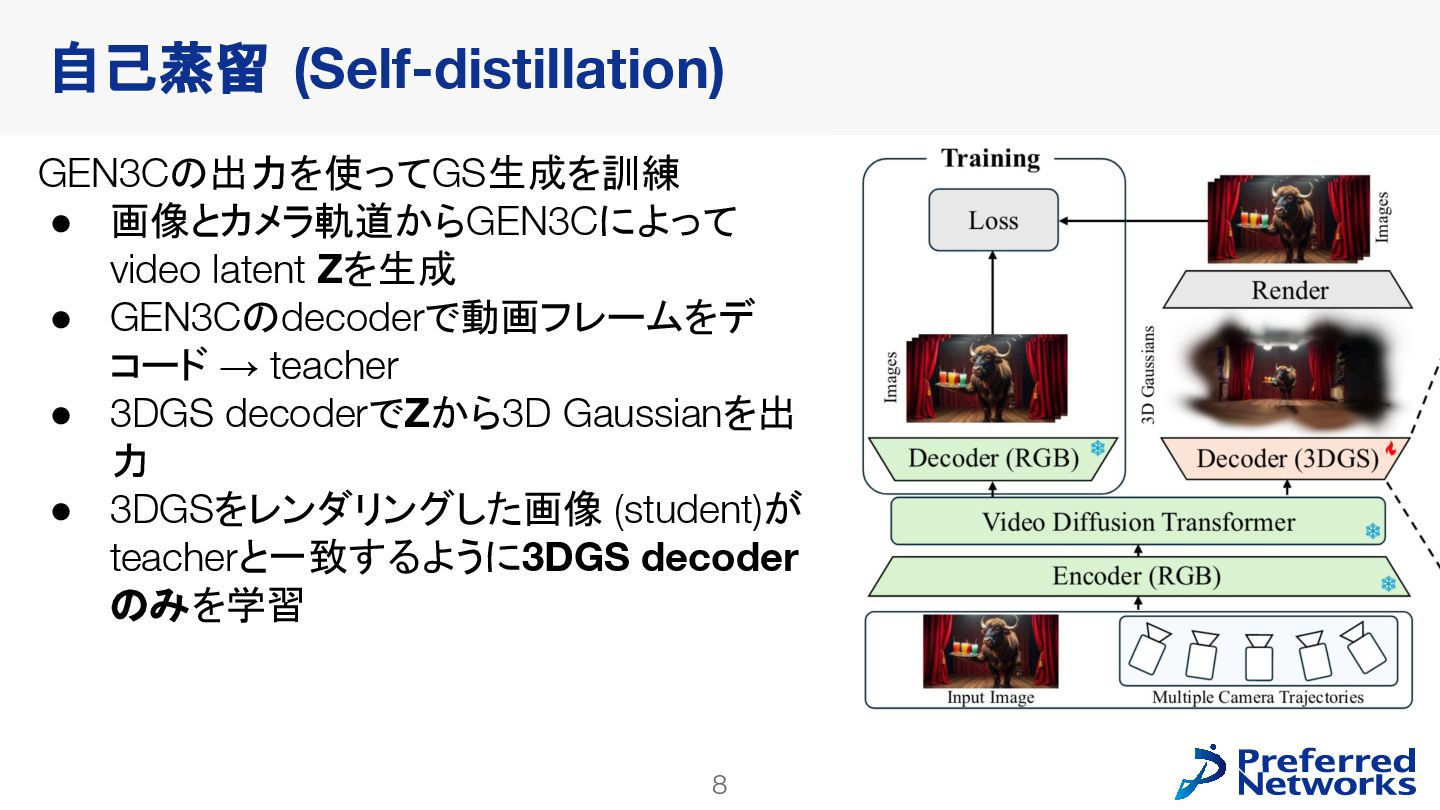
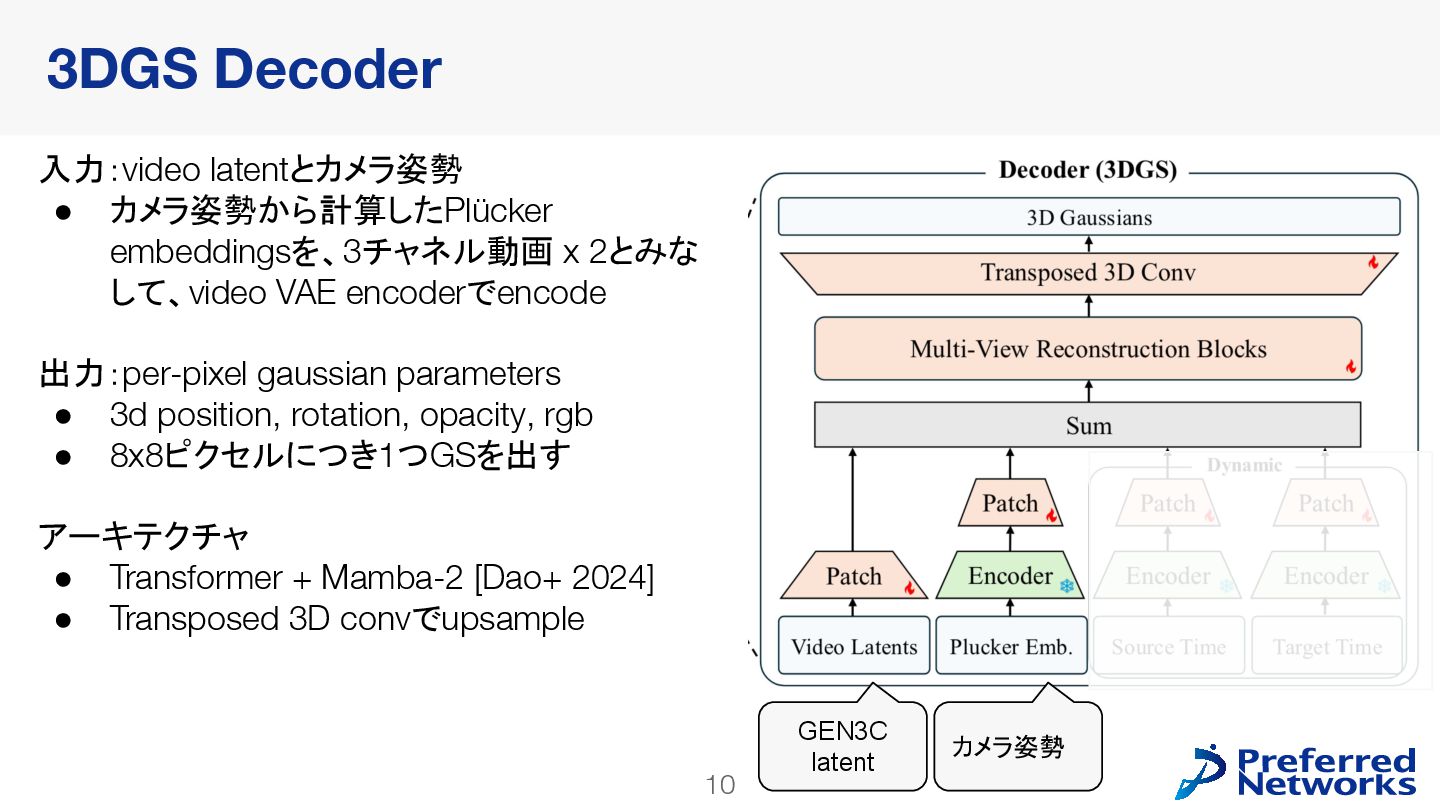
decoderを訓練 • 動画拡散モデルが生成した多様なデータで訓練できる • video latent spaceで訓練することで、計算コストが小さくなる • 明示的な3Dが得られるので、downstream taskに使いやすい Lyra: Generative 3D Scene Reconstruction
{kind=link}
{kind=link}
{kind=link}
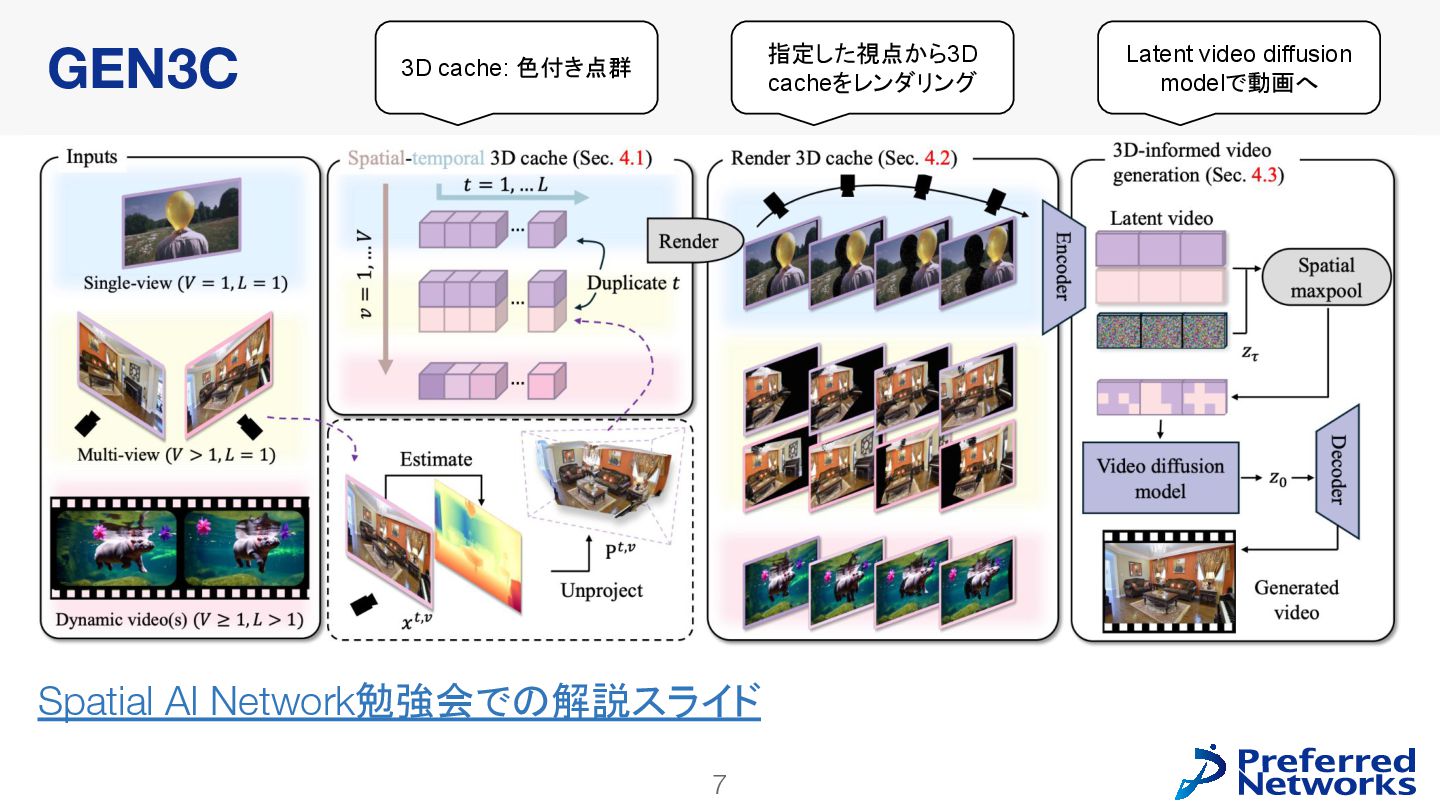
![4 Camera-conditioned video generation • e.g. GEN3C [Ren+ 2025] •](https://files.speakerdeck.com/presentations/f4b3e55937ee48dea8b41a1f21dce458/slide_3.jpg){kind=link}
![5 Feed-forward 3D 再構成 • 画像を入力として3D表現を出力するモデル ◦ GS-LRM [Zhang+ 2024],](https://files.speakerdeck.com/presentations/f4b3e55937ee48dea8b41a1f21dce458/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
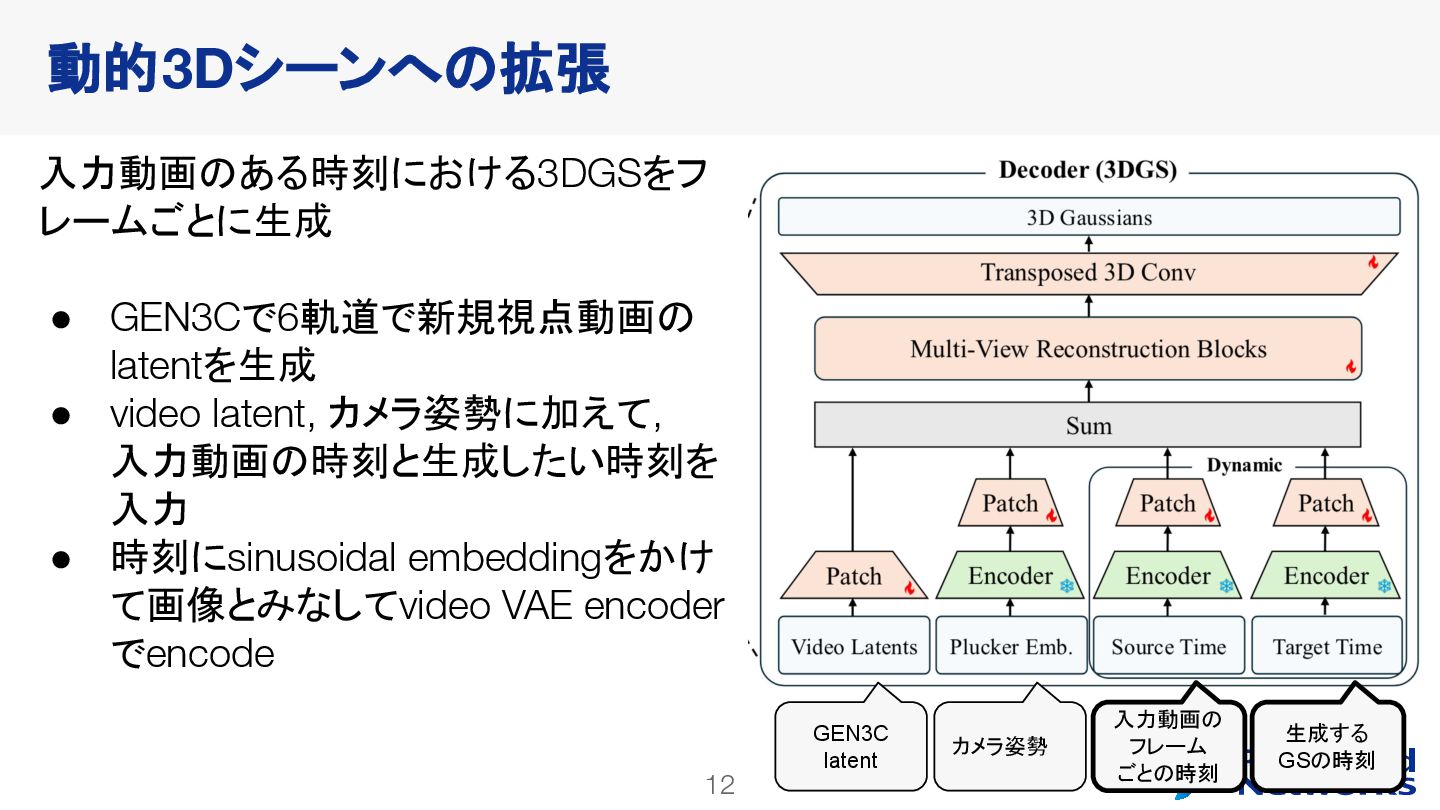{kind=link}
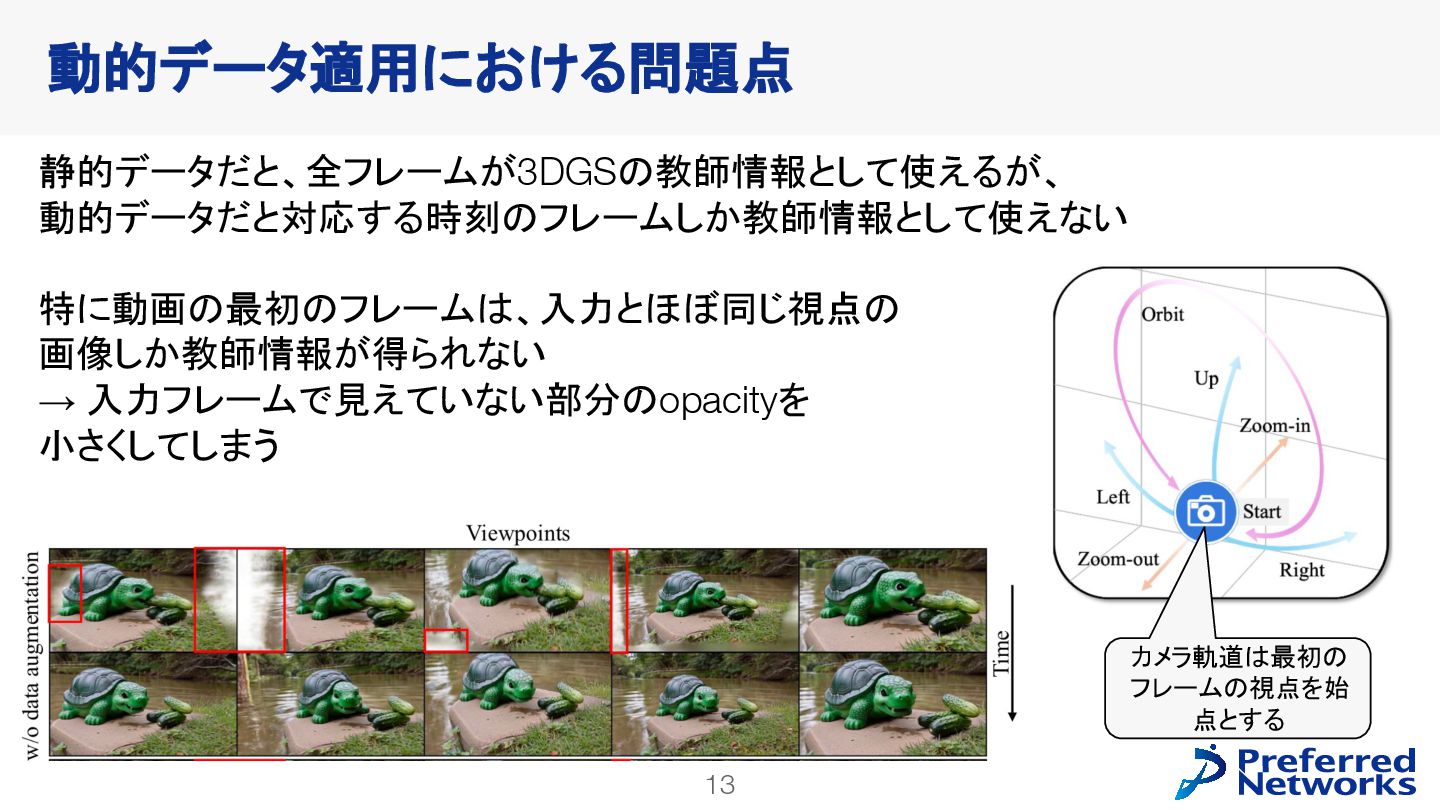{kind=link}
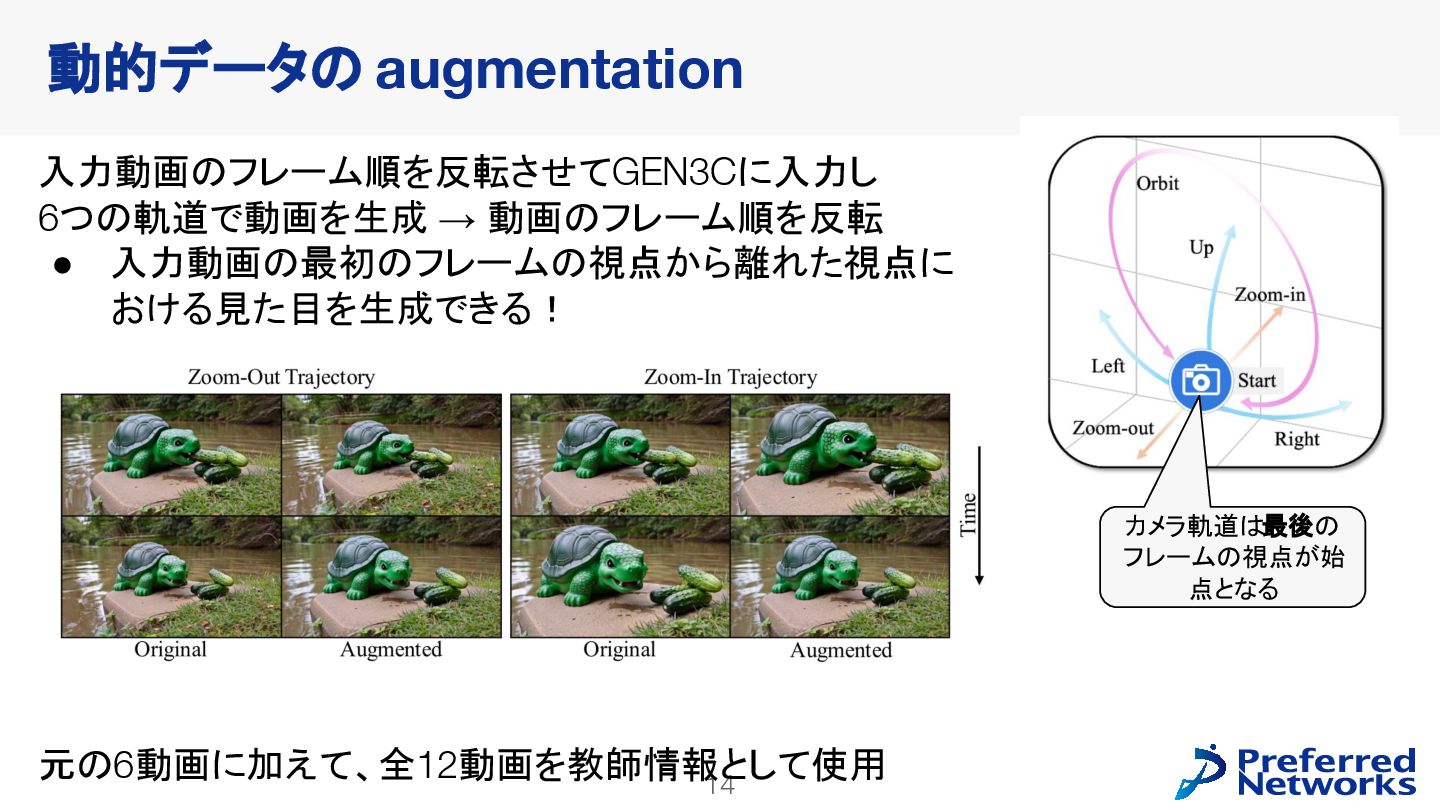{kind=link}
{kind=link}
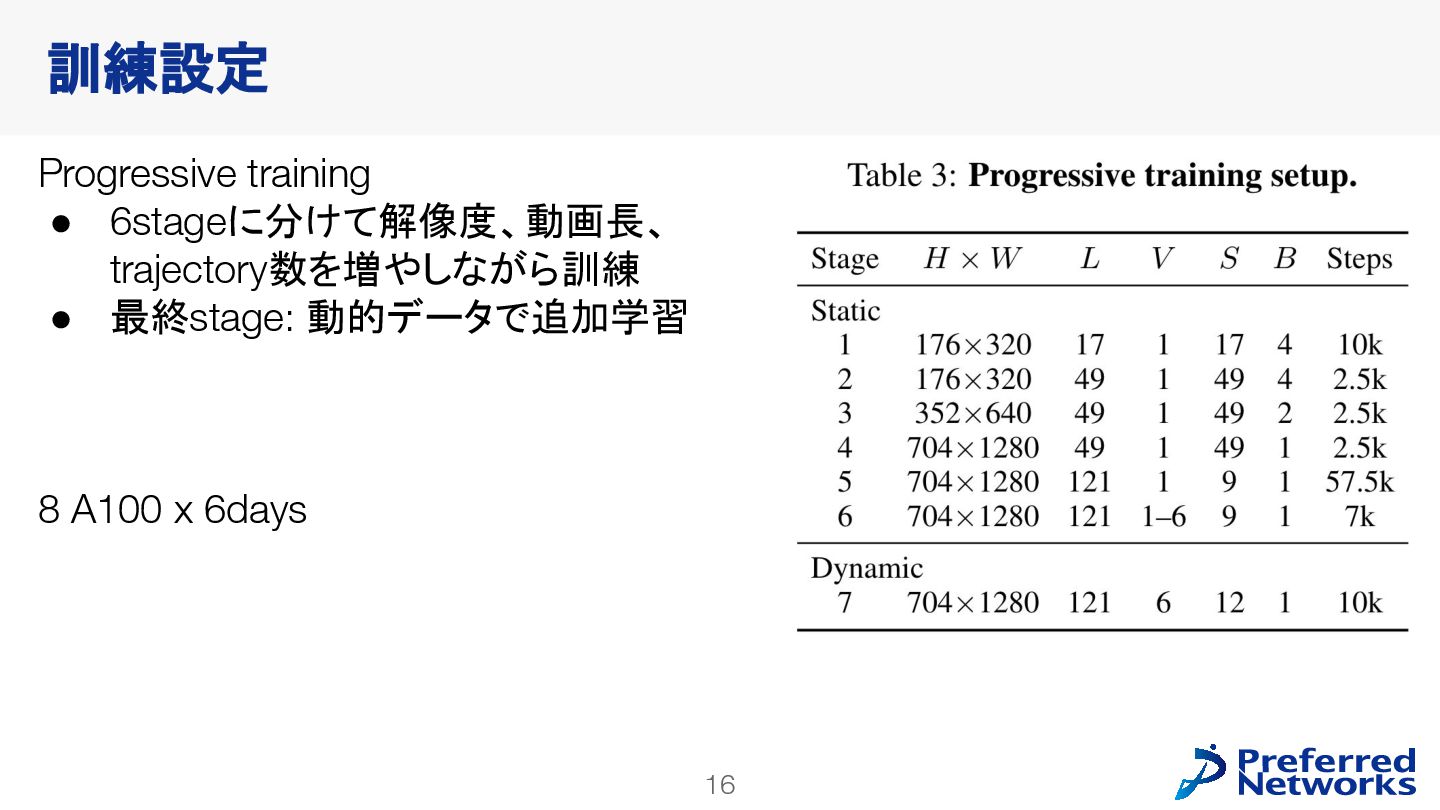{kind=link}
{kind=link}
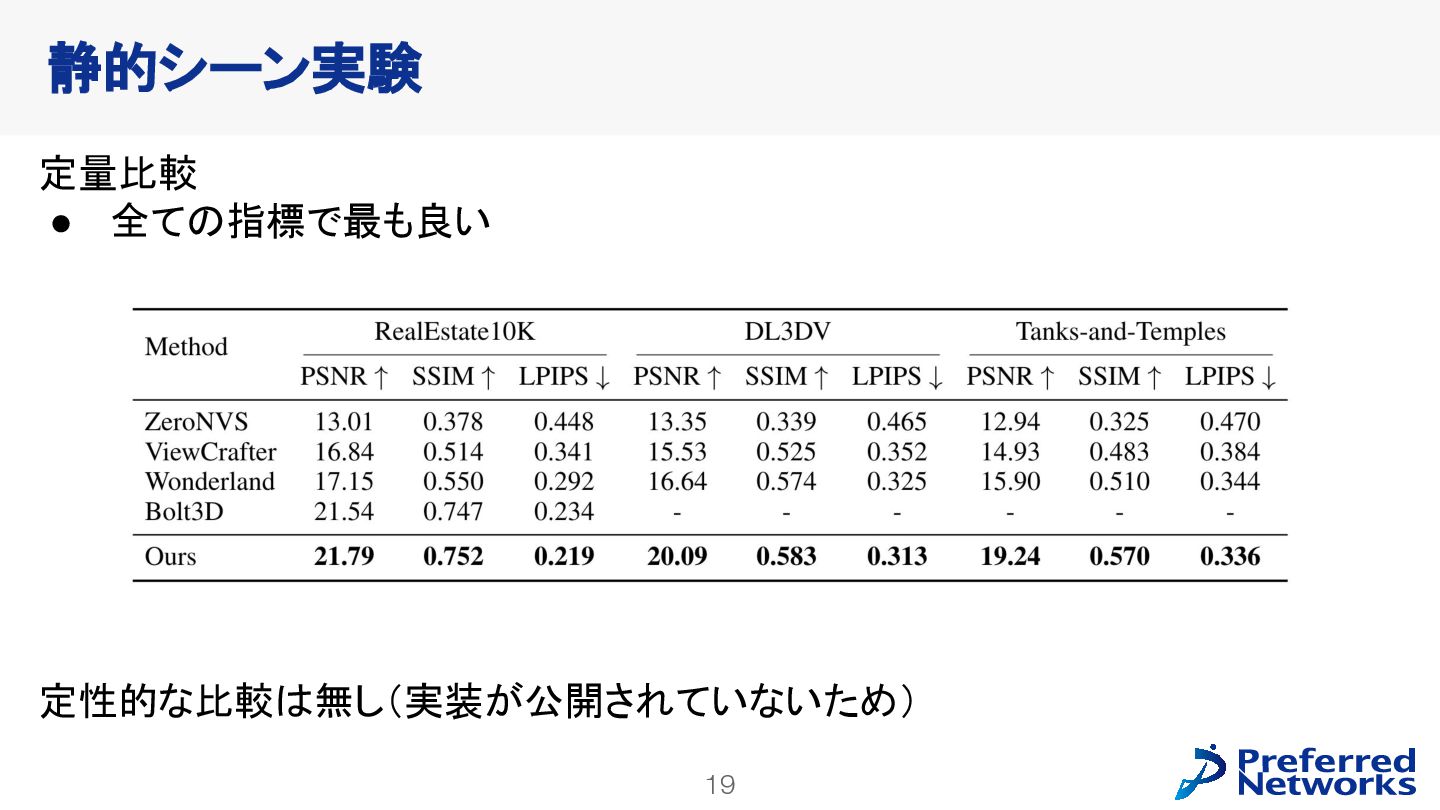
![18 ベースライン • ZeroNVS [Sargent+ 2024] 2D新規視点合成拡散モデルでSDS [Poole+ 2022] •](https://files.speakerdeck.com/presentations/f4b3e55937ee48dea8b41a1f21dce458/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
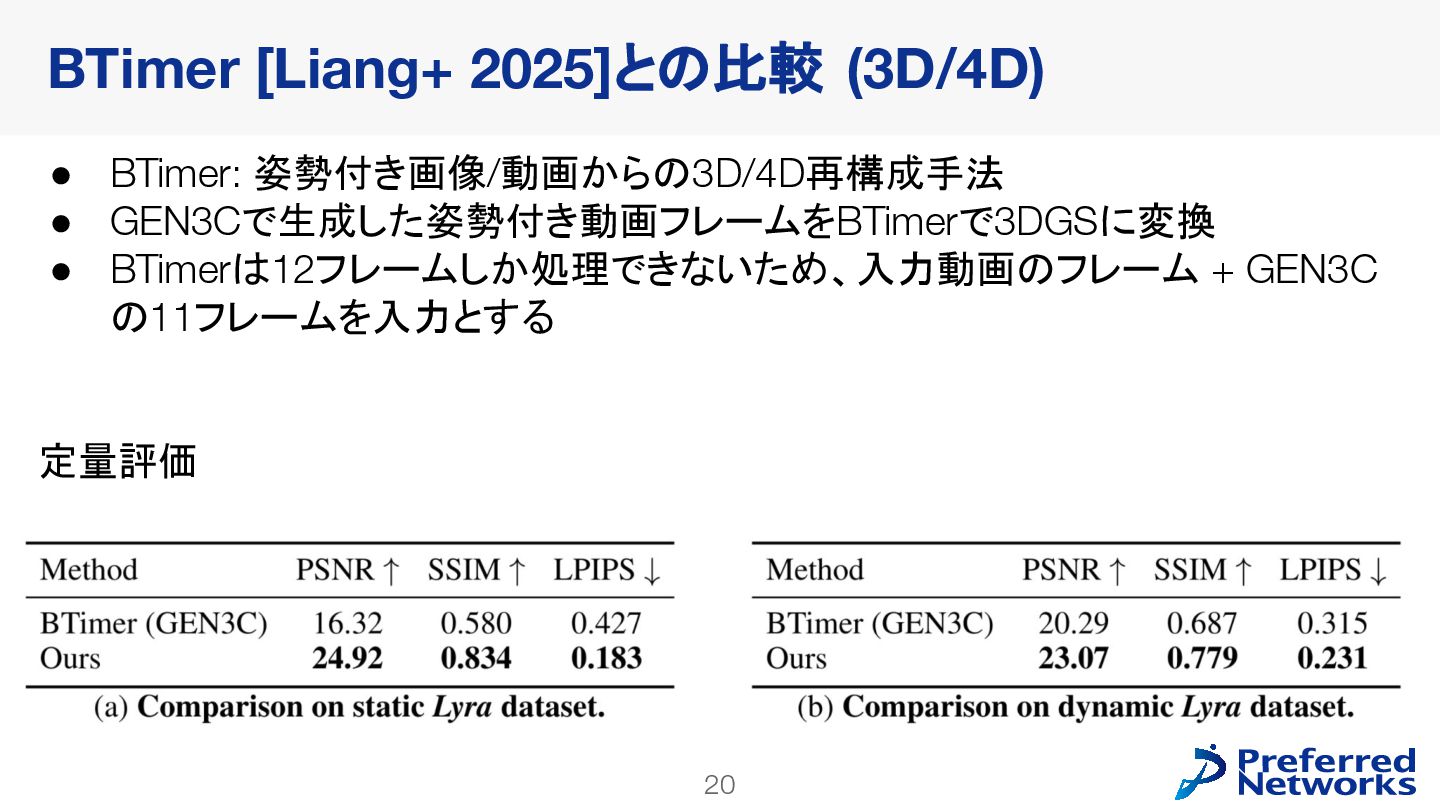
![21 定性評価 (3D) BTimer [Liang+ 2025]との比較 (3D)](https://files.speakerdeck.com/presentations/f4b3e55937ee48dea8b41a1f21dce458/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}