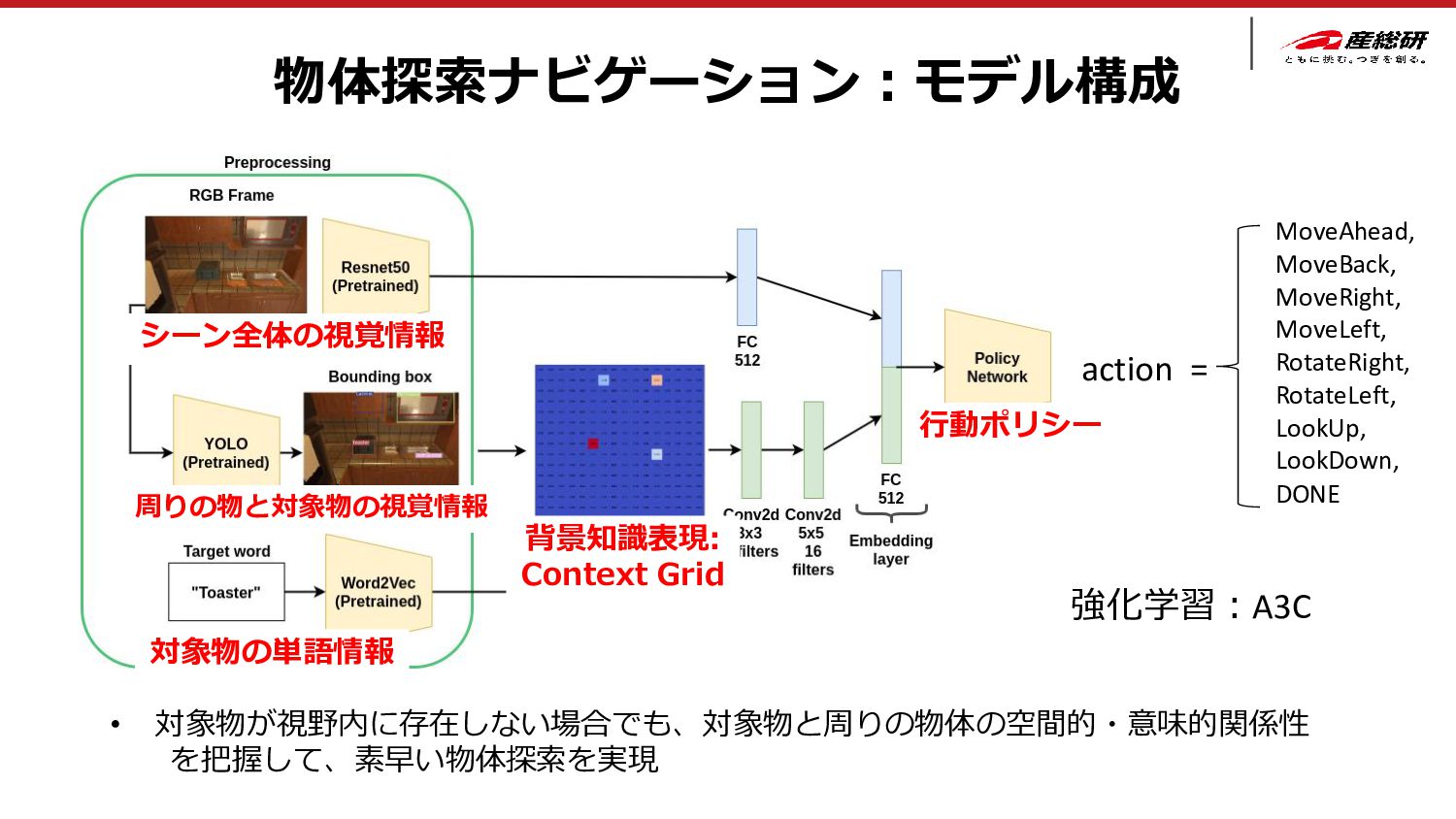
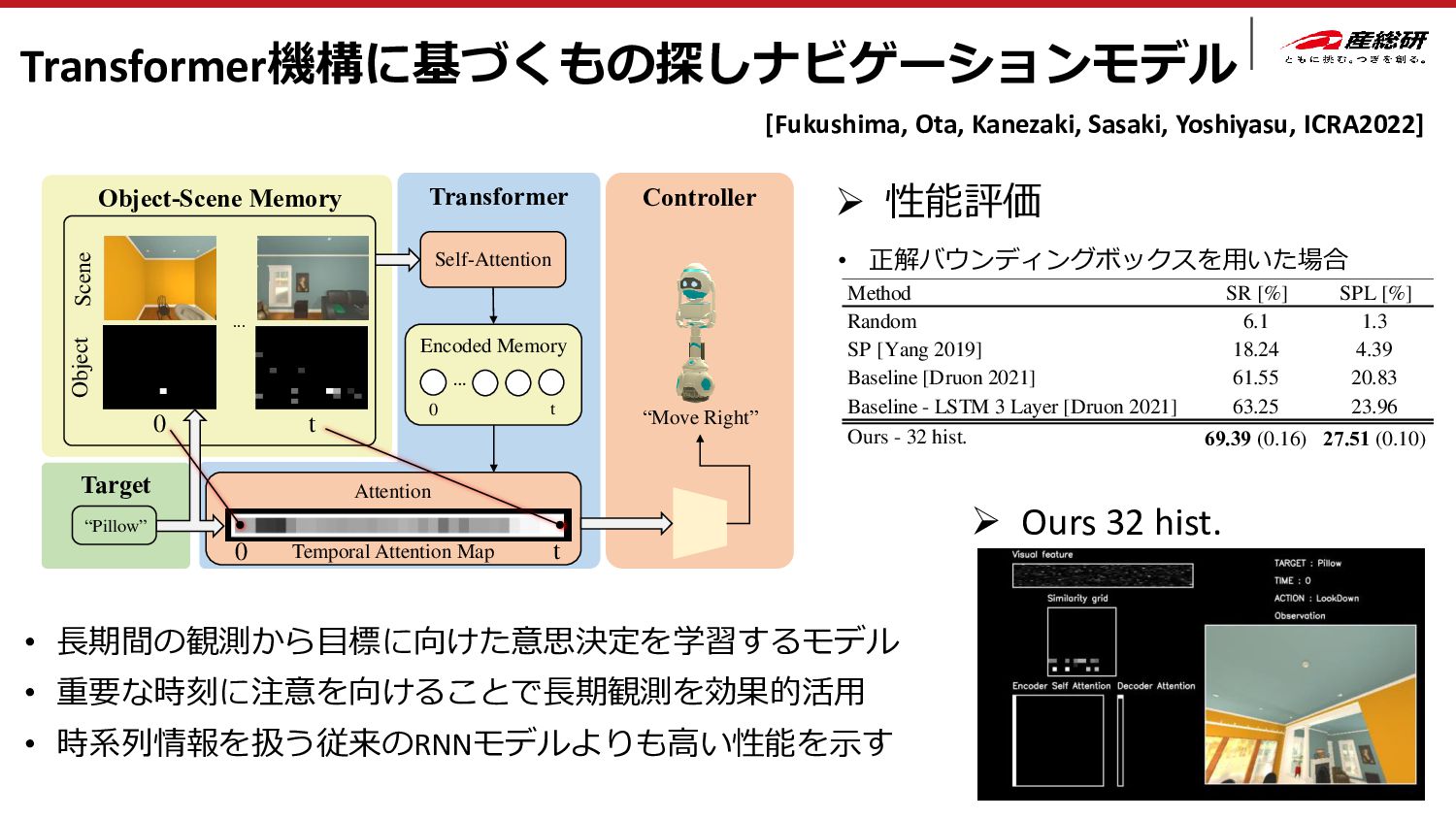
• シミュレータで学習・ソフトウェア技術向上 ⇒ 現実世界に展開 ⇒ 物体探索成功率90% [Gervet 2023] Navigating to Objects in the Real World Theophile Gervet, Soumith Chintala, Dhruv Batra, Jitendra Malik, Devendra Singh Chaplot, 2023 物体探索 成功率90% Find “Toilet” Duan et al.: A Survey of Embodied AI: From Simulators to Research Tasks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![切り抜いた物体領域をさまざまな背景画像に張り付ける [Gabas, Yoshiyasu, Singh, Sagawa, Yoshida, ICIP 2020] [Suzui, Yoshiyasu,](https://files.speakerdeck.com/presentations/baa60a72e435490485e6cbc564c05dfa/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![Transformerに基づくセンサフュージョン・オドメトリ TransFusionOdom [Sun, Ding, Qiu, Yoshiyasu, Kanehiro, in submission] •](https://files.speakerdeck.com/presentations/baa60a72e435490485e6cbc564c05dfa/slide_14.jpg){kind=link}
![Transformerを用いた単眼画像人体三次元形状復元 Deformable mesh transFormer (DeFormer) [Yoshiyasu, CVPR 2023] • メッシュ接続情報と変形モデルに基づく効率的なAttention](https://files.speakerdeck.com/presentations/baa60a72e435490485e6cbc564c05dfa/slide_15.jpg){kind=link}
{kind=link}