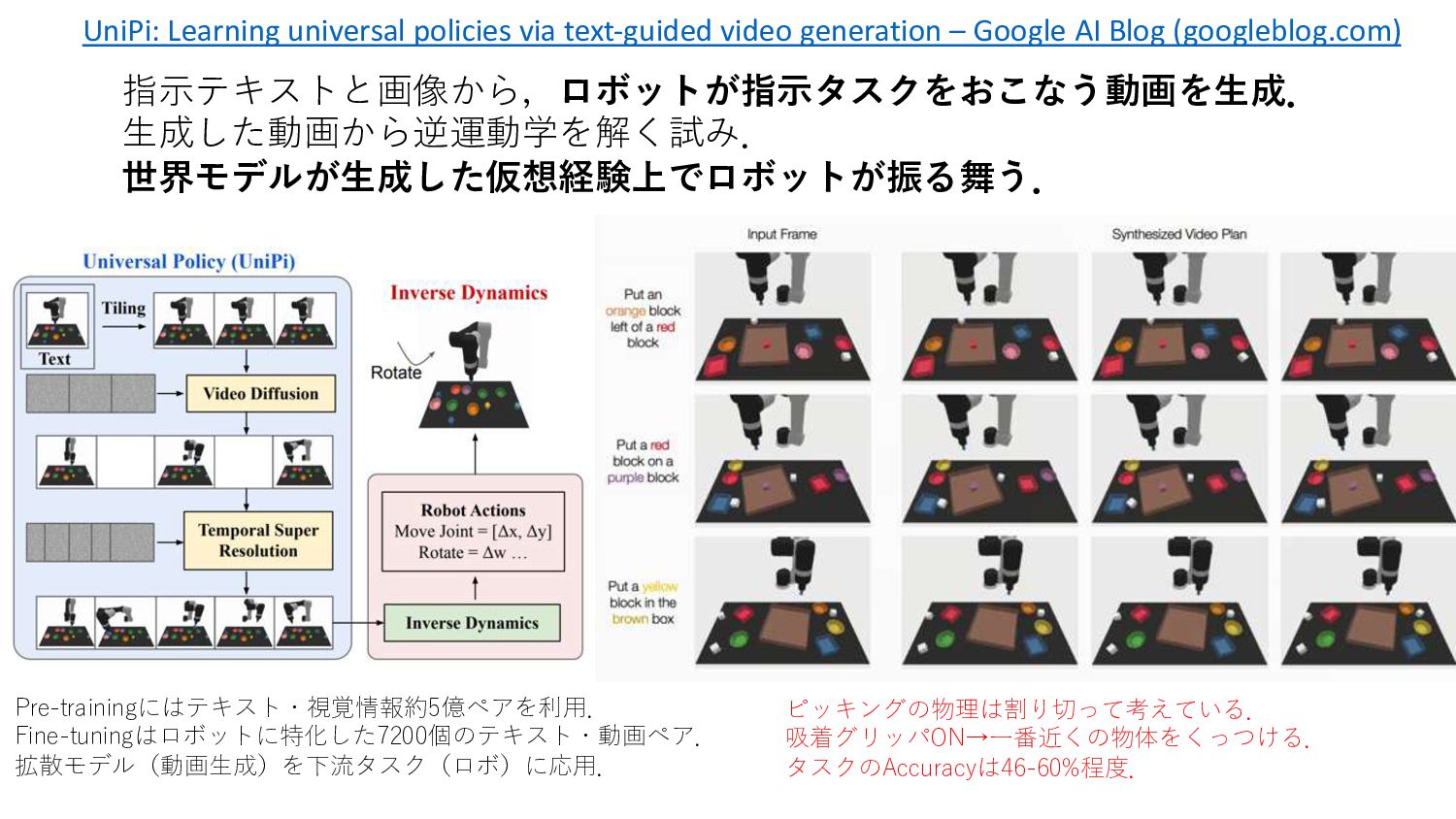
generation – Google AI Blog (googleblog.com) 指⽰テキストと画像から,ロボットが指⽰タスクをおこなう動画を⽣成. ⽣成した動画から逆運動学を解く試み. 世界モデルが⽣成した仮想経験上でロボットが振る舞う. Pre-trainingにはテキスト・視覚情報約5億ペアを利⽤. Fine-tuningはロボットに特化した7200個のテキスト・動画ペア. 拡散モデル(動画⽣成)を下流タスク(ロボ)に応⽤.
neural networks from simulation to the world, J. Tobin, et, el., IROS2017 [2] SimNet: Enabling Robust Unkown Object Manipulation from Pure Synthetic Data via Stereo, M. Laskey, B. Thananjeyan, et. al., CoRL, 2021. レンダリングを⼀様にランダム化. あえてロークオリティーなレンダリングを⼤量に⽣成. 品質でなくデータ量で汎化性を獲得. ロークオリティーであれば⼤量データ⽣成も低コスト[2]. 家庭内物品のモバイルマニピュレーションを実現. 座標,形状,対象・環境の⾊・テクスチャ マテリアル,照明条件,画像ノイズ, カメラパラメタなどを乱拓化.
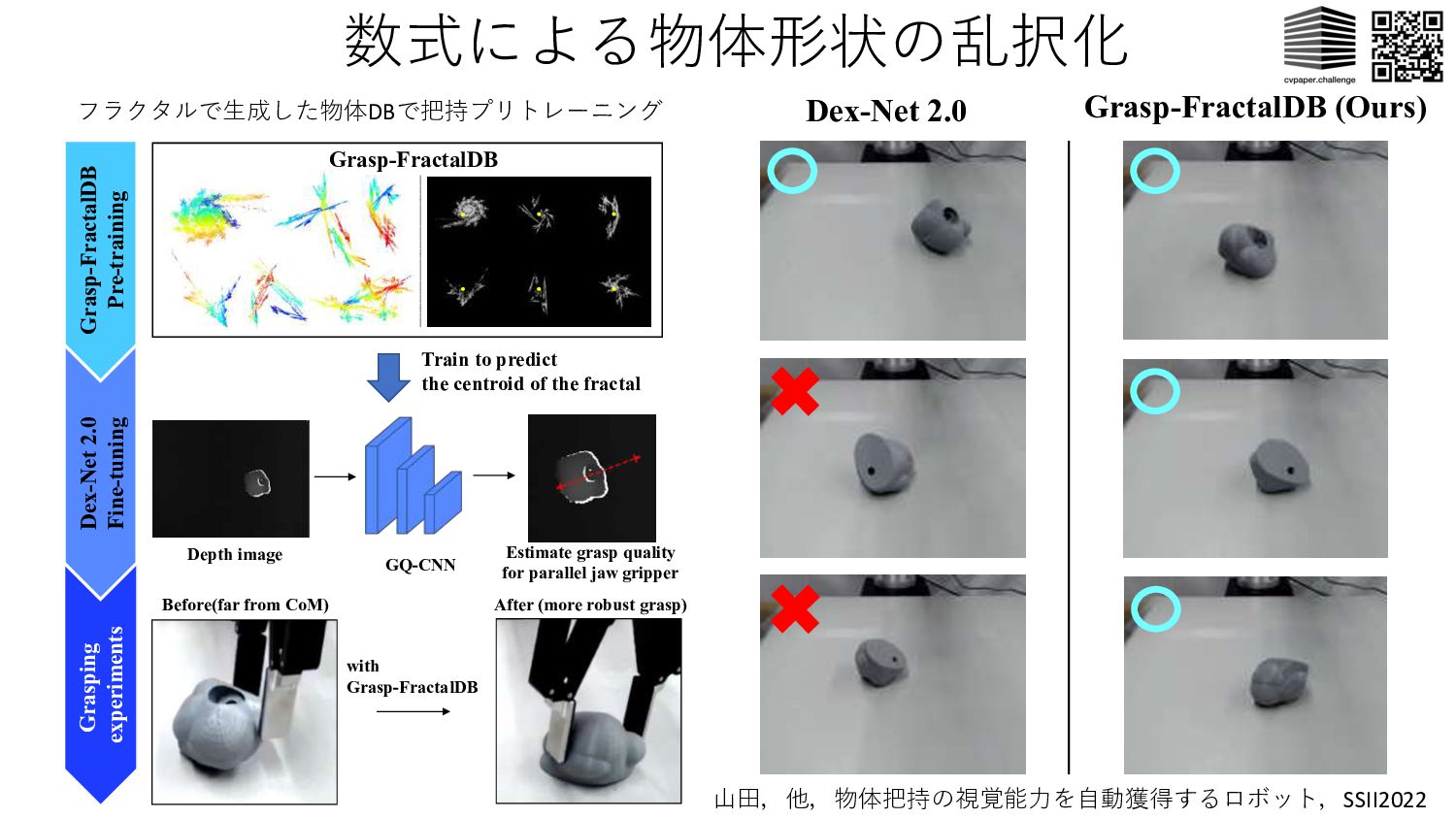
experiments Estimate grasp quality for parallel jaw gripper Before(far from CoM) After (more robust grasp) with Grasp-FractalDB Grasp-FractalDB Train to predict the centroid of the fractal Dex-Net 2.0 Grasp-FractalDB (Ours) ⼭⽥,他,物体把持の視覚能⼒を⾃動獲得するロボット,SSII2022 フラクタルで⽣成した物体DBで把持プリトレーニング
ゼロショットでサブミリオーダのはめ合いを実現. 初期位置誤差, 物体形状種類, クリアランスなどを 段階的に複雑化していく カリキュラムを設計. カリキュラム有無で累計報酬が⼤きく変化. C. Bertran, et el., “Accelerating Robot Learning of Contact-Rich Manipulations: A Curriculum Learning Study”, arXiv, 2022. C. Bertran, et el., “Learning force control for contact-rich manipulation tasks with rigid position-controlled robots”, RA-L, 2020.
time • Domain Randomization ResNet50 Encoder Decoder ResNet based Decoder Forcemap (contact force label) 現実では得難い,⾒えと物体間の⼒分布の 関係を,ドメインランダマイゼーションで ⽣成したデータセットをもとに,Enc-Dec モデルで学習. Force Map: Learning to Predict Contact Force Distribution from Vision (ryhanai.github.io)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“⾒え”の乱拓化 レンダリングを⼀様にランダム化. 実世界の視覚的変動にロバストに対処. 積み⽊のピッキングを実現[1]. [1] Domain randomization for transferring deep](https://files.speakerdeck.com/presentations/a433516c1a6942ff9400fad98a1aa258/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
![“動き”の乱択化 物体やロボットの質量・⼨法 摩擦、制御ゲイン(PID),観測ノイズ, 関節の制約などの物理ダイナミクスに関する パラメタを乱択化しながらタスク学習. [1808.00177] Learning Dexterous In-Hand Manipulation](https://files.speakerdeck.com/presentations/a433516c1a6942ff9400fad98a1aa258/slide_13.jpg){kind=link}
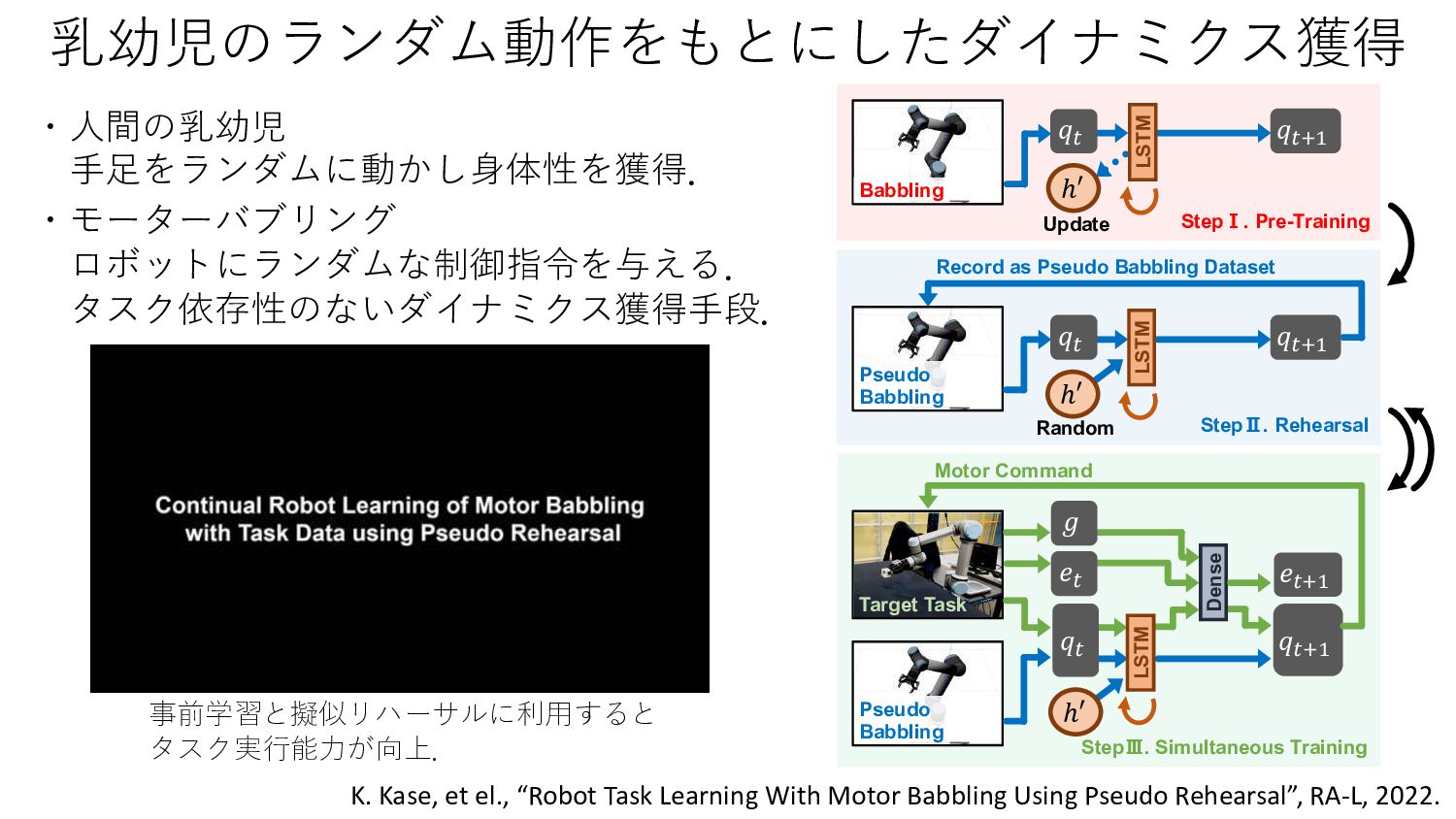{kind=link}
{kind=link}
{kind=link}
{kind=link}
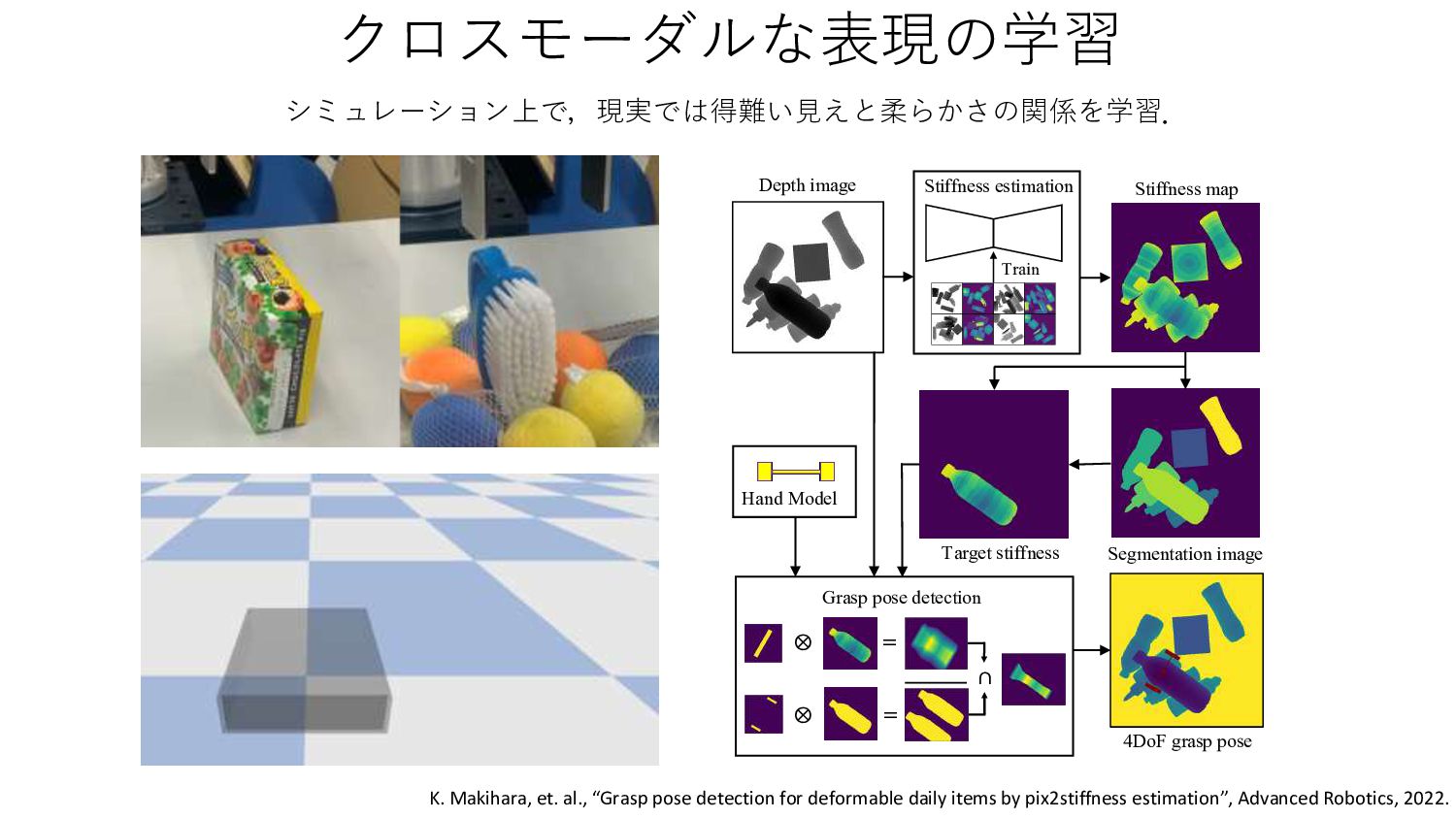{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}