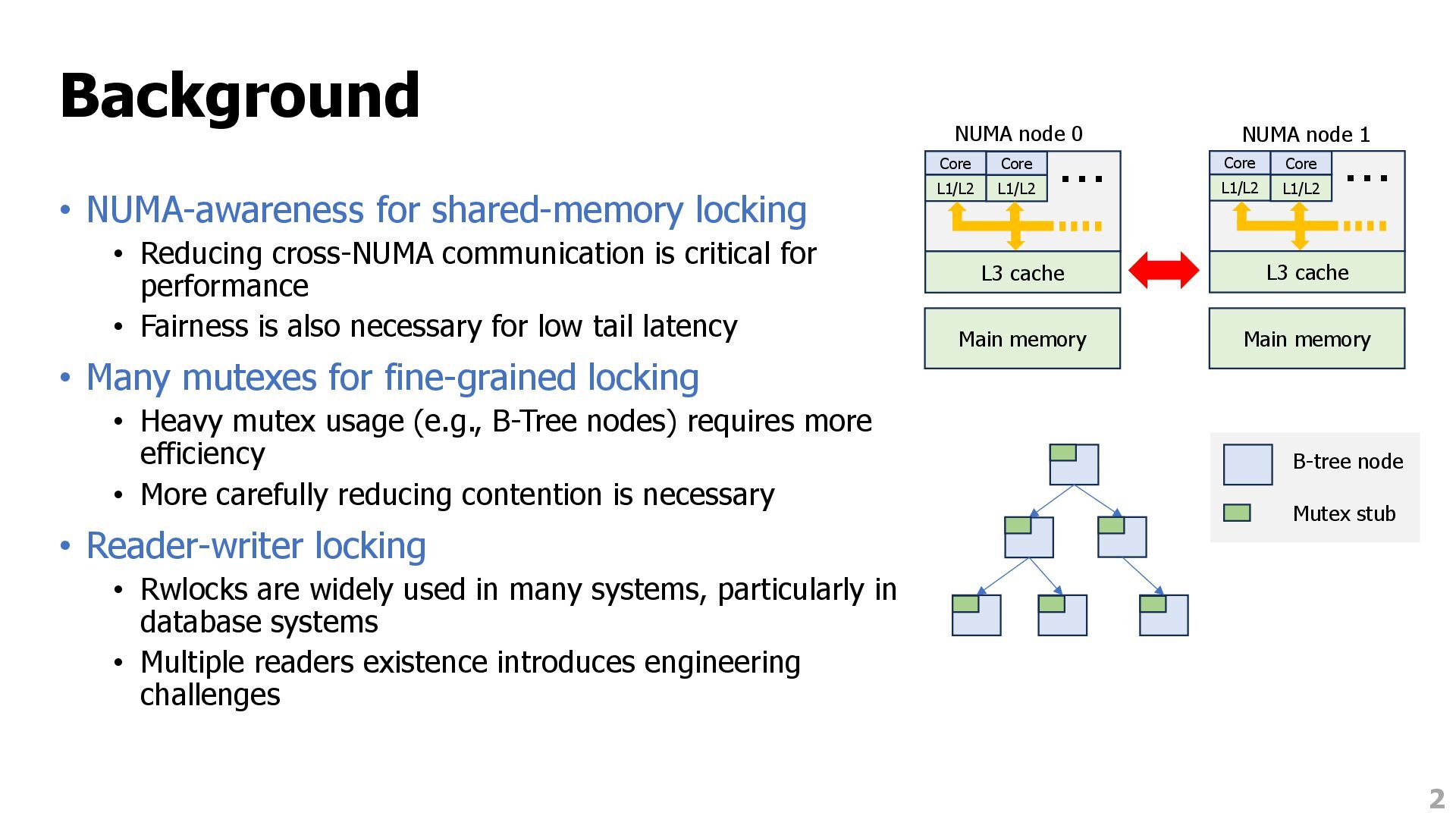
is critical for performance • Fairness is also necessary for low tail latency • Many mutexes for fine-grained locking • Heavy mutex usage (e.g., B-Tree nodes) requires more efficiency • More carefully reducing contention is necessary • Reader-writer locking • Rwlocks are widely used in many systems, particularly in database systems • Multiple readers existence introduces engineering challenges B-tree node Mutex stub 2 L3 cache L1/L2 Core … Main memory L1/L2 Core Main memory NUMA node 0 NUMA node 1 L3 cache L1/L2 Core … L1/L2 Core
scalable reader-writer locking methods • Balancing fairness (low tail latency) and scalability (throughput) in high-level • Key contributions • Freezer mechanism eliminates mutex stub spinning while preserving request stack allocation • Freezer fast path (FFP) does not compromise the fairness policy • Request-queue optimizations enable batching and parallel processing of read requests • Key results • Up to 3.5x higher throughput improvement in B-Tree workloads • Up to 3.1x better tail latency compared to conventional methods with fast paths 3
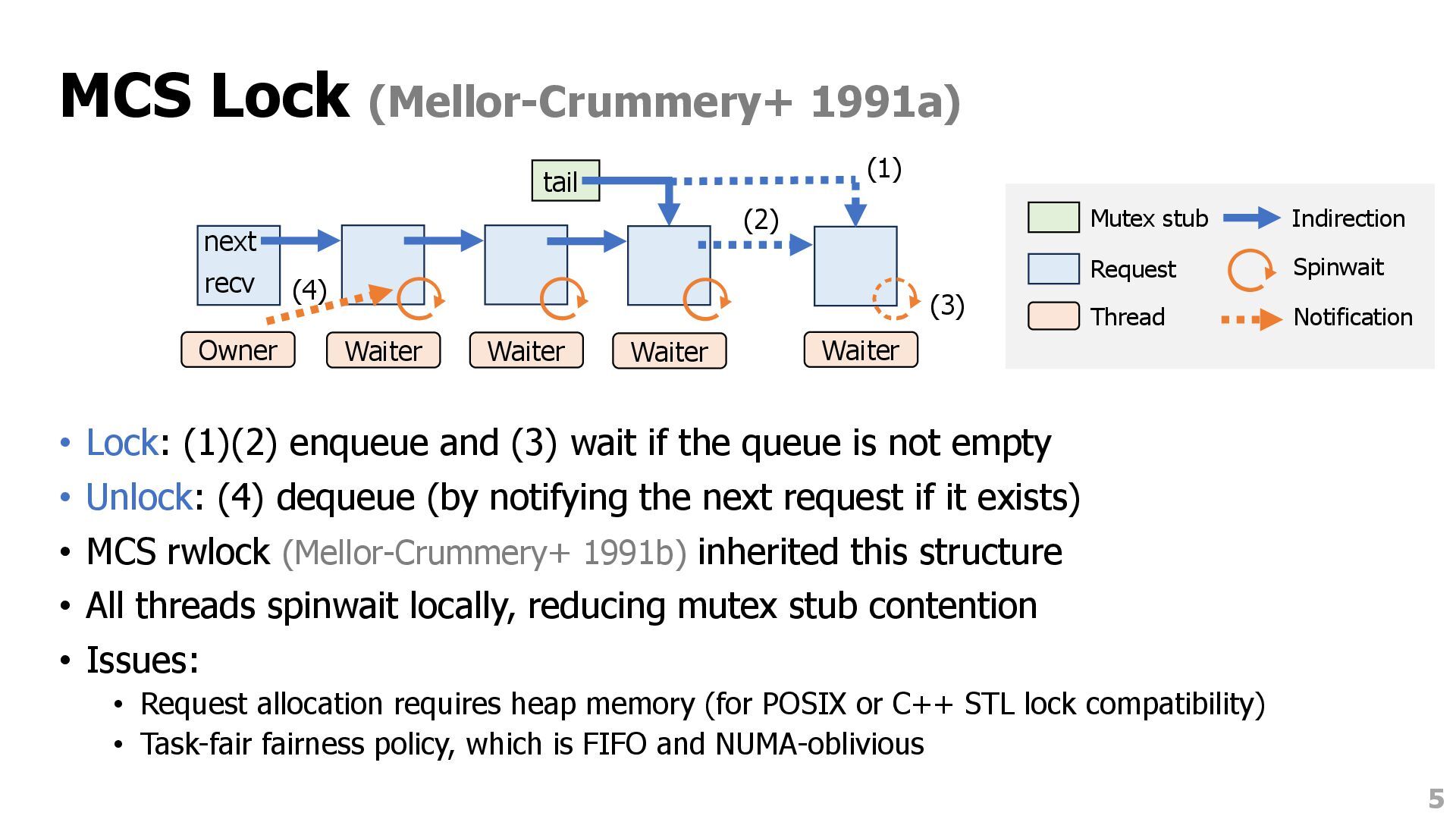
wait if the queue is not empty • Unlock: (4) dequeue (by notifying the next request if it exists) • MCS rwlock (Mellor-Crummery+ 1991b) inherited this structure • All threads spinwait locally, reducing mutex stub contention • Issues: • Request allocation requires heap memory (for POSIX or C++ STL lock compatibility) • Task-fair fairness policy, which is FIFO and NUMA-oblivious 5 tail next recv Owner Waiter Mutex stub Request Thread (1) (2) (3) Waiter Waiter Waiter (4) Spinwait Indirection Notification
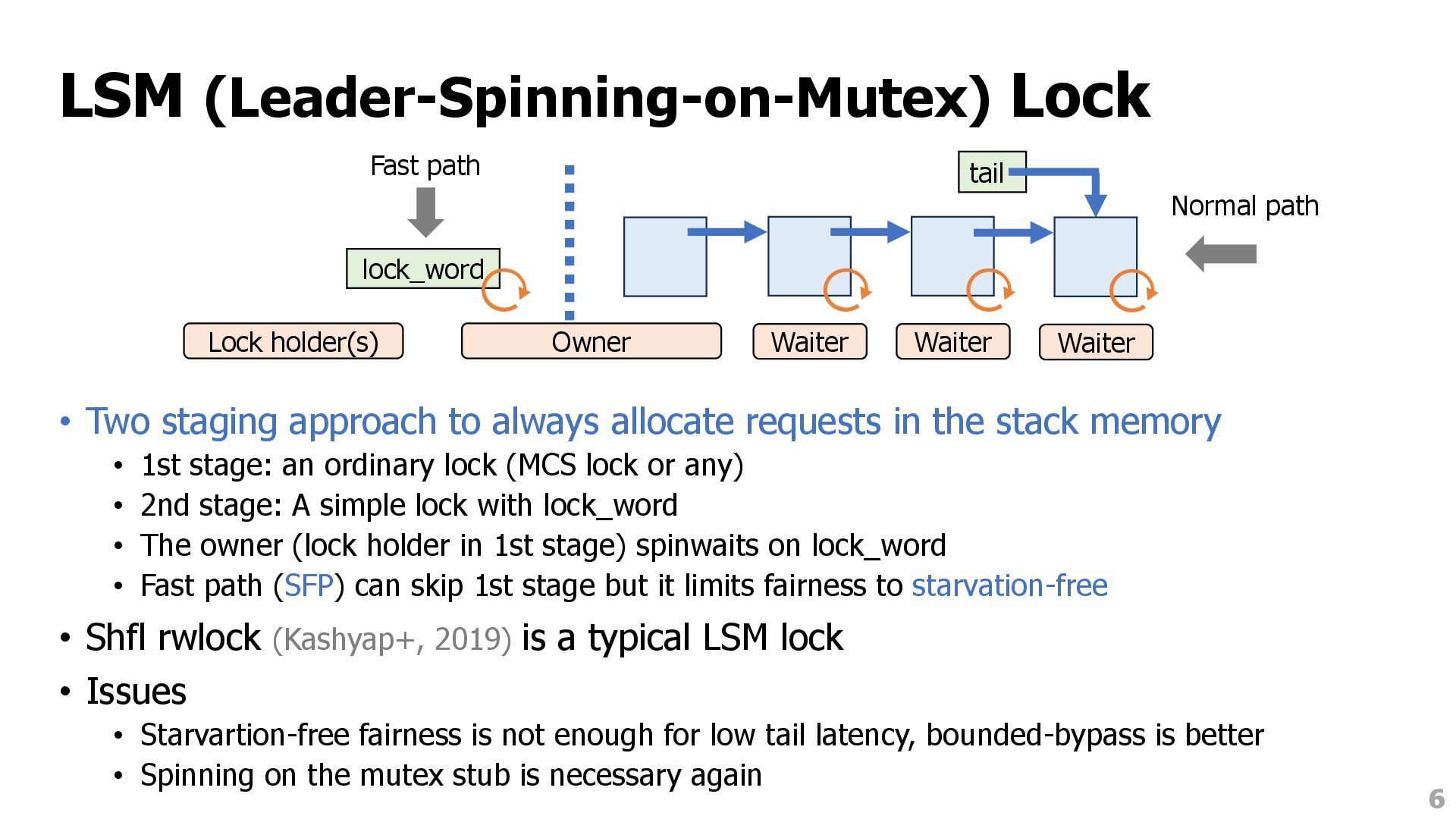
allocate requests in the stack memory • 1st stage: an ordinary lock (MCS lock or any) • 2nd stage: A simple lock with lock_word • The owner (lock holder in 1st stage) spinwaits on lock_word • Fast path (SFP) can skip 1st stage but it limits fairness to starvation-free • Shfl rwlock (Kashyap+, 2019) is a typical LSM lock • Issues • Starvartion-free fairness is not enough for low tail latency, bounded-bypass is better • Spinning on the mutex stub is necessary again 6 tail Waiter Waiter Waiter Owner Lock holder(s) Fast path Normal path
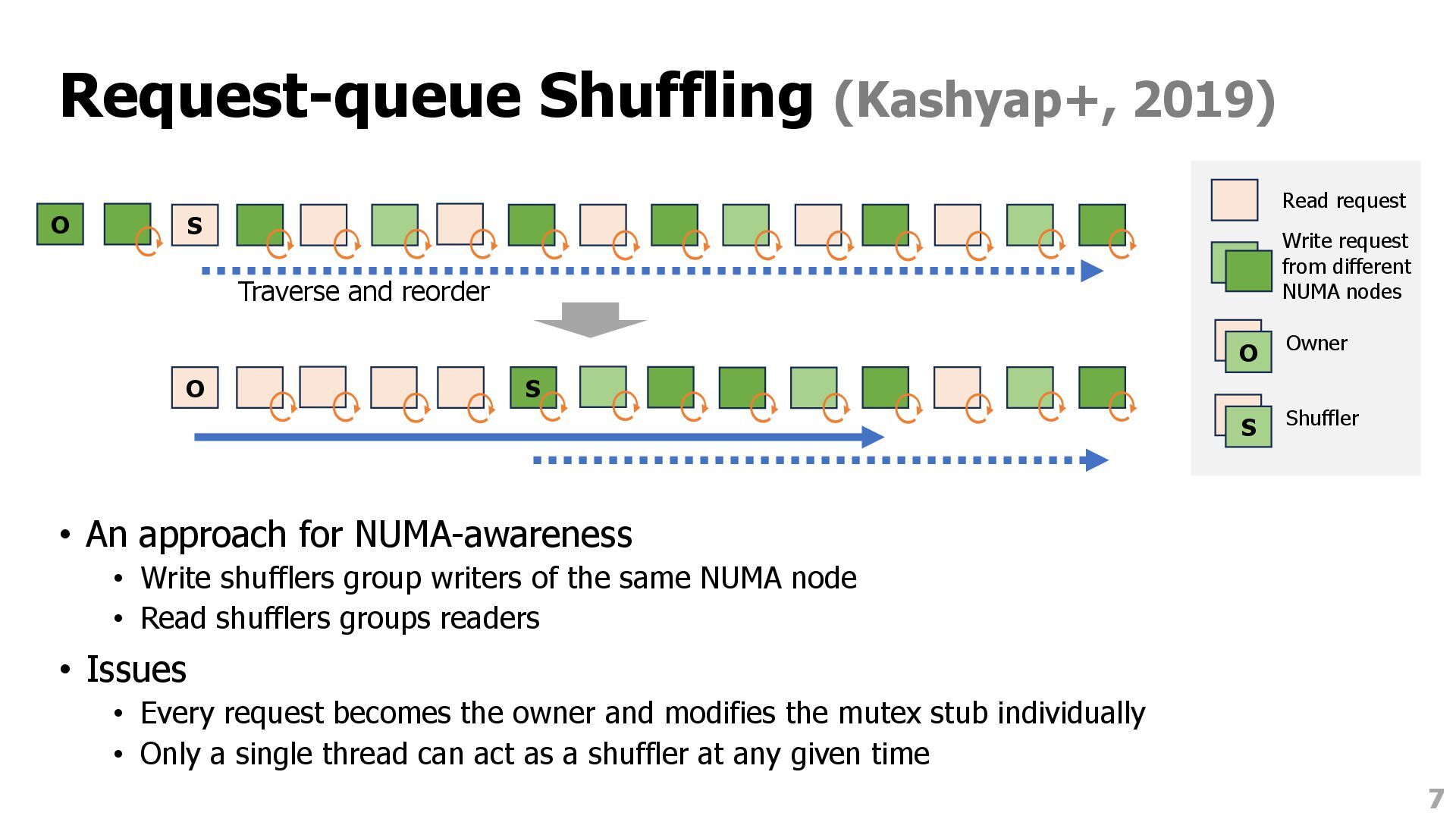
Write shufflers group writers of the same NUMA node • Read shufflers groups readers • Issues • Every request becomes the owner and modifies the mutex stub individually • Only a single thread can act as a shuffler at any given time 7 S O Traverse and reorder S O S Shuffler S S Owner O Read request Write request from different NUMA nodes
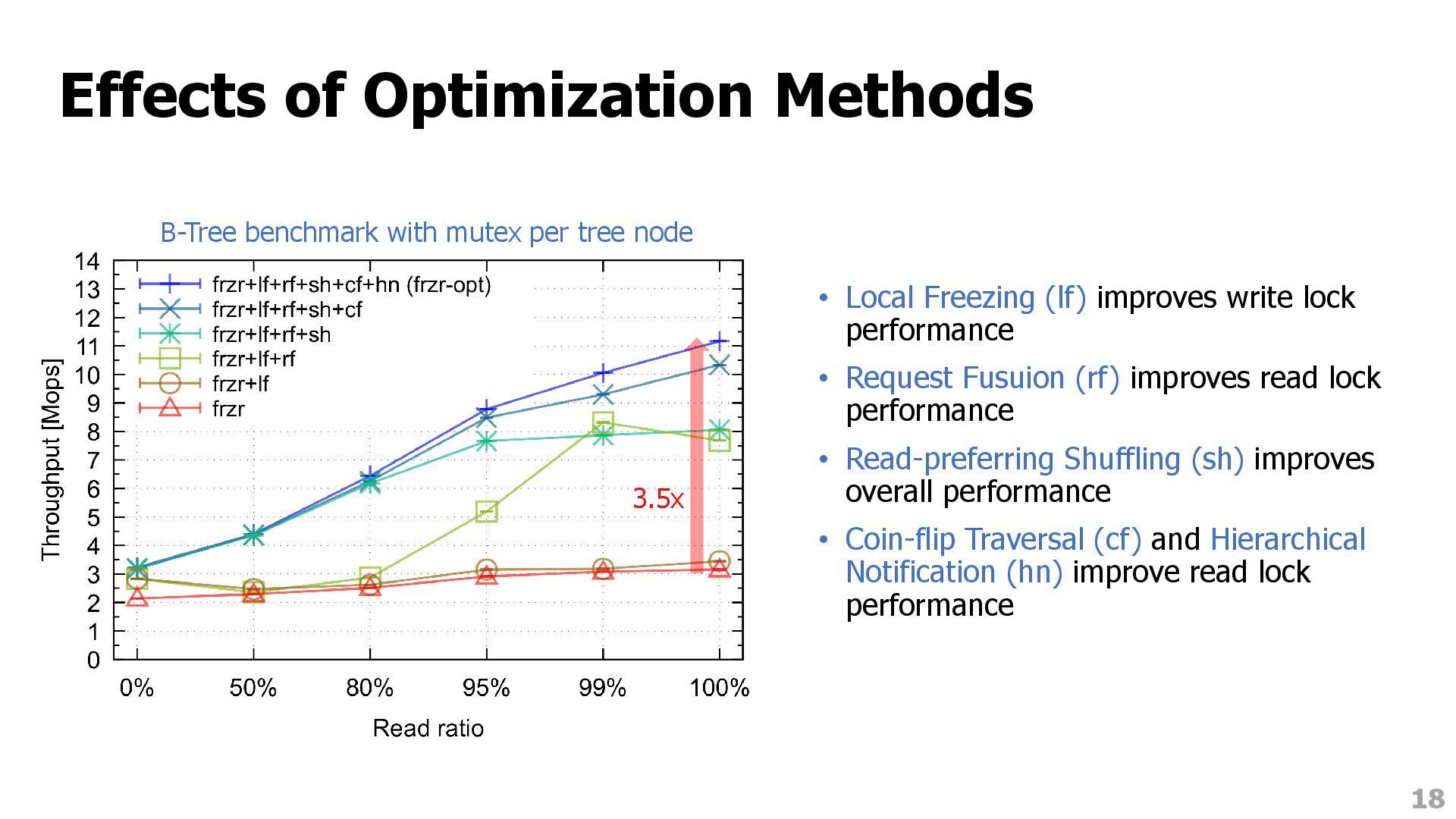
by temporarily freezing the request queue • Freezer Fast Path (FFP) • Does not compromise the fairness property provided by the request queue • Four request-queue optimizations for readers • Ex. batching mutex-stub modifications to reduce contention 10
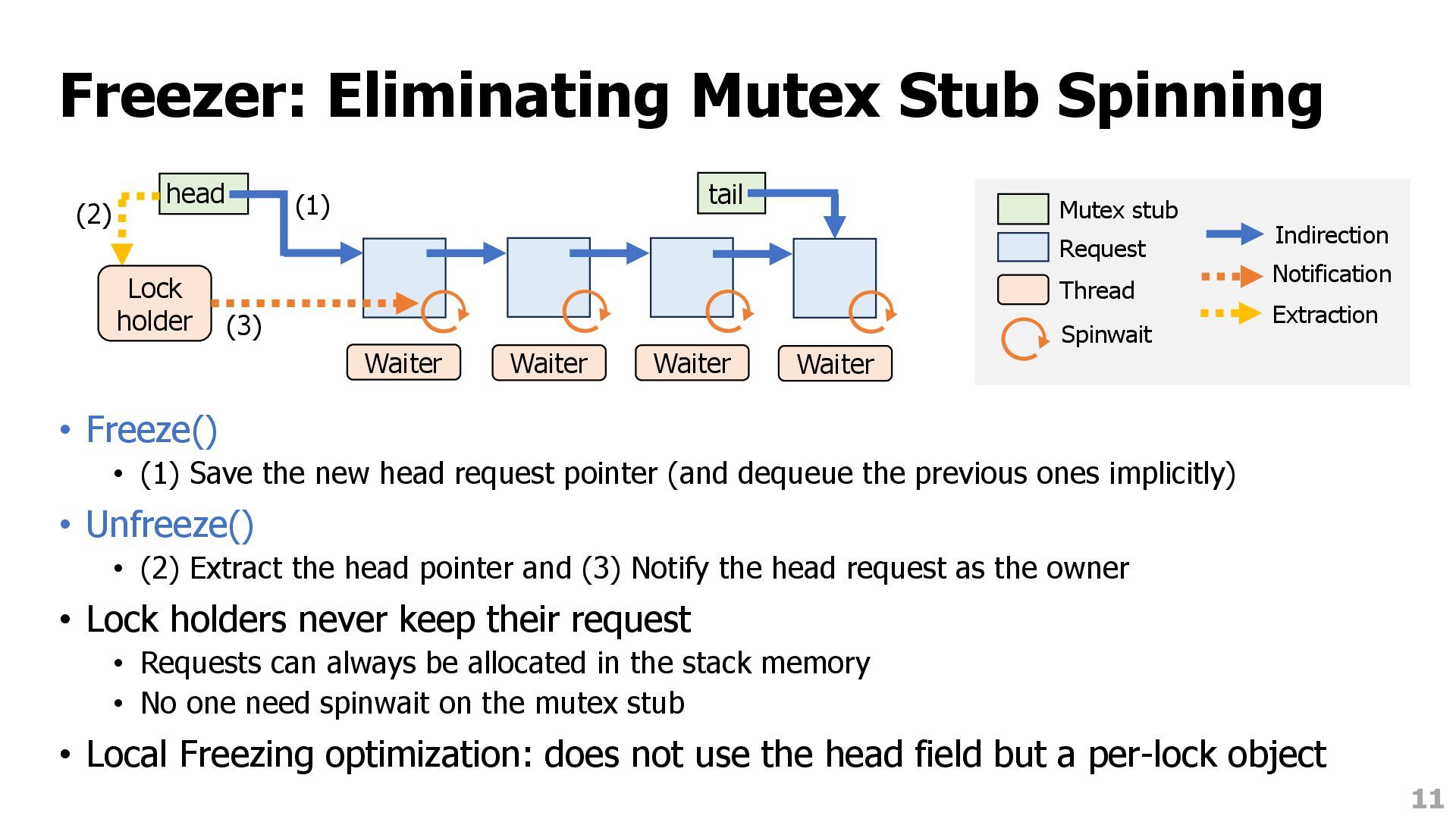
the new head request pointer (and dequeue the previous ones implicitly) • Unfreeze() • (2) Extract the head pointer and (3) Notify the head request as the owner • Lock holders never keep their request • Requests can always be allocated in the stack memory • No one need spinwait on the mutex stub • Local Freezing optimization: does not use the head field but a per-lock object 11 tail Waiter Waiter Waiter Waiter (1) head Lock holder (2) (3) Mutex stub Request Thread Spinwait Indirection Notification Extraction
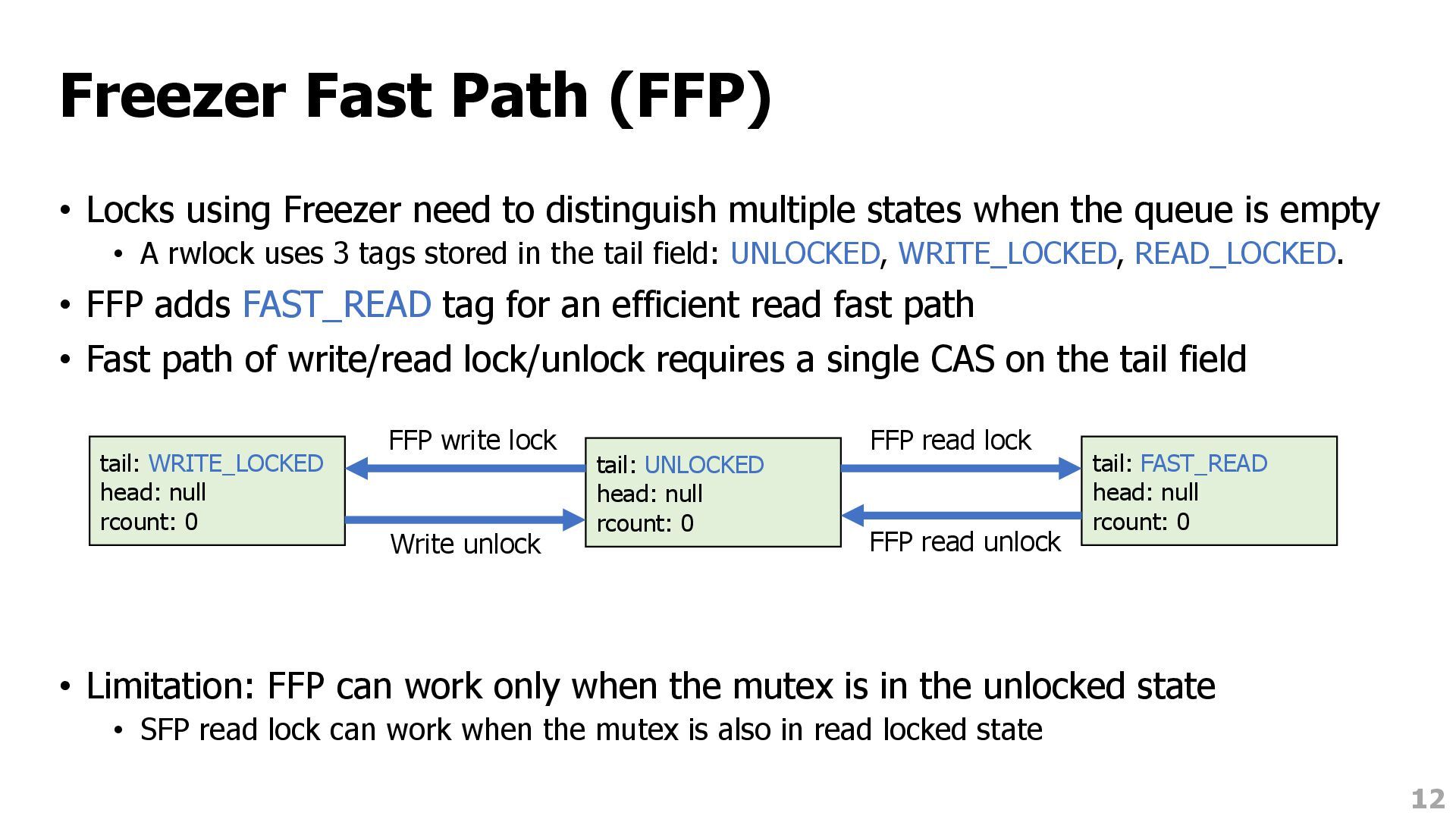
distinguish multiple states when the queue is empty • A rwlock uses 3 tags stored in the tail field: UNLOCKED, WRITE_LOCKED, READ_LOCKED. • FFP adds FAST_READ tag for an efficient read fast path • Fast path of write/read lock/unlock requires a single CAS on the tail field • Limitation: FFP can work only when the mutex is in the unlocked state • SFP read lock can work when the mutex is also in read locked state 12 tail: UNLOCKED head: null rcount: 0 tail: WRITE_LOCKED head: null rcount: 0 tail: FAST_READ head: null rcount: 0 Write unlock FFP read unlock FFP write lock FFP read lock
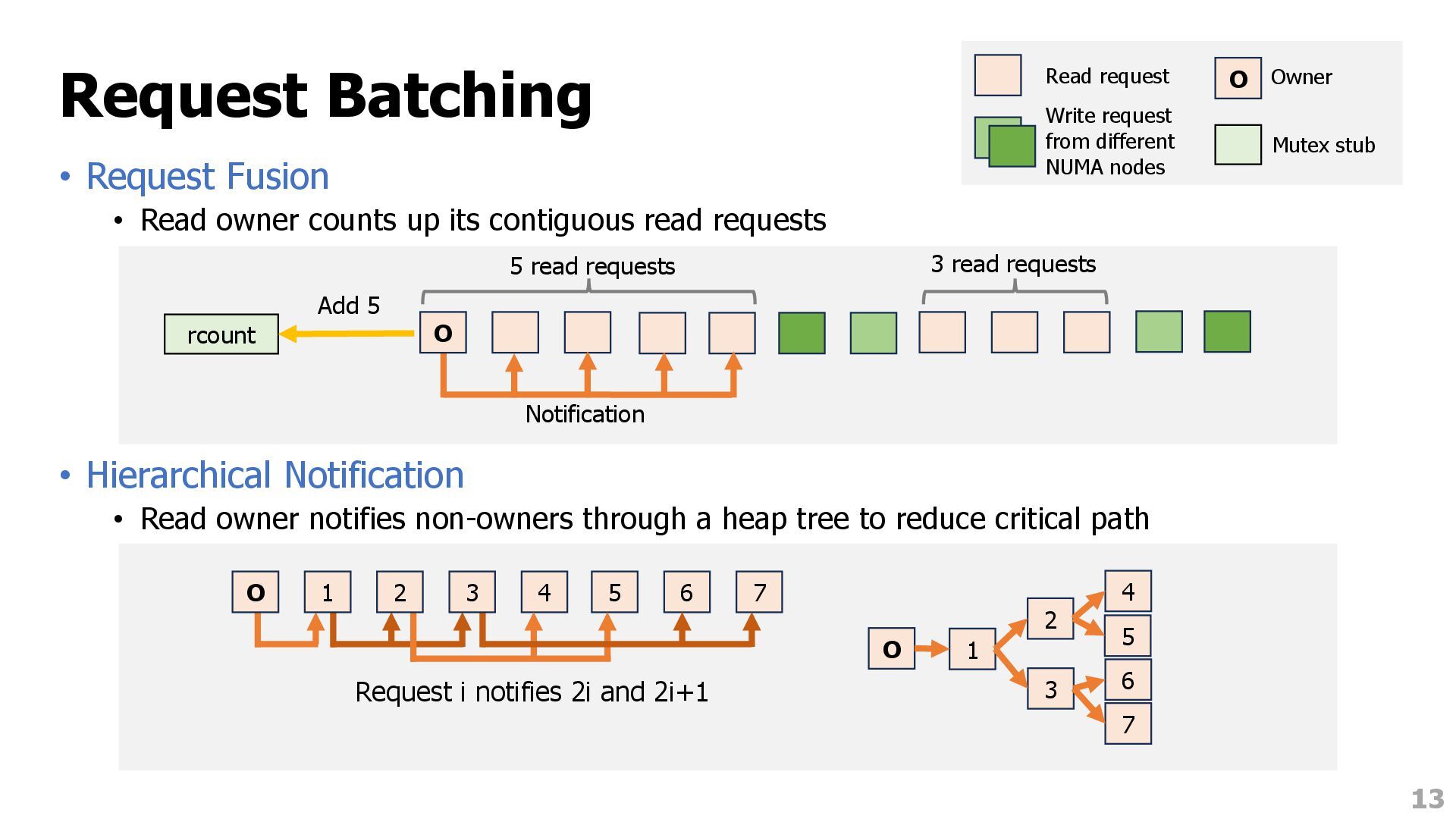
its contiguous read requests • Hierarchical Notification • Read owner notifies non-owners through a heap tree to reduce critical path 13 rcount Add 5 5 read requests 3 read requests Notification O Read request Write request from different NUMA nodes O Owner Mutex stub O 4 5 6 7 1 2 3 Request i notifies 2i and 2i+1 1 2 3 4 5 6 7 O
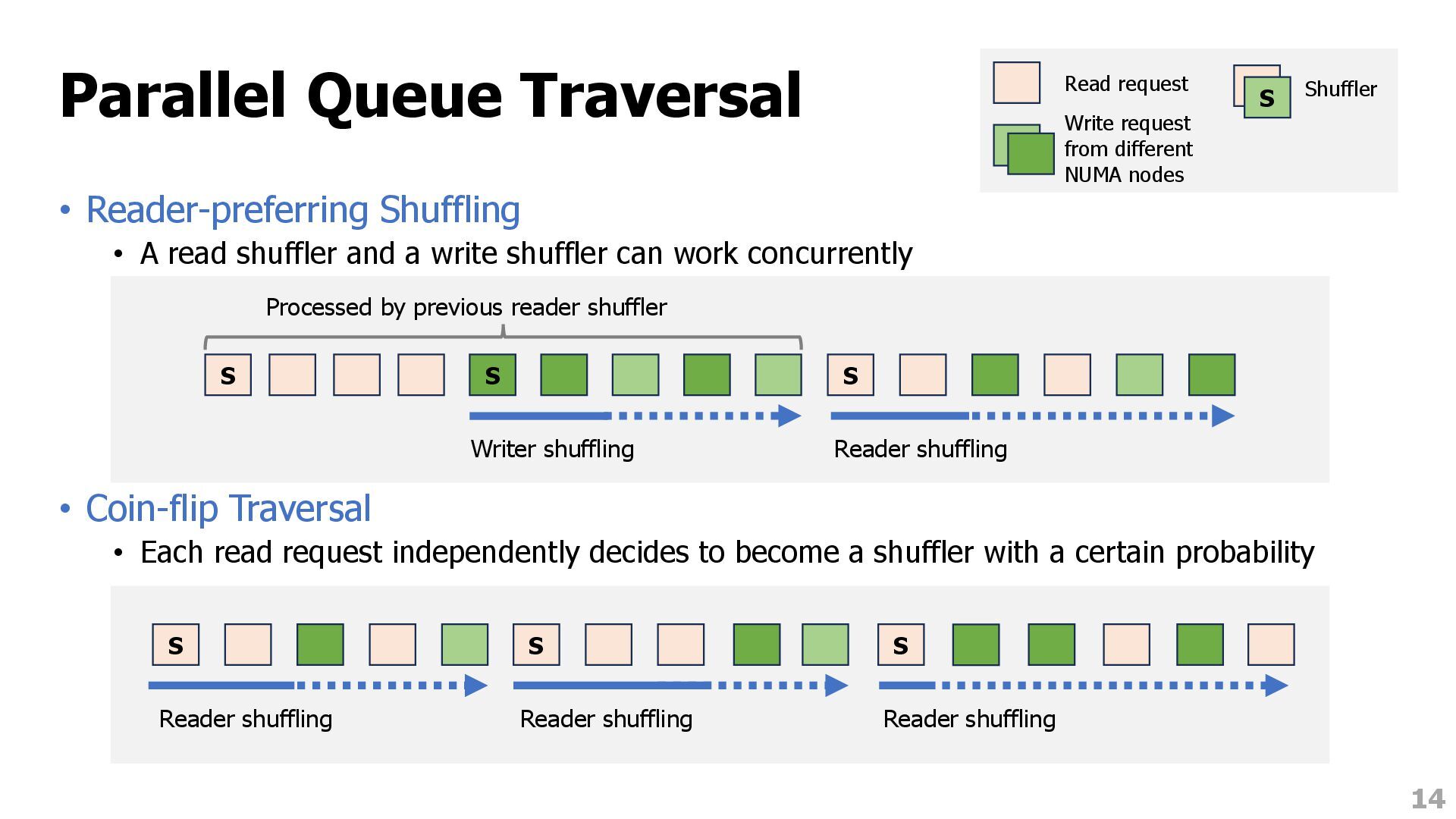
and a write shuffler can work concurrently • Coin-flip Traversal • Each read request independently decides to become a shuffler with a certain probability 14 S S S Writer shuffling Reader shuffling Processed by previous reader shuffler S Reader shuffling S Reader shuffling S Reader shuffling Read request Write request from different NUMA nodes S Shuffler S
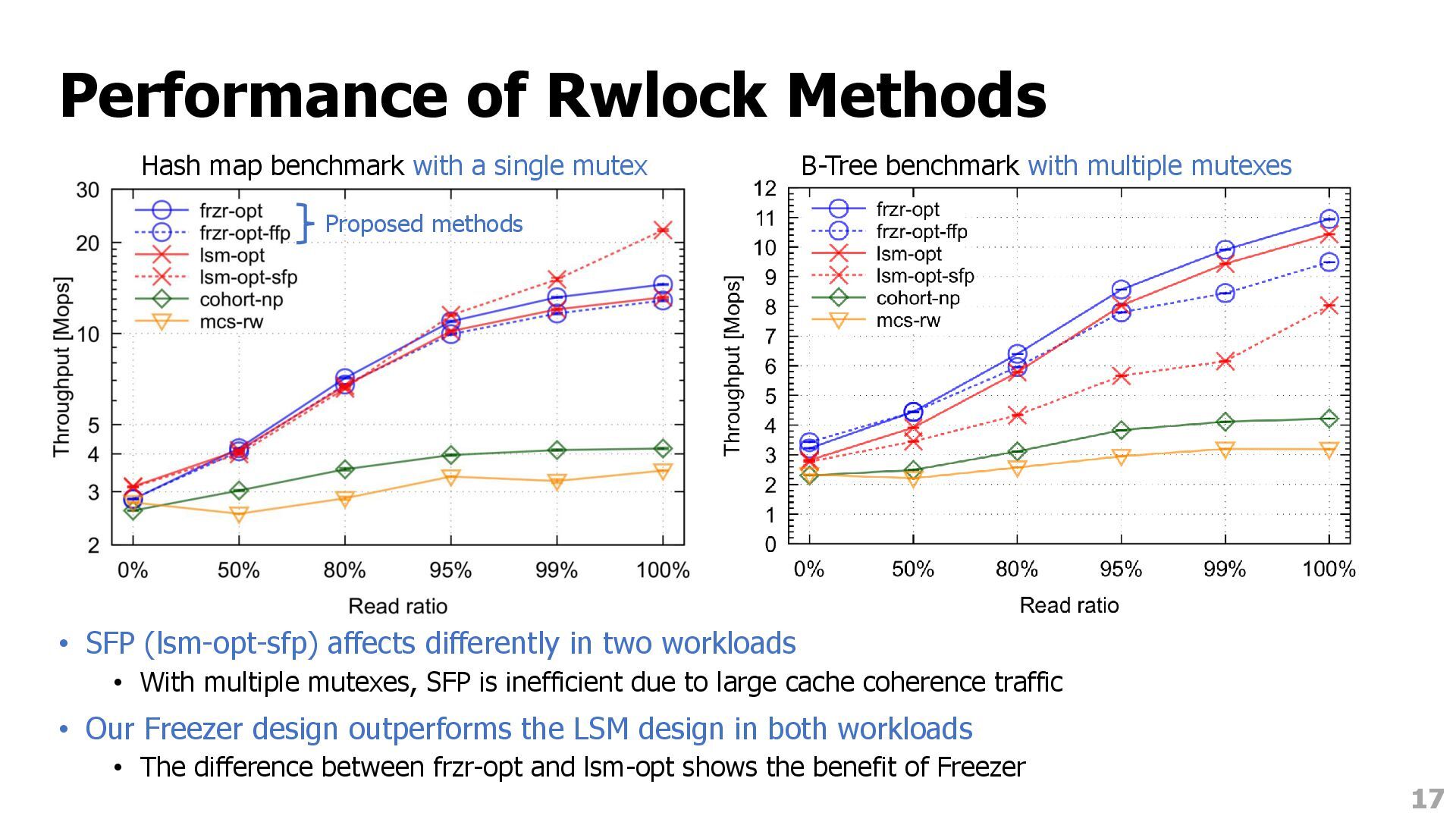
and conventional rwlocks • Impact of each optimization method and fast path • Impact of fairness policies on tail latency • Environment • Two CPUs (Intel Xeon Platinum 8280: 28 cores/56 SMTs, totally 112 threads) • NUMA node per CPU (totally 2 nodes) • 192GB memory • Workloads (110 worker threads run for all workloads) • Hash map benchmark with a single (global) mutex • B-Tree benchmark with a mutex per tree node (by lock coupling) • YCSB variant using transactions with a mutex per record (by two-phase locking) 16
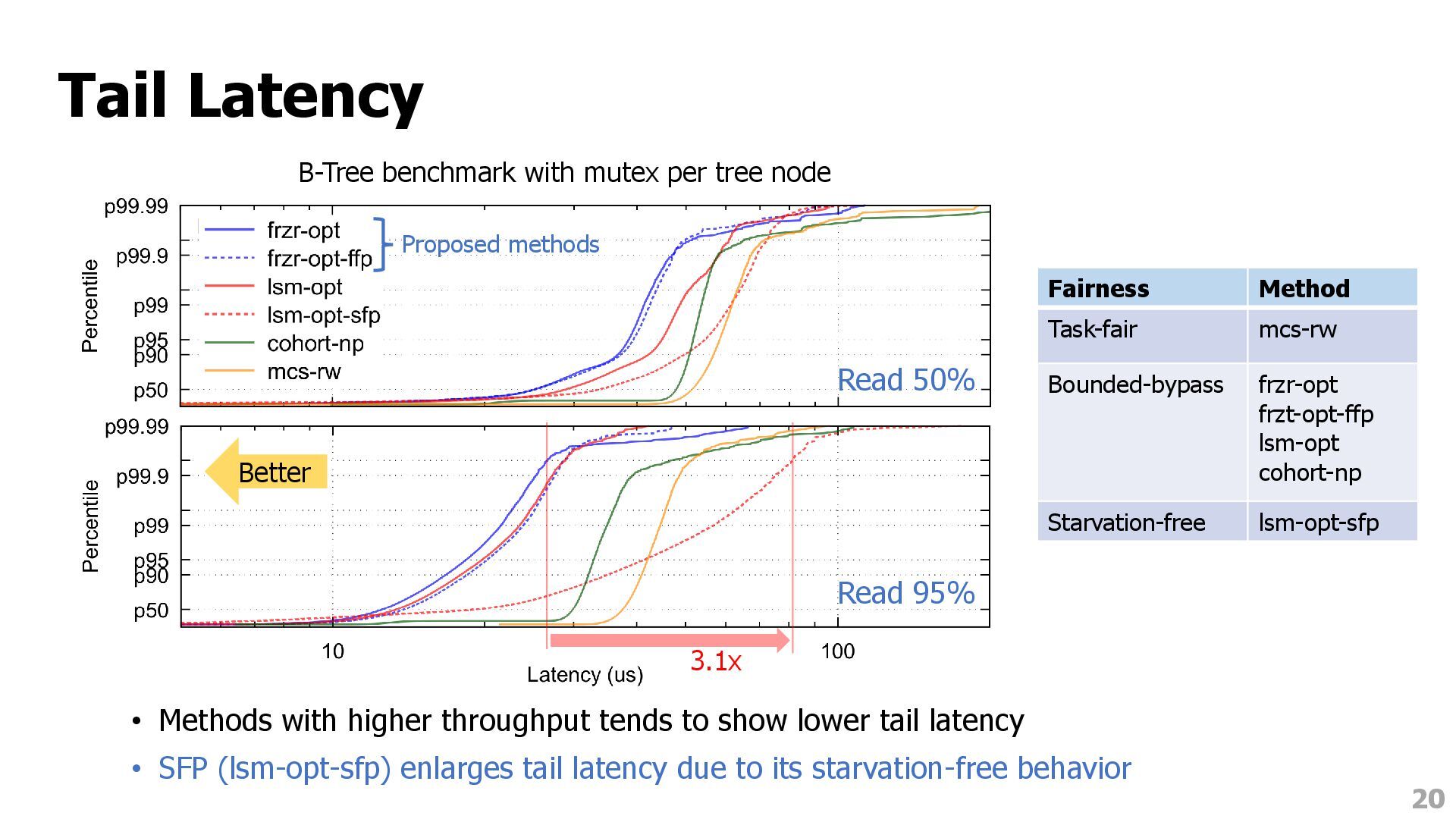
two workloads • With multiple mutexes, SFP is inefficient due to large cache coherence traffic • Our Freezer design outperforms the LSM design in both workloads • The difference between frzr-opt and lsm-opt shows the benefit of Freezer 17 Hash map benchmark with a single mutex B-Tree benchmark with multiple mutexes Proposed methods
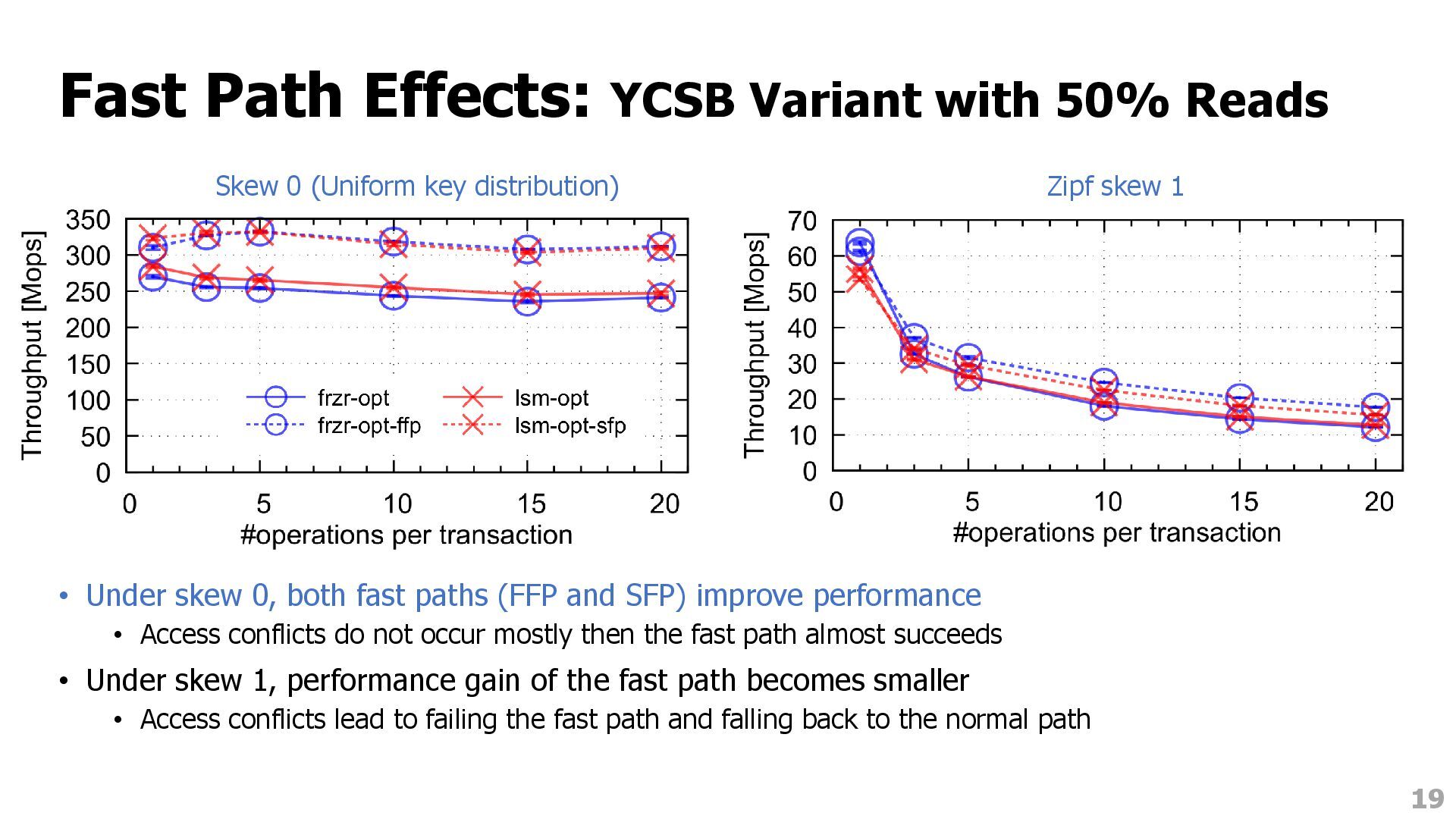
skew 0, both fast paths (FFP and SFP) improve performance • Access conflicts do not occur mostly then the fast path almost succeeds • Under skew 1, performance gain of the fast path becomes smaller • Access conflicts lead to failing the fast path and falling back to the normal path 19 Skew 0 (Uniform key distribution) Zipf skew 1
spinning while preserving request stack allocation • Freezer fast path (FFP): does not change fairness policy by request-queue • Request-queue optimizations: enables batching and parallel processing read requests • Results highlights • Up to 3.5x higher throughput improvement in B-Tree workload • Up to 3.1x better tail latency compared to conventional methods with fast paths • Future work • Integration with reader-counter splitting techniques • Application to more complex locking methods and parallel algorithms 22
Michael L. Scott. 1991. Algorithms for Scalable Synchronization on Shared-Memory Multiprocessors. ACM Trans. Comput. Syst. 9, 1 (Feb. 1991), 21–65. • Mellor-Crummey+ 1991b • John M. Mellor-Crummey and Michael L. Scott. 1991. Scalable Reader-Writer Synchronization for Shared-Memory Multiprocessors. SIGPLAN Not. 26, 7 (April 1991), 106–113. • Brandenburg+ 2010 • Björn B. Brandenburg and James H. Anderson. 2010. Spin-based reader-writer synchronization for multiprocessor real-time systems. Real-Time Systems 46 (2010), 25–87. • Calciu+ 2013 • Irina Calciu, Dave Dice, Yossi Lev, Victor Luchangco, Virendra J. Marathe, and Nir Shavit. 2013. NUMA- Aware Reader-Writer Locks. In Proceedings of the 18th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP ’13). Association for Computing Machinery, New York, NY, USA, 157–166. 23
and Taesoo Kim. 2017. Scalable NUMA-aware Blocking Synchronization Primitives. In 2017 USENIX Annual Technical Conference (USENIX ATC 17). USENIX Association, Santa Clara, CA, 603–615. • Kashyap+ 2019 • Sanidhya Kashyap, Irina Calciu, Xiaohe Cheng, Changwoo Min, and Taesoo Kim. 2019. Scalable and Practical Locking with Shuffling. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19). Association for Computing Machinery, New York, NY, USA, 586–599. 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}