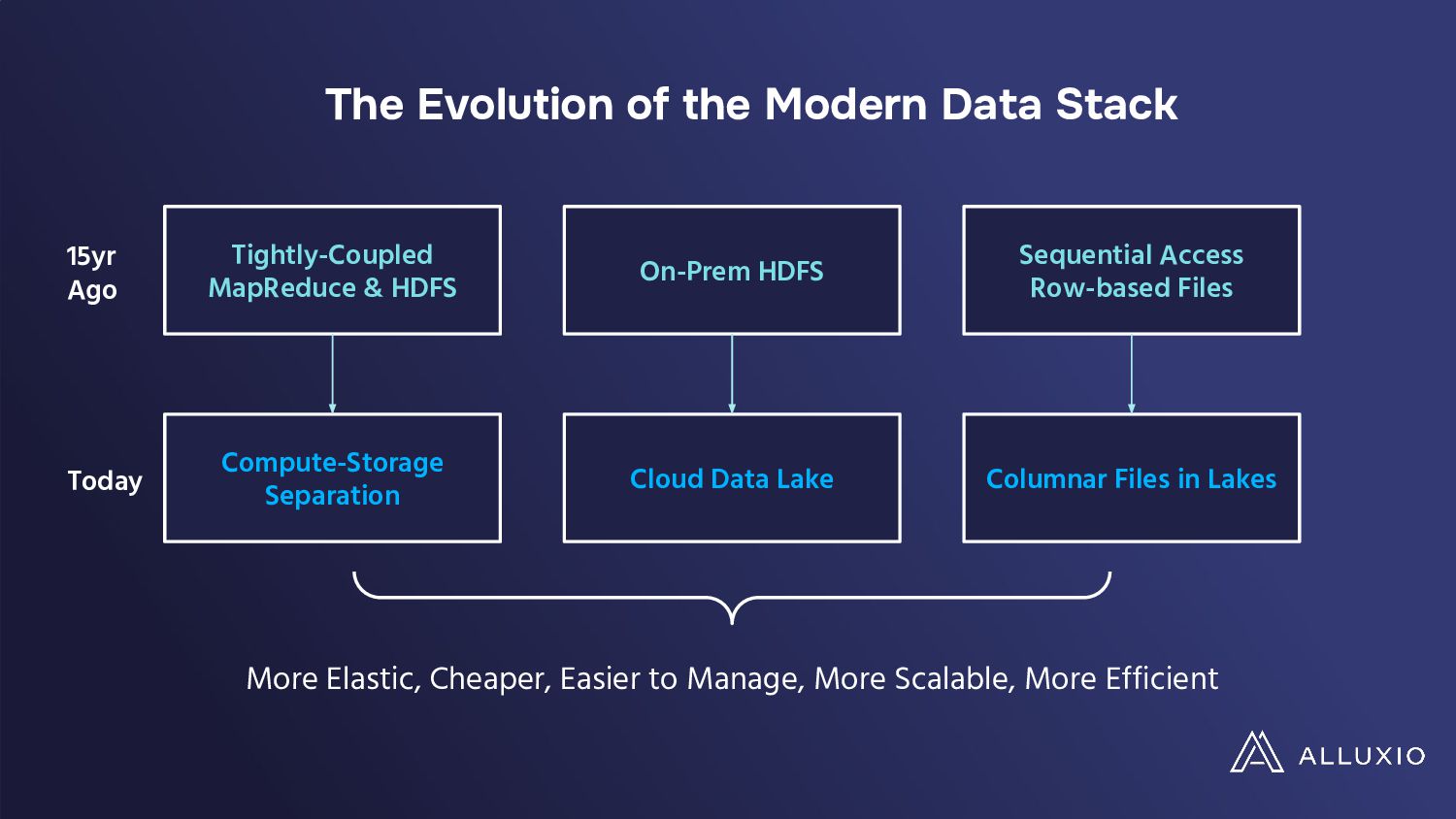
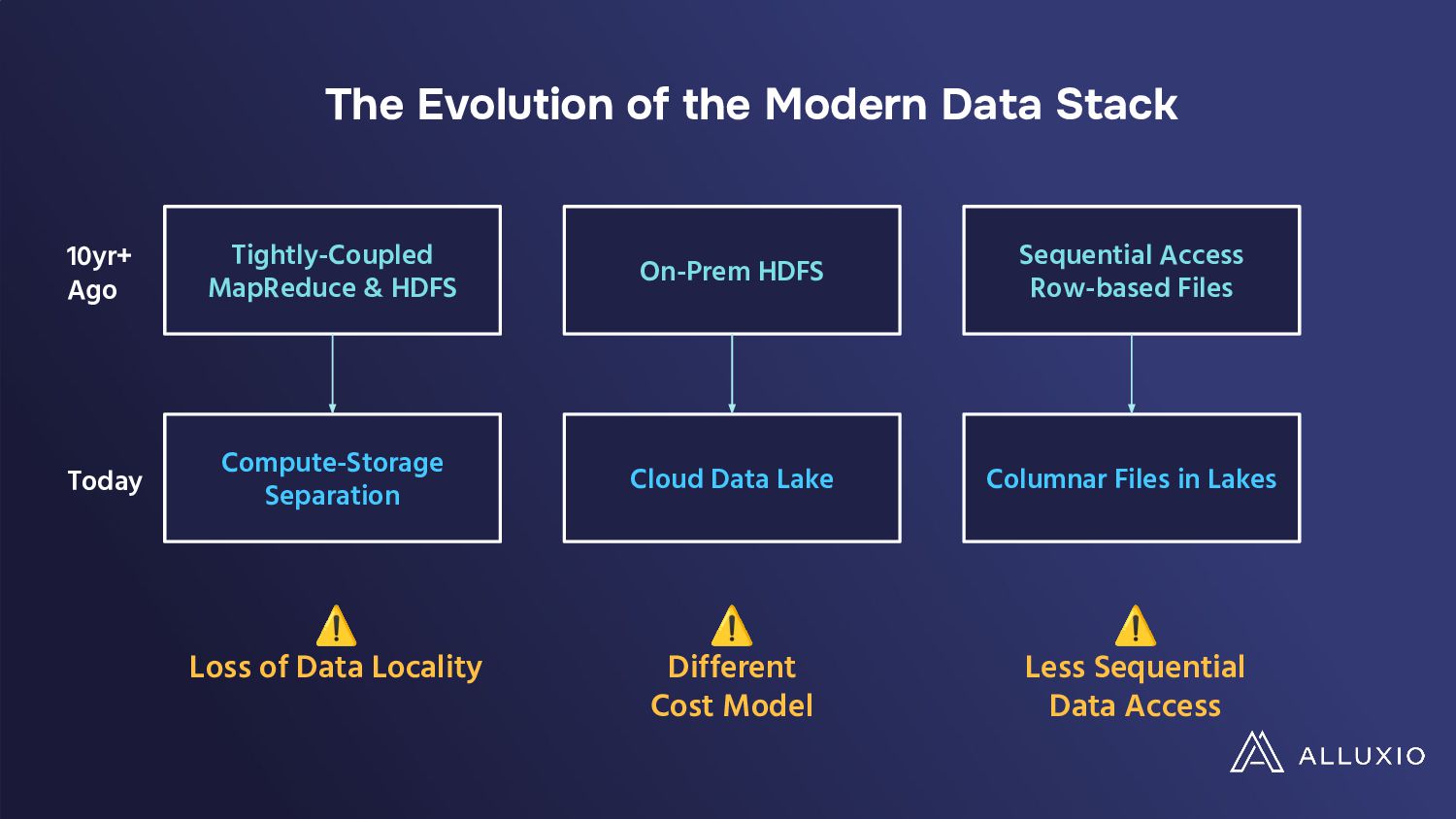
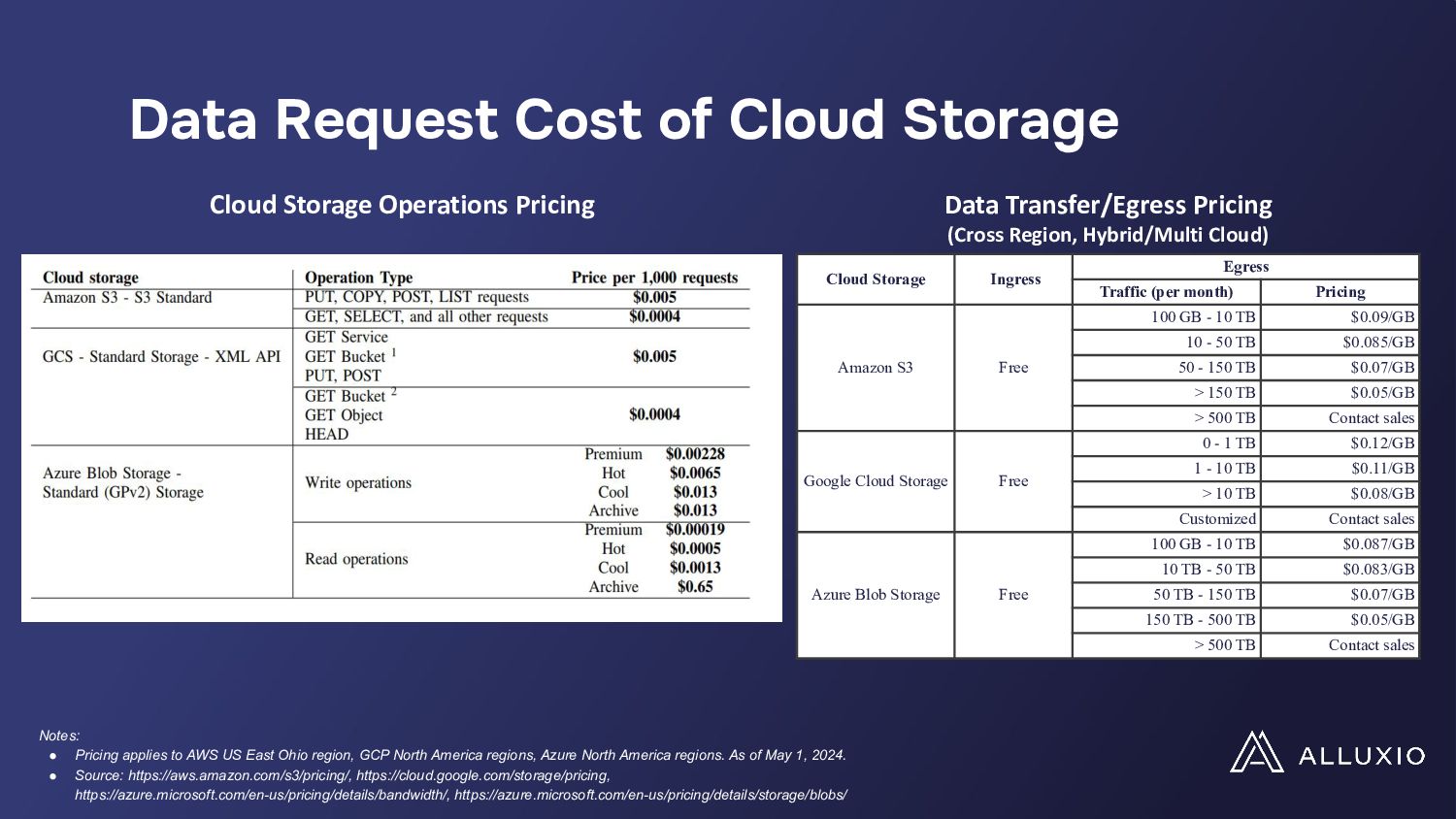
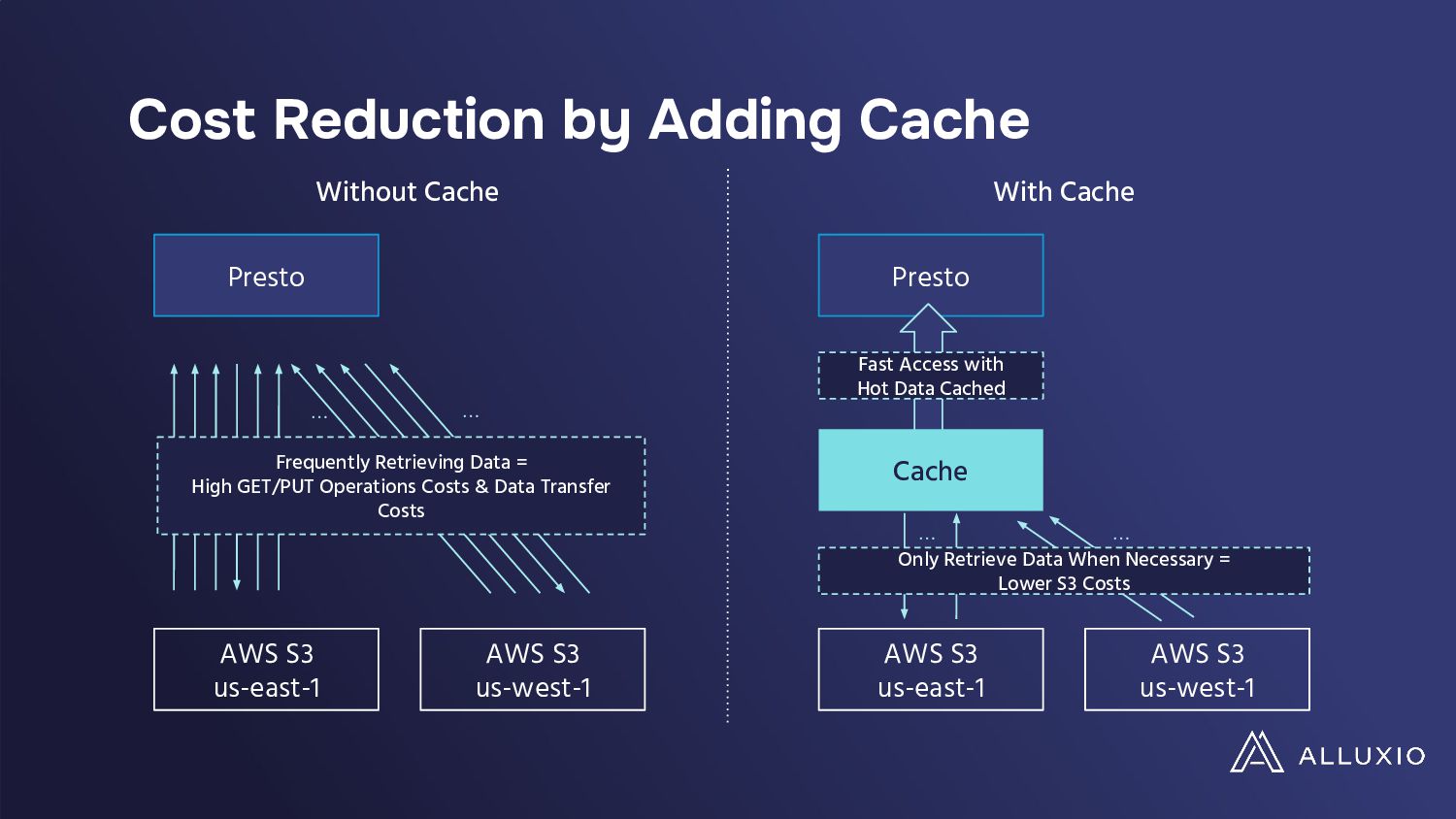
The migration of data-intensive analytics applications to cloud-native environments promises enhanced scalability and flexibility but introduces complex cost models that pose new challenges to traditional optimization strategies. While on-premises setups focused on speed, cloud deployments require a more nuanced approach, factoring in cloud storage operations costs, which can escalate rapidly in real-world scenarios.
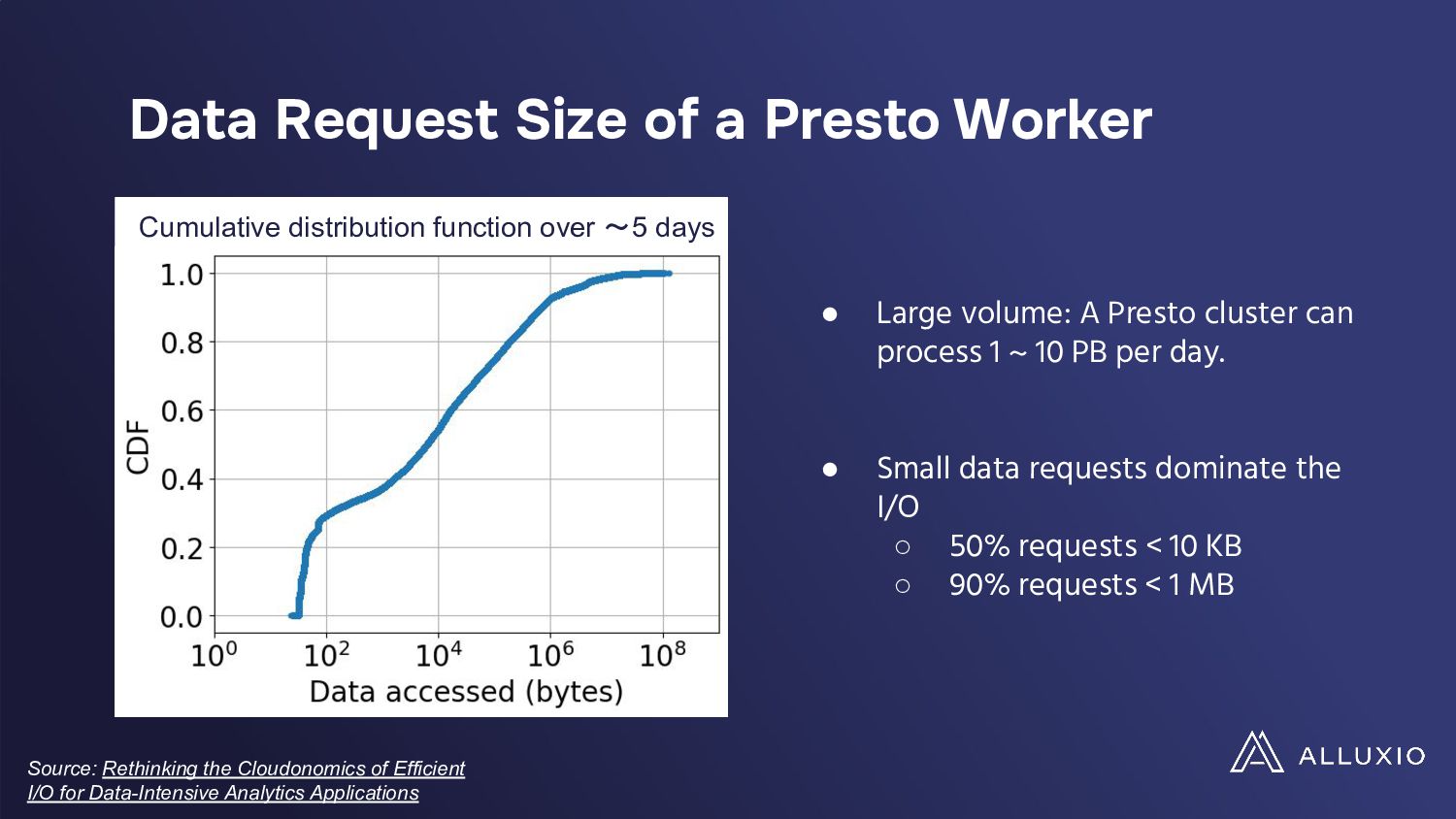
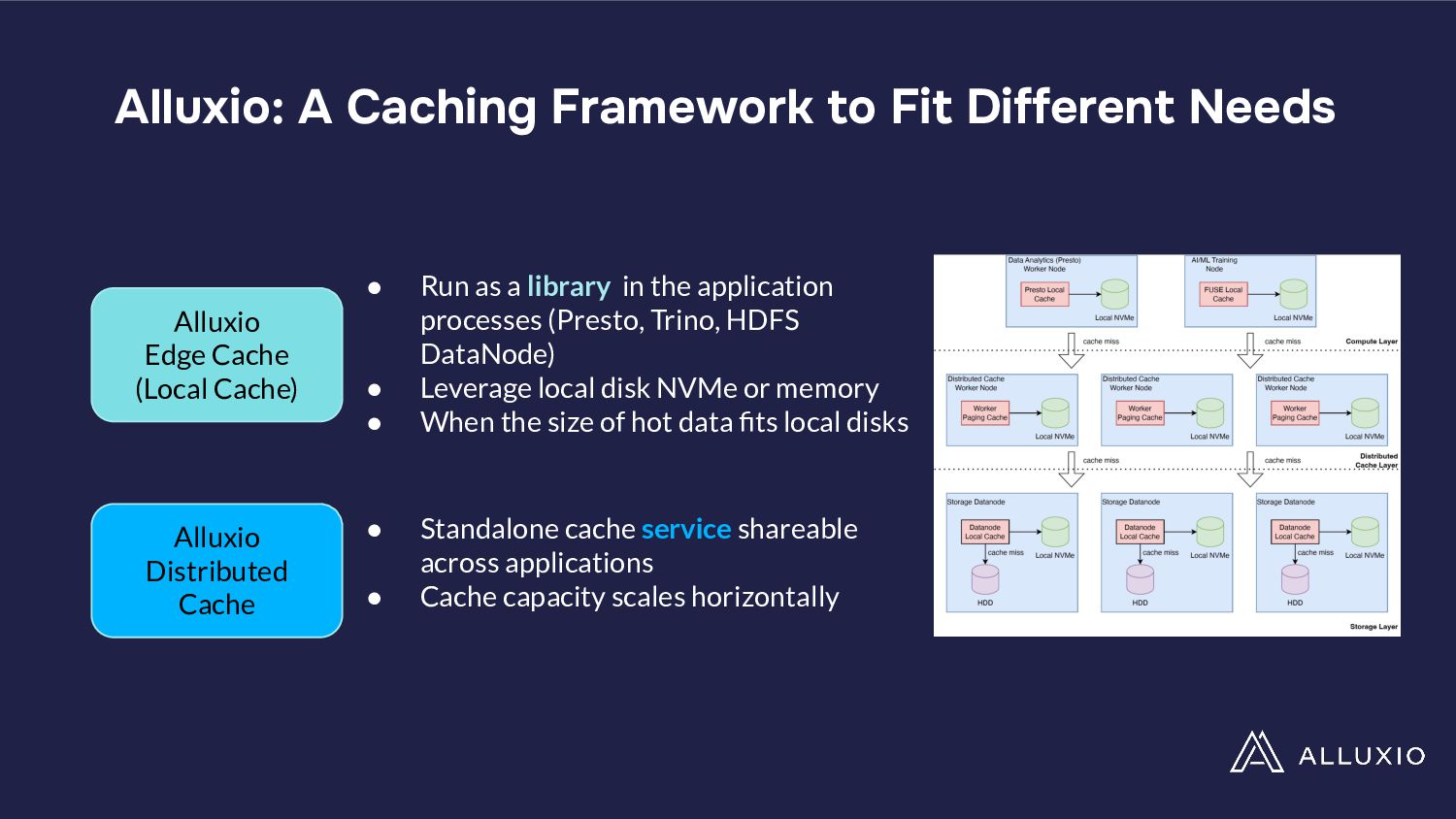
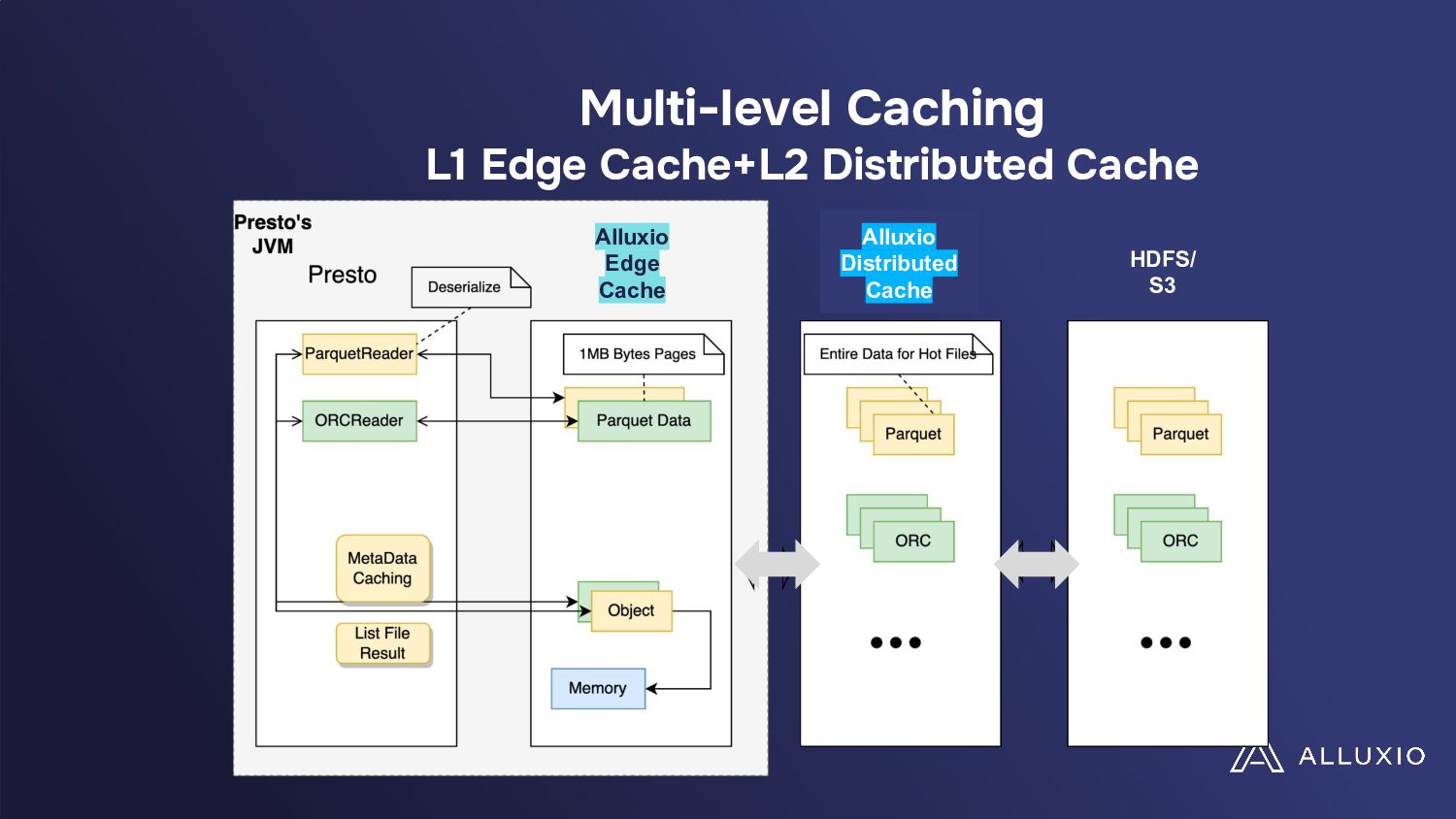
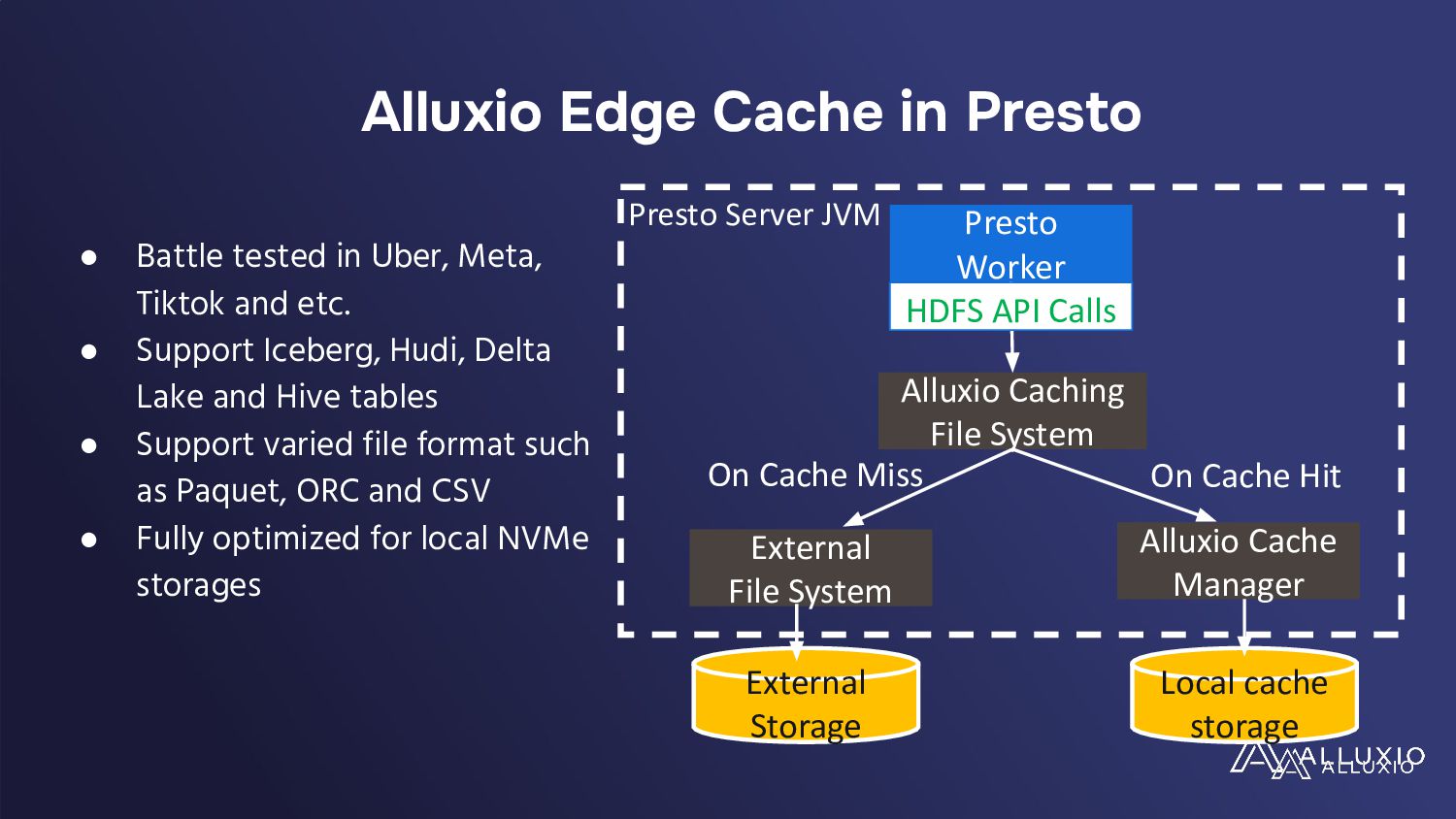
In a presentation, Hope Wang and Chunxu Tang will analyze these challenges through a case study on Presto's large deployment. They will show their findings of unexpected cost implications with standard I/O optimizations like table scans, filters, and broadcast joins when implemented in cloud environments. They will also highlight the need for a paradigm shift in optimizing data-intensive applications for the cloud and advocate for developing new I/O strategies, balancing performance and costs while tailored to cloud ecosystems' unique demands.
By attending this session, you will:
• Understand the complexities and cost challenges of optimizing data-intensive applications in cloud-native environments.
• Gain insights from an in-depth case study on the economic implications of traditional I/O optimizations in cloud deployments.
• Learn about the need for a paradigm shift towards developing I/O strategies that are both performance-efficient and cost-effective in the cloud.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}