Given at AI Dev Day with AI Hub FFM 2024
"How can AI help me in my day-to-day job?" I asked myself.
The question was answered quite quickly the next day when I had to read through a 22-comment-long discussion on GitHub, our developer platform of choice at ioki. I thought about adding a comment like "AI, please summarize!" to that discussion to get an AI-generated summary of it.
That idea became a reality, and we built a small helper tool called summaraizer that does exactly that.
Along the way, we discovered a few interesting things about Large Language Models (LLMs) such as:
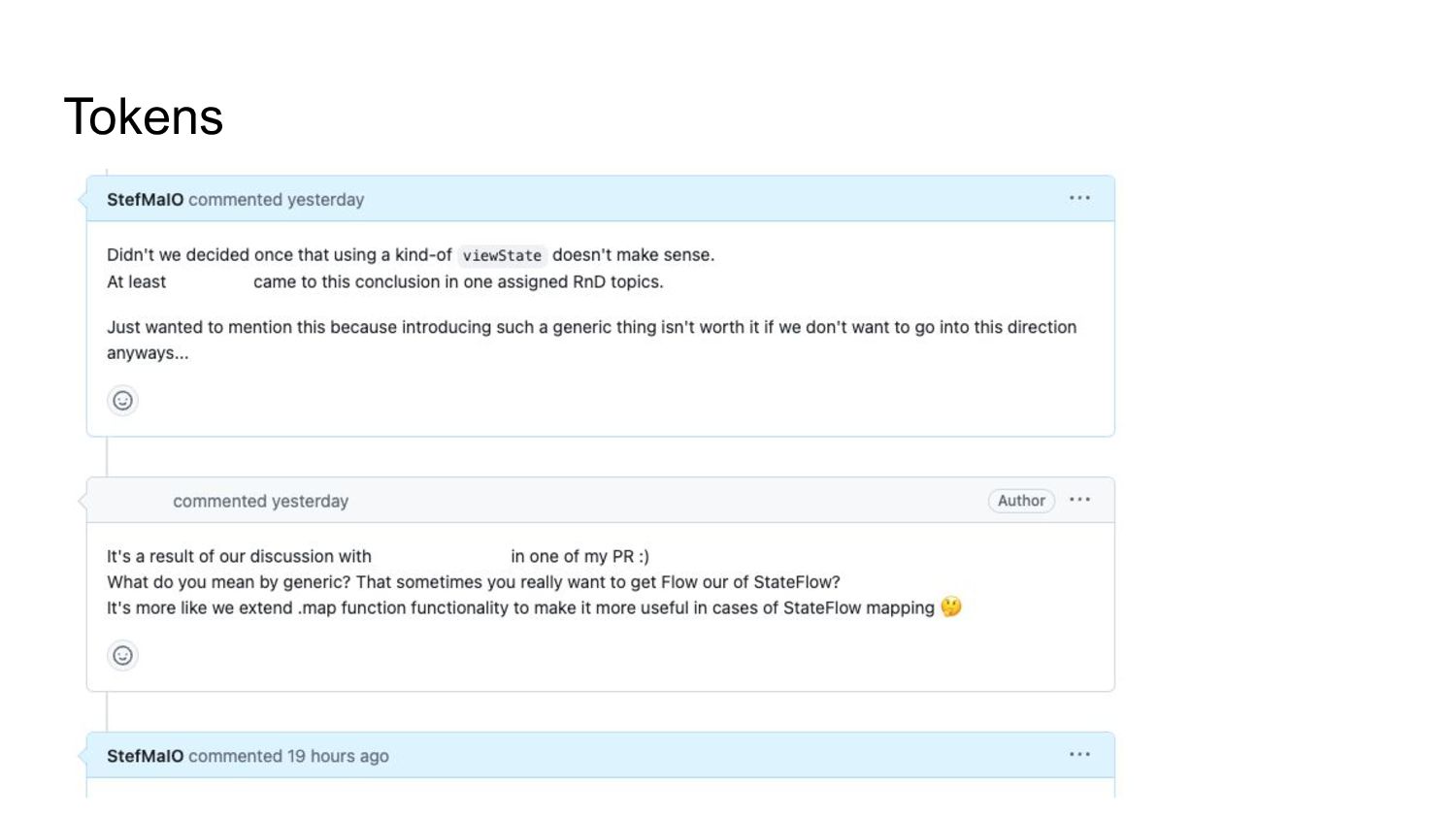
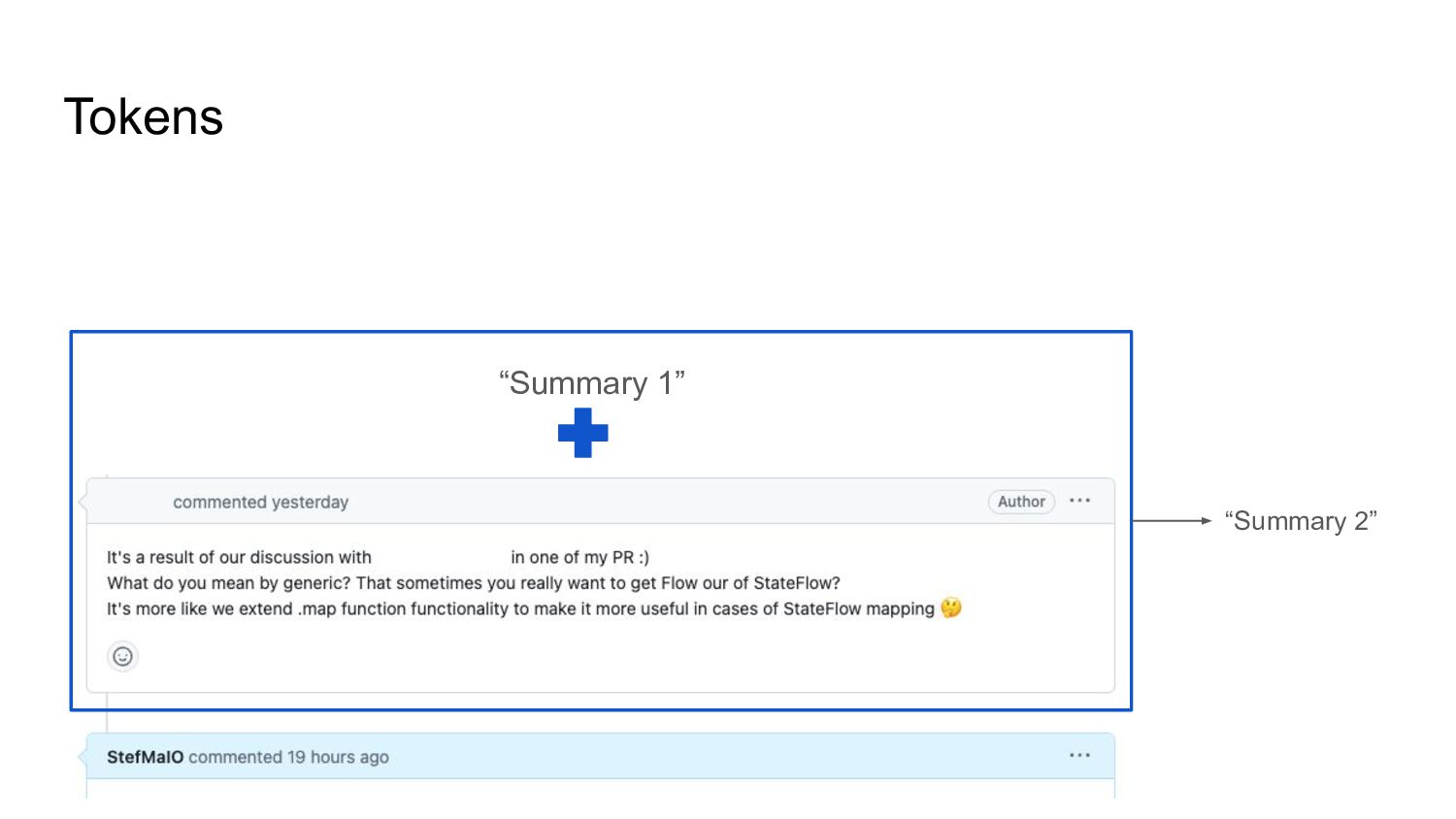
* What is a token limit, why it matters, and how to address it?
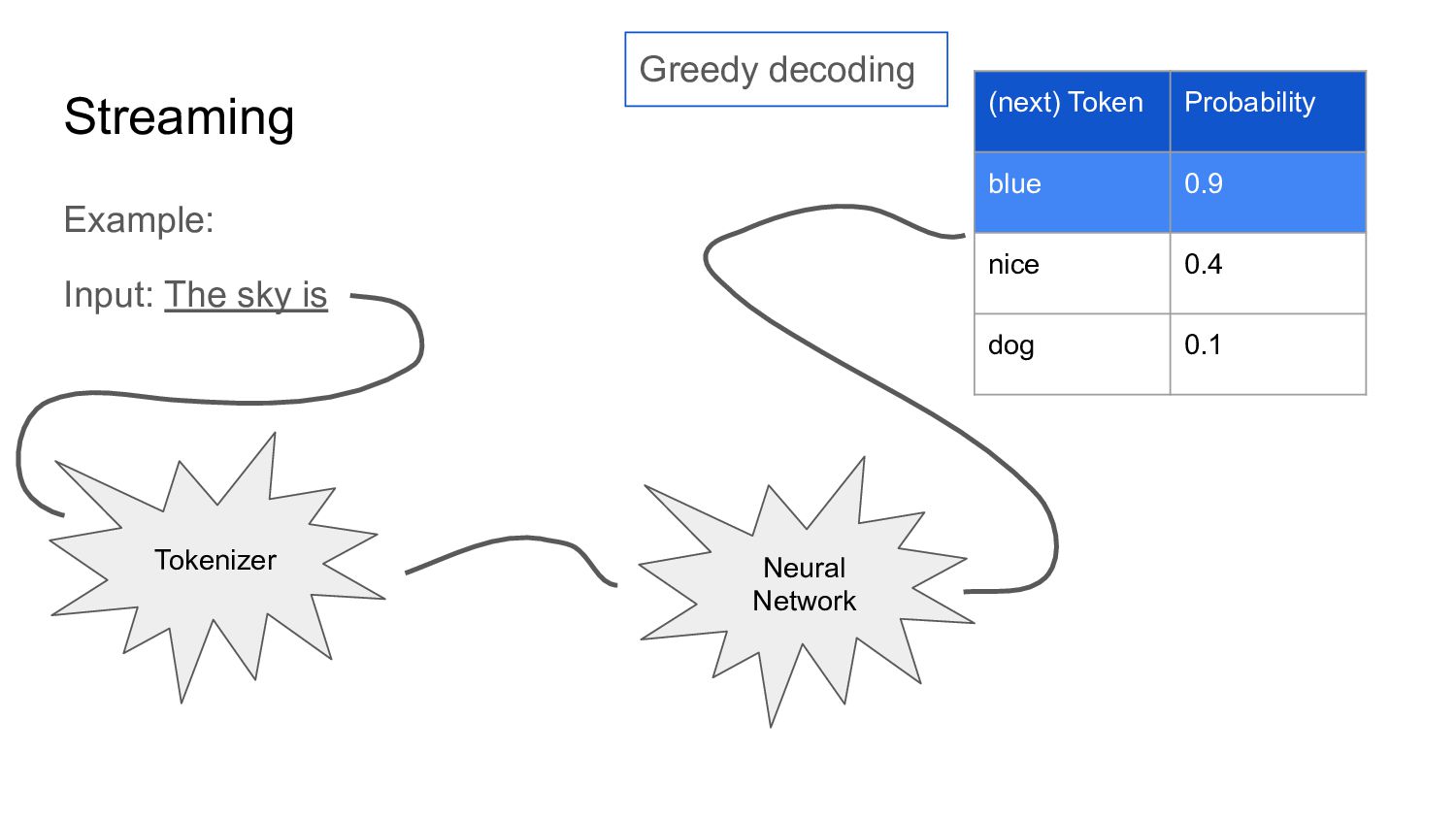
* Why does an LLM stream data?
* How to instruct the model to summarize a series of comments?
* And why doesn't the model always follow the instructions given?
* Why do various model types exist, and how do they differ from one another?
In this talk, I want to provide a brief overview of summaraizer and address some of the questions that arose during its development.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Model variants [model]:[x]b [model]:[text|instruct|...]](https://files.speakerdeck.com/presentations/86ee62cfce4a4f0ca3473bdc54d04726/slide_66.jpg){kind=link}
![Model variants [model]:[x]b b stands for billion (parameters) [model]:[text|instruct|...] variants](https://files.speakerdeck.com/presentations/86ee62cfce4a4f0ca3473bdc54d04726/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}