摘要
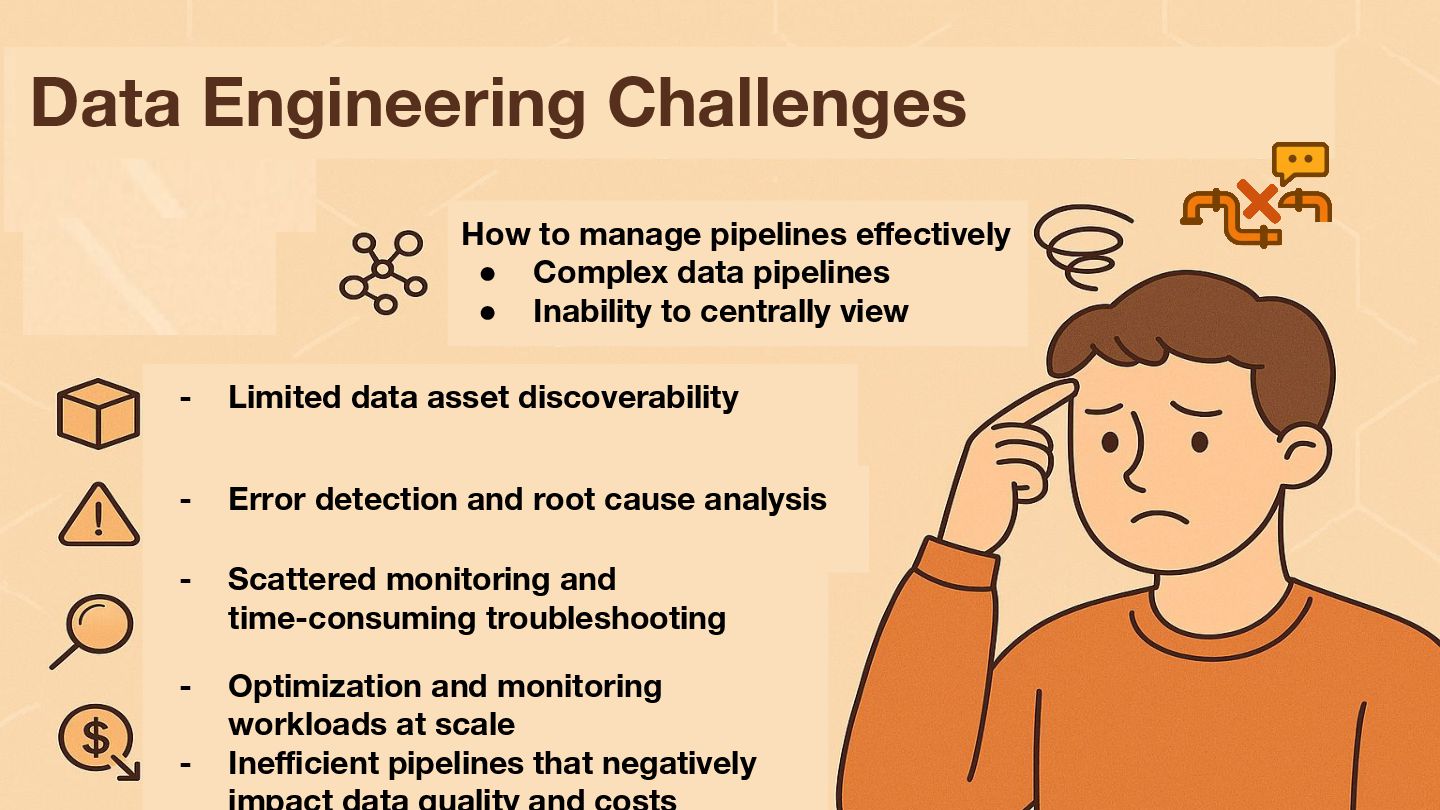
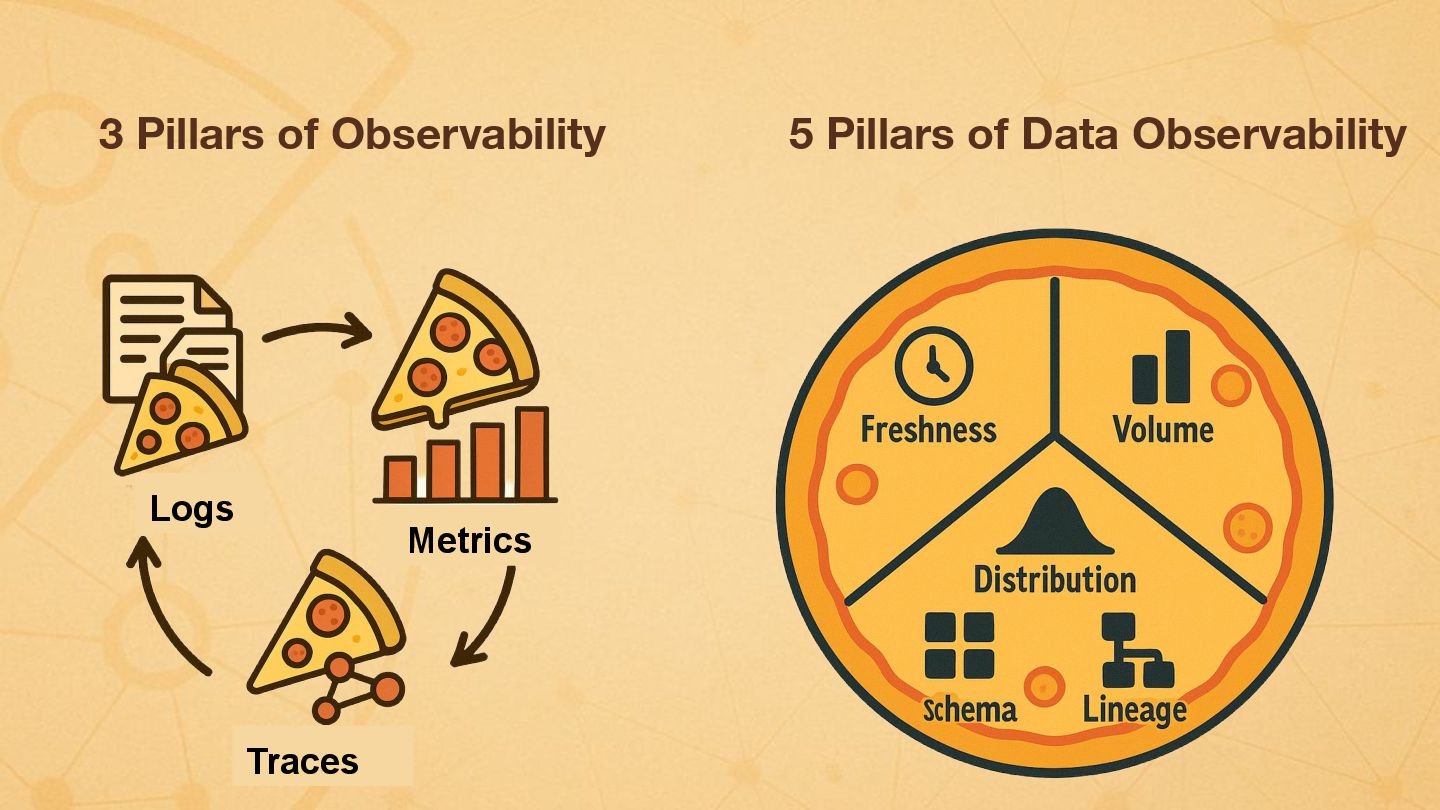
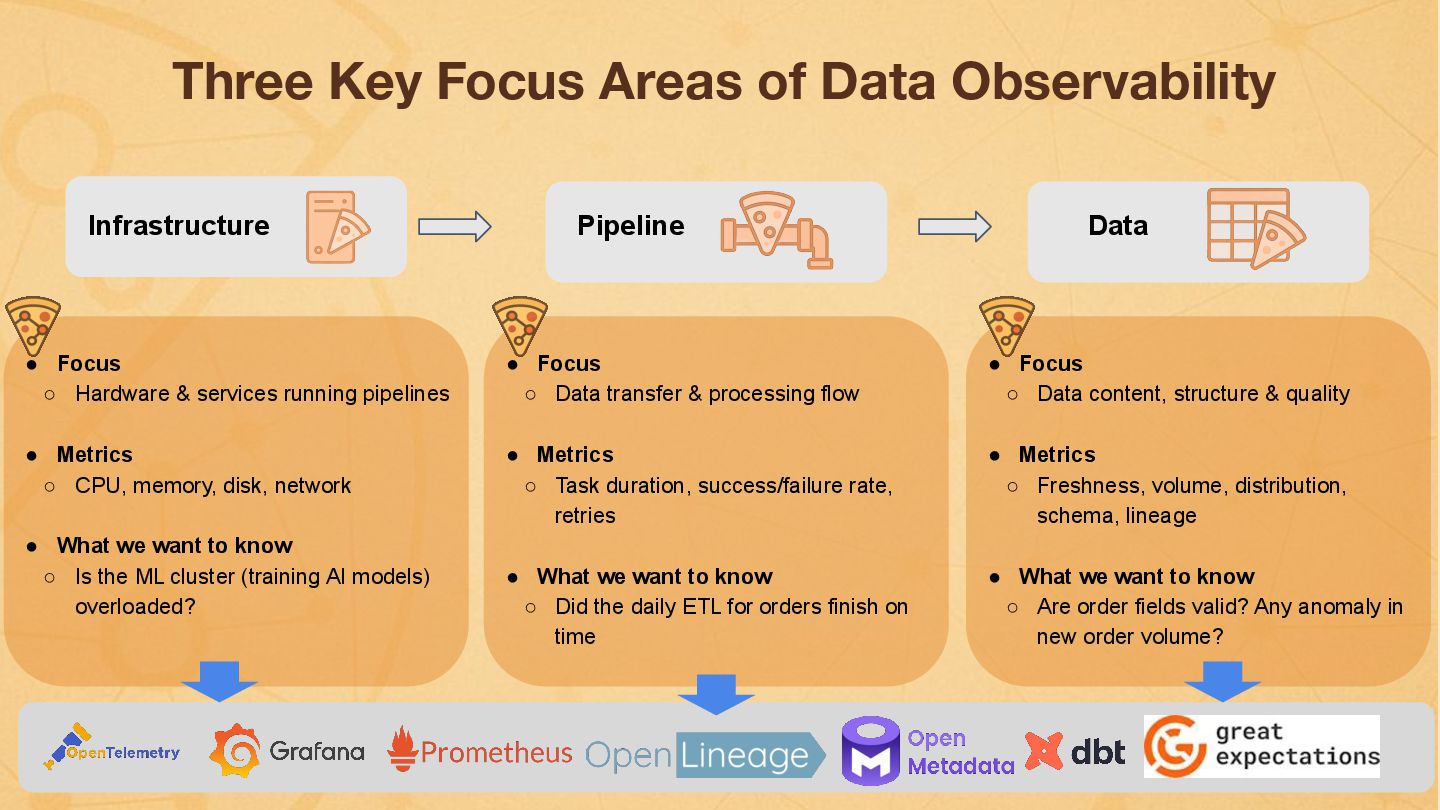
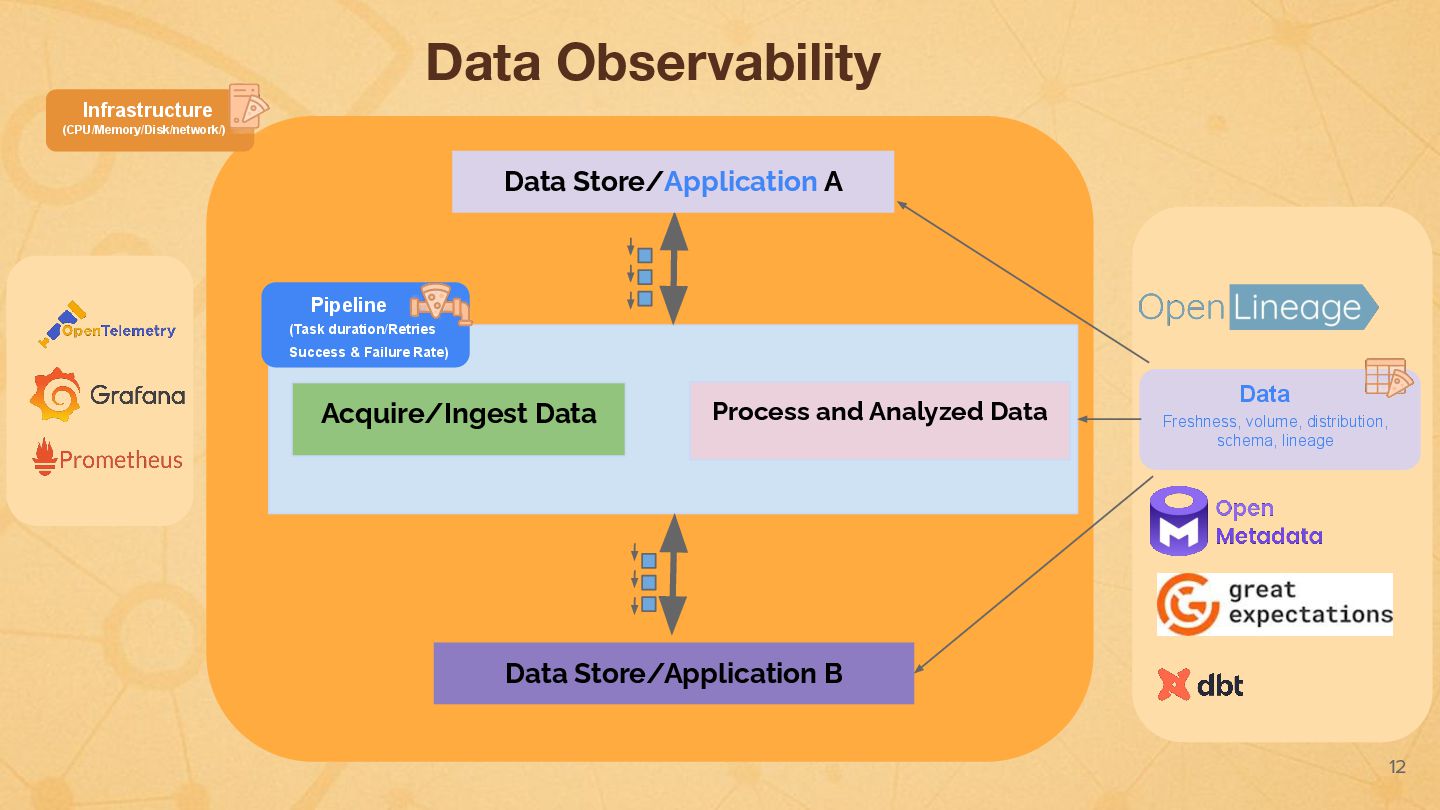
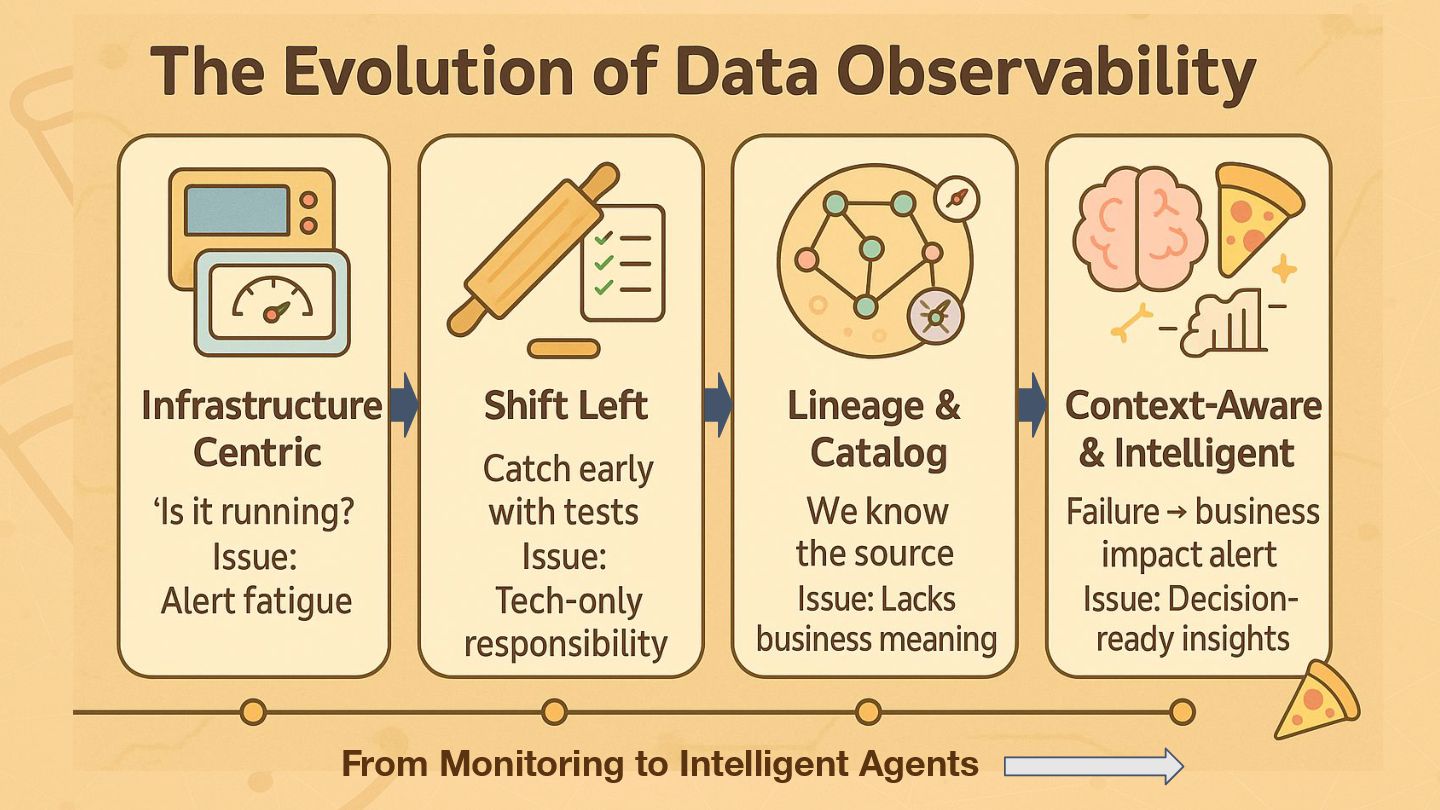
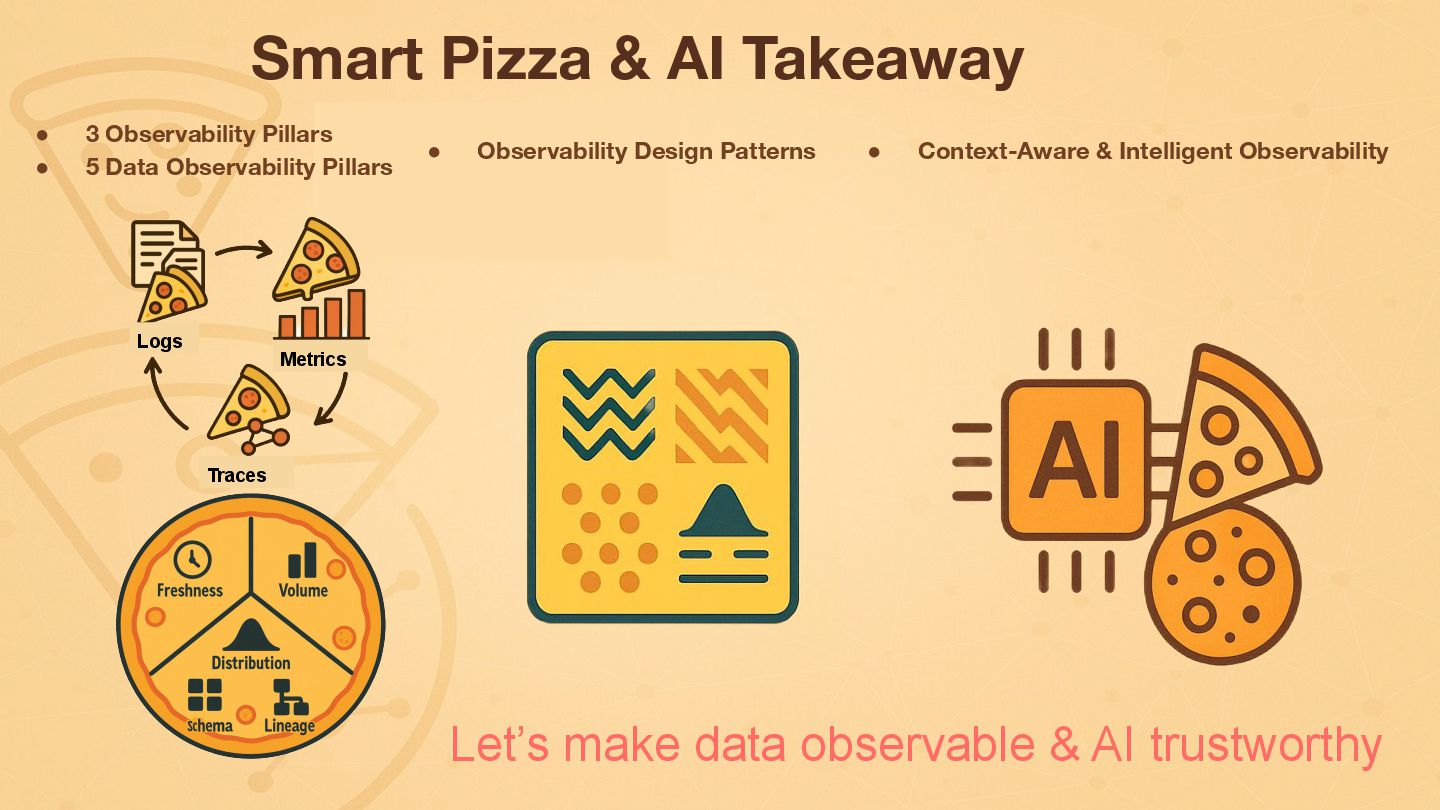
Data pipelines face unique challenges, often failing silently or suffering unnoticed data quality degradation that impacts downstream analytics, ML models, and business decisions. Standard application monitoring falls short. Foundational data engineering observability requires a dedicated approach, monitoring system health (logs, metrics, traces), data pipeline jobs and data-centric viewpoints. This talk introduces the essential data pillars – Freshness, Volume, Distribution, Schema, and Lineage – and explores practical Python implementation approaches. I'll introduce foundational techniques using libraries like OpenTelemetry, data quality tools (e.g., Great Expectations, dbt test), and custom scripts/metrics to establish baseline monitoring. Building this solid foundation is the critical first step towards enabling the advanced data-driven insights and deep correlation associated with the next version of observability for data pipelines.
In PyConTW 2025
{kind=link}
{kind=link}
{kind=link}
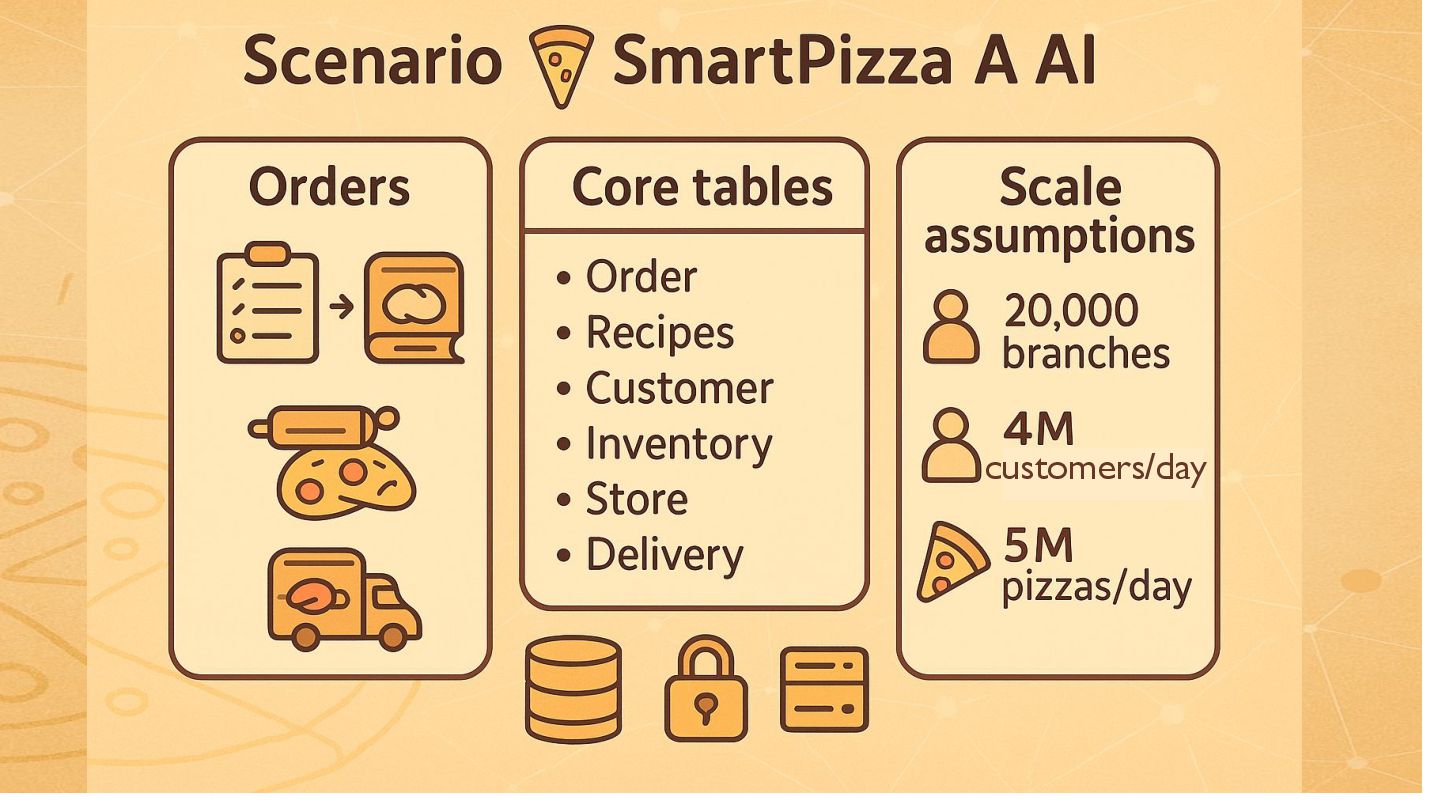{kind=link}
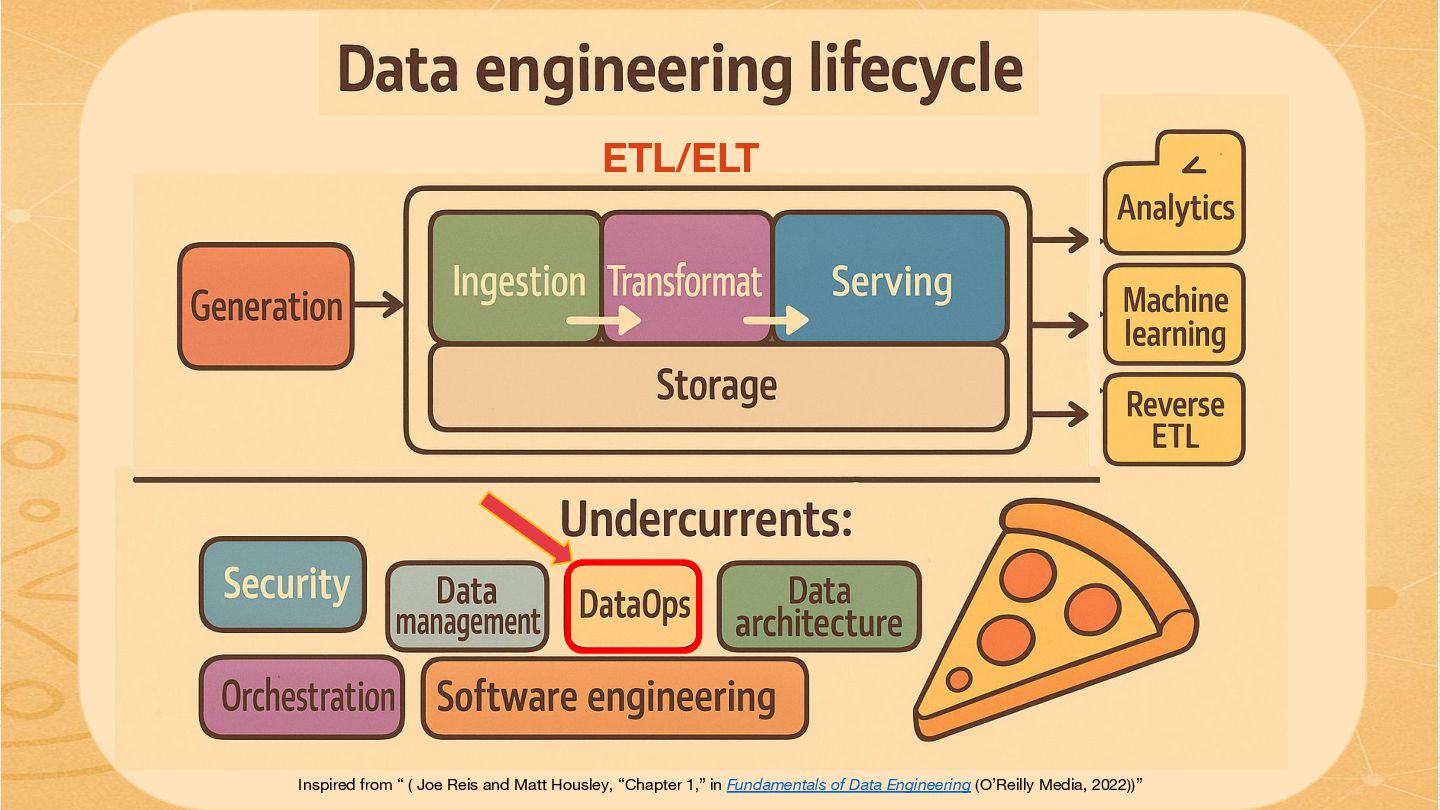{kind=link}
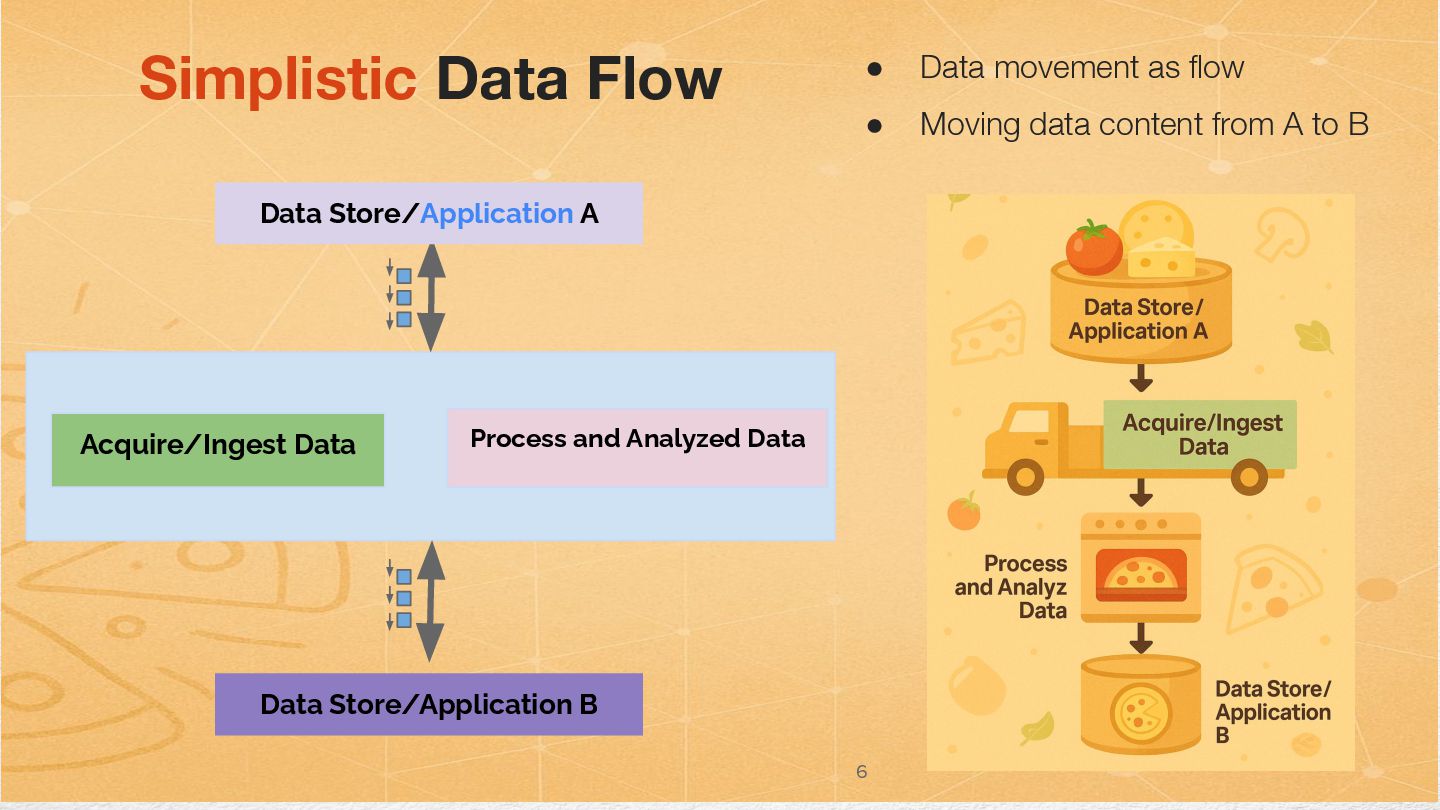{kind=link}
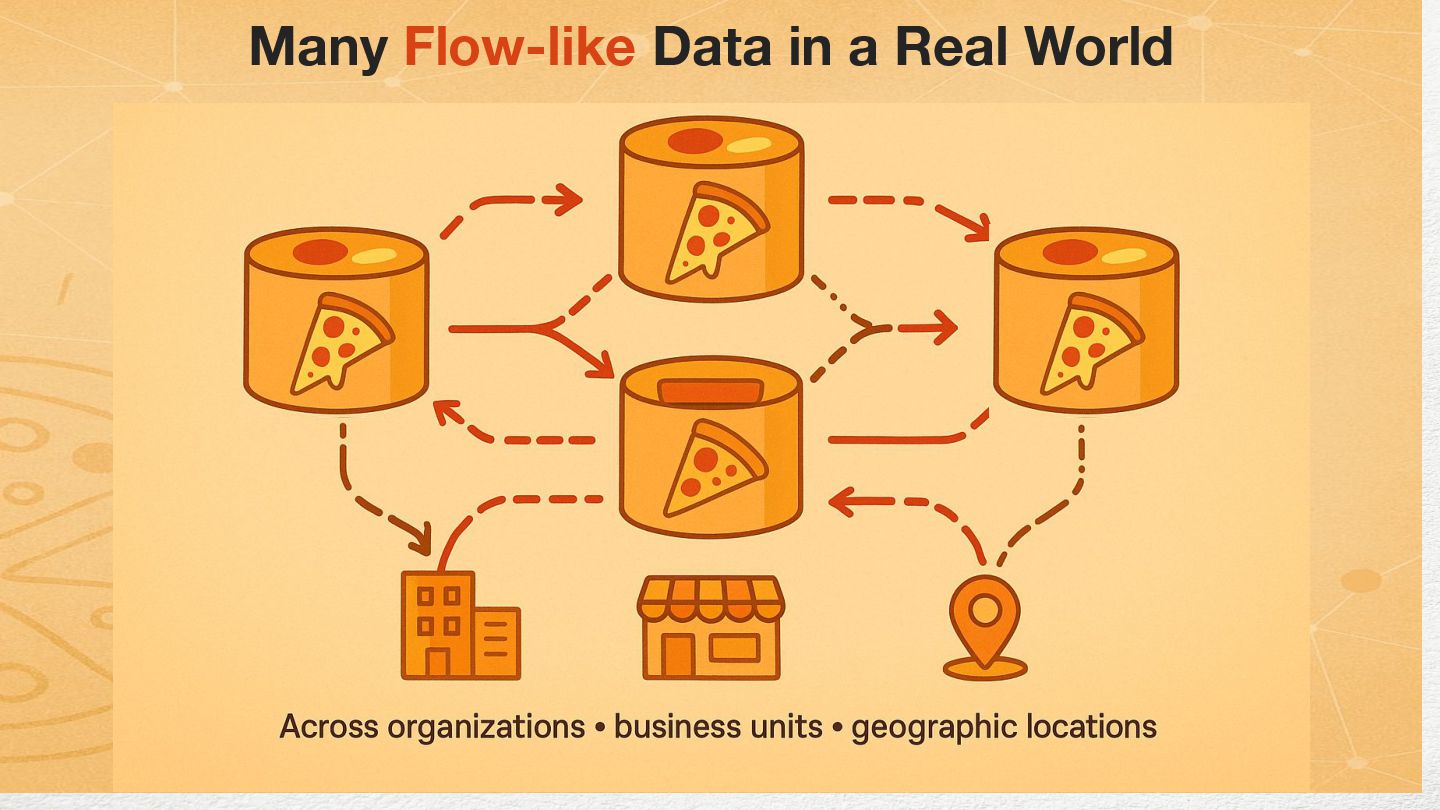{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
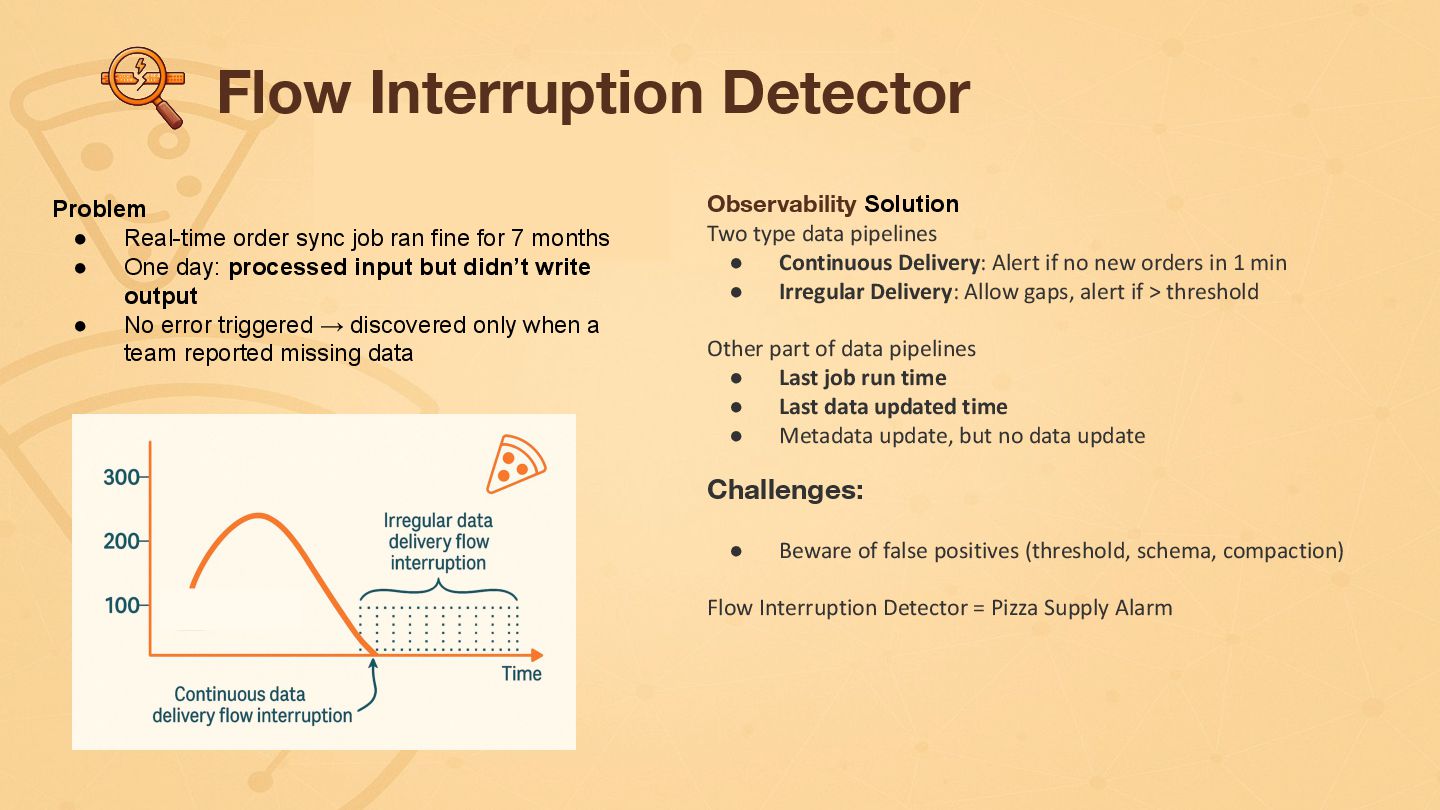{kind=link}
{kind=link}
{kind=link}
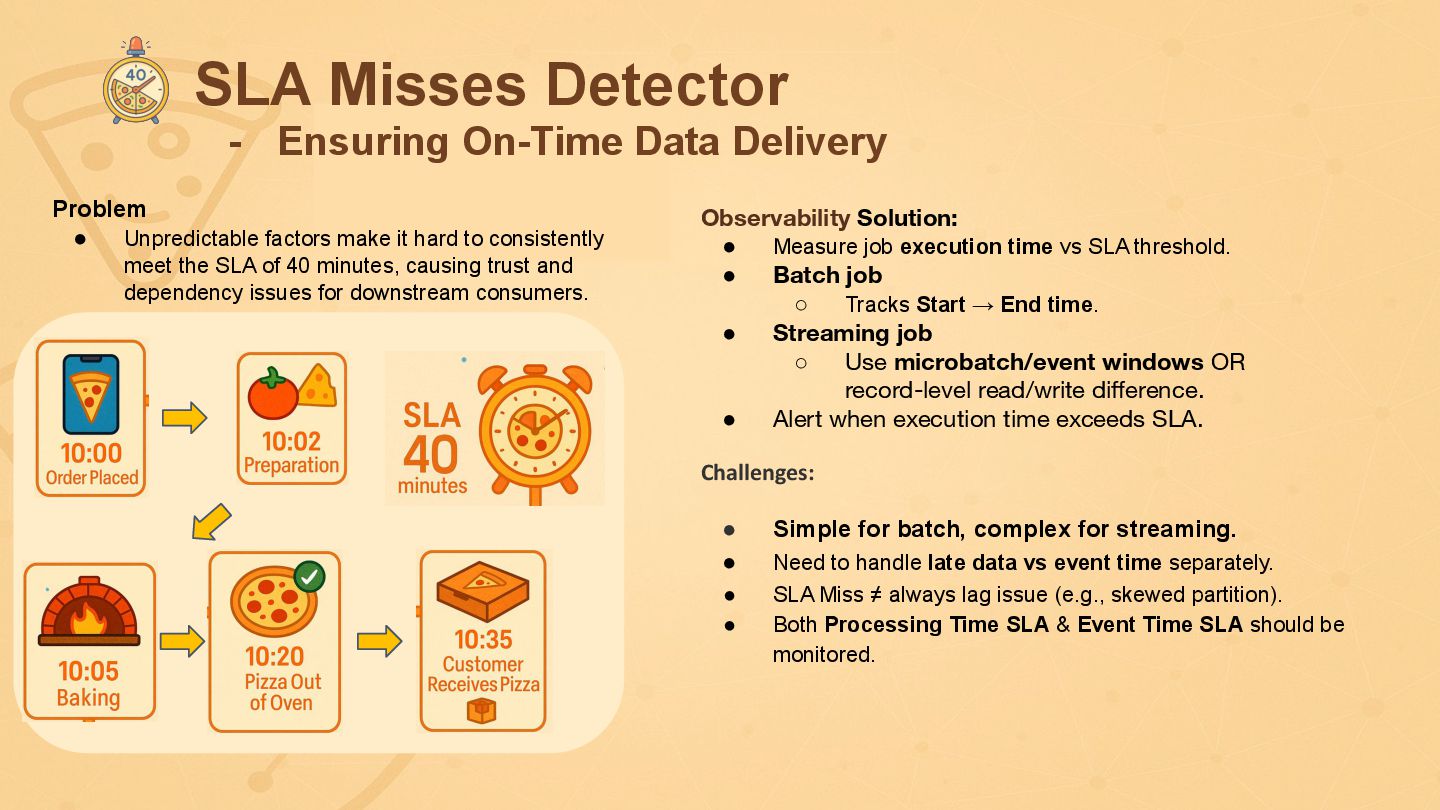{kind=link}
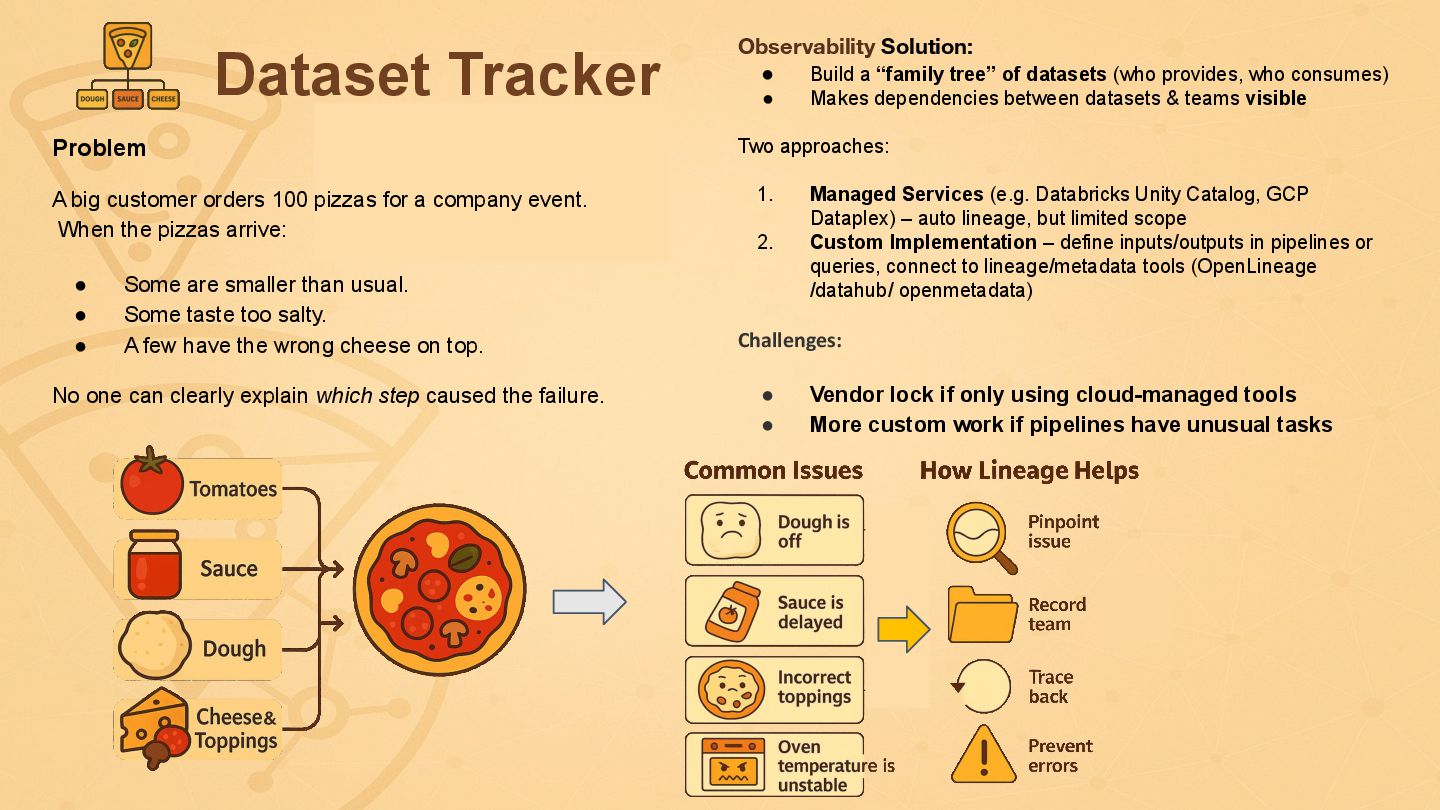{kind=link}
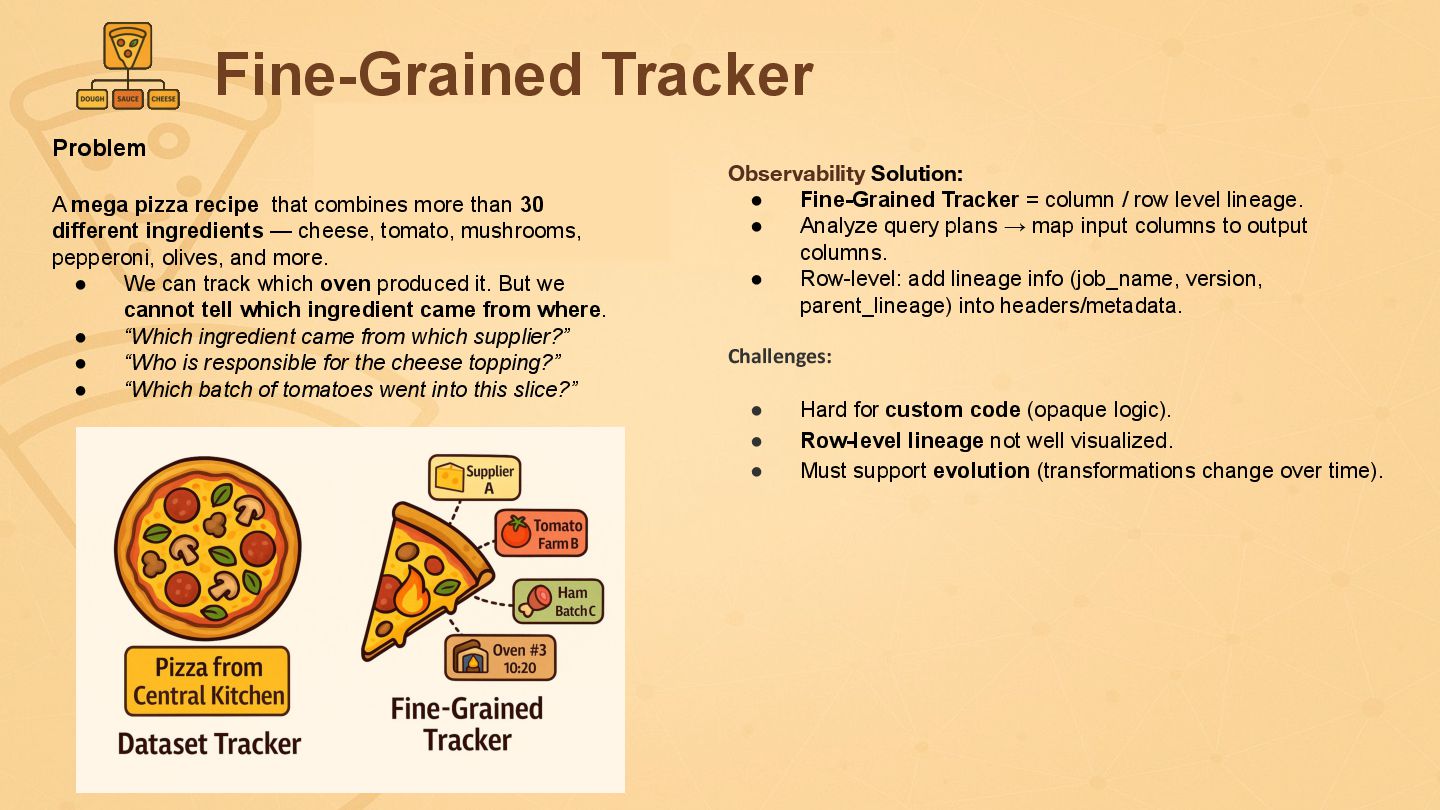{kind=link}
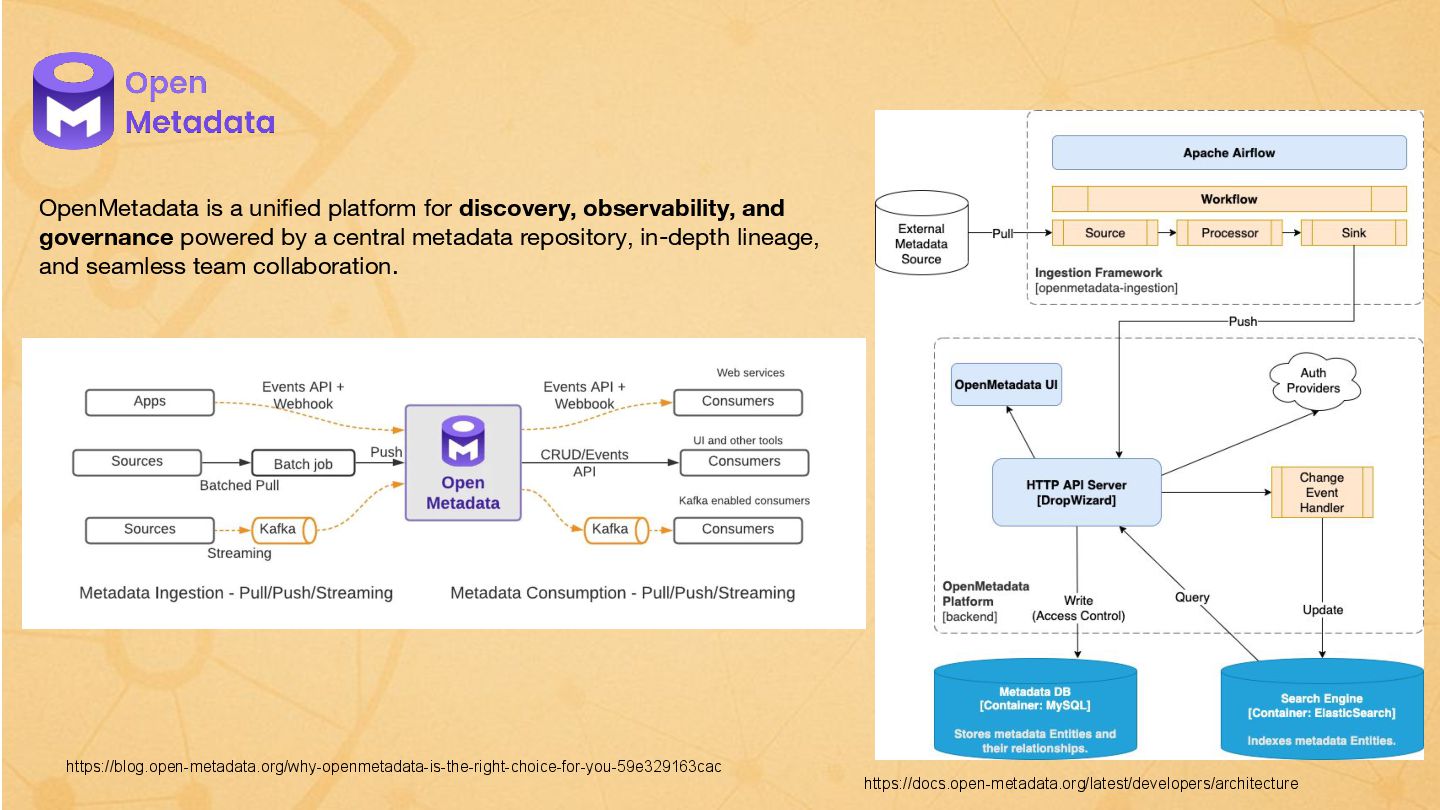{kind=link}
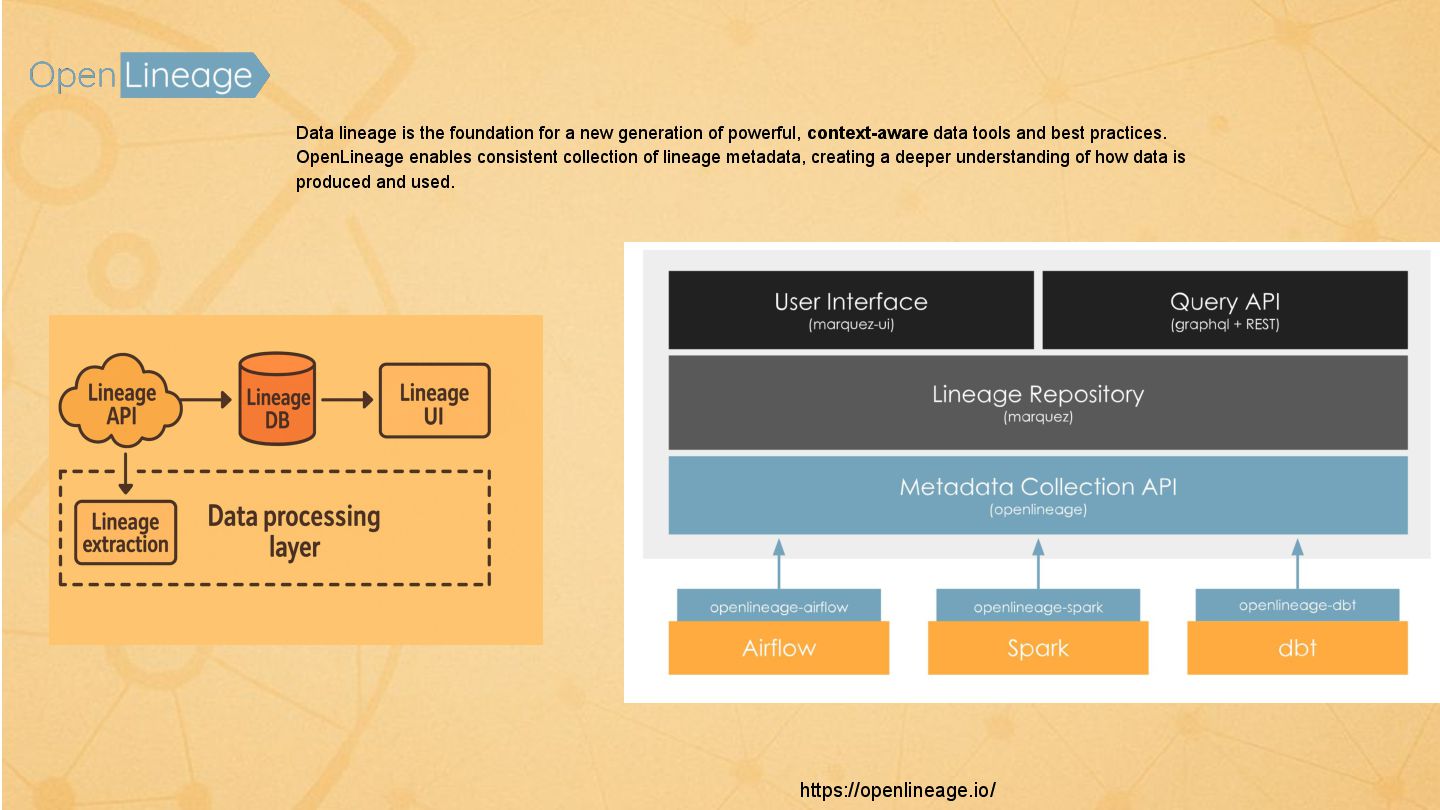{kind=link}
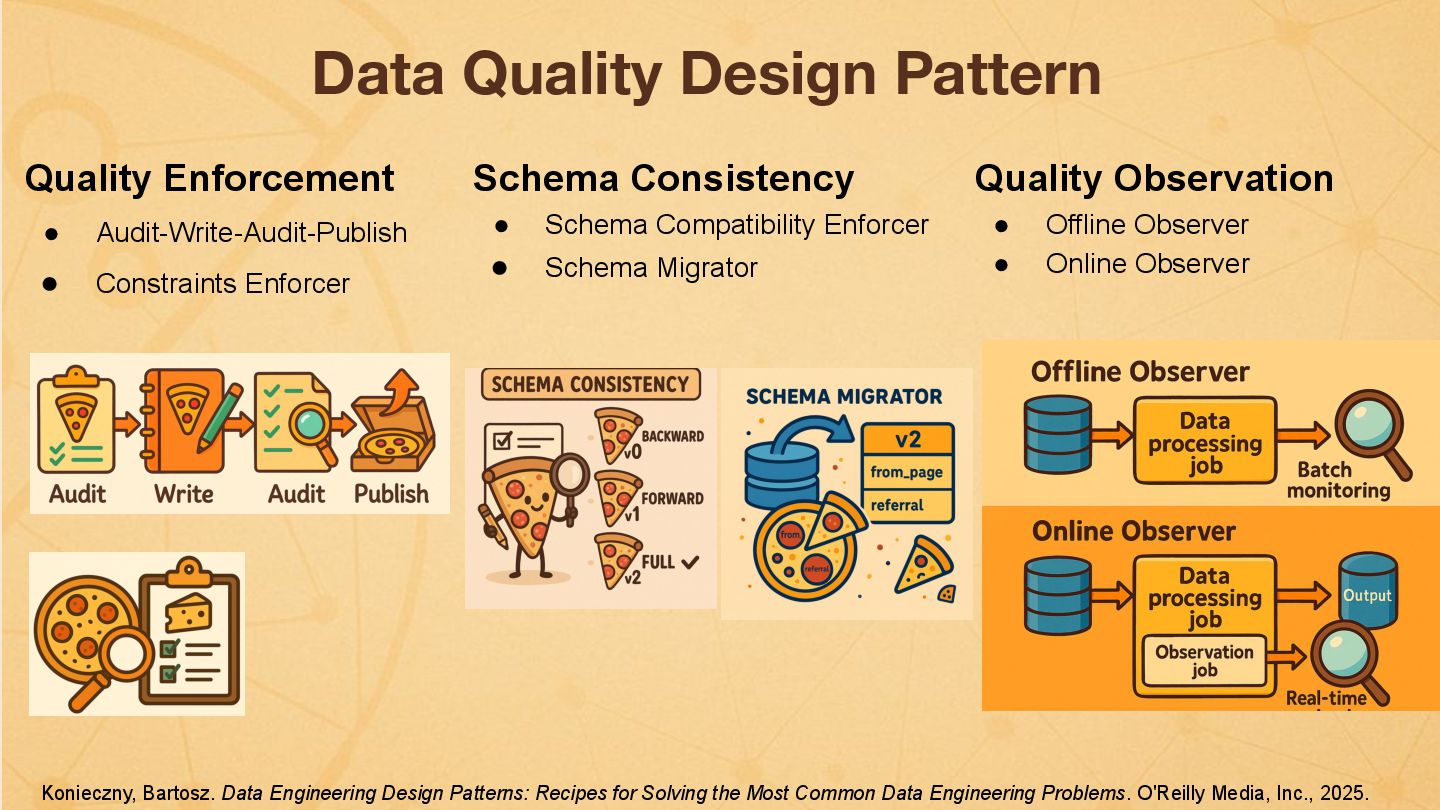{kind=link}
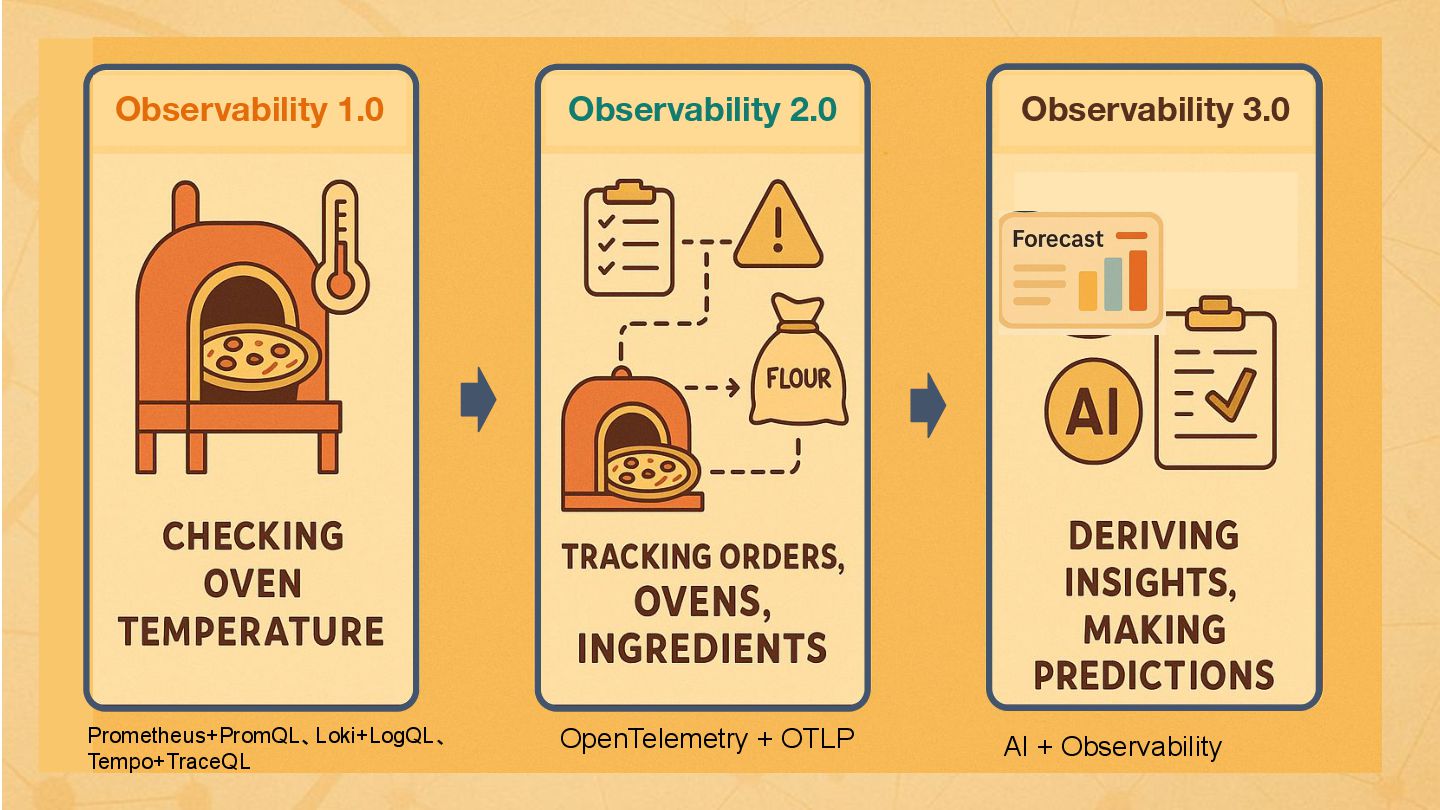{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}