development has long delivered value in big chunks. Many teams make the problem worse by tending to respond to stress by making the chunks of value bigger, from deploying software less frequently to integrating less often.
more things are deferred, the larger the chunk, the higher the risk. In contrast, the principle of flow suggests that for improvement, deploy smaller increments of value ever more frequently.
steps are expressed in practices like test-first programming, which proceeds one test at a time, and continuous integration, which integrates and tests a few hours' worth of changes at a time.
are many barriers to deploying frequently. Some are psychological or social, like a deployment process so stressful that people don't want to go through it twice as often.
solution — the easy but harmful one — is to slow down the release calendar. Like going to the dentist less frequently because it hurts, this response to the problem can only exacerbate the issue.
making very frequent small changes if you've only changed one thing at a time, it is really easy to figure out what broke the site https://www.youtube.com/watch?v=nEmJ_5UHs1g Robert Johnson
you released frequently, so the delta between what is currently in production and the new release is small. If that were true, the risk of release would be greatly diminished
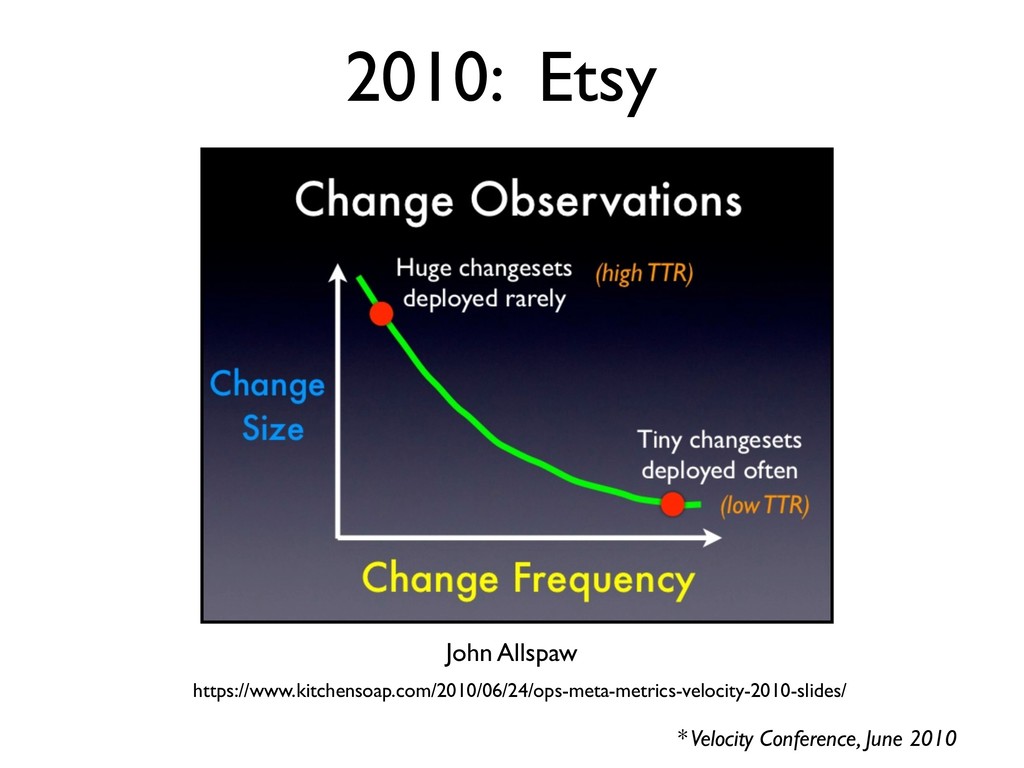
are reducing the amount of complexity that has to be dealt with at any one time by the people working on the batch. Break down large releases into small units of deployment 2012: Damon Edwards http://dev2ops.org/2012/03/devops-lessons-from-lean-small-batches-improve-flow/ * published March 2012
change that involved just one single line of code? Do you do this on a repeatable, reliable basis? * October 2012 2012: Jez Humble https://www.youtube.com/watch?v=skLJuksCRTw
number of changes per deployment, which is an inherent benefit of continuous delivery and helps mitigate risk by making it easier to identify and triage problems if things go south during a deployment. https://medium.com/netflix-techblog/deploying-the-netflix-api-79b6176cc3f0 2013: Netflix * published August 2013
You know what's changed in production. If it doesn't work, rollback is simple * Surge conference, September 2013 https://www.youtube.com/watch?v=8-6azNVq2X0
a day. And there's good reason for that: it's safer overall. Incremental deploys are easier to understand and fix than one gigantic deploy once a year. https://zachholman.com/talk/move-fast-break-nothing/ 2014: Github * published October 2014
due to understandable fear unfortunately, this means that our changes build up between releases 2015: Building Microservices * book published February 2015
to say that we now know that smaller and more frequent changes are much safer than larger and less frequent changes ship early, ship often, ship smaller change sets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
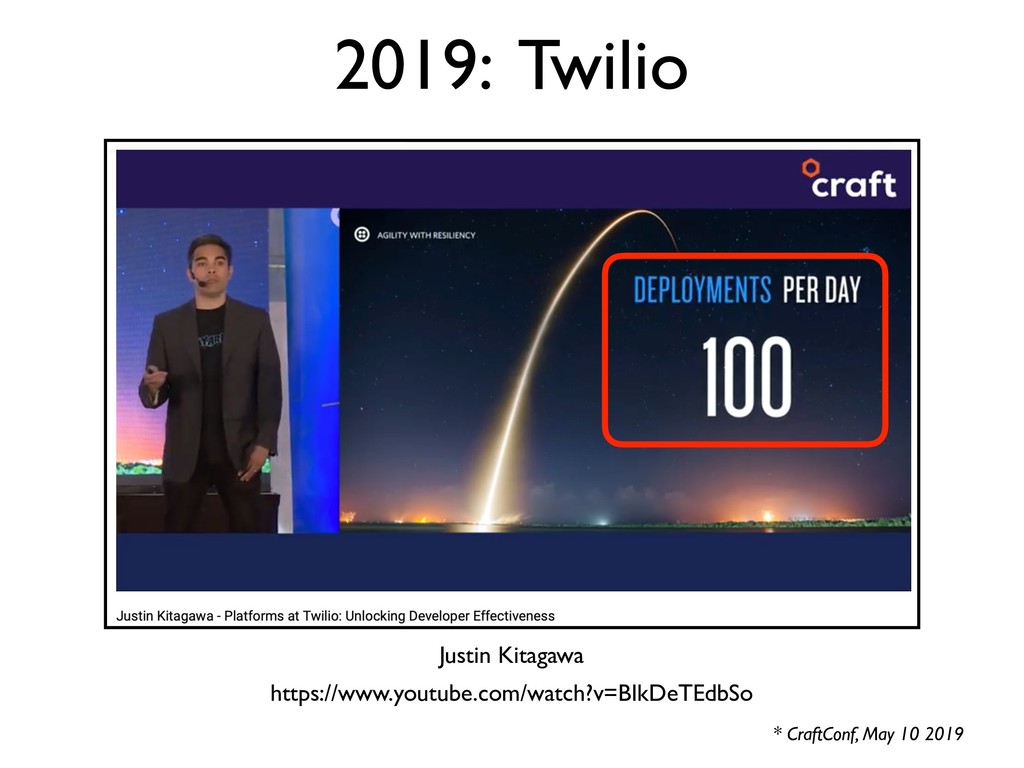{kind=link}
{kind=link}
{kind=link}