Presented at ConFoo 2014
We've all heard in recent years about how Key-Value stores cast off the scaling problems of SQL-based solutions and give developers the flexibility to choose in-memory or disk-persistent, single-node or clustered options.
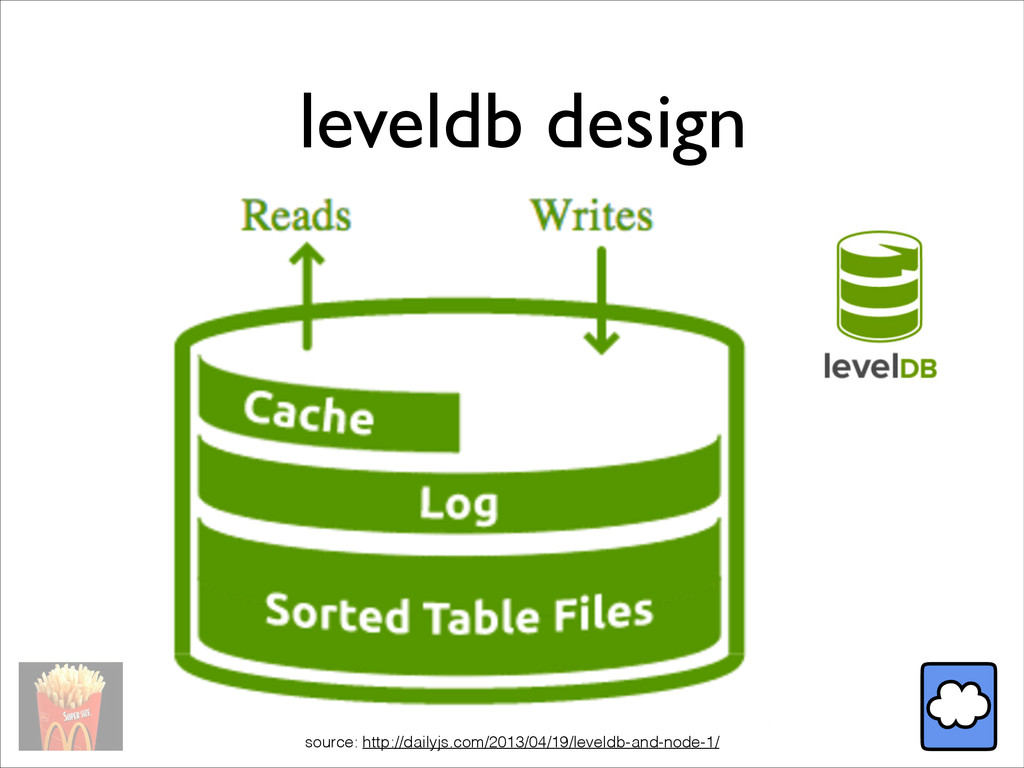
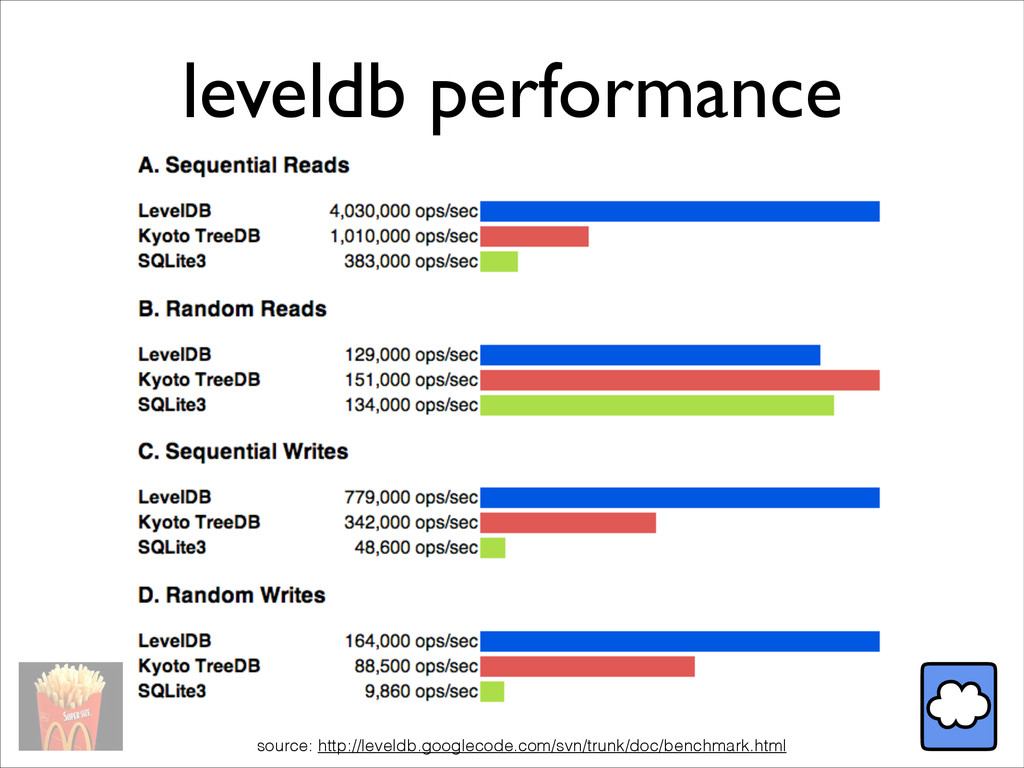
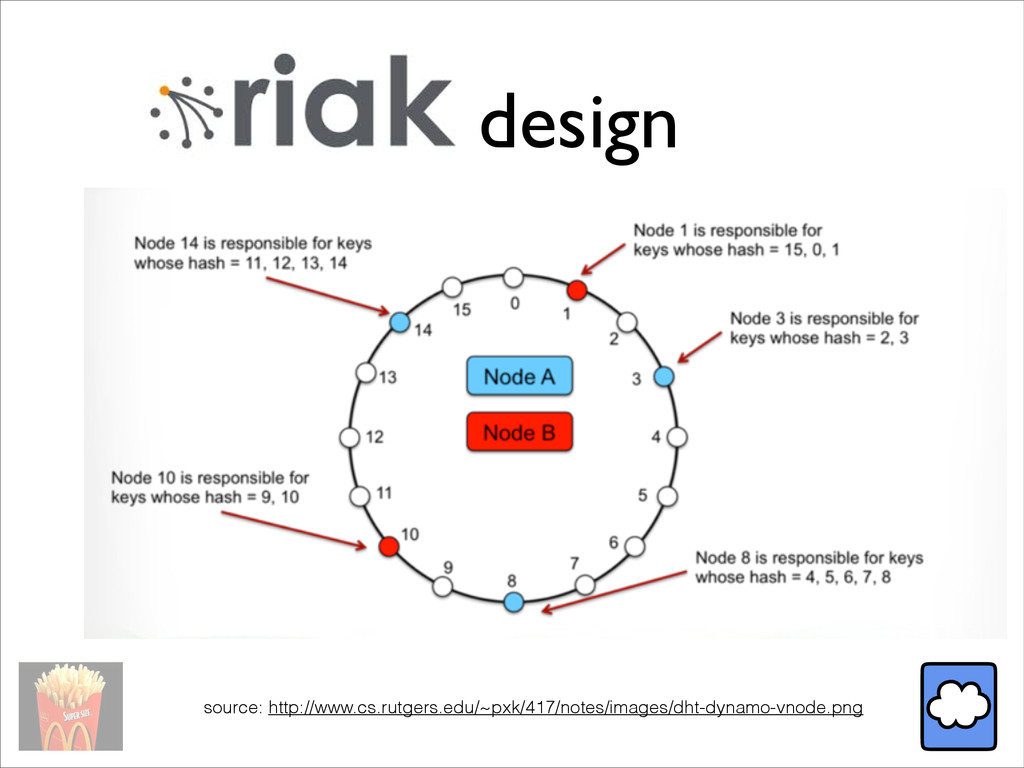
In this talk, we review design and performance of several key-value stores (Riak, LevelDB, and MySQL API), and several techniques such as efficient compression and schema extraction to get the most out of any KV store.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![leveldb api • byte[] DB.get(byte[] key) void DB.put(byte[] key, byte[]](https://files.speakerdeck.com/presentations/5e14724082d5013107e95ea41e86eac8/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
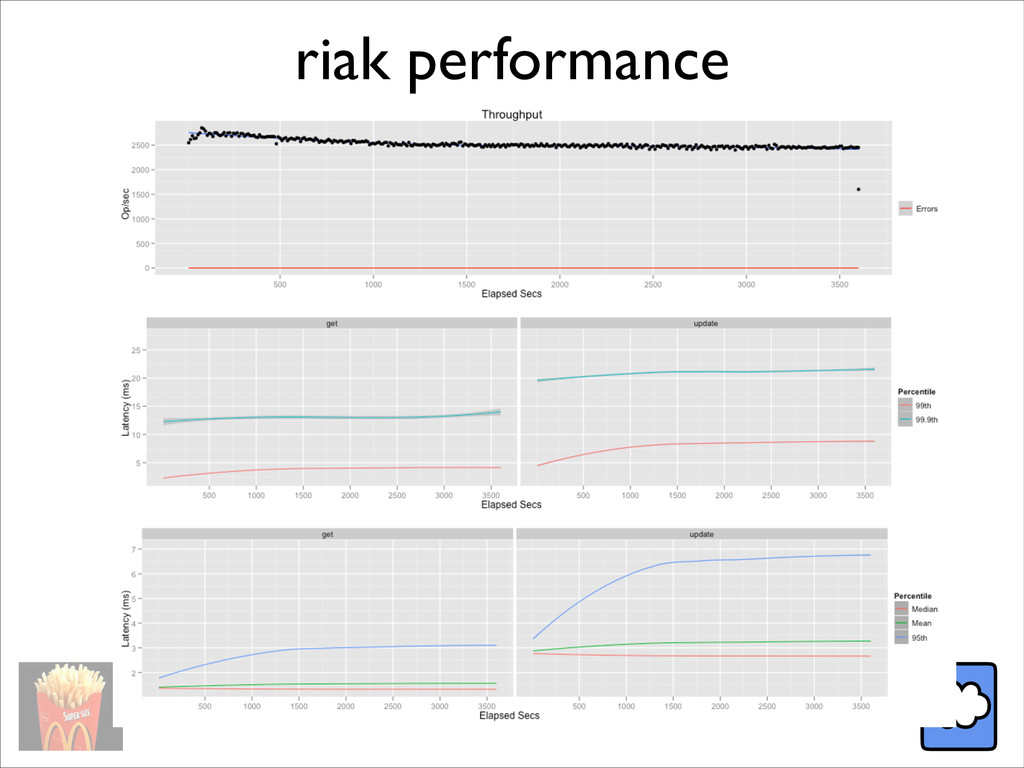{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
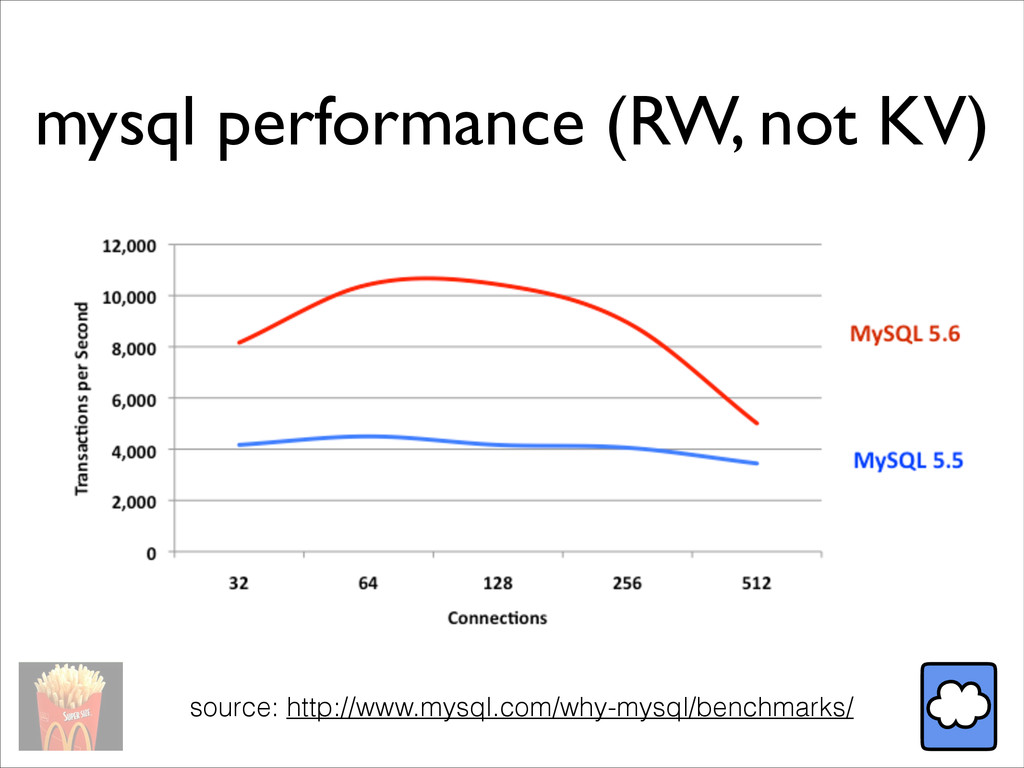{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
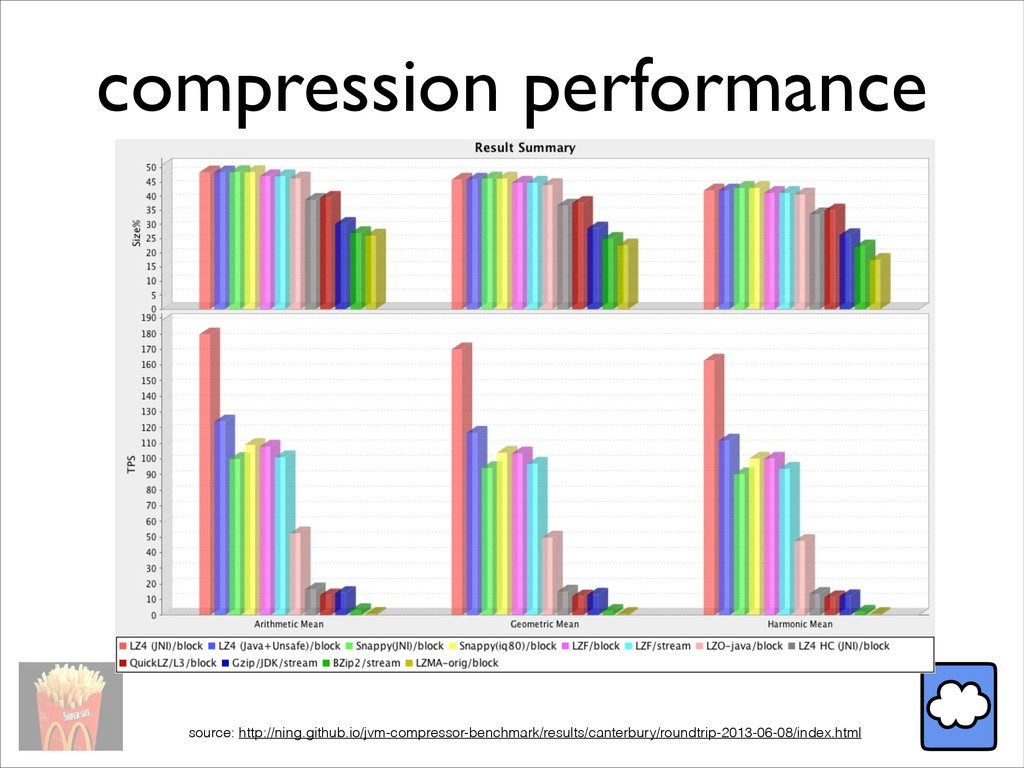{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}