Erlang) Software Transactional Memory (STM) (consistent and safe way to access shared state) Data: decentralized datastores (run map/reduce queries on many nodes at once)
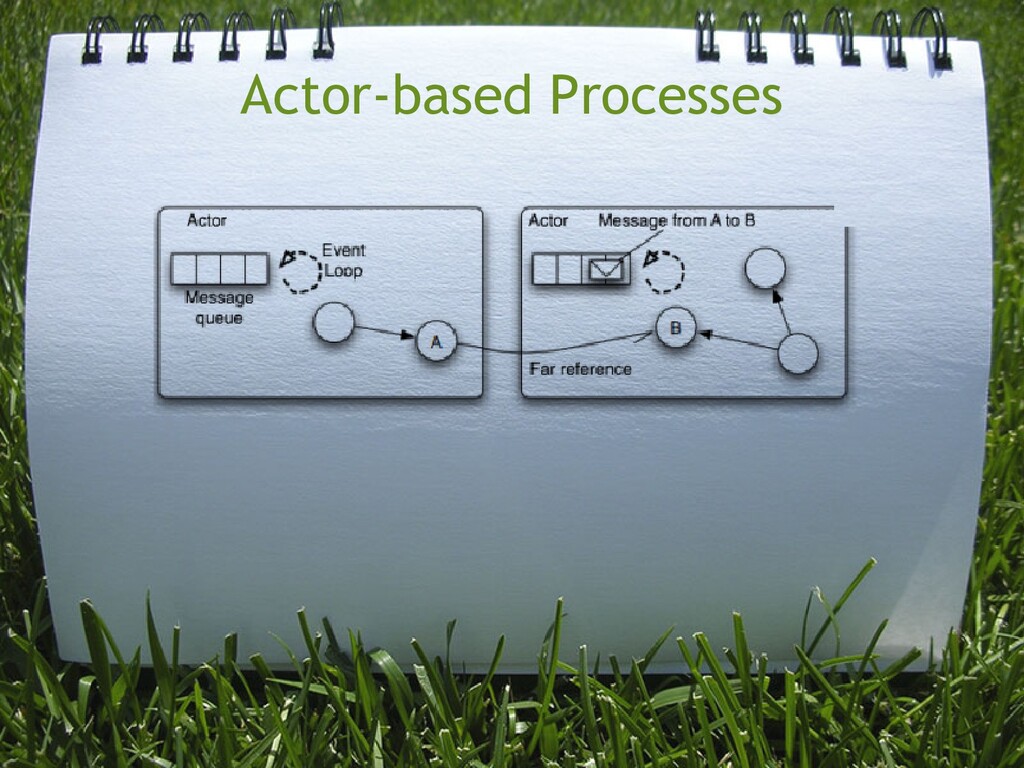
task threads compete for locks on objects synchronous operations within task thread limited task scheduling (e. g. wait, notify) mailboxes buffer incoming messages actors do not share state, thus not competing for locks messages sent asynchronously actors react to messages sent to them
becomes bottleneck (debugging race conditions, deadlocks, livelocks, starvation). Depends on your use case. system is event-driven conceptually. Easier to translate to high level abstraction in actor-based models.
locking Locking semantic need to be hand coded Composable operations are not well supported Analogous to database transaction recording each txn as log entry Optimistic reading Atomic transaction Supports composable operations
numbers of cores/processors (~>=4) Hand coding and debugging locking semantics for application becomes your bottleneck to prevent deadlocks and livelocks Priority inversion often hinders performance BUT YOU CAN'T use STM when operation on shared state cannot be undone. Must be undoable!
for a few use cases Requires full replica(s) of data set on each node Improve throughput, performance of complex queries using map/reduce Flexibility to optimize two of three: Consistency, Availability, Partition tolerance (CAP Theorem) Does not require full replica(s) of data set
distribute without creating/managing your own sharding scheme Want to optimize two of CAP Run distributed map/reduce complex queries BUT datastore should satisfy your other needs first. Usually key-value/bucket lookup, not RDBMS!
your concurrent system judiciously Ensure your applications fit use case(s) for approach Test your hypothesis by benchmarking NEVER assume your changes have made the impact you expect. There is no silver bullet: think, implement and test!
{kind=link}
{kind=link}
{kind=link}
![Traditional Approaches Task-based thread [pools] (e.g. database connections, server sockets)](https://files.speakerdeck.com/presentations/8fe248c751bc409abc52496b5965579b/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions Twitter: @SusanPotter GitHub: http://github.com/mbbx6spp Email: [email protected]](https://files.speakerdeck.com/presentations/8fe248c751bc409abc52496b5965579b/slide_15.jpg){kind=link}